Wprowadzenie
Widzieliśmy już kilka fantazyjnych terminów określających sztuczną inteligencję i głębokie uczenie się, takie jak wstępnie wytrenowane modele, uczenie transferowe itp. Pozwól, że nauczę Cię szeroko stosowanej technologii i jednej z najważniejszych i najskuteczniejszych: transferu uczenia się za pomocą YOLOv5.
You Only Look Once, czyli YOLO, to jedna z najczęściej stosowanych metod identyfikacji obiektów opartych na głębokim uczeniu się. Korzystając z niestandardowego zestawu danych, w tym artykule dowiesz się, jak trenować jedną z jego najnowszych odmian, YOLOv5.
Cele kształcenia
- Ten artykuł skupi się głównie na szkoleniu modelu YOLOv5 na niestandardowej implementacji zestawu danych.
- Zobaczymy, czym są wstępnie wytrenowane modele i zobaczymy, czym jest transfer learning.
- Zrozumiemy, czym jest YOLOv5 i dlaczego używamy wersji 5 YOLO.
Więc nie marnując czasu, zacznijmy od procesu
Spis treści
- Wstępnie przeszkolone modele
- Przenieś naukę
- Co i dlaczego YOLOv5?
- Kroki związane z transferem uczenia się
- Realizacja
- Niektóre wyzwania, którym możesz stawić czoła
- Wnioski
Wstępnie przeszkolone modele
Być może słyszałeś, że analitycy danych często używają terminu „wstępnie wytrenowany model”. Po wyjaśnieniu, co robi model/sieć głębokiego uczenia się, wyjaśnię ten termin. Model głębokiego uczenia się to model zawierający różne warstwy ułożone razem, aby służyły pojedynczemu celowi, takiemu jak klasyfikacja, wykrywanie itp. Sieci głębokiego uczenia się uczą się, odkrywając skomplikowane struktury w danych, które są do nich dostarczane i zapisując wagi w pliku, który są później wykorzystywane do wykonywania podobnych zadań. Wstępnie wytrenowane modele są już wytrenowanymi modelami Deep Learning. Oznacza to, że są już przeszkoleni na ogromnym zbiorze danych zawierającym miliony obrazów.
Oto jak TensorFlow strona internetowa definiuje wstępnie wytrenowane modele: Wstępnie przeszkolony model to zapisana sieć, która została wcześniej przeszkolona na dużym zbiorze danych, zazwyczaj w ramach zadania klasyfikacji obrazów na dużą skalę.
Niektóre wysoce zoptymalizowane i niezwykle wydajne wstępnie wytrenowane modele są dostępne w internecie. Różne modele są używane do wykonywania różnych zadań. Niektóre wstępnie wytrenowane modele to VGG-16, VGG-19, YOLOv5, YOLOv3 i ResNet 50.
To, którego modelu użyć, zależy od zadania, które chcesz wykonać. Na przykład, jeśli chcę wykonać tzw wykrywanie obiektów zadania, skorzystam z modelu YOLOv5.
Przenieś naukę
Przenieś naukę jest najważniejszą techniką, która ułatwia zadanie analityka danych. Szkolenie modelu to ciężkie i czasochłonne zadanie; jeśli model jest szkolony od podstaw, zwykle nie daje to zbyt dobrych rezultatów. Nawet jeśli wytrenujemy model podobny do wstępnie wytrenowanego modelu, nie będzie on działał tak skutecznie, a wytrenowanie modelu może zająć tygodnie. Zamiast tego możemy użyć wstępnie wyszkolonych modeli i wykorzystać już wyuczone wagi, trenując je na niestandardowym zbiorze danych w celu wykonania podobnego zadania. Modele te są bardzo wydajne i dopracowane pod względem architektury i wydajności, a także osiągnęły szczyt, osiągając lepsze wyniki w różnych konkursach. Modele te są trenowane na bardzo dużych ilościach danych, co czyni je bardziej zróżnicowanymi pod względem wiedzy.
Tak więc uczenie się transferowe zasadniczo oznacza przenoszenie wiedzy zdobytej podczas trenowania modelu na poprzednich danych, aby pomóc modelowi uczyć się lepiej i szybciej, aby wykonać inne, ale podobne zadanie.
Na przykład użycie YOLOv5 do wykrywania obiektów, ale obiekt jest czymś innym niż poprzednie dane obiektu.
Co i dlaczego YOLOv5?
YOLOv5 to wstępnie wytrenowany model, który oznacza, że wyglądasz tylko wtedy, gdy wersja 5 jest używana do wykrywania obiektów w czasie rzeczywistym i okazała się bardzo wydajna pod względem dokładności i czasu wnioskowania. Istnieją inne wersje YOLO, ale jak można przewidzieć, YOLOv5 działa lepiej niż inne wersje. YOLOv5 jest szybki i łatwy w użyciu. Opiera się na frameworku PyTorch, który ma większą społeczność niż Yolo v4 Darknet.
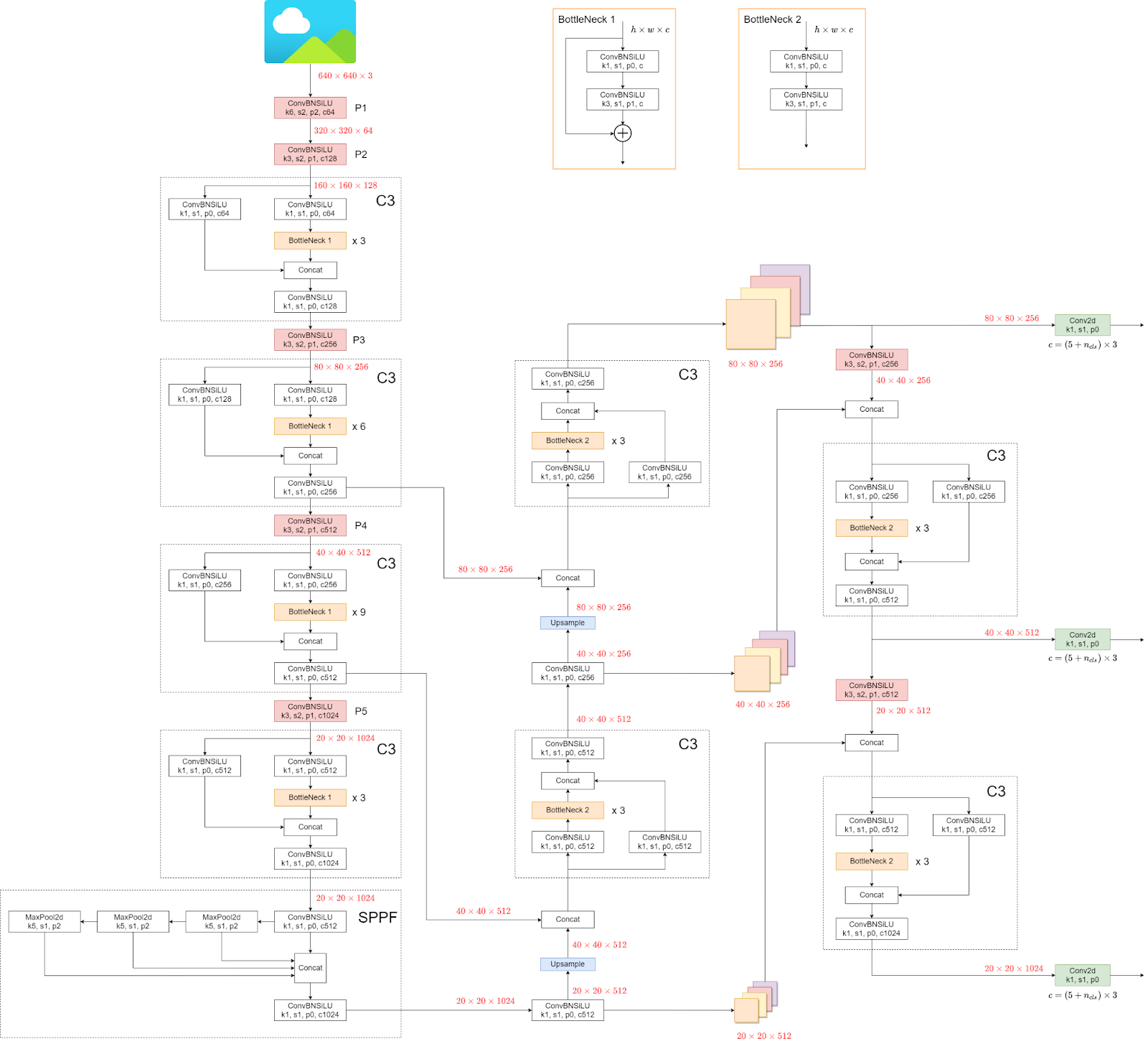
Przyjrzymy się teraz architekturze YOLOv5.
