Z Amazon EMR 6.15 wystartowaliśmy Formacja AWS Lake oparte na drobnoziarnistej kontroli dostępu (FGAC) w formatach Open Table (OTF), w tym Apache Hudi, Apache Iceberg i Delta Lake. Pozwala to uprościć bezpieczeństwo i zarządzanie jeziora danych transakcyjnych zapewniając kontrolę dostępu na poziomie tabeli, kolumny i wiersza w zadaniach Apache Spark. Wiele dużych przedsiębiorstw stara się wykorzystywać swoje transakcyjne jezioro danych do uzyskiwania wglądu i usprawniania procesu decyzyjnego. Możesz zbudować architekturę domu nad jeziorem, korzystając z Amazon EMR zintegrowanego z Lake Formation dla FGAC. To połączenie usług umożliwia przeprowadzanie analizy danych w jeziorze danych transakcyjnych, zapewniając jednocześnie bezpieczny i kontrolowany dostęp.
Komponent serwera rekordów Amazon EMR obsługuje funkcje filtrowania danych na poziomie tabeli, kolumny, wiersza, komórki i atrybutu zagnieżdżonego. Rozszerza obsługę formatów Hive, Apache Hudi, Apache Iceberg i Delta Lake zarówno w przypadku operacji odczytu (w tym podróży w czasie i zapytań przyrostowych), jak i operacji zapisu (na instrukcjach DML, takich jak INSERT). Dodatkowo w wersji 6.15 Amazon EMR wprowadza ochronę kontroli dostępu dla swojego interfejsu sieciowego aplikacji, takiego jak klastrowy serwer historii Spark, serwer osi czasu Yarn i interfejs użytkownika Yarn Resource Manager.
W tym poście pokazujemy, jak wdrożyć FGAC na Apache Hudi tabele wykorzystujące Amazon EMR zintegrowane z Lake Formation.
Przypadek użycia jeziora danych transakcyjnych
Klienci Amazon EMR często korzystają z formatów Open Table do obsługi transakcji ACID i podróży w czasie w jeziorze danych. Zachowując wersje historyczne, podróże w czasie w jeziorze danych zapewniają korzyści, takie jak audyt i zgodność, odzyskiwanie i przywracanie danych, powtarzalna analiza i eksploracja danych w różnych momentach.
Innym popularnym przypadkiem użycia jeziora danych transakcyjnych jest zapytanie przyrostowe. Zapytanie przyrostowe odnosi się do strategii zapytań, która koncentruje się na przetwarzaniu i analizowaniu tylko nowych lub zaktualizowanych danych w jeziorze danych od czasu ostatniego zapytania. Kluczową ideą zapytań przyrostowych jest wykorzystanie metadanych lub mechanizmów śledzenia zmian w celu zidentyfikowania nowych lub zmodyfikowanych danych od czasu ostatniego zapytania. Identyfikując te zmiany, silnik zapytań może zoptymalizować zapytanie tak, aby przetwarzało tylko istotne dane, znacznie redukując czas przetwarzania i wymagania dotyczące zasobów.
Omówienie rozwiązania
W tym poście pokazujemy, jak zaimplementować FGAC na tabelach Apache Hudi przy użyciu Amazon EMR Elastyczna chmura obliczeniowa Amazon (Amazon EC2) zintegrowany z Lake Formation. Apache Hudi to platforma transakcyjnego jeziora danych o otwartym kodzie źródłowym, która znacznie upraszcza przyrostowe przetwarzanie danych i tworzenie potoków danych. Ta nowa funkcja FGAC obsługuje wszystkie OTF. Oprócz demonstracji z Hudim, będziemy śledzić inne tabele OTF na innych blogach. Używamy laptopy in Studio Amazon SageMaker do odczytu i zapisu danych Hudi za pośrednictwem różnych uprawnień dostępu użytkowników za pośrednictwem klastra EMR. Odzwierciedla to rzeczywiste scenariusze dostępu do danych — na przykład, jeśli użytkownik inżynieryjny potrzebuje pełnego dostępu do danych, aby rozwiązać problemy na platformie danych, podczas gdy analitycy danych mogą potrzebować dostępu jedynie do podzbioru tych danych, który nie zawiera informacji umożliwiających identyfikację (PII ). Integracja z Formacją Jeziora poprzez Rola środowiska wykonawczego Amazon EMR dodatkowo umożliwia poprawę stanu bezpieczeństwa danych i upraszcza zarządzanie kontrolą danych w przypadku obciążeń Amazon EMR. Rozwiązanie to zapewnia bezpieczne i kontrolowane środowisko dostępu do danych, spełniając różnorodne potrzeby i wymagania bezpieczeństwa różnych użytkowników i ról w organizacji.
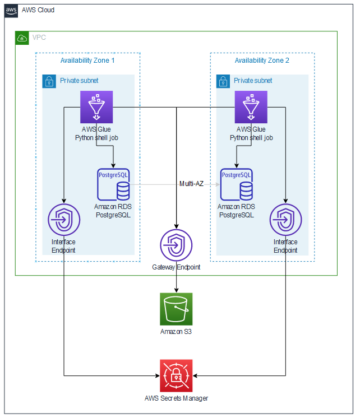
Poniższy schemat ilustruje architekturę rozwiązania.
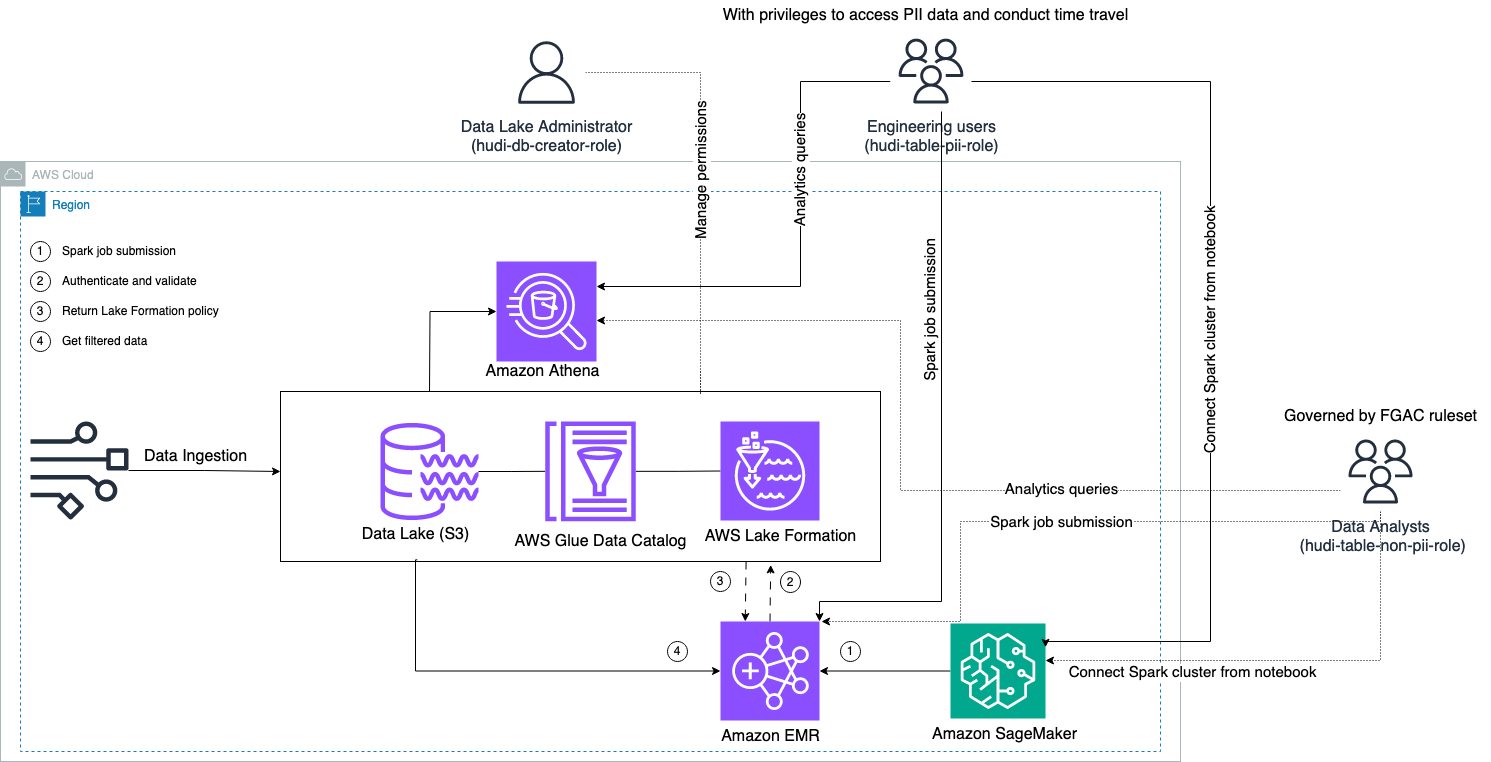
Przeprowadzamy proces pozyskiwania danych, aby zaktualizować (zaktualizować i wstawić) zbiór danych Hudi do pliku Usługa Amazon Simple Storage (Amazon S3) i utrwalić lub zaktualizować schemat tabeli w pliku Klej AWS Katalog danych. Przy zerowym ruchu danych możemy wysyłać zapytania do tabeli Hudi zarządzanej przez Lake Formation za pośrednictwem różnych usług AWS, takich jak Amazonka Atena, Amazon EMR i Amazon Sage Maker.
Gdy użytkownicy przesyłają zadanie Spark za pośrednictwem dowolnego punktu końcowego klastra EMR (EMR Steps, Livy, EMR Studio i SageMaker), Lake Formation sprawdza ich uprawnienia i instruuje klaster EMR, aby odfiltrował poufne dane, takie jak dane umożliwiające identyfikację osób.
To rozwiązanie ma trzy różne typy użytkowników z różnymi poziomami uprawnień dostępu do danych Hudi:
- rola twórcy-hudi-db – Jest używany przez administratora Data Lake, który ma uprawnienia do wykonywania operacji DDL, takich jak tworzenie, modyfikowanie i usuwanie obiektów bazy danych. Mogą definiować reguły filtrowania danych w Lake Formation w celu kontroli dostępu do danych na poziomie wierszy i kolumn. Te zasady FGAC zapewniają, że jezioro danych jest zabezpieczone i spełnia wymagane przepisy dotyczące prywatności danych.
