Wprowadzenie
Pracujesz w firmie konsultingowej jako data scientis. Projekt, do którego jesteś obecnie przydzielony, zawiera dane studentów, którzy niedawno ukończyli kursy dotyczące finansów. Firma finansowa, która prowadzi kursy, chce zrozumieć, czy istnieją wspólne czynniki, które wpływają na to, że studenci kupują te same kursy lub kupują różne kursy. Rozumiejąc te czynniki, firma może stworzyć profil studenta, sklasyfikować każdego studenta według profilu i polecić listę kursów.
Podczas sprawdzania danych z różnych grup uczniów natknąłeś się na trzy dyspozycje punktów, jak w 1, 2 i 3 poniżej:
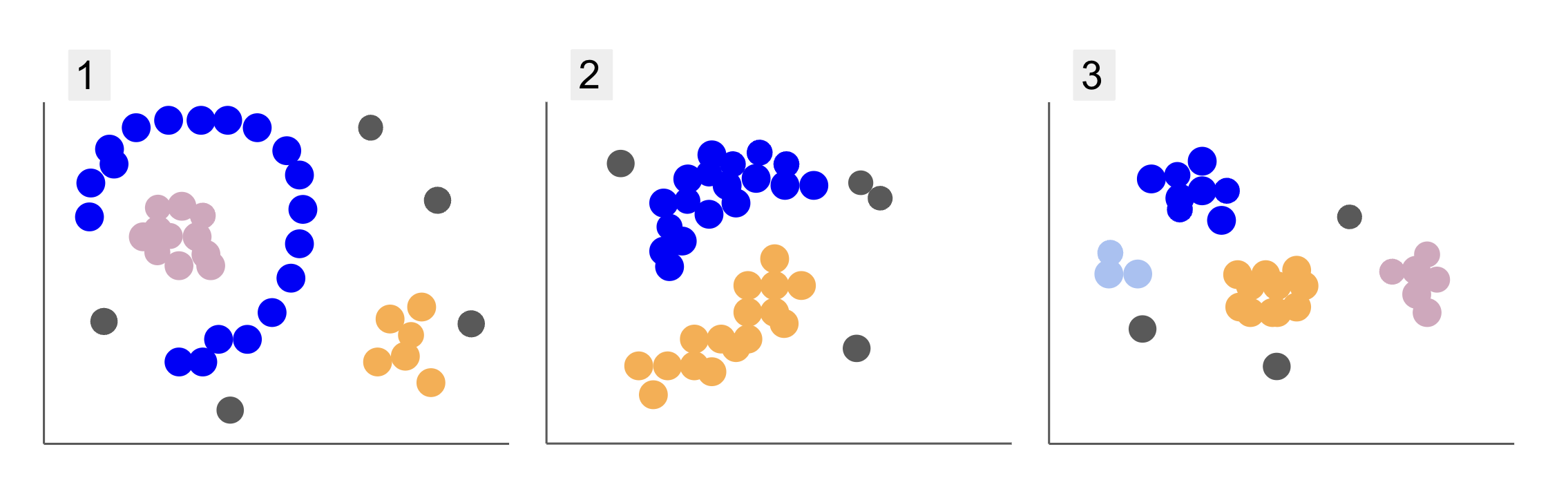
Zauważ, że na wykresie 1 znajdują się fioletowe punkty zorganizowane w półkole, z masą różowych punktów wewnątrz tego okręgu, niewielką koncentracją pomarańczowych punktów poza tym półkolem i pięcioma szarymi punktami, które są daleko od wszystkich innych.
Na działce 2 znajduje się okrągła masa fioletowych punktów, kolejna pomarańczowa, a także cztery szare punkty, które są daleko od wszystkich pozostałych.
A na wykresie 3 widzimy cztery koncentracje punktów: fioletowy, niebieski, pomarańczowy, różowy i trzy bardziej odległe szare punkty.
Teraz, jeśli miałbyś wybrać model, który mógłby zrozumieć nowe dane uczniów i określić podobne grupy, czy istnieje algorytm grupowania, który mógłby dać interesujące wyniki dla tego rodzaju danych?