Struktura może wyglądać zagmatwana, ale to nie ma znaczenia, ponieważ nie musimy patrzeć na architekturę, zamiast bezpośrednio korzystać z modelu i wag.
W nauczaniu transferowym używamy niestandardowego zestawu danych, tj. danych, których model nigdy wcześniej nie widział LUB danych, na których model nie był szkolony. Ponieważ model jest już przeszkolony na dużym zbiorze danych, mamy już wagi. Możemy teraz trenować model dla wielu epok na danych, na których chcemy pracować. Szkolenie jest wymagane, ponieważ model widział dane po raz pierwszy i będzie wymagał pewnej wiedzy, aby wykonać zadanie.
Kroki związane z transferem uczenia się
Transfer learning to prosty proces, który możemy wykonać w kilku prostych krokach:
- Przygotowywanie danych
- Właściwy format adnotacji
- Zmień kilka warstw, jeśli chcesz
- Ponownie wytrenuj model dla kilku iteracji
- Zatwierdź/przetestuj
Przygotowywanie danych
Przygotowanie danych może być czasochłonne, jeśli wybrane dane są nieco duże. Przygotowanie danych oznacza dodawanie adnotacji do obrazów, czyli proces oznaczania obrazów poprzez utworzenie ramki wokół obiektu na obrazie. W ten sposób współrzędne zaznaczonego obiektu zostaną zapisane w pliku, który następnie zostanie wprowadzony do modelu w celu szkolenia. Jest kilka stron internetowych, np makesen.ai i roboflow.com, które mogą pomóc w etykietowaniu danych.
Oto, w jaki sposób możesz dodawać adnotacje do danych dla modelu YOLOv5 na stronie makeense.ai.
1. Odwiedzić https://www.makesense.ai/.
2. Kliknij Rozpocznij w prawym dolnym rogu ekranu.
3. Wybierz obrazy, które chcesz oznaczyć etykietami, klikając zaznaczone na środku pole.
Załaduj obrazy, które chcesz opatrzyć adnotacjami, i kliknij wykrywanie obiektów.
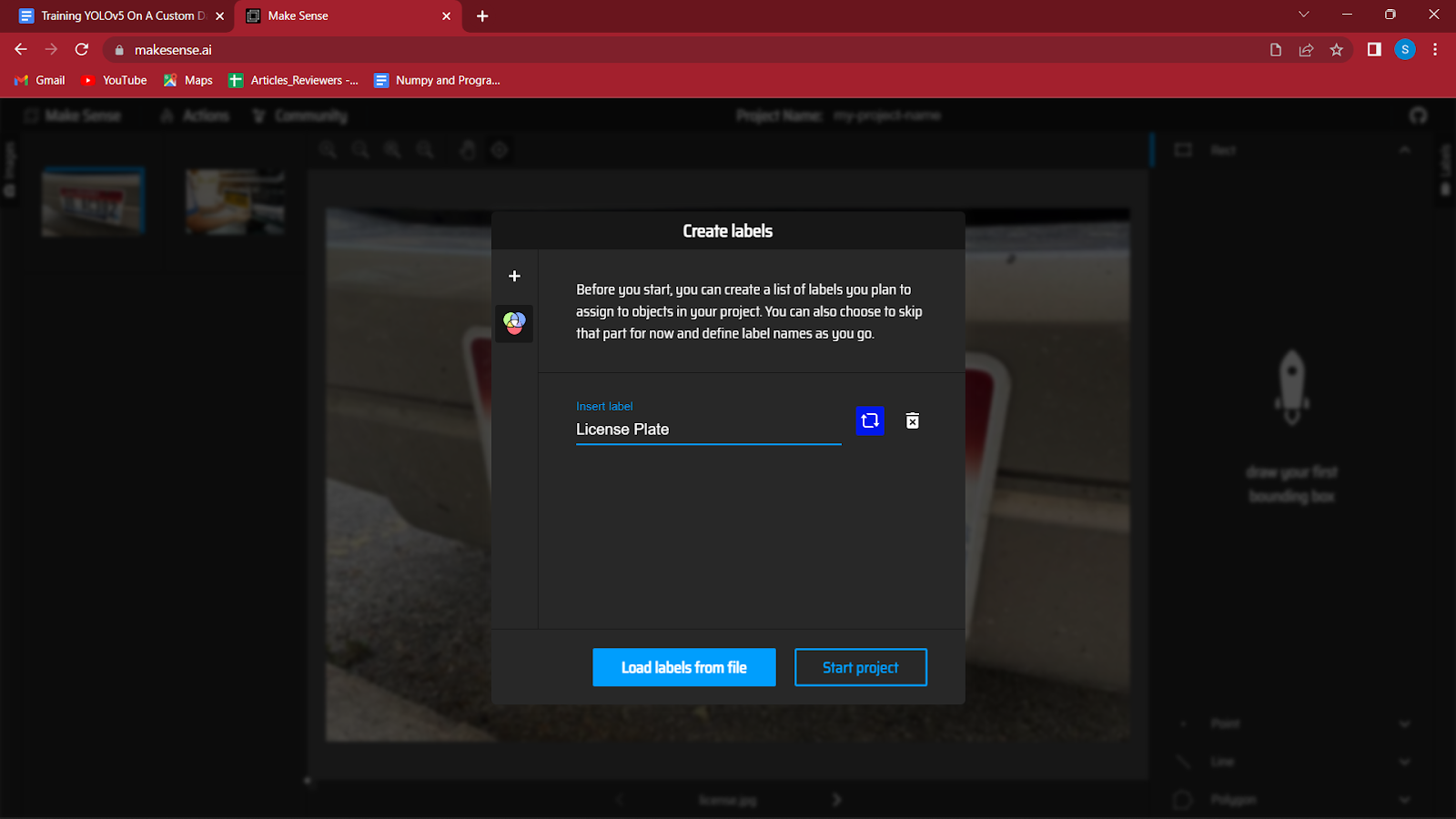
4. Po załadowaniu obrazów zostaniesz poproszony o utworzenie etykiet dla różnych klas Twojego zestawu danych.
Wykrywam tablice rejestracyjne na pojeździe, więc jedyną etykietą, której będę używać, jest „Tablica rejestracyjna”. Możesz utworzyć więcej etykiet, po prostu naciskając Enter, klikając przycisk „+” po lewej stronie okna dialogowego.
