W tym artykule poznasz różne metody konwersji plików PDF na Arkusze Google.
Dowiesz się również, jak działają nanonety zautomatyzuj cały proces konwersji plików PDF na Arkusze Google online.
Zanim przyjrzymy się, jak przekonwertować plik PDF na Arkusze Google, przyjrzyjmy się, dlaczego jest to ważne.
Dlaczego warto konwertować pliki PDF na Arkusze Google?
Według tego Blog Google post z oficjalnej strony bloga Google, ponad 5 milionów firm korzysta z ich rozwiązania G Suite. W tym samym czasie wiele firm zaczęło również używać integracji Arkuszy Google do automatyzacji zadań.
Rozważmy typowy przypadek użycia. Twój zespół ds. rozliczeń otrzymuje fakturę w standardowym formacie PDF. Ktoś ręcznie przegląda fakturę i wprowadza wymagane informacje do dokumentu Arkuszy Google, a następnie przekazuje ją do sekcji Finanse. Sekcja finansów płaci Twojemu dostawcy i dokonuje wpisu w księdze firmy.
Oprócz tego, że jest to długotrwały proces, jest to podatne na błędy i znacznie rozsądniej byłoby po prostu go zautomatyzować.
Teraz, gdy potrzeba konwersji plików PDF na formularz arkusza Google jest jasna, przyjrzyjmy się strukturze dokumentów PDF i wyzwaniom związanym z ich analizą.
Chcesz przekonwertować PDF plików do Arkusze Google ? Sprawdzić Nanonets ' za darmo Konwerter plików PDF na CSV. Lub dowiedz się, jak to zrobić zautomatyzuj cały przepływ pracy PDF do Arkuszy Google za pomocą Nanonets.
Wyzwania związane z analizowaniem dokumentu PDF
Przenośny format dokumentów był formatem plików początkowo opracowanym przez firmę Adobe, a później wydanym jako otwarty standard. Od tego czasu został powszechnie przyjęty, ponieważ jest agnostyczny dla podstawowego systemu operacyjnego.
Dlaczego więc tak trudno jest przeanalizować plik PDF i przekonwertować jego zawartość na inny format? Poniższe obrazy mówią tysiące słów i skłaniają do sedna sprawy.
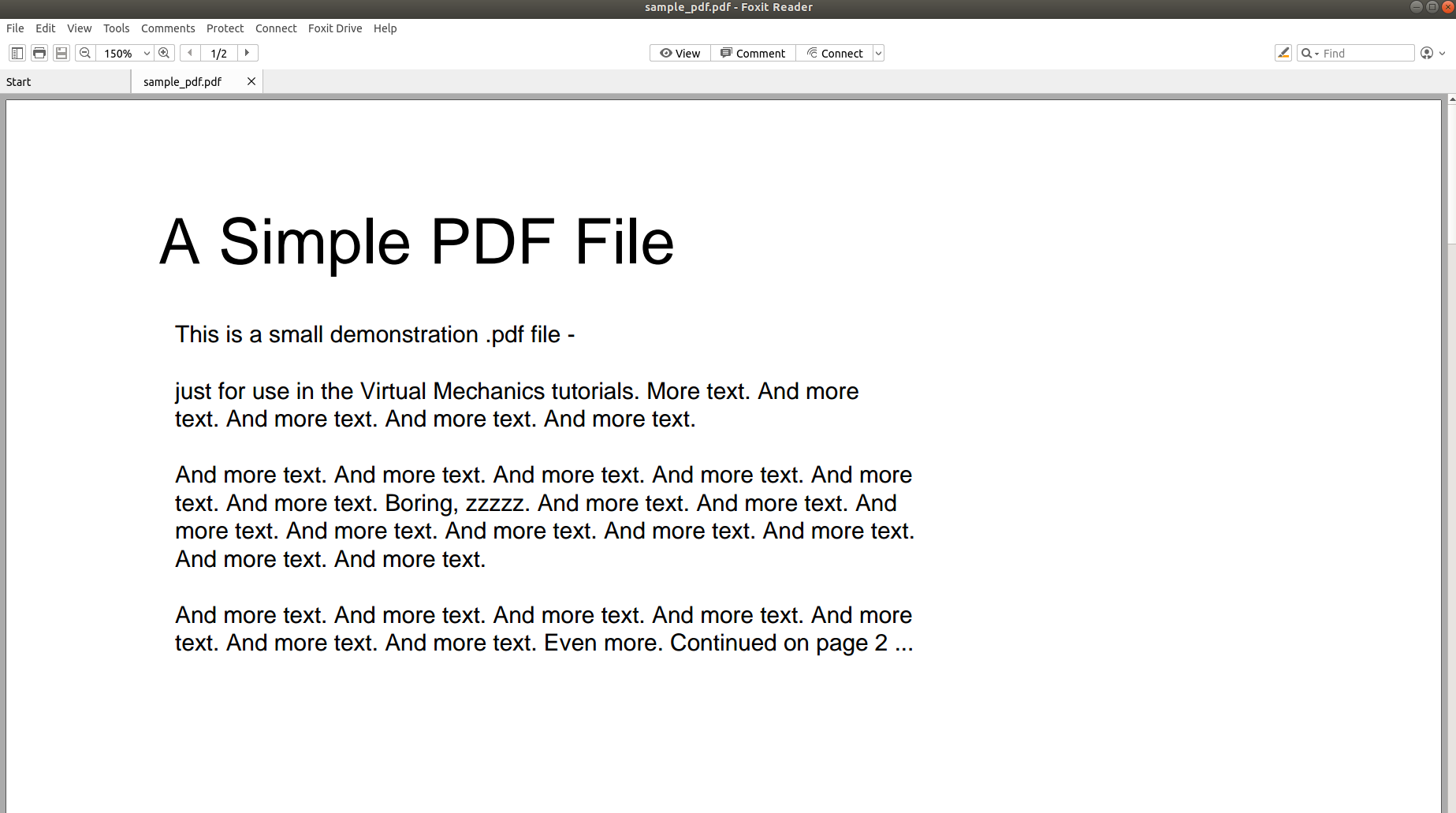
Powyższy obraz przedstawia zrzut ekranu dokumentu PDF, który jest otwierany za pomocą czytnika PDF. Spróbujmy otworzyć ten sam dokument PDF za pomocą edytora tekstu.
