Amazonka Atena to bezserwerowa i interaktywna usługa zapytań, która umożliwia łatwe analizowanie danych w Usługa Amazon Simple Storage (Amazon S3) i ponad 25 źródeł danych, w tym lokalne źródła danych lub inne systemy chmurowe korzystające z języka SQL lub Python. Wbudowane możliwości platformy Athena obejmują wysyłanie zapytań o dane geoprzestrzenne; na przykład możesz policz liczbę trzęsień ziemi w każdym hrabstwie Kalifornii. Wadą analizy na poziomie hrabstwa jest to, że może to dać mylne wrażenie, które części Kalifornii miały najwięcej trzęsień ziemi. Dzieje się tak, ponieważ hrabstwa nie są jednakowej wielkości; hrabstwo mogło mieć więcej trzęsień ziemi po prostu dlatego, że jest dużym hrabstwem. Co by było, gdybyśmy chcieli systemu hierarchicznego, który umożliwiałby powiększanie i pomniejszanie w celu agregowania danych z różnych obszarów geograficznych o jednakowej wielkości?
W tym poście przedstawiamy rozwiązanie, które wykorzystuje Sześciokątny hierarchiczny indeks przestrzenny Ubera (H3) podzielić kulę ziemską na równej wielkości sześciokąty. Następnie używamy Ateny funkcja zdefiniowana przez użytkownika (UDF), aby określić, w którym sześciokącie miało miejsce każde historyczne trzęsienie ziemi. Ponieważ sześciokąty są tej samej wielkości, ta analiza daje dobre wyobrażenie o tym, gdzie zwykle występują trzęsienia ziemi.
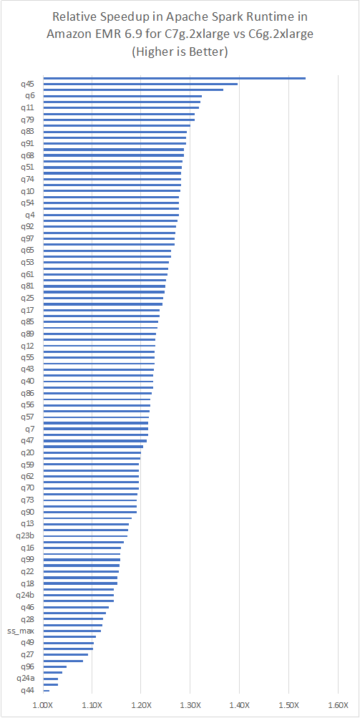
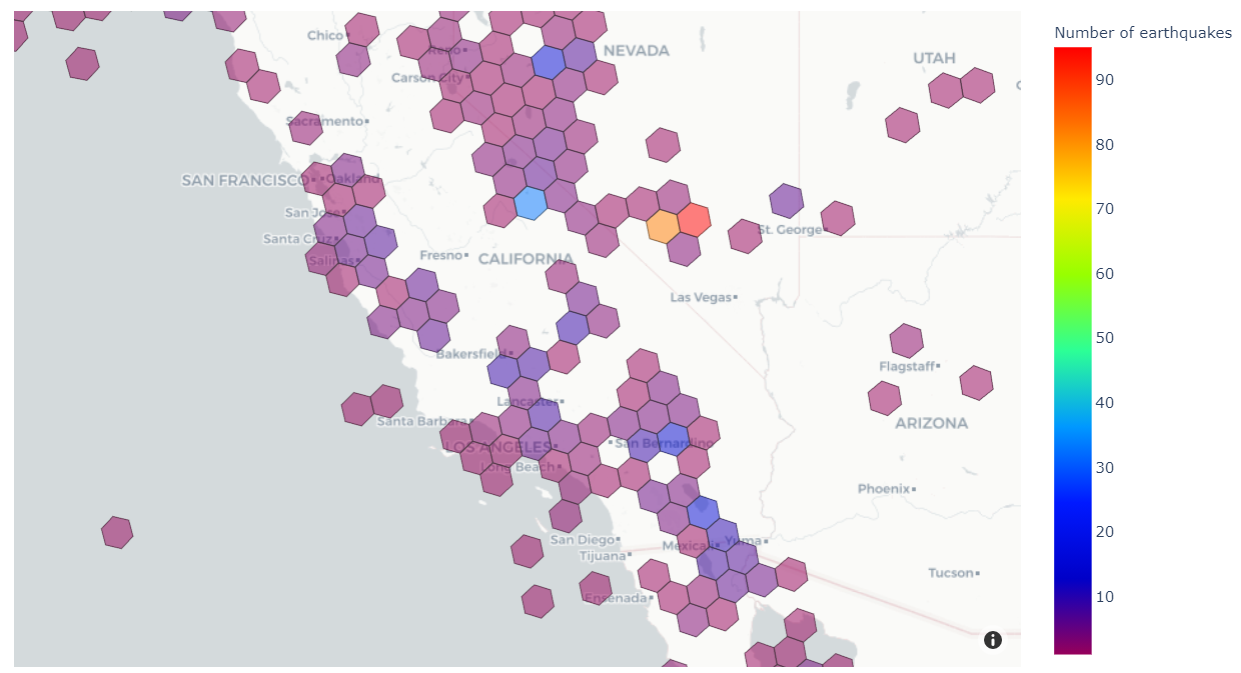
Na koniec utworzymy wizualizację podobną do tej poniżej, która pokazuje liczbę historycznych trzęsień ziemi w różnych obszarach zachodnich Stanów Zjednoczonych.
H3 dzieli kulę ziemską na równej wielkości sześciokąty foremne. Liczba sześciokątów zależy od wybranego rozkład, które mogą wahać się od 0 (122 sześciokątów, każdy o długości krawędzi około 1,100 km) do 15 (569,707,381,193,162 50 3 XNUMX XNUMX sześciokątów, każdy o długości krawędzi około XNUMX cm). HXNUMX umożliwia analizę na poziomie obszaru, a każdy obszar ma ten sam rozmiar i kształt.
