Przepływy pracy zarządzane przez Amazon dla Apache Airflow (Amazon MWAA) to zarządzana usługa orkiestracji dla Przepływ powietrza Apache co ułatwia konfigurowanie i obsługę kompleksowych potoków danych w chmurze na dużą skalę. Potok danych to zestaw zadań i procesów służących do automatyzacji przenoszenia i przekształcania danych między różnymi systemami. Społeczność open source Apache Airflow zapewnia ponad 1,000 gotowych operatorów (wtyczek upraszczających połączenia z usługami) dla Apache Airflow do tworzenia potoków danych. The Pakiet dostawcy Amazon dla Apache Airflow zawiera integracje dla ponad 31 usług AWS, takich jak Usługa Amazon Simple Storage (Amazonka S3), Amazonka Przesunięcie ku czerwieni, Amazon EMR, Klej AWS, Amazon Sage MakerI więcej.
Najczęstszym przypadkiem użycia Airflow jest ETL (extract, transform, load). Prawie wszyscy użytkownicy Airflow wdrażają potoki ETL, od prostych do złożonych. Operacjonalizacja uczenia maszynowego (ML) to kolejny rosnący przypadek użycia, w którym dane muszą zostać przekształcone i znormalizowane, zanim będzie można je załadować do modelu ML. W obu przypadkach potok danych przygotowuje dane do użycia przez pozyskiwanie danych z różnych źródeł i przekształcanie ich w szeregu kroków.
Obserwowalność różnych procesów w potoku danych jest kluczowym elementem monitorowania sukcesu lub niepowodzenia potoku. Chociaż planowanie uruchamiania zadań w potoku danych jest kontrolowane przez Airflow, samo wykonanie zadania (przekształcanie, normalizowanie i agregowanie danych) jest wykonywane przez różne usługi w zależności od przypadku użycia. Kompleksowy widok przepływu danych jest wyzwaniem ze względu na wiele punktów styku w potoku danych.
W tym poście przedstawiamy przegląd ulepszeń logowania podczas pracy z Amazon MWAA, który jest jednym z filarów obserwowalności. Następnie omawiamy rozwiązanie w celu dalszego zwiększenia kompleksowej obserwowalności poprzez modyfikację definicji zadań, które składają się na potok danych. W tym poście skupimy się na definicjach zadań dla dwóch usług: AWS Glue i Amazon EMR, jednak ta sama metoda może być zastosowana w różnych usługach.
Opis projektu
Potoki danych wielu klientów rozpoczynają się od prostego organizowania kilku zadań, az czasem stają się bardziej złożone, składające się z dużej liczby zadań i zależności między nimi. Wraz ze wzrostem złożoności staje się coraz trudniej obsługiwać i debugować w przypadku awarii, co stwarza potrzebę pojedynczej szyby do zapewnienia kompleksowej orkiestracji potoków danych i zarządzania stanem. W przypadku aranżacji potoku danych plik Interfejs Apache Airflow to przyjazne dla użytkownika narzędzie, które zapewnia szczegółowe widoki potoku danych. Jeśli chodzi o zarządzanie stanem potoku, każda usługa, z którą wchodzą w interakcje Twoje zadania, może przechowywać lub publikować dzienniki w różnych lokalizacjach, takich jak zasobnik S3 lub Amazon Cloud Watch logi. Wraz ze wzrostem liczby punktów styku integracji łączenie rozproszonych dzienników generowanych przez różne usługi w różnych lokalizacjach może być trudne.
Jedno rozwiązanie dostarczone przez Amazon MWAA do konsolidacji dzienników przepływu powietrza i zadań w ramach skierowany graf acykliczny (DAG) jest przekazanie dzienników do Grupy dzienników CloudWatch. Dla każdej włączonej opcji rejestrowania przepływu powietrza tworzona jest oddzielna grupa dzienników (np. DAGProcessing, Scheduler, Task, WebServer, Worker). Te dzienniki można przeszukiwać w grupach dzienników przy użyciu CloudWatch Logs Insights.
