Ten post na blogu został napisany wspólnie z Chaoyangiem He i Salmanem Avestimehrem z FedML.
Analizowanie rzeczywistych danych z zakresu opieki zdrowotnej i nauk przyrodniczych (HCLS) wiąże się z kilkoma praktycznymi wyzwaniami, takimi jak rozproszone silosy danych, brak wystarczających danych w jednym miejscu dla rzadkich zdarzeń, wytyczne regulacyjne zabraniające udostępniania danych, wymagania dotyczące infrastruktury i koszty ponoszone przy tworzeniu scentralizowane repozytorium danych. Ponieważ znajdują się w wysoce regulowanej domenie, partnerzy i klienci HCLS poszukują mechanizmów chroniących prywatność, aby zarządzać i analizować duże, rozproszone i poufne dane.
Aby złagodzić te wyzwania, proponujemy platformę federacyjnego uczenia się (FL), opartą na otwartym kodzie źródłowym FedML na AWS, która umożliwia analizę wrażliwych danych HCLS. Obejmuje trenowanie globalnego modelu uczenia maszynowego (ML) na podstawie rozproszonych danych zdrowotnych przechowywanych lokalnie w różnych lokalizacjach. Nie wymaga przenoszenia ani udostępniania danych między lokacjami ani na scentralizowanym serwerze podczas procesu uczenia modelu.
Wdrażanie platformy FL w chmurze wiąże się z kilkoma wyzwaniami. Automatyzacja infrastruktury klient-serwer w celu obsługi wielu kont lub wirtualnych chmur prywatnych (VPC) wymaga komunikacji równorzędnej VPC i wydajnej komunikacji między VPC i instancjami. W przypadku obciążenia produkcyjnego potrzebny jest stabilny potok wdrażania, aby bezproblemowo dodawać i usuwać klientów oraz aktualizować ich konfiguracje bez dużego obciążenia. Ponadto w konfiguracji heterogenicznej klienci mogą mieć różne wymagania dotyczące mocy obliczeniowej, sieci i pamięci masowej. W tej zdecentralizowanej architekturze rejestrowanie i debugowanie błędów na klientach może być trudne. Wreszcie określenie optymalnego podejścia do agregacji parametrów modelu, utrzymania wydajności modelu, zapewnienia prywatności danych i poprawy wydajności komunikacji jest żmudnym zadaniem. W tym poście zajmujemy się tymi wyzwaniami, udostępniając szablon federacyjnych operacji uczenia się (FLOPs), który obsługuje rozwiązanie HCLS. Rozwiązanie jest niezależne od przypadków użycia, co oznacza, że możesz je dostosować do swoich przypadków użycia, zmieniając model i dane.
W tej dwuczęściowej serii pokazujemy, jak wdrożyć platformę FL opartą na chmurze w AWS. w pierwszy post, opisaliśmy koncepcje FL i ramy FedML. W tej drugiej części przedstawiamy przypadek użycia w opiece zdrowotnej i naukach przyrodniczych oparty na rzeczywistym zbiorze danych eICU. Ten zestaw danych obejmuje wieloośrodkową bazę danych intensywnej opieki zebraną z ponad 200 szpitali, co czyni go idealnym do testowania naszych eksperymentów FL.
Przypadek użycia HCLS
W celu demonstracji zbudowaliśmy model FL na publicznie dostępnym zbiorze danych, aby zarządzać krytycznie chorymi pacjentami. Użyliśmy Baza danych wspólnych badań eICU, wieloośrodkowa baza danych oddziałów intensywnej terapii (OIOM), obejmująca 200,859 139,367 spotkań pacjentów na oddziałach dla 335 208 unikalnych pacjentów. Zostali przyjęci na jeden z 2014 oddziałów w 2015 szpitalach w całych Stanach Zjednoczonych w latach 1-XNUMX. Ze względu na leżącą u podstaw heterogeniczność i rozproszony charakter danych stanowi idealny przykład do przetestowania tej struktury FL w świecie rzeczywistym. Zbiór danych obejmuje pomiary laboratoryjne, parametry życiowe, informacje o planie opieki, leki, historię pacjenta, diagnozę przyjęć, diagnozy ze znacznikiem czasu z ustrukturyzowanej listy problemów i podobnie wybrane terapie. Jest dostępny jako zestaw plików CSV, które można załadować do dowolnego systemu relacyjnej bazy danych. Tabele są pozbawione elementów umożliwiających identyfikację w celu spełnienia wymogów prawnych amerykańskiej ustawy o przenośności i odpowiedzialności w ubezpieczeniach zdrowotnych (HIPAA). Dostęp do danych można uzyskać za pośrednictwem repozytorium PhysioNet, a szczegóły procesu dostępu do danych można znaleźć tutaj [XNUMX].
Dane eICU są idealne do opracowywania algorytmów ML, narzędzi wspomagających podejmowanie decyzji i postępów w badaniach klinicznych. Do analizy porównawczej przyjęliśmy zadanie przewidywania śmiertelności wewnątrzszpitalnej pacjentów [2]. Zdefiniowaliśmy to jako zadanie klasyfikacji binarnej, w którym każda próbka danych obejmuje 1-godzinne okno. Aby utworzyć kohortę do tego zadania, wybraliśmy pacjentów ze statusem wypisu ze szpitala w dokumentacji pacjenta i długością pobytu co najmniej 48 godzin, ponieważ koncentrujemy się na przewidywaniu śmiertelności w ciągu pierwszych 24 i 48 godzin. W ten sposób powstała kohorta 30,680 1,164,966 pacjentów zawierająca 3 5 48 rekordów. Przyjęliśmy wstępne przetwarzanie danych specyficzne dla domeny i metody opisane w [48] do przewidywania śmiertelności. Spowodowało to zagregowany zestaw danych zawierający kilka kolumn na pacjenta na rekord, jak pokazano na poniższym rysunku. Poniższa tabela zawiera dane pacjenta w interfejsie w stylu tabelarycznym z czasem w kolumnach (XNUMX przedziałów w ciągu XNUMX godzin) i obserwacjami parametrów życiowych w wierszach. Każdy wiersz reprezentuje zmienną fizjologiczną, a każda kolumna reprezentuje jej wartość zarejestrowaną w oknie czasowym wynoszącym XNUMX godzin dla pacjenta.
