Generatywna sztuczna inteligencja znajduje się w okresie oszałamiającego wzrostu. Coraz bardziej wydajne modele podstawowe są wydawane w sposób ciągły, a duże modele językowe (LLM) są jedną z najbardziej widocznych klas modeli. LLM to modele złożone z miliardów parametrów wyszkolonych na obszernych korpusach tekstowych, do setek miliardów, a nawet bilionów tokenów. Modele te okazały się niezwykle skuteczne w przypadku szerokiego zakresu zadań tekstowych, od odpowiadania na pytania po analizę nastrojów.
Siła LLM wynika z ich zdolności do uczenia się i uogólniania na podstawie obszernych i różnorodnych danych szkoleniowych. Wstępne szkolenie tych modeli odbywa się z różnymi celami, nadzorowanymi, nienadzorowanymi lub hybrydowymi. Uzupełnianie tekstu lub imputacja to jeden z najczęstszych celów nienadzorowanych: biorąc pod uwagę fragment tekstu, model uczy się dokładnie przewidywać, co będzie dalej (na przykład przewidywać następne zdanie). Modele można również szkolić w sposób nadzorowany przy użyciu oznaczonych danych w celu wykonania zestawu zadań (na przykład, czy ta recenzja filmu jest pozytywna, negatywna czy neutralna). Niezależnie od tego, czy model jest szkolony pod kątem uzupełniania tekstu, czy innego zadania, klienci często nie chcą używać tego modelu do tego zadania.
Aby poprawić wydajność wstępnie przeszkolonego LLM w zakresie określonego zadania, możemy dostroić model za pomocą przykładów zadania docelowego w procesie znanym jako dostrajanie instrukcji. Dostrajanie instrukcji wykorzystuje zestaw oznaczonych przykładów w postaci par {prompt, response} w celu dalszego szkolenia wstępnie wytrenowanego modelu w zakresie odpowiedniego przewidywania odpowiedzi na monit. Ten proces modyfikuje wagi modelu.
W tym poście opisano, jak przeprowadzić dostrajanie instrukcji LLM, a mianowicie FLAN T5 XL, używając Szybki start Amazon SageMaker. Pokazujemy, jak to osiągnąć, używając zarówno interfejsu Jumpstart, jak i notebooka Studio Amazon SageMaker. Możesz znaleźć towarzyszący notatnik amazon-sagemaker-przykłady Repozytorium GitHub.
Omówienie rozwiązania
Zadaniem docelowym w tym poście jest, biorąc pod uwagę fragment tekstu w monicie, zwrócenie pytań związanych z tekstem, na które nie można odpowiedzieć na podstawie zawartych w nim informacji. Jest to przydatne zadanie do identyfikowania brakujących informacji w opisie lub określania, czy zapytanie wymaga więcej informacji, aby uzyskać odpowiedź.
Modele FLAN T5 są precyzyjnie dostrojone pod kątem szerokiego zakresu zadań, aby zwiększyć wydajność tych modeli w przypadku wielu typowych zadań[1]. Dodatkowe dostrajanie instrukcji dla konkretnego zadania klienta może jeszcze bardziej zwiększyć dokładność tych modeli, zwłaszcza jeśli zadanie docelowe nie było wcześniej używane do trenowania modelu FLAN T5, jak ma to miejsce w przypadku naszego zadania.
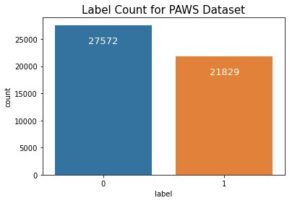
W naszym przykładowym zadaniu jesteśmy zainteresowani wygenerowaniem odpowiednich pytań, na które nie ma odpowiedzi. W tym celu używamy podzbioru wersji 2 zestawu danych Stanford Question Answering Dataset (SQuAD2.0)[2], aby dostroić model. Ten zbiór danych zawiera pytania zadane przez osoby komentujące w zbiorze artykułów w Wikipedii. Oprócz pytań z odpowiedziami, SQuAD2.0 zawiera około 50,000 XNUMX pytań bez odpowiedzi. Takie pytania są prawdopodobne, ale nie można na nie bezpośrednio odpowiedzieć z treści artykułów. Używamy tylko pytań, na które nie ma odpowiedzi. Nasze dane mają strukturę pliku JSON Lines, a każda linia zawiera kontekst i pytanie.

