Duże modele transformatorów oparte na uwadze uzyskały ogromne korzyści w zakresie przetwarzania języka naturalnego (NLP). Jednak szkolenie tych gigantycznych sieci od podstaw wymaga ogromnej ilości danych i obliczeń. W przypadku mniejszych zestawów danych NLP prostą, ale skuteczną strategią jest użycie wstępnie przeszkolonego transformatora, zwykle uczonego w sposób nienadzorowany na bardzo dużych zestawach danych, i dostrojenie go na interesującym zestawie danych. Przytulanie Twarzy utrzymuje duże zoo modeli tych wstępnie przeszkolonych transformatorów i sprawia, że są one łatwo dostępne nawet dla początkujących użytkowników.
Jednak dostrojenie tych modeli nadal wymaga wiedzy eksperckiej, ponieważ są one dość wrażliwe na ich hiperparametry, takie jak szybkość uczenia się lub wielkość partii. W tym poście pokazujemy, jak zoptymalizować te hiperparametry za pomocą frameworka open-source Synchronizuj do rozproszonej optymalizacji hiperparametrów (HPO). Syne Tune pozwala nam znaleźć lepszą konfigurację hiperparametrów, która osiąga względną poprawę między 1-4% w porównaniu z domyślnymi hiperparametrami w popularnych KLEJ wzorcowe zbiory danych. Sam wybór wstępnie wytrenowanego modelu można również uznać za hiperparametr i dlatego zostanie on automatycznie wybrany przez Syne Tune. W przypadku problemu z klasyfikacją tekstu prowadzi to do dodatkowego zwiększenia dokładności o około 5% w porównaniu z modelem domyślnym. Możemy jednak zautomatyzować więcej decyzji, które użytkownik musi podjąć; demonstrujemy to, ujawniając również typ instancji jako hiperparametr, którego później użyjemy do wdrożenia modelu. Wybierając odpowiedni typ instancji, możemy znaleźć konfiguracje, które optymalnie równoważą koszty i opóźnienia.
Aby zapoznać się z wprowadzeniem do Syne Tune, zapoznaj się z Uruchamiaj rozproszone zadania dostrajania hiperparametrów i architektury neuronowej za pomocą Syne Tune.
Optymalizacja hiperparametrów z Syne Tune
Użyjemy KLEJ pakiet porównawczy, który składa się z dziewięciu zestawów danych do zadań związanych ze zrozumieniem języka naturalnego, takich jak rozpoznawanie pociągania za sobą tekstu lub analiza sentymentu. W tym celu dostosowujemy Hugging Face run_glue.py skrypt szkoleniowy. Zestawy danych GLUE są dostarczane z predefiniowanym zestawem treningowym i oceniającym z etykietami, a także zestawem testowym wstrzymania bez etykiet. Dlatego dzielimy zestaw uczący na zestawy uczące i walidacyjne (podział 70%/30%) i używamy zestawu ewaluacyjnego jako naszego zestawu danych testowych wstrzymania. Co więcej, dodajemy kolejną funkcję zwrotną do interfejsu Hugging Face's Trainer API, która raportuje wydajność walidacji po każdej epoce z powrotem do Syne Tune. Zobacz następujący kod:
Zaczynamy od optymalizacji typowych hiperparametrów treningu: szybkości uczenia się, współczynnika rozgrzewki w celu zwiększenia szybkości uczenia się i wielkości partii w celu dostrojenia wstępnie wytrenowanego BERT (bert-base-case), który jest modelem domyślnym w przykładzie Hugging Face. Zobacz następujący kod:
Jako naszą metodę HPO używamy ASHA, który jednolicie losowo próbkuje konfiguracje hiperparametrów i iteracyjnie zatrzymuje ocenę konfiguracji o niskiej wydajności. Chociaż bardziej wyrafinowane metody wykorzystują probabilistyczny model funkcji celu, taki jak BO lub MoBster, w tym poście używamy ASHA, ponieważ nie ma żadnych założeń dotyczących przestrzeni wyszukiwania.
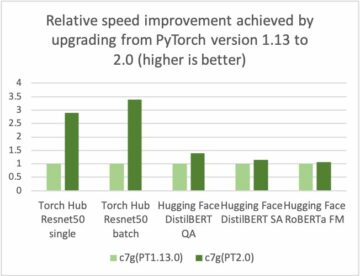
Na poniższym rysunku porównujemy względną poprawę błędu testu w porównaniu z domyślną konfiguracją hiperparametrów Hugging Faces.