| Parametr fizjologiczny | Wykres_Czas_0 | Wykres_Czas_1 | Wykres_Czas_2 | Wykres_Czas_3 | Wykres_Czas_4 |
| Glasgow Ocena śpiączki Oczy | 4 | 4 | 4 | 4 | 4 |
| FiO2 | 15 | 15 | 15 | 15 | 15 |
| Glasgow Ocena śpiączki Oczy | 15 | 15 | 15 | 15 | 15 |
| Tętno | 101 | 100 | 98 | 99 | 94 |
| Inwazyjne ciśnienie rozkurczowe BP | 73 | 68 | 60 | 64 | 61 |
| Inwazyjne ciśnienie skurczowe | 124 | 122 | 111 | 105 | 116 |
| Średnie ciśnienie tętnicze (mmHg) | 77 | 77 | 77 | 77 | 77 |
| Silnik oceny śpiączki Glasgow | 6 | 6 | 6 | 6 | 6 |
| 02 Nasycenie | 97 | 97 | 97 | 97 | 97 |
| Częstość oddechów | 19 | 19 | 19 | 19 | 19 |
| Temperatura (C) | 36 | 36 | 36 | 36 | 36 |
| Glasgow Coma Wynik werbalny | 5 | 5 | 5 | 5 | 5 |
| wysokość wstępu | 162 | 162 | 162 | 162 | 162 |
| waga przyjęć | 96 | 96 | 96 | 96 | 96 |
| wiek | 72 | 72 | 72 | 72 | 72 |
| apacheadmissiondx | 143 | 143 | 143 | 143 | 143 |
| etniczność | 3 | 3 | 3 | 3 | 3 |
| płeć | 1 | 1 | 1 | 1 | 1 |
| glukoza | 128 | 128 | 128 | 128 | 128 |
| przesunięcie przyjęć do szpitala | -436 | -436 | -436 | -436 | -436 |
| stan wypisu ze szpitala | 0 | 0 | 0 | 0 | 0 |
| przesunięcie pozycji | -6 | -1 | 0 | 1 | 2 |
| pH | 7 | 7 | 7 | 7 | 7 |
| identyfikator pobytu jednostki pacjenta | 2918620 | 2918620 | 2918620 | 2918620 | 2918620 |
| przesunięcie rozładowania jednostkowego | 1466 | 1466 | 1466 | 1466 | 1466 |
| stan rozładowania jednostki | 0 | 0 | 0 | 0 | 0 |
Użyliśmy zarówno cech liczbowych, jak i kategorycznych i pogrupowaliśmy wszystkie zapisy każdego pacjenta, aby spłaszczyć je w serie czasowe z pojedynczym rekordem. Siedem cech kategorycznych (diagnoza przyjęcia, pochodzenie etniczne, płeć, Glasgow Coma Score Total, Glasgow Coma Score Eyes, Glasgow Coma Score Motor i Glasgow Coma Score Verbal zostało przekonwertowanych na jedno-gorące wektory kodujące) zawierało 429 unikalnych wartości i zostało przekształconych w jedną -gorące zatopienie. Aby zapobiec wyciekom danych między serwerami węzłów szkoleniowych, podzieliliśmy dane według identyfikatorów szpitali i przechowywaliśmy wszystkie dane szpitala w jednym węźle.
Omówienie rozwiązania
Poniższy diagram przedstawia architekturę wielokontowego wdrożenia FedML w AWS. Obejmuje to dwóch klientów (Uczestnik A i Uczestnik B) oraz agregator modeli.
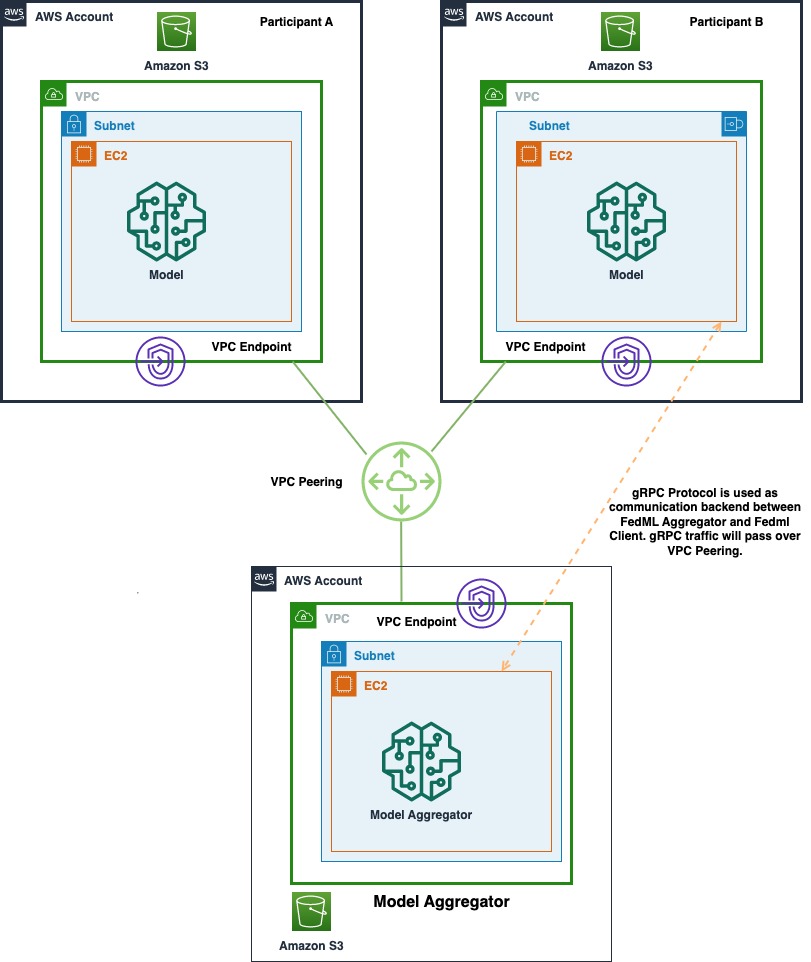
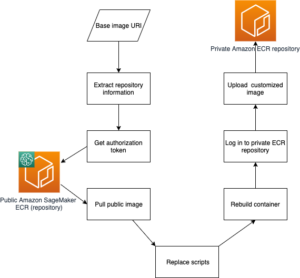
Architektura składa się z trzech oddzielnych Elastyczna chmura obliczeniowa Amazon (Amazon EC2) działające na własnym koncie AWS. Właścicielem każdej z dwóch pierwszych instancji jest klient, a właścicielem trzeciej instancji jest agregator modeli. Konta są połączone przez peering VPC, aby umożliwić wymianę modeli i wag ML między klientami a agregatorem. gRPC służy jako zaplecze komunikacyjne do komunikacji między agregatorem modeli a klientami. Przetestowaliśmy rozproszoną konfigurację obliczeniową opartą na jednym koncie z jednym serwerem i dwoma węzłami klienckimi. Każda z tych instancji została utworzona przy użyciu niestandardowego AMI Amazon EC2 z zainstalowanymi zależnościami FedML zgodnie z Instrukcja instalacji FedML.ai.
Skonfiguruj komunikację równorzędną VPC
Po uruchomieniu trzech instancji na odpowiednich kontach AWS ustanawiasz komunikację równorzędną VPC między kontami za pośrednictwem Wirtualna prywatna chmura Amazon (Amazon VPC). Aby skonfigurować połączenie równorzędne VPC, najpierw utwórz żądanie połączenia równorzędnego z innym VPC. Możesz poprosić o połączenie równorzędne VPC z innym VPC na swoim koncie lub z VPC na innym koncie AWS. Aby aktywować prośbę, właściciel VPC musi ją zaakceptować. Na potrzeby tej demonstracji skonfigurowaliśmy połączenie równorzędne między VPC na różnych kontach, ale w tym samym regionie. Informacje o innych konfiguracjach komunikacji równorzędnej VPC można znaleźć w artykule Utwórz połączenie równorzędne VPC.
Zanim zaczniesz, upewnij się, że masz numer konta AWS i identyfikator VPC VPC, z którym chcesz się połączyć.
Poproś o połączenie równorzędne VPC
Aby utworzyć połączenie równorzędne VPC, wykonaj następujące czynności:
- W konsoli Amazon VPC w okienku nawigacji wybierz Połączenia równorzędne.
- Dodaj Utwórz połączenie równorzędne.
- W razie zamówieenia projektu Znacznik nazwy połączenia równorzędnego, możesz opcjonalnie nazwać połączenie równorzędne VPC. Spowoduje to utworzenie tagu z kluczem o podanej nazwie i wartości. Ten tag jest widoczny tylko dla Ciebie; właściciel równorzędnego VPC może tworzyć własne tagi dla połączenia równorzędnego VPC.
- W razie zamówieenia projektu VPC (zgłaszający), wybierz VPC na swoim koncie, aby utworzyć połączenie równorzędne.