Po utworzeniu wszystkich etykiet kliknij przycisk Rozpocznij projekt.
Jeśli pominąłeś jakieś etykiety, możesz je później edytować, klikając czynności, a następnie edytując etykiety.
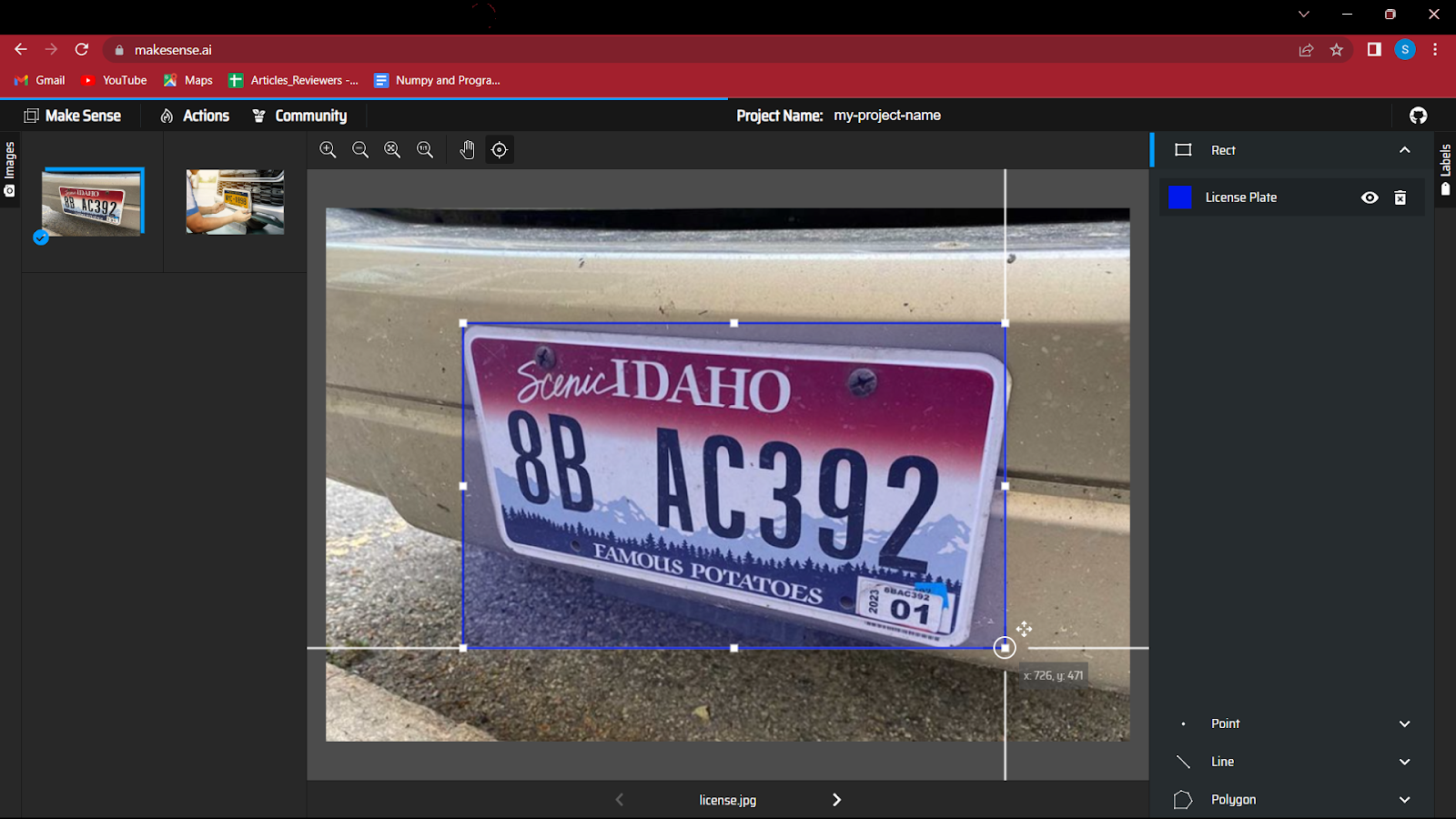
5. Zacznij tworzyć obwiednię wokół obiektu na obrazie. To ćwiczenie może początkowo wydawać się zabawne, ale przy bardzo dużych danych może być męczące.