Omówienie rozwiązania
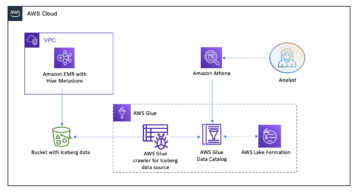
Rozwiązanie rozciąga się Wbudowane możliwości geoprzestrzenne platformy Athena tworząc UDF obsługiwany przez AWS Lambda. Na koniec używamy Amazon Sage Maker notatnik do uruchamiania zapytań Athena, które są renderowane jako mapa choropleth. Poniższy diagram ilustruje tę architekturę.

Architektura od końca do końca wygląda następująco:
- Plik CSV z historycznymi trzęsieniami ziemi jest przesyłany do zasobnika S3.
- An Klej AWS zewnętrzna tabela jest tworzona na podstawie CSV trzęsienia ziemi.
- Funkcja Lambda oblicza sześciokąty H3 dla parametrów (szerokość, długość geograficzna, rozdzielczość). Funkcja jest napisana w Javie i może być wywoływana jako UDF przy użyciu zapytań w Athenie.
- Notatnik SageMaker wykorzystuje plik AWS SDK dla pand pakiet do uruchamiania zapytania SQL w Athenie, w tym UDF.
- Pakiet Plotly Express renderuje kartograficzną mapę liczby trzęsień ziemi w każdym sześciokącie.
Wymagania wstępne
W tym poście używamy Atheny do odczytu danych w Amazon S3 przy użyciu tabeli zdefiniowanej w AWS Glue Data Catalog powiązanej z naszym zestawem danych o trzęsieniach ziemi. Jeśli chodzi o uprawnienia, istnieją dwa główne wymagania:
Skonfiguruj Amazon S3
Pierwszym krokiem jest utworzenie zasobnika S3 do przechowywania zestawu danych o trzęsieniach ziemi w następujący sposób:
- Pobierz plik CSV z historycznymi trzęsieniami ziemi z GitHub.
- Na konsoli Amazon S3 wybierz Wiadra w okienku nawigacji.
- Dodaj Utwórz wiadro.
- W razie zamówieenia projektu Nazwa wiadra, wprowadź globalnie unikalną nazwę zasobnika danych.
