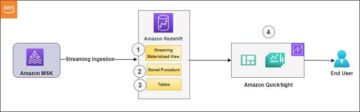
Obecnie setki tysięcy klientów korzysta z jezior danych do analiz i uczenia maszynowego. Jednak inżynierowie danych muszą oczyścić i przygotować te dane, zanim będzie można ich użyć. Bazowe dane muszą być dokładne i aktualne, aby klient mógł podejmować pewne decyzje biznesowe. W przeciwnym razie konsumenci danych tracą zaufanie do danych i podejmują nieoptymalne lub błędne decyzje. Częstym zadaniem inżynierów danych jest ocena, czy dane są dokładne i aktualne, czy nie. Obecnie istnieją różne narzędzia do jakości danych. Jednak popularne narzędzia do zapewniania jakości danych zwykle wymagają ręcznych procesów monitorowania jakości danych.
AWS Glue Data Quality to funkcja podglądu Klej AWS która mierzy i monitoruje jakość danych Usługa Amazon Simple Storage (Amazon S3) oraz w zadaniach wyodrębniania, przekształcania i ładowania AWS Glue (ETL). Jest to funkcja otwartego podglądu, więc jest już włączona na Twoim koncie w dostępne regiony. Możesz łatwo zdefiniować i zmierzyć kontrole jakości danych w konsoli AWS Glue Studio bez pisania kodów. Upraszcza zarządzanie jakością danych.
Ten post jest częścią 2 z serii czterech postów wyjaśniających, jak działa AWS Glue Data Quality. Sprawdź poprzedni wpis z tej serii:
W tym poście pokazujemy, jak utworzyć zadanie AWS Glue, które mierzy i monitoruje jakość danych w potoku danych. Pokazujemy również, jak podjąć działania w oparciu o wyniki jakości danych.
Omówienie rozwiązania
Rozważmy przykładowy przypadek użycia, w którym inżynier danych musi zbudować potok danych w celu pozyskania danych ze strefy surowej do strefy nadzorowanej w jeziorze danych. Jednym z Twoich kluczowych obowiązków jako inżyniera danych — obok wyodrębniania, przekształcania i ładowania danych — jest sprawdzanie jakości danych. Zidentyfikowanie problemów z jakością danych z wyprzedzeniem pomaga zapobiegać umieszczaniu złych danych w nadzorowanej strefie i uniknąć uciążliwych incydentów związanych z uszkodzeniem danych.
W tym poście dowiesz się, jak łatwo skonfigurować wbudowany i zwyczaj sprawdzanie poprawności danych w zadaniu AWS Glue, aby zapobiec uszkodzeniu przez złe dane dalszych danych o wysokiej jakości.
Zbiór danych użyty w tym poście jest generowany syntetycznie; Poniższy zrzut ekranu pokazuje przykład danych.

Skonfiguruj zasoby za pomocą AWS CloudFormation
Ten post zawiera m.in Tworzenie chmury AWS szablon do szybkiej konfiguracji. Możesz go przejrzeć i dostosować do swoich potrzeb.
Szablon CloudFormation generuje następujące zasoby:
- Zasobnik Amazon Simple Storage Service (Amazon S3) (
gluedataqualitystudio-*). - Następujące prefiksy i obiekty w zasobniku S3:
datalake/raw/customer/customer.csvdatalake/curated/customer/scripts/sparkHistoryLogs/temporary/
- AWS Zarządzanie tożsamością i dostępem (IAM) użytkowników, ról i zasad. rola IAM (
GlueDataQualityStudio-*) ma uprawnienia do odczytu i zapisu z zasobnika S3. - AWS Lambda funkcje i zasady IAM wymagane przez te funkcje do tworzenia i usuwania tego stosu.
Aby utworzyć zasoby, wykonaj następujące czynności:
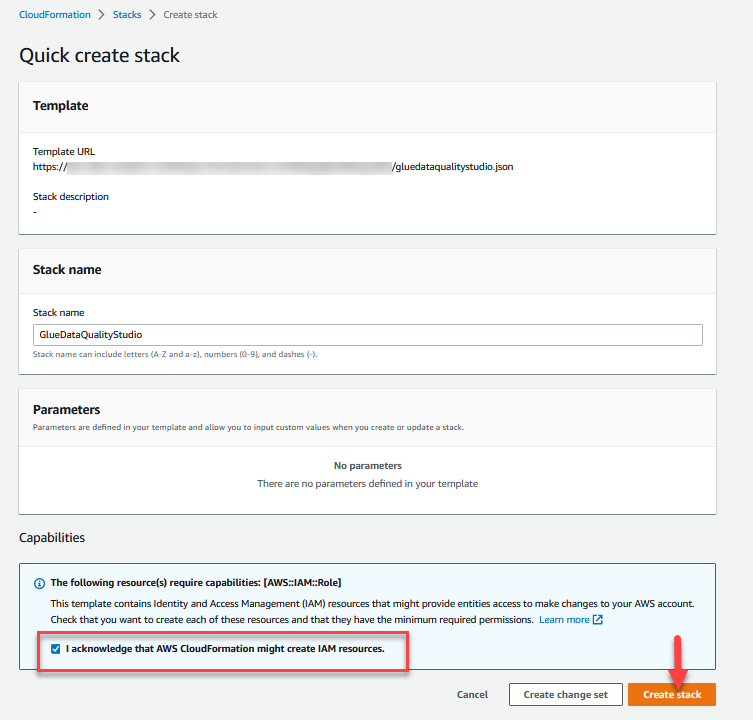
- Zaloguj się do Konsola AWS CloudFormation
us-east-1Region. - Dodaj Uruchom stos:

- Wybierz Przyjmuję do wiadomości, że AWS CloudFormation może tworzyć zasoby IAM.