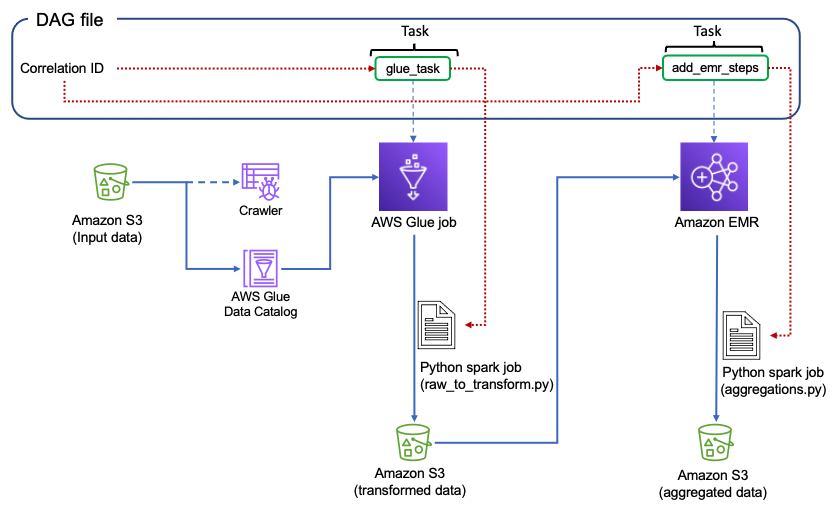
Typowym podejściem do śledzenia rozproszonego jest użycie identyfikatora korelacji do łączenia i wysyłania zapytań do dzienników rozproszonych. Identyfikator korelacji to unikatowy identyfikator, który jest przekazywany przez przepływ żądań w celu śledzenia sekwencji działań przez cały okres istnienia przepływu pracy. Gdy każda usługa w przepływie pracy musi rejestrować informacje, może zawierać ten identyfikator korelacji, zapewniając w ten sposób śledzenie pełnego żądania od początku do końca.
Silnik Airflow mija kilka zmienne domyślnie dostępne dla wszystkich szablonów. run_id jest jedną z takich zmiennych, która jest unikalnym identyfikatorem przebiegu DAG. The run_id może służyć jako identyfikator korelacji do wysyłania zapytań do różnych grup dzienników w CloudWatch w celu przechwycenia wszystkich dzienników dla określonego przebiegu DAG.
Należy jednak pamiętać, że usługi, z którymi współpracują Twoje zadania, będą używać oddzielnej grupy dzienników i nie będą rejestrować run_id jako część ich produkcji. Uniemożliwi to uzyskanie kompleksowego widoku całego przebiegu DAG.
Na przykład, jeśli potok danych składa się z zadania AWS Glue uruchamiającego zadanie Spark w ramach potoku, dzienniki zadań Airflow będą dostępne w jednej grupie dzienników CloudWatch, a dzienniki zadań AWS Glue będą w innej grupie dzienników CloudWatch . Jednak zadanie Spark, które jest uruchamiane jako część zadania AWS Glue, nie ma dostępu do identyfikatora korelacji i nie może być powiązane z konkretnym przebiegiem DAG. Więc nawet jeśli używasz identyfikatora korelacji do wysyłania zapytań do różnych grup dzienników CloudWatch, nie uzyskasz żadnych informacji o uruchomieniu zadania platformy Spark.
Omówienie rozwiązania
Jak teraz wiesz, run_id jest zmienną, która jest unikalnym identyfikatorem przebiegu DAG. The run_id jest obecny jako część dzienników zadań Airflow. Aby użyć run_id skutecznie i zwiększyć obserwowalność w przebiegu DAG, którego używamy run_id jako identyfikator korelacji i przekazać go do różnych zadań z DAG. Identyfikator korelacji jest następnie używany przez skrypty używane w zadaniach.
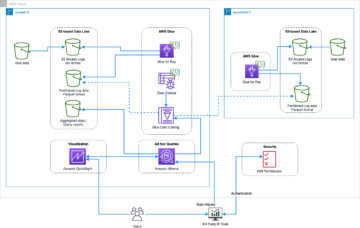
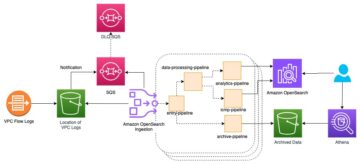
Poniższy schemat ilustruje architekturę rozwiązania.
Potok danych, na którym się skupiamy, składa się z następujących komponentów:
- Zasobnik S3 zawierający dane źródłowe
- An Robot indeksujący AWS Glue który tworzy metadane tabeli w wykazie danych z danych źródłowych
- An AWS Klej zadanie który przekształca surowe dane w przetworzony format danych podczas wykonywania konwersji formatu pliku
- An praca ERM który generuje zestawy danych raportowania
Aby uzyskać szczegółowe informacje na temat architektury i kompletne kroki dotyczące uruchamiania DAG, patrz Warsztaty Amazon MWAA dla analityki.