- hudi-table-pii-role – Jest używany przez użytkowników inżynieryjnych. Użytkownicy inżynierii są w stanie przeprowadzać podróże w czasie i zapytania przyrostowe zarówno w trybie kopiowania przy zapisie (CoW), jak i łączenia przy czytaniu (MoR). Mają także uprawnienia dostępu do danych umożliwiających identyfikację osób na podstawie dowolnych znaczników czasu.
- hudi-table-non-pii-role – Używają tego analitycy danych. Prawa dostępu analityków danych podlegają autoryzowanym regułom FGAC kontrolowanym przez administratorów Data Lake. Nie są widoczne w kolumnach zawierających dane umożliwiające identyfikację, takie jak nazwiska i adresy. Ponadto nie mają dostępu do wierszy danych, które nie spełniają określonych warunków. Na przykład użytkownicy mają dostęp tylko do wierszy danych należących do ich kraju.
Wymagania wstępne
Możesz pobrać trzy notesy użyte w tym poście z GitHub repo.
Przed wdrożeniem rozwiązania upewnij się, że masz następujące elementy:
Wykonaj następujące kroki, aby skonfigurować uprawnienia:
- Zaloguj się na swoje konto AWS przy użyciu konta administratora IAM.
Upewnij się, że jesteś wus-east-1Region.
- Utwórz wiadro S3 w pliku
us-east-1Region (np.emr-fgac-hudi-us-east-1-<ACCOUNT ID>).
Następnie włączamy formowanie jeziora przez zmiana domyślnego modelu uprawnień.
- Zaloguj się do konsoli Lake Formation jako użytkownik administrator.
- Dodaj Ustawienia katalogu danych dla Administracja w okienku nawigacji.
- Pod Domyślne uprawnienia dla nowo utworzonych baz danych i tabel, odznacz Używaj tylko kontroli dostępu IAM dla nowych baz danych i Używaj tylko kontroli dostępu IAM dla nowych tabel w nowych bazach danych.
- Dodaj Zapisz.
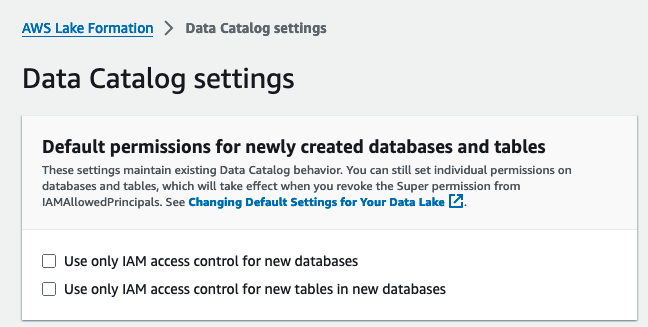
Alternatywnie musisz odwołać IAMAllowedPrincipals dla zasobów (baz danych i tabel) utworzonych, jeśli uruchomiłeś Lake Formation z opcją domyślną.
Na koniec tworzymy parę kluczy dla Amazon EMR.
- Na konsoli Amazon EC2 wybierz Pary kluczy w okienku nawigacji.
- Dodaj Utwórz parę kluczy.
- W razie zamówieenia projektu Imię, wpisz nazwę (np
emr-fgac-hudi-keypair). - Dodaj Utwórz parę kluczy.
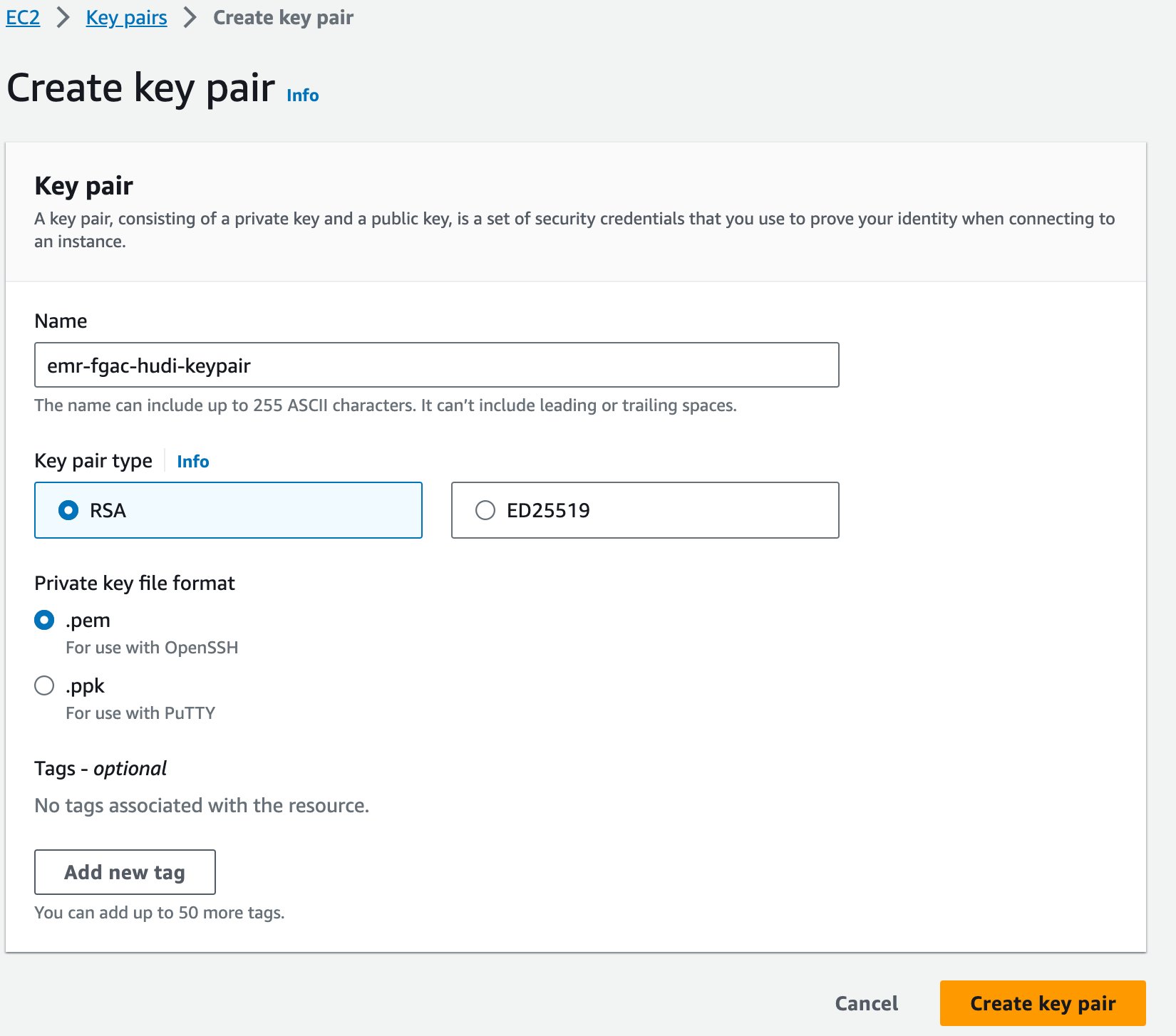
Wygenerowana para kluczy (w tym poście emr-fgac-hudi-keypair.pem) zostanie zapisany na komputerze lokalnym.
Następnie tworzymy Chmura AWS9 interaktywne środowisko programistyczne (IDE).
- Na konsoli AWS Cloud9 wybierz Środowiska w okienku nawigacji.
- Dodaj Stwórz środowisko.
- W razie zamówieenia projektu Imię¸ wprowadź nazwę (np.
emr-fgac-hudi-env). - Zachowaj pozostałe ustawienia jako domyślne.
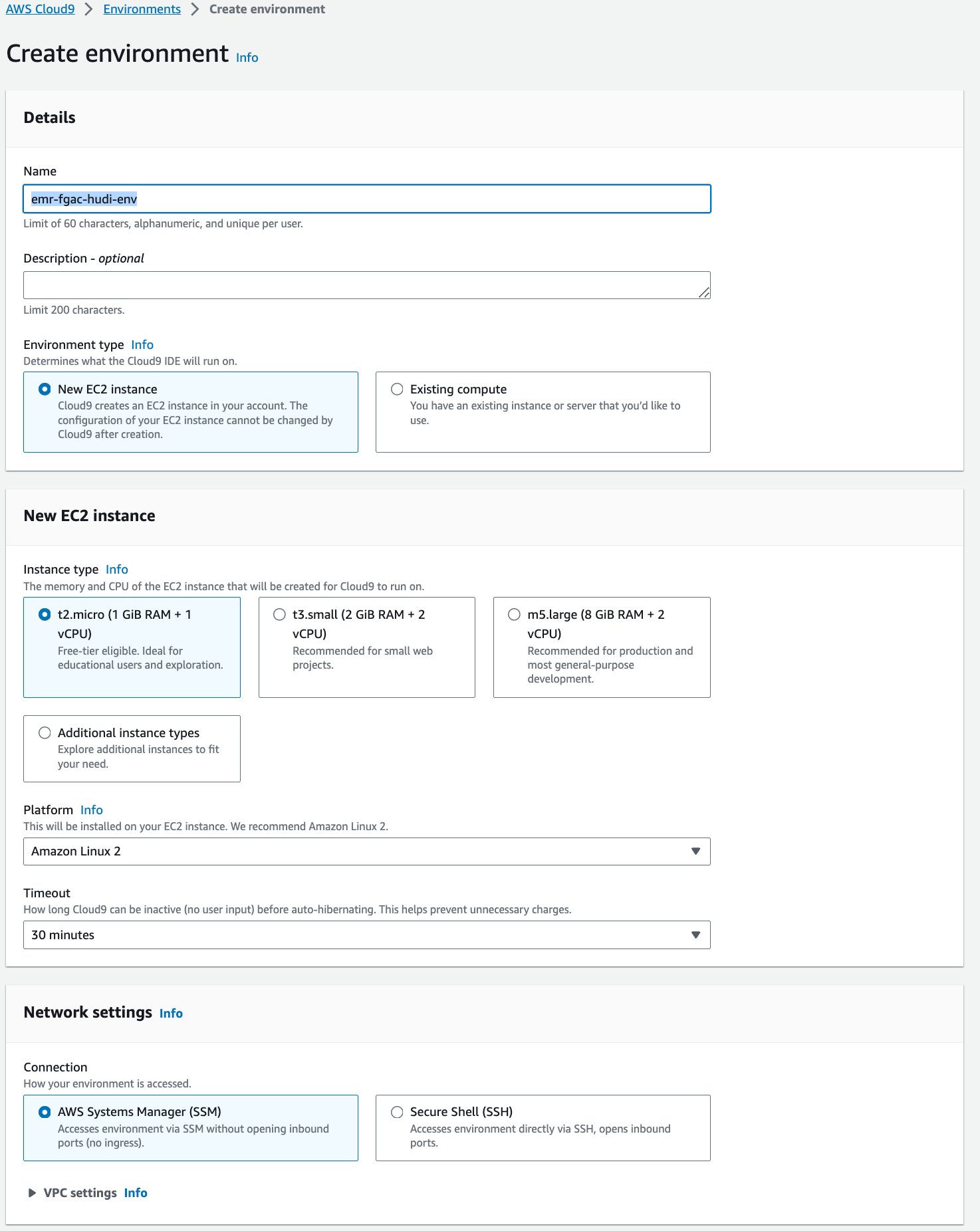
- Dodaj Stwórz.
