Ten post został napisany wspólnie z Mahimą Agarwal, inżynierem uczenia maszynowego i Deepakiem Mettem, starszym kierownikiem ds. inżynierii w VMware Carbon Black
VMware Sadza to renomowane rozwiązanie bezpieczeństwa oferujące ochronę przed pełnym spektrum współczesnych cyberataków. Mając do dyspozycji terabajty danych generowanych przez produkt, zespół analityków bezpieczeństwa koncentruje się na budowaniu rozwiązań uczenia maszynowego (ML) w celu ujawniania krytycznych ataków i wykrywania pojawiających się zagrożeń wynikających z szumu.
Niezwykle ważne jest, aby zespół VMware Carbon Black zaprojektował i zbudował niestandardowy, kompleksowy potok MLOps, który koordynuje i automatyzuje przepływy pracy w cyklu życia ML oraz umożliwia szkolenie modeli, oceny i wdrożenia.
Istnieją dwa główne cele tworzenia tego potoku: wspieranie naukowców zajmujących się danymi w opracowywaniu modeli na późnym etapie oraz przewidywania modeli powierzchniowych w produkcie poprzez obsługę modeli w dużej ilości i w ruchu produkcyjnym w czasie rzeczywistym. Dlatego VMware Carbon Black i AWS zdecydowały się zbudować niestandardowy potok MLOps przy użyciu Amazon Sage Maker ze względu na łatwość obsługi, wszechstronność i w pełni zarządzaną infrastrukturę. Organizujemy nasze potoki szkoleniowe i wdrożeniowe ML przy użyciu Przepływy pracy zarządzane przez Amazon dla Apache Airflow (Amazon MWAA), co pozwala nam bardziej skoncentrować się na programistycznym tworzeniu przepływów pracy i potoków bez martwienia się o automatyczne skalowanie lub konserwację infrastruktury.
Dzięki temu potokowi to, co kiedyś było oparte na notebookach firmy Jupyter, jest teraz zautomatyzowanym procesem wdrażania modeli do produkcji z niewielką ręczną interwencją ze strony analityków danych. Wcześniej proces szkolenia, oceny i wdrażania modelu mógł zająć jeden dzień; dzięki tej implementacji wszystko jest na wyciągnięcie ręki i skróciło całkowity czas do kilku minut.
W tym poście architekci VMware Carbon Black i AWS omawiają, w jaki sposób zbudowaliśmy niestandardowe przepływy pracy ML i zarządzamy nimi Gitlab, Amazon MWAA i SageMaker. Omawiamy to, co osiągnęliśmy do tej pory, dalsze ulepszenia potoku i wnioski wyciągnięte po drodze.
Omówienie rozwiązania
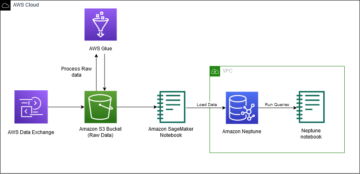
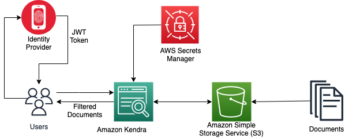
Poniższy diagram ilustruje architekturę platformy ML.

Projekt rozwiązania na wysokim poziomie
Ta platforma ML została zaprojektowana i zaprojektowana do użytku przez różne modele w różnych repozytoriach kodu. Nasz zespół używa GitLab jako narzędzia do zarządzania kodem źródłowym do utrzymywania wszystkich repozytoriów kodu. Wszelkie zmiany w kodzie źródłowym repozytorium modeli są na bieżąco integrowane przy użyciu Gitlab CI, która wywołuje kolejne przepływy pracy w potoku (szkolenie modelu, ocena i wdrożenie).
Poniższy diagram architektury ilustruje kompleksowy przepływ pracy i składniki zaangażowane w nasz potok MLOps.

