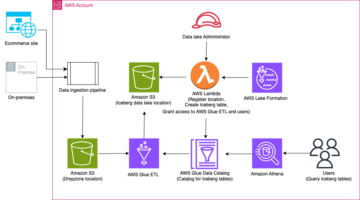
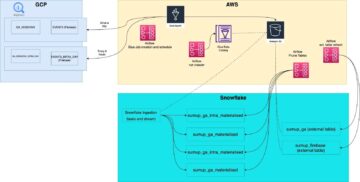
To jest wpis na blogu gościnnym, napisany wspólnie z Sumeshem M R z Cargotec i Tero Karttunenem z Knowit Finland.
Cargotec (Nasdaq Helsinki: CGCBV) to fińska firma specjalizująca się w rozwiązaniach i usługach w zakresie obsługi ładunków. Ich siedziba znajduje się w Helsinkach w Finlandii i działa globalnie w ponad 100 krajach. Dzięki wiodącym rozwiązaniom i usługom w zakresie obsługi ładunków są pionierami w swojej dziedzinie. Dzięki swojej wyjątkowej pozycji w portach, na morzu i na drogach optymalizują globalne przepływy ładunków i tworzą zrównoważoną wartość dla klienta.
Cargotec rejestruje terabajty danych telemetrycznych IoT ze swoich maszyn obsługiwanych przez wielu klientów na całym świecie. Dane te należy pozyskać do jeziora danych, przekształcić i udostępnić na potrzeby analiz, uczenia maszynowego (ML) i wizualizacji. W tym celu firma Cargotec zbudowała Usługa Amazon Simple Storage (Amazon S3) data Lake i skatalogowałem zasoby danych w AWS Glue Data Catalog. Oni wybrali Klej AWS jako preferowane narzędzie do integracji danych ze względu na bezserwerowy charakter, niskie koszty utrzymania, możliwość wcześniejszej kontroli zasobów obliczeniowych i skalowanie w razie potrzeby.
Na tym blogu omawiamy wyzwania techniczne stojące przed firmą Cargotec podczas replikowania metadanych kleju AWS na kontach AWS oraz to, jak pomyślnie poradziła sobie z tymi wyzwaniami, aby umożliwić udostępnianie danych między kontami. Dzieląc się ich historiami, mamy nadzieję zainspirować czytelników stojących przed podobnymi wyzwaniami i zapewnić wgląd w to, w jaki sposób można dostosować nasze usługi do Twoich konkretnych potrzeb.
Wyzwania
Podobnie jak wielu klientów, jezioro danych Cargotec jest rozproszone na wielu kontach AWS, których właścicielami są różne zespoły. Firma Cargotec chciała znaleźć rozwiązanie umożliwiające udostępnianie zbiorów danych między kontami i korzystanie z nich Amazonka Atena aby ich zapytać. Aby udostępnić zbiory danych, potrzebowali sposobu na współdzielenie dostępu do danych i dostępu do metadanych katalogu w postaci tabel i widoków. Przypadki użycia firmy Cargotec wymagały również utworzenia widoków obejmujących tabele i widoki obejmujące katalogi. Wdrożenie Cargotec obejmuje trzy osobne konta AWS, 25 baz danych, 150 tabel i 10 widoków.
Omówienie rozwiązania
Firma Cargotec potrzebowała jednego katalogu na konto, który zawierałby metadane z innych kont AWS. Rozwiązaniem, które najlepiej odpowiadało ich potrzebom, była replikacja metadanych przy użyciu wewnętrznej wersji publicznie dostępnego narzędzia o nazwie Narzędzie do migracji Metastore. Cargotec rozszerzył narzędzie, zmieniając ogólną warstwę orkiestracji, dodając plik Amazon SQS powiadomienie i AWS Lambda. Podejście polegało na programowym skopiowaniu i udostępnieniu każdej jednostki katalogu (baz danych, tabel i widoków) wszystkim kontom klientów. Dzięki temu tabele lub widoki są lokalne dla konta, na którym uruchamiane jest zapytanie, podczas gdy dane nadal pozostają w źródłowym zasobniku S3.