W kolejnych sekcjach omawiamy następujące tematy:
- Plik DAG, aby zrozumieć, jak zdefiniować, a następnie przekazać identyfikator korelacji w zadaniach AWS Glue i EMR
- Kod potrzebny w skryptach języka Python do wyprowadzania informacji na podstawie identyfikatora korelacji
Patrz: GitHub repo aby uzyskać szczegółową definicję DAG i skrypty Spark. Aby uruchomić skrypty, zapoznaj się z sekcją Warsztaty analityczne Amazon MWAA.
definicje DAG
W tej sekcji przyjrzymy się fragmentom dodatków potrzebnych do pliku DAG. Omówimy również, jak przekazać identyfikator korelacji do zadań AWS Glue i EMR. Patrz GitHub repo dla pełnego kodu DAG.
Plik DAG zaczyna się od zdefiniowania zmiennych:
# Zmienne
Następnie przyjrzyjmy się, jak przekazać identyfikator korelacji do zadania AWS Glue za pomocą operatora AWS Glue. Operatorzy są elementami budulcowymi DAG Airflow. Zawierają logikę przetwarzania danych w potoku danych. Każde zadanie w DAG jest definiowane przez utworzenie instancji operatora.
Airflow zapewnia operatorom różne zadania. W tym poście używamy Operator kleju AWS.
Definicja zadania AWS Glue zawiera następujące elementy:
- Skrypt zadania Python Spark (raw_to_transform.py), aby uruchomić zadanie
- Nazwa DAG, identyfikator zadania i identyfikator korelacji, które są przekazywane jako argumenty
- Połączenia Rola usługi AWS Glue przypisany, który ma uprawnienia do uruchamiania przeszukiwacza i zadań
Zobacz następujący kod:
# Definicja zadania kleju
Następnie przekazujemy identyfikator korelacji do zadania EMR przy użyciu Operator EMR. Obejmuje to następujące kroki:
- Zdefiniuj konfigurację klastra EMR.
- Utwórz klaster EMR.
- Zdefiniuj kroki, które ma wykonać zadanie EMR.
- Uruchom zadanie EMR:
- Używamy skryptu zadania Python Spark agregacje.py.
- Przekazujemy nazwę DAG, identyfikator zadania i identyfikator korelacji jako argumenty do kroków dla zadania EMR.
Zacznijmy od zdefiniowania konfiguracji dla klastra EMR. The correlation_id jest przekazywany w nazwie klastra, aby łatwo zidentyfikować klaster odpowiadający przebiegowi DAG. Dzienniki generowane przez zadania EMR są publikowane w zasobniku S3; the correlation_id jest częścią LogUri również. Zobacz następujący kod:
# Zdefiniuj konfigurację klastra EMR
Zdefiniujmy teraz zadanie tworzenia klastra EMR na podstawie konfiguracji:
# Utwórz klaster EMR
cluster_creator = EmrCreateJobFlowOperator( task_id= emr_task_id, job_flow_overrides=JOB_FLOW_OVERRIDES, aws_conn_id=’aws_default’, emr_conn_id=’emr_default’, dag=dag
)Następnie zdefiniujmy kroki potrzebne do uruchomienia w ramach zadania EMR. Dane wejściowe i wyjściowe przetwarzane przez zadanie EMR są przechowywane w zasobniku S3 przekazywanym jako argumenty. Dag_name, task_id, correlation_id są również przekazywane jako argumenty. Użyty identyfikator_zadania może być wybraną nazwą; tutaj używamy add_steps:
# Kroki EMR do wykonania przez klaster EMR
Następnie Dodajmy zadanie, aby uruchomić kroki w klastrze EMR. The job_flow_id jest identyfikatorem JobFlow, który jest przekazywany z EMR create task opisane wcześniej użycie XCom przepływu powietrza. Zobacz następujący kod:
#Uruchom zadanie EMR
To kończy kroki wymagane do przekazania identyfikatora korelacji w ramach definicji zadania DAG.
W następnej sekcji użyjemy tego identyfikatora w uruchamianym skrypcie do rejestrowania szczegółów.