- Dodaj Utwórz stos i poczekaj na zakończenie etapu tworzenia stosu.
Zaimplementuj rozwiązanie
Aby rozpocząć konfigurowanie rozwiązania, wykonaj następujące kroki:
- Na Konsola AWS Glue Studiowybierz Oferty pracy w okienku nawigacji.
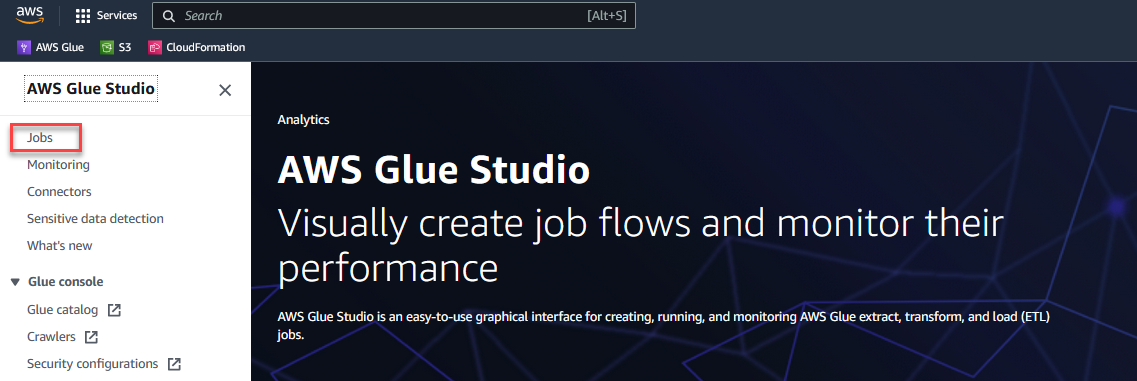
- Wybierz Wizualne z pustym płótnem i wybierz Stwórz.
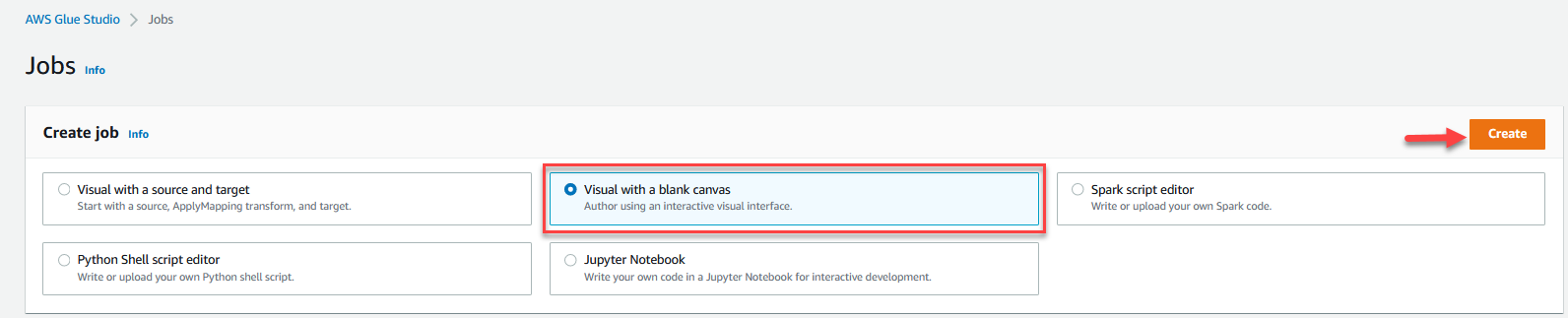
- Wybierz szczegóły pracy kartę, aby skonfigurować zadanie.
- W razie zamówieenia projektu Imię, wchodzić
GlueDataQualityStudio. - W razie zamówieenia projektu Rola uprawnień, wybierz rolę zaczynającą się od
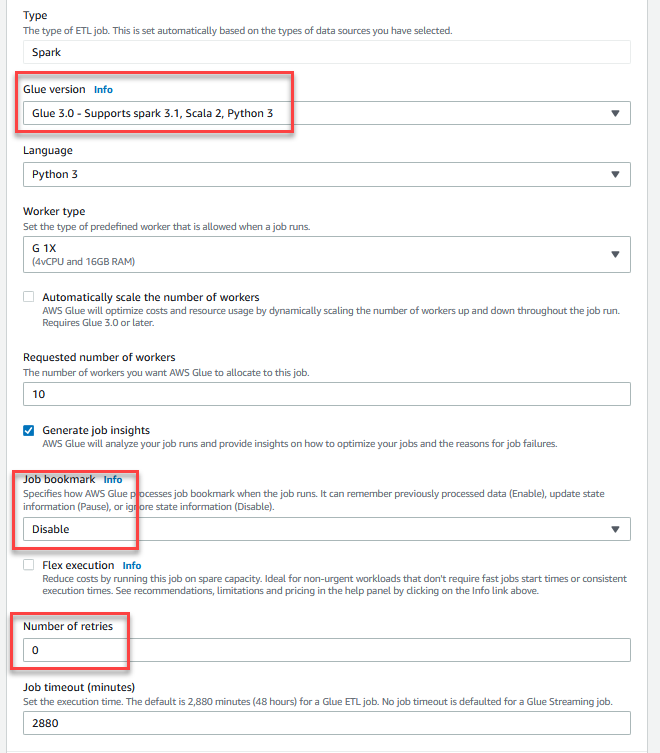
GlueDataQualityStudio-*. - W razie zamówieenia projektu Wersja klejuwybierz Klej 3.0.