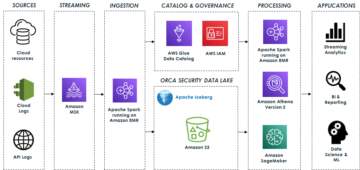
Architektura rozwiązań Cargotec
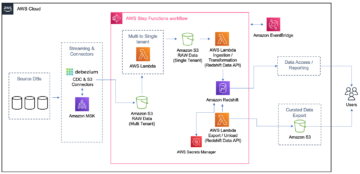
Poniższy diagram podsumowuje architekturę i ogólny przebieg wydarzeń w projekcie Cargotec.
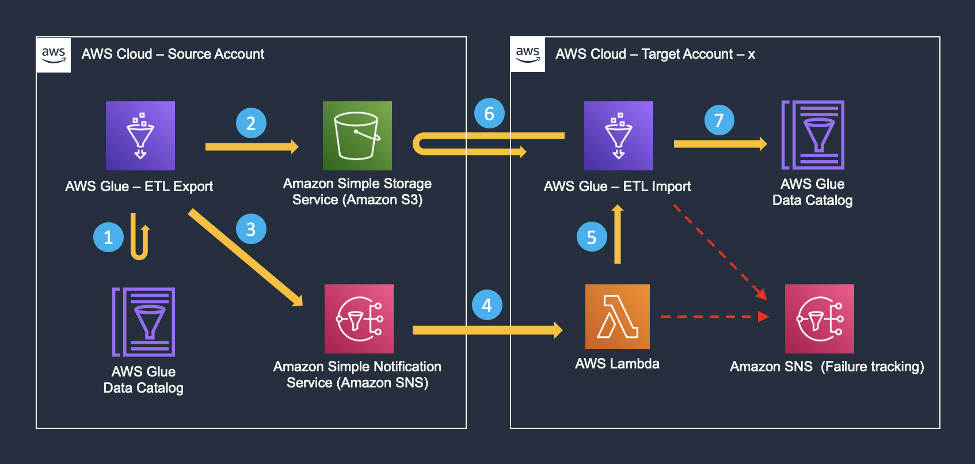
Wpisy katalogu z konta źródłowego są programowo replikowane na wiele kont docelowych, wykonując następującą serię kroków.
- Zadanie AWS Glue (eksporter metadanych) jest uruchamiane codziennie na koncie źródłowym. Odczytuje informacje o tabeli i partycjach ze źródłowego katalogu danych kleju AWS. Ponieważ konto docelowe służy do celów analitycznych i nie wymaga zmian schematu w czasie rzeczywistym, eksporter metadanych uruchamia się tylko raz dziennie. Cargotec korzysta z projekcji przegród, co zapewnia dostępność nowych przegród w czasie rzeczywistym.
- Następnie zadanie zapisuje metadane w zasobniku S3 na tym samym koncie. Należy pamiętać, że rozwiązanie nie obejmuje przenoszenia danych pomiędzy kontami. Konta docelowe odczytują dane z zasobników S3 konta źródłowego. Wskazówki dotyczące konfigurowania odpowiednich uprawnień można znaleźć w artykule Podręcznik użytkownika Amazon Athena.
- Po zakończeniu eksportu metadanych zadanie AWS Glue przesyła powiadomienie do Usługa prostego powiadomienia Amazon (Amazon SNS) temat. Ta wiadomość zawiera ścieżkę S3 do najnowszego eksportu metadanych. Powiadomienie SNS to dostosowanie firmy Cargotec do istniejącego narzędzia typu open source.
- Każde konto docelowe obsługuje AWS Lambda funkcja powiadamiająca, gdy temat SNS konta źródłowego otrzyma push. Krótko mówiąc, istnieje wiele funkcji Lambda abonenta (jedna na konto docelowe) dla tematów SNS konta źródłowego, które są wyzwalane po zakończeniu zadania eksportu.
