Każda firma potrzebuje umiejętności dokładnego przewidywania przyszłości, aby podejmować lepsze decyzje i dać firmie przewagę konkurencyjną. Dzięki danym historycznym firmy mogą zrozumieć trendy, przewidywać, co może się wydarzyć i kiedy, oraz uwzględniać te informacje w swoich planach na przyszłość, od zapotrzebowania na produkty po planowanie zapasów i personelu. Jeśli prognoza jest zbyt wysoka, firmy mogą nadmiernie inwestować w produkty i personel, co skutkuje marnotrawstwem inwestycji. Jeśli prognoza jest zbyt niska, firmy mogą niedoinwestować, co prowadzi do niedoboru surowców i zapasów, co prowadzi do złego doświadczenia klientów.
Prognozowanie szeregów czasowych to technika, która przewiduje przyszłe dane szeregów czasowych na podstawie danych historycznych. Prognozowanie szeregów czasowych jest przydatne w wielu dziedzinach, w tym w handlu detalicznym, finansach, logistyce i opiece zdrowotnej. Prognozowanie popytu wykorzystuje historyczne dane szeregów czasowych w celu dokonania przyszłych szacunków w odniesieniu do popytu klientów w określonym okresie i usprawnienia procesu podejmowania decyzji podażowo-popytowych w firmach. Przypadki użycia związane z prognozowaniem popytu obejmują przewidywanie sprzedaży biletów w branży transportowej, cen akcji, liczby wizyt w szpitalach, liczby przedstawicieli klientów do zatrudnienia w wielu lokalizacjach w następnym miesiącu, sprzedaży produktów w wielu regionach w następnym kwartale, wykorzystania serwera w chmurze dla następnego dnia w przypadku usługi przesyłania strumieniowego wideo, zużycie energii elektrycznej w wielu regionach w ciągu następnego tygodnia, liczba urządzeń IoT i czujników, takich jak zużycie energii i inne.
Dane szeregów czasowych są klasyfikowane jako jednoczynnikowy i wielowymiarowy. Na przykład całkowite zużycie energii elektrycznej w jednym gospodarstwie domowym jest jednowymiarowym szeregiem czasowym w pewnym okresie czasu. Gdy wiele jednowymiarowych szeregów czasowych jest ułożonych jeden na drugim, nazywa się to wielowymiarowym szeregiem czasowym. Na przykład łączne zużycie energii elektrycznej w 10 różnych (ale skorelowanych) gospodarstwach domowych w jednym sąsiedztwie tworzy zbiór danych o wielu zmiennych szeregach czasowych.
Tradycyjne podejścia do prognozowania szeregów czasowych obejmują: zintegrowana średnia ruchoma z automatyczną regresją (ARIMA) dla jednowymiarowych danych szeregów czasowych i autoregresja wektorowa (VAR) dla wielu zmiennych danych szeregów czasowych. Metody te często wymagają żmudnego wstępnego przetwarzania danych i generowania funkcji przed uczeniem modelu. Wyzwania te są rozwiązywane za pomocą metod głębokiego uczenia (DL) poprzez automatyzację etapu generowania funkcji przed szkoleniem modelu, na przykład uwzględnienie różnych normalizacji danych, opóźnień, różnych skal czasowych, niektórych danych kategorycznych, radzenie sobie z brakującymi wartościami i nie tylko, z lepszym przewidywaniem moc i szybkie szkolenie i wdrażanie z wykorzystaniem GPU.
W tym poście pokazujemy, jak wdrożyć rozwiązanie do prognozowania popytu za pomocą Amazon SageMaker JumpStart. Przeprowadzimy Cię przez kompleksowe rozwiązanie zadania prognozowania popytu przy użyciu trzech najnowocześniejszych algorytmów szeregów czasowych: Sieć LST, prorok, SageMaker DeepAR, które są dostępne w GluonTS i Amazon Sage Maker. Dane wejściowe to wielowymiarowy szereg czasowy, który obejmuje dane godzinowe pobór prądu 321 użytkowników w latach 2012-2014. Następnie każdy algorytm pobiera historyczne wielowymiarowe i skorelowane dane szeregów czasowych do trenowania i generowania dokładnych prognoz (wartości wielowymiarowych) w przedziale predykcji. Dla każdego z algorytmów szeregów czasowych mamy dwa wyjścia: wytrenowany model na godzinę dane o zużyciu energii elektrycznej oraz punkt końcowy SageMaker, który może przewidywać przyszłe (wiele zmiennych) wartości przy danym interwale przewidywania.