- Dodaj Utwórz folderi wprowadź nazwę folderu
earthquakes. - Prześlij plik do zasobnika S3. W tym przykładzie przesyłamy plik
earthquakes.csvplik doearthquakesprefiks.

Utwórz tabelę w Athenie
Przejdź do konsoli Athena, aby utworzyć tabelę. Wykonaj następujące kroki:
- Na konsoli Athena wybierz Edytor zapytań.
- Wybierz preferowaną grupę roboczą za pomocą menu rozwijanego.

- W edytorze SQL użyj następującego kodu, aby utworzyć tabelę w domyślnej bazie danych:
Utwórz funkcję Lambda dla Athena UDF
Aby uzyskać dokładne wyjaśnienie, jak zbudować UDF Athena, zobacz Wykonywanie zapytań za pomocą funkcji zdefiniowanych przez użytkownika. Używamy Javy 11 i Wiązanie Uber H3 Java zbudować H3 UDF. Zapewniamy wdrożenie UDF na GitHub.
Istnieje kilka opcji wdrażanie UDF za pomocą Lambda. W tym przykładzie używamy Konsola zarządzania AWS. W przypadku wdrożeń produkcyjnych prawdopodobnie chcesz użyć infrastruktury jako kodu, takiego jak Zestaw programistyczny AWS Cloud (CDK AWS). Aby uzyskać informacje o tym, jak używać AWS CDK do wdrażania funkcji Lambda, zobacz repozytorium kodu projektu. Inną możliwą opcją wdrożenia jest użycie AWS Serverless Application Repository (SAR).
Wdróż UDF
Wdróż powiązanie UDF Uber H3 za pomocą konsoli w następujący sposób:
- Przejdź do katalogu binarnego w GitHub repozytorium i pobrać
aws-h3-athena-udf-*.jarna lokalny pulpit. - Utwórz funkcję Lambda o nazwie
H3UDFw Czas pracy Ustawić Java 11 (korekta), Architektura Ustawić x86_64.
- Prześlij plik
aws-h3-athena-udf*.jarplik.
- Zmień nazwę obsługi na
com.aws.athena.udf.h3.H3AthenaHandler.
- W Ogólna konfiguracja Sekcja, wybierz Edytuj aby ustawić pamięć funkcji Lambda na 4096 MB, czyli ilość pamięci, która działa w naszych przykładach. Może być konieczne ustawienie większego rozmiaru pamięci dla przypadków użycia.

Użyj funkcji Lambda jako Athena UDF
Po utworzeniu funkcji Lambda możesz używać jej jako funkcji UDF. Poniższy zrzut ekranu pokazuje szczegóły funkcji.

Możesz teraz używać tej funkcji jako Athena UDF. W konsoli Athena uruchom następujące polecenie:

Połączenia udf/examples folder w GitHub repozytorium zawiera więcej przykładów zapytań Athena.
Rozwój UDF
Teraz, gdy pokazaliśmy, jak wdrożyć UDF dla Atheny za pomocą Lambdy, przejdźmy głębiej do tworzenia tego rodzaju UDF. Jak wyjaśniono w Wykonywanie zapytań za pomocą funkcji zdefiniowanych przez użytkownika, aby opracować UDF, musimy najpierw zaimplementować klasę, która dziedziczy UserDefinedFunctionHandler. Następnie musimy zaimplementować funkcje wewnątrz klasy, które mogą być używane jako UDF Ateny.
Implementację UDF rozpoczynamy od zdefiniowania klasy H3AthenaHandler który dziedziczy UserDefinedFunctionHandler. Następnie implementujemy funkcje, które działają jako opakowania funkcji zdefiniowanych w pliku Wiązanie Uber H3 Java. Dbamy o to, aby wszystkie funkcje zdefiniowane w API H3 Java Binding zostały zmapowane, tak aby mogły być używane w Athenie jako UDF. Mapujemy np lat_lng_to_cell_address funkcja użyta w poprzednim przykładzie do latLngToCell wiązania Java H3.