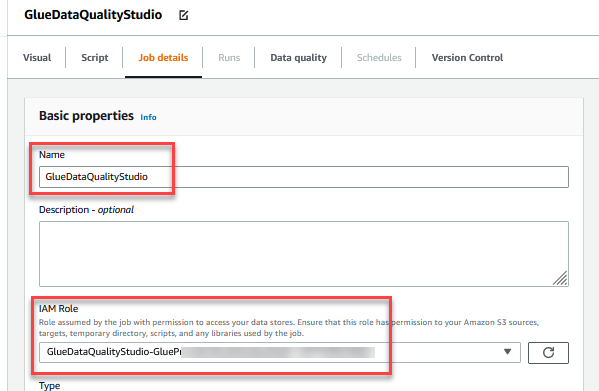
- W razie zamówieenia projektu Zakładka pracywybierz Wyłącz. Pozwala to na wielokrotne uruchamianie tego zadania z tym samym wejściowym zestawem danych.
- W razie zamówieenia projektu Liczba ponownych prób, wchodzić
0.
- W Zaawansowane właściwości sekcji, podaj wiadro S3 utworzone przez szablon CloudFormation (począwszy od
gluedataqualitystudio-*).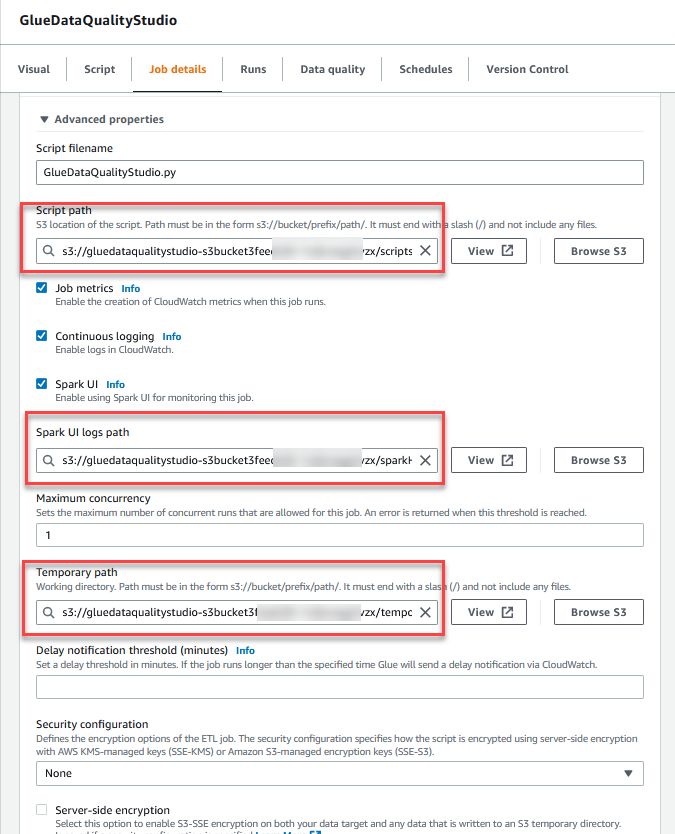
- Dodaj Zapisz.
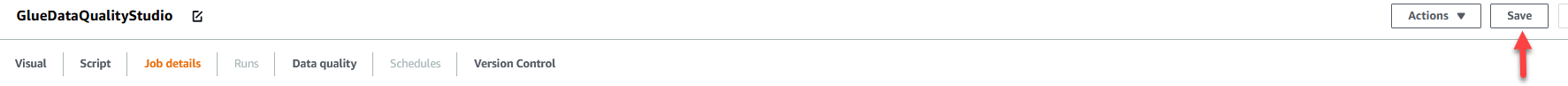
- Po zapisaniu pracy wybierz Wizualny zakładka i na Źródło menu, wybierz Amazon S3.
