Wprowadzenie
Świat audytu danych może być złożony i wiązać się z wieloma wyzwaniami. Jednym z największych wyzwań jest obsługa atrybutów kategorycznych podczas pracy ze zbiorami danych. W tym artykule zagłębimy się w świat inspekcji danych, wykrywania anomalii i wpływu kodowania atrybutów kategorycznych na modele.
Jednym z głównych wyzwań związanych z wykrywaniem anomalii na potrzeby inspekcji danych jest obsługa atrybutów kategorycznych. Kodowanie atrybutów jakościowych jest obowiązkowe, ponieważ modele nie mogą interpretować wprowadzanego tekstu. Zwykle odbywa się to za pomocą kodowania Label lub One Hot. Jednak w dużym zbiorze danych kodowanie One-hot może prowadzić do niskiej wydajności modelu z powodu przekleństwa wymiarowości.
Cele kształcenia
-
Aby zrozumieć koncepcję audytu danych i wyzwanie
- Ocena różnych metod głębokiego wykrywania anomalii bez nadzoru.
- Zrozumienie wpływu kodowania atrybutów kategorycznych na modele używane do wykrywania anomalii w danych audytowych.
Ten artykuł został opublikowany jako część Blogathon Data Science.
Spis treści
- Co to jest Auata?
- Co to jest wykrywanie anomalii?
- Główne wyzwania napotykane podczas audytu danych
- Audytowanie zbiorów danych pod kątem wykrywania anomalii
- Kodowanie atrybutów kategorialnych
- Kodowanie kategoryczne
- Modele wykrywania anomalii bez nadzoru
- Jak kodowanie atrybutów kategorialnych wpływa na modele?
8.1 Reprezentacja t-SNE zbioru danych ubezpieczenia samochodu
8.2 Reprezentacja t-SNE zbioru danych dotyczących ubezpieczenia pojazdu
8.3 Reprezentacja t-SNE zbioru danych roszczeń dotyczących pojazdów - Wnioski
w jest Audyt danych?
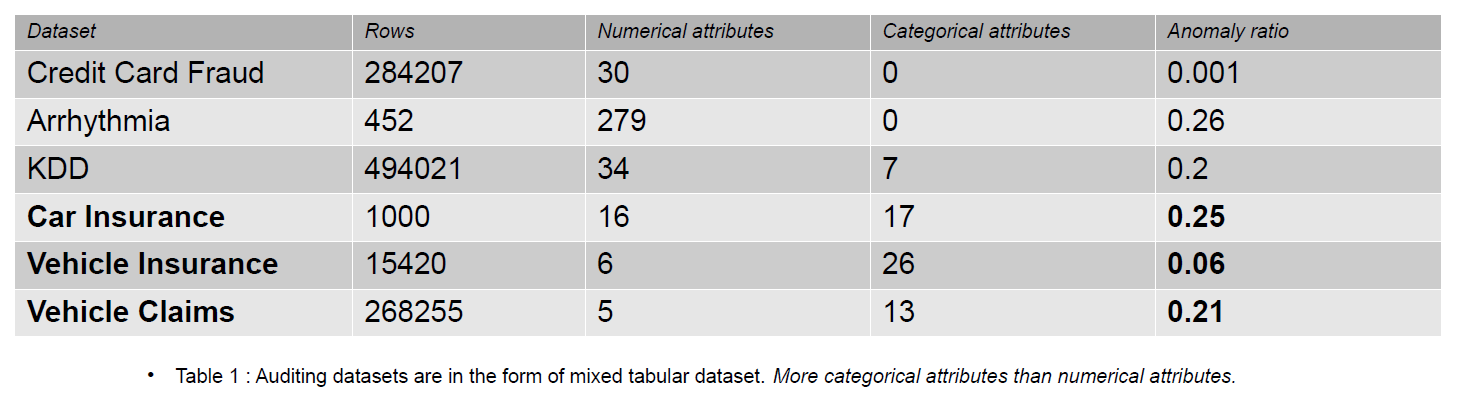
Dane audytowe mogą obejmować dzienniki, roszczenia ubezpieczeniowe i dane dotyczące włamań dla systemów informatycznych; w tym artykule podane przykłady dotyczą roszczeń ubezpieczeniowych pojazdów. Roszczenia ubezpieczeniowe różnią się od zbiorów danych służących do wykrywania anomalii, np. KDD, dzięki większej liczbie cech kategorycznych.