Oprócz wywołania powiązania Java wiele funkcji w H3AthenaHandler sprawdź, czy parametr wejściowy jest pusty. Sprawdzanie wartości null jest przydatne, ponieważ nie zakładamy, że dane wejściowe są różne od wartości null. W praktyce wartości puste dla indeksu H3 lub adresu nie są niczym niezwykłym.
Poniższy kod przedstawia implementację get_resolution funkcjonować:
Niektóre funkcje API H3, takie jak cellToLatLng powrót List<Double> z dwóch elementów, gdzie pierwszy element to szerokość geograficzna, a drugi to długość geograficzna. Implementowany przez nas UDF H3 zapewnia funkcję, która zwraca dobrze znany tekst (WKT) reprezentacja. Zapewniamy np cell_to_lat_lng_wkt, która zwraca a Point Ciąg WKT zamiast List<Double>. Możemy wtedy użyć danych wyjściowych cell_to_lat_lng_wkt w połączeniu z wbudowaną przestrzenną funkcją Athena ST_GeometryFromText w sposób następujący:
Athena UDF obsługuje tylko skalarne typy danych i nie obsługuje typów zagnieżdżonych. Jednak niektóre interfejsy API H3 zwracają typy zagnieżdżone. Na przykład polygonToCells funkcja w H3 przyjmuje a List<List<List<GeoCoord>>>. Nasza realizacja pt polygon_to_cells UDF otrzymuje Polygon Zamiast tego WKT. Poniżej przedstawiono przykładowe zapytanie Athena używające tego UDF:
Użyj notatników SageMaker do wizualizacji
A Notatnik SageMakera to zarządzane wystąpienie obliczeniowe uczenia maszynowego, na którym działa aplikacja notesu Jupyter. W tym przykładzie użyjemy notatnika SageMaker do napisania i uruchomienia naszego kodu w celu wizualizacji naszych wyników, ale jeśli twój przypadek użycia obejmuje Apache Spark, użycie Amazon Athena dla Apache Spark byłby świetnym wyborem. Aby uzyskać porady dotyczące najlepszych praktyk bezpieczeństwa dla SageMaker, patrz Budowanie bezpiecznych środowisk uczenia maszynowego za pomocą Amazon SageMaker. Możesz stworzyć swój własny notatnik SageMaker, postępując zgodnie z poniższymi instrukcjami:
- W konsoli SageMaker wybierz Notatnik w okienku nawigacji.
- Dodaj Instancje notebooków.
- Dodaj Utwórz instancję notesu.
- Wprowadź nazwę wystąpienia notatnika.
- Wybierz istniejącą rolę IAM lub stworzyć rolę który pozwala uruchomić SageMaker i zapewnia dostęp do Amazon S3 i Athena.
- Dodaj Utwórz instancję notesu.

- Poczekaj, aż stan notatnika zmieni się z
CreatingdoInService. - Otwórz instancję notesu, wybierając jupiter or laboratorium jupytera.
Przeglądaj dane
Jesteśmy teraz gotowi do eksploracji danych.
- Na konsoli Jupyter pod Nowościwybierz Notatnik.
- Na Wybierz Kernel wybierz z menu rozwijanego conda_python3.
- Dodaj nowe komórki, wybierając znak plus.