- Gdy IDE będzie gotowe, wybierz Otwarte aby go otworzyć.
- W środowisku IDE AWS Cloud9 na platformie filet menu, wybierz Prześlij pliki lokalne.

- Prześlij plik pary kluczy (
emr-fgac-hudi-keypair.pem). - Wybierz znak plus i wybierz Nowy terminal.
- W terminalu wprowadź następujące wiersze poleceń:
Należy pamiętać, że przykładowy kod stanowi dowód koncepcji wyłącznie w celach demonstracyjnych. W przypadku systemów produkcyjnych użyj zaufanego urzędu certyfikacji (CA), aby wystawiać certyfikaty. Odnosić się do Dostarczanie certyfikatów do szyfrowania danych w transporcie za pomocą szyfrowania Amazon EMR dla szczegółów.
Wdróż rozwiązanie poprzez AWS CloudFormation
Zapewniamy Tworzenie chmury AWS szablon, który automatycznie konfiguruje następujące usługi i komponenty:
- Wiadro S3 dla jeziora danych. Zawiera przykładowy zbiór danych TPC-DS.
- Klaster EMR z konfiguracją zabezpieczeń i włączonym publicznym DNS.
- Role IAM środowiska uruchomieniowego EMR z szczegółowymi uprawnieniami do formacji jeziora:
- -hudi-db-creator-role – Ta rola służy do tworzenia bazy danych i tabel Apache Hudi.
- -hudi-table-pii-role – Ta rola zapewnia uprawnienia do wykonywania zapytań we wszystkich kolumnach tabel Hudi, w tym w kolumnach zawierających informacje umożliwiające identyfikację.
- -hudi-table-non-pii-role – Ta rola zapewnia uprawnienia do wysyłania zapytań do tabel Hudi, które odfiltrowały kolumny umożliwiające identyfikację osób według formacji Lake.
- Role wykonawcze SageMaker Studio, które pozwalają użytkownikom przyjąć odpowiadające im role środowiska wykonawczego EMR.
- Zasoby sieciowe, takie jak VPC, podsieci i grupy zabezpieczeń.
Wykonaj następujące kroki, aby wdrożyć zasoby:
- Dodaj Szybkie tworzenie stosu aby uruchomić stos CloudFormation.
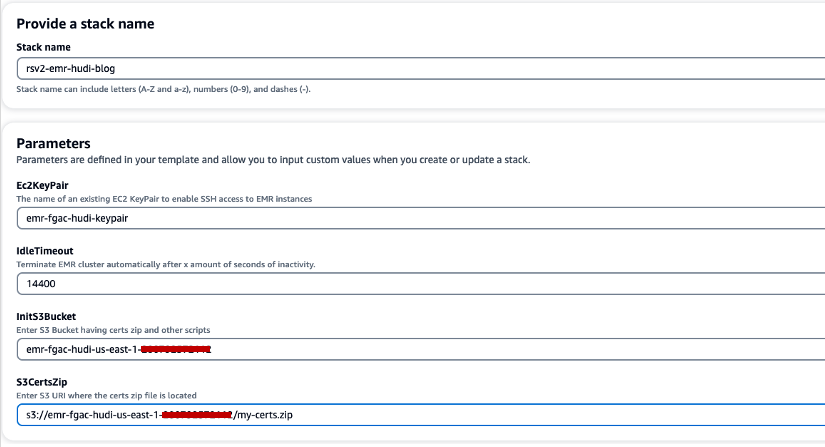
- W razie zamówieenia projektu Nazwa stosu, wprowadź nazwę stosu (na przykład
rsv2-emr-hudi-blog). - W razie zamówieenia projektu Para kluczy Ec2, wprowadź nazwę pary kluczy.
- W razie zamówieenia projektu Limit czasu bezczynności, wprowadź limit czasu bezczynności klastra EMR, aby uniknąć płacenia za klaster, gdy nie jest on używany.
- W razie zamówieenia projektu Wiadro InitS3, wprowadź nazwę segmentu S3 utworzoną w celu zapisania pliku .zip certyfikatu szyfrowania Amazon EMR.
- W razie zamówieenia projektu S3CertsZip, wprowadź identyfikator URI S3 pliku .zip certyfikatu szyfrowania Amazon EMR.
- Wybierz Potwierdzam, że AWS CloudFormation może tworzyć zasoby IAM o niestandardowych nazwach.
- Dodaj Utwórz stos.
Wdrożenie stosu CloudFormation zajmuje około 10 minut.
Skonfiguruj Formację Jeziora na potrzeby integracji z Amazon EMR
Wykonaj następujące kroki, aby skonfigurować formację jeziora:
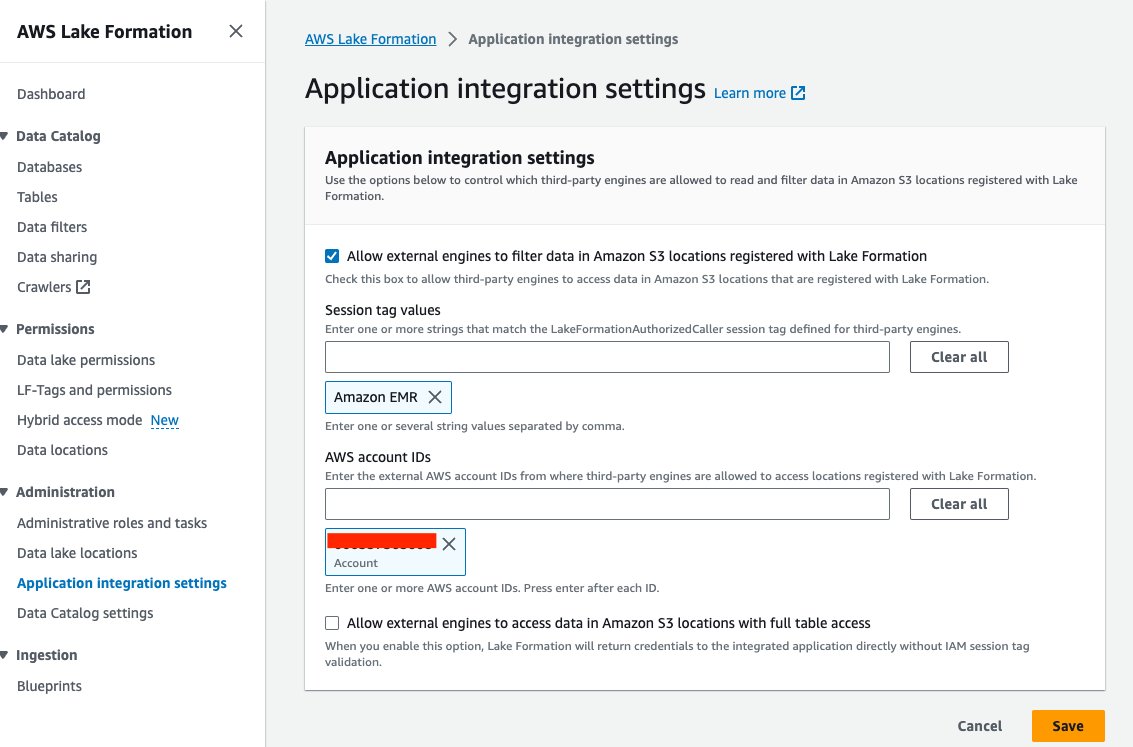
- W konsoli Lake Formation wybierz Ustawienia integracji aplikacji dla Administracja w okienku nawigacji.
- Wybierz Zezwalaj zewnętrznym silnikom na filtrowanie danych w lokalizacjach Amazon S3 zarejestrowanych w Lake Formation.
- Dodaj Amazon EMR dla Wartości znaczników sesji.
- Wprowadź identyfikator swojego konta AWS dla Identyfikatory kont AWS.
- Dodaj Zapisz.
- Dodaj Bazy danych dla Katalog danych w okienku nawigacji.
- Dodaj Utwórz bazę danych.
- W razie zamówieenia projektu Imię, wpisz wartość domyślną.
- Dodaj Utwórz bazę danych.