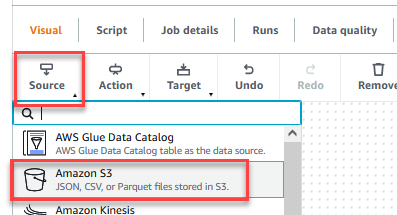
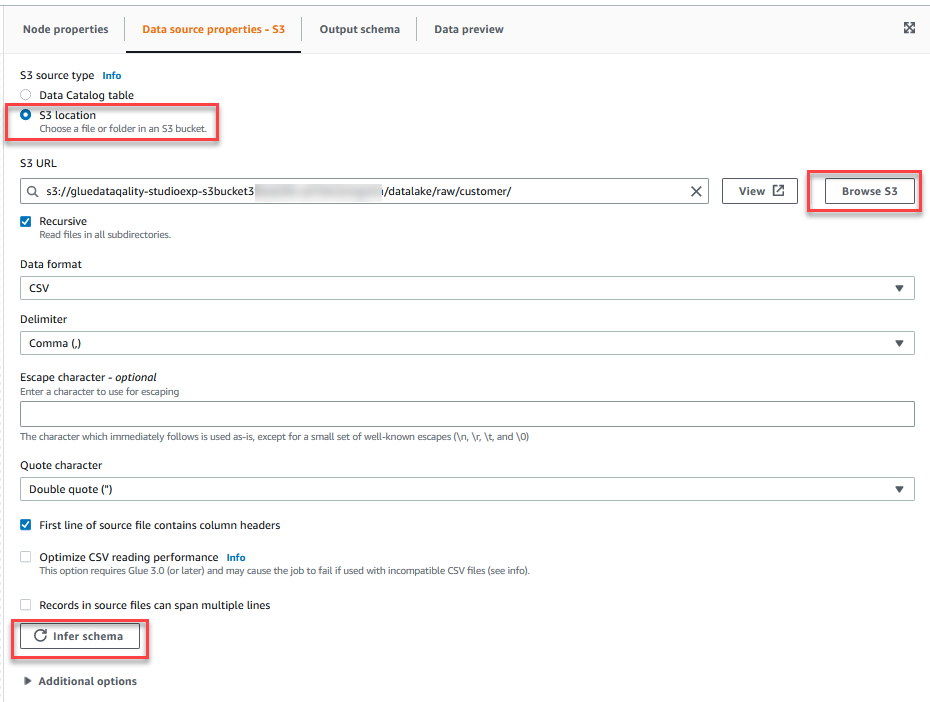
- Na Właściwości źródła danych - S3 tab, dla Typ źródła S3, Wybierz Lokalizacja S3.
- Dodaj Przeglądaj S3 i przejdź do prefiksu
/datalake/raw/customer/w zasobniku S3 zaczynającym się odgluedataqualitystudio-*. - Dodaj Wywnioskować schemat.
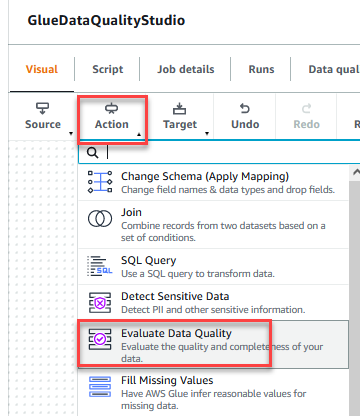
- Na Działania menu, wybierz Oceń jakość danych.
- Wybierz Oceń jakość danych węzeł.
Na Przekształcać możesz teraz rozpocząć budowanie reguł jakości danych. Pierwszą regułą, którą tworzysz, jest sprawdzenie, czyCustomer_IDjest unikalny i nie ma wartości null przy użyciu metodyisPrimaryKeyreguła. - Na Typy reguł zakładka Konstruktor reguł DQDL, Szukaj
isprimarykeyi wybierz znak plus.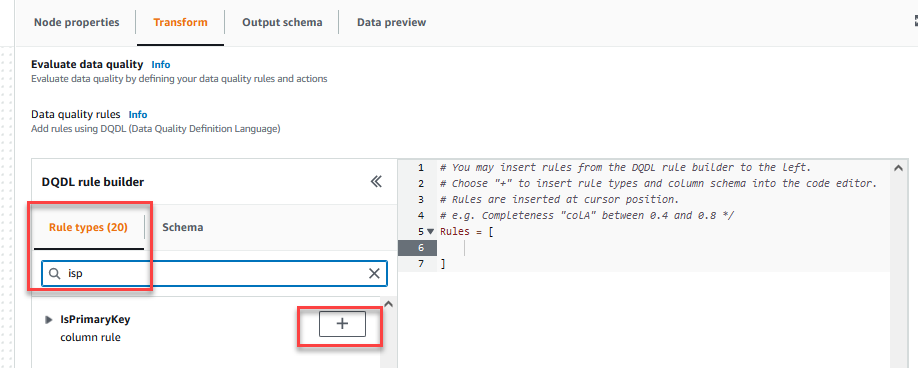
- Na schemat zakładka Konstruktor reguł DQDL, wybierz znak plus obok
Customer_ID. - Usuń w edytorze reguł
id.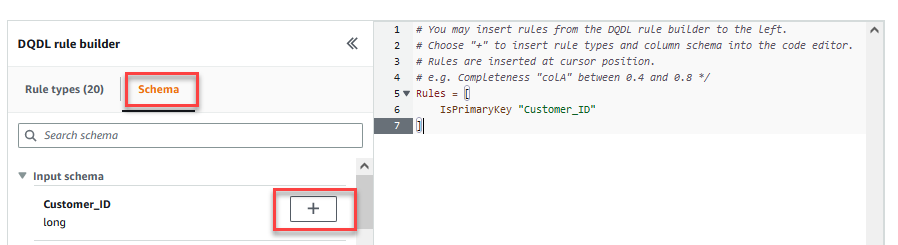
Następna reguła, którą dodamy, sprawdza, czyFirst_Namewartość kolumny jest obecna dla wszystkich wierszy. - Możesz również wprowadzić reguły jakości danych bezpośrednio w edytorze reguł. Dodaj przecinek (,) i wprowadź
IsComplete "First_Name",po pierwszej regule.
