Ten artykuł został opublikowany jako część Blogathon Data Science
Wprowadzenie
Cześć wszystkim! Chociaż cyberpunk nie wkroczył jeszcze tak bardzo w nasze życie, a interfejsy neuro są dalekie od ideału, LiDAR może stać się pierwszym etapem na drodze do przyszłości manipulatorów. Dlatego, aby nie nudzić się podczas wakacji, postanowiłem trochę pofantazjować na temat sterowania komputerem i prawdopodobnie dowolnym urządzeniem, aż do koparki, statku kosmicznego, drona czy pieca.
Główną ideą jest poruszanie myszą, poruszanie nie całą ręką, a jedynie palcem wskazującym, co pozwoli na poruszanie się po menu bez odrywania rąk od klawiatury, wciskania przycisków i wraz ze skrótami klawiszowymi zamienia się w prawdziwy ninja klawiatury! Co się stanie, jeśli dodasz gesty przesuwania lub przewijania? Myślę, że będzie bomba! Ale do tej chwili musimy jeszcze poczekać kilka lat)
Zacznijmy składać nasz prototyp manipulatora przyszłości
Czego potrzebujesz:
-
Kamera z LiDAR Intel Realsense L515.
-
Umiejętność programowania w pytonie
-
Wystarczy trochę zapamiętać szkolną matematykę
-
Mocowanie kamery na monitorze aka statywie
Aparat mocujemy do statywu z aliexpress, okazał się bardzo wygodny, lekki i tani)


Zastanawiamy się, jak i na czym wykonać prototyp
Istnieje wiele podejść do wykonania tego zadania. Możesz samodzielnie wytrenować wykrywacz lub segmentację dłoni, wyciąć wynikowy obraz prawej ręki, a następnie zastosować to wspaniałe repozytorium z badań Facebooka na obrazie, uzyskać doskonały wynik lub jeszcze bardziej ułatwić.
Aby skorzystać z repozytorium potoku mediów, po przeczytaniu tego linku, możesz zrozumieć, że jest to jedna z najlepszych opcji na dziś.
Po pierwsze, wszystko jest już po wyjęciu z pudełka – instalacja i uruchomienie zajmie 30 minut, biorąc pod uwagę wszystkie wymagania wstępne.
Po drugie, dzięki potężnemu zespołowi programistów, nie tylko biorą pod uwagę stan techniki w szacowaniu pozycji w ręku, ale także zapewniają łatwy do zrozumienia interfejs API.
Po trzecie, sieć jest gotowa do działania na procesorze, więc próg wejścia jest minimalny.
Zapytacie pewnie, dlaczego tu nie trafiłem i nie korzystałem z repozytoriów zwycięzców tego konkursu. W rzeczywistości szczegółowo przestudiowałem ich rozwiązanie, są one dość gotowe, nie ma stosów milionów siatek itp. Ale wydaje mi się, że największym problemem jest to, że pracują z obrazami głębi. Ponieważ są to naukowcy, nie zawahali się przekonwertować wszystkich danych przez Matlab, dodatkowo rozdzielczość, w której sfilmowano głębie, wydawała mi się niewielka. Może to mieć głęboki wpływ na wynik. Dlatego wydaje się, że najłatwiej jest uzyskać kluczowe punkty na obrazie RGB i wziąć wartość wzdłuż osi Z w Depth Frame przez współrzędne XY. Teraz zadaniem nie jest optymalizacja czegoś, więc zrobimy to tak, jak jest to szybsze z rozwojowego punktu widzenia.
Zapamiętywanie szkolnej matematyki
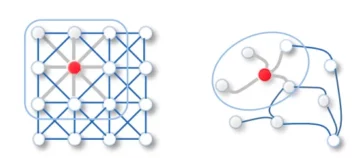
Jak już pisałem, aby uzyskać współrzędną punktu, w którym powinien znajdować się kursor myszy, musimy zbudować linię przechodzącą przez dwa kluczowe punkty paliczka palca i znaleźć punkt przecięcia prostej i płaszczyzna monitora.