Definicje skryptów pracy
W tej sekcji przejrzymy zmiany wymagane do rejestrowania informacji na podstawie correlation_id. Zacznijmy od skryptu zadania AWS Glue (pełny kod znajduje się poniżej filet w GitHubie):
# Zmiany skryptu w pliku „raw_to_transform”
Następnie skupimy się na skrypcie zadania EMR (pełny kod można znaleźć w pliku filet w GitHubie):
# Zmiany skryptu w pliku „nyc_agregations”
To kończy kroki przekazywania identyfikatora korelacji do uruchomienia skryptu.
Po uzupełnieniu definicji DAG i uzupełnieniu skryptów możemy uruchomić DAG. Dzienniki dla określonego przebiegu DAG można przeszukiwać przy użyciu identyfikatora korelacji. Identyfikator korelacji dla przebiegu DAG można znaleźć za pośrednictwem pliku Interfejs przepływu powietrza. Przykładem identyfikatora korelacji jest manual__2022-07-12T00:22:36.111190+00:00. Dzięki temu unikalnemu ciągowi możemy uruchamiać zapytania w odpowiednich grupach dzienników CloudWatch za pomocą CloudWatch Logs Insights. Wynik zapytania obejmuje logowanie dostarczone przez skrypty AWS Glue i EMR, wraz z innymi dziennikami powiązanymi z identyfikatorem korelacji.
Przykładowe zapytanie o dzienniki poziomu DAG: manual__2022-07-12T00:22:36.111190+00:00
Możemy również uzyskać dzienniki na poziomie zadania, używając formatu <dag_name.task_id correlation_id>:
Przykładowe zapytanie: data_pipeline.glue_task manual__2022-07-12T00:22:36.111190+00:00
Sprzątać
Jeśli utworzyłeś konfigurację do uruchamiania i testowania skryptów przy użyciu Warsztaty analityczne Amazon MWAA, Wykonaj cleanup kroki, aby uniknąć ponoszenia opłat.
Wnioski
W tym poście pokazaliśmy, jak wysłać logi Amazon MWAA do grup logów CloudWatch. Następnie omówiliśmy, jak powiązać dzienniki z różnych zadań w ramach DAG przy użyciu unikalnego identyfikatora korelacji. Identyfikator korelacji można wyprowadzić z taką samą ilością lub niewielką ilością informacji, jaka jest wymagana przez zadanie, aby zapewnić więcej szczegółów w całym przebiegu DAG. Następnie możesz użyć usługi CloudWatch Logs Insights, aby wysłać zapytanie do dzienników.
Dzięki temu rozwiązaniu możesz używać Amazon MWAA jako jednego panelu do orkiestracji potoków danych i dzienników CloudWatch do zarządzania stanem potoków danych. Unikalny identyfikator poprawia kompleksową obserwowalność przebiegu DAG i pomaga skrócić czas potrzebny do rozwiązywania problemów.
Aby dowiedzieć się więcej i zdobyć praktyczne doświadczenie, zacznij od Warsztaty analityczne Amazon MWAA a następnie użyj skryptów w GitHub repo aby uzyskać większą obserwowalność przebiegu DAG.
O autorze
 Payala Singha jest architektem rozwiązań partnerskich w Amazon Web Services, koncentruje się na platformie Serverless. Jest odpowiedzialna za pomoc partnerom i klientom w modernizacji i migracji ich aplikacji do AWS.