- Po uruchomieniu funkcja Lambda inicjuje zadanie AWS Glue (importer metadanych) na odpowiednim koncie docelowym. Zadanie otrzymuje jako dane wejściowe ścieżkę S3 konta źródłowego do metadanych, które zostały niedawno wyeksportowane.
- Na podstawie podanej ścieżki importer metadanych odczytuje wyeksportowane metadane ze źródłowego zasobnika S3.
- Osoba importująca metadane używa teraz tych informacji do tworzenia lub aktualizowania odpowiednich informacji katalogowych na koncie docelowym.
Wszystkie błędy są publikowane w osobnym temacie SNS w celu rejestrowania i monitorowania. Dzięki takiemu podejściu firma Cargotec była w stanie tworzyć i wykorzystywać widoki obejmujące tabele i widoki z wielu katalogów rozmieszczonych na różnych kontach AWS.
Realizacja
Trzon narzędzia do replikacji katalogów stanowią dwa skrypty AWS Glue:
- Eksporter metadanych – Zadanie AWS Glue, które odczytuje katalog danych źródłowych i tworzy eksport baz danych, tabel i partycji w zasobniku S3 na koncie źródłowym.
- Importer metadanych – Zadanie AWS Glue, które odczytuje eksport utworzony przez eksportera metadanych i stosuje metadane do docelowych baz danych. Ten kod jest wyzwalany przez funkcję Lambda po zapisaniu plików w S3. Zadanie jest uruchamiane na koncie docelowym.
Eksporter metadanych
Ta sekcja zawiera szczegółowe informacje na temat zadania kleju AWS, które eksportuje katalog danych kleju AWS do lokalizacji S3. Kod źródłowy aplikacji znajduje się na serwerze GitHub kleju AWS. Chociaż może zaistnieć potrzeba dostosowania tego do Twoich potrzeb, w tym blogu omówimy podstawowe komponenty kodu.
Dane wejściowe eksportera metadanych
Aplikacja przyjmuje kilka parametrów wejściowych zadania, jak opisano poniżej:
--modeklucz akceptuje obato-s3orto-jdbc. Ten ostatni jest używany, gdy kod przenosi metadane bezpośrednio do magazynu metadanych JDBC Hive. W przypadku Cargotec, ponieważ przenosimy metadane do plików na S3, wartość dla--modepozostanieto-s3.--output-pathakceptuje lokalizację S3, w której powinny zostać zapisane wyeksportowane metadane. Kod tworzy podkatalogi odpowiadające bazom danych, tabelom i partycjom.--database-namesakceptuje rozdzieloną średnikami listę baz danych w katalogu źródłowym, które należy zreplikować do miejsca docelowego
Czytanie katalogu
Metadane dotyczące bazy danych, tabel i partycji są odczytywane z katalogu AWS Glue.
Powyższy fragment kodu odczytuje metadane do ramki DynamicFrame AWS Glue. Ramka jest następnie konwertowana na ramkę danych Spark. Jest filtrowany do poszczególnych ramek danych w zależności od tego, czy jest częścią bazy danych, tabeli czy partycji. Schemat jest dołączany do ramki danych przy użyciu jednego z poniższych sposobów:
Aby uzyskać szczegółowe informacje na temat schematu poszczególnych pozycji, zobacz definicja schematu w GitHubie.
Utrwalanie metadanych
Po przekonwertowaniu na ramkę DataFrame ze schematem jest ona utrwalana w lokalizacji S3 oznaczonej parametrem ścieżka wyjściowa
Badanie wyników
Przejdź do zasobnika S3 zawierającego lokalizację wyjściową. Metadane wyjściowe powinny być widoczne w formacie. Przykładowy eksport tabeli będzie wyglądał jak poniższy fragment kodu.