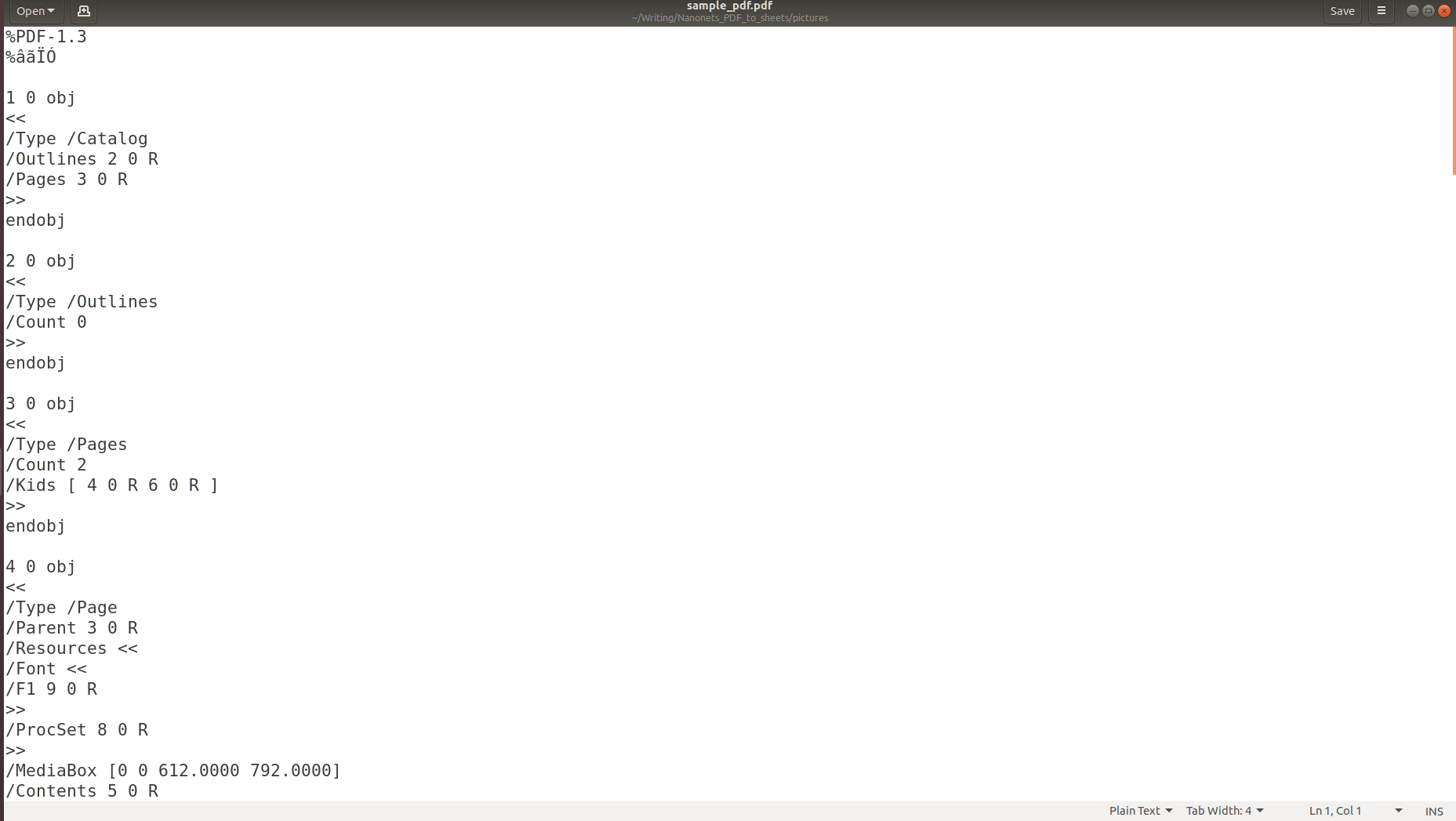
Powyższe zdjęcia jasno pokazują, że gdy informacje są przechowywane w pliku PDF, ich pierwotna struktura jest całkowicie tracona. Dzieje się tak, ponieważ format PDF składa się po prostu z instrukcji dotyczących drukowania/rysowania sekwencji znaków na stronie.
Jeśli uważasz, że wyodrębnienie tekstu jest trudne, wyodrębnienie danych zawartych w tabelach jest jeszcze trudniejsze ze względu na bardzo różne formaty tabel, które są używane.
Mamy nadzieję, że jesteś przekonany, że konwersja dokumentu PDF na formularz Arkuszy Google to nie spacer po parku. W następnej sekcji omówiono podejście stosowane przez większość nowoczesnych parserów PDF do rozpoznawania/analizowania informacji z dokumentu PDF.
Nowoczesne podejście do analizowania dokumentów PDF
Większość nowoczesnych parserów PDF korzysta z opisanego poniżej przepływu do analizowania nieustrukturyzowanych danych z dokumentów PDF.
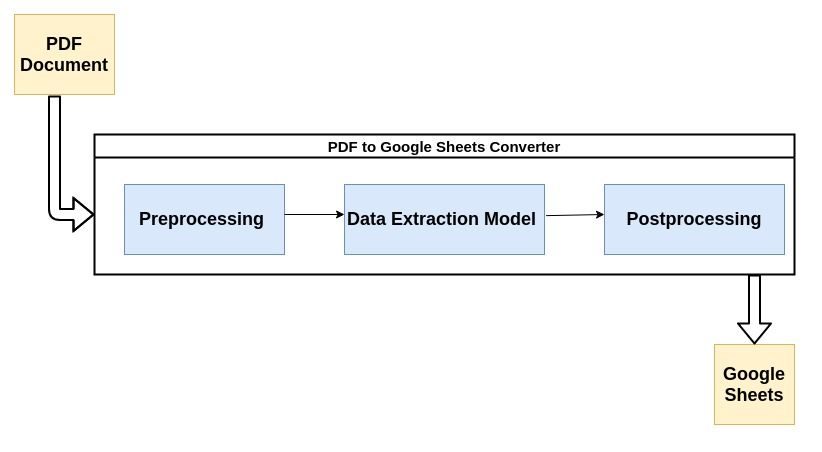
Przyjrzyjmy się pokrótce każdemu etapowi procesu:
1. Wstępne przetwarzanie lub czyszczenie danych:
Im lepiej wygląda Twój plik PDF, tym łatwiej będzie wyodrębnić Twój model uczenia maszynowego lub przechwytywać dane z tego. Na przykład, jeśli dokument PDF został zeskanowany, może zawierać pewne artefakty skanowania, które mogą wpłynąć na wydajność konwertera.