Cechy kategoryczne są dyskami w naszych danych, które mogą być typu całkowitego lub znakowego. Cechy numeryczne to ciągłe atrybuty w naszych danych, które zawsze mają wartość rzeczywistą. Zestawy danych z funkcjami numerycznymi są popularne w społeczności zajmującej się wykrywaniem anomalii, na przykład dane dotyczące oszustw związanych z kartami kredytowymi. Większość publicznie dostępnych zbiorów danych zawiera mniej cech kategorycznych niż dane dotyczące roszczeń ubezpieczeniowych. Cech kategorialnych jest więcej niż cech liczbowych w zbiorach danych roszczeń ubezpieczeniowych.
Roszczenie ubezpieczeniowe obejmuje takie cechy, jak model, marka, dochód, koszt, problem, kolor itp. Liczba cech kategorycznych jest wyższa w danych audytowych niż w zbiorach danych kart kredytowych i KDD. Te zestawy danych są wzorcami w nienadzorowanych metodach wykrywania anomalii. Jak widać w poniższej tabeli, zestawy danych roszczeń ubezpieczeniowych mają bardziej kategoryczne cechy, które są ważne dla zrozumienia zachowania fałszywych danych.
Audytowe zestawy danych używane do oceny wpływu kodowania kategorycznego to Ubezpieczenie samochodu, Ubezpieczenie pojazdu i Roszczenia dotyczące pojazdu.
Co to jest wykrywanie anomalii?
Anomalia to obserwacja zlokalizowana daleko od normalnych danych w zbiorze danych o określoną odległość (próg). Jeśli chodzi o dane audytowe, preferujemy termin fałszywe dane. Wykrywanie anomalii rozróżnia normalne i fałszywe dane za pomocą uczenia maszynowego lub modelu uczenia głębokiego. Różne metody może być używany do wykrywania anomalii, takich jak szacowanie gęstości, błąd rekonstrukcji i metody klasyfikacji.
- Oszacowanie gęstości – Te metody szacują normalny rozkład danych i klasyfikują dane anomalne, jeśli nie zostały one pobrane z wyuczonego rozkładu.
- Błąd rekonstrukcji – Metody rekonstrukcji oparte na błędach opierają się na zasadzie, że normalne dane można zrekonstruować z mniejszymi stratami niż dane anomalne. Im większa utrata rekonstrukcji, tym większe prawdopodobieństwo, że dane są anomalią.
- Metody klasyfikacji - Metody klasyfikacji, np Losowy las, las izolacyjny, jedna klasa — maszyny wektorów nośnych i lokalne czynniki odstające mogą być używane do wykrywania anomalii. Klasyfikacja w wykrywaniu anomalii polega na zidentyfikowaniu jednej z klas jako anomalii. Mimo to klasy są podzielone na dwie grupy (0 i 1) w scenariuszu z wieloma klasami, a klasa z mniejszą liczbą danych jest klasą anomalną.
Wynikiem powyższych metod są wyniki anomalii lub błędy rekonstrukcji. Następnie musimy zdecydować o progu, według którego będziemy klasyfikować dane anomalne.
Główne wyzwania napotykane podczas audytu danych
- Obsługa atrybutów kategorycznych: Kodowanie atrybutów jakościowych jest obowiązkowe, ponieważ model nie może interpretować wprowadzanego tekstu. Tak więc wartości są kodowane za pomocą kodowania Label lub One Hot. Ale w dużym zbiorze danych jedno kodowanie na gorąco przekształca dane w przestrzeń wielowymiarową, zwiększając liczbę atrybutów. Model spisuje się słabo ze względu na tzw przekleństwo wymiarowości.