Po zakończeniu zadania eksportu wyjściowa ścieżka S3 zostanie przesłana do tematu SNS. Funkcja Lambda na koncie docelowym przetwarza ten komunikat i wywołuje zadanie importowania kleju AWS, przekazując lokalizację importu S3.
Importer metadanych
Zadanie importowania jest uruchamiane na koncie docelowym. Kod zadania jest dostępny na GitHub. Podobnie jak w przypadku eksportera, może być konieczne dostosowanie go do konkretnych wymagań, ale kod w niezmienionej postaci powinien działać w większości scenariuszy.
Dane wejściowe importera metadanych
Dane wejściowe do aplikacji są dostarczane jako parametry zadania. Poniżej znajduje się lista parametrów wykorzystywanych w procesie importu:
--modeklucz akceptuje obafrom-s3orfrom-jdbc. To drugie jest używane w przypadku migracji ze źródła JDBC do katalogu danych kleju AWS. W Cargotec metadane są już zapisane w Amazon S3, dlatego wartość tego klucza jest zawsze ustawiona nafrom-s3.--regionklucz akceptuje prawidłowy region AWS dla katalogu klejów AWS. Region docelowy jest określany za pomocą tego klucza.--database-input-pathklucz akceptuje ścieżkę do pliku zawierającego metadane bazy danych. To jest wynik poprzedniego zadania importu.--table-input-pathkey akceptuje ścieżkę do pliku zawierającego metadane tabeli. To jest wynik poprzedniego zadania importu.--partition-input-pathkey akceptuje ścieżkę do pliku zawierającego metadane partycji. To jest wynik poprzedniego zadania importu.
Czytanie metadanych
Metadane, jak omówiono wcześniej, to pliki na Amazon S3. Są one wczytywane do poszczególnych ramek danych iskry wraz z odpowiednimi informacjami o schemacie
Ładowanie katalogu
Po odczytaniu ramek danych Spark są one konwertowane do AWS Glue DynamicFrame, a następnie ładowane do katalogu, jak pokazano w poniższym fragmencie.
Po zakończeniu zadania możesz wysłać zapytanie do docelowego katalogu kleju AWS, aby upewnić się, że tabele ze źródła zostały zsynchronizowane z miejscem docelowym. Aby wszystko było proste i łatwe w zarządzaniu, zamiast wdrażać mechanizm identyfikujący tabele zmieniające się w czasie, Cargotec aktualizuje informacje katalogowe wszystkich baz danych lub tabel skonfigurowanych w zadaniu eksportu.
rozważania
Chociaż konfiguracja ta sprawdza się skutecznie w przypadku bieżących wymagań biznesowych Cargotec, podejście to ma kilka wad, które przedstawiono poniżej:
- Rozwiązanie wymaga kodu. Dostosowano istniejące narzędzie typu open source, aby móc publikować powiadomienia SNS po zakończeniu eksportu oraz funkcję Lambda uruchamiającą proces importu.
- Proces eksportu na koncie źródłowym jest zadaniem zaplanowanym. Dlatego nie ma synchronizacji w czasie rzeczywistym między kontami źródłowymi i docelowymi. Nie był to wymóg w procesie biznesowym Cargotec.
- W przypadku tabel, które nie korzystają z projekcji partycji Athena, wyniki zapytań mogą być nieaktualne do czasu dodania nowych partycji do metastore za pomocą MSCK REPAIR TABLE, ALTER TABLE ADD PARTITION, przeszukiwacza AWS Glue i tak dalej.
- Obecne podejście wymaga synchronizowania wszystkich tabel w źródle i miejscu docelowym. Jeśli wymaganie polega na uwzględnieniu tylko tych, które uległy zmianie, zamiast zaplanowanego codziennego eksportu, projekt musi ulec zmianie i może skorzystać na Most zdarzeń Amazona integracja z klejem AWS. Przykładową implementację wykorzystania API AWS Glue do identyfikacji zmian pokazano w Zidentyfikuj zmiany schematu źródłowego za pomocą AWS Glue.