Payala Singha jest architektem rozwiązań partnerskich w Amazon Web Services, koncentruje się na platformie Serverless. Jest odpowiedzialna za pomoc partnerom i klientom w modernizacji i migracji ich aplikacji do AWS.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/improve-observability-across-amazon-mwaa-tasks/
- 000
- 1
- 10
- 100
- 11
- a
- O nas
- dostęp
- dostępny
- w poprzek
- zajęcia
- acykliczny
- wzbogacenie
- przed
- Wszystkie kategorie
- Chociaż
- Amazonka
- Amazon Web Services
- analityka
- i
- Inne
- Apache
- aplikacje
- stosowany
- podejście
- architektura
- argumenty
- przydzielony
- powiązany
- zautomatyzować
- dostępny
- uniknąć
- AWS
- Klej AWS
- z powrotem
- na podstawie
- staje się
- zanim
- pomiędzy
- Bloki
- budować
- budowniczy
- Budowanie
- zdobyć
- walizka
- Etui
- katalog
- wyzwanie
- wyzwanie
- Zmiany
- Opłaty
- wybór
- Chmura
- Grupa
- kod
- wspólny
- społeczność
- kompletny
- Ukończył
- kompleks
- kompleksowość
- składnik
- składniki
- systemu
- połączenia
- Składający się
- konsolidować
- spożywane
- konsumpcja
- zawiera
- kontrolowanych
- rdzeń
- Korelacja
- Odpowiedni
- mógłby
- crawler
- Stwórz
- stworzony
- tworzy
- Klientów
- DZIEŃ
- dane
- Domyślnie
- zdefiniowane
- definiowanie
- opisane
- szczegółowe
- detale
- różne
- dyskutować
- omówione
- dystrybuowane
- Nie
- na dół
- każdy
- Wcześniej
- z łatwością
- faktycznie
- włączony
- koniec końców
- silnik
- zapewnienie
- Cały
- Eter (ETH)
- Parzyste
- przykład
- doświadczenie
- odkryj
- wyciąg
- Brak
- kilka
- filet
- koniec
- pływ
- Skupiać
- koncentruje
- następujący
- format
- Naprzód
- znaleziono
- od
- pełny
- Funkcje
- dalej
- Wzrost
- wygenerowane
- generuje
- otrzymać
- miejsce
- GitHub
- szkło
- wykres
- Zarządzanie
- Grupy
- Rosnąć
- Rozwój
- hands-on
- Ciężko
- mający
- Zdrowie
- pomoc
- pomaga
- tutaj
- W jaki sposób
- How To
- Jednak
- HTML
- HTTPS
- identyfikator
- zidentyfikować
- wdrożenia
- importować
- podnieść
- poprawia
- in
- zawierać
- obejmuje
- Zwiększać
- Zwiększenia
- coraz bardziej
- Informacja
- wkład
- spostrzeżenia
- integracja
- integracje
- interakcji
- IT
- samo
- Praca
- Oferty pracy
- Klawisz
- Wiedzieć
- duży
- UCZYĆ SIĘ
- nauka
- poziom
- dożywotni
- mało
- załadować
- lokalizacji
- log4j
- Popatrz
- maszyna
- uczenie maszynowe
- robić
- WYKONUJE
- zarządzane
- i konserwacjami
- rynek
- mistrz
- Metadane
- metoda
- migrować
- ML
- model
- modele
- zmodernizować
- monitor
- jeszcze
- większość
- ruch
- wielokrotność
- Nazwa
- prawie
- Potrzebować
- potrzebne
- wymagania
- Następny
- węzły
- numer
- uzyskać
- ONE
- open source
- działać
- operator
- operatorzy
- Option
- orkiestracja
- zamówienie
- Inne
- przegląd
- chleb
- część
- szczególny
- partnerem
- minęło
- przebiegi
- Przechodzący
- wykonać
- wykonywania
- uprawnienia
- rurociąg
- Platforma
- plato
- Analiza danych Platona
- PlatoDane
- wtyczki
- zwrotnica
- Post
- przygotowanie
- teraźniejszość
- zapobiec
- procesów
- zapewniać
- pod warunkiem,
- dostawca
- dostawców
- zapewnia
- opublikowany
- Wydawniczy
- Python
- nośny
- Surowy
- surowe dane
- zmniejszyć
- Raportowanie
- zażądać
- wymagany
- odpowiedzialny
- dalsze
- przeglądu
- run
- bieganie
- taki sam
- SC
- Skala
- skrypty
- Sekcja
- działy
- oddzielny
- Sekwencja
- Serie
- Bezserwerowe
- usługa
- Usługi
- Sesja
- zestaw
- ustawienie
- Prosty
- upraszczać
- pojedynczy
- So
- rozwiązanie
- Rozwiązania
- Źródło
- Źródła
- Iskra
- SQL
- początek
- rozpoczęty
- Cel
- przechowywanie
- przechowywany
- sukces
- taki
- systemy
- stół
- Zadanie
- zadania
- Szablony
- test
- Połączenia
- Źródło
- ich
- a tym samym
- Przez
- poprzez
- TIE
- Związany
- czas
- do
- narzędzie
- tematy
- Kontakt
- Rysunek kalkowy
- śledzić
- Śledzenie
- Przekształcać
- Transformacja
- przekształcony
- transformatorowy
- prawdziwy
- zrozumieć
- wyjątkowy
- Stosowanie
- posługiwać się
- przypadek użycia
- łatwy w obsłudze
- Użytkownicy
- różnorodny
- przez
- Zobacz i wysłuchaj
- widoki
- sieć
- usługi internetowe
- który
- Podczas
- będzie
- w ciągu
- workflow
- przepływów pracy
- pracujący
- warsztaty
- Twój
- zefirnet