![]()
Dla uproszczenia ograniczamy porównanie do MRPC, COLA i STSB, ale obserwujemy również podobne ulepszenia również dla innych zestawów danych GLUE. Dla każdego zestawu danych uruchamiamy ASHA na pojedynczym ml.g4dn.xlarge Amazon Sage Maker wystąpienie z budżetem wykonawczym wynoszącym 1,800 sekund, co odpowiada odpowiednio około 13, 7 i 9 pełnym ocenom funkcji w tych zestawach danych. Aby uwzględnić wewnętrzną losowość procesu uczenia, na przykład spowodowaną próbkowaniem mini-partii, uruchamiamy zarówno ASHA, jak i domyślną konfigurację dla pięciu powtórzeń z niezależnym ziarnem dla generatora liczb losowych i zgłaszamy średnią i odchylenie standardowe względna poprawa w powtórzeniach. Widzimy, że we wszystkich zestawach danych możemy w rzeczywistości poprawić wydajność predykcyjną o 1-3% w stosunku do wydajności starannie wybranej konfiguracji domyślnej.
Zautomatyzuj wybór wstępnie wytrenowanego modelu
Możemy użyć HPO nie tylko do znajdowania hiperparametrów, ale także do automatycznego wybierania odpowiedniego wstępnie wytrenowanego modelu. Dlaczego chcemy to zrobić? Ponieważ żaden pojedynczy model nie przewyższa wszystkich zestawów danych, musimy wybrać odpowiedni model dla określonego zestawu danych. Aby to zademonstrować, oceniamy szereg popularnych modeli transformatorów firmy Hugging Face. Dla każdego zestawu danych oceniamy każdy model według jego wydajności testowej. Ranking w zestawach danych (patrz poniższy rysunek) zmienia się i nie ma jednego modelu, który uzyskał najwyższą ocenę w każdym zestawie danych. Jako odniesienie pokazujemy również bezwzględną wydajność testu każdego modelu i zestawu danych na poniższym rysunku.
Aby automatycznie wybrać odpowiedni model, możemy rzucić wybór modelu jako parametry kategoryczne i dodać to do naszej przestrzeni wyszukiwania hiperparametrów:
Chociaż przestrzeń wyszukiwania jest teraz większa, niekoniecznie oznacza to, że trudniej ją zoptymalizować. Poniższy rysunek przedstawia błąd testowy najlepiej obserwowanej konfiguracji (na podstawie błędu walidacji) na zestawie danych MRPC ASHA w czasie, gdy przeszukujemy w oryginalnej przestrzeni (niebieska linia) (z wstępnie wytrenowanym modelem opartym na BERT ) lub w nowej rozszerzonej przestrzeni wyszukiwania (linia pomarańczowa). Przy takim samym budżecie ASHA jest w stanie znaleźć znacznie lepszą konfigurację hiperparametrów w rozszerzonej przestrzeni wyszukiwania niż w mniejszej przestrzeni.
![]()
Zautomatyzuj wybór typu instancji
W praktyce możemy nie tylko dbać o optymalizację predykcyjnej wydajności. Możemy również dbać o inne cele, takie jak czas szkolenia, koszt (w dolarach), opóźnienia lub wskaźniki uczciwości. Musimy również dokonać innych wyborów poza hiperparametrami modelu, na przykład wybierając typ instancji.
Chociaż typ wystąpienia nie wpływa na wydajność predykcyjną, ma duży wpływ na koszt (w dolarach), czas wykonywania szkolenia i opóźnienie. To ostatnie staje się szczególnie ważne, gdy model jest wdrażany. Możemy określić HPO jako problem optymalizacji wielocelowej, w którym dążymy do jednoczesnej optymalizacji wielu celów. Jednak żadne pojedyncze rozwiązanie nie optymalizuje wszystkich metryk jednocześnie. Zamiast tego staramy się znaleźć zestaw konfiguracji, które optymalnie równoważą jeden cel z drugim. Nazywa się to Zestaw Pareto.