Wymagania wstępne
Aby rozpocząć, potrzebujesz tylko konta AWS, na którym możesz korzystać ze Studio. Musisz utworzyć profil użytkownika dla Studio, jeśli jeszcze go nie masz.
Dostosuj FLAN-T5 za pomocą interfejsu Jumpstart
Aby dostroić model za pomocą interfejsu Jumpstart, wykonaj następujące czynności:
- W konsoli SageMaker otwórz Studio.
- Pod Szybki start SageMakera w okienku nawigacji wybierz Modele, notebooki, rozwiązania.
Zobaczysz listę modeli podkładów, w tym FLAN T5 XL, który jest oznaczony jako dostrojony.
- Dodaj Zobacz model.
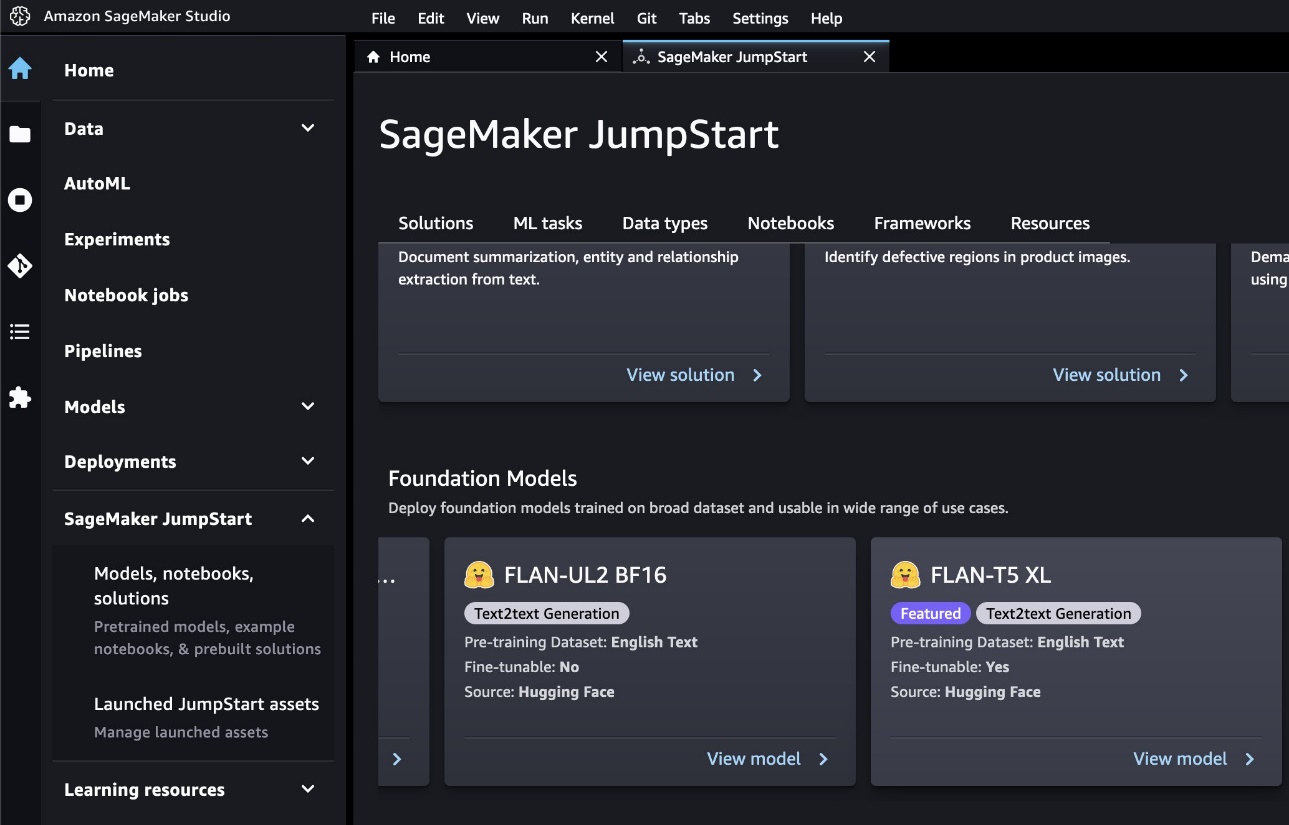
- Pod Źródło danych, możesz podać ścieżkę do swoich danych treningowych. Źródło danych użytych w tym poście jest domyślnie podane.