Usuwanie szumów za pomocą odpowiednich filtrów, binaryzacja, korekcja skosu itp. to jedne z najczęstszych etapów przetwarzania wstępnego. Następujące Nanonets post Nanonet Tesseract Post zawiera kilka świetnych przykładów tego, jak dokumenty mogą być wstępnie przetwarzane wcześniej Optyczne rozpoznawanie znaków(OCR) jest na nich uruchomiony.
To tutaj dzieje się większość magii. Ekstrakcja danych jest zwykle przeprowadzana przez model uczenia maszynowego (ML). Większość modeli ML używanych do ekstrakcji danych z plików PDF zawiera kombinację narzędzi do optycznego rozpoznawania znaków, narzędzi do rozpoznawania tekstu i wzorów itp.
Na potrzeby tego posta możemy potraktować model jako czarną skrzynkę, która przyjmuje dokument PDF jako dane wejściowe i wypluwa przeanalizowane informacje. Ponadto, ponieważ w swoim rdzeniu wykorzystuje ML, można go przeszkolić za pomocą niestandardowych danych, aby dopasować go do przypadku użycia w firmie.
3. Przetwarzanie końcowe:
Na tym etapie wyodrębnione dane są konwertowane do wymaganego formatu, takiego jak CSV, XML, JSON itp. Ponadto do przewidywań dokonywanych przez sztuczną inteligencję dodawane są dodatkowe reguły zdefiniowane przez użytkownika. Może to obejmować zasady formatowania danych wyjściowych, dodatkowe ograniczenia dotyczące wyodrębnianych informacji itp.
W poniższej sekcji przyjrzymy się niektórym metrykom, których możemy użyć do pomiaru wydajności parsera PDF.
Chcesz przekonwertować PDF plików do Arkusze Google ? Sprawdzić Nanonets ' za darmo Konwerter plików PDF na CSV. Dowiedz się, jak zautomatyzować cały przepływ pracy z plikami PDF do Arkuszy Google za pomocą Nanonets.