Aby dokładniej przeanalizować to ustawienie, dodajemy wybór typu wystąpienia jako dodatkowy hiperparametr kategorialny do naszej przestrzeni wyszukiwania:
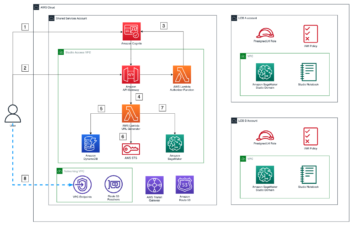
Używamy pliki MO-ASHA, który dostosowuje ASHA do scenariusza z wieloma celami za pomocą sortowania niezdominowanego. W każdej iteracji MO-ASHA wybiera również dla każdej konfiguracji również typ instancji, na której chcemy ją ocenić. Aby uruchomić HPO na heterogenicznym zestawie instancji, Syne Tune udostępnia backend SageMaker. Dzięki temu zapleczu każda próba jest oceniana jako niezależne zadanie szkoleniowe SageMaker na własnej instancji. Liczba pracowników określa, ile zadań SageMaker uruchamiamy równolegle w danym czasie. Sam optymalizator, w naszym przypadku MO-ASHA, działa albo na lokalnym komputerze, na notebooku Sagemakera, albo na oddzielnym zadaniu treningowym SageMaker. Zobacz następujący kod:
Poniższe rysunki pokazują opóźnienie w porównaniu z błędem testu po lewej stronie i opóźnienie w porównaniu z kosztem po prawej stronie dla losowych konfiguracji próbkowanych przez MO-ASHA (ograniczamy oś widoczności) w zestawie danych MRPC po uruchomieniu go przez 10,800 XNUMX sekund na czterech pracownikach. Kolor wskazuje typ wystąpienia. Przerywana czarna linia reprezentuje zbiór Pareto, czyli zbiór punktów, które dominują nad wszystkimi innymi punktami w co najmniej jednym celu.
Możemy zaobserwować kompromis między opóźnieniem a błędem testu, co oznacza, że najlepsza konfiguracja z najniższym błędem testu nie zapewnia najmniejszego opóźnienia. W oparciu o swoje preferencje możesz wybrać konfigurację hiperparametrów, która poświęca wydajność testu, ale ma mniejsze opóźnienie. Widzimy również kompromis między opóźnieniem a kosztem. Używając na przykład mniejszego wystąpienia ml.g4dn.xlarge, tylko nieznacznie zwiększamy opóźnienie, ale płacimy jedną czwartą kosztu wystąpienia ml.g4dn.8xlarge.
Wnioski
W tym poście omówiliśmy optymalizację hiperparametrów do precyzyjnego dostrajania wstępnie wytrenowanych modeli transformatorów od Hugging Face w oparciu o Syne Tune. Zobaczyliśmy, że optymalizując hiperparametry, takie jak szybkość uczenia się, wielkość partii i współczynnik rozgrzewki, możemy poprawić starannie wybraną konfigurację domyślną. Możemy to również rozszerzyć, automatycznie wybierając wstępnie wytrenowany model za pomocą optymalizacji hiperparametrów.
Za pomocą backendu SageMaker firmy Syne Tune możemy traktować typ instancji jako hiperparametr. Chociaż typ wystąpienia nie wpływa na wydajność, ma znaczący wpływ na opóźnienie i koszt. Dlatego rzucając HPO jako problem optymalizacji wielokryterialnej, jesteśmy w stanie znaleźć zestaw konfiguracji, które optymalnie godzą jeden cel z drugim. Jeśli chcesz sam to wypróbować, sprawdź nasze przykładowy notatnik.
O autorach
![]() Aaron Klein jest naukowcem stosowanym w AWS.
Aaron Klein jest naukowcem stosowanym w AWS.
![]() Maciej Seeger jest głównym naukowcem w AWS.
Maciej Seeger jest głównym naukowcem w AWS.
![]() Dawid Salinas jest starszym naukowcem w AWS.
Dawid Salinas jest starszym naukowcem w AWS.
![]() Emily Webber dołączył do AWS zaraz po uruchomieniu SageMaker i od tego czasu próbuje opowiedzieć o tym światu! Poza tworzeniem nowych doświadczeń związanych z ML dla klientów, Emily lubi medytować i studiować buddyzm tybetański.