- W razie zamówieenia projektu Kontowybierz Inne konto.
- W razie zamówieenia projektu ID konta, wprowadź identyfikator konta AWS właściciela VPC akceptującego.
- W razie zamówieenia projektu VPC (akceptujący), wprowadź identyfikator VPC, za pomocą którego chcesz utworzyć połączenie równorzędne VPC.
- W oknie dialogowym potwierdzenia wybierz OK.
- Dodaj Utwórz połączenie równorzędne.
Zaakceptuj połączenie równorzędne VPC
Jak wspomniano wcześniej, połączenie równorzędne VPC musi zostać zaakceptowane przez właściciela VPC, do którego wysłano żądanie połączenia. Wykonaj następujące kroki, aby zaakceptować żądanie połączenia równorzędnego:
- W konsoli Amazon VPC użyj selektora regionu, aby wybrać region akceptującego VPC.
- W okienku nawigacji wybierz Połączenia równorzędne.
- Wybierz oczekujące połączenie równorzędne VPC (stan to
pending-acceptance) i na Akcje menu, wybierz Zaakceptować prośbę. - W oknie dialogowym potwierdzenia wybierz Tak, zaakceptuj.
- W drugim oknie dialogowym potwierdzenia wybierz Zmodyfikuj teraz moje tabele tras aby przejść bezpośrednio do strony z tabelami tras, lub wybierz Zamknij zrobić to później.
Zaktualizuj tabele tras
Aby włączyć prywatny ruch IPv4 między instancjami w równorzędnych VPC, dodaj trasę do tabel tras powiązanych z podsieciami obu instancji. Miejscem docelowym trasy jest blok CIDR (lub część bloku CIDR) równorzędnego VPC, a celem jest identyfikator połączenia równorzędnego VPC. Aby uzyskać więcej informacji, zobacz Skonfiguruj tabele tras.
Zaktualizuj swoje grupy zabezpieczeń, aby odwoływały się do równorzędnych grup VPC
Zaktualizuj reguły ruchu przychodzącego lub wychodzącego dla swoich grup zabezpieczeń VPC, aby odwoływały się do grup zabezpieczeń w równorzędnym VPC. Pozwala to na przepływ ruchu między instancjami, które są powiązane z przywoływaną grupą zabezpieczeń w równorzędnym VPC. Aby uzyskać więcej informacji na temat konfigurowania grup zabezpieczeń, zobacz Zaktualizuj swoje grupy zabezpieczeń, aby odwoływały się do równorzędnych grup zabezpieczeń.
Skonfiguruj FedML
Po uruchomieniu trzech instancji EC2 połącz się z każdą z nich i wykonaj następujące czynności:
- Sklonuj repozytorium FedML.
- Podaj dane topologii swojej sieci w pliku konfiguracyjnym
grpc_ipconfig.csv.
Plik ten można znaleźć pod adresem FedML/fedml_experiments/distributed/fedavg w repozytorium FedML. Plik zawiera dane o serwerze i klientach oraz ich mapowaniu wyznaczonych węzłów, takich jak FL Server — Node 0, FL Client 1 — Node 1 i FL Client 2 — Node2.
- Zdefiniuj plik konfiguracyjny mapowania GPU.
Plik ten można znaleźć pod adresem FedML/fedml_experiments/distributed/fedavg w repozytorium FedML. Plik gpu_mapping.yaml składa się z danych konfiguracyjnych do mapowania serwera klienta na odpowiedni procesor GPU, jak pokazano w poniższym fragmencie kodu.
Po zdefiniowaniu tych konfiguracji można przystąpić do uruchamiania klientów. Pamiętaj, że klienty muszą zostać uruchomione przed uruchomieniem serwera. Zanim to zrobimy, skonfigurujmy moduły ładujące dane do eksperymentów.
Dostosuj FedML do eICU
Aby dostosować repozytorium FedML dla zestawu danych eICU, wprowadź następujące zmiany w danych i module ładującym dane.
Dane
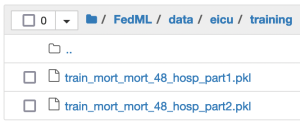
Dodaj dane do wstępnie przypisanego folderu danych, jak pokazano na poniższym zrzucie ekranu. Możesz umieścić dane w dowolnym wybranym przez siebie folderze, o ile ścieżka jest konsekwentnie przywoływana w skrypcie szkoleniowym i ma włączony dostęp. Aby postępować zgodnie z rzeczywistym scenariuszem HCLS, w którym lokalne dane nie są udostępniane w różnych lokalizacjach, podziel i próbkuj dane, aby uniknąć nakładania się identyfikatorów szpitali na dwóch klientach. Dzięki temu dane szpitala są hostowane na jego własnym serwerze. Wymusiliśmy również to samo ograniczenie, aby podzielić dane na zestawy pociągów/testów w ramach każdego klienta. Każdy z zestawów pociągów/testów u klientów miał stosunek etykiet pozytywnych do negatywnych w stosunku 1:10, z około 27,000 3,000 próbek podczas szkolenia i XNUMX XNUMX próbek w teście. Zajmujemy się nierównowagą danych w szkoleniu modeli za pomocą funkcji ważonej straty.
Ładowarka danych
Każdy z klientów FedML ładuje dane i konwertuje je na tensory PyTorch w celu wydajnego szkolenia na GPU. Rozszerz istniejącą nomenklaturę FedML, aby dodać folder dla danych eICU w data_processing teczka.

Poniższy fragment kodu ładuje dane ze źródła danych. Wstępnie przetwarza dane i zwraca jeden element na raz za pośrednictwem __getitem__ funkcja.
Uczenie modeli ML z pojedynczym punktem danych w danym momencie jest żmudne i czasochłonne. Trening modelu jest zwykle wykonywany na partiach punktów danych u każdego klienta. Aby to zaimplementować, moduł ładujący dane w data_loader.py skrypt konwertuje tablice NumPy na tensory Torch, jak pokazano w poniższym fragmencie kodu. Pamiętaj, że FedML zapewnia dataset.py i data_loader.py skrypty zarówno dla danych ustrukturyzowanych, jak i nieustrukturyzowanych, których można użyć do zmian specyficznych dla danych, tak jak w każdym projekcie PyTorch.
Zaimportuj moduł ładujący dane do skryptu szkoleniowego
Po utworzeniu modułu ładującego dane zaimportuj go do kodu FedML na potrzeby trenowania modelu ML. Jak każdy inny zestaw danych (na przykład CIFAR-10 i CIFAR-100), załaduj dane eICU do main_fedavg.py skrypt w ścieżce FedML/fedml_experiments/distributed/fedavg/. Tutaj użyliśmy uśredniania federacyjnego (fedavg) funkcja agregująca. Możesz zastosować podobną metodę, aby skonfigurować main plik dla dowolnej innej funkcji agregacji.
Funkcję ładującą dane dla danych eICU wywołujemy następującym kodem:
Zdefiniuj model
FedML obsługuje kilka gotowych algorytmów głębokiego uczenia się dla różnych typów danych, takich jak dane tabelaryczne, tekstowe, graficzne, wykresy i Internet rzeczy (IoT). Załaduj model specyficzny dla eICU z wymiarami wejściowymi i wyjściowymi zdefiniowanymi na podstawie zestawu danych. W celu sprawdzenia poprawności koncepcji wykorzystaliśmy model regresji logistycznej do trenowania i przewidywania śmiertelności pacjentów z domyślnymi konfiguracjami. Poniższy fragment kodu przedstawia aktualizacje, które wprowadziliśmy w main_fedavg.py scenariusz. Pamiętaj, że możesz także używać niestandardowych modeli PyTorch z FedML i importować je do main_fedavg.py skrypt.