Opisując działki, wspomnieliśmy o terminach takich jak masa punktów i koncentracja punktów, co wskazuje, że na wszystkich wykresach są obszary o większej gęstości. Odnieśliśmy się również do okrągły i półkolisty kształty, które trudno jest zidentyfikować rysując linię prostą lub po prostu badając najbliższe punkty. Ponadto istnieje kilka odległych punktów, które prawdopodobnie odbiegają od głównego rozkładu danych, wprowadzając więcej wyzwań lub hałas przy ustalaniu grup.
Algorytm oparty na gęstości, który może odfiltrować szum, taki jak DBSCAN (Dbezpieczeństwo-Based Suprzejmy Cpołysk Aaplikacje z Noise) to dobry wybór w sytuacjach z gęstszymi obszarami, zaokrąglonymi kształtami i hałasem.
O DBSCANIE
DBSCAN jest jednym z najczęściej cytowanych algorytmów w badaniach, jego pierwsza publikacja ukazała się w 1996 roku, jest to oryginalny papier DBSCAN. W artykule naukowcy demonstrują, w jaki sposób algorytm może identyfikować nieliniowe klastry przestrzenne i wydajnie przetwarzać dane o wyższych wymiarach.
Główną ideą DBSCAN jest to, że istnieje minimalna liczba punktów, które będą znajdować się w określonej odległości lub promień z najbardziej „centralnego” punktu skupienia, tzw punkt centralny. Punkty w obrębie tego promienia są punktami sąsiedztwa, a punkty na krawędzi tego sąsiedztwa są punktami punkty graniczne or punkty graniczne. Nazywa się promień lub odległość sąsiedztwa dzielnica epsilon, ε-sąsiedztwo lub po prostu ε (symbol greckiej litery epsilon).
Dodatkowo, gdy istnieją punkty, które nie są punktami rdzeniowymi ani punktami granicznymi, ponieważ przekraczają promień przynależności do określonego klastra, a także nie mają minimalnej liczby punktów, aby być punktem rdzeniowym, są one uważane punkty hałasu.
Oznacza to, że mamy trzy różne rodzaje punktów, a mianowicie: core, granica i hałas. Co więcej, należy zauważyć, że główna idea jest zasadniczo oparta na promieniu lub odległości, co sprawia, że DBSCAN – podobnie jak większość modeli klastrowania – jest zależny od tej metryki odległości. Ta metryka może być euklidesowa, Manhattan, Mahalanobis i wiele innych. Dlatego tak ważny jest wybór odpowiedniej metryki odległości uwzględniającej kontekst danych. Na przykład, jeśli używasz danych o przebytej odległości z GPS, interesujące może być użycie metryki uwzględniającej układ ulic, takiej jak odległość od Manhattanu.

Uwaga: Ponieważ DBSCAN odwzorowuje punkty tworzące szum, może być również używany jako algorytm wykrywania wartości odstających. Na przykład, jeśli próbujesz ustalić, które transakcje bankowe mogą być oszukańcze, a odsetek oszukańczych transakcji jest niewielki, DBSCAN może być rozwiązaniem do identyfikacji tych punktów.
Aby znaleźć punkt centralny, DBSCAN najpierw wybierze losowo punkt, zmapuje wszystkie punkty w jego sąsiedztwie ε i porówna liczbę sąsiadów wybranego punktu z minimalną liczbą punktów. Jeśli wybrany punkt ma taką samą lub więcej sąsiadów niż minimalna liczba punktów, zostanie oznaczony jako punkt główny. Ten punkt główny i punkty z nim sąsiadujące będą stanowić pierwsze skupienie.
Algorytm następnie zbada każdy punkt pierwszego klastra i sprawdzi, czy ma on taką samą lub więcej punktów sąsiadujących niż minimalna liczba punktów w obrębie ε. Jeśli tak, te sąsiednie punkty zostaną również dodane do pierwszego klastra. Proces ten będzie kontynuowany, dopóki punkty pierwszego klastra będą miały mniej sąsiadów niż minimalna liczba punktów w obrębie ε. Kiedy tak się dzieje, algorytm przestaje dodawać punkty do tego klastra, identyfikuje inny punkt główny poza tym klastrem i tworzy nowy klaster dla tego nowego punktu głównego.