Zdjęcie przedstawia schematycznie płaszczyznę monitora oraz linię, która go przecina. Możesz spojrzeć na matematykę tutaj.
Używając dwóch punktów otrzymujemy parametryczną reprezentację linii prostej w przestrzeni.


Nie będę się zbytnio skupiał na programie nauczania matematyki w szkole.
Instalowanie biblioteki do pracy z kamerą
To chyba najtrudniejsza część tej pracy. Jak się okazało, oprogramowanie kamery dla Ubuntu jest bardzo prymitywne, liberalny rozsądek jest po prostu zaśmiecony różnego rodzaju błędami, usterkami i tańcami z tamburynem.
Do tej pory nie udało mi się pokonać dziwnego zachowania aparatu, czasami nie ładuje parametrów przy starcie.
Aparat działa tylko raz po ponownym uruchomieniu komputera !!! Ale jest rozwiązanie: przed każdym uruchomieniem wykonaj programowy twardy reset aparatu, zresetuj USB i może wszystko będzie dobrze. Nawiasem mówiąc, w systemie Windows 10 wszystko jest w porządku. Dziwne, że twórcy wyobrażają sobie roboty oparte na Windows =)
Aby uzyskać prawdziwy sens pod Ubuntu 20, zrób tak:
$ sudo apt-get install libusb-1.0-0-dev Następnie ponownie uruchom cmake i dokonać instalacji. Tutaj is kompletny przepis, który zadziałał dla ja: $ sudo apt-get install libusb-1.0-0-dev $ git clone https://github.com/IntelRealSense/librealsense.git $ cd librealsense/ $ mkdir build && cd build
Po zebraniu z różnych gatunków będzie mniej lub bardziej stabilny. Miesiąc komunikacji z pomocą techniczną ujawnił, że musisz zainstalować Ubuntu 16 lub cierpisz. Sam go wybrałem, wiesz co.
Nadal rozumiemy zawiłości sieci neuronowej
Zobaczmy teraz kolejny film przedstawiający działanie palca i myszy. Należy pamiętać, że wskaźnik nie może stać w jednym miejscu i niejako unosi się wokół zamierzonego punktu. Jednocześnie mogę spokojnie skierować go na słowo, którego potrzebuję, ale z literą jest to trudniejsze, muszę ostrożnie przesuwać kursor:
To, jak rozumiesz, nie uścisk dłoni, w wakacje piłem tylko jeden kubek Nowej Anglii DIPA =) Chodzi o ciągłe wahania kluczowych punktów i współrzędnych Z na podstawie wartości uzyskanych z lidara.
Przyjrzyjmy się bliżej:
W naszej SOTA z media pipe jest z pewnością mniej wahań, ale one również istnieją. Jak się okazało, borykają się z tym, używając prokid vaniya z poprzedniej mapy termicznej klatek w obecnej sieci klatek i pociągów – daje to większą stabilność, ale nie 100%.
Wydaje mi się też, że ważną rolę odgrywa specyfika znaczników. Trudno jest zrobić ten sam znacznik na takiej liczbie klatek, nie mówiąc już o tym, że rozdzielczość klatki jest wszędzie inna i niezbyt duża. Nie widzimy też migotania światła, które najprawdopodobniej nie jest stałe ze względu na różne okresy pracy i ilość naświetlenia aparatu. A sieć zwraca też kanapkę z heatmapy równą liczbie kluczowych punktów na ekranie, rozmiar tego tensora to BxNx96x96, gdzie N to liczba kluczowych punktów i oczywiście po progu i zmianie rozmiaru do oryginału rozmiar ramki, otrzymujemy to, co otrzymujemy (
Przykład renderowania mapy cieplnej:

Przegląd kodu
Cały kod znajduje się w tym repozytorium i jest bardzo krótki. Rzućmy okiem na główny plik i zobaczmy resztę na własne oczy.