Prowadź i monitoruj szkolenia FedML na AWS
Poniższy film przedstawia inicjowanie procesu szkolenia w każdym z klientów. Po wyświetleniu listy obu klientów dla serwera utwórz proces uczenia serwera, który przeprowadza federacyjną agregację modeli.
Aby skonfigurować serwer i klientów FL, wykonaj następujące kroki:
- Uruchom Klienta 1 i Klienta 2.
Aby uruchomić klienta, wprowadź następujące polecenie z odpowiednim identyfikatorem węzła. Na przykład, aby uruchomić Klienta 1 z identyfikatorem węzła 1, uruchom z wiersza poleceń:
- Po uruchomieniu obu instancji klienta uruchom instancję serwera, używając tego samego polecenia i odpowiedniego identyfikatora węzła zgodnie z konfiguracją w pliku
grpc_ipconfig.csv file. Możesz zobaczyć wagi modelu przekazywane do serwera z instancji klienta.
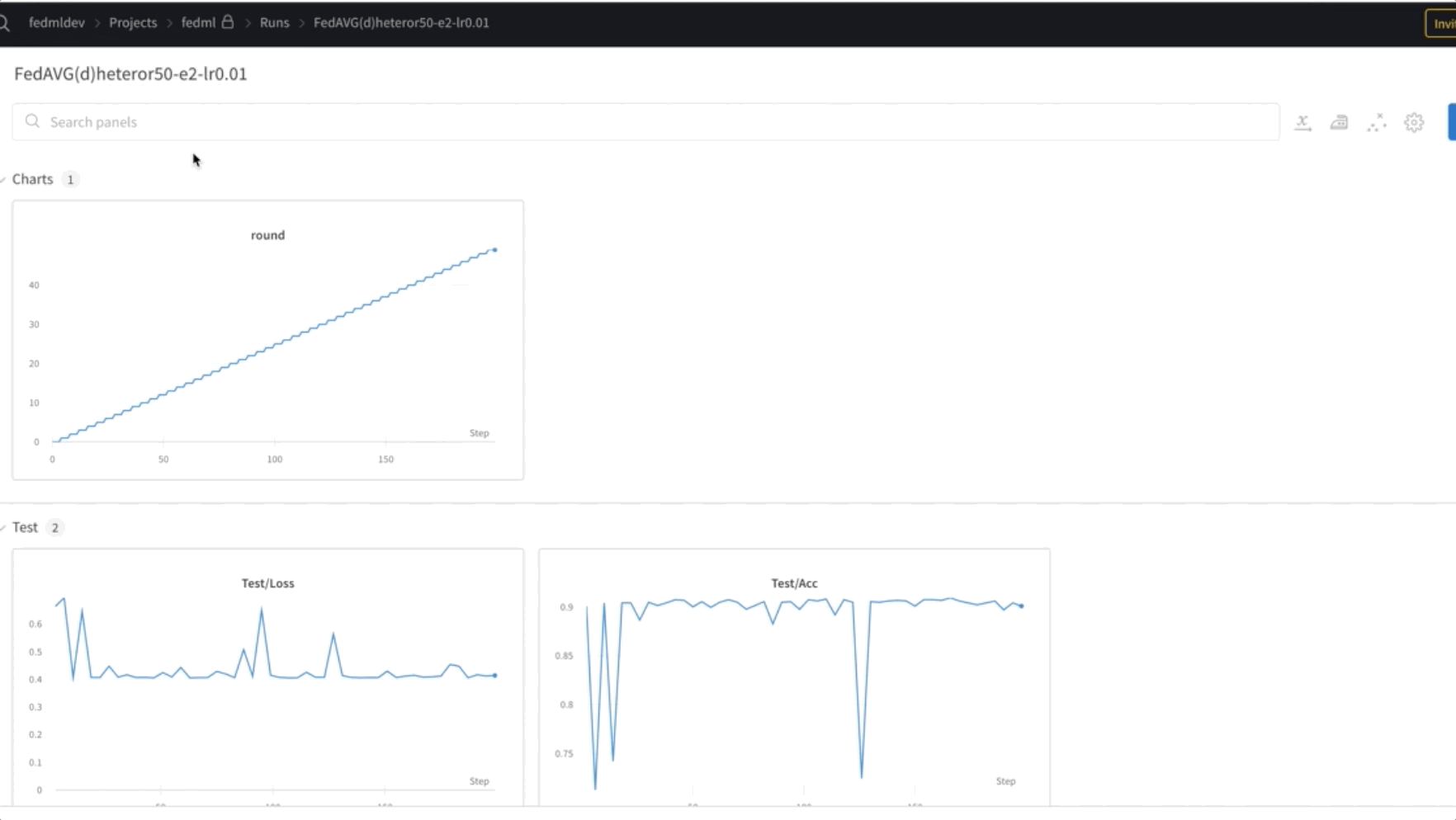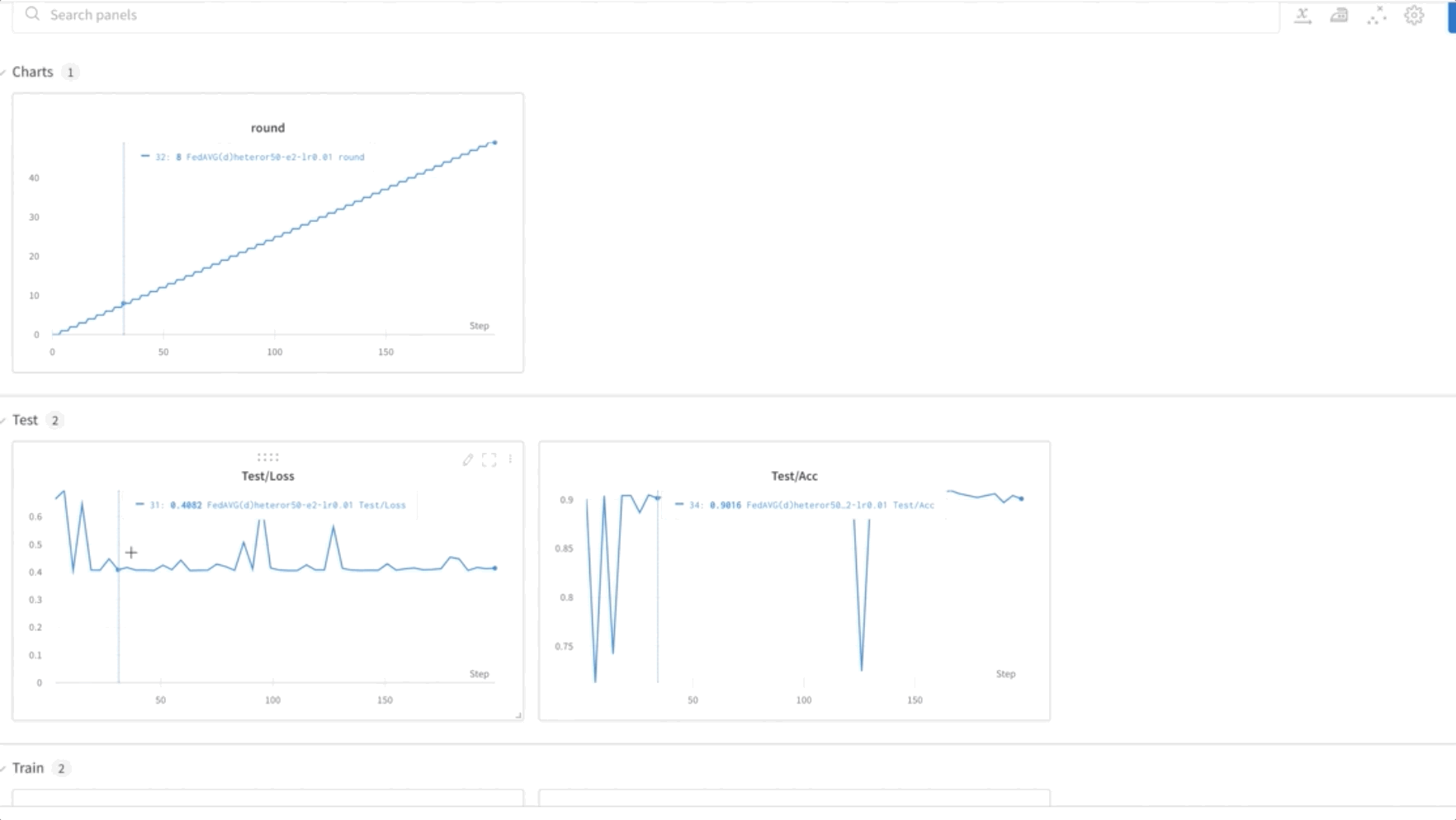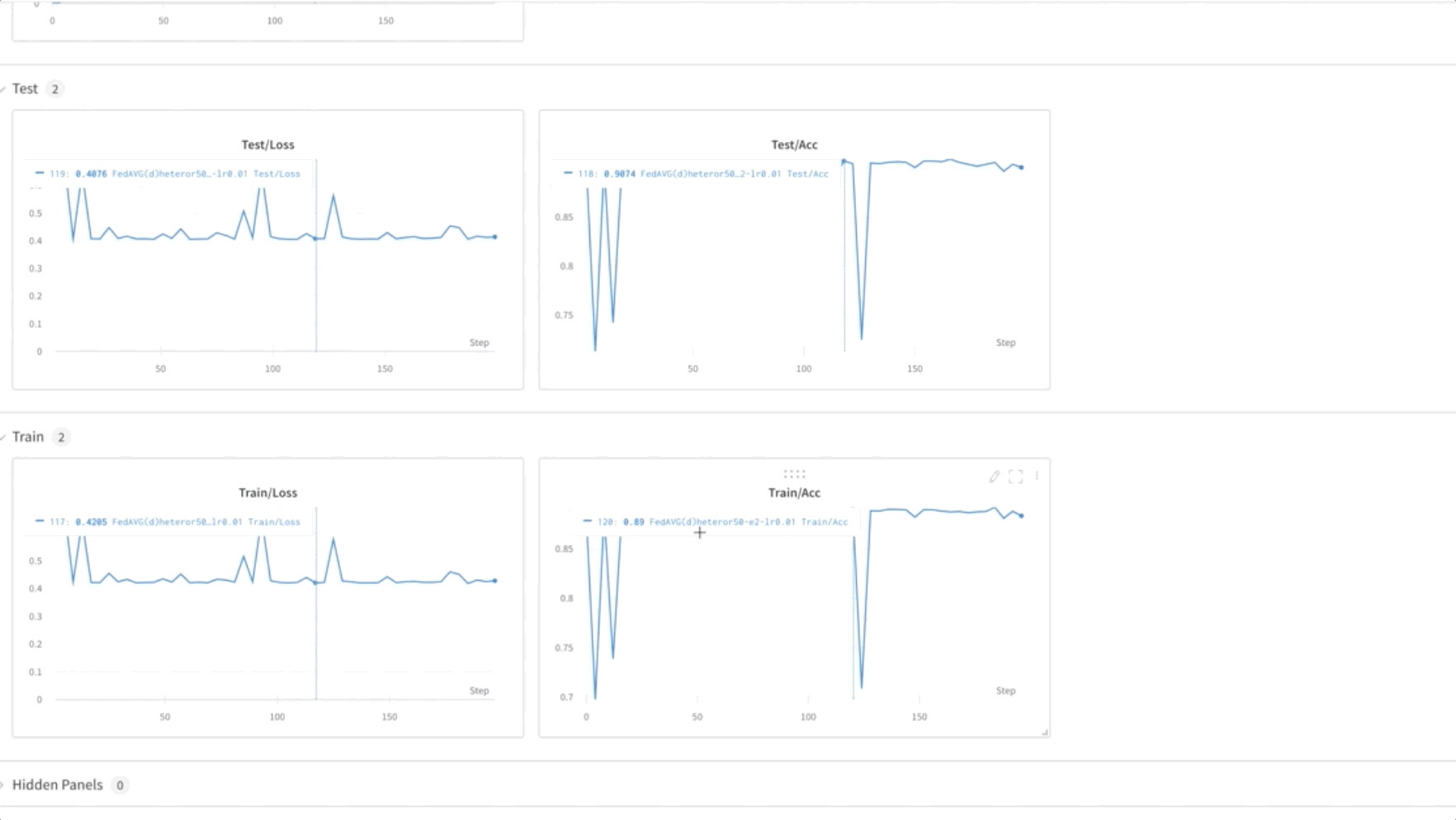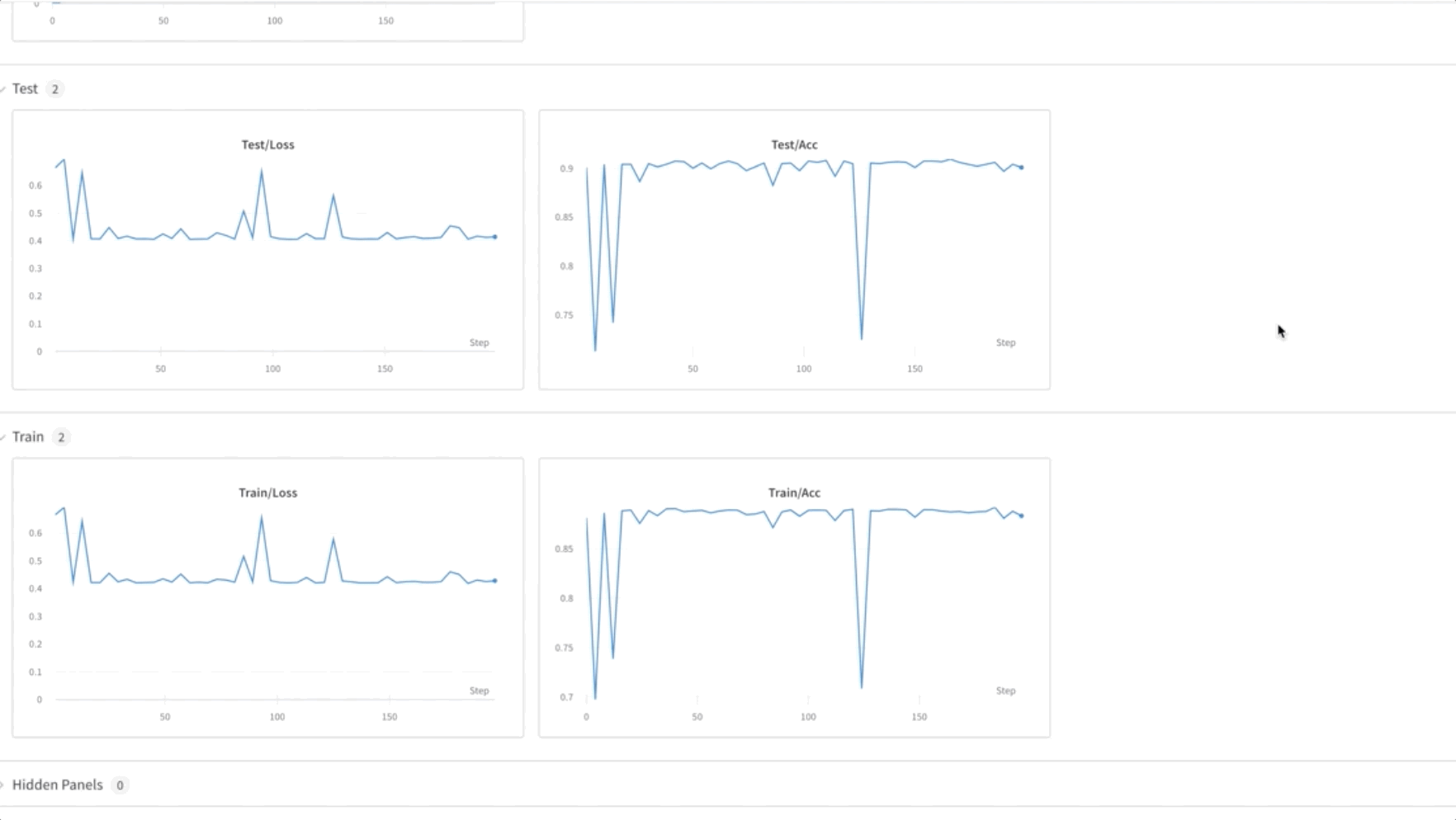
- Trenujemy model FL przez 50 epok. Jak widać na poniższym filmie, wagi są przenoszone między węzłami 0, 1 i 2, co wskazuje, że uczenie przebiega zgodnie z oczekiwaniami w sposób federacyjny.