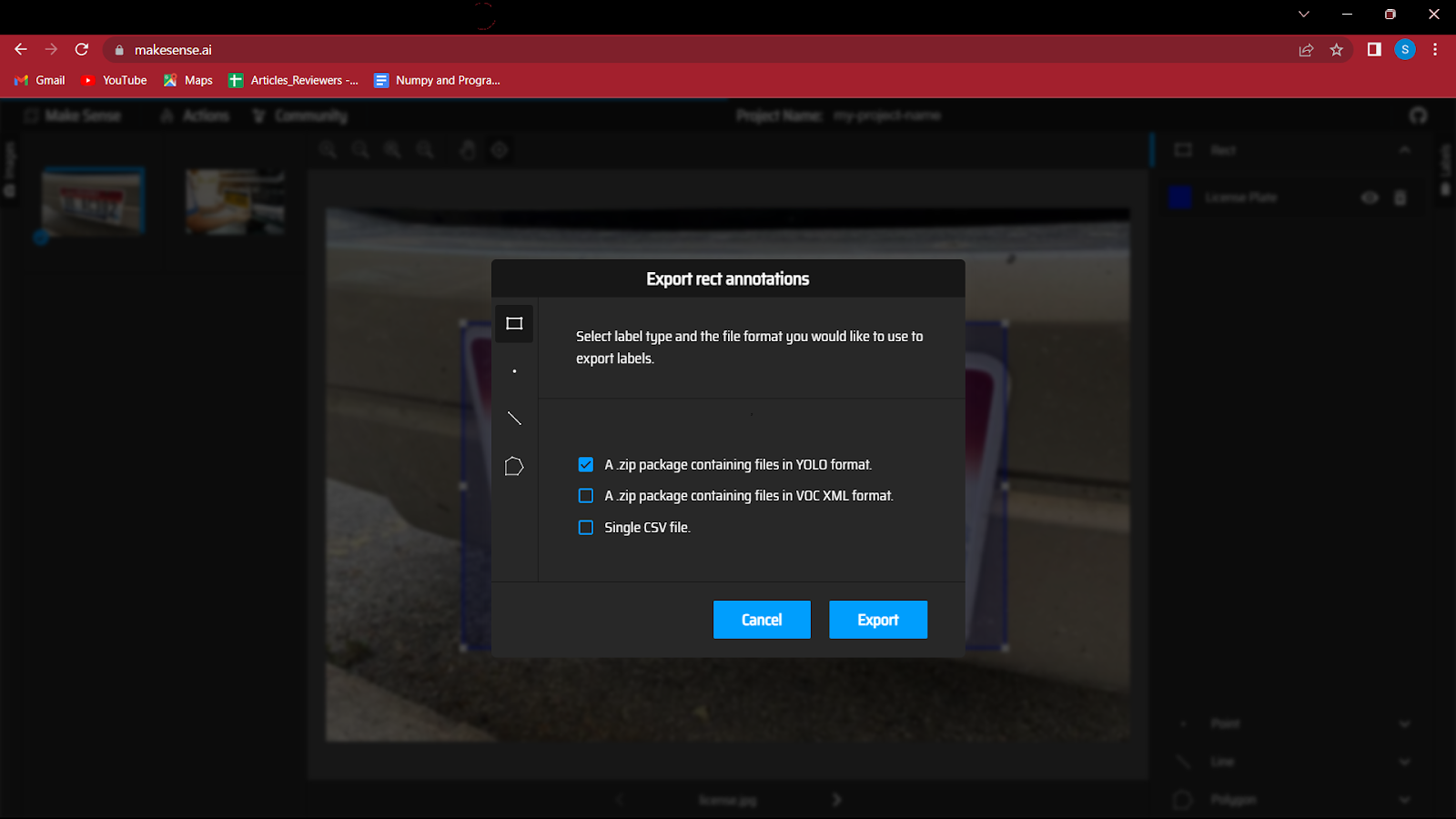
6. Po adnotacji wszystkich obrazów należy zapisać plik, który będzie zawierał współrzędne obwiedni wraz z klasą.
Musisz więc przejść do przycisku akcji i kliknąć adnotacje eksportu, nie zapomnij zaznaczyć opcji „Pakiet zip zawierający pliki w formacie YOLO”, ponieważ spowoduje to zapisanie plików we właściwym formacie wymaganym w modelu YOLO.
7. To ważny krok, więc postępuj zgodnie z nim ostrożnie.
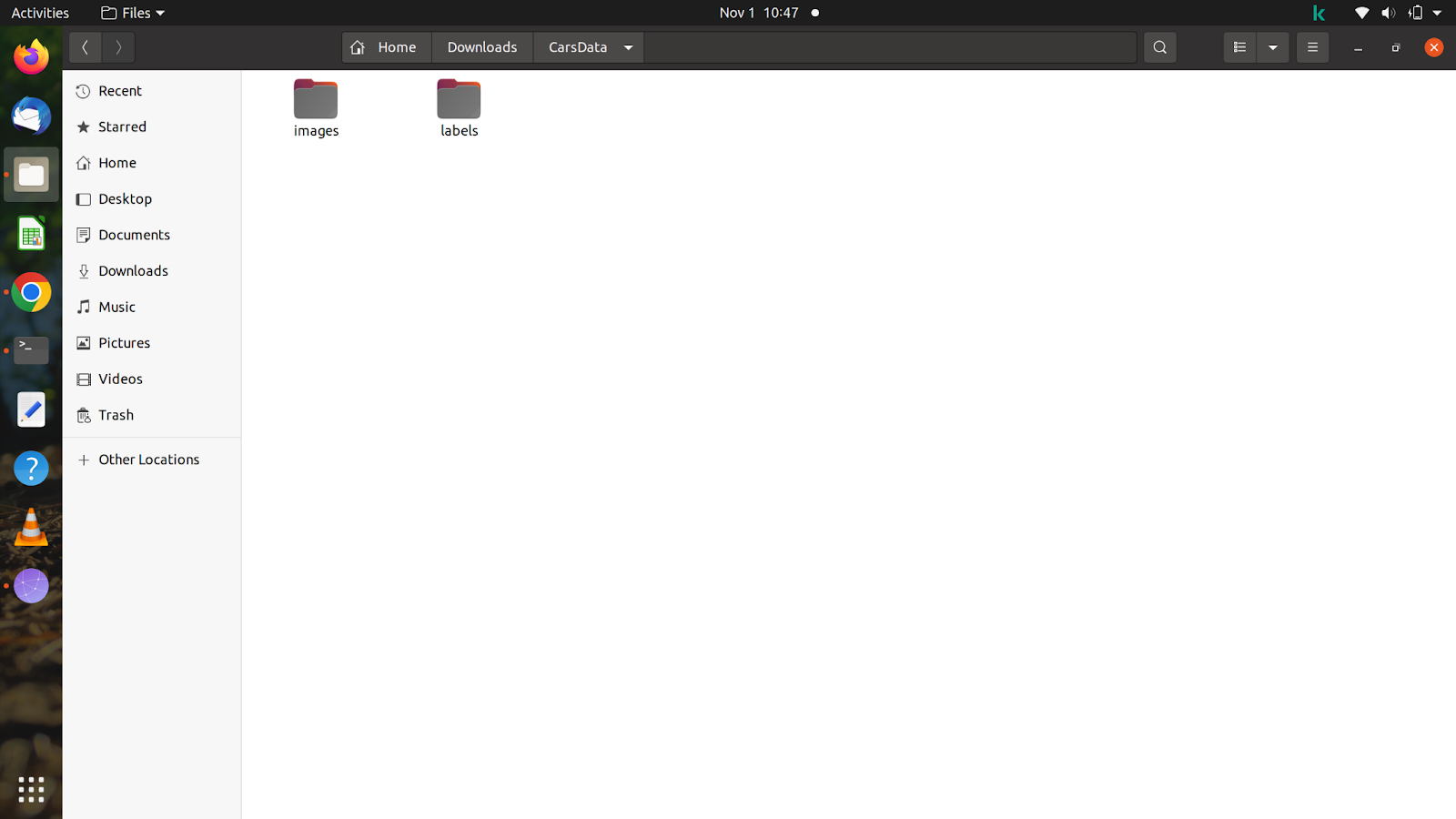
Po uzyskaniu wszystkich plików i obrazów utwórz folder o dowolnej nazwie. Kliknij folder i utwórz dwa kolejne foldery z obrazami nazw i etykietami w folderze. Nie zapomnij nazwać folderu tak samo jak powyżej, ponieważ model automatycznie wyszukuje etykiety po podaniu ścieżki szkoleniowej w poleceniu.
Aby dać ci wyobrażenie o folderze, utworzyłem folder o nazwie „CarsData”, aw nim dwa foldery – „obrazy” i „etykiety”.
Wewnątrz dwóch folderów musisz utworzyć jeszcze dwa foldery o nazwach „train” i „val”. W folderze obrazów możesz dzielić obrazy według swojej woli, ale musisz zachować ostrożność podczas dzielenia etykiety, ponieważ etykiety powinny pasować do obrazów, które podzieliłeś
8. Teraz utwórz plik ZIP z folderu i prześlij go na dysk, abyśmy mogli go użyć w colab.
Realizacja
Przejdziemy teraz do części implementacyjnej, która jest bardzo prosta, ale trudna. Jeśli nie wiesz, które pliki dokładnie zmienić, nie będziesz w stanie wytrenować modelu na niestandardowym zestawie danych.
Oto kody, których należy przestrzegać, aby trenować model YOLOv5 na niestandardowym zbiorze danych
Polecam korzystanie z Google colab do tego samouczka, ponieważ zapewnia on również procesor graficzny, który zapewnia szybsze obliczenia.
1. Klon !git https://github.com/ultralytics/yolov5
Spowoduje to utworzenie kopii repozytorium YOLOv5, które jest repozytorium GitHub utworzonym przez ultralytics.
2. cd yolov5
Jest to polecenie powłoki wiersza poleceń używane do zmiany bieżącego katalogu roboczego na katalog YOLOv5.
3. !pip install -r wymagania.txt
To polecenie zainstaluje wszystkie pakiety i biblioteki używane do uczenia modelu.
4. !Rozpakuj '/content/drive/MyDrive/CarsData.zip'
Rozpakowanie folderu zawierającego obrazy i etykiety w google colab
Nadchodzi najważniejszy krok…
Wykonałeś już prawie wszystkie kroki i musisz napisać jeszcze jeden wiersz kodu, który wytrenuje model, ale wcześniej musisz wykonać kilka dodatkowych kroków i zmienić niektóre katalogi, aby podać ścieżkę do niestandardowego zestawu danych i wytrenuj swój model na tych danych.