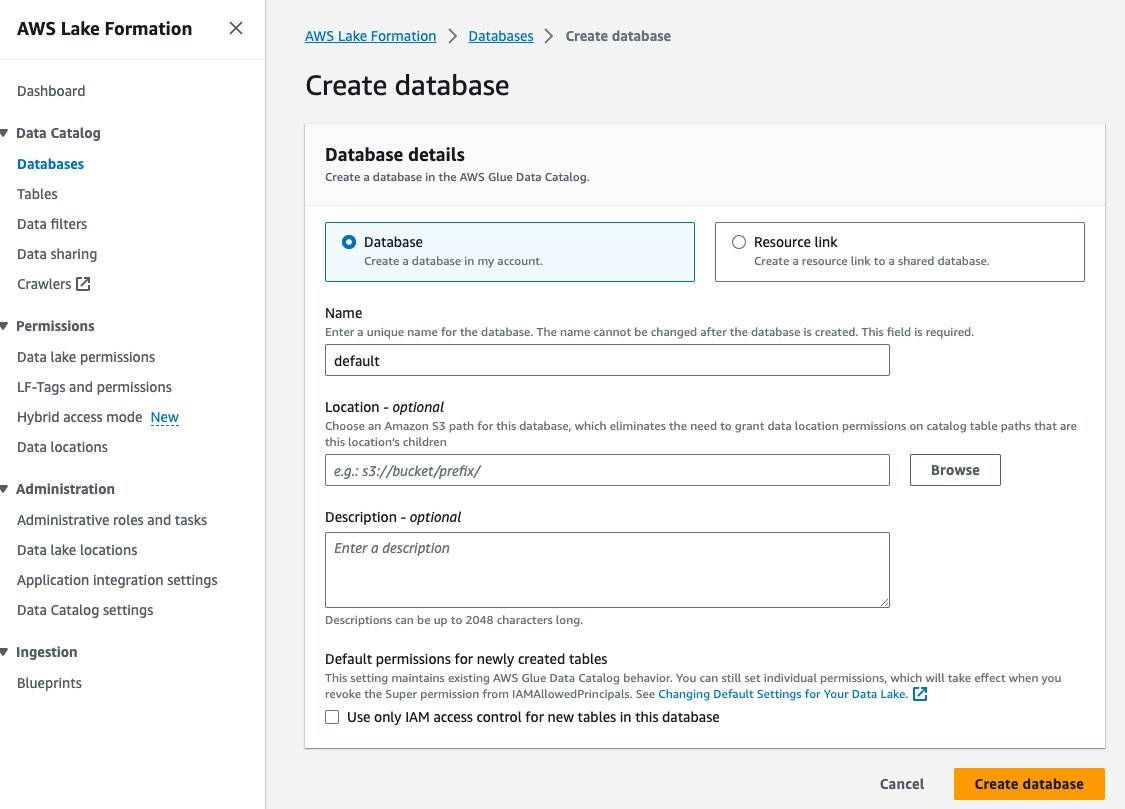
- Dodaj Uprawnienia do jeziora danych dla Uprawnienia w okienku nawigacji.
- Dodaj Dotacja.
- Wybierz Użytkownicy i role uprawnień.
- Wybierz swoje role IAM.
- W razie zamówieenia projektu Bazy danych, wybierz opcję domyślną.
- W razie zamówieenia projektu Uprawnienia do bazy danych, Wybierz Opisać.
- Dodaj Dotacja.
Skopiuj plik Hudi JAR do Amazon EMR HDFS
Do używaj Hudi z notatnikami Jupyter, musisz wykonać następujące kroki dla klastra EMR, co obejmuje skopiowanie pliku JAR Hudi z lokalnego katalogu Amazon EMR do jego magazynu HDFS, aby móc skonfigurować sesję Spark do korzystania z Hudi:
- Autoryzuj przychodzący ruch SSH (port 22).
- Skopiuj wartość dla Publiczny DNS węzła podstawowego (na przykład ec2-XXX-XXX-XXX-XXX.compute-1.amazonaws.com) z klastra EMR Podsumowanie

- Wróć do poprzedniego terminala AWS Cloud9, którego użyłeś do utworzenia pary kluczy EC2.
- Uruchom następujące polecenie, aby połączyć się z protokołem SSH w węźle podstawowym EMR. Zastąp symbol zastępczy nazwą hosta DNS EMR:
- Uruchom następujące polecenie, aby skopiować plik Hudi JAR do systemu HDFS:
Utwórz bazę danych i tabele Hudi w Formacji Jeziora
Teraz jesteśmy gotowi do utworzenia bazy danych i tabel Hudi z włączoną funkcją FGAC w roli środowiska wykonawczego EMR. The Rola środowiska wykonawczego EMR to rola uprawnień, którą możesz określić podczas przesyłania zadania lub zapytania do klastra EMR.
Przyznaj uprawnienia twórcy bazy danych
Najpierw przyznajmy uprawnienia twórcy bazy danych Lake Formation<STACK-NAME>-hudi-db-creator-role:
- Zaloguj się na swoje konto AWS jako administrator.
- W konsoli Lake Formation wybierz Role i zadania administracyjne dla Administracja w okienku nawigacji.
- Upewnij się, że użytkownik logowania AWS został dodany jako administrator jeziora danych.
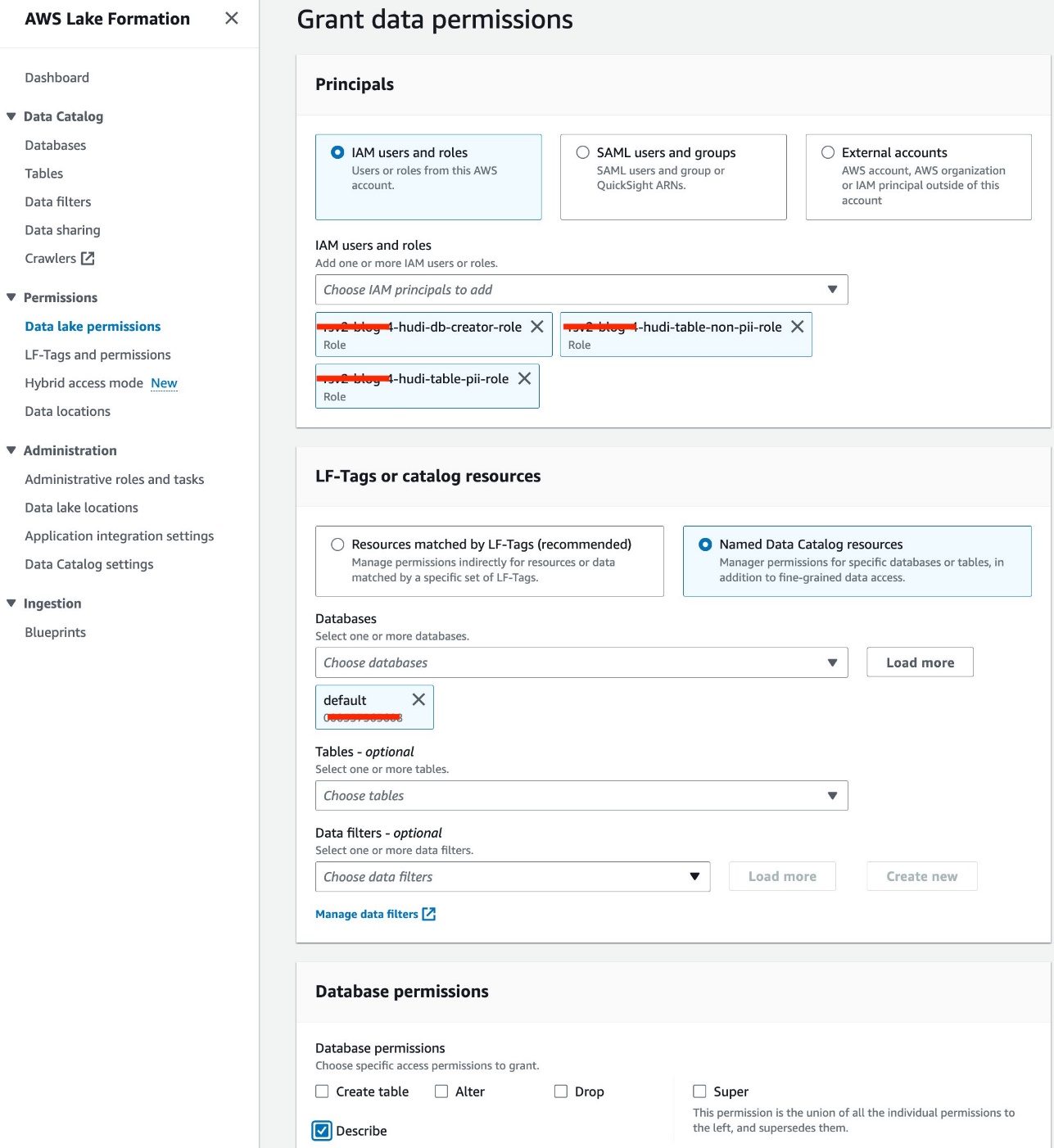
- W Twórca bazy danych Sekcja, wybierz Dotacja.
- W razie zamówieenia projektu Użytkownicy i role uprawnieńwybierz
<STACK-NAME>-hudi-db-creator-role. - W razie zamówieenia projektu Uprawnienia do katalogu, Wybierz Utwórz bazę danych.
- Dodaj Dotacja.
Zarejestruj lokalizację jeziora danych
Następnie zarejestrujmy lokalizację jeziora danych S3 w Lake Formation:
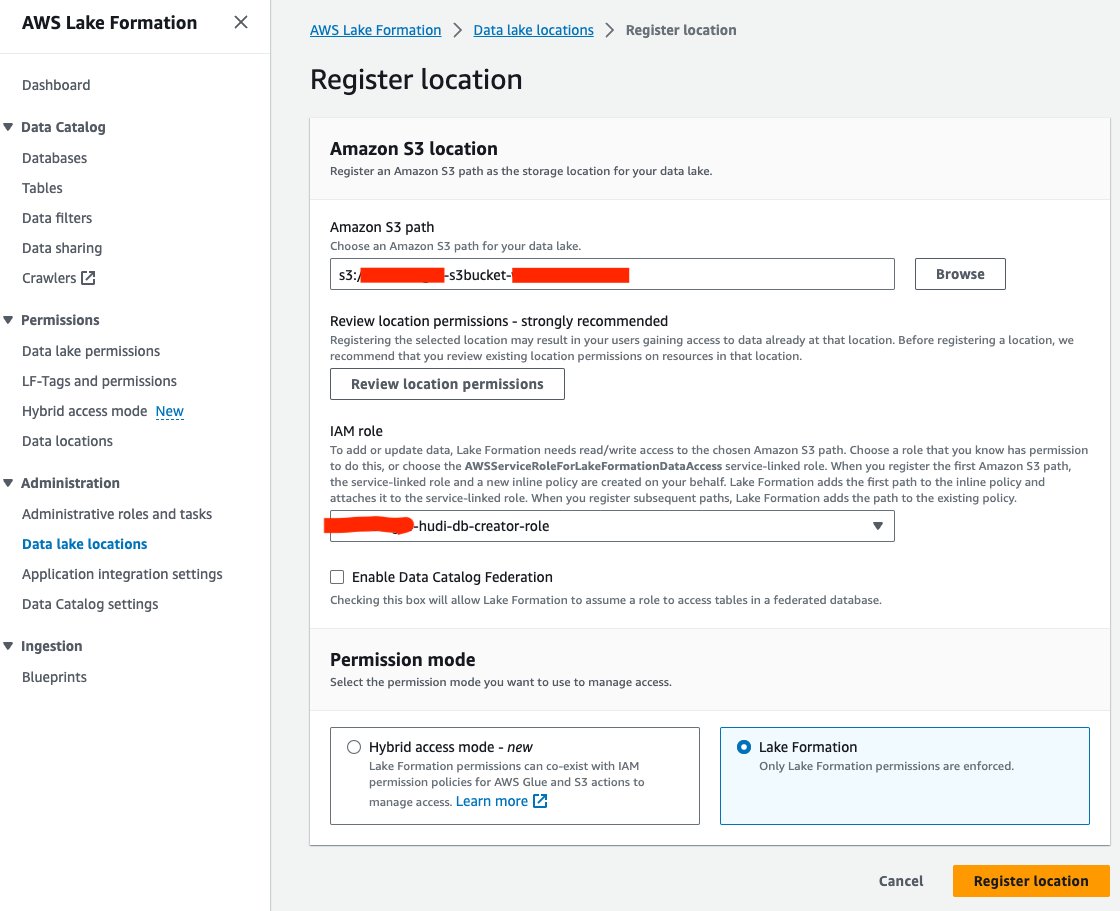
- W konsoli Lake Formation wybierz Lokalizacje jeziora danych dla Administracja w okienku nawigacji.