- Na koniec monitoruj i śledź postęp szkolenia modelu FL w różnych węzłach w klastrze za pomocą wagi i uprzedzenia (wandb), jak pokazano na poniższym zrzucie ekranu. Wykonaj podane kroki tutaj zainstalować wandb i skonfigurować monitorowanie dla tego rozwiązania.
Poniższy film przedstawia wszystkie te kroki, aby zapewnić kompleksową demonstrację FL na AWS przy użyciu FedML:
Wnioski
W tym poście pokazaliśmy, jak można wdrożyć platformę FL opartą na open source FedML na AWS. Pozwala trenować model ML na rozproszonych danych, bez konieczności ich udostępniania lub przenoszenia. Stworzyliśmy architekturę wielokontową, w której w rzeczywistym scenariuszu szpitale lub organizacje opieki zdrowotnej mogą dołączyć do ekosystemu, aby czerpać korzyści ze wspólnego uczenia się przy jednoczesnym zachowaniu zarządzania danymi. Do przetestowania tego wdrożenia wykorzystaliśmy wieloszpitalny zestaw danych eICU. Ramy te można również zastosować do innych przypadków użycia i domen. Będziemy nadal rozszerzać tę pracę, automatyzując wdrażanie za pośrednictwem infrastruktury jako kodu (przy użyciu Tworzenie chmury AWS), dalsze włączenie mechanizmów chroniących prywatność oraz poprawa interpretowalności i rzetelności modeli FL.
Zapoznaj się z prezentacją pod adresem re:MARS 2022 skoncentrowaną na „Managed Federated Learning on AWS: studium przypadku dla służby zdrowia”, aby uzyskać szczegółowy opis tego rozwiązania.
Numer Referencyjny
[1] Pollard, Tom J. i in. „Baza danych eICU Collaborative Research Database, ogólnodostępna wieloośrodkowa baza danych do badań w zakresie opieki krytycznej”. Dane naukowe 5.1 (2018): 1-13.
[2] Yin, X., Zhu, Y. i Hu, J., 2021. Kompleksowe badanie federacyjnego uczenia się chroniącego prywatność: taksonomia, przegląd i przyszłe kierunki. Ankiety komputerowe ACM (CSUR), 54(6), pp.1-36.
[3] Sheikhaliszahi, Seyedmostafa, Vevake Balaraman i Venet Osmani. „Benchmarking modeli uczenia maszynowego na wieloośrodkowym zbiorze danych eICU”. Plos jeden 15.7 (2020): e0235424.
O autorach
 Widja Sagar Rawipati jest Menedżerem w Laboratorium rozwiązań Amazon ML, gdzie wykorzystuje swoje bogate doświadczenie w wielkoskalowych systemach rozproszonych i swoją pasję do uczenia maszynowego, aby pomóc klientom AWS z różnych branż w przyspieszeniu wdrażania sztucznej inteligencji i chmury. Wcześniej był inżynierem uczenia maszynowego w Connectivity Services w Amazon, który pomagał budować platformy do personalizacji i konserwacji predykcyjnej.
Widja Sagar Rawipati jest Menedżerem w Laboratorium rozwiązań Amazon ML, gdzie wykorzystuje swoje bogate doświadczenie w wielkoskalowych systemach rozproszonych i swoją pasję do uczenia maszynowego, aby pomóc klientom AWS z różnych branż w przyspieszeniu wdrażania sztucznej inteligencji i chmury. Wcześniej był inżynierem uczenia maszynowego w Connectivity Services w Amazon, który pomagał budować platformy do personalizacji i konserwacji predykcyjnej.
 Oliwia Choudhury, PhD, jest starszym architektem rozwiązań partnerskich w AWS. Pomaga partnerom w dziedzinie opieki zdrowotnej i nauk przyrodniczych projektować, rozwijać i skalować najnowocześniejsze rozwiązania wykorzystujące AWS. Ma doświadczenie w genomice, analityce opieki zdrowotnej, uczeniu federacyjnym i uczeniu maszynowym chroniącym prywatność. Poza pracą gra w planszówki, maluje pejzaże i kolekcjonuje mangi.
Oliwia Choudhury, PhD, jest starszym architektem rozwiązań partnerskich w AWS. Pomaga partnerom w dziedzinie opieki zdrowotnej i nauk przyrodniczych projektować, rozwijać i skalować najnowocześniejsze rozwiązania wykorzystujące AWS. Ma doświadczenie w genomice, analityce opieki zdrowotnej, uczeniu federacyjnym i uczeniu maszynowym chroniącym prywatność. Poza pracą gra w planszówki, maluje pejzaże i kolekcjonuje mangi.
 Wajahat Aziz jest głównym architektem rozwiązań Machine Learning i HPC w AWS, gdzie koncentruje się na pomaganiu klientom z sektora opieki zdrowotnej i nauk przyrodniczych w wykorzystaniu technologii AWS do opracowywania najnowocześniejszych rozwiązań ML i HPC dla szerokiej gamy zastosowań, takich jak opracowywanie leków, Badania kliniczne i uczenie maszynowe chroniące prywatność. Poza pracą Wajahat lubi odkrywać przyrodę, piesze wędrówki i czytać.
Wajahat Aziz jest głównym architektem rozwiązań Machine Learning i HPC w AWS, gdzie koncentruje się na pomaganiu klientom z sektora opieki zdrowotnej i nauk przyrodniczych w wykorzystaniu technologii AWS do opracowywania najnowocześniejszych rozwiązań ML i HPC dla szerokiej gamy zastosowań, takich jak opracowywanie leków, Badania kliniczne i uczenie maszynowe chroniące prywatność. Poza pracą Wajahat lubi odkrywać przyrodę, piesze wędrówki i czytać.
 Divya Bhargawi jest Data Scientist oraz pionową liderem ds. mediów i rozrywki w firmie Laboratorium rozwiązań Amazon ML, gdzie rozwiązuje problemy biznesowe o dużej wartości dla klientów AWS z wykorzystaniem uczenia maszynowego. Zajmuje się rozumieniem obrazu/wideo, systemami rekomendacji opartymi na grafach wiedzy, predykcyjnymi przypadkami użycia reklamy.