Alternatywnie, jeśli szukasz w pełni zarządzanej usługi do dostarczania bardzo dokładnych prognoz bez pisania kodu, zalecamy sprawdzenie Prognoza Amazon. Amazon Forecast to usługa prognozowania szeregów czasowych oparta na uczeniu maszynowym (ML) i stworzona do analizy metryk biznesowych. Opierając się na tej samej technologii, co Amazon.com, Amazon Forecast wykorzystuje uczenie maszynowe do łączenia danych szeregów czasowych z dodatkowymi zmiennymi w celu tworzenia prognoz.
Omówienie rozwiązania
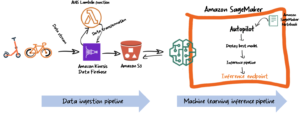
Poniższy diagram przedstawia architekturę kompleksowego procesu szkolenia i wdrażania.

Przepływ pracy rozwiązania wygląda następująco:
- Dane wejściowe do treningu znajdują się w Usługa Amazon Simple Storage Łyżka (Amazon S3).
- Dostarczone Notatnik SageMakera pobiera dane wejściowe i uruchamia następujące kroki.
- Dla każdego z Sieć LST, prorok, SageMaker DeepAR algorytmów, trenuj model i oceniaj jego wyniki za pomocą programu SageMaker.
- Wdróż wytrenowany model i utwórz punkt końcowy SageMaker, który jest Punkt końcowy HTTPS który jest zdolny do tworzenia prognoz.
- Monitoruj szkolenie i wdrażanie modelu za pomocą Amazon Cloud Watch.
- Dane wejściowe do wnioskowania znajdują się w wiadrze S3. Z notatnika SageMaker wyślij żądania do punktu końcowego SageMaker i dokonaj prognoz.
Wymagania wstępne
Aby wypróbować rozwiązanie na własnym koncie, upewnij się, że masz następujące elementy:
- Konto AWS umożliwiające korzystanie z tego rozwiązania. Jeśli nie masz konta, możesz zarejestruj się na jeden.
- Rozwiązanie opisane w tym poście jest częścią Amazon SageMaker JumpStart. Aby uruchomić rozwiązanie JumpStart 1P i wdrożyć infrastrukturę na koncie AWS, musisz utworzyć plik active Studio Amazon SageMaker instancja (patrz Na pokładzie do domeny Amazon SageMaker).
Gdy instancja Studio jest gotowa, możesz uruchomić Studio i uzyskać dostęp do JumpStart. Funkcje JumpStart nie są dostępne w instancjach notatników SageMaker i nie można uzyskać do nich dostępu za pośrednictwem interfejsów API SageMaker lub Interfejs wiersza poleceń AWS (interfejs wiersza poleceń AWS).
Uruchom rozwiązanie
Aby uruchomić rozwiązanie, wykonaj następujące czynności:
- Otwórz JumpStart za pomocą programu uruchamiającego JumpStart w Rozpocznij sekcji lub wybierając ikonę JumpStart na lewym pasku bocznym.
- W Rozwiązania Sekcja, wybierz Prognozowanie popytu aby otworzyć rozwiązanie w innej karcie Studio.

- Na karcie Prognozowanie popytu wybierz opcję Uruchom, aby wdrożyć zasoby rozwiązania.

- Otworzy się kolejna karta pokazująca stan wdrożenia i wygenerowane artefakty. Po zakończeniu wdrażania pojawi się przycisk Otwórz notatnik. Wybierać Otwórz notatnik aby otworzyć notes rozwiązania w programie Studio.

W kolejnych sekcjach przeprowadzimy Cię przez kroki rozwiązania do głębokiego prognozowania popytu.
Przygotowanie i wizualizacja danych
Zestaw danych, którego tutaj używamy, to wielowymiarowe szeregi czasowe zużycie energii elektrycznej dane zaczerpnięte z Dua, D. i Graff, C. (2019). Repozytorium uczenia maszynowego UCI, Irvine, Kalifornia: Uniwersytet Kalifornijski, Szkoła Informacji i Informatyki. Używamy oczyszczonej wersji danych zawierającej 321 szeregów czasowych z częstotliwością co godzinę, począwszy od 1 stycznia 1 r. z 2012 krokami czasowymi. Udostępniliśmy również kurs wymiany zestaw danych na wypadek, gdybyś chciał spróbować również z innymi zestawami danych.