- Wybór progu do klasyfikacji: Jeśli dane nie są oznaczone, trudno jest ocenić wydajność modelu, ponieważ nie znamy liczby anomalii obecnych w zbiorze danych. Wcześniejsza wiedza o zbiorze danych ułatwia określenie progu. Powiedzmy, że mamy 5 z 10 próbek anomalii w naszych danych. Możemy więc wybrać próg na poziomie 50 percentyla.
- Publiczne zbiory danych: Większość zestawów danych audytowych jest poufna, ponieważ należą do firm korporacyjnych i zawierają poufne i osobiste informacje. Jednym z możliwych sposobów złagodzenia problemów związanych z poufnością jest szkolenie z wykorzystaniem syntetycznych zestawów danych (Roszczenia dotyczące pojazdów).
Audytowanie zbiorów danych pod kątem wykrywania anomalii
Roszczenia ubezpieczeniowe dotyczące pojazdów obejmują informacje o właściwościach pojazdu, takie jak model, marka, cena, rok produkcji i rodzaj paliwa. Zawiera informacje o kierowcy, dacie urodzenia, płci i zawodzie. Dodatkowo reklamacja może zawierać informację o całkowitym koszcie naprawy. Zestawy danych używane w tym artykule pochodzą z jednej domeny, ale różnią się liczbą atrybutów i liczbą wystąpień.
-
Zbiór danych Vehicle Claims jest duży i zawiera ponad 250,000 1171 wierszy, a jego atrybuty kategorialne mają kardynalność równą XNUMX. Ze względu na duży rozmiar ten zbiór danych cierpi na przekleństwo wymiarowości.
- Zestaw danych Ubezpieczenia pojazdów jest średniej wielkości i zawiera 15,420 151 wierszy oraz XNUMX unikatowych wartości kategorycznych. Dzięki temu jest mniej podatny na przekleństwo wymiarowości.
- Zbiór danych Car Insurance jest mały, zawiera etykiety i 25% nieprawidłowych próbek i zawiera podobną liczbę cech liczbowych i jakościowych. Dzięki 169 unikalnym kategoriom nie cierpi na klątwę wymiarowości.
Kodowanie atrybutów kategorialnych
Różne kodowania wartości kategorycznych
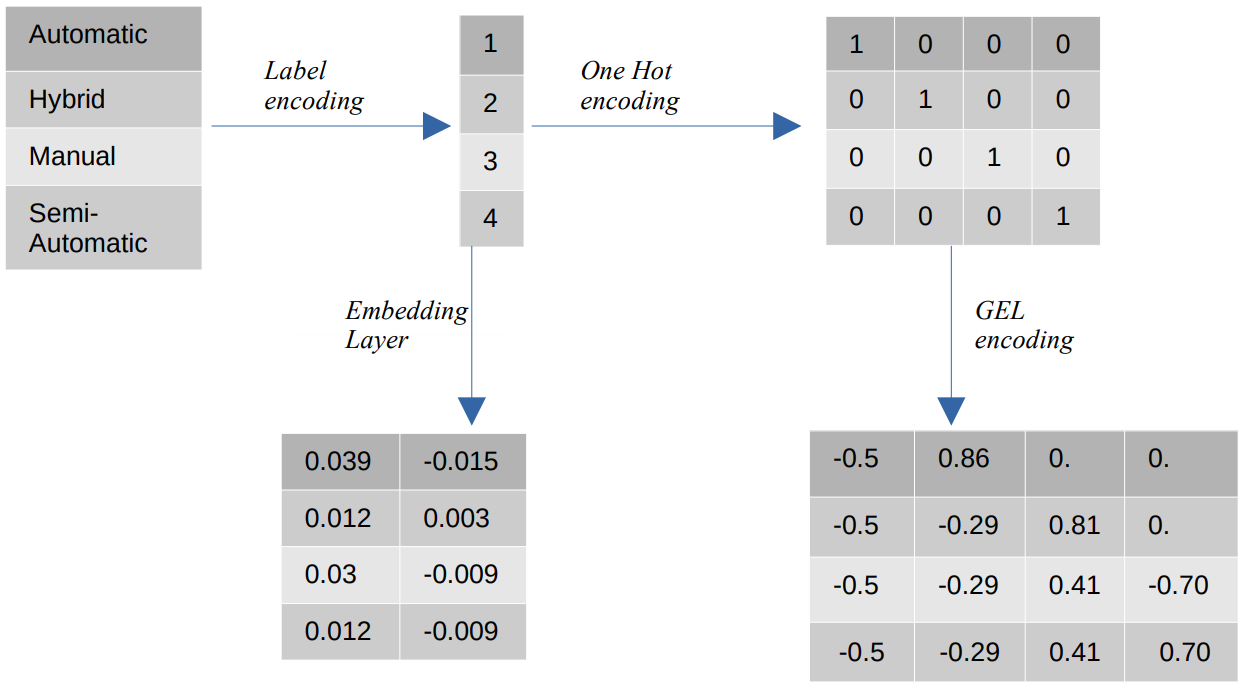
- Kodowanie etykiet – W kodowaniu etykiet wartości kategoryczne są zastępowane liczbowymi wartościami całkowitymi z zakresu od 1 do liczby kategorii. Kodowanie etykiet reprezentuje kategorie w zamierzony sposób dla wartości porządkowych. Jednak gdy cechy są nominalne, reprezentacja jest błędna, ponieważ wartości kategoryczne nie są zgodne z określonym porządkiem.