Następnie dodajesz regułę niestandardową, aby sprawdzić, czy nie istnieje żaden wiersz bez niejTelephoneorEmail. - Wprowadź następującą regułę niestandardową w edytorze reguł:

Funkcja Oceń jakość danych umożliwia zarządzanie wynikami zadania na podstawie wyników jakości zadania. - W przypadku tego posta wybierz Niepowodzenie zadania, gdy jakość danych zawiedzie i wybierz Niepowodzenie zadania bez ładowania celu dane działania. w Ustawienie wyjścia jakości danych Sekcja, wybierz Przeglądaj S3 i przejdź do prefiksu
dqresultsw zasobniku S3 zaczynającym się odgluedataqualitystudio-*.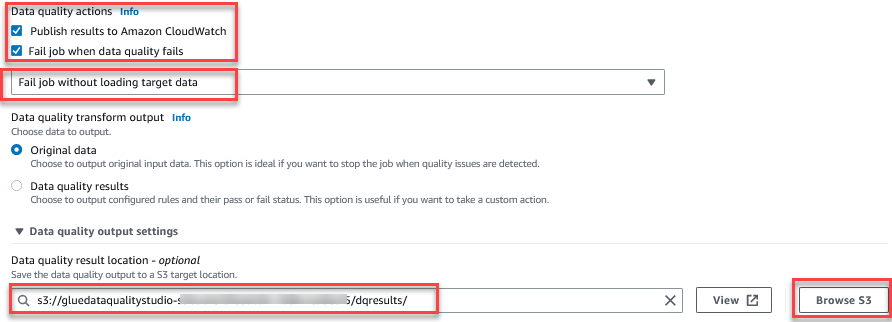
- Na cel menu, wybierz Amazon S3.
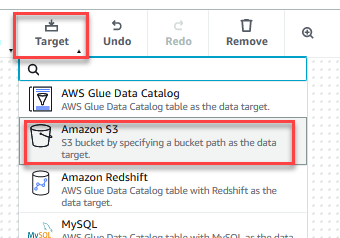
- Wybierz Cel danych – wiadro S3 węzeł.
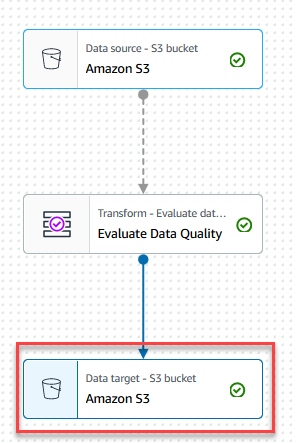
- Na Właściwości celu danych - S3 tab, dla utworzonywybierz Parkiet, A na Rodzaj kompresjiwybierz Żwawy.
- W razie zamówieenia projektu Lokalizacja docelowa S3wybierz Przeglądaj S3 i przejdź do prefiksu
/datalake/curated/customer/w zasobniku S3 zaczynającym się odgluedataqualitystudio-*.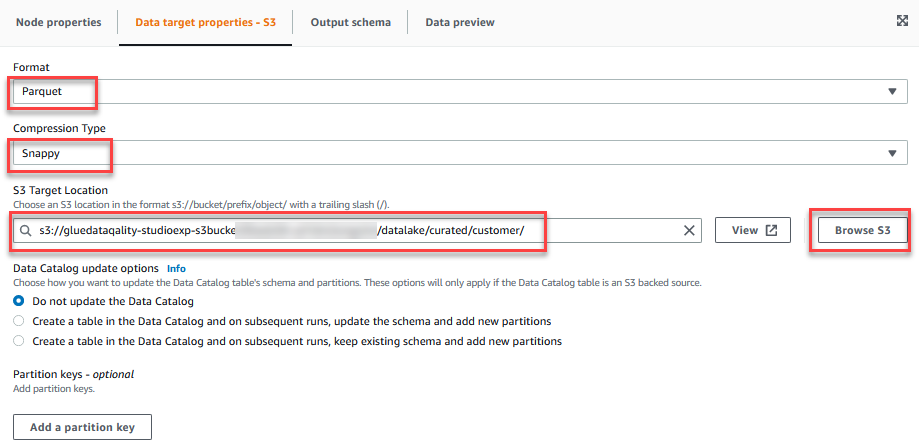
- Dodaj Zapisz, A następnie wybierz run.
 Szczegóły uruchomienia zadania można wyświetlić na karcie Uruchomienia. W naszym przykładzie zadanie kończy się niepowodzeniem z komunikatem o błędzie „AssertionError: Zadanie nie powiodło się z powodu niepowodzenia reguł DQ dla węzła: ”.