Dostarczyliśmy narzędzia do tworzenia dataframe z danych pociągów i testów. Dane treningowe zawierają wartości godzinowego zużycia energii elektrycznej (dla 321 gospodarstw domowych) od 2012 od 01:01:00 do 00 00:2014:05, a dane testowe zawierają wartości od 26 19 00:00:2012 do 01-01-00 00:00:2014 (06 dni danych godzinowych więcej w porównaniu z danymi treningowymi). Aby wytrenować model prognozowania szeregów czasowych, CONTEXT_LENGTH definiuje długość każdego wejściowego szeregu czasowego, a PREDICTION_LENGTH określa długość każdego wyjściowego szeregu czasowego.
Ponieważ CONTEXT_LENGTH i PREDICTION_LENGTH są ustawione na 168 (7 dni) i 24 (następny 1 dzień), wykreślamy ostatnie 7 dni danych treningowych i kolejny 1 dzień danych testowych w celach demonstracyjnych. Wykreślone dane treningowe i dane testowe od 2014-05-19 20:00:00 do 2014-05-26 19:00:00 i od 2014-05-26 20:00:00 do 2014-05-27 02 00:00:11, odpowiednio. W celach demonstracyjnych wykreślamy tylko 321 szeregów czasowych z łącznej liczby XNUMX, jak pokazano na poniższym rysunku.

Trenuj modelki
W tej sekcji przedstawiono szkolenie i Sieć LST model za pomocą GluonTS, A prorok model za pomocą GluonTSI SageMaker DeepAR model z optymalizacją hiperparametrów (HPO) i bez niej. Dla każdego z nich najpierw trenowaliśmy model bez HPO, a następnie trenowaliśmy model z HPO. Pokazujemy, jak wydajność modelu wzrasta wraz z HPO, pokazując metryki porównania, a mianowicie RRSE (błąd względny kwadratu pierwiastka), MAPE (średni błąd procentowy bezwzględny) i sMAPE (błąd symetryczny średni bezwzględny błąd procentowy). W przypadku HPO używamy RRSE jako metryki oceny dla wszystkich trzech algorytmów.
Wytrenuj optymalny model LSTNet za pomocą GluonTS
LSTNet to model głębokiego uczenia, który obejmuje tradycyjne auto-regresywne modele liniowe równolegle do nieliniowej części sieci neuronowej, co sprawia, że nieliniowy model głębokiego uczenia się jest bardziej niezawodny w przypadku szeregów czasowych, które naruszają zmiany skali. Aby uzyskać informacje na temat matematyki stojącej za LSTNet, zobacz Modelowanie długo- i krótkoterminowych wzorców czasowych za pomocą głębokich sieci neuronowych.
Najpierw trenujemy model LSTNet bez HPO. Po zdefiniowaniu hiperparametrów możemy uruchomić zadanie szkoleniowe. Używamy GluonTS z MXNet jako backendową platformą uczenia głębokiego do definiowania i trenowania naszego modelu LSTNet. SageMaker sprawia, że robi to za pomocą estymatorów frameworków, które mają już skonfigurowane frameworki do uczenia głębokiego. Tutaj tworzymy estymator SageMaker MXNet i przekazujemy nasz modelowy skrypt treningowy, hiperparametry, a także żądaną liczbę i typ instancji szkoleniowych.
Następnie szkolimy optymalny model LSTNet z HPO i dalej poprawiamy wydajność modelu za pomocą Automatyczne dostrajanie modelu SageMaker. Automatyczne dostrajanie modelu SageMaker, znane również jako dostrajanie hiperparametrów, znajduje najlepszą wersję modelu, uruchamiając wiele zadań szkoleniowych w zestawie danych przy użyciu algorytmu i zakresów hiperparametrów określonych przez użytkownika. Następnie wybiera wartości hiperparametrów, które dają w wyniku model, który działa najlepiej, mierząc wybraną metryką. Najlepszy model i odpowiadające mu hiperparametry są wybierane na podstawie danych walidacyjnych od 2014 r. 05:26:20 do 00 r. 00:2014:06 (co odpowiada 01 dniom). Następnie wdrażamy najlepszy model w punkcie końcowym, do którego możemy wysłać zapytanie w celu prognozowania. Wreszcie, najlepszy model jest oceniany na podstawie danych testowych z okresu od 19 r. 00:00:6 do 2014 r. 06:01:20 (co odpowiada kolejnemu 00 dniu). W poniższej tabeli porównano wydajność modelu.