- Możesz zachować domyślną wartość konfiguracji wdrożenia (w tym typu instancji), zabezpieczeń i hiperparametrów, ale aby uzyskać dobre wyniki, należy zwiększyć liczbę epok do co najmniej trzech.
- Dodaj Pociąg trenować modelkę.
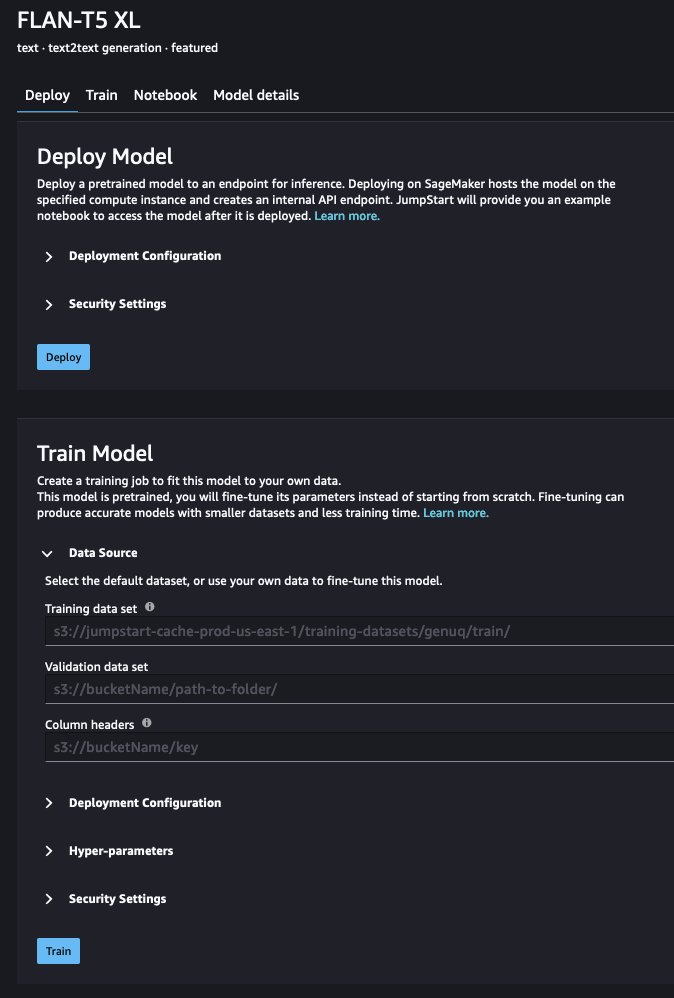
Możesz śledzić status zadania szkoleniowego w interfejsie użytkownika.
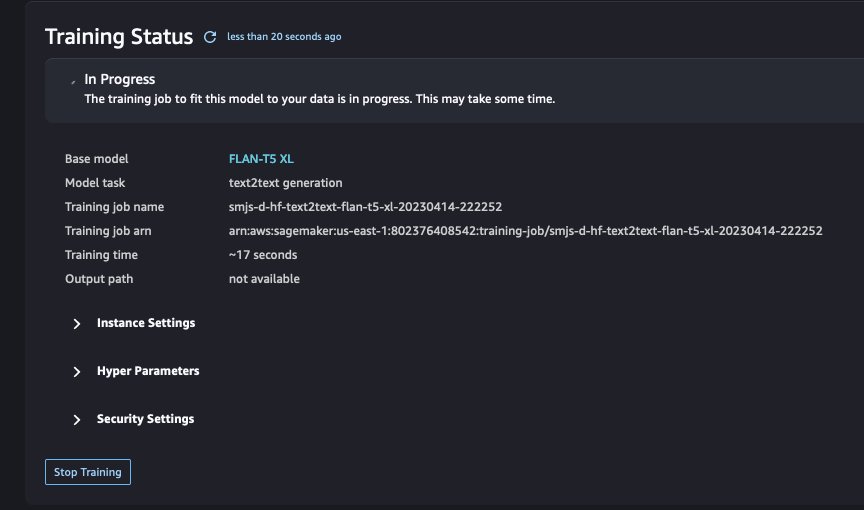
- Po zakończeniu treningu (w naszym przypadku po około 53 minutach) wybierz Rozmieścić wdrożyć dopracowany model.