importować cv2
importować rura medialna as mp
importować tępy as np
importować pyautogui
importować pyralsense2.pyrealsense2 as rs
od google.protobuf.json_format importować WiadomośćDoDict
od mediapipe.python.solutions.drawing_utils importować _znormalizowane_do_współrzędnych_pikselowych
od pysk importować klawiatura
od utils.wspólne importować get_filtered_values, Draw_cam_out, get_right_index
od utils.hard_reset importować resetowanie_sprzętu
od utils.set_options importować set_short_range pyautogui.FAILSAFE = Fałsz mp_drawing = mp.solutions.drawing_utils mp_hands = mp.solutions.hands # Szacowanie pozycji rąk hands = mp_hands.Hands(max_num_hands=2, min_detection_confidence=0.9) def on_press(klucz):
if klucz == keyboard.Key.ctrl: pyautogui.leftClick()
if klawisz == keyboard.Key.alt: pyautogui.rightClick()
def pobierz_głębokość_koloru(potok, align, colorizer): frames = pipeline.wait_for_frames(timeout_ms=15000) # oczekiwanie na klatkę z kameryalign_frames = align.process(frames) depth_frame = wyrównane_frames.get_depth_frame() color_frame = wyrównane_frames.get_color_frame()
if nie ramka_głębokości or nie kolor_ramki:
powrót Brak, brak, brak depth_ima = np. asanyarray(depth_frame.get_data()) depth_col_img = np.asanyarray(colorizer.colorize(depth_frame).get_data()) color_image = np. asanyarray(color_frame.get_data()) depth_col_img = cv2. cvtColor(cv2.flip(cv2.flip(depth_col_img, 1), 0), cv2.COLOR_BGR2RGB) color_img = cv2.cvtColor(cv2.flip(cv2.flip(color_img, 1), 0), cv2.COLOR_BGR2RGB) depth_img = np.flipud(np.fliplr(depth_img)) depth_col_img = cv2.resize(depth_col_img, (1280 * 2, 720 * 2)) col_img = cv2.resize(col_img, (1280 * 2, 720 * 2)) depth_img = cv2 .resize(głębokość_img, (1280 * 2, 720 * 2))
powrót obraz_kolorowy, obraz_kolorowy_głęboki, obraz_głęboki
def get_right_hand_coords(color_image, depth_color_image): color_image.flags.writeable = False results = hands.process(color_image) color_image.flags.writeable = True color_image = cv2.cvtColor(color_image, cv2.COLOR_RGB2BGR) handedness_dict = [] idx_to_coordinates = {} xy xy0 = Brak, Brak
if wyniki.multi_hand_landmarks:
dla idx, ręka_ręczność in enumerate(results.multi_handedness): handedness_dict.append(MessageToDict(handed_handedness)) right_hand_index = get_right_index(handedness_dict)
if indeks_prawej_ręki != -1:
dla ja, lista_punktów orientacyjnych in enumerate(results.multi_hand_landmarks):
if i == indeks_ prawej ręki: image_rows, image_cols, _ = color_image.shape
dla idx, punkt orientacyjny in enumerate(lista_punktów orientacyjnych.punkt orientacyjny): punkt orientacyjny_px = _znormalizowane_do_pixel_coordinates(punkt orientacyjny.x, punkt orientacyjny.y, obraz_kolumny, wiersze_obrazu)
if punkt orientacyjny_px: idx_do_współrzędnych[idx] = punkt orientacyjny_px