| Metryka | LSTNet bez HPO | LSTNet z HPO |
| RRSE | 0.555 | 0.506 |
| MAPE | 0.318 | 0.301 |
| SMAPE | 0.337 | 0.323 |
| Czas treningu (minuty) | 10.780 | 57.242 |
| Czas wnioskowania (sekundy) | 5.202 | 5.340 |
Z wyjątkiem czasu uczenia i wnioskowania, dla RRSE, MAPE i sMAPE mniejsze wartości wskazują na lepszą wydajność predykcyjną. W związku z tym możemy zaobserwować, że wydajność modelu wytrenowanego z HPO jest znacznie lepsza niż modelu wytrenowanego bez HPO.
Wytrenuj optymalny model Prophet za pomocą GluonTS z HPO
prorok to algorytm do prognozowania danych szeregów czasowych w oparciu o model addytywny, w którym trendy nieliniowe są dopasowane do sezonowości rocznej, tygodniowej i dziennej oraz efektów świątecznych. Działa najlepiej w przypadku szeregów czasowych, które mają silne efekty sezonowe i kilka sezonów danych historycznych. Prophet jest odporny na brakujące dane i zmiany trendu i zazwyczaj dobrze radzi sobie z wartościami odstającymi. Do implementacji algorytmu Prophet używamy GluonTS wersja, która jest cienkim opakowaniem do dzwonienia fbprorok pakiet. Najpierw szkolimy model Prophet bez HPO za pomocą programu SageMaker Estimator. Następnie szkolimy optymalny model Proroka z Automatyczne strojenie modeli SageMaker (HPO) i dalszą poprawę wydajności modelu.
| Metryka | Prorok bez HPO | Prorok z HPO |
| RRSE | 0.183 | 0.147 |
| MAPE | 0.288 | 0.278 |
| SMAPE | 0.278 | 0.289 |
| Czas treningu (minuty) | - | 45.633 |
| Czas wnioskowania (sekundy) | 44.813 | 45.327 |
Wartości metryki z dostrajaniem HPO są mniejsze niż te bez dostrajania HPO na tych samych danych testowych. Wskazuje to, że strojenie HPO dodatkowo poprawia wydajność modelu.
Wytrenuj optymalny model SageMaker DeepAR z HPO
Algorytm prognozowania SageMaker DeepAR to nadzorowany algorytm uczenia się do prognozowania skalarnych (jednowymiarowych) szeregów czasowych przy użyciu rekurencyjnych sieci neuronowych (RNN). Klasyczne metody prognozowania, takie jak autoregresyjna zintegrowana średnia krocząca (ARIMA) lub wygładzanie wykładnicze (ETS), dopasowują pojedynczy model do poszczególnych szeregów czasowych. Następnie używają tego modelu do ekstrapolacji szeregów czasowych w przyszłość.
Jednak w wielu aplikacjach istnieje wiele podobnych szeregów czasowych w zestawie jednostek przekrojowych. Na przykład możesz mieć grupowania szeregów czasowych dla popytu na różne produkty, obciążenia serwera i żądania stron internetowych. W przypadku tego typu aplikacji można skorzystać z trenowania jednego modelu łącznie we wszystkich szeregach czasowych. DeepAR stosuje takie podejście. Gdy Twój zbiór danych zawiera setki powiązanych szeregów czasowych, DeepAR przewyższa standardowe metody ARIMA i ETS. Wyszkolonego modelu można również użyć do wygenerowania prognoz dla nowych szeregów czasowych, które są podobne do tych, na których został wyszkolony. Aby uzyskać informacje na temat matematyki stojącej za DeepAR, zobacz DeepAR: Prognozy probabilistyczne z autoregresyjnymi sieciami rekurencyjnymi.