- Dodaj Zarejestruj lokalizację.
- W razie zamówieenia projektu Ścieżka Amazon S3, Wybierz Przeglądaj i wybierz zasobnik Data Lake S3. (
<STACK_NAME>s3bucket-XXXXXXX) utworzony ze stosu CloudFormation. - W razie zamówieenia projektu Rola IAMwybierz
<STACK-NAME>-hudi-db-creator-role. - W razie zamówieenia projektu Tryb uprawnień, Wybierz Formacja jeziora.
- Dodaj Zarejestruj lokalizację.
Przyznaj uprawnienia do lokalizacji danych
Następnie musimy przyznać<STACK-NAME>-hudi-db-creator-rolezezwolenie na lokalizację danych:
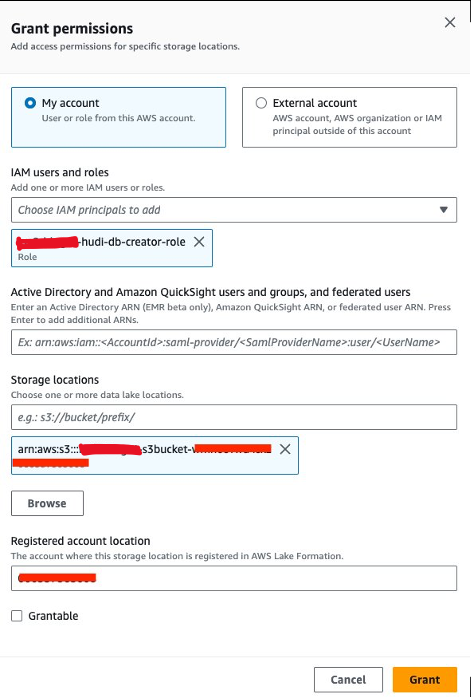
- W konsoli Lake Formation wybierz Lokalizacje danych dla Uprawnienia w okienku nawigacji.
- Dodaj Dotacja.
- W razie zamówieenia projektu Użytkownicy i role uprawnieńwybierz
<STACK-NAME>-hudi-db-creator-role. - W razie zamówieenia projektu Miejsca przechowywania, wejdź do segmentu S3 (
<STACK_NAME>-s3bucket-XXXXXXX). - Dodaj Dotacja.
Połącz się z klastrem EMR
Teraz użyjmy notatnika Jupyter w SageMaker Studio, aby połączyć się z klastrem EMR z rolą wykonawczą EMR twórcy bazy danych:
- W konsoli SageMaker wybierz domeny w okienku nawigacji.
- Wybierz domenę
<STACK-NAME>-Studio-EMR-LF-Hudi. - Na Premiera menu obok profilu użytkownika
<STACK-NAME>-hudi-db-creatorwybierz Studio.
- Pobierz notatnik rsv2-hudi-db-twórca-notebook.
- Wybierz ikonę przesyłania.
- Wybierz pobrany notatnik Jupyter i wybierz Otwarte.
- Otwórz przesłany notatnik.
- W razie zamówieenia projektu Obrazwybierz IskraMagia.
- W razie zamówieenia projektu Jądrowybierz PySpark.
- Pozostaw pozostałe konfiguracje jako domyślne i wybierz Wybierz.
- Dodaj Grupa aby połączyć się z klastrem EMR.

- Wybierz EMR w klastrze EC2 (
<STACK-NAME>-EMR-Cluster) utworzony przy użyciu stosu CloudFormation. - Dodaj Skontaktuj się.
- W razie zamówieenia projektu Rola wykonawcza EMRwybierz
<STACK-NAME>-hudi-db-creator-role. - Dodaj Skontaktuj się.
Utwórz bazę danych i tabele
Teraz możesz wykonać kroki opisane w notatniku, aby utworzyć bazę danych i tabele Hudi. Główne kroki są następujące:
- Po uruchomieniu notebooka skonfiguruj
“spark.sql.catalog.spark_catalog.lf.managed":"true"aby poinformować Sparka, że spark_catalog jest chroniony przez Lake Formation. - Utwórz tabele Hudi, korzystając z następującego języka Spark SQL.
- Wstaw dane z tabeli źródłowej do tabel Hudi.
- Wstaw dane ponownie do tabel Hudi.
Zapytaj o tabele Hudi za pośrednictwem Lake Formation za pomocą FGAC
Po utworzeniu bazy danych i tabel Hudi możesz wysyłać zapytania do tabel przy użyciu szczegółowej kontroli dostępu w Lake Formation. Stworzyliśmy dwa typy tabel Hudi: Copy-On-Write (COW) i Merge-On-Read (MOR). Tabela COW przechowuje dane w formacie kolumnowym (Parkiet), a każda aktualizacja podczas zapisu tworzy nową wersję plików. Oznacza to, że przy każdej aktualizacji Hudi zapisuje cały plik na nowo, co może wymagać więcej zasobów, ale zapewnia szybszą wydajność odczytu. Z drugiej strony MOR jest wprowadzany w przypadkach, gdy COW może nie być optymalny, szczególnie w przypadku obciążeń wymagających dużej liczby zapisów lub zmian. W tabeli MOR przy każdej aktualizacji Hudi zapisuje tylko wiersz dotyczący zmienionego rekordu, co zmniejsza koszty i umożliwia zapis z niskim opóźnieniem. Jednak wydajność odczytu może być wolniejsza w porównaniu do tabel COW.
Przyznaj uprawnienia dostępu do tabeli
Używamy roli IAM<STACK-NAME>-hudi-table-pii-roledo wysyłania zapytań do Hudi COW i MOR zawierających kolumny PII. Najpierw udzielamy pozwolenia na dostęp do tabeli za pośrednictwem Lake Formation:
- W konsoli Lake Formation wybierz Uprawnienia do jeziora danych dla Uprawnienia w okienku nawigacji.
- Dodaj Dotacja.
- Dodaj
<STACK-NAME>-hudi-table-pii-roledla Użytkownicy i role uprawnień. - Wybierz
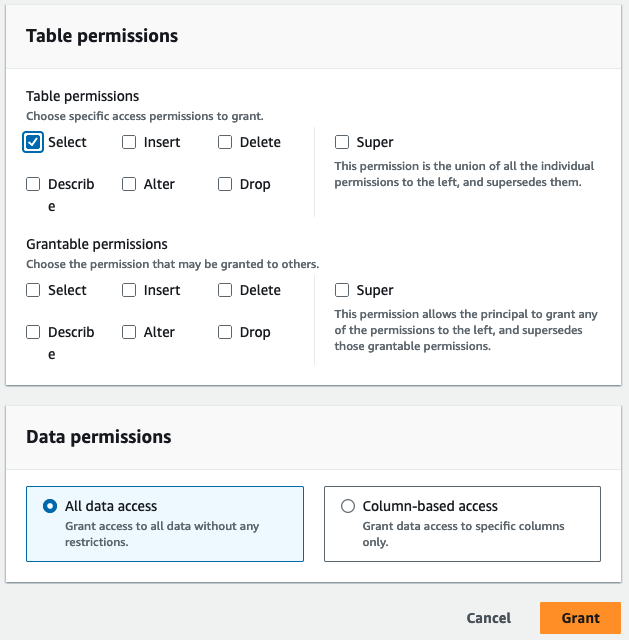
rsv2_blog_hudi_db_1baza danych dla Bazy danych. - W razie zamówieenia projektu Stoły, wybierz cztery tabele Hudi utworzone w notatniku Jupyter.