DBSCAN powtórzy następnie proces pierwszego klastra, aby znaleźć wszystkie punkty połączone z nowym punktem rdzenia drugiego klastra, dopóki nie będzie już więcej punktów do dodania do tego klastra. Następnie napotka kolejny punkt główny i utworzy trzeci klaster lub wykona iterację przez wszystkie punkty, których wcześniej nie przeglądał. Jeśli punkty te znajdują się w odległości ε od klastra, są dodawane do tego klastra, stając się punktami granicznymi. Jeśli nie są, są uważane za punkty hałasu.
Rada: Istnieje wiele zasad i demonstracji matematycznych związanych z ideą stojącą za DBSCAN, jeśli chcesz kopać głębiej, możesz rzucić okiem na oryginalny artykuł, do którego link znajduje się powyżej.
Ciekawie jest wiedzieć, jak działa algorytm DBSCAN, chociaż na szczęście nie ma potrzeby kodowania algorytmu, skoro biblioteka Scikit-Learn Pythona ma już implementację.
Zobaczmy, jak to działa w praktyce!
Importowanie danych do tworzenia klastrów
Aby zobaczyć, jak DBSCAN działa w praktyce, zmienimy nieco projekty i użyjemy małego zestawu danych klientów, który ma gatunek, wiek, roczny dochód i wynik wydatków 200 klientów.
Wynik wydatków waha się od 0 do 100 i przedstawia, jak często dana osoba wydaje pieniądze w centrum handlowym w skali od 1 do 100. Innymi słowy, jeśli klient ma wynik 0, nigdy nie wydaje pieniędzy, a jeśli wynik jest 100, to oni wydają najwięcej.
Uwaga: Możesz pobrać zbiór danych tutaj.
Po pobraniu zestawu danych zobaczysz, że jest to plik CSV (wartości oddzielone przecinkami) o nazwie zakupy-dane.csv, załadujemy go do DataFrame przy użyciu Pandas i zapiszemy w customer_data zmienna:
import pandas as pd path_to_file = '../../datasets/dbscan/dbscan-with-python-and-scikit-learn-shopping-data.csv'
customer_data = pd.read_csv(path_to_file)
Aby rzucić okiem na pierwsze pięć wierszy naszych danych, możesz wykonać customer_data.head():
To skutkuje:
CustomerID Genre Age Annual Income (k$) Spending Score (1-100)
0 1 Male 19 15 39
1 2 Male 21 15 81
2 3 Female 20 16 6
3 4 Female 23 16 77
4 5 Female 31 17 40
Analizując dane, możemy zobaczyć numery identyfikacyjne klientów, gatunek, wiek, dochody w tysiącach dolarów i wyniki wydatków. Należy pamiętać, że niektóre lub wszystkie z tych zmiennych zostaną użyte w modelu. Na przykład, gdybyśmy mieli użyć Age i Spending Score (1-100) jako zmienne dla DBSCAN, który wykorzystuje metrykę odległości, ważne jest, aby sprowadzić je do wspólnej skali, aby uniknąć wprowadzania zniekształceń od Age mierzony jest w latach i Spending Score (1-100) ma ograniczony zakres od 0 do 100. Oznacza to, że przeprowadzimy pewnego rodzaju skalowanie danych.
Możemy również sprawdzić, czy dane wymagają dalszego przetwarzania wstępnego poza skalowaniem, sprawdzając, czy typ danych jest spójny i sprawdzając, czy są jakieś brakujące wartości, które należy potraktować, wykonując Panda info() metoda:
customer_data.info()
Wyświetla:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 200 entries, 0 to 199
Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 CustomerID 200 non-null int64 1 Genre 200 non-null object 2 Age 200 non-null int64 3 Annual Income (k$) 200 non-null int64 4 Spending Score (1-100) 200 non-null int64 dtypes: int64(4), object(1)
memory usage: 7.9+ KB
Możemy zaobserwować, że nie ma brakujących wartości, ponieważ istnieje 200 wpisów innych niż null dla każdej cechy klienta. Widzimy również, że tylko kolumna gatunku ma treść tekstową, ponieważ jest to zmienna kategorialna, która jest wyświetlana jako object, a wszystkie inne cechy są numeryczne typu int64. Zatem pod względem spójności typów danych i braku wartości pustych nasze dane są gotowe do dalszej analizy.
Możemy przystąpić do wizualizacji danych i określenia, które funkcje byłyby interesujące do wykorzystania w DBSCAN. Po wybraniu tych cech możemy je skalować.