dla ja, punkt orientacyjny_px in wyliczyć(idx_to_cooperatives.values()):
if i == 5: xy0 = punkt orientacyjny_px
if i == 7: xy1 = punkt orientacyjny_px
złamać
powrót col_img, głębokość_col_img, xy0, xy1, idx_to_coordinates
def początek(): pipeline = rs.pipeline() # zainicjuj librealsense config = rs.config() print("Rozpocznij konfigurację ładowania") config.enable_stream(rs.stream.depth, 1024, 768, rs.format.z16, 30) config.enable_stream(rs.stream.color, 1280, 720, rs.format.bgr8, 30) profile = pipeline.start(config) depth_sensor = profile.get_device (). first_depth_sensor () set_short_range (depth_sensor) # załaduj parametry do pracy z niewielkiej odległości colorizer = rs.colorizer () print ("Załadowana konfiguracja") align_to = rs.stream.color align = rs.align (align_to) # połącz mapę głębokości i color image spróbuj: while True: col_img, depth_col_img, depth_img = get_col_depth (pipelin, align, colorize) jeśli color_img to None, color_img to None i color_img to None: kontynuuj color_img, depth_col_img, xy00, xy11, idx_to_coordinates_img_get_right (col ) jeśli xy00 nie jest Brak lub xy11 nie jest Brak: z_val_f, z_val_s, m_xy, c_xy, xy00_f, xy11_f, x, y, z = get_filtered_values (depth_img, xy00, xy11) pyautogui.moveTo (int (x), int) (3500 - z)) # 3500 hardcode specyficzny dla mojego monitora, jeśli draw_cam_out (col_img, depth_col_img, xy00_f, xy11_f, c_xy, m_xy): przerwa w końcu: hands.close () pipeline.stop () hardware_reset () # uruchom ponownie kamerę i poczekaj aż się pojawi listener = keyboard.Listener (on_press = on_press) # ustaw listener dla klawisza przycisk tablicy naciska listener.start () start () # uruchom program
Nie korzystałem z klas ani strumieni, ponieważ w tak prostym przypadku wystarczy wykonać wszystko w głównym wątku w nieskończonej pętli while.
Na samym początku inicjowana jest rura medialna, kamera, ładowane są ustawienia kamery dla zmiennych bliskiego zasięgu i pomocniczych. Następnie pojawia się magia zwana „rozpaleniem głębi do koloru” – ta funkcja dopasowuje każdy punkt z obrazu RGB, punkt na ramce głębi, czyli daje nam możliwość uzyskania współrzędnych XY, wartości Z. Zrozumiałe jest, że konieczna jest kalibracja na swoim monitorze… celowo nie wyciągałem tych parametrów osobno, aby czytnik, który zdecydował się na uruchomienie kodu zrobił to sam, jednocześnie zostanie on ponownie wykorzystany w kodzie)
Następnie z całej prognozy bierzemy tylko punkty o numerach 5 i 7 prawej ręki.

Pozostało tylko przefiltrować otrzymane współrzędne za pomocą średniej ruchomej. Możliwe było oczywiście zastosowanie poważniejszych algorytmów filtrujących, ale po przyjrzeniu się ich wizualizacji i pociągnięciu różnych dźwigni stało się jasne, że do demo wystarczyłaby średnia ruchoma o głębokości 5 klatek, zaznaczam, że dla XY wystarczyły 2-3 klatki. ale jest gorzej z Z.