Kompleksowy przepływ pracy
Potoki szkolenia, oceny i wdrażania modelu ML są organizowane przy użyciu usługi Amazon MWAA, określanej jako a Skierowany graf acykliczny (DAG). DAG to zbiór zadań razem, zorganizowanych z zależnościami i relacjami, aby powiedzieć, jak powinny działać.
Na wysokim poziomie architektura rozwiązania obejmuje trzy główne komponenty:
- Repozytorium kodu potoku ML
- Potok szkolenia i oceny modelu ML
- Potok wdrażania modelu ML
Omówmy, jak zarządza się tymi różnymi składnikami i jak wchodzą ze sobą w interakcje.
Repozytorium kodu potoku ML
Po tym, jak repozytorium modelowe zintegruje repozytorium MLOps jako potok podrzędny, a analityk danych zatwierdzi kod w swoim repozytorium modelowym, program uruchamiający GitLab przeprowadza standardowe sprawdzanie poprawności kodu i testowanie zdefiniowane w tym repozytorium oraz uruchamia potok MLOps na podstawie zmian w kodzie. Używamy potoku wielu projektów Gitlab, aby włączyć ten wyzwalacz w różnych repozytoriach.
Potok MLOps GitLab uruchamia określony zestaw etapów. Przeprowadza podstawową weryfikację kodu za pomocą Pylinta, pakuje kod uczący i wnioskowania modelu w obrazie Dockera i publikuje obraz kontenera do Rejestr elastycznego pojemnika Amazon (Amazon ECR). Amazon ECR to w pełni zarządzany rejestr kontenerów oferujący wysokowydajny hosting, dzięki czemu można niezawodnie wdrażać obrazy aplikacji i artefakty w dowolnym miejscu.
Potok szkolenia i oceny modelu ML
Po opublikowaniu obrazu uruchamia szkolenie i ocenę Przepływ powietrza Apache rurociąg przez AWS Lambda funkcjonować. Lambda to bezserwerowa, sterowana zdarzeniami usługa obliczeniowa, która umożliwia uruchamianie kodu praktycznie dowolnego typu aplikacji lub usługi zaplecza bez udostępniania serwerów i zarządzania nimi.
Po pomyślnym uruchomieniu potoku uruchamiany jest trening i ocena DAG, który z kolei rozpoczyna szkolenie modelu w SageMaker. Na końcu tego potoku szkoleniowego zidentyfikowana grupa użytkowników otrzymuje powiadomienie z wynikami szkolenia i oceny modelu za pośrednictwem poczty e-mail Usługa prostego powiadomienia Amazon (Amazon SNS) i Slack. Amazon SNS to w pełni zarządzana usługa pub/sub do przesyłania wiadomości A2A i A2P.
Po skrupulatnej analizie wyników oceny analityk danych lub inżynier ML może wdrożyć nowy model, jeśli wydajność nowo wyszkolonego modelu jest lepsza w porównaniu z poprzednią wersją. Wydajność modeli jest oceniana na podstawie metryk specyficznych dla modelu (takich jak wynik F1, MSE lub macierz pomyłek).
Potok wdrażania modelu ML
Aby rozpocząć wdrażanie, użytkownik uruchamia zadanie GitLab, które uruchamia DAG wdrożenia za pomocą tej samej funkcji Lambda. Po pomyślnym uruchomieniu potoku tworzy lub aktualizuje punkt końcowy SageMaker przy użyciu nowego modelu. Spowoduje to również wysłanie powiadomienia ze szczegółami punktu końcowego przez e-mail za pomocą Amazon SNS i Slack.
W przypadku awarii któregoś z potoków użytkownicy są powiadamiani tymi samymi kanałami komunikacyjnymi.
SageMaker oferuje wnioskowanie w czasie rzeczywistym, które jest idealne dla obciążeń wnioskowania z niskimi opóźnieniami i wysokimi wymaganiami dotyczącymi przepustowości. Te punkty końcowe są w pełni zarządzane, równoważone obciążeniem i automatycznie skalowane oraz mogą być wdrażane w wielu strefach dostępności w celu zapewnienia wysokiej dostępności. Nasz potok tworzy taki punkt końcowy dla modelu po jego pomyślnym uruchomieniu.