Metryki mierzące wydajność konwertera plików PDF
Ponieważ większość konwerterów PDF będzie używana do przetwarzania faktur lub powiązanych zadań, dokładność i szybkość wyodrębniania tabeli z dokumentu PDF jest krytycznym czynnikiem przy ocenie wydajności konwertera PDF.
2. Wielojęzyczność:
Większość dużych firm musi otrzymywać faktury w wielu różnych językach. Parser PDF powinien albo obsługiwać wielojęzyczne analizowanie po wyjęciu z pudełka, albo powinien zapewniać opcję, dzięki której użytkownicy mogą trenować model przy użyciu niestandardowych danych.
3. Integracja z oprogramowaniem księgowym:
Idealny konwerter plików PDF powinien być modułem plug and play, który można łatwo dodać do istniejącego obieg dokumentów. Powinien obsługiwać integrację z popularnymi programami księgowymi, takimi jak QuickBooks, Xero, Wave itp.
4. Łatwy i intuicyjny:
Narzędzie będzie najprawdopodobniej obsługiwane przez użytkowników nietechnicznych. Byłoby korzystne, gdyby można było go obsługiwać przy minimalnej wiedzy technicznej.
Różne metody konwertowania plików PDF na Arkusze Google
1. Używanie Dokumentów Google do konwersji plików PDF na Arkusze Google
Dysk Google ma wbudowaną funkcję rozpoznawania tabel i tekstu w prostych dokumentach PDF. Musisz po prostu:
-
Prześlij plik PDF na Dysk Google
-
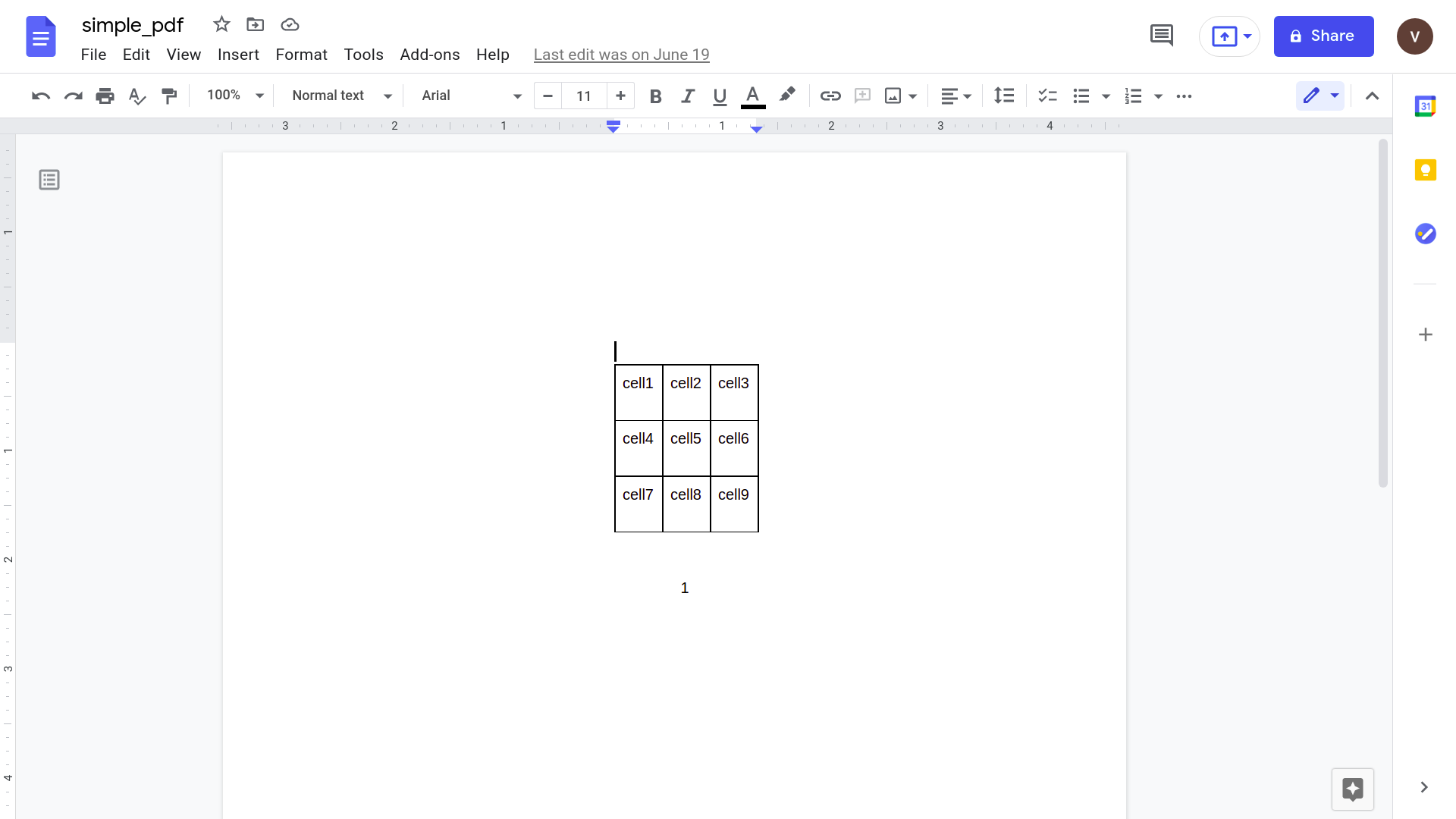
Kliknij „Otwórz w Dokumentach Google”
-
Skopiuj żądane dane i wklej je do Arkuszy Google
Chociaż wydaje się, że to działa dobrze, spróbujmy czegoś bardziej praktycznego. Rozważ tę prostą fakturę.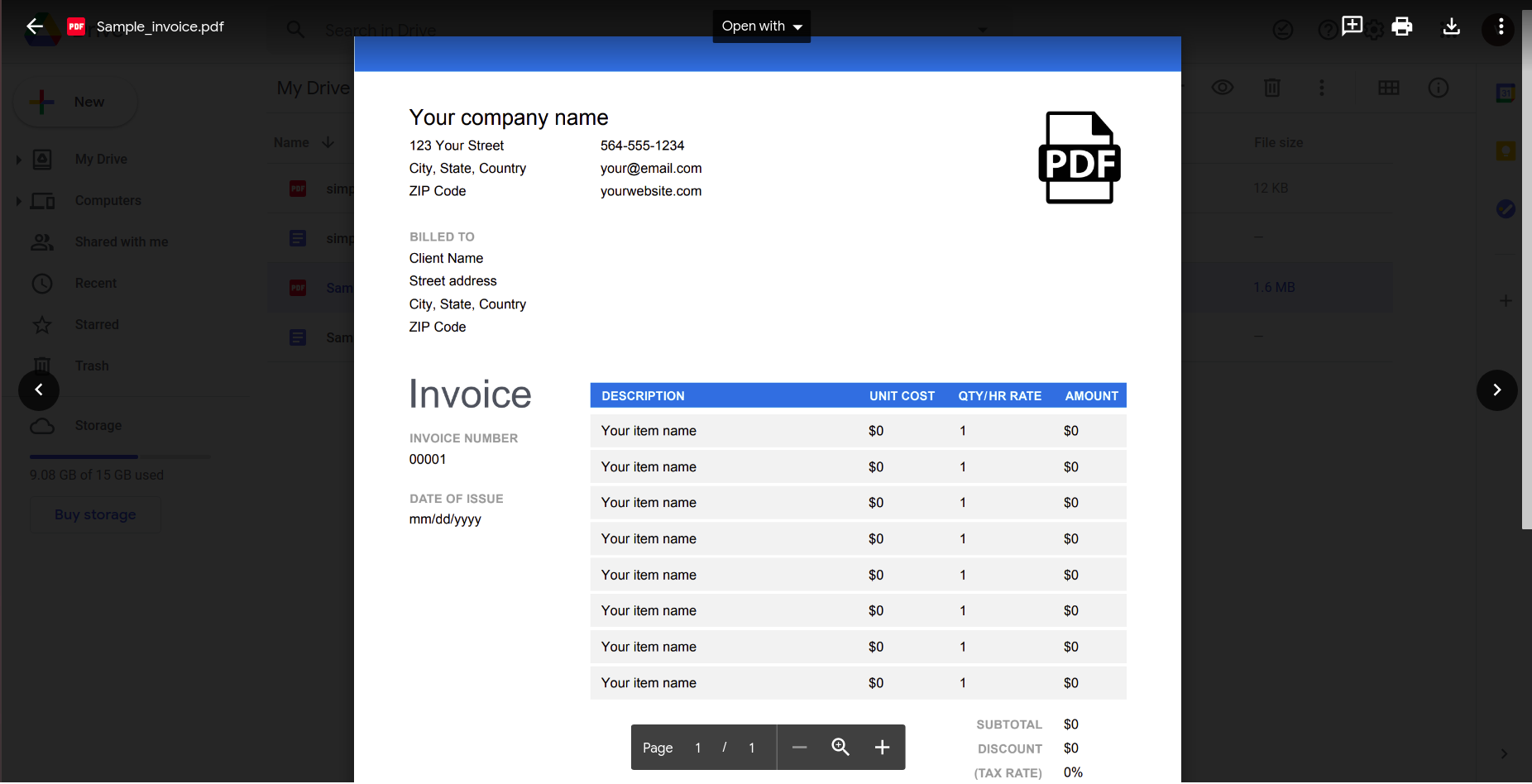
Otwarcie tego za pomocą aplikacji Dokumenty Google daje następujący wynik.