Ten zestaw danych klientów jest taki sam, jak ten używany w naszym ostatecznym przewodniku po klastrowaniu hierarchicznym. Aby dowiedzieć się więcej o tych danych, sposobach ich eksploracji oraz o wskaźnikach odległości, możesz rzucić okiem na Ostateczny przewodnik po hierarchicznym klastrowaniu za pomocą Pythona i Scikit-Learn!
Wizualizacja danych
Używając Seaborn's pairplot(), możemy wykreślić wykres punktowy dla każdej kombinacji cech. Od CustomerID jest tylko identyfikacją, a nie cechą, usuniemy ją drop() przed kreśleniem:
import seaborn as sns customer_data = customer_data.drop('CustomerID', axis=1) sns.pairplot(customer_data);
To daje:

Patrząc na kombinację funkcji tworzonych przez pairplot, wykres Annual Income (k$) w Spending Score (1-100) wydaje się wyświetlać około 5 grup punktów. To wydaje się być najbardziej obiecującą kombinacją cech. Możemy utworzyć listę z ich nazwami, wybrać je z listy customer_data DataFrame i zapisz zaznaczenie w customer_data ponownie do wykorzystania w naszym przyszłym modelu.
selected_cols = ['Annual Income (k$)', 'Spending Score (1-100)']
customer_data = customer_data[selected_cols]
Po wybraniu kolumn możemy wykonać skalowanie omówione w poprzedniej sekcji. Aby doprowadzić funkcje do tej samej skali lub ujednolicić je, możemy zaimportować Scikit-Learn StandardScaler, utwórz go, dopasuj nasze dane, aby obliczyć jego średnią i odchylenie standardowe, a następnie przekształć dane, odejmując ich średnią i dzieląc przez odchylenie standardowe. Można to zrobić w jednym kroku za pomocą fit_transform() metoda:
from sklearn.preprocessing import StandardScaler ss = StandardScaler() scaled_data = ss.fit_transform(customer_data)
Zmienne są teraz skalowane i możemy je zbadać, po prostu drukując zawartość pliku scaled_data zmienny. Alternatywnie możemy również dodać je do nowego scaled_customer_data DataFrame wraz z nazwami kolumn i użyj head() metoda ponownie:
scaled_customer_data = pd.DataFrame(columns=selected_cols, data=scaled_data)
scaled_customer_data.head()
To daje:
Annual Income (k$) Spending Score (1-100)
0 -1.738999 -0.434801
1 -1.738999 1.195704
2 -1.700830 -1.715913
3 -1.700830 1.040418
4 -1.662660 -0.395980 Te dane są gotowe do grupowania! Wprowadzając DBSCAN wspomnieliśmy o minimalnej liczbie punktów i epsilonie. Te dwie wartości należy wybrać przed utworzeniem modelu. Zobaczmy, jak to się robi.
Wybór min. Próbki i Epsilon
Aby wybrać minimalną liczbę punktów dla klastrowania DBSCAN, istnieje praktyczna zasada, która mówi, że musi być ona równa lub większa niż liczba wymiarów w danych plus jeden, na przykład:
$$
tekst { min. points} >= tekst{wymiary danych} + 1
$$
Wymiary to liczba kolumn w ramce danych, używamy 2 kolumn, więc min. punkty powinny wynosić 2+1, czyli 3, lub więcej. W tym przykładzie użyjmy 5 minut. zwrotnica.
$$
tekst{5 (min. pkt.)} >= tekst{2 (wymiary danych)} + 1
$$
Zapoznaj się z naszym praktycznym, praktycznym przewodnikiem dotyczącym nauki Git, zawierającym najlepsze praktyki, standardy przyjęte w branży i dołączoną ściągawkę. Zatrzymaj polecenia Google Git, a właściwie uczyć się to!
Teraz, aby wybrać wartość dla ε, istnieje metoda, w której a Najbliżsi sąsiedzi Algorytm jest używany do znajdowania odległości określonej liczby najbliższych punktów dla każdego punktu. Ta predefiniowana liczba sąsiadów to min. punkty, które właśnie wybraliśmy minus 1. Tak więc w naszym przypadku algorytm znajdzie 5-1, czyli 4 najbliższe punkty dla każdego punktu naszych danych. to są k-sąsiedzi i nasz k równa się 4.
$$
tekst{k-sąsiadów} = tekst{min. punkty} – 1
$$
Po znalezieniu sąsiadów uszeregujemy ich odległości od największej do najmniejszej i wykreślimy odległości na osi y oraz punkty na osi x. Patrząc na wykres, dowiemy się, gdzie przypomina zgięcie łokcia, a punkt na osi y opisujący to zgięcie łokcia jest sugerowaną wartością ε.