Wnioski
W tym poście na blogu omówiliśmy rozwiązanie umożliwiające udostępnianie danych i tabel między kontami, które umożliwia firmie Cargotec tworzenie widoków łączących dane z wielu kont AWS. Cieszymy się, że możemy podzielić się sukcesem Cargotec i wierzymy, że ten post dostarczył Ci cennych spostrzeżeń i inspiracji do własnych projektów.
Zachęcamy do zapoznania się z naszą ofertą usług i sprawdzenia, w jaki sposób mogą one pomóc w osiągnięciu Twoich celów. Na koniec, aby uzyskać więcej blogów poświęconych danym i analizom, możesz dodać je do zakładek Blog AWSs.
O autorach
 Sumesh M. R jest architektem uczenia maszynowego Full Stack w firmie Cargotec. Ma kilkuletnie doświadczenie w inżynierii oprogramowania i ML. Sumesh jest ekspertem w zakresie Sagemaker i innych usług AWS ML/Analytics. Pasjonuje się analityką danych i uwielbia poznawać najnowsze biblioteki i techniki ML. Przed dołączeniem do Cargotec pracował jako architekt rozwiązań w TCS. W wolnym czasie uwielbia grać w krykieta i badmintona.
Sumesh M. R jest architektem uczenia maszynowego Full Stack w firmie Cargotec. Ma kilkuletnie doświadczenie w inżynierii oprogramowania i ML. Sumesh jest ekspertem w zakresie Sagemaker i innych usług AWS ML/Analytics. Pasjonuje się analityką danych i uwielbia poznawać najnowsze biblioteki i techniki ML. Przed dołączeniem do Cargotec pracował jako architekt rozwiązań w TCS. W wolnym czasie uwielbia grać w krykieta i badmintona.
 Tero Karttunena jest starszym architektem chmury w Knowit Finland. Doradza klientom w zakresie projektowania i wdrażania architektur danych, które najlepiej odpowiadają ich potrzebom w zakresie analityki danych i uczenia maszynowego. Od ponad dwóch lat pomaga firmie Cargotec w podróżowaniu po danych. Poza pracą lubi biegać, uprawiać sporty zimowe i gry RPG.
Tero Karttunena jest starszym architektem chmury w Knowit Finland. Doradza klientom w zakresie projektowania i wdrażania architektur danych, które najlepiej odpowiadają ich potrzebom w zakresie analityki danych i uczenia maszynowego. Od ponad dwóch lat pomaga firmie Cargotec w podróżowaniu po danych. Poza pracą lubi biegać, uprawiać sporty zimowe i gry RPG.
 Arun AK jest architektem rozwiązań specjalistycznych Big Data w AWS. Współpracuje z klientami, aby zapewnić wskazówki architektoniczne dotyczące uruchamiania rozwiązań analitycznych na AWS Glue, AWS Lake Formation, Amazon Athena i Amazon EMR. W wolnym czasie lubi spędzać czas z przyjaciółmi i rodziną.
Arun AK jest architektem rozwiązań specjalistycznych Big Data w AWS. Współpracuje z klientami, aby zapewnić wskazówki architektoniczne dotyczące uruchamiania rozwiązań analitycznych na AWS Glue, AWS Lake Formation, Amazon Athena i Amazon EMR. W wolnym czasie lubi spędzać czas z przyjaciółmi i rodziną.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- EVM Finanse. Ujednolicony interfejs dla zdecentralizowanych finansów. Dostęp tutaj.
- Quantum Media Group. Wzmocnienie IR/PR. Dostęp tutaj.