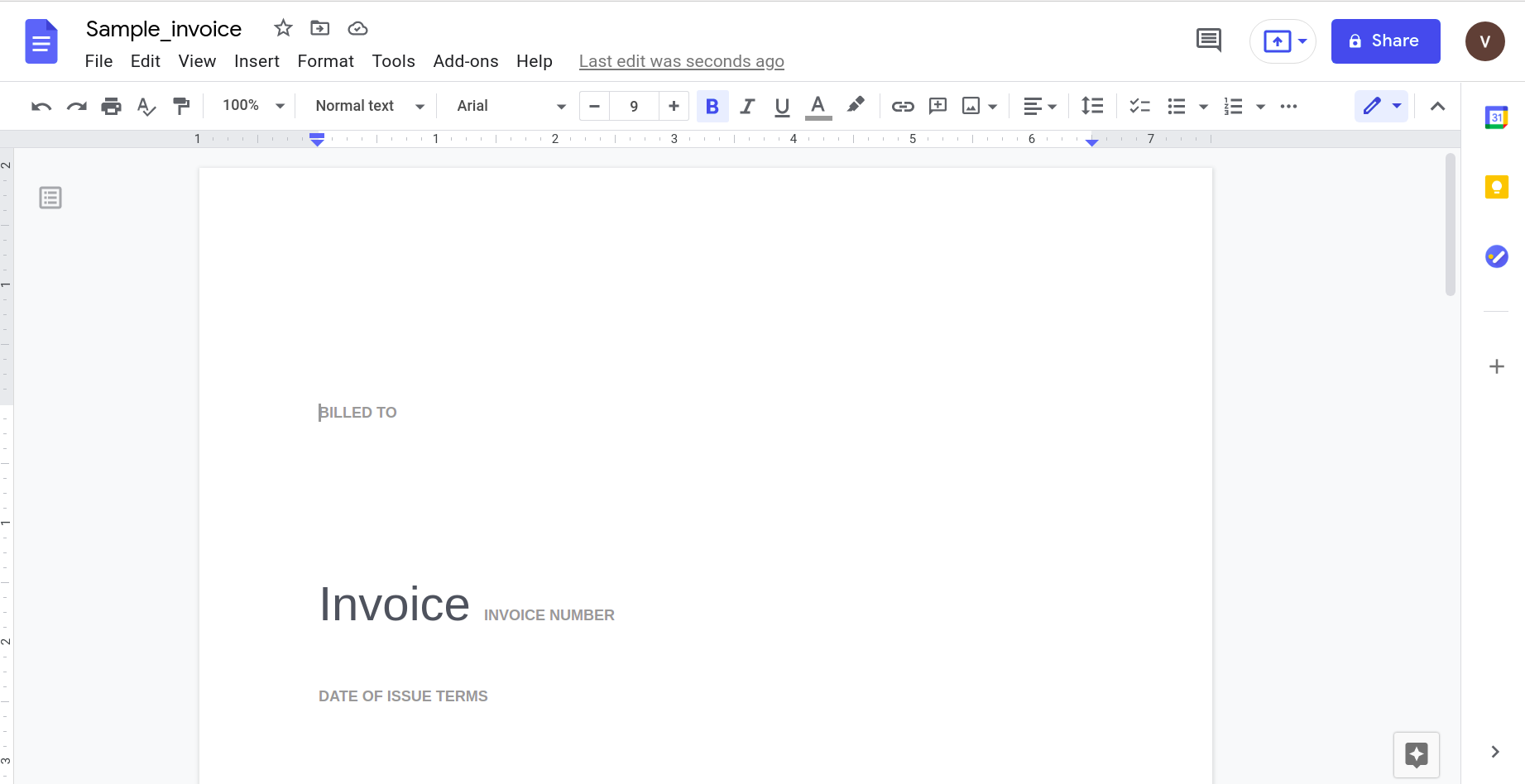
Oczywiście, wraz ze wzrostem złożoności dokumentu, musimy polegać na bardziej wyrafinowanych narzędziach do rozpoznawania danych.
2. Korzystanie z narzędzi online:
Kilka narzędzi online, takich jak ekstraktor tabel PDF, Online2PDF itp., bezpośrednio integruje się z Dyskiem Google i zapewnia gotową możliwość konwertowania dokumentów PDF na Arkusze Google.
Jednak podczas testowania tych narzędzi przy użyciu pokazanego powyżej przykładowego pliku PDF z fakturą tabele nie zostały wykryte w większości przypadków.
Chcesz przekonwertować PDF plików do Arkusze Google ? Sprawdzić Nanonets ' za darmo Konwerter plików PDF na CSV. Dowiedz się, jak zautomatyzować cały przepływ pracy PDF do Arkuszy Google za pomocą Nanonet, jak pokazano poniżej.
Automatyzacja procesu konwersji pliku PDF na Arkusze Google
Za pomocą poniższych narzędzi możemy całkowicie zautomatyzować proces parsowania pliku PDF i wyodrębniania danych do formularza Arkuszy Google.
1. Korzystanie z webhooków:
Webhook to niestandardowe zdefiniowane żądania HTTP. Są one zwykle wyzwalane w przypadku zdarzenia, tzn. gdy wystąpi zdarzenie, aplikacja wysyła informacje pod predefiniowany adres URL.
Jak możesz to wykorzystać do automatyzacji przepływu pracy? Rozważmy typowy przypadek użycia przetwarzania faktur. Otrzymujesz wiele faktur od swoich dostawców i przesyłasz je do swojego konwertera PDF na Arkusze Google, który znajduje się w chmurze. Skąd wiesz, kiedy modelka zakończyła przetwarzanie dokumentów?
Zamiast ręcznie sprawdzać, czy konwersja została ukończona, możesz po prostu skorzystać z webhooka, który powiadomi Cię, gdy dane z pliku PDF zostaną wyodrębnione do dokumentu Arkuszy Google.
2. Korzystanie z API
API oznacza interfejs programowania aplikacji. Korzystając z odpowiednich wywołań interfejsu API, konwersja dokumentów PDF na Arkusze Google może okazać się tak prosta, jak napisanie następujących wierszy kodu:
#Feed the PDF documents into the PDF to Google sheets converter
Success_code, unique_id = NanonetsAPI.uploaddata(PDF_documents)
Jeśli Twoja firma skonfigurowała już integrację z Webhooks, otrzymasz powiadomienie, gdy Twoje dokumenty PDF zostaną pomyślnie przekonwertowane. Następnie możesz pobrać formularz Arkuszy Google, korzystając z interfejsu API pokazanego poniżej.
#Download Google Sheets forms
Google_sheets_data = NanonetsAPI.downloaddata(unqiue_id)
PDF do Arkuszy Google z Nanonets
Parser plików PDF Nanonets sprawia, że analizowanie i konwersja są łatwe i dokładne. Do analizy przykładowej faktury wykorzystano parser PDF. W tej sekcji zademonstrowano łatwość obsługi i dokładność narzędzia. Zamiast mówić o tym, jakie to wspaniałe, poniższe obrazy trafnie ilustrują tę kwestię.
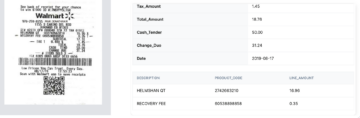
Poniższy obraz to zrzut ekranu przykładowej faktury, która została podana do parsera Nanonets PDF.