Szczegóły uruchomienia zadania można wyświetlić na karcie Uruchomienia. W naszym przykładzie zadanie kończy się niepowodzeniem z komunikatem o błędzie „AssertionError: Zadanie nie powiodło się z powodu niepowodzenia reguł DQ dla węzła: ”.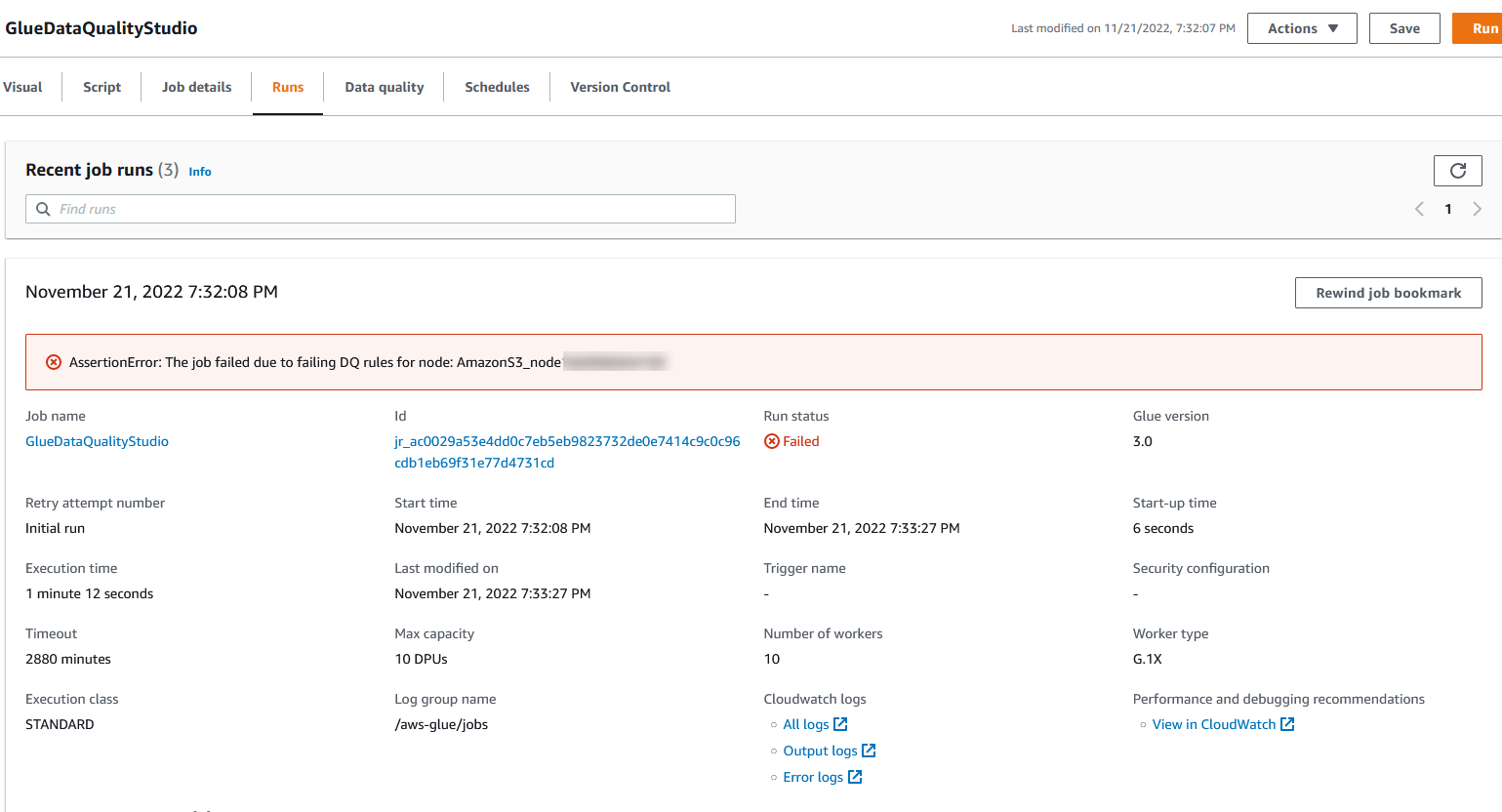 Wynik jakości danych można przejrzeć na karcie Jakość danych. W naszym przykładzie niestandardowa weryfikacja jakości danych nie powiodła się, ponieważ jeden z wierszy w zbiorze danych nie zawierał
Wynik jakości danych można przejrzeć na karcie Jakość danych. W naszym przykładzie niestandardowa weryfikacja jakości danych nie powiodła się, ponieważ jeden z wierszy w zbiorze danych nie zawierał TelephoneorEmailwartość. Wyniki oceny jakości danych są również zapisywane w zasobniku S3 w formacie JSON na podstawie parametru lokalizacji wyniku jakości danych węzła.