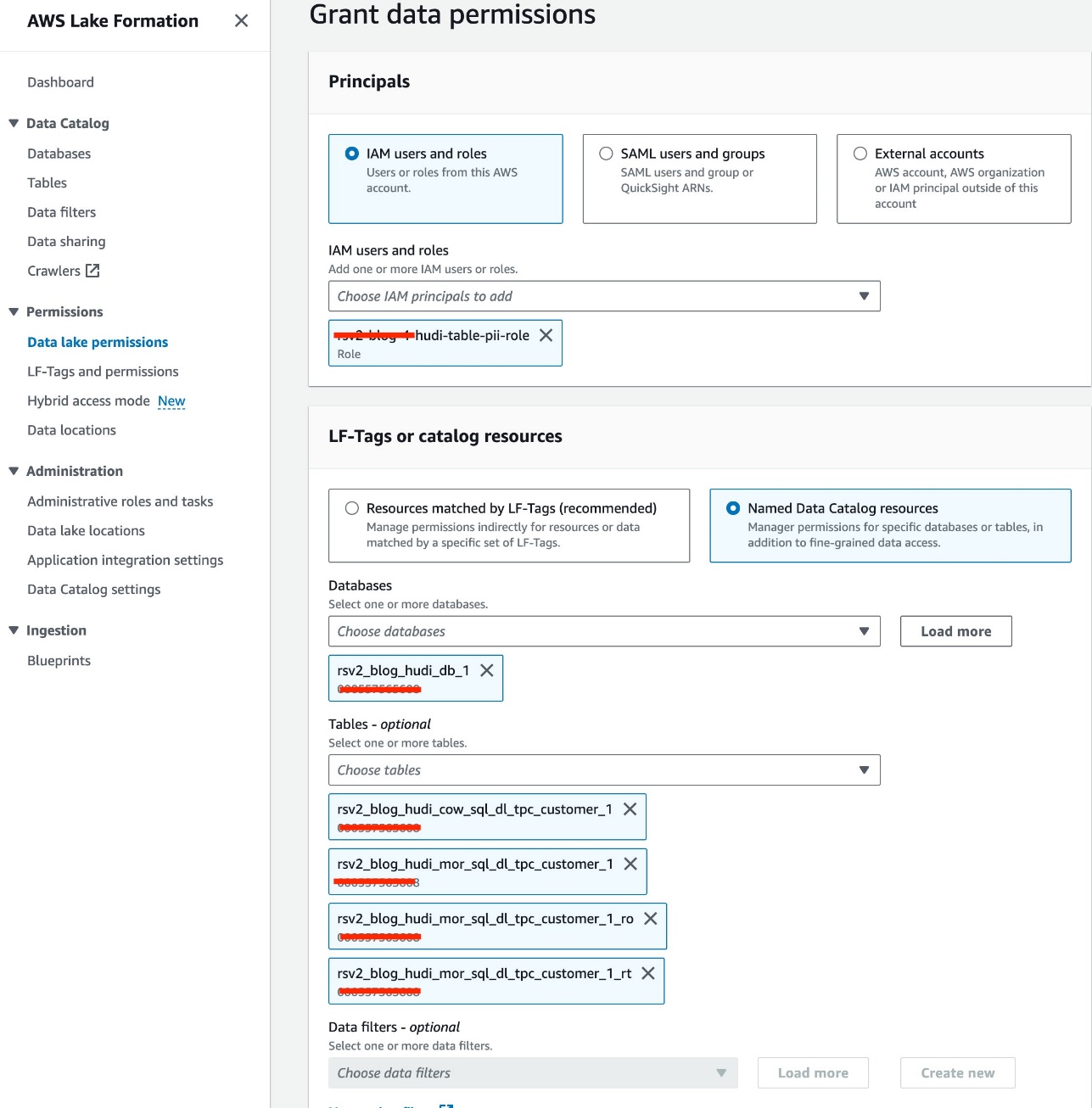
- W razie zamówieenia projektu Uprawnienia do tabeli, Wybierz Wybierz.
- Dodaj Dotacja.
Zapytanie o kolumny umożliwiające identyfikację osób
Teraz możesz uruchomić notatnik i wysłać zapytanie do tabel Hudi. Wykonajmy kroki podobne do poprzedniej sekcji, aby uruchomić notatnik w SageMaker Studio:
- W konsoli SageMaker przejdź do
<STACK-NAME>-Studio-EMR-LF-Hudidomeny. - Na Premiera menu obok
<STACK-NAME>-hudi-table-readerprofil użytkownika, wybierz Studio. - Prześlij pobrany notatnik rsv2-hudi-table-pii-czytnik-notebook.
- Otwórz przesłany notatnik.
- Powtórz kroki konfiguracji notebooka i połącz się z tym samym klastrem EMR, ale użyj roli
<STACK-NAME>-hudi-table-pii-role.
Na obecnym etapie klaster EMR z obsługą FGAC musi wysyłać zapytania do kolumny czasu zatwierdzenia Hudi w celu wykonywania zapytań przyrostowych i podróży w czasie. Nie obsługuje składni „znacznika czasu od” platformy Spark i Spark.read(). Aktywnie pracujemy nad włączeniem obsługi obu działań do przyszłych wydań Amazon EMR z włączoną funkcją FGAC.
Możesz teraz wykonać kroki opisane w notatniku. Oto kilka wyróżnionych kroków:
- Uruchom zapytanie migawki.
- Uruchom zapytanie przyrostowe.
- Uruchom zapytanie dotyczące podróży w czasie.
- Uruchamiaj zapytania do tabel MOR zoptymalizowane pod kątem odczytu i działające w czasie rzeczywistym.
Wysyłaj zapytania do tabel Hudi za pomocą filtrów danych na poziomie kolumn i wierszy
Używamy roli IAM<STACK-NAME>-hudi-table-non-pii-roledo wysyłania zapytań do tabel Hudi. Ta rola nie pozwala na wykonywanie zapytań w żadnych kolumnach zawierających informacje umożliwiające identyfikację. Używamy filtrów danych na poziomie kolumn i wierszy Lake Formation, aby wdrożyć precyzyjną kontrolę dostępu:
- W konsoli Lake Formation wybierz Filtry danych dla Katalog danych w okienku nawigacji.
- Dodaj Utwórz nowy filtr.
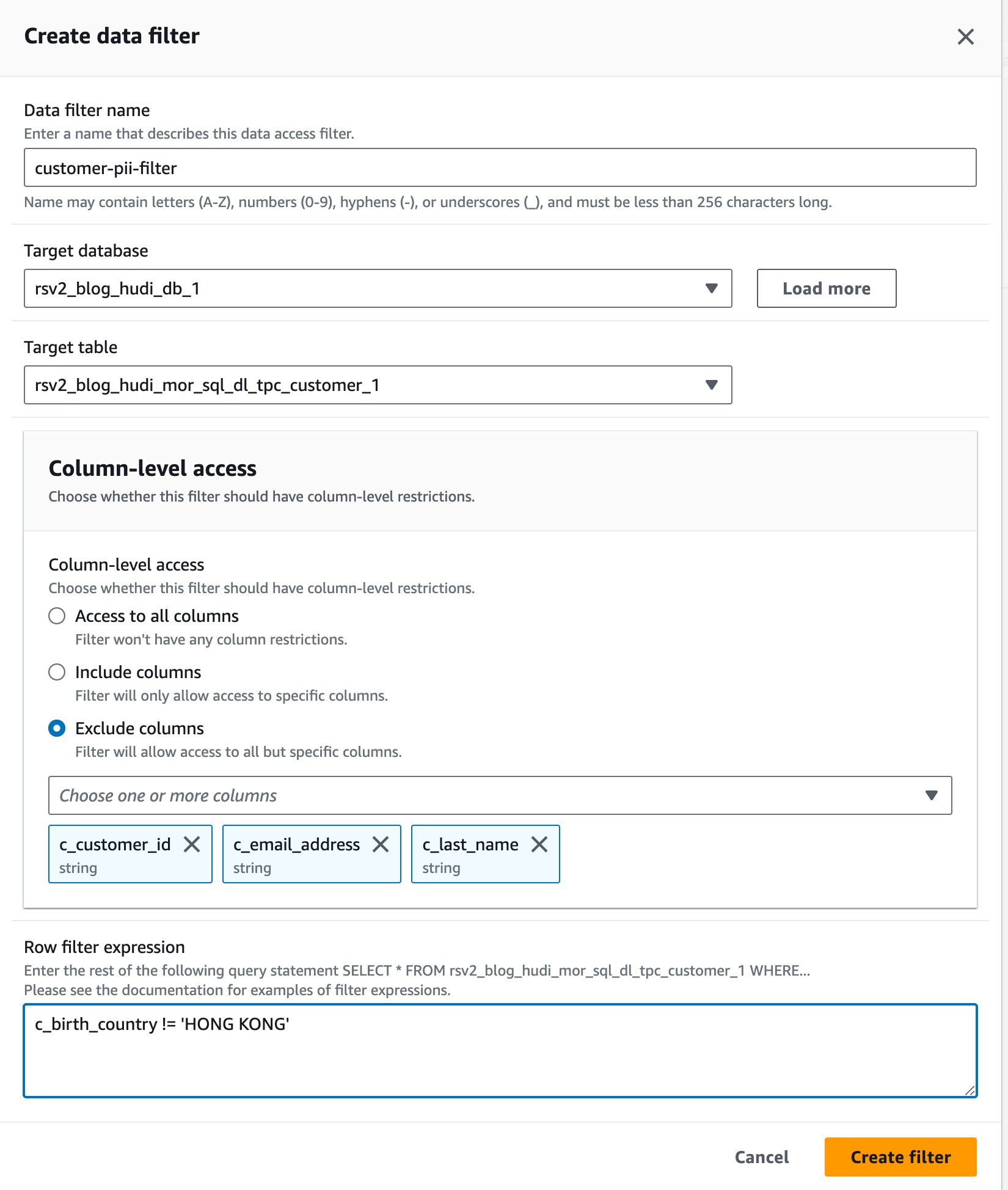
- W razie zamówieenia projektu Nazwa filtra danych, wchodzić
customer-pii-filter. - Dodaj
rsv2_blog_hudi_db_1dla Docelowa baza danych. - Dodaj
rsv2_blog_hudi_mor_sql_dl_customer_1dla Tabela docelowa. - Wybierz Wyklucz kolumny i wybierz
c_customer_id,c_email_address,c_last_namekolumny. - Wchodzę
c_birth_country != 'HONG KONG'dla Wyrażenie filtra wierszy. - Dodaj Utwórz filtr.