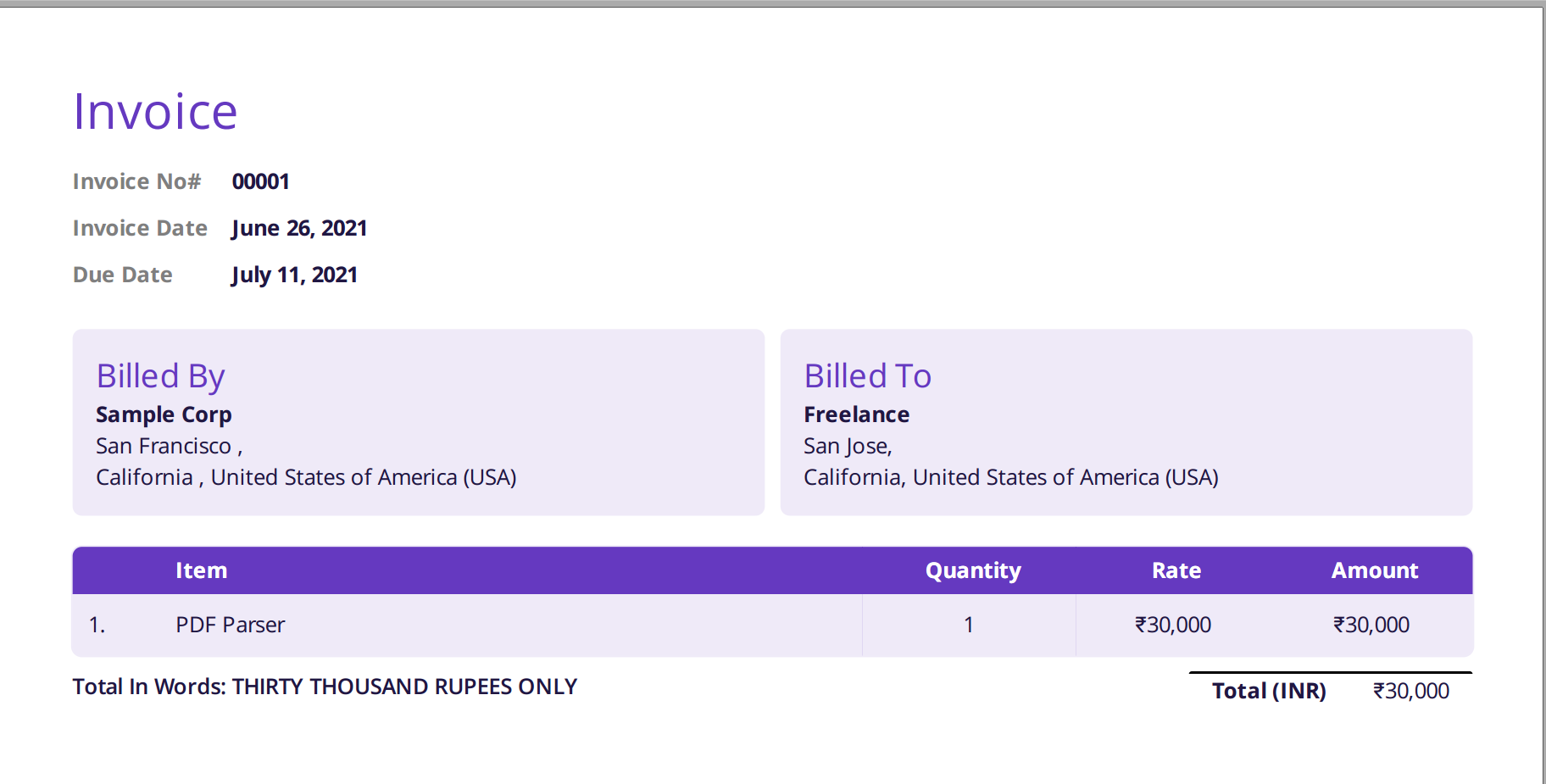
Po prostu przejdź do witryny Nanonets i prześlij fakturę. Konwersja zajmuje tylko kilka sekund, po czym przeanalizowane dane można pobrać w różnych formatach, takich jak CSV, XLSX itp. (sprawdź Nanonets' Konwerter plików PDF na CSV)
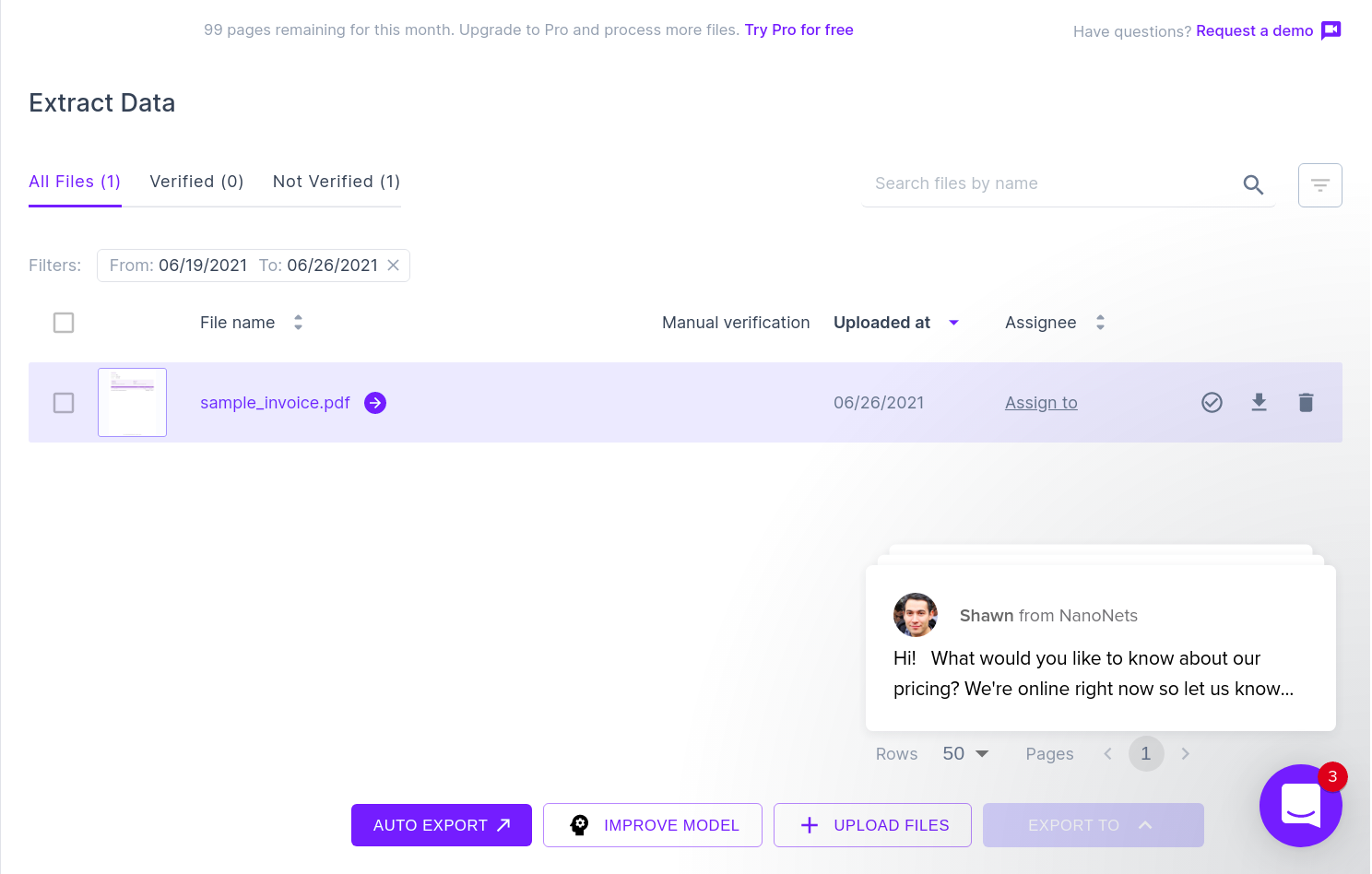
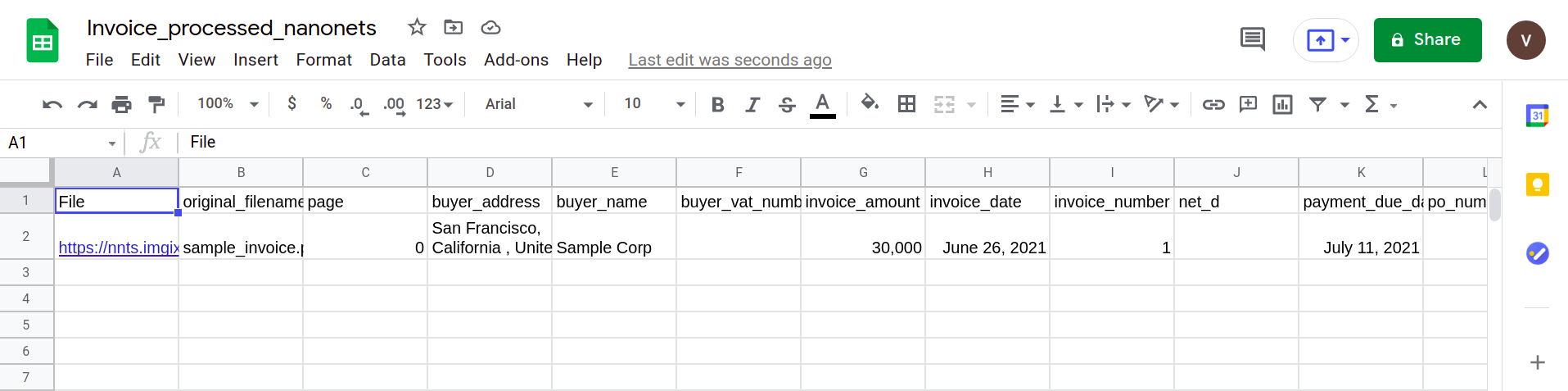
Następny obraz przedstawia zrzut ekranu pliku CSV, który zawiera przeanalizowane dane z dokumentu PDF.

Na koniec, aby przekonwertować plik CSV na formularz arkuszy Google, wystarczy przesłać plik XLSX/CSV na dysk Google. Ten krok można zautomatyzować, korzystając z interfejsów API dysków Google.