Oto, co musisz zrobić.
Po wykonaniu 4 powyższych kroków będziesz mieć folder yolov5 w swoim google colab. Przejdź do folderu yolov5 i kliknij folder „data”. Teraz zobaczysz folder o nazwie „coco128.yaml”.
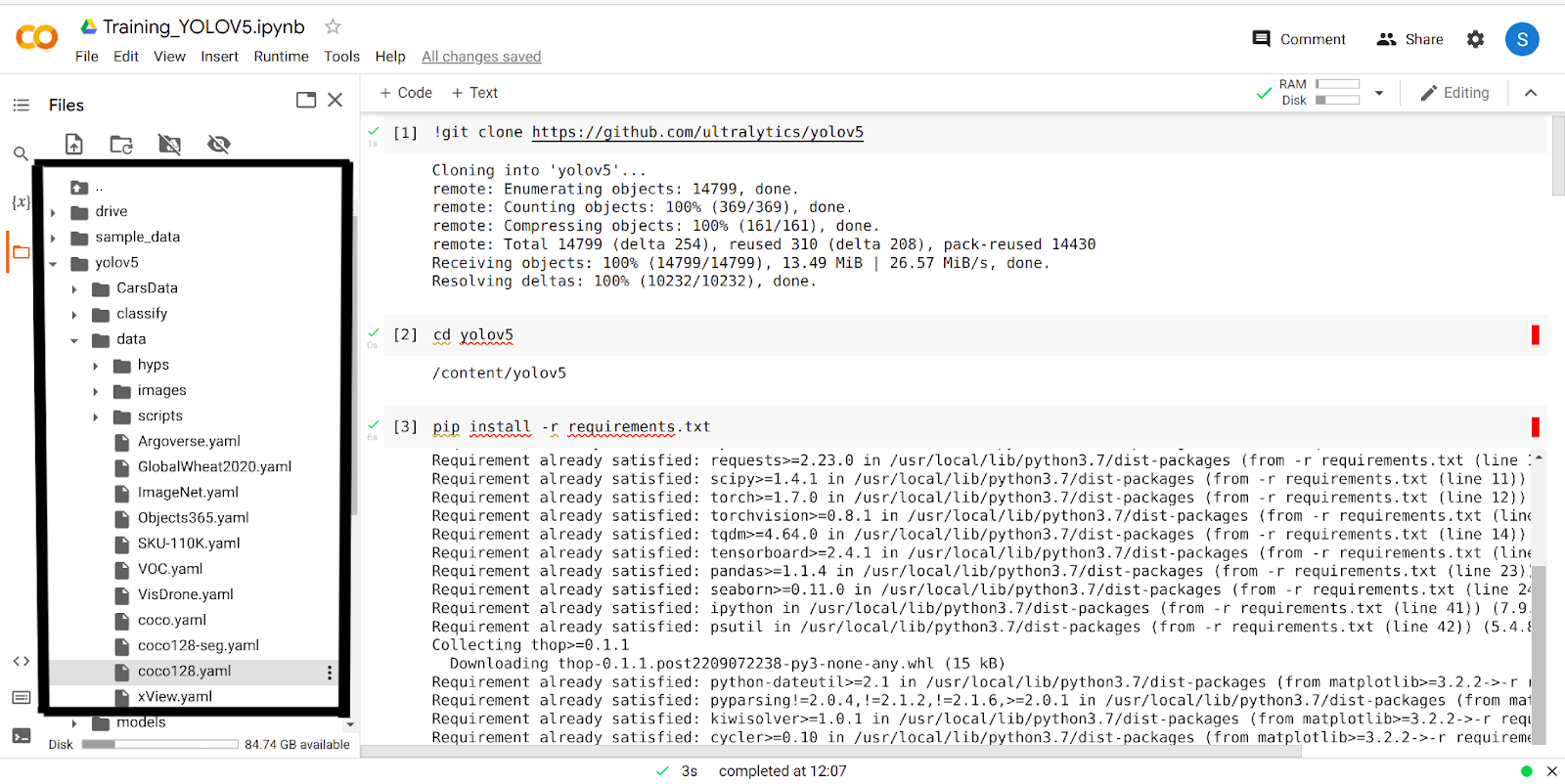
Śmiało i pobierz ten folder.
Po pobraniu folderu musisz wprowadzić w nim kilka zmian i przesłać go z powrotem do tego samego folderu, z którego został pobrany.
Przyjrzyjmy się teraz zawartości pliku, który pobraliśmy, a będzie on wyglądał mniej więcej tak.
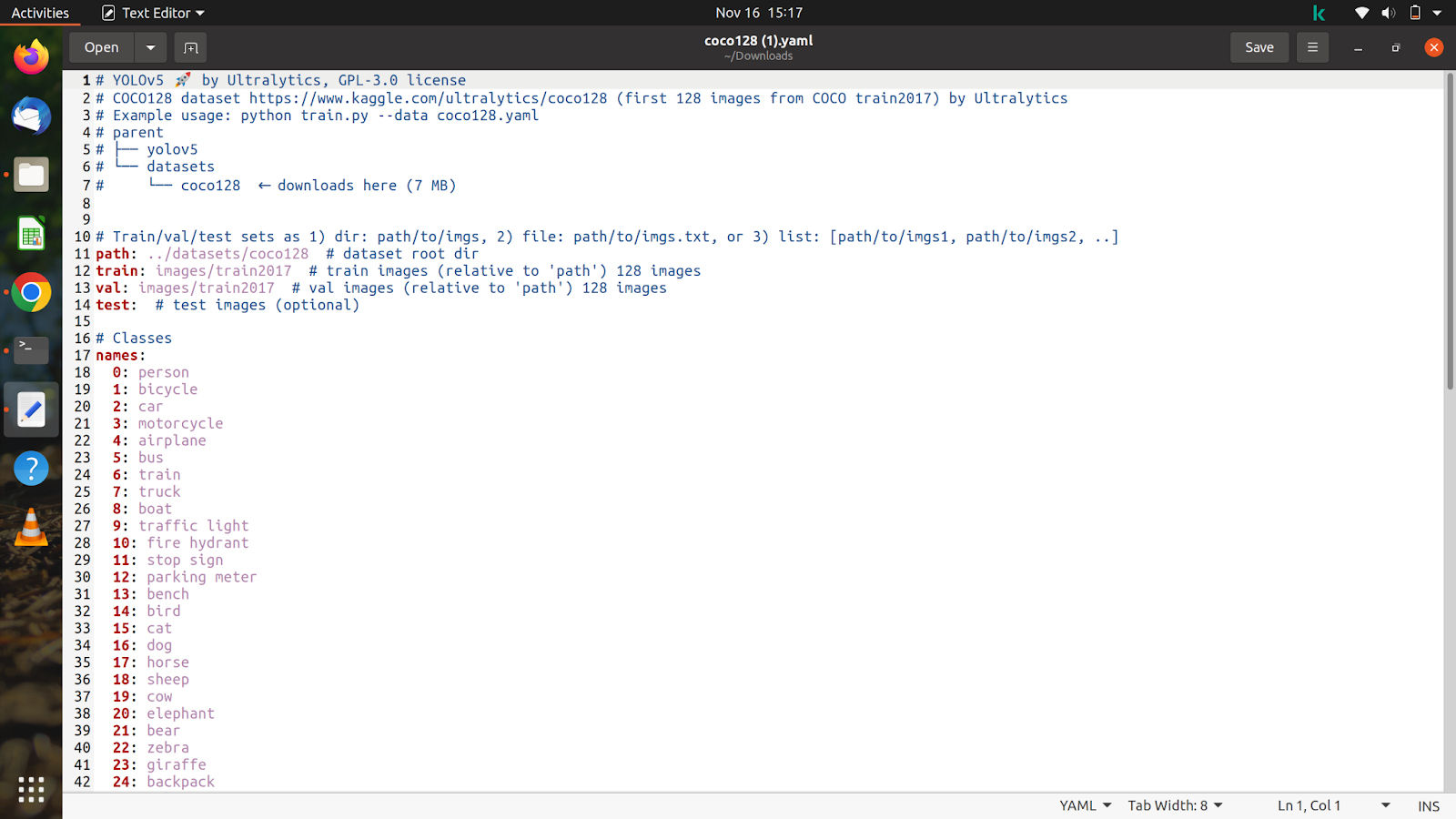
Zamierzamy dostosować ten plik zgodnie z naszym zestawem danych i adnotacjami.