- W pierwszej komórce pobierz następujące moduły Pythona, których nie ma w standardowym środowisku SageMaker:
GeoJSON to popularny format przechowywania danych przestrzennych w formacie JSON. The
geojsonmoduł umożliwia łatwe odczytywanie i zapisywanie danych GeoJSON za pomocą Pythona. Instalujemy drugi moduł,awswrangler, jest AWS SDK dla pand. Jest to bardzo łatwy sposób na wczytanie danych z różnych źródeł danych AWS do ramek danych Pandy. Używamy go do odczytywania danych o trzęsieniach ziemi z tabeli Athena. - Następnie importujemy wszystkie pakiety, których używamy do importowania danych, zmiany ich kształtu i wizualizacji:
- Rozpoczynamy importowanie naszych danych za pomocą
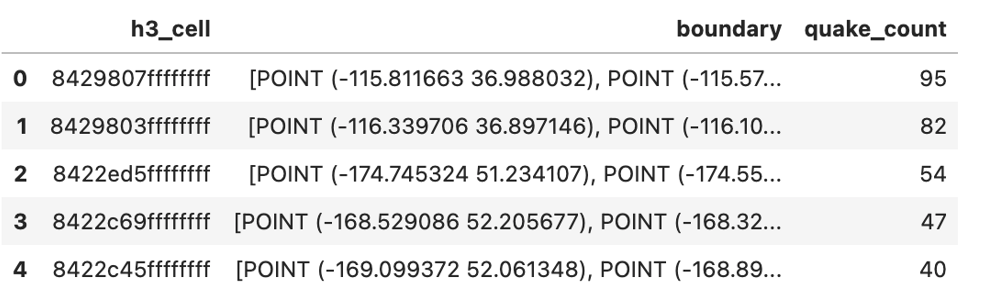
athena.read_sql._queryfunkcja w AWS SDK dla pand. Zapytanie Athena ma podzapytanie, które używa UDF do dodania kolumnyh3_celldo każdego rzędu wearthquakestabeli, w oparciu o szerokość i długość geograficzną trzęsienia ziemi. Funkcja analitycznaCOUNTjest następnie używany do znalezienia liczby trzęsień ziemi w każdej komórce H3. W tej wizualizacji interesują nas tylko trzęsienia ziemi w USA, więc odfiltrowujemy wiersze w ramce danych, które znajdują się poza obszarem zainteresowania:Poniższy zrzut ekranu przedstawia nasze wyniki.
Postępuj zgodnie z pozostałymi krokami w naszym Notatnik Jupyter aby zobaczyć, jak analizujemy i wizualizujemy nasz przykład z danymi H3 UDF.
Wizualizuj wyniki
Aby zwizualizować nasze wyniki, używamy Plotka ekspresowa moduł do tworzenia kartogramów naszych danych. Kartogram to rodzaj wizualizacji cieniowanej na podstawie wartości ilościowych. To świetna wizualizacja do naszego przypadku użycia, ponieważ cieniujemy różne regiony na podstawie częstotliwości trzęsień ziemi.
Na powstałym obrazie możemy zobaczyć zakresy częstotliwości trzęsień ziemi w różnych obszarach Ameryki Północnej. Uwaga, rozdzielczość H3 na tej mapie jest niższa niż na wcześniejszej mapie, przez co każdy sześciokąt obejmuje większy obszar globu.

Sprzątać
Aby uniknąć dodatkowych opłat na koncie, usuń utworzone przez siebie zasoby:
- W konsoli SageMaker wybierz notatnik i na Akcje menu, wybierz Stop.
- Poczekaj, aż stan notatnika zmieni się na
Stopped, a następnie ponownie wybierz notatnik i na Akcje menu, wybierz Usuń. - Na konsoli Amazon S3 wybierz utworzony wiadro i wybierz pusty.
- Wprowadź nazwę zasobnika i wybierz pusty.
- Wybierz ponownie wiadro i wybierz Usuń.
- Wprowadź nazwę zasobnika i wybierz Usuń zasobnik.
- W konsoli Lambda wybierz nazwę funkcji i na Akcje menu, wybierz Usuń.
Wnioski
W tym poście zobaczyłeś, jak rozszerzyć funkcje w Athenie na potrzeby analizy geoprzestrzennej, dodając własną funkcję zdefiniowaną przez użytkownika. Chociaż w tej demonstracji użyliśmy indeksu geoprzestrzennego H3 firmy Uber, możesz przynieść własny indeks geoprzestrzenny do własnej niestandardowej analizy geoprzestrzennej.
W tym poście użyliśmy notatników Athena, Lambda i SageMaker do wizualizacji wyników naszych UDF w zachodnich Stanach Zjednoczonych. Przykłady kodu znajdują się w h3-udf-dla-ateny Repozytorium GitHub.
W kolejnym kroku możesz zmodyfikować kod w tym poście i dostosować go do własnych potrzeb, aby uzyskać dalsze informacje na podstawie własnych danych geograficznych. Na przykład możesz zwizualizować inne przypadki, takie jak susze, powodzie i wylesianie.
O autorach
 Johna Telforda jest starszym konsultantem w Amazon Web Services. Jest specjalistą w zakresie big data i hurtowni danych. John ukończył informatykę na Uniwersytecie Brunel.