W poniższej sekcji pokazano, jak można utworzyć prosty potok przy użyciu parsera Nanonets PDF.
Chcesz wyodrębnić informacje z dokumentów PDF i przekonwertować/dodać je do dokumentu Arkuszy Google? Sprawdź Nanonet™ aby zautomatyzować eksport dowolnych informacji z dowolnego dokumentu PDF do Arkuszy Google!
Tworzenie prostego potoku
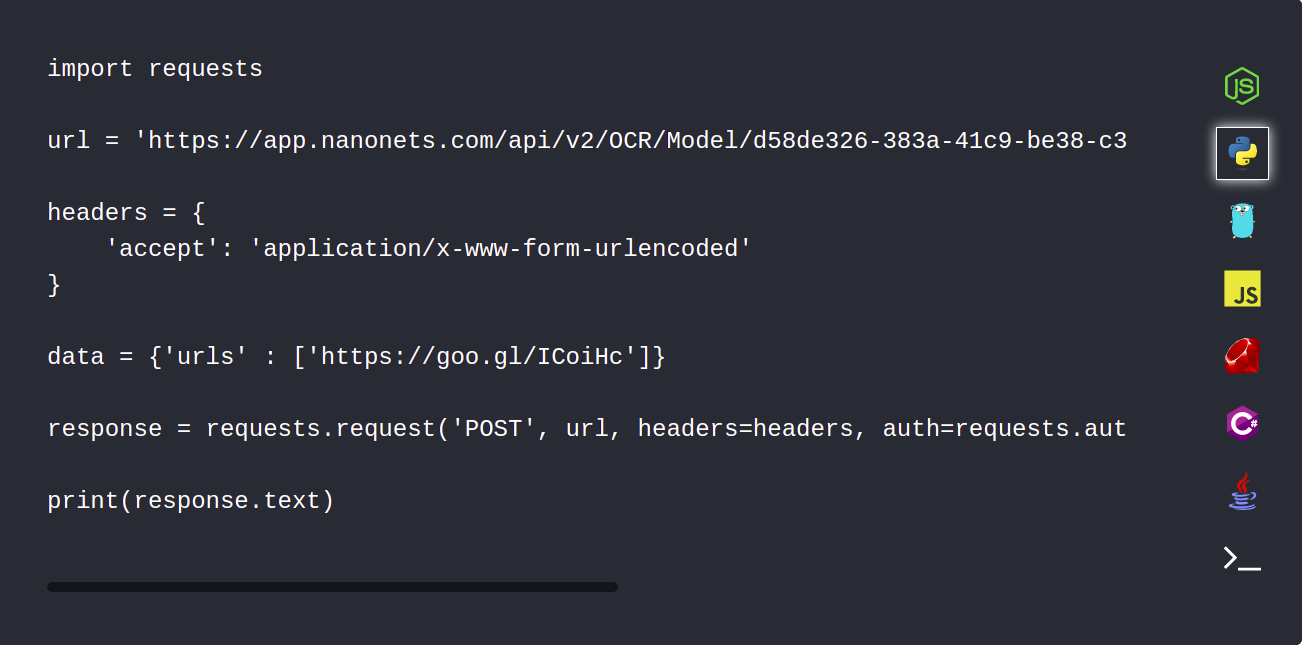
1. Automatycznie przesyłaj dokumenty PDF za pomocą Nanonets API
Interfejs API Nanonets umożliwia automatyczne przesyłanie dokumentów, które muszą zostać przeanalizowane. Poniższy fragment kodu pokazuje, jak można to zrobić za pomocą Pythona.