Rozpakowaliśmy już zestaw danych na colab, więc skopiujemy ścieżkę naszego pociągu i obrazów weryfikacyjnych. Po skopiowaniu ścieżki obrazów pociągu, która będzie znajdować się w folderze zestawu danych i wygląda mniej więcej tak: „/content/yolov5/CarsData/images/train”, wklej ją do pliku coco128.yaml, który właśnie pobraliśmy.
Zrób to samo z obrazami testowymi i weryfikacyjnymi.
Teraz, gdy skończymy z tym, wymienimy liczbę klas, takich jak „nc: 1”. Liczba klas w tym przypadku wynosi tylko 1. Następnie wymienimy nazwę, jak pokazano na poniższym obrazku. Usuń wszystkie pozostałe klasy i część z komentarzem, która nie jest potrzebna, po czym nasz plik powinien wyglądać mniej więcej tak.
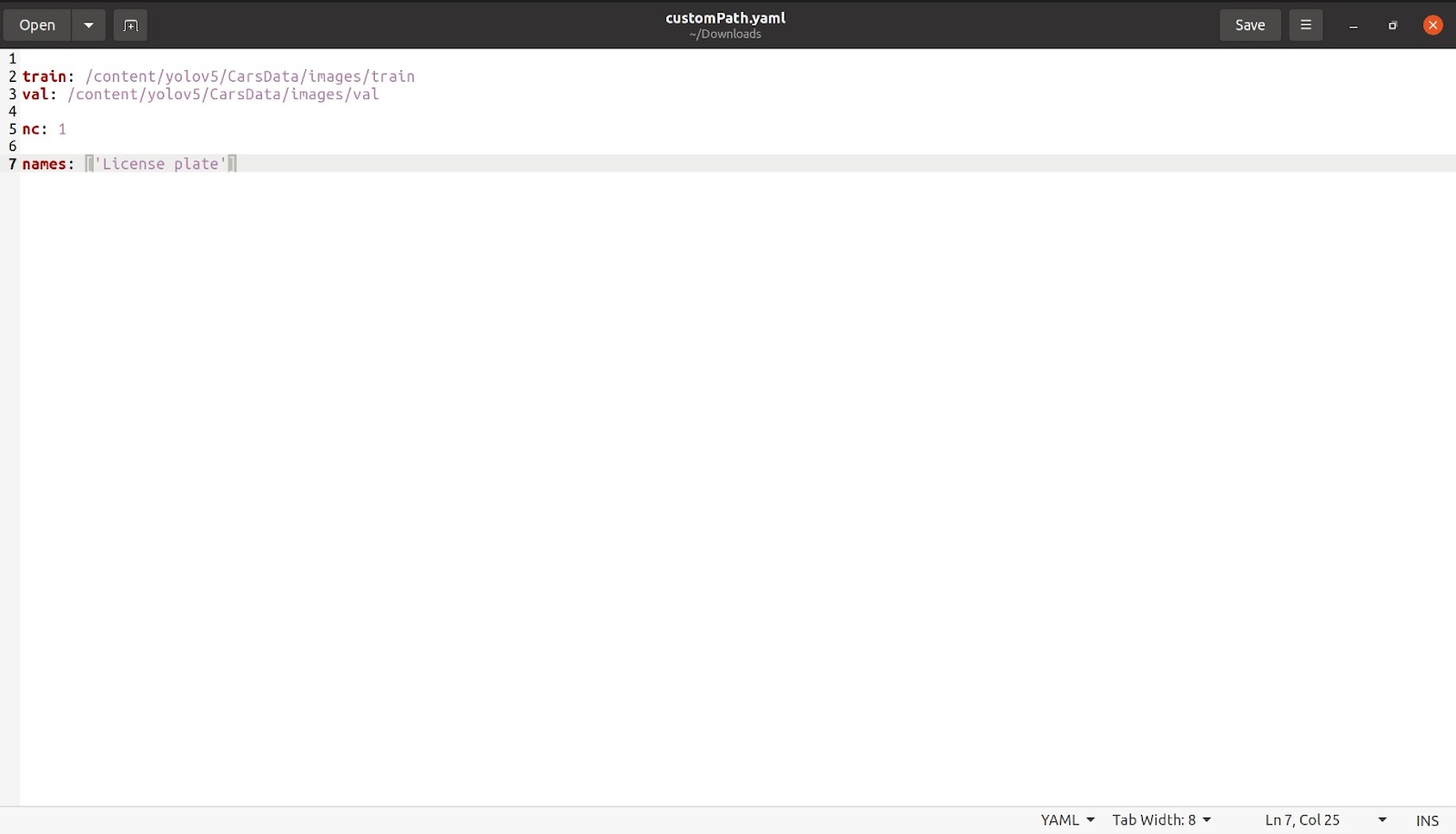
Zapisz ten plik pod dowolną nazwą. Zapisałem plik o nazwie customPath.yaml i teraz przesyłam ten plik z powrotem do colab w tym samym miejscu, gdzie znajdował się coco128.yaml.
Teraz skończyliśmy z częścią edycyjną i jesteśmy gotowi do trenowania modelu.
Uruchom następujące polecenie, aby wytrenować model pod kątem kilku interakcji w niestandardowym zbiorze danych.
Nie zapomnij zmienić nazwy przesłanego pliku ('customPath.yaml). Możesz także zmienić liczbę epok, w których chcesz trenować model. W tym przypadku zamierzam trenować model tylko przez 3 epoki.
5. !python train.py –img 640 –batch 16 –epochs 10 –data /content/yolov5/customPath.yaml –waga yolov5s.pt
Pamiętaj o ścieżce, do której przesyłasz folder. Jeśli ścieżka zostanie zmieniona, polecenia w ogóle nie będą działać.
Po uruchomieniu tego polecenia Twój model powinien rozpocząć trening, a na ekranie zobaczysz coś takiego.