Note: możliwe, że wykres do znajdowania wartości ε ma jedno lub więcej „wygięć łokciowych”, dużych lub małych, kiedy tak się dzieje, możesz znaleźć wartości, przetestować je i wybrać te, których wyniki najlepiej opisują skupienia, albo patrząc na metryki działek.
Aby wykonać te kroki, możemy zaimportować algorytm, dopasować go do danych, a następnie możemy wyodrębnić odległości i indeksy każdego punktu za pomocą kneighbors() metoda:
from sklearn.neighbors import NearestNeighbors
import numpy as np nn = NearestNeighbors(n_neighbors=4) nbrs = nn.fit(scaled_customer_data)
distances, indices = nbrs.kneighbors(scaled_customer_data)
Po znalezieniu odległości możemy je posortować od największej do najmniejszej. Ponieważ pierwsza kolumna tablicy odległości dotyczy punktu sama w sobie (co oznacza, że wszystkie są równe 0), druga kolumna zawiera najmniejsze odległości, a następnie trzecia kolumna, która ma większe odległości niż druga itd., możemy wybrać tylko wartości drugiej kolumny i przechowuj je w distances zmienna:
distances = np.sort(distances, axis=0)
distances = distances[:,1] Teraz, gdy mamy posortowane najmniejsze odległości, możemy zaimportować matplotlib, wyznacz odległości i narysuj czerwoną linię w miejscu „zgięcia łokcia”:
import matplotlib.pyplot as plt plt.figure(figsize=(6,3))
plt.plot(distances)
plt.axhline(y=0.24, color='r', linestyle='--', alpha=0.4) plt.title('Kneighbors distance graph')
plt.xlabel('Data points')
plt.ylabel('Epsilon value')
plt.show();
Oto wynik:

Zauważ, że podczas rysowania linii dowiemy się, jaka jest wartość ε, w tym przypadku tak jest 0.24.
W końcu mamy nasze minimalne punkty i ε. Dzięki obu zmiennym możemy stworzyć i uruchomić model DBSCAN.
Tworzenie modelu DBSCAN
Aby stworzyć model, możemy go zaimportować z Scikit-Learn, utworzyć za pomocą ε, które jest takie samo jak eps argument, a minimum punktów, do którego to jest mean_samples argument. Następnie możemy zapisać go w zmiennej, nazwijmy ją dbs i dopasuj go do przeskalowanych danych:
from sklearn.cluster import DBSCAN dbs = DBSCAN(eps=0.24, min_samples=5)
dbs.fit(scaled_customer_data)
Właśnie w ten sposób nasz model DBSCAN został stworzony i przeszkolony na danych! Aby wyodrębnić wyniki, uzyskujemy dostęp do pliku labels_ nieruchomość. Możemy również utworzyć nowy labels kolumna w scaled_customer_data ramkę danych i wypełnij ją przewidywanymi etykietami:
labels = dbs.labels_ scaled_customer_data['labels'] = labels
scaled_customer_data.head()
Oto wynik końcowy:
Annual Income (k$) Spending Score (1-100) labels
0 -1.738999 -0.434801 -1
1 -1.738999 1.195704 0
2 -1.700830 -1.715913 -1
3 -1.700830 1.040418 0
4 -1.662660 -0.395980 -1
Zauważ, że mamy etykiety z -1 wartości; to są punkty hałasu, które nie należą do żadnego klastra. Aby wiedzieć, ile punktów szumu znalazł algorytm, możemy policzyć, ile razy wartość -1 pojawia się na naszej liście etykiet:
labels_list = list(scaled_customer_data['labels'])
n_noise = labels_list.count(-1)
print("Number of noise points:", n_noise)
To daje:
Number of noise points: 62
Wiemy już, że 62 punkty z naszych oryginalnych danych z 200 punktów uznano za szum. To dużo szumu, co wskazuje, że być może grupowanie DBSCAN nie uwzględniało wielu punktów jako części klastra. Wkrótce zrozumiemy, co się stało, kiedy narysujemy dane.