Po utworzeniu punktu końcowego (kilka minut) możesz otworzyć notatnik i zacząć korzystać z precyzyjnie dostrojonego modelu.
Dostosuj FLAN-T5 za pomocą notatnika Pythona
Nasz przykładowy notatnik pokazuje, jak używać Jumpstart i SageMaker do programistycznego dostrajania i wdrażania modelu FLAN T5 XL. Można go uruchomić w Studio lub lokalnie.
W tej sekcji najpierw przejdziemy przez ogólną konfigurację. Następnie dostrajasz model przy użyciu zestawów danych SQuADv2. Następnie wdrażasz wstępnie wytrenowaną wersję modelu za punktem końcowym SageMaker i robisz to samo z precyzyjnie dostrojonym modelem. Na koniec można wykonać zapytanie dotyczące punktów końcowych i porównać jakość danych wyjściowych wstępnie wytrenowanego i dostrojonego modelu. Przekonasz się, że dane wyjściowe precyzyjnie dostrojonego modelu są znacznie wyższej jakości.
Skonfiguruj wymagania wstępne
Rozpocznij od zainstalowania i uaktualnienia niezbędnych pakietów. Zrestartuj jądro po uruchomieniu następującego kodu:
Następnie uzyskaj rolę wykonawczą powiązaną z bieżącą instancją notatnika:
Możesz zdefiniować wygodne menu rozwijane, które zawiera listę rozmiarów modeli dostępnych do precyzyjnego dostrojenia:
Program Jumpstart automatycznie pobiera odpowiednie typy instancji uczących i wnioskowania dla wybranego modelu:
Teraz możesz przystąpić do dostrajania.
Ponownie naucz model na dostrajającym zestawie danych
Po zakończeniu konfiguracji wykonaj następujące czynności:
Użyj następującego kodu, aby pobrać identyfikator URI dla potrzebnych artefaktów:
Dane treningowe znajdują się w przestrzeni publicznej Usługa Amazon Simple Storage Łyżka (Amazon S3).
Użyj poniższego kodu, aby wskazać lokalizację danych i skonfigurować lokalizację wyjściową w zasobniku na swoim koncie:
Oryginalne dane nie są w formacie odpowiadającym zadaniu, dla którego dostrajasz model, więc możesz go ponownie sformatować:
Teraz możesz zdefiniować niektóre hiperparametry dla treningu:
Teraz możesz rozpocząć zadanie szkoleniowe:
W zależności od rozmiaru danych dostrajających i wybranego modelu, dostrajanie może zająć nawet kilka godzin.
Za pomocą można monitorować metryki wydajności, takie jak utrata szkolenia i walidacji Amazon Cloud Watch podczas treningu. W wygodny sposób możesz również pobrać najnowszą migawkę metryk, uruchamiając następujący kod:
Po ukończeniu szkolenia masz dopracowany model w model_uri. użyjmy tego!
Można utworzyć dwa punkty końcowe wnioskowania: jeden dla oryginalnego wstępnie wytrenowanego modelu i jeden dla precyzyjnie dostrojonego modelu. Pozwala to na porównanie danych wyjściowych obu wersji modelu. W następnym kroku wdrażasz punkt końcowy wnioskowania dla wstępnie wytrenowanego modelu. Następnie wdrażasz punkt końcowy dla swojego precyzyjnie dostrojonego modelu.
Wdróż wstępnie wytrenowany model
Zacznijmy od wdrożenia wstępnie przeszkolonego modelu pobierania identyfikatora URI obrazu platformy Docker wnioskowania. To jest podstawowy obraz kontenera Hugging Face. Użyj następującego kodu:
Możesz teraz utworzyć punkt końcowy i wdrożyć wstępnie przeszkolony model. Pamiętaj, że musisz przekazać klasę Predictor podczas wdrażania modelu za pośrednictwem klasy Model, aby móc uruchamiać wnioskowanie za pośrednictwem interfejsu API SageMaker. Zobacz następujący kod:
Tworzenie punktu końcowego i wdrażanie modelu może zająć kilka minut, po czym punkt końcowy jest gotowy do odbierania wywołań wnioskowania.