Divya Bhargawi jest Data Scientist oraz pionową liderem ds. mediów i rozrywki w firmie Laboratorium rozwiązań Amazon ML, gdzie rozwiązuje problemy biznesowe o dużej wartości dla klientów AWS z wykorzystaniem uczenia maszynowego. Zajmuje się rozumieniem obrazu/wideo, systemami rekomendacji opartymi na grafach wiedzy, predykcyjnymi przypadkami użycia reklamy.
 Ujjwal Ratan jest liderem AI/ML i Data Science w AWS Healthcare and Life Science Business Unit, a także jest głównym architektem rozwiązań AI/ML. Przez lata Ujjwal był liderem w branży opieki zdrowotnej i nauk przyrodniczych, pomagając wielu organizacjom z listy Global Fortune 500 osiągnąć ich cele w zakresie innowacji poprzez przyjęcie uczenia maszynowego. Jego praca obejmująca analizę obrazowania medycznego, nieustrukturyzowanego tekstu klinicznego i genomiki pomogła AWS zbudować produkty i usługi, które zapewniają wysoce spersonalizowaną i precyzyjnie ukierunkowaną diagnostykę i terapię. W wolnym czasie lubi słuchać (i grać) muzyki oraz odbywać nieplanowane wycieczki samochodowe z rodziną.
Ujjwal Ratan jest liderem AI/ML i Data Science w AWS Healthcare and Life Science Business Unit, a także jest głównym architektem rozwiązań AI/ML. Przez lata Ujjwal był liderem w branży opieki zdrowotnej i nauk przyrodniczych, pomagając wielu organizacjom z listy Global Fortune 500 osiągnąć ich cele w zakresie innowacji poprzez przyjęcie uczenia maszynowego. Jego praca obejmująca analizę obrazowania medycznego, nieustrukturyzowanego tekstu klinicznego i genomiki pomogła AWS zbudować produkty i usługi, które zapewniają wysoce spersonalizowaną i precyzyjnie ukierunkowaną diagnostykę i terapię. W wolnym czasie lubi słuchać (i grać) muzyki oraz odbywać nieplanowane wycieczki samochodowe z rodziną.
 Chaoyang He jest współzałożycielem i CTO FedML, Inc., startupu działającego na rzecz społeczności budującej otwartą i współpracującą sztuczną inteligencję z dowolnego miejsca i na dowolną skalę. Jego badania koncentrują się na rozproszonych/sfederowanych algorytmach, systemach i aplikacjach uczenia maszynowego. Uzyskał tytuł doktora. na kierunku Informatyka z kl University of Southern California, Los Angeles, USA.
Chaoyang He jest współzałożycielem i CTO FedML, Inc., startupu działającego na rzecz społeczności budującej otwartą i współpracującą sztuczną inteligencję z dowolnego miejsca i na dowolną skalę. Jego badania koncentrują się na rozproszonych/sfederowanych algorytmach, systemach i aplikacjach uczenia maszynowego. Uzyskał tytuł doktora. na kierunku Informatyka z kl University of Southern California, Los Angeles, USA.
 Salmana Avestimehra jest współzałożycielem i dyrektorem generalnym FedML, Inc., startupu działającego na rzecz społeczności budującej otwartą i współpracującą sztuczną inteligencję z dowolnego miejsca i na dowolną skalę. Salman Avestimehr jest światowej sławy ekspertem w dziedzinie uczenia się federacyjnego z ponad 20-letnim doświadczeniem jako lider w dziedzinie badań i rozwoju zarówno w środowisku akademickim, jak i przemysłowym. Jest profesorem dziekańskim i inauguracyjnym dyrektorem USC-Amazon Center on Trustworthy Machine Learning na University of Southern California. Był także Amazon Scholar w Amazon. Jest zdobywcą nagrody prezydenckiej Stanów Zjednoczonych za swój głęboki wkład w technologię informacyjną oraz członkiem IEEE.
Salmana Avestimehra jest współzałożycielem i dyrektorem generalnym FedML, Inc., startupu działającego na rzecz społeczności budującej otwartą i współpracującą sztuczną inteligencję z dowolnego miejsca i na dowolną skalę. Salman Avestimehr jest światowej sławy ekspertem w dziedzinie uczenia się federacyjnego z ponad 20-letnim doświadczeniem jako lider w dziedzinie badań i rozwoju zarówno w środowisku akademickim, jak i przemysłowym. Jest profesorem dziekańskim i inauguracyjnym dyrektorem USC-Amazon Center on Trustworthy Machine Learning na University of Southern California. Był także Amazon Scholar w Amazon. Jest zdobywcą nagrody prezydenckiej Stanów Zjednoczonych za swój głęboki wkład w technologię informacyjną oraz członkiem IEEE.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/part-2-federated-learning-on-aws-with-fedml-health-analytics-without-sharing-sensitive-data/
- 000
- 1
- 10
- 100
- 20 roku
- 2018
- 2020
- 2021
- 2022
- 28
- 7
- 9
- a
- O nas
- powyżej
- Akademia
- przyśpieszyć
- Akceptuj
- dostęp
- dostęp
- Konto
- odpowiedzialność
- Konta
- Osiągać
- w poprzek
- działać
- przystosować
- adres
- Przyznał
- przyjęty
- Przyjęcie
- Przyjęcie
- Reklama
- Po
- zbiór
- Agregator
- AI
- AI / ML
- Algorytmy
- Wszystkie kategorie
- pozwala
- Amazonka
- Amazon EC2
- analiza
- analityka
- w czasie rzeczywistym sprawiają,
- Analizując
- i
- Angeles
- Inne
- nigdzie
- aplikacje
- stosowany
- podejście
- właściwy
- architektura
- powiązany
- automatyzacja
- dostępny
- nagroda
- AWS
- Backend
- tło
- na podstawie
- bo
- zanim
- jest
- poniżej
- Benchmark
- korzyści
- pomiędzy
- Blokować
- Blog
- deska
- Gry planszowe
- Pudełko
- BP
- budować
- Budowanie
- wybudowany
- biznes
- California
- wezwanie
- przechwytuje
- który
- walizka
- studium przypadku
- Etui
- Centrum
- scentralizowane
- ceo
- wyzwania
- Zmiany
- wymiana pieniędzy
- wybór
- Dodaj
- wybrany
- klasa
- klasyfikacja
- klient
- klientów
- Kliniczne
- Badania kliniczne
- Chmura
- adopcja chmury
- Grupa
- Współzałożyciel
- kod
- Kohorta
- współpracy
- zbiera
- Kolumna
- kolumny
- śpiączka
- Komunikacja
- społeczność
- budowanie społeczności
- kompletny
- wszechstronny
- obliczać
- komputer
- Computer Science
- computing
- pojęcie
- Koncepcje
- systemu
- Skontaktuj się
- połączony
- połączenie
- Łączność
- za
- Konsola
- kontynuować
- składki
- przeliczone
- Odpowiedni
- Koszty:
- Stwórz
- stworzony
- tworzy
- Tworzenie