Początkowo, kiedy obserwowaliśmy dane, wydawało się, że ma 5 skupisk punktów. Aby wiedzieć, ile klastrów utworzył DBSCAN, możemy policzyć liczbę etykiet, które nie są równe -1. Istnieje wiele sposobów napisania tego kodu; tutaj napisaliśmy pętlę for, która zadziała również dla danych, w których DBSCAN znalazł wiele klastrów:
total_labels = np.unique(labels) n_labels = 0
for n in total_labels: if n != -1: n_labels += 1
print("Number of clusters:", n_labels)
To daje:
Number of clusters: 6
Widzimy, że algorytm przewidział, że dane będą miały 6 klastrów z wieloma punktami szumu. Zwizualizujmy to, porównując to z seabornem scatterplot:
sns.scatterplot(data=scaled_customer_data, x='Annual Income (k$)', y='Spending Score (1-100)', hue='labels', palette='muted').set_title('DBSCAN found clusters');
To skutkuje:

Patrząc na wykres, widzimy, że DBSCAN przechwycił punkty, które były gęściej połączone, a punkty, które można uznać za część tego samego klastra, były albo szumem, albo uważano, że tworzą inny, mniejszy klaster.

Jeśli podświetlimy klastry, zwróć uwagę, jak DBSCAN całkowicie pobiera klaster 1, czyli klaster z mniejszą przestrzenią między punktami. Następnie pobiera części klastrów 0 i 3, w których punkty są blisko siebie, uznając więcej oddalonych punktów za szum. Rozważa również punkty w lewej dolnej połowie jako szum i dzieli punkty w prawym dolnym rogu na 3 klastry, ponownie przechwytując klastry 4, 2 i 5, gdzie punkty są bliżej siebie.
Możemy zacząć dochodzić do wniosku, że DBSCAN był świetny do przechwytywania gęstych obszarów klastrów, ale nie do identyfikacji większego schematu danych, rozgraniczeń 5 klastrów. Interesujące byłoby przetestowanie większej liczby algorytmów grupowania z naszymi danymi. Zobaczmy, czy metryka potwierdzi tę hipotezę.
Ocena algorytmu
Aby ocenić DBSCAN, użyjemy wynik sylwetki który będzie uwzględniał odległość między punktami tego samego klastra oraz odległości między klastrami.
Uwaga: Obecnie większość metryk klastrowania nie nadaje się do oceny DBSCAN, ponieważ nie są one oparte na gęstości. Tutaj używamy wyniku sylwetki, ponieważ jest on już zaimplementowany w Scikit-learn i ponieważ próbuje spojrzeć na kształt klastra.
Aby uzyskać bardziej dopasowaną ocenę, możesz użyć lub połączyć ją z Walidacja klastrowania oparta na gęstości (DBCV), który został zaprojektowany specjalnie do grupowania opartego na gęstości. Dostępna jest implementacja DBCV GitHub.
Po pierwsze, możemy importować silhouette_score z Scikit-Learn, a następnie podaj nasze kolumny i etykiety:
from sklearn.metrics import silhouette_score s_score = silhouette_score(scaled_customer_data, labels)
print(f"Silhouette coefficient: {s_score:.3f}")
To daje:
Silhouette coefficient: 0.506
Według tego wyniku wydaje się, że DBSCAN może przechwycić około 50% danych.
Wnioski
Zalety i wady DBSCAN
DBSCAN to bardzo unikalny algorytm lub model klastrowania.
Jeśli spojrzymy na jego zalety, bardzo dobrze radzi sobie z wykrywaniem gęstych obszarów danych i punktów, które są daleko od innych. Oznacza to, że dane nie muszą mieć określonego kształtu i mogą być otoczone innymi punktami, o ile są one również gęsto połączone.
Wymaga od nas określenia punktów minimalnych i ε, ale nie ma potrzeby wcześniejszego określania liczby klastrów, jak na przykład w K-średnich. Może być również używany z bardzo dużymi bazami danych, ponieważ został zaprojektowany dla danych wielowymiarowych.