Wyniki oceny jakości danych są również zapisywane w zasobniku S3 w formacie JSON na podstawie parametru lokalizacji wyniku jakości danych węzła. - Nawigować do
dqresultsprzedrostek pod początkiem wiadra S3gluedataqualitystudio-*. Zobaczysz, że wynik jakości danych jest podzielony według daty.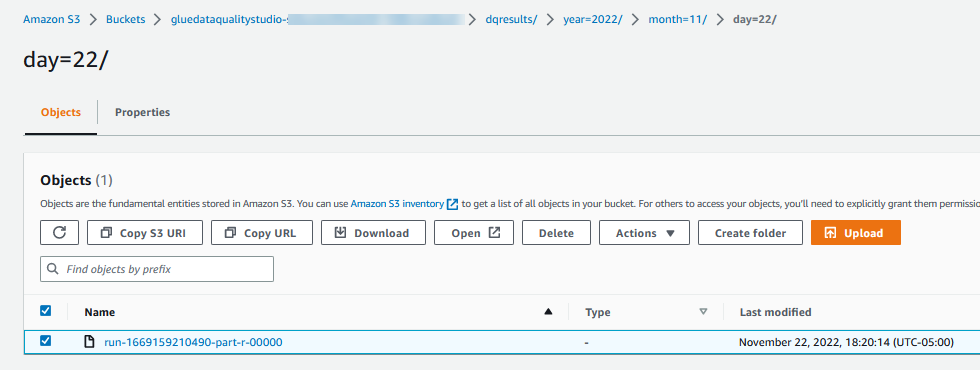
Poniżej przedstawiono dane wyjściowe pliku JSON. Możesz użyć tego pliku wyjściowego do tworzenia niestandardowych pulpitów nawigacyjnych wizualizacji jakości danych.

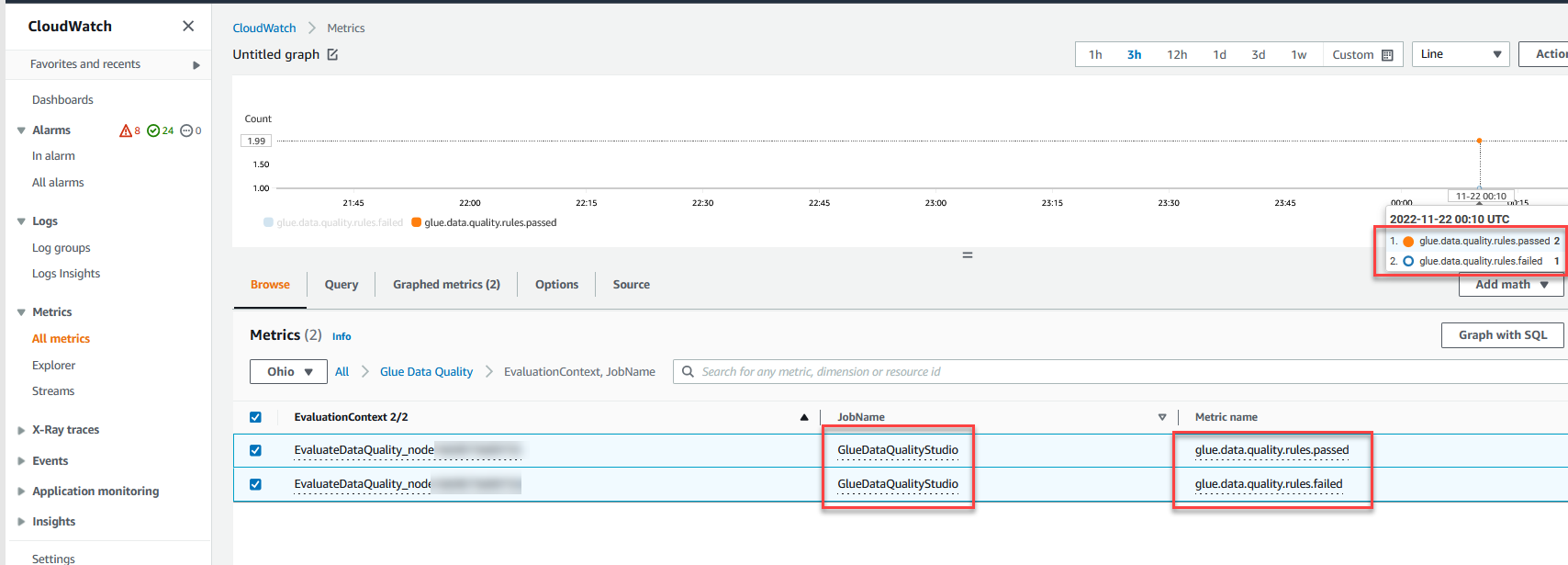
Możesz także monitorować Oceń jakość danych węzeł przez Amazon Cloud Watch metryki i ustawiaj alarmy, aby wysyłać powiadomienia o wynikach jakości danych. Aby dowiedzieć się więcej o konfigurowaniu alarmów CloudWatch, zobacz Korzystanie z alarmów Amazon CloudWatch.
Sprzątać
Aby uniknąć naliczania przyszłych opłat oraz wyczyścić nieużywane role i zasady, usuń utworzone przez siebie zasoby:
- usunąć
GlueDataQualityStudiopraca, którą utworzyłeś w ramach tego posta. - W konsoli AWS CloudFormation usuń plik
GlueDataQualityStudiostos.
Wnioski
AWS Glue Data Quality oferuje łatwy sposób mierzenia i monitorowania jakości danych w potoku ETL. W tym poście nauczyłeś się, jak podejmować niezbędne działania na podstawie wyników jakości danych, co pomaga zachować wysokie standardy danych i podejmować pewne decyzje biznesowe.