2. Użyj integracji webhooków, aby otrzymać powiadomienie po zakończeniu parsowania
Webhooki można skonfigurować tak, aby automatycznie powiadamiały Cię o przeanalizowaniu dokumentów.
3. Przejrzyj i prześlij do Arkuszy Google
Pobierz i przejrzyj pliki CSV, aby upewnić się, że wszystko jest w porządku, i prześlij dane do Arkuszy Google za pomocą interfejsu API dysku Google.
Krawędź nanonetów
Oto kilka funkcji Nanonets PDF Parser, które czynią go idealnym narzędziem dla Twojej firmy.
1. Integracje zewnętrzne:
Model nanonetów można łatwo zintegrować z MySql, Quickbooks, Salesforce itp. Oznacza to, że bieżący przepływ pracy pozostaje niezakłócony, a konwerter nanonetów można po prostu podłączyć jako dodatkowy moduł.
2. Wysoka dokładność i krótki czas przetwarzania:
Parser Nanonets PDF ma dokładność ponad 95%+, która jest znacznie wyższa w porównaniu z jego konkurentami.
3. Fajne funkcje przetwarzania końcowego:
Załóżmy, że Twoja baza danych została zintegrowana z modelem nanonets. Model automatycznie wypełnia niektóre pola (dane z Twojej bazy danych) na podstawie danych wyodrębnionych z dokumentu. Na przykład:
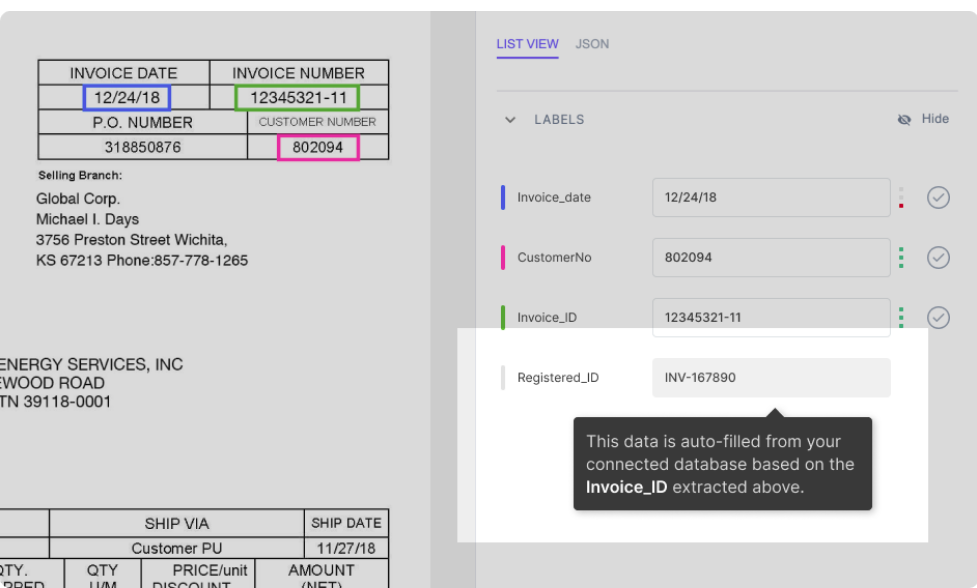
Jak pokazano na rysunku, pole Registered_ID jest wypełniane automatycznie (przez wyszukiwanie w bazie danych) na podstawie identyfikatora faktury wyodrębnionego z pliku PDF.
4. Prosty i intuicyjny interfejs
Chociaż ta funkcja jest niedoceniana, uważam, że interfejs użytkownika i UX są na miejscu. Cały proces rejestracji, wgrania dokumentu i parsowania danych zajął mniej niż 5 minut. To prawie tyle, ile zajmuje mój laptop, aby się uruchomić!
5. Ogromna baza klientów
Jeśli nadal masz wątpliwości co do wykorzystania Nanonetów do automatyzacji pracy, przyjrzyj się niektórym firmom, które korzystają z ich usług.
- Deloitte
- Sherwin-Williams
- Drzwiczki
- P&G
Chcesz wyodrębnić informacje z dokumentów PDF i przekonwertować/dodać je do dokumentu Arkuszy Google? Sprawdź Nanonet™ aby zautomatyzować eksport dowolnych informacji z dowolnego dokumentu PDF do Arkuszy Google!
Wnioski
W tym poście przyjrzeliśmy się, jak możesz zautomatyzować przepływ pracy za pomocą konwertera plików PDF na Arkusze Google. Początkowo dowiedzieliśmy się o konieczności konwersji dokumentów PDF do Arkuszy Google, a następnie o wyzwaniach, jakie stoją przed tym procesem. Następnie zagłębiliśmy się w podejścia stosowane przez nowoczesne parsery do analizowania dokumentów PDF, a także wdrożyliśmy niektóre z typowych podejść. Dowiedzieliśmy się także jak możemy całkowicie zautomatyzować konwersję wykorzystując integracje zewnętrzne takie jak webhooki i API. Na koniec użyliśmy narzędzia Nanonets do przeanalizowania przykładowej faktury, wyodrębnienia danych do formularza Arkuszy Google, a także sprawdziliśmy niektóre z jego ciekawych funkcji przetwarzania końcowego.
Czy dałeś szansę modelowi Nanonets? Jeśli tak, zostaw poniżej komentarz dotyczący Twojego doświadczenia z narzędziem. Jeśli nie, śmiało wypróbuj. To może po prostu uczynić Twój dzień!
- AI
- AI i uczenie maszynowe
- ai sztuka
- generator sztuki ai
- masz robota
- sztuczna inteligencja
- certyfikacja sztucznej inteligencji
- sztuczna inteligencja w bankowości
- robot sztucznej inteligencji
- roboty sztucznej inteligencji
- oprogramowanie sztucznej inteligencji
- blockchain
- konferencja blockchain ai
- pomysłowość
- sztuczna inteligencja konwersacyjna
- konferencja kryptograficzna
- Dall's
- głęboka nauka
- google to
- uczenie maszynowe
- pdf do arkuszy Google
- plato
- Platon Ai
- Analiza danych Platona
- Gra Platona
- PlatoDane
- platogaming
- skala ai
- składnia
- zefirnet