W kolejnych sekcjach rozwijamy różne komponenty i zagłębiamy się w szczegóły.
GitLab: modele pakietów i potoki wyzwalające
Używamy GitLab jako naszego repozytorium kodu i dla potoku do spakowania kodu modelu i wyzwalania dalszych DAG Airflow.
Potok wielu projektów
Funkcja potoku GitLab obejmująca wiele projektów jest używana, gdy potok nadrzędny (w górę) jest modelowym repozytorium, a potok podrzędny (w dół) to repozytorium MLOps. Każde repozytorium przechowuje plik .gitlab-ci.yml, a następujący blok kodu włączony w potoku nadrzędnym wyzwala potok MLOps podrzędnego.
Potok nadrzędny wysyła kod modelu do potoku podrzędnego, w którym uruchamiane są zadania pakowania i publikowania CI. Kod służący do konteneryzacji kodu modelu i publikowania go w Amazon ECR jest utrzymywany i zarządzany przez potok MLOps. Wysyła zmienne, takie jak ACCESS_TOKEN (można utworzyć pod Ustawienia, Wejdź), JOB_ID (aby uzyskać dostęp do nadrzędnych artefaktów) i $CI_PROJECT_ID (identyfikator projektu repozytorium modelu), dzięki czemu potok MLOps może uzyskać dostęp do plików kodu modelu. z artefakty pracy Feature z Gitlab, repozytorium podrzędne uzyskuje dostęp do zdalnych artefaktów za pomocą następującego polecenia:
Repozytorium modelu może zużywać potoki podrzędne dla wielu modeli z tego samego repozytorium, rozszerzając etap, który je uruchamia, za pomocą rozciąga się słowo kluczowe z GitLab, które pozwala na ponowne użycie tej samej konfiguracji na różnych etapach.
Po opublikowaniu obrazu modelu w Amazon ECR potok MLOps uruchamia potok szkoleniowy Amazon MWAA przy użyciu Lambda. Po zatwierdzeniu przez użytkownika uruchamia również potok wdrażania modelu Amazon MWAA przy użyciu tej samej funkcji Lambda.
Wersjonowanie semantyczne i przekazywanie wersji w dół
Opracowaliśmy niestandardowy kod do wersji obrazów ECR i modeli SageMaker. Potok MLOps zarządza semantyczną logiką wersjonowania dla obrazów i modeli w ramach etapu, w którym kod modelu jest konteneryzowany i przekazuje wersje do późniejszych etapów jako artefakty.
Przekwalifikowanie
Ponieważ ponowne szkolenie jest kluczowym aspektem cyklu życia uczenia maszynowego, w ramach naszego potoku wdrożyliśmy możliwości ponownego szkolenia. Używamy interfejsu API list-modeli SageMaker, aby określić, czy jest to ponowne uczenie na podstawie numeru wersji i sygnatury czasowej ponownego uczenia modelu.
Zarządzamy dziennym harmonogramem potoku przekwalifikowań za pomocą Potoki harmonogramu GitLab.
Terraform: Konfiguracja infrastruktury
Oprócz klastra Amazon MWAA, repozytoriów ECR, funkcji Lambda i tematu SNS, to rozwiązanie wykorzystuje również AWS Zarządzanie tożsamością i dostępem (IAM) role, użytkownicy i zasady; Usługa Amazon Simple Storage (Amazon S3) wiadra i Amazon Cloud Watch spedytor logów.
Aby usprawnić konfigurację i konserwację infrastruktury dla usług zaangażowanych w całym naszym rurociągu, używamy Terraform zaimplementować infrastrukturę jako kod. Ilekroć wymagane są aktualizacje infra, zmiany w kodzie uruchamiają skonfigurowany przez nas potok GitLab CI, który weryfikuje i wdraża zmiany w różnych środowiskach (na przykład dodanie uprawnień do polityki IAM na kontach deweloperów, etapów i produktów).