Na przykład, jeśli w obiekcie mamy kategorie takie jak Automatyczna, Hybrydowa, Ręczna i Półautomatyczna, kodowanie etykiet przekształca te wartości na {1: Automatyczne, 2: Hybrydowe, 3: Ręczne, 4: Półautomatyczne}. Ta reprezentacja nie dostarcza żadnych informacji o wartościach kategorycznych, ale reprezentacja taka jak {0: Niska, 1: Średnia, 2: Wysoka} zapewnia jasną reprezentację, ponieważ zmiennej cechy Niska jest przypisana niższa wartość liczbowa. Dlatego kodowanie etykiet jest lepsze dla wartości porządkowych, ale niekorzystne dla wartości nominalnych. - Jedno gorące kodowanie – Jedno kodowanie Hot służy do rozwiązania problemu nominalnych wartości kodowania, które przekształca każdą wartość kategoryczną w odrębną cechę w zbiorze danych składającym się z wartości binarnych. Na przykład w przypadku czterech różnych kategorii zakodowanych jako {1, 2, 3, 4} kodowanie One Hot stworzyłoby nowe funkcje, takie jak {Automatic: [1,0,0,0], Hybrid: [0,1,0,0 ,0,0,1,0], Ręczny: [0,0,0,1], Półautomatyczny: [XNUMX]}.
Wymiar zbioru danych zależy wtedy bezpośrednio od liczby kategorii obecnych w zbiorze danych. W rezultacie kodowanie One Hot może prowadzić do przekleństwa wymiarowości, co jest wadą tej metody kodowania. - Kodowanie żelowe – Kodowanie GEL to technika osadzania, która może być stosowana w metodach uczenia nadzorowanego i nienadzorowanego. Opiera się na zasadzie kodowania One Hot i może służyć do zmniejszania wymiarowości cech kategorycznych, które zostały zakodowane przy użyciu kodowania One Hot.
- Warstwa osadzania - Osadzanie słów umożliwia użycie zwartej i gęstej reprezentacji, w której podobne słowa mają podobne kodowanie. Osadzanie to gęsty wektor wartości zmiennoprzecinkowych, które są parametrami, które można trenować. Osadzanie słów może mieć zakres od 8-wymiarowych (w przypadku małych zestawów danych) do 1024-wymiarowych (w przypadku dużych zestawów danych).
Osadzanie o wyższych wymiarach może uchwycić bardziej szczegółowe relacje między słowami, ale wymaga większej ilości danych do nauczenia się. Warstwa osadzania to tabela przeglądowa, która konwertuje każde słowo obecne w macierzy na wektor o określonym rozmiarze.