Johna Telforda jest starszym konsultantem w Amazon Web Services. Jest specjalistą w zakresie big data i hurtowni danych. John ukończył informatykę na Uniwersytecie Brunel.
 Anwara Rizala jest starszym konsultantem ds. uczenia maszynowego z siedzibą w Paryżu. Współpracuje z klientami AWS nad opracowywaniem rozwiązań w zakresie danych i sztucznej inteligencji, aby zapewnić zrównoważony rozwój ich działalności.
Anwara Rizala jest starszym konsultantem ds. uczenia maszynowego z siedzibą w Paryżu. Współpracuje z klientami AWS nad opracowywaniem rozwiązań w zakresie danych i sztucznej inteligencji, aby zapewnić zrównoważony rozwój ich działalności.
 Paulina Ting jest Data Scientist w zespole AWS Professional Services. Wspiera klientów w osiąganiu i przyspieszaniu ich wyników biznesowych poprzez opracowywanie zrównoważonych rozwiązań AI/ML. W wolnym czasie Pauline lubi podróżować, surfować i próbować nowych deserów.
Paulina Ting jest Data Scientist w zespole AWS Professional Services. Wspiera klientów w osiąganiu i przyspieszaniu ich wyników biznesowych poprzez opracowywanie zrównoważonych rozwiązań AI/ML. W wolnym czasie Pauline lubi podróżować, surfować i próbować nowych deserów.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/extend-geospatial-queries-in-amazon-athena-with-udfs-and-aws-lambda/
- :Jest
- 1
- 10
- 100
- 11
- 7
- 70
- 8
- 9
- a
- O nas
- przyspieszenie
- dostęp
- Konto
- osiągnięcia
- działać
- adres
- Rada
- AI
- AI / ML
- Wszystkie kategorie
- pozwala
- Chociaż
- Amazonka
- Amazonka Atena
- Amazon Web Services
- Ameryka
- ilość
- analiza
- Analityczny
- w czasie rzeczywistym sprawiają,
- Analizując
- i
- Inne
- Apache
- Apache Spark
- api
- Pszczoła
- Zastosowanie
- architektura
- SĄ
- POWIERZCHNIA
- obszary
- AS
- powiązany
- At
- uniknąć
- AWS
- Klej AWS
- AWS Lambda
- Usługi profesjonalne AWS
- na podstawie
- BE
- bo
- rozpocząć
- poniżej
- BEST
- Najlepsze praktyki
- pomiędzy
- Duży
- Big Data
- wiążący
- przynieść
- budować
- wbudowany
- biznes
- by
- oblicza
- California
- wezwanie
- nazywa
- CAN
- możliwości
- walizka
- Etui
- katalog
- Komórki
- zmiana
- Opłaty
- ZOBACZ
- wybór
- Dodaj
- Wybierając
- wybrany
- klasa
- Chmura
- kod
- Kolumna
- połączenie
- kompletny
- obliczać
- komputer
- Computer Science
- systemu
- Konsola
- konsultant
- mógłby
- hrabstwo
- pokrywa
- Stwórz
- stworzony
- Tworzenie
- zwyczaj
- Klientów
- dostosować
- dane
- naukowiec danych
- magazyn danych
- Baza danych
- głębiej
- Domyślnie
- zdefiniowane
- definiowanie
- wylesianie
- Stopień
- zależy
- rozwijać
- Wdrożenie
- wdrożenia
- głębokość
- stacjonarny
- detale
- Ustalać
- rozwijać
- rozwijanie
- oprogramowania
- różne
- Niekorzyść
- dystans
- nie
- Podwójna
- pobieranie
- każdy
- Wcześniej
- trzęsienie ziemi
- z łatwością
- łatwo
- krawędź
- redaktor
- element
- Elementy
- Umożliwia
- koniec końców
- Wchodzę
- Środowisko
- środowiska
- Równie
- Eter (ETH)
- przykład
- przykłady