Podobnie jak w przypadku ustawień w poprzednich modelach, najpierw trenujemy model DeepAR bez HPO. Następnie trenujemy optymalny model DeepAR z HPO. Następnie wdrażamy najlepszy model w punkcie końcowym, do którego możemy wysłać zapytanie w celu prognozowania. W poniższej tabeli porównano wydajność modelu.
| Metryka | DeepAR bez HPO | DeepAR z HPO |
| RRSE | 0.136 | 0.098 |
| MAPE | 0.087 | 0.099 |
| SMAPE | 0.104 | 0.116 |
| Czas treningu (minuty) | 24.048 | 210.530 |
| Czas wnioskowania (sekundy) | 68.411 | 72.829 |
Wartości metryk z dostrajaniem HPO są mniejsze niż te bez dostrajania HPO na tych samych danych testowych. Wskazuje to, że strojenie HPO dodatkowo poprawia wydajność modelu.
Oceń wydajność modelu wszystkich trzech algorytmów na tych samych danych testowych wstrzymania
W tej sekcji porównujemy wydajność modelu z trzech modeli wytrenowanych z HPO. Na podstawie danych wejściowych porównania mogą się różnić dla różnych zestawów danych wejściowych. Poniższa tabela porównuje trzy algorytmy dla przykładowych danych wejściowych dotyczących energii elektrycznej użytych w tym poście.
| Metryka | LSTNet z HPO | Prorok z HPO | DeepAR z HPO |
| RRSE | 0.506 | 0.147 | 0.098 |
| MAPE | 0.302 | 0.278 | 0.099 |
| SMAPE | 0.323 | 0.289 | 0.116 |
| Czas treningu (minuty) | 57.242 | 45.633 | 210.530 |
| Czas wnioskowania (sekundy) | 5.340 | 45.327 | 72.829 |
Poniższe rysunki przedstawiają te wyniki.

Poniższy rysunek to kolejny sposób wizualizacji wyników.
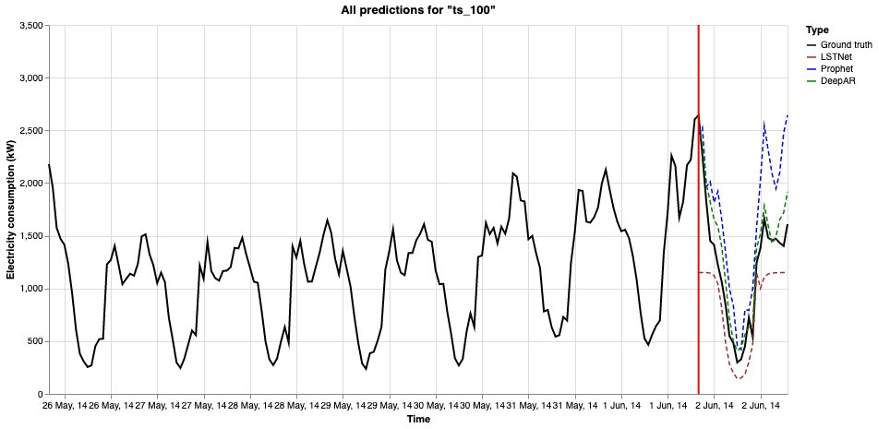
Dane treningowe i testowe (prawda podstawowa) są pokazane jako czarna ciągła linia (oddzielona czerwoną pionową linią) na wykresie. Prognozy z różnych algorytmów prognozowania są wyświetlane jako linie przerywane. Im bliżej kreska zbliża się do czarnej linii ciągłej, tym dokładniejsze są przewidywania.
Sprzątać
Po zakończeniu korzystania z tego rozwiązania upewnij się, że usuniesz wszystkie niechciane zasoby AWS, aby uniknąć niezamierzonych opłat. Notatnik rozwiązania zawiera kod czyszczenia. Na karcie rozwiązania możesz również wybrać Usuń wszystkie zasoby Usuń rozwiązanie

Wnioski
W tym poście przedstawiliśmy kompleksowe rozwiązanie do zadania prognozowania popytu przy użyciu trzech najnowocześniejszych algorytmów szeregów czasowych: LSTNet, Prophet i SageMaker DeepAR, które są dostępne w GluonTS i SageMaker. Omówiliśmy trzy podejścia do treningu: trenowanie optymalnego modelu LSTNet przy użyciu GluonTS, trenowanie optymalnego modelu Prophet przy użyciu GluonTS oraz trenowanie optymalnego modelu SageMaker DeepAR przy użyciu HPO. Dla każdego z nich najpierw trenowaliśmy model bez HPO, a następnie trenowaliśmy model z HPO. Pokazaliśmy, jak wydajność modelu wzrasta wraz z HPO, porównując metryki, a mianowicie RRSE, MAPE i sMAPE.