Jeśli chodzi o jego wady, widzieliśmy, że nie był w stanie uchwycić różnych gęstości w tej samej gromadzie, więc ma trudności z dużymi różnicami w gęstościach. Jest to również zależne od metryki odległości i skalowania punktów. Oznacza to, że jeśli dane nie są dobrze zrozumiane, z różnicami w skali iz metryką odległości, która nie ma sensu, prawdopodobnie ich nie zrozumie.
Rozszerzenia DBSCAN
Istnieją inne algorytmy, np Hierarchiczny DBSCAN (HDBSCAN) i Punkty porządkowe do identyfikacji struktury klastrowej (OPTYKA), które są uważane za rozszerzenia DBSCAN.
Zarówno HDBSCAN, jak i OPTICS mogą zwykle działać lepiej, gdy w danych znajdują się klastry o różnej gęstości, a także są mniej wrażliwe na wybór lub początkowe min. punkty i parametry ε.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://stackabuse.com/dbscan-with-scikit-learn-in-python/
- :Jest
- $W GÓRĘ
- 1
- 10
- 100
- 11
- 1996
- 39
- 7
- 77
- 8
- 9
- a
- O nas
- powyżej
- dostęp
- w poprzek
- faktycznie
- w dodatku
- do tego
- Zalety
- Po
- Alarm
- algorytm
- Algorytmy
- Wszystkie kategorie
- już
- Chociaż
- analiza
- i
- roczny
- Inne
- właściwy
- w przybliżeniu
- SĄ
- obszary
- argument
- na około
- Szyk
- AS
- przydzielony
- At
- dostępny
- uniknąć
- Bank
- TRANSAKCJE BANKOWE
- na podstawie
- BE
- bo
- staje
- za
- poniżej
- BEST
- Ulepsz Swój
- pomiędzy
- Duży
- większe
- Bit
- Niebieski
- granica
- przynieść
- by
- obliczać
- wezwanie
- nazywa
- CAN
- zdobyć
- Przechwytywanie
- walizka
- centralny
- wyzwania
- zmiana
- ZOBACZ
- wybór
- Dodaj
- wybrany
- Okrągłe
- cytowane
- klasa
- Klasyfikuj
- dokładnie
- bliższy
- Grupa
- klastrowanie
- kod
- Kolumna
- kolumny
- połączenie
- połączyć
- jak
- wspólny
- sukcesy firma
- porównać
- całkowicie
- stężenie
- konkluzja
- prowadzi
- połączony
- Rozważać
- wynagrodzenie
- za
- wobec
- rozważa
- zgodny
- stanowić
- consulting
- zawiera
- zawartość
- kontekst
- kontynuować
- rdzeń
- potwierdzać
- mógłby
- kursy
- Stwórz
- stworzony
- tworzy
- Tworzenie
- istotny
- Obecnie
- klient
- Klientów
- dane
- punkty danych
- Bazy danych
- DBS
- głębiej
- ostateczny
- wykazać
- gęstość
- zależny
- opisać
- zaprojektowany
- Wykrywanie
- Ustalać
- ustalona
- określaniu
- odchylenie
- Różnice
- różne
- trudny
- KOPAĆ
- Wymiary
- omówione
- Wyświetlacz
- wyświetlacze
- dystans
- Odległy
- 分配
- pobieranie
- rysunek
- jazdy
- każdy
- krawędź
- skutecznie
- bądź
- spotkanie
- Równa się
- oceniać
- ewaluację
- Badanie
- przykład
- przekraczać
- wykonać
- wykonywania
- odkryj
- rozszerzenia
- wyciąg
- Czynniki
- FAIL
- daleko
- Cecha
- Korzyści
- Płeć żeńska
- filet
- wypełniać
- filtrować
- finał
- W końcu
- Finanse
- budżetowy
- Znajdź
- znalezieniu
- i terminów, a
- dopasować
- Skupiać
- następnie
- W razie zamówieenia projektu
- Nasz formularz
- utworzony
- na szczęście
- znaleziono
- FRAME
- nieuczciwy
- od
- zasadniczo
- dalej
- Ponadto
- przyszłość
- git
- Dać
- dobry
- GPS
- wykres
- wykresy
- szary
- wspaniały
- większy
- Grupy
- poprowadzi