Emily Webber dołączył do AWS zaraz po uruchomieniu SageMaker i od tego czasu próbuje opowiedzieć o tym światu! Poza tworzeniem nowych doświadczeń związanych z ML dla klientów, Emily lubi medytować i studiować buddyzm tybetański.
![]() Cedrik Archambeau jest głównym naukowcem stosowanym w AWS i członkiem Europejskiego Laboratorium Uczenia się i Inteligentnych Systemów.
Cedrik Archambeau jest głównym naukowcem stosowanym w AWS i członkiem Europejskiego Laboratorium Uczenia się i Inteligentnych Systemów.
- Coinsmart. Najlepsza w Europie giełda bitcoinów i kryptowalut.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. DARMOWY DOSTĘP.
- CryptoJastrząb. Radar Altcoin. Bezpłatna wersja próbna.
- Źródło: https://aws.amazon.com/blogs/machine-learning/hyperparameter-optimization-for-fine-tuning-pre-trained-transformer-models-from-hugging-face/
- "
- 10
- 100
- 7
- 9
- a
- O nas
- bezwzględny
- dostępny
- Konto
- Osiągać
- w poprzek
- Dodatkowy
- oddziaływać
- Wszystkie kategorie
- pozwala
- Chociaż
- Amazonka
- ilość
- analiza
- w czasie rzeczywistym sprawiają,
- Inne
- api
- stosowany
- w przybliżeniu
- architektura
- zwiększona
- zautomatyzować
- automatycznie
- średni
- AWS
- Oś
- bo
- Benchmark
- BEST
- Ulepsz Swój
- pomiędzy
- Poza
- Czarny
- podnieść
- budżet
- Budowanie
- który
- walizka
- powodowany
- wybór
- wybory
- wybrany
- klasa
- klasyfikacja
- kod
- jak
- w porównaniu
- obliczać
- systemu
- kontrola
- Klientów
- dane
- Decyzje
- wykazać
- rozwijać
- wdrażane
- dystrybuowane
- Nie
- Dolar
- każdy
- z łatwością
- Efektywne
- europejski
- oceniać
- ewaluację
- przykład
- Doświadczenia
- ekspert
- rozciągać się
- Twarz
- Moda
- Postać
- następujący
- Framework
- od
- pełny
- funkcjonować
- dalej
- Ponadto
- generator
- pomoc
- tutaj
- W jaki sposób
- How To
- Jednak
- HTTPS
- Rezultat
- ważny
- podnieść
- poprawa
- Zwiększać
- niezależny
- wpływ
- przykład
- Inteligentny
- odsetki
- IT
- samo
- Praca
- Oferty pracy
- Dołączył
- wiedza
- laboratorium
- Etykiety
- język
- duży
- większe
- uruchomiona
- Wyprowadzenia
- nauka
- LIMIT
- Linia
- miejscowy
- maszyna
- robić
- WYKONUJE
- masywny
- znaczenie
- metody
- Metryka
- może
- ML
- model
- modele
- jeszcze
- wielokrotność
- Naturalny
- koniecznie
- wymagania
- sieci
- notatnik
- numer
- Cele
- uzyskane
- optymalizacja
- Optymalizacja
- optymalizacji
- oryginalny
- Inne
- własny
- szczególnie
- Zapłacić
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- wykonywania
- Proszę
- zwrotnica
- Popularny
- praktyka
- Główny
- Problem
- wygląda tak
- przetwarzanie
- zapewnia
- zasięg
- Ranking
- raport
- reporter
- Raporty
- reprezentuje
- Wymaga
- Efekt
- run
- bieganie
- taki sam
- Naukowiec
- Szukaj
- sekund
- nasienie
- wybrany
- sentyment
- zestaw
- ustawienie
- pokazać
- znaczący
- podobny
- Prosty
- pojedynczy
- Rozmiar
- rozwiązanie
- wyrafinowany
- Typ przestrzeni
- specyficzny
- dzielić
- standard
- początek
- Stan
- Nadal
- Strategia
- systemy
- zadania
- test
- Połączenia
- świat
- w związku z tym
- czas
- handel
- Trening
- leczyć
- ogromny
- próba
- zrozumienie
- us
- posługiwać się
- Użytkownicy
- zazwyczaj
- wykorzystać
- uprawomocnienie
- widoczność
- Wikipedia
- bez
- pracowników
- świat
- Twój