W tym poście użyliśmy danych dotyczących energii elektrycznej jako naszego zestawu danych wejściowych. Możesz jednak zmienić dane wejściowe i przenieść własne dane do zasobnika S3. Możesz użyć tych danych do trenowania modeli i uzyskania różnych wyników wydajności oraz odpowiedniego wyboru najlepszego algorytmu.
W konsoli SageMaker otwórz Studio i uruchom rozwiązanie w JumpStart, aby rozpocząć, lub możesz sprawdzić rozwiązanie Repozytorium GitHub aby przejrzeć kod i więcej informacji.
O autorach
 Alaka Eswaradassa jest starszym architektem rozwiązań w AWS z siedzibą w Chicago, Illinois. Jej pasją jest pomaganie klientom w projektowaniu architektur chmurowych wykorzystujących usługi AWS do rozwiązywania problemów biznesowych. Posiada tytuł magistra inżyniera informatyki. Przed dołączeniem do AWS pracowała dla różnych organizacji opieki zdrowotnej i ma dogłębne doświadczenie w projektowaniu złożonych systemów, innowacji technologicznych i badań. W wolnym czasie spędza czas z córkami i eksploruje tereny.
Alaka Eswaradassa jest starszym architektem rozwiązań w AWS z siedzibą w Chicago, Illinois. Jej pasją jest pomaganie klientom w projektowaniu architektur chmurowych wykorzystujących usługi AWS do rozwiązywania problemów biznesowych. Posiada tytuł magistra inżyniera informatyki. Przed dołączeniem do AWS pracowała dla różnych organizacji opieki zdrowotnej i ma dogłębne doświadczenie w projektowaniu złożonych systemów, innowacji technologicznych i badań. W wolnym czasie spędza czas z córkami i eksploruje tereny.
 Dr Xin Huang jest naukowcem w zakresie wbudowanych algorytmów Amazon SageMaker JumpStart i Amazon SageMaker. Koncentruje się na tworzeniu skalowalnych algorytmów uczenia maszynowego. Jego zainteresowania badawcze dotyczą przetwarzania języka naturalnego, wyjaśnialnego głębokiego uczenia się na danych tabelarycznych oraz solidnej analizy nieparametrycznego klastrowania czasoprzestrzennego.
Dr Xin Huang jest naukowcem w zakresie wbudowanych algorytmów Amazon SageMaker JumpStart i Amazon SageMaker. Koncentruje się na tworzeniu skalowalnych algorytmów uczenia maszynowego. Jego zainteresowania badawcze dotyczą przetwarzania języka naturalnego, wyjaśnialnego głębokiego uczenia się na danych tabelarycznych oraz solidnej analizy nieparametrycznego klastrowania czasoprzestrzennego.
- Coinsmart. Najlepsza w Europie giełda bitcoinów i kryptowalut.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. DARMOWY DOSTĘP.
- CryptoJastrząb. Radar Altcoin. Bezpłatna wersja próbna.