- krytyczny
- CTO
- zwyczaj
- Klientów
- dostosować
- dane
- dostęp do danych
- wyciek danych
- punkty danych
- prywatność danych
- nauka danych
- naukowiec danych
- udostępnianie danych
- Baza danych
- Zdecentralizowane
- decyzja
- głęboko
- głęboka nauka
- Domyślnie
- wykazać
- rozwijać
- Wdrożenie
- opisane
- Wnętrze
- miejsce przeznaczenia
- szczegółowe
- detale
- określaniu
- rozwijać
- rozwijanie
- oprogramowania
- Dialog
- różne
- trudny
- Wymiary
- bezpośrednio
- Dyrektor
- dystrybuowane
- przetwarzanie rozproszone
- systemy rozproszone
- 分配
- Nie
- robi
- domena
- domeny
- lek
- Rozwój leków
- podczas
- każdy
- Wcześniej
- Ekosystem
- efektywność
- wydajny
- umożliwiać
- włączony
- Umożliwia
- koniec końców
- inżynier
- zapewnić
- zapewnia
- Wchodzę
- rozrywka
- epoki
- Błędy
- zapewniają
- Eter (ETH)
- wydarzenia
- przykład
- Przede wszystkim system został opracowany
- spodziewany
- doświadczenie
- ekspert
- odkryj
- rozciągać się
- Oczy
- uczciwość
- członków Twojej rodziny
- Korzyści
- facet
- Postać
- filet
- Akta
- W końcu
- i terminów, a
- pływ
- Skupiać
- koncentruje
- koncentruje
- obserwuj
- następujący
- Majątek
- znaleziono
- Framework
- Darmowy
- od
- funkcjonować
- Funkcje
- dalej
- Ponadto
- przyszłość
- Games
- Płeć
- genomika
- gif
- Globalne
- Go
- Gole
- zarządzanie
- GPU
- wykres
- wykresy
- Zarządzanie
- Grupy
- wytyczne
- uchwyt
- Zdrowie
- ubezpieczenie zdrowotne
- opieki zdrowotnej
- Trzymany
- pomoc
- pomógł
- pomoc
- pomaga
- tutaj
- wysoko
- turystyka
- historia
- Szpital
- szpitale
- hostowane
- GODZINY
- W jaki sposób
- HPC
- HTML
- HTTPS
- idealny
- IEEE
- obraz
- Obrazowanie
- brak równowagi
- wdrożenia
- importować
- podnieść
- poprawy
- in
- Inauguracyjny
- Inc
- obejmuje
- włączenie
- wskaźnik
- przemysł
- Informacja
- Infrastruktura
- Innowacja
- wkład
- zainstalować
- przykład
- ubezpieczenie
- Interfejs
- Internet
- Internet przedmiotów
- Internet przedmiotów
- IT
- przystąpić
- Klawisz
- wiedza
- Etykiety
- laboratorium
- Brak
- na dużą skalę
- uruchomić
- prowadzić
- lider
- Przywództwo
- nauka
- Długość
- Dźwignia
- wykorzystuje
- lewarowanie
- życie
- Life Science
- Life Sciences
- Linia
- Lista
- Katalogowany
- Słuchanie
- załadować
- ładowarka
- masa
- miejscowy
- lokalnie
- usytuowany
- długo
- im
- Los Angeles
- od
- maszyna
- uczenie maszynowe
- zrobiony
- utrzymać
- konserwacja
- robić
- WYKONUJE
- zarządzanie
- kierownik
- sposób
- mapowanie
- marzec
- znaczy
- Pomiary
- Media
- medyczny
- obrazowanie medyczne
- Poznaj nasz
- wzmiankowany
- metoda
- metody
- MIT
- Złagodzić
- ML
- Algorytmy ML
- model
- modele
- monitor
- monitorowanie
- jeszcze
- Silnik
- ruch
- przeniesienie
- wielokrotność
- Muzyka
- Nazwa
- Natura
- Nawigacja
- Potrzebować
- potrzebne
- wymagania
- ujemny
- sieć
- węzeł
- węzły
- numer
- tępy
- ONE
- koncepcja
- open source
- operacje
- Optymalny
- organizacji
- Inne
- zewnętrzne
- własny
- własność
- właściciel
- chleb
- parametry
- część
- partnerem
- wzmacniacz
- minęło
- pasja
- ścieżka
- pacjent
- pacjenci
- par
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- wykonuje
- personalizacja
- Personalizowany
- rurociąg
- Miejsce
- krok po kroku
- Platformy
- plato
- Analiza danych Platona
- PlatoDane
- gra
- Proszę
- punkt
- zwrotnica
- stwarza
- pozytywny
- Post
- Praktyczny
- precyzyjnie
- przewidzieć
- przewidywanie
- przepowiednia
- teraźniejszość
- presentation
- prezydencki
- nacisk
- zapobiec
- poprzednio
- Główny
- prywatność
- prywatny
- Problem
- problemy
- wygląda tak
- Produkcja
- Produkty
- Produkty i usługi
- Profesor
- postępuje
- progresja
- zakazać
- projekt
- dowód
- dowód koncepcji
- zaproponować
- zapewniać
- zapewnia
- że
- publicznie
- cel
- płomień
- R & D
- przypadkowy
- RZADKO SPOTYKANY
- Kurs
- stosunek
- RE
- Czytający
- gotowy
- Prawdziwy świat
- Odebrane
- Rekomendacja
- rekord
- nagrany
- dokumentacja
- region
- regresja
- regulowane
- regulacyjne
- usunąć
- składnica
- reprezentuje
- zażądać
- wymagać
- wymaganie
- wymagania
- Wymaga
- Badania naukowe
- osób
- powrót
- powraca
- przeglądu
- droga
- w przybliżeniu
- Trasa
- RZĄD
- reguły
- run
- bieganie
- taki sam
- Skala
- nauka
- NAUKI
- Naukowiec
- skrypty
- płynnie
- druga
- bezpieczeństwo
- Szukajcie
- wybrany
- SAMEGO SIEBIE
- senior
- wrażliwy
- Serie
- Usługi
- zestaw
- Zestawy
- ustawienie
- ustawienie
- siedem
- kilka
- Share
- shared
- dzielenie
- pokazane
- Targi
- znak
- znaki
- podobny
- Podobnie
- pojedynczy
- witryna internetowa
- Witryny
- So
- rozwiązanie
- Rozwiązania
- Rozwiązuje
- Źródło
- Południowy
- rozpiętości
- specyficzny
- dzielić
- stabilny
- standard
- początek
- rozpoczęty
- startup
- state-of-the-art
- Zjednoczone
- Rynek
- pobyt
- Cel
- przechowywanie
- zbudowany
- dane ustrukturyzowane i nieustrukturyzowane
- Badanie
- styl
- podsieci
- taki
- wystarczający
- wsparcie
- podpory
- Badanie
- system
- systemy
- stół
- TAG
- biorąc
- cel
- ukierunkowane
- Zadanie
- taksonomia
- Technologies
- Technologia
- szablon
- test
- Połączenia
- ich
- lecznictwo
- rzeczy
- Trzeci
- myśl
- trzy
- Przez
- poprzez
- czas
- Szereg czasowy
- czasochłonne
- do
- narzędzie
- narzędzia
- pochodnia
- Pochodnia
- Kwota produktów:
- śledzić
- ruch drogowy
- Pociąg
- Trening
- przeniesione
- Próby
- godny zaufania
- typy
- zazwyczaj
- zasadniczy
- zrozumienie
- wyjątkowy
- jednostka
- Zjednoczony
- United States
- jednostek
- uniwersytet
- University of Southern California
- Aktualizacja
- Nowości
- us
- USA
- posługiwać się
- przypadek użycia
- wartość
- Wartości
- różnorodność
- różnorodny
- Naprawiono
- pionowe
- przez
- Wideo
- Wirtualny
- widoczny
- istotny
- solucja
- który
- Podczas
- KIM
- szeroki
- będzie
- w ciągu
- bez
- Praca
- działa
- światowej sławy
- X
- lat
- Twój
- zefirnet