Amazon ECR, Amazon S3 i Lambda: ułatwienia w rurociągu
Korzystamy z następujących kluczowych usług, aby usprawnić nasz potok:
- Amazon ECR – Aby utrzymać i umożliwić wygodne pobieranie obrazów kontenerów modelu, oznaczamy je wersjami semantycznymi i przesyłamy do repozytoriów ECR utworzonych zgodnie z
${project_name}/${model_name}przez Terraforma. Zapewnia to dobrą warstwę izolacji między różnymi modelami i umożliwia nam korzystanie z niestandardowych algorytmów oraz formatowanie żądań wnioskowania i odpowiedzi w celu uwzględnienia żądanych informacji manifestu modelu (nazwa modelu, wersja, ścieżka danych szkoleniowych itd.). - Amazon S3 – Używamy zasobników S3 do utrwalania danych szkoleniowych modelu, wytrenowanych artefaktów modelu na model, DAG przepływu powietrza i innych dodatkowych informacji wymaganych przez potoki.
- Lambda – Ponieważ nasz klaster Airflow jest wdrożony w oddzielnym VPC ze względów bezpieczeństwa, nie można uzyskać bezpośredniego dostępu do DAG. Dlatego używamy funkcji Lambda, również obsługiwanej przez Terraform, do wyzwalania dowolnych DAG określonych przez nazwę DAG. Przy prawidłowej konfiguracji IAM zadanie GitLab CI uruchamia funkcję Lambda, która przechodzi przez konfiguracje do żądanych szkoleń lub wdrożeń DAG.
Amazon MWAA: potoki szkoleniowe i wdrożeniowe
Jak wspomniano wcześniej, używamy Amazon MWAA do organizowania potoków szkoleniowych i wdrożeniowych. Korzystamy z operatorów SageMaker dostępnych w Pakiet dostawcy Amazon dla Airflow do integracji z SageMaker (aby uniknąć tworzenia szablonów jinja).
W tym potoku szkoleniowym używamy następujących operatorów (pokazanych na poniższym diagramie przepływu pracy):

Rurociąg szkoleniowy MWAA
W potoku wdrażania używamy następujących operatorów (pokazanych na poniższym diagramie przepływu pracy):

Potok wdrażania modelu
Używamy Slack i Amazon SNS do publikowania komunikatów o błędach/sukcesach i wyników oceny w obu potokach. Slack zapewnia szeroki zakres opcji dostosowywania wiadomości, w tym:
- Operator SnsPublish - Używamy Operator SnsPublish do wysyłania powiadomień o sukcesie/porażce na e-maile użytkowników
- Luźny interfejs API – Stworzyliśmy tzw adres URL przychodzącego elementu webhoo aby otrzymywać powiadomienia z potoku na żądany kanał
CloudWatch i VMware Wavefront: monitorowanie i rejestrowanie
Używamy pulpitu nawigacyjnego CloudWatch do konfigurowania monitorowania i rejestrowania punktów końcowych. Pomaga wizualizować i śledzić różne metryki wydajności operacyjnej i modelowej specyficzne dla każdego projektu. Oprócz zasad automatycznego skalowania skonfigurowanych w celu śledzenia niektórych z nich, stale monitorujemy zmiany wykorzystania procesora i pamięci, żądań na sekundę, opóźnień odpowiedzi i metryk modelu.
CloudWatch jest nawet zintegrowany z pulpitem nawigacyjnym VMware Tanzu Wavefront, dzięki czemu może wizualizować metryki dla punktów końcowych modelu, a także innych usług na poziomie projektu.