- Źródło: https://aws.amazon.com/blogs/machine-learning/deep-demand-forecasting-with-amazon-sagemaker/
- "
- 10
- 100
- 11
- 2019
- 7
- a
- zdolność
- O nas
- bezwzględny
- dostęp
- odpowiednio
- Konto
- dokładny
- w poprzek
- aktywny
- Dodatkowy
- Korzyść
- algorytm
- Algorytmy
- Wszystkie kategorie
- już
- Amazonka
- analiza
- Inne
- Pszczoła
- Zastosowanie
- aplikacje
- stosowany
- podejście
- awanse
- architektura
- POWIERZCHNIA
- automatycznie
- automatyzacja
- dostępny
- średni
- AWS
- zanim
- za
- korzyści
- BEST
- Ulepsz Swój
- Czarny
- granica
- przynieść
- budować
- wbudowany
- biznes
- biznes
- California
- zdolny
- walizka
- Etui
- wyzwania
- zmiana
- Opłaty
- kontrola
- Chicago
- Dodaj
- bliższy
- Chmura
- kod
- Firmy
- sukcesy firma
- w porównaniu
- konkurencyjny
- kompletny
- kompleks
- komputer
- Computer Science
- Konsola
- konsumpcja
- zawiera
- Odpowiedni
- mógłby
- Stwórz
- Tworzenie
- klient
- doświadczenie klienta
- Klientów
- codziennie
- myślnik
- dane
- dzień
- Dni
- czynienia
- Decyzje
- głęboko
- Kreowanie
- wykazać
- wykazać
- rozwijać
- Wdrożenie
- Wnętrze
- rozwijanie
- urządzenia
- różne
- każdy
- ruchomości
- elektryczność
- koniec końców
- Punkt końcowy
- energia
- Inżynieria
- oceniać
- ewaluację
- przykład
- doświadczenie
- FAST
- Cecha
- Korzyści
- Łąka
- Postać
- W końcu
- finansować
- znajduje
- i terminów, a
- dopasować
- koncentruje
- następujący
- następujący sposób
- Framework
- Ramy
- Darmowy
- od
- dalej
- przyszłość
- Generować
- wygenerowane
- generacja
- GitHub
- zdarzyć
- opieki zdrowotnej
- wysokość
- pomoc
- tutaj
- Wysoki
- wysoko
- zatrudnić
- historyczny
- gospodarstwo domowe
- gospodarstw domowych
- W jaki sposób
- How To
- Jednak
- HTTPS
- Setki
- ICON
- Illinois
- realizacja
- podnieść
- zawierać
- obejmuje
- Włącznie z
- wskazać
- indywidualny
- przemysł
- Informacja
- Infrastruktura
- Innowacja
- wkład
- przykład
- zintegrowany
- zainteresowania
- inwentarz
- inwestycja
- Internet przedmiotów
- urządzenia iot
- IT
- styczeń
- Praca
- Oferty pracy
- łączący
- znany
- język
- uruchomić
- uruchamia
- Wyprowadzenia
- nauka
- Linia
- linie
- lokalizacji
- logistyka
- poszukuje
- maszyna
- uczenie maszynowe
- robić
- WYKONUJE
- zarządzane
- mistrzowski
- materiały
- matematyka
- metody
- Metryka
- może
- ML
- model
- modele
- Miesiąc
- jeszcze
- przeniesienie
- wielokrotność
- mianowicie
- Naturalny
- wymagania
- sieć
- sieci
- Następny
- notatnik
- numer
- koncepcja
- otwiera
- optymalizacja
- zamówienie
- organizacji
- Inne
- na zewnątrz
- własny
- pakiet
- część
- namiętny
- procent
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- okres
- planowanie
- plany
- biedny
- power
- przewidzieć
- przepowiednia
- Przewidywania
- poprzedni
- wygląda tak
- przetwarzanie
- produkować
- Produkt
- Produkty
- pod warunkiem,
- zapewnia
- cele
- Kwartał
- Surowy
- polecić
- wywołań
- wymagać
- Badania naukowe
- Zasoby
- Efekt
- detaliczny
- przeglądu
- korzeń
- run
- bieganie
- sole
- taki sam
- skalowalny
- Skala
- Szkoła
- nauka
- Naukowiec
- sekund
- wybrany
- Serie
- usługa
- Usługi
- zestaw
- kilka
- krótkoterminowy
- niedobór
- pokazać
- pokazane
- podobny
- Prosty
- pojedynczy
- solidny
- rozwiązanie
- Rozwiązania
- ROZWIĄZANIA
- kilka
- specyficzny
- standard
- rozpoczęty
- state-of-the-art
- Rynek
- stany magazynowe
- przechowywanie
- Streaming
- Usługa transmisji strumieniowej
- opływowy
- silny
- studio
- systemy
- Technologia
- test
- Testowanie
- Połączenia
- w związku z tym
- trzy
- Przez
- bilet
- czas
- tradycyjny
- Pociąg
- Trening
- transport
- Trendy
- zazwyczaj
- zrozumieć
- jednostek
- uniwersytet
- University of California
- posługiwać się
- Użytkownicy
- Użytkowe
- Wykorzystując
- uprawomocnienie
- różnorodny
- wersja
- Wideo
- tydzień
- tygodniowy
- Co
- Wikipedia
- bez
- pracował
- działa
- pisanie
- Twój