- PlatoAiStream. Analiza danych Web3. Wiedza wzmocniona. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/how-cargotec-uses-metadata-replication-to-enable-cross-account-data-sharing/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 1
- 10
- 100
- 12
- 14
- 25
- 46
- 9
- a
- zdolność
- Zdolny
- O nas
- powyżej
- Akceptuje
- dostęp
- Konto
- Konta
- Osiągać
- w poprzek
- Dodaj
- w dodatku
- dodanie
- Przyjęcie
- awansować
- Wszystkie kategorie
- wzdłuż
- już
- również
- zawsze
- Amazonka
- Amazonka Atena
- Amazon EMR
- Amazon Web Services
- an
- Analityczny
- analityka
- i
- każdy
- Apache
- Pszczoła
- Zastosowanie
- podejście
- architektoniczny
- architektura
- SĄ
- AS
- Aktywa
- At
- przywiązany
- dostępny
- AWS
- Klej AWS
- Formacja AWS Lake
- tło
- na podstawie
- BE
- być
- zanim
- jest
- uwierzyć
- poniżej
- korzyści
- BEST
- pomiędzy
- Duży
- Big Data
- Blog
- blogi
- wybudowany
- biznes
- Proces biznesowy
- ale
- by
- nazywa
- CAN
- zdobyć
- przechwytuje
- Ładunek
- walizka
- Etui
- katalog
- katalogi
- wyzwania
- zmiana
- zmieniony
- Zmiany
- wymiana pieniędzy
- wybrał
- klientów
- Chmura
- kod
- kolumny
- połączyć
- sukcesy firma
- kompletny
- Zakończony
- składniki
- obliczać
- połączenia
- konsumować
- konsument
- zawarte
- zawiera
- kontrola
- przeliczone
- 轉換
- rdzeń
- Odpowiedni
- mógłby
- kraje
- obejmuje
- crawler
- Stwórz
- stworzony
- tworzy
- krykiet
- Aktualny
- klient
- Klientów
- dostosowywanie
- dostosować
- dostosowane
- codziennie
- dane
- Analityka danych
- integracja danych
- Jezioro danych
- nauka danych
- udostępnianie danych
- Baza danych
- Bazy danych
- zbiory danych
- dzień
- Domyślnie
- opisane
- Wnętrze
- miejsce przeznaczenia
- detale
- różne
- bezpośrednio
- dyskutować
- omówione
- dystrybuowane
- robi
- Nie
- nie
- wady
- z powodu
- każdy
- łatwo
- faktycznie
- bądź
- umożliwiać
- zachęcać
- Inżynieria
- zapewnić
- zapewnia
- jednostka
- Błędy
- Eter (ETH)
- wydarzenia
- przykład
- podniecony
- Przede wszystkim system został opracowany
- ekspert
- odkryj
- zbadane
- eksport
- eksport
- zewnętrzny
- w obliczu
- okładzina
- fałszywy
- członków Twojej rodziny
- czuć
- kilka
- pole
- filet
- Akta
- Znajdź
- Finlandia
- fiński
- dopasować
- pływ
- Przepływy
- następujący
- W razie zamówieenia projektu
- Nasz formularz
- format
- formacja
- FRAME
- Darmowy
- przyjaciele
- od
- pełny
- Pełny stos
- funkcjonować
- Funkcje
- Games
- otrzymać
- Globalne
- Globalnie
- globus
- Go
- Gole
- Gość
- Blog gościa
- poradnictwo
- Hadoop
- Prowadzenie
- Have
- he
- z siedzibą
- pomoc
- pomógł
- stąd
- Podświetlony
- jego
- Ul
- nadzieję
- hostowane
- W jaki sposób
- HTML
- HTTPS
- zidentyfikować
- if
- realizacja
- wykonawczych
- importować
- in
- indywidualny
- Informacja
- Inicjuje
- wkład
- Wejścia
- spostrzeżenia
- Inspiracja
- inspirować
- zamiast
- integracja
- najnowszych
- inwokuje
- angażować
- dotyczy
- Internet przedmiotów
- IT
- szt
- JEGO
- Praca
- łączący
- podróż
- json
- Trzymać
- Klawisz
- jezioro
- firmy
- warstwa
- prowadzący
- nauka
- biblioteki
- lubić
- Lista
- miejscowy
- lokalizacja
- zalogowaniu
- Popatrz
- wygląda jak
- kocha
- niski
- maszyna
- uczenie maszynowe
- maszyny
- zrobiony
- konserwacja
- robić
- WYKONUJE
- zarządzanie
- wiele
- wyraźny
- Może..