Korzyści biznesowe i co dalej
Potoki ML są bardzo istotne dla usług i funkcji ML. W tym poście omówiliśmy przypadek użycia end-to-end ML z wykorzystaniem możliwości AWS. Zbudowaliśmy niestandardowy potok przy użyciu SageMaker i Amazon MWAA, których możemy ponownie używać w różnych projektach i modelach, a także zautomatyzowaliśmy cykl życia uczenia maszynowego, co skróciło czas od szkolenia modelu do wdrożenia produkcyjnego do zaledwie 10 minut.
Wraz z przeniesieniem obciążenia związanego z cyklem życia ML na SageMaker, zapewniono zoptymalizowaną i skalowalną infrastrukturę do szkolenia i wdrażania modeli. Obsługa modelu za pomocą SageMaker pomogła nam w dokonywaniu prognoz w czasie rzeczywistym z milisekundowymi opóźnieniami i możliwościami monitorowania. Użyliśmy Terraform w celu ułatwienia konfiguracji i zarządzania infrastrukturą.
Kolejnymi krokami w tym potoku byłoby ulepszenie potoku szkolenia modeli o możliwości ponownego uczenia, niezależnie od tego, czy jest to zaplanowane, czy oparte na wykrywaniu dryfowania modelu, wsparcie wdrożenia w tle lub testowanie A/B w celu szybszego i kwalifikowanego wdrożenia modelu oraz śledzenie linii ML. Planujemy też ocenić Rurociągi Amazon SageMaker ponieważ integracja GitLab jest teraz obsługiwana.
Wyciągnięte wnioski
W ramach tworzenia tego rozwiązania nauczyliśmy się, że należy wcześnie uogólniać, ale nie przesadzać. Kiedy po raz pierwszy zakończyliśmy projektowanie architektury, staraliśmy się utworzyć i wymusić tworzenie szablonów kodu dla kodu modelu jako najlepszą praktykę. Jednak na tak wczesnym etapie procesu opracowywania szablony były albo zbyt ogólne, albo zbyt szczegółowe, aby nadawały się do ponownego wykorzystania w przyszłych modelach.
Po dostarczeniu pierwszego modelu przez potok, szablony wyszły naturalnie na podstawie spostrzeżeń z naszej poprzedniej pracy. Rurociąg nie może zrobić wszystkiego od pierwszego dnia.
Eksperymentowanie i produkcja modeli często mają bardzo różne (a czasem nawet sprzeczne) wymagania. Kluczowe znaczenie ma zrównoważenie tych wymagań od samego początku jako zespół i odpowiednie ustalenie priorytetów.
Ponadto możesz nie potrzebować wszystkich funkcji usługi. Korzystanie z podstawowych funkcji usługi i posiadanie modułowej konstrukcji to klucze do wydajniejszego rozwoju i elastycznego potoku.
Wnioski
W tym poście pokazaliśmy, jak zbudowaliśmy rozwiązanie MLOps przy użyciu SageMaker i Amazon MWAA, które zautomatyzowało proces wdrażania modeli do produkcji, przy niewielkiej ręcznej interwencji ze strony analityków danych. Zachęcamy do oceny różnych usług AWS, takich jak SageMaker, Amazon MWAA, Amazon S3 i Amazon ECR, aby zbudować kompletne rozwiązanie MLOps.
*Apache, Apache Airflow i Airflow są zastrzeżonymi znakami towarowymi lub znakami towarowymi firmy Apache Software Foundation w Stanach Zjednoczonych i/lub innych krajach.
O autorach
 Deepak Mettem jest starszym kierownikiem ds. inżynierii w firmie VMware w dziale Carbon Black. On i jego zespół pracują nad tworzeniem aplikacji i usług opartych na strumieniowaniu, które są wysoce dostępne, skalowalne i odporne, aby dostarczać klientom rozwiązania oparte na uczeniu maszynowym w czasie rzeczywistym. On i jego zespół są również odpowiedzialni za tworzenie narzędzi niezbędnych analitykom danych do budowania, trenowania, wdrażania i weryfikowania ich modeli ML w środowisku produkcyjnym.