- Pół
- uchwyt
- hands-on
- się
- dzieje
- Ciężko
- Have
- tutaj
- wyższy
- Najwyższa
- Atrakcja
- unosić
- W jaki sposób
- How To
- HTTPS
- ICON
- ID
- pomysł
- Identyfikacja
- identyfikuje
- zidentyfikować
- identyfikacja
- realizacja
- realizowane
- importować
- ważny
- in
- W innych
- włączony
- Dochód
- wskazuje
- Indeksy
- wpływ
- początkowy
- przykład
- ciekawy
- wprowadzenie
- Wprowadzenie
- zaangażowany
- IT
- JEGO
- samo
- Trzymać
- Uprzejmy
- Wiedzieć
- Etykiety
- duży
- większe
- największym
- UCZYĆ SIĘ
- nauka
- list
- LG
- Biblioteka
- lubić
- Prawdopodobnie
- Ograniczony
- Linia
- powiązany
- Lista
- mało
- załadować
- długo
- Popatrz
- wyglądał
- poszukuje
- Partia
- Główny
- robić
- WYKONUJE
- wiele
- mapa
- Mapy
- wyraźny
- Masa
- matematyczny
- matplotlib
- znaczenie
- znaczy
- Pamięć
- wzmiankowany
- jedynie
- metoda
- metryczny
- Metryka
- może
- nic
- minimum
- brakujący
- model
- modele
- pieniądze
- jeszcze
- większość
- mianowicie
- Nazwy
- Potrzebować
- wymagania
- sąsiedzi
- Nowości
- Hałas
- numer
- z naszej
- tępy
- przedmiot
- obserwować
- of
- on
- ONE
- optyka
- Orange
- zamówienie
- Zorganizowany
- oryginalny
- Inne
- Pozostałe
- zewnętrzne
- pandy
- Papier
- parametry
- część
- strony
- wykonać
- może
- osoba
- wybierać
- plato
- Analiza danych Platona
- PlatoDane
- plus
- punkt
- zwrotnica
- możliwy
- Praktyczny
- praktyka
- Przewiduje
- poprzedni
- poprzednio
- Wcześniejszy
- prawdopodobnie
- wygląda tak
- Wytworzony
- Profil
- projekt
- projektowanie
- obiecujący
- własność
- Publikacja
- zakup
- Python
- przypadkowy
- zasięg
- Kurs
- gotowy
- niedawno
- polecić
- Czerwony
- , o którym mowa
- usunąć
- powtarzać
- reprezentuje
- Wymaga
- Badania naukowe
- Badacze
- przypomina
- dalsze
- Efekt
- Pierścień
- okrągły
- Zasada
- reguły
- run
- s
- taki sam
- Skala
- skalowaniem
- schemat
- nauka-scikit
- poroże morskie
- druga
- Sekcja
- widzenie
- wydawało się
- wydaje
- wybrany
- wybierając
- wybór
- rozsądek
- wrażliwy
- Shadow
- Shape
- kształty
- powinien
- podobny
- po prostu
- ponieważ
- sytuacje
- mały
- mniejszy
- najmniejszy
- So
- rozwiązanie
- kilka
- Wkrótce
- Typ przestrzeni
- Przestrzenne
- specyficzny
- swoiście
- wydać
- Spędzanie
- Dzieli
- Nadużycie stosu
- standard
- standardy
- początek
- Zjednoczone
- Ewolucja krok po kroku
- Cel
- Stop
- Zatrzymuje
- sklep
- proste
- ulica
- silny
- Struktura
- student
- Studenci
- taki
- otoczony
- SVG
- symbol
- Brać
- trwa
- REGULAMIN
- test
- że
- Połączenia
- Wykres
- ich
- Im
- w związku z tym
- Te
- Trzeci
- trzy
- Przez
- czas
- czasy
- do
- razem
- Kwota produktów:
- przeszkolony
- transakcje
- Przekształcać
- przejście
- prawdziwy
- typy
- zrozumieć
- zrozumienie
- zrozumiany
- wyjątkowy
- us
- Stosowanie
- posługiwać się
- zazwyczaj
- wartość
- Wartości
- zmienne
- Ve
- weryfikacja
- wyobrażać sobie
- sposoby
- DOBRZE
- Co
- który
- KIM
- będzie
- w
- w ciągu
- słowa
- Praca
- pracujący
- działa
- by
- napisać
- napisany
- lat
- zefirnet