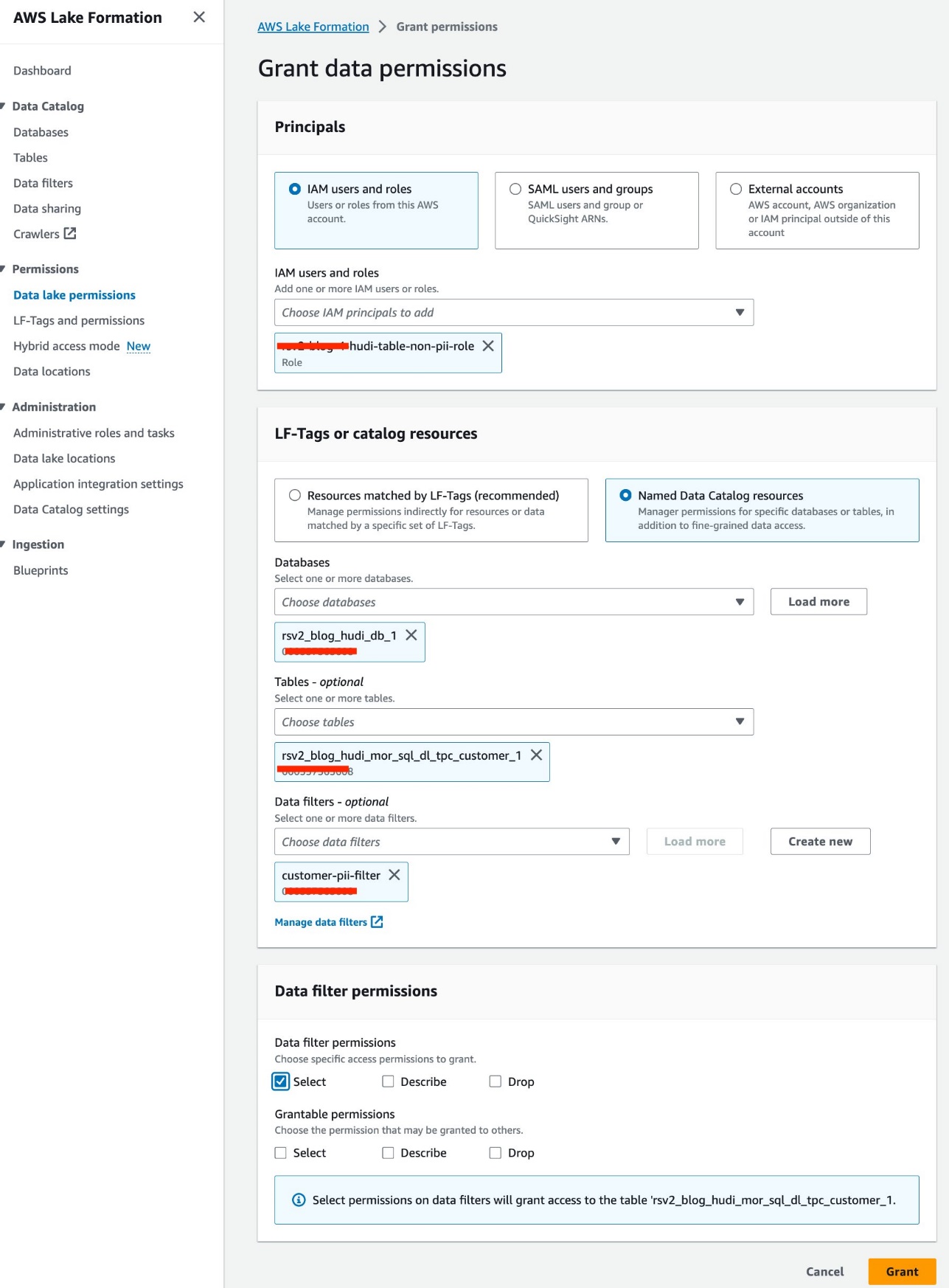
- Dodaj Uprawnienia do jeziora danych dla Uprawnienia w okienku nawigacji.
- Dodaj Dotacja.
- Dodaj
<STACK-NAME>-hudi-table-non-pii-roledla Użytkownicy i role uprawnień. - Dodaj
rsv2_blog_hudi_db_1dla Bazy danych. - Dodaj
rsv2_blog_hudi_mor_sql_dl_tpc_customer_1dla Stoły. - Dodaj
customer-pii-filterdla Filtry danych. - W razie zamówieenia projektu Uprawnienia do filtrowania danych, Wybierz Wybierz.
- Dodaj Dotacja.
Wykonajmy podobne kroki, aby uruchomić notatnik w SageMaker Studio:
- W konsoli SageMaker przejdź do domeny
Studio-EMR-LF-Hudi. - Na Premiera menu dla
hudi-table-readerprofil użytkownika, wybierz Studio. - Prześlij pobrany notatnik rsv2-hudi-table-non-pii-czytnik-notebook i wybierz Otwarte.
- Powtórz kroki konfiguracji notebooka i połącz się z tym samym klastrem EMR, ale wybierz rolę
<STACK-NAME>-hudi-table-non-pii-role.
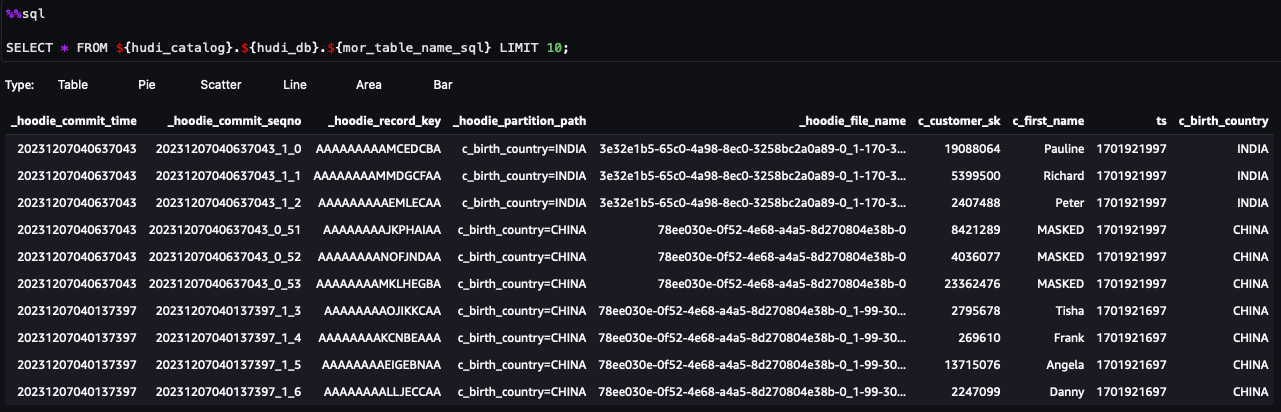
Możesz teraz wykonać kroki opisane w notatniku. Na podstawie wyników zapytania widać, że zastosowano FGAC poprzez filtr danych Formacja jeziora. Rola nie widzi kolumn umożliwiających identyfikacjęc_customer_id,c_last_name,c_email_address. Również wiersze zHONG KONGzostały przefiltrowane.
Sprzątać
Po zakończeniu eksperymentowania z rozwiązaniem zalecamy oczyszczenie zasobów, wykonując następujące czynności, aby uniknąć nieoczekiwanych kosztów:
- Zamknij aplikacje SageMaker Studio dla profili użytkowników.
Klaster EMR zostanie automatycznie usunięty po przekroczeniu limitu czasu bezczynności.
- usunąć System plików Amazon Elastic Wolumin (Amazon EFS) utworzony dla domeny.
- Opróżnij wiadra S3 utworzony przez stos CloudFormation.
- W konsoli AWS CloudFormation usuń stos.
Wnioski
W tym poście użyliśmy Apachi Hudi, jednego z typów tabel OTF, aby zademonstrować tę nową funkcję wymuszającą precyzyjną kontrolę dostępu w Amazon EMR. Możesz zdefiniować szczegółowe uprawnienia w Lake Formation dla tabel OTF i zastosować je za pośrednictwem zapytań Spark SQL w klastrach EMR. Można także używać funkcji transakcyjnego jeziora danych, takich jak uruchamianie zapytań migawkowych, zapytań przyrostowych, podróży w czasie i zapytań DML. Należy pamiętać, że ta nowa funkcja obejmuje wszystkie stoły OTF.
Ta funkcja jest uruchamiana począwszy od wersji Amazon EMR 6.15 regiony gdzie dostępny jest Amazon EMR. Dzięki integracji Amazon EMR z Lake Formation możesz pewnie zarządzać dużymi zbiorami danych i je przetwarzać, odblokowując spostrzeżenia i ułatwiając podejmowanie świadomych decyzji, zachowując jednocześnie bezpieczeństwo i zarządzanie danymi.
Aby dowiedzieć się więcej, zapoznaj się z Włącz tworzenie jezior za pomocą Amazon EMR i skontaktuj się z architektami rozwiązań AWS, którzy mogą Ci pomóc w podróży danych.
O autorze
 Raymonda Laia jest starszym architektem rozwiązań specjalizującym się w zaspokajaniu potrzeb dużych klientów korporacyjnych. Jego doświadczenie polega na pomaganiu klientom w migracji skomplikowanych systemów korporacyjnych i baz danych do AWS, tworzeniu korporacyjnych hurtowni danych i platform jezior danych. Raymond specjalizuje się w identyfikowaniu i projektowaniu rozwiązań dla przypadków użycia AI/ML, a szczególnie koncentruje się na rozwiązaniach AWS Serverless i projektowaniu architektury opartej na zdarzeniach.
Raymonda Laia jest starszym architektem rozwiązań specjalizującym się w zaspokajaniu potrzeb dużych klientów korporacyjnych. Jego doświadczenie polega na pomaganiu klientom w migracji skomplikowanych systemów korporacyjnych i baz danych do AWS, tworzeniu korporacyjnych hurtowni danych i platform jezior danych. Raymond specjalizuje się w identyfikowaniu i projektowaniu rozwiązań dla przypadków użycia AI/ML, a szczególnie koncentruje się na rozwiązaniach AWS Serverless i projektowaniu architektury opartej na zdarzeniach.
 Bin WangaDoktor, jest starszym specjalistą ds. rozwiązań analitycznych w AWS i może poszczycić się ponad 12-letnim doświadczeniem w branży ML, ze szczególnym uwzględnieniem reklamy. Posiada wiedzę specjalistyczną w zakresie przetwarzania języka naturalnego (NLP), systemów rekomendacyjnych, różnorodnych algorytmów ML i operacji ML. Jego pasją jest stosowanie technik ML/DL i big data do rozwiązywania rzeczywistych problemów.
Bin WangaDoktor, jest starszym specjalistą ds. rozwiązań analitycznych w AWS i może poszczycić się ponad 12-letnim doświadczeniem w branży ML, ze szczególnym uwzględnieniem reklamy. Posiada wiedzę specjalistyczną w zakresie przetwarzania języka naturalnego (NLP), systemów rekomendacyjnych, różnorodnych algorytmów ML i operacji ML. Jego pasją jest stosowanie technik ML/DL i big data do rozwiązywania rzeczywistych problemów.
 Aditya Shah jest inżynierem ds. rozwoju oprogramowania w AWS. Interesuje się bazami danych i silnikami hurtowni danych. Pracował nad optymalizacją wydajności, zgodnością z bezpieczeństwem i zgodnością z ACID dla silników takich jak Apache Hive i Apache Spark.
Aditya Shah jest inżynierem ds. rozwoju oprogramowania w AWS. Interesuje się bazami danych i silnikami hurtowni danych. Pracował nad optymalizacją wydajności, zgodnością z bezpieczeństwem i zgodnością z ACID dla silników takich jak Apache Hive i Apache Spark.
 Melodia Yang jest starszym architektem rozwiązań Big Data dla Amazon EMR w AWS. Jest doświadczonym liderem analityki współpracującym z klientami AWS, aby zapewnić wskazówki dotyczące najlepszych praktyk i porady techniczne, aby pomóc im w sukcesie w transformacji danych. Jej zainteresowania to frameworki i automatyzacja open source, inżynieria danych oraz DataOps.