Deepak Mettem jest starszym kierownikiem ds. inżynierii w firmie VMware w dziale Carbon Black. On i jego zespół pracują nad tworzeniem aplikacji i usług opartych na strumieniowaniu, które są wysoce dostępne, skalowalne i odporne, aby dostarczać klientom rozwiązania oparte na uczeniu maszynowym w czasie rzeczywistym. On i jego zespół są również odpowiedzialni za tworzenie narzędzi niezbędnych analitykom danych do budowania, trenowania, wdrażania i weryfikowania ich modeli ML w środowisku produkcyjnym.
 Mahima Agarwal jest inżynierem uczenia maszynowego w VMware, Carbon Black Unit.
Mahima Agarwal jest inżynierem uczenia maszynowego w VMware, Carbon Black Unit.
Zajmuje się projektowaniem, budowaniem i rozwijaniem podstawowych komponentów i architektury platformy uczenia maszynowego dla VMware CB SBU.
 Wamszi Kryszna Enabotala jest starszym architektem specjalizującym się w sztucznej inteligencji w AWS. Współpracuje z klientami z różnych sektorów, aby przyspieszyć inicjatywy dotyczące danych, analiz i uczenia maszynowego o dużym wpływie. Pasjonuje się systemami rekomendacji, NLP oraz obszarami widzenia komputerowego w AI i ML. Poza pracą Vamshi jest entuzjastą RC, buduje sprzęt RC (samoloty, samochody i drony), a także lubi ogrodnictwo.
Wamszi Kryszna Enabotala jest starszym architektem specjalizującym się w sztucznej inteligencji w AWS. Współpracuje z klientami z różnych sektorów, aby przyspieszyć inicjatywy dotyczące danych, analiz i uczenia maszynowego o dużym wpływie. Pasjonuje się systemami rekomendacji, NLP oraz obszarami widzenia komputerowego w AI i ML. Poza pracą Vamshi jest entuzjastą RC, buduje sprzęt RC (samoloty, samochody i drony), a także lubi ogrodnictwo.
 Sahil Thapar jest architektem rozwiązań dla przedsiębiorstw. Współpracuje z klientami, pomagając im tworzyć wysoce dostępne, skalowalne i odporne aplikacje w chmurze AWS. Obecnie koncentruje się na kontenerach i rozwiązaniach do uczenia maszynowego.
Sahil Thapar jest architektem rozwiązań dla przedsiębiorstw. Współpracuje z klientami, pomagając im tworzyć wysoce dostępne, skalowalne i odporne aplikacje w chmurze AWS. Obecnie koncentruje się na kontenerach i rozwiązaniach do uczenia maszynowego.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/how-vmware-built-an-mlops-pipeline-from-scratch-using-gitlab-amazon-mwaa-and-amazon-sagemaker/
- :Jest
- $W GÓRĘ
- 1
- 10
- 100
- 7
- 8
- a
- O nas
- przyśpieszyć
- dostęp
- dostęp
- odpowiednio
- Konta
- osiągnięty
- w poprzek
- acykliczny
- dodatek
- Dodatkowy
- Dodatkowe informacje
- Po
- przed
- AI
- Algorytmy
- Wszystkie kategorie
- pozwala
- Amazonka
- Amazon Sage Maker
- analiza
- analityka
- i
- nigdzie
- Apache
- api
- Zastosowanie
- aplikacje
- stosowany
- Zastosowana sztuczna inteligencja
- zatwierdzenie
- architektura
- SĄ
- obszary
- AS
- aspekt
- At