Wdróż dostrojony model
Wdróżmy dostrojony model do jego własnego punktu końcowego. Proces jest prawie identyczny z tym, którego użyliśmy wcześniej dla wstępnie wytrenowanego modelu. Jedyna różnica polega na tym, że używamy precyzyjnie dostrojonej nazwy modelu i identyfikatora URI:
Po zakończeniu tego procesu zarówno wstępnie przeszkolone, jak i dostrojone modele są wdrażane za własnymi punktami końcowymi. Porównajmy ich wyniki.
Wygeneruj dane wyjściowe i porównaj wyniki
Zdefiniuj kilka funkcji narzędziowych, aby wysłać zapytanie do punktu końcowego i przeanalizować odpowiedź:
W następnym fragmencie kodu definiujemy zachętę i dane testowe. Opisuje nasze docelowe zadanie, którym jest wygenerowanie pytań, które są związane z dostarczonym tekstem, ale nie można na jego podstawie odpowiedzieć.
Dane testowe składają się z trzech różnych akapitów, z których jeden dotyczy australijskiego miasta Adelajda pierwsze dwa akapity tej strony w Wikipedii, jeden dotyczący Sklep Amazon Elastic Block (Amazon EBS) z Dokumentacja Amazon EBSi jeden z Amazon Comprehend z Dokumentacja Amazon Zrozumieć. Oczekujemy, że model będzie identyfikował pytania związane z tymi akapitami, na które nie można odpowiedzieć za pomocą informacji w nich zawartych.
Możesz teraz przetestować punkty końcowe, korzystając z przykładowych artykułów
Dane testowe: Adelajda
Używamy następującego kontekstu:
Wstępnie wytrenowana odpowiedź modelu jest następująca:
Dostrojone odpowiedzi modelu są następujące:
Dane testowe: Amazon EBS
Używamy następującego kontekstu:
Wstępnie wytrenowane odpowiedzi modelu są następujące:
Dostrojone odpowiedzi modelu są następujące:
Dane testowe: Amazon Zrozum
Używamy następującego kontekstu:
Wstępnie wytrenowane odpowiedzi modelu są następujące:
Dostrojone odpowiedzi modelu są następujące:
Różnica w jakości danych wyjściowych między modelem wstępnie wyszkolonym a modelem dostrojonym jest wyraźna. Pytania dostarczane przez dopracowany model dotyczą szerszego zakresu tematów. Są to systematycznie znaczące pytania, co nie zawsze ma miejsce w przypadku wstępnie wytrenowanego modelu, co ilustruje przykład Amazon EBS.
Chociaż nie stanowi to formalnej i systematycznej oceny, jasne jest, że proces dostrajania poprawił jakość odpowiedzi modelu w tym zadaniu.
Sprzątać
Na koniec pamiętaj, aby wyczyścić i usunąć punkty końcowe:
Wnioski
W tym poście pokazaliśmy, jak korzystać z dostrajania instrukcji w modelach FLAN T5 za pomocą interfejsu użytkownika Jumpstart lub notebooka Jupyter działającego w Studio. Dostarczyliśmy kod wyjaśniający, jak przeszkolić model przy użyciu danych dla zadania docelowego i wdrożyć precyzyjnie dostrojony model za punktem końcowym. Zadaniem docelowym w tym poście było zidentyfikowanie pytań, które odnoszą się do fragmentu tekstu podanego w danych wejściowych, na które nie można odpowiedzieć na podstawie informacji podanych w tym tekście. Pokazaliśmy, że model dostrojony do tego konkretnego zadania daje lepsze wyniki niż model wstępnie wytrenowany.
Teraz, gdy wiesz, jak precyzyjnie dostroić model za pomocą programu Jumpstart, możesz tworzyć wydajne modele dostosowane do Twojej aplikacji. Zbierz trochę danych do swojego przypadku użycia, prześlij je do Amazon S3 i użyj interfejsu użytkownika Studio lub notebooka, aby dostroić model FLAN T5!
Referencje
[1] Chung, Hyung Won i in. „Skalowanie instrukcji — precyzyjnie dostrojone modele językowe”. arXiv preprint arXiv:2210.11416 (2022).