Modele wykrywania anomalii bez nadzoru
W świecie rzeczywistym dane w większości przypadków nie są etykietowane, a etykietowanie danych jest kosztowne i czasochłonne. Dlatego do naszych ocen użyjemy modeli bez nadzoru.
- SOM - Samoorganizująca się mapa (SOM) to konkurencyjna metoda uczenia się, w której wagi neuronów są aktualizowane w sposób konkurencyjny, zamiast korzystania z uczenia wstecznego. SOM składa się z mapy neuronów, z których każdy ma wektor wagi o takim samym rozmiarze jak wektor wejściowy. Wektor wagi jest inicjowany losowymi wagami przed rozpoczęciem treningu. Podczas uczenia każde wejście jest porównywane z neuronami mapy w oparciu o metrykę odległości (np. odległość euklidesową) i jest mapowane do jednostki najlepszego dopasowania (BMU), czyli neuronu o minimalnej odległości od wektora wejściowego.
Wagi BMU są aktualizowane o wagi wektora wejściowego, a sąsiednie neurony są aktualizowane na podstawie promienia sąsiedztwa (sigma). Ponieważ neurony konkurują ze sobą, aby być najlepiej dopasowaną jednostką, proces ten jest znany jako konkurencyjne uczenie się. W końcu neurony dla normalnych próbek są bliżej niż te anomalne. Wyniki anomalii są definiowane przez błąd kwantyzacji, który jest różnicą między próbką wejściową a wagami najlepiej dopasowanej jednostki. Wyższy błąd kwantyzacji wskazuje na większe prawdopodobieństwo, że próbka jest anomalią. - DAGMM – Deep Autoencoding Gaussian Mixture Model (DAGMM) to metoda szacowania gęstości, która zakłada, że anomalie leżą w obszarze o niskim prawdopodobieństwie. Sieć jest podzielona na dwie części: sieć kompresji, która służy do rzutowania danych do niższych wymiarów za pomocą autoenkodera, oraz sieć estymacji, która służy do estymacji parametrów modelu mieszaniny Gaussa. DAGMM szacuje liczbę k mieszanin Gaussa, gdzie k może być dowolną liczbą od 1 do N (liczba punktów danych), i zakłada się, że normalne punkty leżą w obszarze o dużej gęstości, co oznacza, że prawdopodobieństwo pobrania próbki z Mieszanka Gaussa jest wyższa dla normalnych punktów niż dla próbek anomalnych. Wyniki anomalii są definiowane przez oszacowaną energię próbki.
- RSRAE – Robust Surface Recovery Layer for Unsupervised Anomaly Detection to metoda błędu rekonstrukcji, która najpierw wyświetla dane w niższym wymiarze za pomocą autoenkodera. Ukryta reprezentacja jest następnie poddawana ortogonalnej projekcji na liniową podprzestrzeń, która jest odporna na wartości odstające. Następnie dekoder rekonstruuje dane wyjściowe z liniowej podprzestrzeni. W tej metodzie większy błąd rekonstrukcji wskazuje na większe prawdopodobieństwo, że próbka jest anomalią.
- SOM-DAGMM- Samoorganizująca się mapa (SOM) - Deep Autoencoding Gaussian Mixture Model (DAGMM) jest również modelem szacowania gęstości. Podobnie jak DAGMM, szacuje również rozkład prawdopodobieństwa normalnych punktów danych i klasyfikuje punkt danych jako anomalię, jeśli ma niskie prawdopodobieństwo, że zostanie pobrany z wyuczonej dystrybucji. Główna różnica między SOM-DAGMM i DAGMM polega na tym, że SOM-DAGMM zawiera znormalizowane współrzędne SOM dla próbki wejściowej, co zapewnia brakujące informacje topologiczne w przypadku DAGMM do sieci estymacji. Cel jest również podobny do DAGMM, ponieważ wyniki anomalii są definiowane przez oszacowaną energię próbki, a niska energia wskazuje na większe prawdopodobieństwo, że próbka będzie anomalią.