- Ataki
- autoring
- samochód
- zautomatyzowane
- automaty
- dostępność
- dostępny
- uniknąć
- AWS
- Backend
- Bilans
- na podstawie
- podstawowy
- BE
- bo
- Początek
- Korzyści
- BEST
- Ulepsz Swój
- pomiędzy
- Czarny
- Blokować
- Oddział
- przynieść
- budować
- Budowanie
- wybudowany
- ciężar
- by
- CAN
- nie może
- możliwości
- węgiel
- samochody
- walizka
- CB
- pewien
- Zmiany
- kanały
- dziecko
- wybrał
- Chmura
- Grupa
- kod
- kolekcja
- Komunikacja
- w porównaniu
- kompletny
- składniki
- obliczać
- komputer
- Wizja komputerowa
- prowadzi
- systemu
- konfiguracje
- Sprzeczny
- zamieszanie
- Rozważania
- konsumować
- spożywane
- Pojemnik
- Pojemniki
- bez przerwy
- Wygodny
- rdzeń
- mógłby
- kraje
- CPU
- Stwórz
- stworzony
- tworzy
- Tworzenie
- krytyczny
- istotny
- Obecnie
- zwyczaj
- Klientów
- dostosować
- cyberataki
- DZIEŃ
- codziennie
- tablica rozdzielcza
- dane
- naukowiec danych
- dzień
- zdefiniowane
- dostarczanie
- rozwijać
- wdrażane
- wdrażanie
- Wdrożenie
- wdrożenia
- wdraża się
- Wnętrze
- zaprojektowany
- projektowanie
- szczegółowe
- detale
- Wykrywanie
- dev
- rozwinięty
- rozwijanie
- oprogramowania
- różne
- bezpośrednio
- dyskutować
- omówione
- Doker
- nie
- na dół
- Drony
- każdy
- Wcześniej
- Wcześnie
- łatwość użycia
- wydajny
- bądź
- wschodzących
- umożliwiać
- włączony
- Umożliwia
- zachęcać
- koniec końców
- Punkt końcowy
- inżynier
- Inżynieria
- Enterprise
- Enterprise Solutions
- entuzjasta
- środowiska
- sprzęt
- niezbędny
- Eter (ETH)
- oceniać
- oceniane
- oceny
- ewaluację
- oceny
- Parzyste
- wydarzenie
- Każdy
- wszystko
- przykład
- Rozszerzać
- rozsuwalny
- f1
- ułatwiać
- Brak
- daleko
- szybciej
- Cecha
- Korzyści
- kilka
- Akta
- i terminów, a
- elastyczne
- Skupiać
- koncentruje
- koncentruje
- następujący
- W razie zamówieenia projektu
- format
- od
- pełny
- pełne spektrum
- w pełni
- funkcjonować
- Funkcje
- dalej
- przyszłość
- wygenerowane
- otrzymać
- dobry
- Zarządzanie
- Have
- mający
- pomoc
- pomógł
- pomaga
- Wysoki
- wysoka wydajność
- wysoko
- Hosting
- W jaki sposób
- Jednak
- HTML
- http
- HTTPS
- IAM
- ID
- idealny
- zidentyfikowane
- zidentyfikować
- tożsamość
- obraz
- zdjęcia
- wdrożenia
- realizacja
- realizowane
- in
- zawierać
- obejmuje
- Włącznie z
- Informacja
- Infrastruktura
- inicjatywy
- spostrzeżenia
- integrować
- zintegrowany
- Integruje się
- integracja
- interakcji
- interwencja
- inwokuje
- zaangażowany
- izolacja
- IT
- JEGO
- Praca
- Oferty pracy
- jpg
- Trzymać
- Klawisz
- Klawisze
- Utajenie
- warstwa
- dowiedziałem
- nauka
- Lekcje
- Lessons Learned
- pozwala
- poziom
- wifecycwe
- lubić
- mało
- załadować
- niski
- maszyna
- uczenie maszynowe
- Główny
- utrzymać
- utrzymuje
- konserwacja
- robić
- zarządzanie
- zarządzane
- i konserwacjami
- kierownik
- zarządza
- zarządzający