[2] Rajpurkar, Pranav, Robin Jia i Percy Liang. „Wiedz to, czego nie wiesz: pytania bez odpowiedzi dla SQuAD”. Materiały z 56. dorocznego spotkania Association for Computational Linguistics (tom 2: Short Papers). 2018.
O autorach
 Laurenta Calota jest głównym naukowcem stosowanym i menedżerem w AWS AI Labs, który pracował nad różnymi problemami związanymi z uczeniem maszynowym, od podstawowych modeli i generatywnej sztucznej inteligencji po prognozowanie, wykrywanie anomalii, przyczynowość i operacje AI.
Laurenta Calota jest głównym naukowcem stosowanym i menedżerem w AWS AI Labs, który pracował nad różnymi problemami związanymi z uczeniem maszynowym, od podstawowych modeli i generatywnej sztucznej inteligencji po prognozowanie, wykrywanie anomalii, przyczynowość i operacje AI.
 Andrzej Kan jest starszym naukowcem stosowanym w AWS AI Labs z zainteresowaniami i doświadczeniem w różnych dziedzinach uczenia maszynowego. Obejmują one badania nad modelami podstawowymi, a także aplikacje ML dla wykresów i szeregów czasowych.
Andrzej Kan jest starszym naukowcem stosowanym w AWS AI Labs z zainteresowaniami i doświadczeniem w różnych dziedzinach uczenia maszynowego. Obejmują one badania nad modelami podstawowymi, a także aplikacje ML dla wykresów i szeregów czasowych.
 Dr Ashish Khetan jest starszym naukowcem z wbudowanymi algorytmami Amazon SageMaker i pomaga rozwijać algorytmy uczenia maszynowego. Doktoryzował się na University of Illinois Urbana Champaign. Jest aktywnym badaczem uczenia maszynowego i wnioskowania statystycznego oraz opublikował wiele artykułów na konferencjach NeurIPS, ICML, ICLR, JMLR, ACL i EMNLP.
Dr Ashish Khetan jest starszym naukowcem z wbudowanymi algorytmami Amazon SageMaker i pomaga rozwijać algorytmy uczenia maszynowego. Doktoryzował się na University of Illinois Urbana Champaign. Jest aktywnym badaczem uczenia maszynowego i wnioskowania statystycznego oraz opublikował wiele artykułów na konferencjach NeurIPS, ICML, ICLR, JMLR, ACL i EMNLP.
 Barisa Kurta jest naukowcem stosowanym w AWS AI Labs. Interesuje się wykrywaniem anomalii szeregów czasowych i modelami podstawowymi. Uwielbia tworzyć przyjazne dla użytkownika systemy ML.
Barisa Kurta jest naukowcem stosowanym w AWS AI Labs. Interesuje się wykrywaniem anomalii szeregów czasowych i modelami podstawowymi. Uwielbia tworzyć przyjazne dla użytkownika systemy ML.
 Jonasa Kublera jest naukowcem stosowanym w AWS AI Labs. Pracuje nad modelami podstawowymi, których celem jest ułatwienie zastosowań specyficznych dla przypadków użycia.
Jonasa Kublera jest naukowcem stosowanym w AWS AI Labs. Pracuje nad modelami podstawowymi, których celem jest ułatwienie zastosowań specyficznych dla przypadków użycia.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoAiStream. Analiza danych Web3. Wiedza wzmocniona. Dostęp tutaj.
- Wybijanie przyszłości w Adryenn Ashley. Dostęp tutaj.