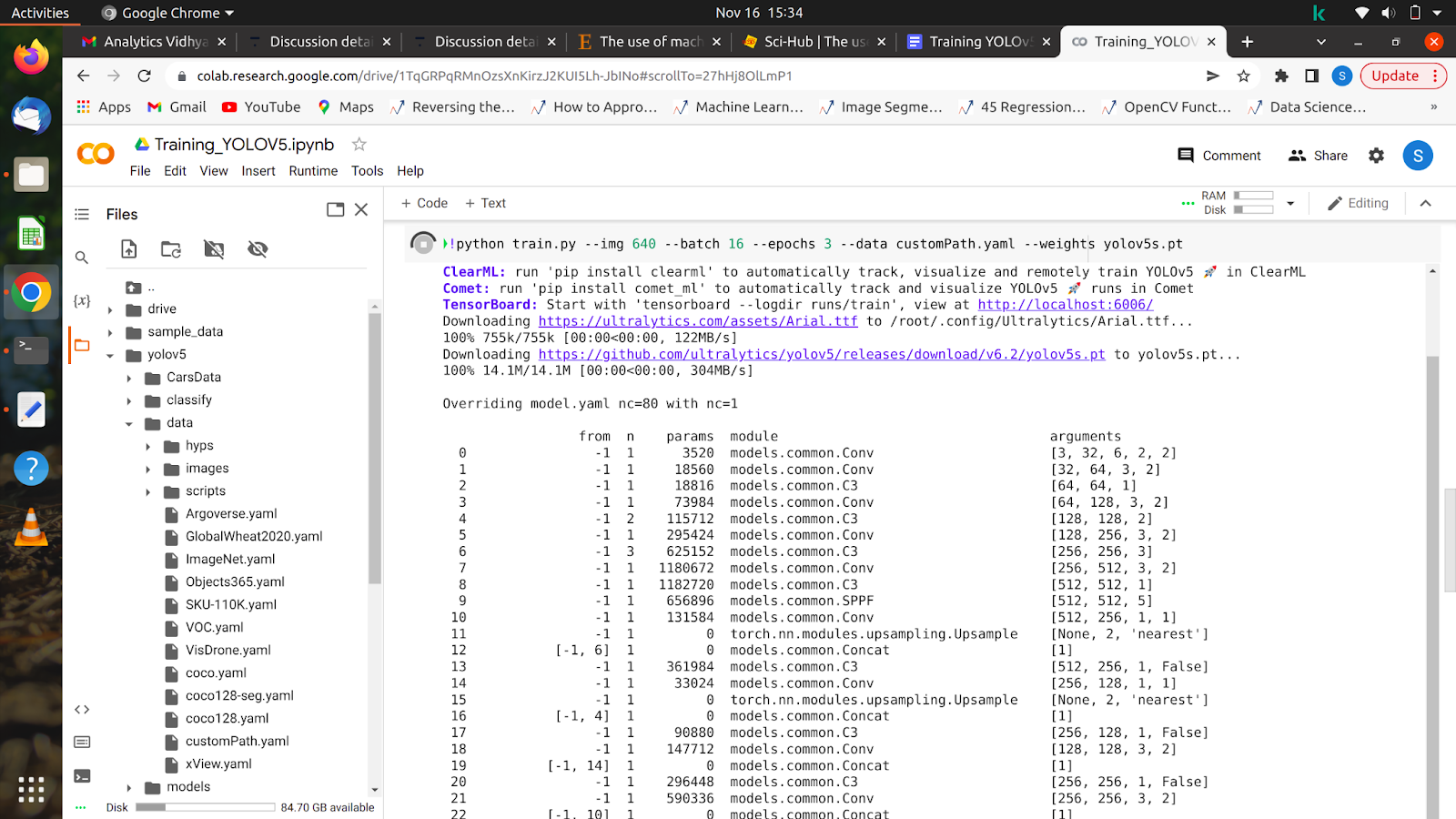
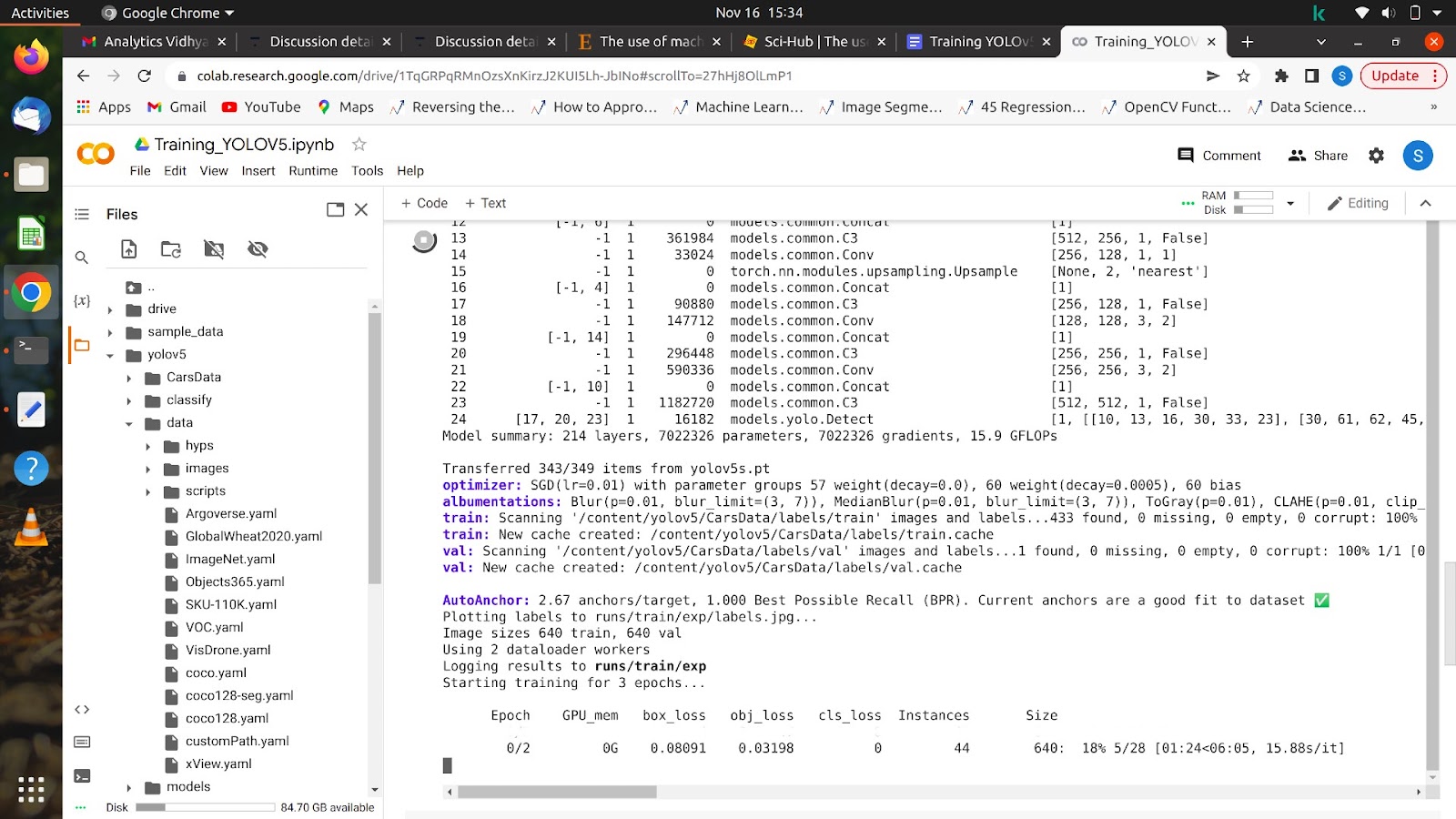
Po zakończeniu wszystkich epok Twój model można przetestować na dowolnym obrazie.
Możesz zrobić więcej dostosowań w pliku wykrywania.py, co chcesz zapisać, a czego nie lubisz, wykrycia, w których wykrywane są tablice rejestracyjne itp.
6. !python detector.py –weight /content/yolov5/runs/train/exp/weights/best.pt –source path_of_the_image
Możesz użyć tego polecenia, aby przetestować predykcję modelu na niektórych obrazach.