- Przede wszystkim system został opracowany
- wyjaśnione
- wyjaśnienie
- odkryj
- ekspresowy
- rozciągać się
- zewnętrzny
- dodatkowy
- sprawiedliwy
- Łąka
- filet
- filtrować
- finał
- W końcu
- Znajdź
- i terminów, a
- następujący
- następujący sposób
- W razie zamówieenia projektu
- format
- FRAME
- Częstotliwość
- od
- funkcjonować
- Funkcje
- dalej
- Wzrost
- szczelina
- geograficzny
- geograficzny
- geometria
- otrzymać
- GitHub
- Dać
- daje
- Globalnie
- globus
- Dotacje
- wspaniały
- Zarządzanie
- Rosnąć
- Have
- historyczny
- W jaki sposób
- How To
- Jednak
- HTML
- http
- HTTPS
- IAM
- wdrożenia
- realizacja
- importować
- importowanie
- in
- zawierać
- włączony
- obejmuje
- Włącznie z
- wskaźnik
- Informacja
- Infrastruktura
- wkład
- spostrzeżenia
- zainstalować
- przykład
- zamiast
- instrukcje
- interaktywne
- odsetki
- zainteresowany
- IT
- Java
- John
- json
- Notebook Jupyter
- większe
- szerokość
- nauka
- poziom
- lubić
- LNG
- masa
- miejscowy
- lokalizacja
- długo
- maszyna
- uczenie maszynowe
- Główny
- robić
- WYKONUJE
- zarządzane
- i konserwacjami
- wiele
- mapa
- mapowanie
- Pamięć
- Menu
- modyfikować
- moduł
- Moduły
- jeszcze
- Nazwa
- Nawigacja
- Potrzebować
- wymagania
- Nowości
- Następny
- Północ
- Ameryka Północna
- notatnik
- laptopy
- numer
- miejsce
- of
- on
- ONE
- Option
- Opcje
- zamówienie
- Inne
- Wynik
- wydajność
- zewnętrzne
- własny
- pakiet
- Pakiety
- pandy
- chleb
- parametr
- parametry
- Paryż
- strony
- uprawnienia
- Miejsca
- plato
- Analiza danych Platona
- PlatoDane
- plus
- Wielokąt
- Popularny
- możliwy
- Post
- powered
- praktyka
- praktyki
- Korzystny
- teraźniejszość
- prawdopodobnie
- produkować
- Produkcja
- profesjonalny
- zapewniać
- zapewnia
- publiczny
- Python
- ilościowy
- zasięg
- RE
- Czytaj
- gotowy
- otrzymuje
- regiony
- regularny
- renderuje
- obsługi produkcji rolnej, która zastąpiła
- składnica
- reprezentacja
- wymagania
- Rozkład
- Zasoby
- REST
- dalsze
- wynikły
- Efekt
- powrót
- powraca
- Rola
- RZĄD
- run
- sagemaker
- taki sam
- nauka
- Naukowiec
- Sdk
- druga
- bezpieczne
- bezpieczeństwo
- senior
- Bezserwerowe
- usługa
- Usługi
- zestaw
- kilka
- Shape
- Targi
- znak
- Prosty
- po prostu
- Rozmiar
- So
- rozwiązanie
- Rozwiązania
- kilka
- Źródło
- Źródła
- Iskra
- Przestrzenne
- specjalista
- SQL
- standard
- Rynek
- Ewolucja krok po kroku
- Cel
- przechowywanie
- sklep
- przechowywany
- taki
- wsparcie
- podpory
- zrównoważone
- system
- systemy
- stół
- trwa
- zespół
- REGULAMIN
- że
- Połączenia
- Strefa
- ich
- Te
- czas
- do
- Top
- Podróżowanie
- typy
- Uber
- dla
- wyjątkowy
- uniwersytet
- niezwykły
- przesłanych
- us
- USA
- posługiwać się
- przypadek użycia
- Użytkownik
- Wartości
- różnorodny
- wyobrażanie sobie
- wyobrażać sobie
- poszukiwany
- Droga..
- sieć
- usługi internetowe
- Western
- Co
- czy
- który
- Wikipedia
- będzie
- w
- w ciągu
- WKT
- Workgroup
- działa
- by
- napisać
- napisany
- Twój
- zefirnet
- zoom