Następnie zajmiemy się wyzwaniem związanym z obsługą atrybutów kategorycznych.
Jak kodowanie atrybutów kategorialnych wpływa na modele?
Aby zrozumieć wpływ różnych kodowań na zestawy danych, użyjemy t-SNE do wizualizacji niskowymiarowych reprezentacji danych dla różnych kodowań. t-SNE wyświetla wielowymiarowe dane w przestrzeni o niższych wymiarach, ułatwiając ich wizualizację. Porównując wizualizacje t-SNE i wyniki numeryczne różnych kodowań tego samego zestawu danych, można zaobserwować różnicę w uzyskanych reprezentacjach i zrozumieniu wpływu kodowania na zbiór danych.
Reprezentacja t-SNE zbioru danych ubezpieczenia samochodu
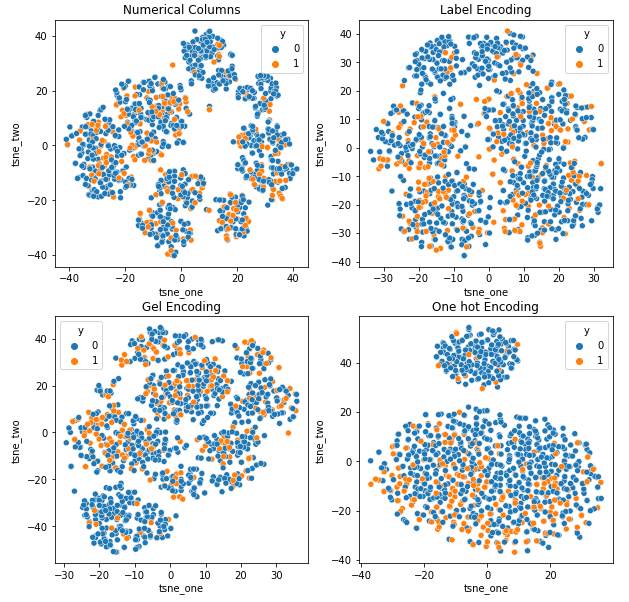
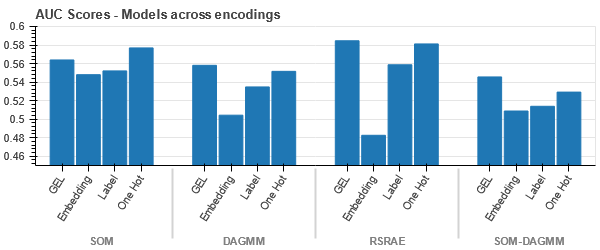
Reprezentacja t-SNE zbioru danych ubezpieczenia pojazdu
-
Dane są bliżej siebie, ponieważ liczba wierszy jest większa niż w zbiorze danych Car Insurance. Rozdzielenie przy zwiększonej wymiarowości w kodowaniu One Hot staje się trudne.
-
Kodowanie GEL jest lepsze niż kodowanie One Hot we wszystkich przypadkach z wyjątkiem DAGMM.