Aby dowiedzieć się więcej o jakości danych AWS Glue, zapoznaj się z dokumentacją:
O autorach
 Deenbandhu Prasad jest starszym specjalistą ds. analityki w AWS, specjalizującym się w usługach big data. Z pasją pomaga klientom budować nowoczesną architekturę danych w AWS Cloud. Pomagał klientom różnej wielkości wdrażać rozwiązania do zarządzania danymi, hurtowni danych i jezior danych.
Deenbandhu Prasad jest starszym specjalistą ds. analityki w AWS, specjalizującym się w usługach big data. Z pasją pomaga klientom budować nowoczesną architekturę danych w AWS Cloud. Pomagał klientom różnej wielkości wdrażać rozwiązania do zarządzania danymi, hurtowni danych i jezior danych.
 Yannisa Mentekidisa jest starszym inżynierem rozwoju oprogramowania w zespole AWS Glue.
Yannisa Mentekidisa jest starszym inżynierem rozwoju oprogramowania w zespole AWS Glue.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/getting-started-with-aws-glue-data-quality-for-etl-pipelines/
- 1
- 100
- 7
- a
- O nas
- dostęp
- Konto
- dokładny
- uznać
- Działania
- działania
- Po
- Wszystkie kategorie
- pozwala
- już
- Amazonka
- analityka
- i
- architektura
- AWS
- Tworzenie chmury AWS
- Klej AWS
- Łazienka
- złe dane
- na podstawie
- bo
- zanim
- Duży
- Big Data
- budować
- Budowanie
- biznes
- walizka
- Opłaty
- ZOBACZ
- Wykrywanie urządzeń szpiegujących
- Dodaj
- Chmura
- Kolumna
- wspólny
- kompletny
- pewność
- Rozważać
- Konsola
- Konsumenci
- Korupcja
- Stwórz
- stworzony
- tworzenie
- kurator
- zwyczaj
- klient
- Klientów
- dostosować
- dane
- Jezioro danych
- zarządzanie danymi
- Data
- Decyzje
- detale
- oprogramowania
- bezpośrednio
- dokumentacja
- z łatwością
- redaktor
- inżynier
- Inżynierowie
- Wchodzę
- błąd
- Eter (ETH)
- oceniać
- przykład
- istnieje
- doświadczenie
- Wyjaśniać
- wyciąg
- Failed
- nie
- Cecha
- filet
- i terminów, a
- następujący
- format
- od
- Funkcje
- przyszłość
- wygenerowane
- generuje
- miejsce
- pomógł
- pomoc
- pomaga
- Wysoki
- wysokiej jakości
- W jaki sposób
- How To
- Jednak
- HTML
- HTTPS
- Setki
- identyfikacja
- tożsamość
- wdrożenia
- in
- obejmuje
- wkład
- problemy
- IT
- Praca
- Oferty pracy
- json
- Klawisz
- jezioro
- UCZYĆ SIĘ
- dowiedziałem
- nauka
- załadować
- załadunek
- lokalizacja
- stracić
- maszyna
- uczenie maszynowe
- utrzymać
- robić
- zarządzanie
- i konserwacjami
- zarządzający
- podręcznik
- zmierzyć
- środków
- Menu
- wiadomość
- Metryka
- może
- Nowoczesne technologie
- monitor
- monitory
- jeszcze
- wielokrotność
- Nawigacja
- Nawigacja
- niezbędny
- wymagania
- Następny
- węzeł
- Powiadomienia
- obiekty
- Oferty
- ONE
- koncepcja
- Inaczej
- chleb
- parametr
- część
- namiętny
- pozwolenie
- rurociąg
- wprowadzanie
- plato
- Analiza danych Platona
- PlatoDane
- plus
- polityka
- Post
- Przygotować
- teraźniejszość
- zapobiec
- Podgląd
- poprzedni
- pierwotny
- procesów
- niska zabudowa
- zapewniać
- zapewnia
- jakość
- Szybki
- Surowy
- Czytaj
- niedawny
- region
- wymagać
- wymagany
- Zasoby
- dalsze
- Efekt
- przeglądu
- Rola
- role
- RZĄD
- Zasada
- reguły
- run
- taki sam
- Szukaj
- Sekcja
- Serie
- usługa
- Usługi
- zestaw
- ustawienie
- ustawienie
- pokazać
- Targi
- znak
- Prosty
- rozmiary
- So
- Tworzenie
- rozwoju oprogramowania
- rozwiązanie
- Rozwiązania
- Źródło
- specjalista
- specjalizujący się
- stos
- standardy
- początek
- rozpoczęty
- Startowy
- Ewolucja krok po kroku
- Cel
- przechowywanie
- studio
- Garnitur
- syntetycznie
- Brać
- cel
- Zadanie
- zespół
- szablon
- Połączenia
- tysiące
- Przez
- czasy
- do
- już dziś
- narzędzia
- Przekształcać
- transformatorowy
- Zaufaj
- dla
- zasadniczy
- wyjątkowy
- nieużywana
- posługiwać się
- przypadek użycia
- Użytkownicy
- zazwyczaj
- UPRAWOMOCNIĆ
- uprawomocnienie
- wartość
- różnorodny
- Zobacz i wysłuchaj
- wyobrażanie sobie
- czekać
- czy
- który
- będzie
- bez
- działa
- napisać
- pisanie
- napisany
- Twój
- zefirnet