deque_l = 5 x0_d = kolekcje.deque(deque_l * [0.], deque_l) y0_d = kolekcje.deque(deque_l * [0.], deque_l) x1_d = kolekcje.deque(deque_l * [0.], deque_l) y1_d = collections.deque(deque_l * [0.], deque_l) z_val_f_d = collections.deque(deque_l * [0.], deque_l) z_val_s_d = collections.deque(deque_l * [0.], deque_l) m_xy_d = collections.deque(deque_l * [0.], deque_l) c_xy_d = collections.deque(deque_l * [0.], deque_l) x_d = collections.deque(deque_l * [0.], deque_l) y_d = collections.deque(deque_l * [0.] , deque_l) z_d = kolekcje.deque(deque_l * [0.], deque_l) def pobierz_filtrowane_wartości(głębokość_obrazu, xy0, xy1): światowy x0_d, y0_d, x1_d, y1_d, m_xy_d, c_xy_d, z_val_f_d, z_val_s_d, x_d, y_d, z_d x0_d.append(float(xy0[1])) x0_f = round(mean(x0_at.x) 0])) y0_f = round(mean(y0_d)) x0_d.append(float(xy0[1])) x1_f = round(mean(x1_d)) y1_d.append(float(xy1[1])) y1_f = round( mean(y0_d)) z_val_f = get_area_mean_z_val(depth_image, x1_f, y1_f) z_val_f_d.append(float(z_val_f)) z_val_f = mean(z_val_f_d) z_val_s = get_area_mean_z_val_sf_f) = średnia(z_val_s_d) punkty = [(y0_f, x0_f), (y1_f, x1_f)] x_coords, y_coords = zip(*punkty) A = np.vstack([x_coords, np.ones(len(x_coords))]). T m, c = lstsq(A, y_coords)[0] m_xy_d.append(float(m)) m_xy = średnia(m_xy_d) c_xy_d.append(float(c)) c_xy = średnia(c_xy_d) a0, a1, a1, a0 = równanie_płaszczyzna() x, y, z = przecięcie_linii_płaszczyznowych(y0_f, x1_f, z_v_s, y2_f, x3_f, z_v_f, a0, a0, a1, a1) x_d.append(float(x)) x = round(mean(x_d) ) y_d.append(float(y)) y = round(mean(y_d)) z_d.append(float(z)) z = round(mean(z_d)) powrót z_v_f, z_v_s, m_xy, c_xy, (y00_f, x0_f), (y11_f, x1_f), x, y, z
Tworzymy deque o długości 5 klatek i uśredniamy wszystko w rzędzie =) Dodatkowo obliczamy y = mx + c, Ax + By + Cz + d = 0, równaniem dla prostej jest promień w RGB obraz i równanie płaszczyzny monitora, otrzymujemy y = 0.
Wnioski
Cóż, to wszystko, wypiłowaliśmy najprostszy manipulator, który nawet przy dramatycznie prostym wykonaniu może już być używany, choć z trudem, w prawdziwym życiu!
Media pokazane w tym artykule nie są własnością Analytics Vidhya i są używane według uznania Autora.
Związane z
- "
- &
- 7
- 9
- Konto
- Algorytmy
- Wszystkie kategorie
- analityka
- api
- na około
- Sztuka
- artykuł
- BEST
- Najwyższa
- Pudełko
- błędy
- budować
- bliższy
- kod
- wspólny
- Komunikacja
- konkurencja
- kontynuować
- Para
- Aktualny
- CZ
- dane
- detal
- deweloperzy
- oprogramowania
- ZROBIŁ
- dystans
- truteń
- Anglia
- itp
- egzekucja
- Postać
- W końcu
- w porządku
- i terminów, a
- Skupiać
- format
- funkcjonować
- przyszłość
- git
- tutaj
- wakacje
- W jaki sposób
- HTTPS
- pomysł
- IDX
- obraz
- wskaźnik
- Intel
- IT
- Praca
- Klawisz
- duży
- uruchomić
- Biblioteka
- sprawa
- lekki
- Linia
- załadować
- mapa
- matematyka
- Media
- ruch
- sieć
- Nerwowy
- Okazja
- Opcje
- zamówienie
- obraz
- rura
- Punkt widzenia
- przepowiednia
- naciśnij
- Profil
- Program
- ciągnięcie
- Python
- Czytelnik
- Czytający
- Przepis
- Badania naukowe
- REST
- Efekt
- powraca
- roboty
- run
- Szkoła
- nauka
- Ekran
- rozsądek
- zestaw
- Short
- Prosty
- Rozmiar
- mały
- So
- Tworzenie
- Rozwiązania
- Typ przestrzeni
- Stabilność
- STAGE
- początek
- startup
- Stan
- Sudo
- wsparcie
- Techniczny
- pomoc techniczna
- Przyszłość
- czas
- Ubuntu
- us
- usb
- wartość
- Wideo
- Zobacz i wysłuchaj
- wyobrażanie sobie
- czekać
- KIM
- okna
- Praca
- działa
- X
- lat