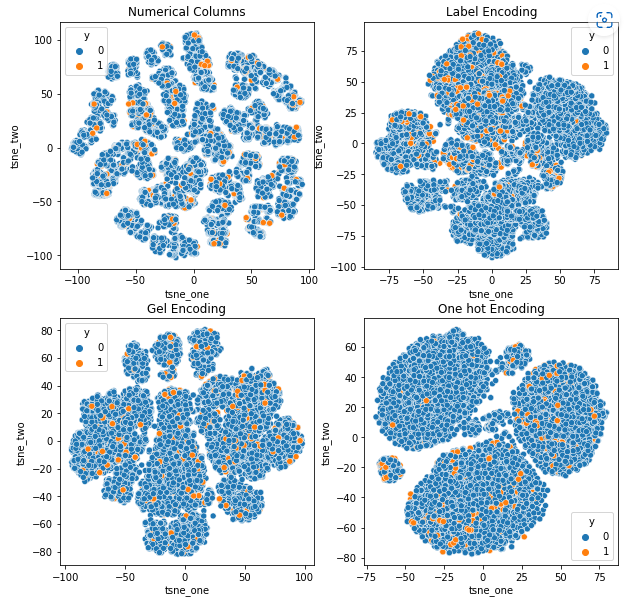
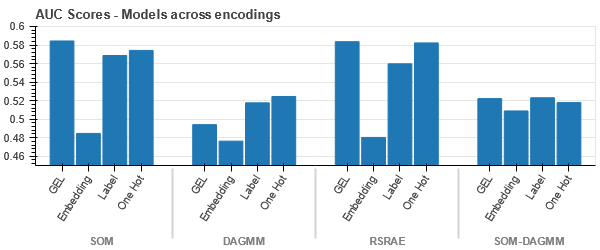
Reprezentacja t-SNE zbioru danych roszczeń dotyczących pojazdów
-
Dane są ściśle powiązane we wszystkich przypadkach, co utrudnia ich rozdzielenie przy zwiększonej wymiarowości. Jest to jedna z przyczyn słabej wydajności modeli ze względu na zwiększoną wymiarowość.
- SOM przewyższa wszystkie inne modele dla tego zestawu danych. Mimo to warstwa osadzania jest w większości przypadków bardziej odpowiednia, co stanowi alternatywę dla kodowania atrybuty kategoryczne do wykrywania anomalii.
Wnioski
W tym artykule przedstawiono krótkie omówienie inspekcji danych, wykrywania anomalii i kodowania kategorycznego. Ważne jest, aby zrozumieć, że obsługa atrybutów kategorycznych w danych kontrolnych jest trudna. Dzięki zrozumieniu wpływu kodowania atrybutów na modele możemy poprawić dokładność wykrywania anomalii w zestawach danych. Kluczowe wnioski z tego artykułu to:
- Wraz ze wzrostem rozmiaru danych ważne jest stosowanie alternatywnych metod kodowania dla atrybutów kategorycznych, takich jak kodowanie GEL i warstwy osadzania, ponieważ kodowanie One Hot jest nieodpowiednie.
- Jeden model nie działa dla wszystkich zestawów danych. W przypadku zestawów danych tabelarycznych znajomość dziedziny jest niezwykle ważna.
- Wybór metody kodowania zależy od wyboru modelu.
Kod do oceny modeli jest dostępny na GitHub.
Media pokazane w tym artykule nie są własnością Analytics Vidhya i są wykorzystywane według uznania Autora.
Związane z
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://www.analyticsvidhya.com/blog/2023/01/impact-of-categorical-encodings-on-anomaly-detection-methods/
- 000
- 1
- 10
- 420
- a
- O nas
- powyżej
- Stosownie
- precyzja
- do tego
- adres
- Wszystkie kategorie
- pozwala
- alternatywny
- zawsze
- analityka
- Analityka Widhja
- i
- wykrywanie anomalii
- awanse
- artykuł
- przydzielony
- powiązany
- przypuszczalny
- atrybuty
- audytu
- automatycznie
- dostępny
- na podstawie
- bo
- staje się
- zanim
- jest
- poniżej
- Benchmarki
- BEST
- Ulepsz Swój
- pomiędzy
- Najwyższa
- związany
- marka
- nie może
- zdobyć
- wózek
- ubezpieczenie samochodu
- karta
- walizka
- Etui
- kategorie
- wyzwanie
- wyzwania
- wyzwanie
- duża szansa,
- charakter
- wybór
- roszczenie
- roszczenia
- klasa
- Klasy
- klasyfikacja
- Klasyfikuj
- jasny
- bliższy
- kod
- kolor
- powszechnie
- społeczność
- Firmy
- w porównaniu
- porównanie
- rywalizować
- konkurencyjny
- kompleks
- pojęcie
- poufność
- Składający się
- zawiera
- ciągły
- Korporacyjny
- Koszty:
- Stwórz
- kredyt
- Karta kredytowa
- dane
- punkty danych
- zbiory danych
- Data
- czynienia
- spadek
- głęboko
- głęboka nauka
- zależy
- szczegółowe