- mechanizm
- Poznaj nasz
- wiadomość
- Metadane
- migracja
- ML
- monitorowanie
- jeszcze
- większość
- ruch
- przeniesienie
- wielokrotność
- Nazwa
- Nasdaq
- Natura
- Potrzebować
- potrzebne
- wymagania
- Nowości
- Nie
- noty
- powiadomienie
- już dziś
- liczny
- of
- on
- pewnego razu
- ONE
- te
- tylko
- open source
- eksploatowane
- działa
- Optymalizacja
- or
- orkiestracja
- Inne
- ludzkiej,
- wydajność
- zewnętrzne
- koniec
- ogólny
- własny
- własność
- właściciel
- parametry
- część
- Przechodzący
- namiętny
- ścieżka
- uprawnienia
- pionierzy
- plato
- Analiza danych Platona
- PlatoDane
- Grać
- Proszę
- porty
- position
- możliwy
- Post
- Korzystny
- poprzedni
- poprzednio
- wygląda tak
- procesów
- Projekcja
- projektowanie
- zapewniać
- pod warunkiem,
- dostawca
- zapewnia
- publicznie
- publikować
- opublikowany
- cele
- Naciskać
- popychany
- zasięg
- Czytaj
- czytelnicy
- w czasie rzeczywistym
- otrzymuje
- niedawno
- region
- pozostawać
- szczątki
- naprawa
- replikowane
- replikacja
- wymagać
- wymagany
- wymaganie
- wymagania
- Wymaga
- Zasoby
- osób
- Efekt
- retencja
- prawo
- drogi
- Odgrywanie ról
- run
- bieganie
- działa
- sagemaker
- taki sam
- Skala
- scenariusze
- zaplanowane
- nauka
- skrypty
- SEA
- Sekcja
- widzieć
- senior
- oddzielny
- Serie
- służyć
- Bezserwerowe
- usługa
- Usługi
- zestaw
- ustawienie
- ustawienie
- kilka
- Share
- dzielenie
- Short
- powinien
- pokazane
- podobny
- Prosty
- ponieważ
- pojedynczy
- So
- Tworzenie
- Inżynieria oprogramowania
- rozwiązanie
- Rozwiązania
- Źródło
- Kod źródłowy
- Źródła
- rozpiętość
- Iskra
- specjalista
- specjalizuje się
- specyficzny
- określony
- wydać
- SPORTOWE
- rozpiętość
- SQL
- stos
- Cel
- Nadal
- przechowywanie
- Historia
- sznur
- sukces
- Z powodzeniem
- Garnitur
- zrównoważone
- stół
- trwa
- cel
- Zespoły
- Techniczny
- Techniki
- niż
- że
- Połączenia
- Źródło
- ich
- Im
- następnie
- Tam.
- Te
- one
- rzeczy
- to
- chociaż?
- trzy
- Przez
- czas
- do
- narzędzie
- aktualny
- tematy
- przekształcony
- wyzwalać
- rozsierdzony
- prawdziwy
- drugiej
- rodzaj
- wyjątkowy
- aż do
- Aktualizacja
- Nowości
- posługiwać się
- używany
- Użytkownik
- zastosowania
- za pomocą
- użyteczność
- Cenny
- wartość
- wersja
- widoki
- wyobrażanie sobie
- poszukiwany
- była
- Droga..
- we
- sieć
- usługi internetowe
- były
- jeśli chodzi o komunikację i motywację
- który
- Podczas
- będzie
- w Zimie
- w
- Praca
- pracował
- działa
- by
- napisać
- napisany
- lat
- ty
- Twój
- zefirnet