Melodia Yang jest starszym architektem rozwiązań Big Data dla Amazon EMR w AWS. Jest doświadczonym liderem analityki współpracującym z klientami AWS, aby zapewnić wskazówki dotyczące najlepszych praktyk i porady techniczne, aby pomóc im w sukcesie w transformacji danych. Jej zainteresowania to frameworki i automatyzacja open source, inżynieria danych oraz DataOps.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/enforce-fine-grained-access-control-on-open-table-formats-via-amazon-emr-integrated-with-aws-lake-formation/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 1
- 10
- 100
- 11
- 12
- 130
- 15%
- 16
- 17
- 20
- 22
- 400
- 7
- 8
- 9
- a
- O nas
- dostęp
- Konto
- uznać
- działania
- aktywnie
- w dodatku
- do tego
- Adresy
- Admin
- Administratorzy
- Reklama
- Rada
- Po
- ponownie
- AI / ML
- Algorytmy
- Wszystkie kategorie
- dopuszczać
- dozwolony
- pozwala
- wzdłuż
- również
- Amazonka
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- an
- analiza
- analitycy
- Analityczny
- analityka
- Analizując
- i
- każdy
- Apache
- Apache Spark
- Zastosowanie
- stosowany
- Aplikuj
- Stosowanie
- architekci
- architektura
- SĄ
- obszary
- na około
- AS
- pomagać
- Wsparcie
- pomoc
- założyć
- At
- audytu
- władza
- upoważniony
- automatycznie
- Automatyzacja
- dostępny
- uniknąć
- AWS
- Chmura AWS9
- Tworzenie chmury AWS
- Formacja AWS Lake
- z powrotem
- na podstawie
- BE
- być
- za
- jest
- Korzyści
- oprócz
- BEST
- Duży
- Big Data
- blogi
- chwaląc się
- obie
- budować
- ale
- by
- CA
- CAN
- zdolny
- nieść
- noszenie
- walizka
- Etui
- katalog
- catering
- pewien
- świadectwo
- certyfikaty
- Certyfikacja
- zmiana
- zmieniony
- Zmiany
- Chiny
- Dodaj
- Sprzątanie
- Cloud9
- Grupa
- kod
- Kolumna
- kolumny
- COM
- połączenie
- popełnić
- Firmy
- w porównaniu
- kompletny
- spełnienie
- składnik
- składniki
- obliczać
- komputer
- pojęcie
- Warunki
- Prowadzenie
- ufnie
- systemu
- konfiguracje
- Skontaktuj się
- Konsola
- budowy
- skontaktuj się
- zawierać
- zawiera
- kontrola
- kontrolowanych
- kontroli
- biurowy
- Odpowiedni
- Koszty:
- Koszty:
- kraj
- obejmuje
- Stwórz
- stworzony
- tworzy
- Tworzenie
- twórca
- Aktualny
- zwyczaj
- Klientów
- dane
- dostęp do danych
- analiza danych
- Jezioro danych
- Platforma danych
- prywatność danych
- analiza danych
- bezpieczeństwo danych
- hurtownia danych
- Baza danych
- Bazy danych
- Podejmowanie decyzji
- głęboko
- Domyślnie
- określić
- Delta
- wykazać
- demonstrowanie
- rozwijać
- Wdrożenie
- Wnętrze
- projektowanie
- detale
- oprogramowania
- różne
- odrębny
- inny
- dns
- do
- robi
- Nie
- domena
- zrobić
- nie
- na dół
- pobieranie
- napędzany
- podczas
- każdy
- więcej
- umożliwiać
- włączony
- Umożliwia
- szyfrowanie
- zakończenia
- Punkty końcowe
- egzekwować
- silnik
- inżynier
- Inżynieria
- silniki
- zapewnić
- zapewnia
- zapewnienie
- Wchodzę
- Enterprise
- klienci korporacyjni
- Cały
- Środowisko
- Eter (ETH)
- wydarzenie
- Każdy
- przykład
- egzekucja
- istnieje
- doświadczenie
- doświadczony
- ekspertyza
- eksploracja
- rozciąga się
- zewnętrzny
- ułatwienie
- szybciej
- Cecha
- Korzyści
- czuć
- filet
- Akta
- filtrować
- filtracja
- filtry
- i terminów, a
- Skupiać
- koncentruje
- obserwuj
- następujący
- następujący sposób
- W razie zamówieenia projektu
- format
- formacja
- Formaty
- cztery
- Framework
- Ramy
- Darmowy
- od
- Spełnić
- pełny
- Funkcjonalność
- dalej
- przyszłość
- Wzrost
- wygenerowane
- zarządzanie
- regulowane
- przyznać
- ziarnisty
- bardzo
- Zarządzanie
- Grupy
- poradnictwo
- ręka
- Have
- he
- jej
- tutaj
- Podświetlony
- jego
- historyczny
- historia
- Ul
- Hong
- Hongkong
- dom
- W jaki sposób
- How To
- Jednak
- HTML
- http
- HTTPS
- IAM
- ICON
- ID
- pomysł
- zidentyfikować
- identyfikacja
- Idle
- if
- ilustruje
- wdrożenia
- podnieść
- in
- obejmuje
- Włącznie z
- włączenie
- przyrostowe
- Indie
- przemysł
- informować
- Informacja
- poinformowany
- wkład
- spostrzeżenia
- zintegrowany
- Integracja
- integracja
- interaktywne
- zainteresowany
- zainteresowania
- Interfejs
- wewnętrzny
- najnowszych
- zawiły
- wprowadzono
- Przedstawia
- problem
- IT
- JEGO
- Praca
- Oferty pracy
- podróż
- jpg
- Notebook Jupyter
- Klawisz
- Kong
- jezioro
- język
- duży
- Nazwisko
- uruchomić
- uruchomiona
- lider
- UCZYĆ SIĘ
- poziomy
- leży
- lubić
- LIMIT
- linie
- miejscowy
- lokalizacja
- lokalizacji
- Zaloguj Się
- poważny
- robić
- zarządzanie
- zarządzane
- i konserwacjami
- kierownik
- wiele
- Może..
- znaczy
- Mechanizmy
- Spotkanie
- Menu
- Metadane
- może
- migracja
- minuty
- ML
- Algorytmy ML
- zmodyfikowano
- jeszcze
- ruch
- Nazwa
- Nazwy
- Naturalny
- Język naturalny
- Przetwarzanie języka naturalnego
- Nawigacja
- Nawigacja
- Potrzebować
- wymagania
- Nowości
- Nowa cecha
- nowo
- Następny
- nlp
- węzeł
- noty
- notatnik
- laptopy
- już dziś
- obiekty
- of
- często
- on
- ONE
- tylko
- koncepcja
- open source
- openssl
- operacje
- Optymalny
- Optymalizacja
- Option
- Opcje
- or
- zamówienie
- organizacja
- Inne
- na zewnątrz
- koniec
- đôi
- chleb
- szczególny
- szczególnie
- namiętny
- zwracając
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- wykonywania
- pozwolenie
- uprawnienia
- Osobiście
- PhD
- pii
- zastępczy
- Platforma
- Platformy
- plato
- Analiza danych Platona
- PlatoDane
- Proszę
- plus
- zwrotnica
- Popularny
- posiada
- Post
- praktyka
- konserwowanie
- poprzedni
- pierwotny
- prywatność
- przywilej
- przywileje
- problemy
- wygląda tak
- przetwarzanie
- Produkcja
- Profil
- profile
- dowód
- dowód koncepcji
- chroniony
- ochrona
- zapewniać
- zapewnia
- że
- publiczny
- cele
- zapytania
- Czytaj
- Czytający
- gotowy
- Prawdziwy świat
- w czasie rzeczywistym
- polecić
- rekord
- regeneracja
- zmniejsza
- redukcja
- odnosić się
- odnosi
- odzwierciedla
- region
- zarejestrować
- zarejestrowany
- regulamin
- zwolnić
- prasowe
- obsługi produkcji rolnej, która zastąpiła
- wymagany
- wymagania
- Zasób
- zasobochłonne
- Zasoby
- dalsze
- Efekt
- prawa
- Rola
- role
- RZĄD
- RSA
- reguły
- run
- bieganie
- Czas
- sagemaker
- taki sam
- Zapisz
- Sekcja
- bezpieczne
- zabezpieczone
- bezpieczeństwo
- widzieć
- Szukajcie
- wybierać
- senior
- wrażliwy
- serwer
- Bezserwerowe
- Usługi
- Sesja
- zestaw
- Zestawy
- w panelu ustawień
- ustawienie
- ona
- znak
- znacznie
- podobny
- Prosty
- upraszcza
- upraszczać
- ponieważ
- Migawka
- So
- Tworzenie
- rozwoju oprogramowania
- rozwiązanie
- Rozwiązania
- ROZWIĄZANIA
- kilka
- Źródło
- Iskra
- specjalista
- specjalizuje się
- SQL
- stos
- STAGE
- początek
- rozpoczęty
- Startowy
- oświadczenia
- Cel
- przechowywanie
- sklep
- Strategia
- sznur
- studio
- Zatwierdź
- podsieci
- sukces
- taki
- PODSUMOWANIE
- wsparcie
- podpory
- pewnie
- składnia
- systemy
- stół
- TAG
- trwa
- Techniczny
- Techniki
- szablon
- terminal
- że
- Połączenia
- Źródło
- ich
- Im
- następnie
- Tam.
- Te
- one
- to
- trzy
- Przez
- czas
- podróż w czasie
- Oś czasu
- do
- Śledzenie
- transakcja
- transakcyjny
- Transformacja
- tranzyt
- podróżować
- prawdziwy
- zaufany
- Ts
- drugiej
- rodzaj
- typy
- ui
- dla
- Nieoczekiwany
- nieznany
- odblokowywanie
- Aktualizacja
- zaktualizowane
- utrzymanie
- przesłanych
- URI
- posługiwać się
- przypadek użycia
- używany
- Użytkownik
- Użytkownicy
- za pomocą
- wartość
- różnorodny
- wersja
- Wersje
- przez
- widoczność
- Tom
- Magazyn
- Magazynowanie
- we
- sieć
- usługi internetowe
- jeśli chodzi o komunikację i motywację
- natomiast
- który
- Podczas
- KIM
- będzie
- w
- w ciągu
- pracował
- pracujący
- napisać
- lat
- ty
- Twój
- zefirnet
- zero
- Zamek błyskawiczny