- Wykrywanie
- Ustalać
- różnica
- różne
- trudny
- Wymiary
- Wymiary
- bezpośrednio
- dyskrecja
- dystans
- odrębny
- 分配
- podzielony
- domena
- kierowca
- podczas
- każdy
- łatwiej
- bądź
- energia
- błąd
- Błędy
- oszacowanie
- szacunkowa
- Szacunki
- itp
- oceniać
- ewaluację
- oceny
- przykład
- przykłady
- Z wyjątkiem
- drogi
- niezwykle
- w obliczu
- Czynniki
- Cecha
- Korzyści
- i terminów, a
- las
- oszustwo
- nieuczciwy
- od
- Paliwo
- Płeć
- Grupy
- Prowadzenie
- Wysoki
- wyższy
- HOT
- Jednak
- HTTPS
- Hybrydowy
- identyfikacja
- Rezultat
- ważny
- podnieść
- in
- zawierać
- obejmuje
- Dochód
- wzrosła
- Zwiększenia
- wzrastający
- wskazuje
- Informacja
- Systemy informacyjne
- wkład
- ubezpieczenie
- izolacja
- problem
- problemy
- IT
- Klawisz
- Wiedzieć
- wiedza
- znany
- Etykieta
- etykietowanie
- Etykiety
- duży
- większe
- warstwa
- nioski
- prowadzić
- UCZYĆ SIĘ
- dowiedziałem
- nauka
- miejscowy
- usytuowany
- wyszukiwania
- od
- straty
- niski
- maszyna
- uczenie maszynowe
- maszyny
- Główny
- WYKONUJE
- Dokonywanie
- obowiązkowe
- podręcznik
- wiele
- mapa
- dopasowywanie
- Matrix
- znaczenie
- Media
- średni
- metoda
- metody
- metryczny
- minimum
- brakujący
- Złagodzić
- mieszanina
- model
- modele
- jeszcze
- większość
- sieć
- Neurony
- Nowości
- Nowe funkcje
- normalna
- numer
- cel
- ONE
- zamówienie
- Inne
- Przewyższa
- Przezwyciężać
- przegląd
- własność
- parametry
- część
- strony
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- wykonuje
- osobisty
- plato
- Analiza danych Platona
- PlatoDane
- punkt
- zwrotnica
- biedny
- Popularny
- możliwy
- woleć
- teraźniejszość
- prezenty
- Cena
- zasada
- Wcześniejszy
- prawdopodobieństwo
- Problem
- wygląda tak
- zawód
- projekt
- dane projektu
- Projekcja
- projektowanie
- niska zabudowa
- zapewniać
- pod warunkiem,
- zapewnia
- opublikowany
- przypadkowy
- zasięg
- real
- Prawdziwy świat
- Przyczyny
- regeneracja
- region
- Relacje
- naprawy
- otrzymuje
- reprezentacja
- reprezentuje
- Wymaga
- dalsze
- wynikły
- Efekt
- krzepki
- taki sam
- nauka
- wrażliwy
- oddzielny
- pokazane
- Sigma
- podobny
- ponieważ
- pojedynczy
- Rozmiar
- mały
- mniejszy
- So
- Typ przestrzeni
- specyficzny
- rozpocznie
- Nadal
- taki
- Cierpią
- odpowiedni
- wsparcie
- Powierzchnia
- syntetyczny
- systemy
- stół
- Takeaways
- REGULAMIN
- Połączenia
- świat
- w związku z tym
- próg
- ciasno
- czasochłonne
- do
- Kwota produktów:
- Pociąg
- Trening
- zrozumieć
- zrozumienie
- wyjątkowy
- jednostka
- uczenie się bez nadzoru
- zaktualizowane
- us
- posługiwać się
- wartość
- Wartości
- pojazd
- Pojazdy
- waga
- Co
- Co to jest
- który
- Podczas
- będzie
- słowo
- słowa
- Praca
- świat
- by
- rok
- zefirnet