Niektóre wyzwania, którym możesz stawić czoła
Chociaż opisane powyżej kroki są prawidłowe, istnieją pewne problemy, które możesz napotkać, jeśli nie będziesz ich dokładnie przestrzegać.
- Niewłaściwa ścieżka: może to być ból głowy lub problem. Jeśli wprowadziłeś gdzieś niewłaściwą ścieżkę podczas uczenia obrazu, może to być trudne do zidentyfikowania i nie będziesz w stanie wytrenować modelu.
- Niewłaściwy format etykiet: Jest to powszechny problem, z którym borykają się ludzie podczas treningu YOLOv5. Model akceptuje tylko format, w którym każdy obraz ma swój własny plik tekstowy z żądanym formatem w środku. Często do sieci przesyłany jest plik w formacie XLS lub pojedynczy plik CSV, co powoduje błąd. Jeśli skądś pobierasz dane, zamiast dodawać adnotacje do każdego obrazu, może istnieć inny format pliku, w którym zapisywane są etykiety. Oto artykuł dotyczący konwersji formatu XLS na format YOLO. (link po zakończeniu artykułu).
- Niepoprawne nazwanie plików: Niepoprawne nazwanie pliku ponownie doprowadzi do błędu. Zwróć uwagę na kroki podczas nazywania folderów i unikaj tego błędu.
Wnioski
W tym artykule dowiedzieliśmy się, czym jest transfer learning i model wstępnie wytrenowany. Dowiedzieliśmy się, kiedy i dlaczego używać modelu YOLOv5 oraz jak trenować model na niestandardowym zbiorze danych. Przeszliśmy przez każdy krok, od przygotowania zestawu danych do zmiany ścieżek i wreszcie wprowadzenia ich do sieci w ramach implementacji techniki, i dokładnie zrozumieliśmy kroki. Przyjrzeliśmy się również typowym problemom napotykanym podczas szkolenia YOLOv5 i ich rozwiązaniom. Mam nadzieję, że ten artykuł pomógł Ci wytrenować swój pierwszy YOLOv5 na niestandardowym zbiorze danych i że podoba Ci się ten artykuł.
Związane z
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://www.analyticsvidhya.com/blog/2023/02/how-to-train-a-custom-dataset-with-yolov5/
- 1
- 10
- a
- Zdolny
- powyżej
- Akceptuje
- Stosownie
- precyzja
- działania
- Po
- przed
- AI
- Wszystkie kategorie
- już
- kwoty
- i
- architektura
- na około
- artykuł
- Uwaga
- automatycznie
- dostępny
- uniknąć
- z powrotem
- na podstawie
- Gruntownie
- zanim
- poniżej
- Ulepsz Swój
- Bit
- Dolny
- Pudełko
- Skrzynki
- przycisk
- ostrożny
- ostrożnie
- walizka
- CD
- Centrum
- wyzwania
- zmiana
- Zmiany
- wymiana pieniędzy
- ZOBACZ
- wybrany
- klasa
- Klasy
- klasyfikacja
- kod
- jak
- skomentował
- wspólny
- społeczność
- Zakończony
- ukończenia
- skomplikowane
- obliczenia
- mylące
- zawiera
- zawartość
- konwertować
- biurowy
- prawidłowo
- Stwórz
- stworzony
- Tworzenie
- Aktualny
- zwyczaj
- dostosowywanie
- dostosować
- Darknet
- dane
- Przygotowywanie danych
- naukowiec danych
- głęboko
- głęboka nauka
- Definiuje
- zależy
- wykryte
- Wykrywanie
- Dialog
- różne
- bezpośrednio
- katalogi
- odkrywanie
- inny
- robi
- nie
- pobieranie
- napęd
- każdy
- Łatwość
- kształcić
- Efektywne
- faktycznie
- wydajny
- Wchodzę
- wpisana
- epoki
- błąd
- itp
- Parzyste
- Każdy
- dokładnie
- przykład
- Ćwiczenie
- Wyjaśniać
- wyjaśnione
- wyjaśniając
- eksport
- niezwykle
- Twarz
- w obliczu
- FAST
- szybciej
- nakarmiony
- karmienie
- kilka
- filet
- Akta
- W końcu
- i terminów, a
- pierwszy raz
- Skupiać
- obserwuj
- następujący
- format
- Framework
- od
- zabawa
- otrzymać
- GitHub
- Dać
- Go
- będzie
- dobry
- GPU
- głowa
- wysłuchany
- pomoc
- pomógł
- tutaj
- Podświetlony
- wysoko
- uderzanie
- nadzieję
- W jaki sposób
- How To
- HTTPS
- olbrzymi
- pomysł
- Identyfikacja
- zidentyfikować
- obraz
- zdjęcia
- realizacja
- ważny
- in
- początkowo
- zainstalować
- zamiast
- Interakcje
- Internet
- zaangażowany
- IT
- Wiedzieć
- wiedza
- Etykieta
- Etykiety
- duży
- na dużą skalę
- większe
- nioski
- prowadzić
- UCZYĆ SIĘ
- dowiedziałem
- nauka
- biblioteki
- Licencja
- Linia
- LINK
- załadunek
- Popatrz
- wyglądał
- WYGLĄD
- zrobiony
- robić
- Dokonywanie
- wyraźny
- Mecz
- Materia
- Maksymalna szerokość
- znaczy
- metody
- może
- miliony
- nic
- model
- modele
- jeszcze
- większość
- Nazwa
- O imieniu
- nazywania
- Potrzebować
- potrzebne
- sieć
- sieci
- numer
- przedmiot
- Wykrywanie obiektów
- ONE
- zoptymalizowane
- Option
- zamówienie
- Inne
- własny
- pakiet
- Pakiety
- część
- ścieżka
- Zapłacić
- Ludzie
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- wykonywania
- wykonuje
- Miejsce
- plato
- Analiza danych Platona
- PlatoDane
- przewidzieć
- przepowiednia
- przygotowanie
- poprzedni
- poprzednio
- Problem
- problemy
- wygląda tak
- projekt
- Sprawdzony
- zapewnia
- cel
- płomień
- gotowy
- w czasie rzeczywistym
- niedawny
- polecić
- rafinowany
- usunąć
- składnica
- wymagać
- wymagany
- wymagania
- wynikły
- Efekt
- run
- taki sam
- Zapisz
- oszczędność
- Naukowiec
- Naukowcy
- Ekran
- służyć
- Powłoka
- powinien
- pokazać
- pokazane
- znaczący
- podobny
- Prosty
- po prostu
- ponieważ
- pojedynczy
- So
- rozwiązanie
- kilka
- coś
- gdzieś
- dzielić
- ułożone w stos
- stojaki
- początek
- rozpoczęty
- Ewolucja krok po kroku
- Cel
- Struktura
- taki
- Brać
- Zadanie
- zadania
- Technologia
- REGULAMIN
- test
- Połączenia
- ich
- całkowicie
- Przez
- czas
- czasochłonne
- do
- razem
- Top
- Pociąg
- przeszkolony
- Trening
- przenieść
- Przesyłanie
- Tutorial
- zazwyczaj
- zrozumieć
- zrozumiany
- posługiwać się
- zazwyczaj
- uprawomocnienie
- różnorodny
- pojazd
- wersja
- Strona internetowa
- strony internetowe
- tygodni
- Co
- który
- Podczas
- szeroko
- rozpowszechniony
- będzie
- bez
- Praca
- pracujący
- by
- napisać
- Źle
- jamla
- Yolo
- Twój
- zefirnet
- Zamek błyskawiczny