- podręcznik
- Matrix
- Pamięć
- wzmiankowany
- wiadomości
- wiadomości
- Metryka
- może
- milisekunda
- minuty
- ML
- MLOps
- model
- modele
- Nowoczesne technologie
- monitor
- monitorowanie
- jeszcze
- bardziej wydajny
- wielokrotność
- Nazwa
- naturalnie
- niezbędny
- Potrzebować
- Nowości
- Następny
- nlp
- Hałas
- powiadomienie
- Powiadomienia
- numer
- of
- oferuje
- Oferty
- on
- ONE
- operacyjny
- operatorzy
- zoptymalizowane
- Opcje
- orkiestrowany
- Zorganizowany
- Inne
- zewnętrzne
- ogólny
- pakiet
- Pakiety
- opakowania
- część
- przebiegi
- Przechodzący
- namiętny
- ścieżka
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- pozwolenie
- rurociąg
- krok po kroku
- Planes
- Platforma
- plato
- Analiza danych Platona
- PlatoDane
- polityka
- polityka
- Post
- praktyka
- Przewidywania
- poprzedni
- Priorytet
- wygląda tak
- Produkt
- Produkcja
- projekt
- projektowanie
- właściwy
- ochrona
- pod warunkiem,
- dostawca
- zapewnia
- publikować
- opublikowany
- Publikuje
- Wydawniczy
- cele
- wykwalifikowany
- zasięg
- w czasie rzeczywistym
- Rekomendacja
- Zredukowany
- , o którym mowa
- zarejestrowany
- rejestr
- Relacje
- zdalny
- Słynny
- składnica
- wniosek
- wywołań
- wymagany
- wymagania
- Badania naukowe
- sprężysty
- odpowiedź
- odpowiedzialny
- Efekt
- przekwalifikowanie
- wielokrotnego użytku
- role
- run
- biegacz
- sagemaker
- taki sam
- skalowalny
- skalowaniem
- rozkład
- zaplanowane
- Naukowiec
- Naukowcy
- druga
- działy
- Sektory
- bezpieczeństwo
- senior
- oddzielny
- Bezserwerowe
- Serwery
- usługa
- Usługi
- służąc
- zestaw
- ustawienie
- Shadow
- PRZESUNIĘCIE
- powinien
- pokazane
- Prosty
- luźny
- So
- dotychczas
- Tworzenie
- rozwiązanie
- Rozwiązania
- kilka
- Źródło
- Kod źródłowy
- specjalista
- specyficzny
- określony
- Widmo
- reflektor
- STAGE
- etapy
- standard
- początek
- rozpocznie
- Zjednoczone
- Cel
- przechowywanie
- Strategia
- Streaming
- opływowy
- kolejny
- Z powodzeniem
- taki
- wsparcie
- Utrzymany
- Powierzchnia
- systemy
- TAG
- Brać
- zadania
- zespół
- Szablony
- Terraform
- Testowanie
- że
- Połączenia
- ich
- Im
- w związku z tym
- Te
- zagrożenia
- trzy
- Przez
- poprzez
- wydajność
- czas
- znak czasu
- do
- razem
- także
- narzędzie
- narzędzia
- Top
- aktualny
- śledzić
- Śledzenie
- znaki towarowe
- ruch drogowy
- Pociąg
- przeszkolony
- Trening
- wyzwalać
- rozsierdzony
- SKRĘCAĆ
- dla
- jednostka
- Zjednoczony
- United States
- Nowości
- us
- Stosowanie
- posługiwać się
- przypadek użycia
- Użytkownik
- Użytkownicy
- UPRAWOMOCNIĆ
- uprawomocnienie
- zmienne
- różnorodny
- wersja
- prawie
- wizja
- wyobrażać sobie
- vmware
- Tom
- Droga..
- DOBRZE
- Co
- czy
- który
- szeroki
- Szeroki zasięg
- w
- w ciągu
- bez
- Praca
- workflow
- przepływów pracy
- działa
- by
- zefirnet
- Zamek błyskawiczny
- Strefy