- Kupuj i sprzedawaj akcje spółek PRE-IPO z PREIPO®. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/instruction-fine-tuning-for-flan-t5-xl-with-amazon-sagemaker-jumpstart/
- :ma
- :Jest
- :nie
- $W GÓRĘ
- 000
- 1
- 10
- 100
- 11
- 12
- 13
- 17
- 1M
- 20
- 2018
- 2022
- 22
- 40
- 50
- 7
- 8
- 80
- 9
- a
- Zdolny
- O nas
- Akceptuj
- dostęp
- dostępny
- wykonać
- Konto
- precyzja
- dokładnie
- aktywny
- dodatek
- Dodatkowy
- odpowiednio
- Po
- AI
- AL
- Algorytmy
- Wszystkie kategorie
- pozwala
- już
- również
- zawsze
- Amazonka
- Amazon Comprehend
- Amazon Sage Maker
- Amazon SageMaker JumpStart
- Amazon Web Services
- an
- analiza
- w czasie rzeczywistym sprawiają,
- i
- roczny
- wykrywanie anomalii
- odpowiedzi
- każdy
- api
- Pszczoła
- Zastosowanie
- aplikacje
- stosowany
- właściwy
- SĄ
- POWIERZCHNIA
- argument
- artykuł
- towary
- AS
- powiązany
- Stowarzyszenie
- At
- przywiązany
- Australia
- australijski
- automatycznie
- dostępny
- AWS
- baza
- na podstawie
- BE
- Plaża
- Belka
- za
- jest
- poniżej
- Ulepsz Swój
- pomiędzy
- miliardy
- Blokować
- ciało
- obie
- wbudowany
- ale
- by
- nazywa
- Połączenia
- CAN
- nie może
- możliwości
- zdolny
- Pojemność
- kapitał
- walizka
- centrum
- zmiana
- wybór
- Dodaj
- wybrał
- wybrany
- Miasto
- klasa
- Klasy
- klasyfikacja
- jasny
- klient
- Wybrzeże
- kod
- byliśmy spójni, od początku
- wspólny
- porównać
- kompletny
- ukończenia
- w składzie
- zrozumieć
- konferencje
- systemu
- Konsola
- stanowić
- Pojemnik
- zawiera
- zawartość
- kontekst
- ciągły
- bez przerwy
- Wygodny
- odpowiada
- mógłby
- Para
- Stwórz
- stworzony
- Tworzenie
- tworzenie
- Aktualny
- zwyczaj
- klient
- Klientów
- dostosowane
- dane
- Bazy danych
- zbiory danych
- Domyślnie
- wykazać
- wykazać
- W zależności
- rozwijać
- wdrażane
- wdrażanie
- Wdrożenie
- opis
- Wykrywanie
- Ustalać
- rozwijać
- rozwijanie
- rozwija się
- urządzenie
- urządzenia
- różnica
- różne
- bezpośrednio
- Wyświetlacz
- inny
- do
- Doker
- dokument
- dokumenty
- robi
- Nie
- dominujący
- nie
- napęd
- podczas
- dynamicznie
- E i T
- każdy
- Wcześniej
- Wschód
- ebs
- Efektywne
- bądź
- Elementy
- więcej
- zakończenia
- Punkt końcowy
- Cały
- podmioty
- jednostka
- epoka
- epoki
- szczególnie
- Eter (ETH)
- ewaluację
- Parzyste
- zbadać
- przykład
- przykłady
- wykonać
- egzekucja
- oczekiwać
- doświadczenie
- wyjaśniając
- narażony
- rozbudowa
- rozległy
- wyciąg
- niezwykle
- Twarz
- ułatwiać
- daleko
- Moda
- Cecha
- Korzyści
- kilka
- Łąka
- filet
- Akta
- W końcu
- Znajdź
- w porządku
- i terminów, a
- następujący
- następujący sposób
- W razie zamówieenia projektu
- Nasz formularz
- formalny
- format
- znaleziono
- Fundacja
- Czwarty
- Framework
- często
- przyjazny
- od
- Funkcje
- dalej
- zbierać
- Ogólne
- Generować
- wygenerowane
- generujący
- generacja
- generatywny
- generatywna sztuczna inteligencja
- otrzymać
- GitHub
- dany
- cel
- dobry
- wykresy
- wspaniały
- większy
- Wzrost
- Ciężko
- dysk twardy
- Have
- he
- pomaga
- wyższy
- Wzgórza
- jego
- GODZINY
- W jaki sposób
- How To
- HTML
- http
- HTTPS
- Przytulanie twarzy
- człowiek
- Setki
- Hybrydowy
- i
- ICLR
- ID
- identiques
- zidentyfikować
- ids
- if
- Illinois
- obraz
- importować
- podnieść
- ulepszony
- in
- zawierać
- Włącznie z
- Zwiększać
- coraz bardziej
- niezależnie
- Informacje
- Informacja
- informacyjny
- początkowy
- wkład
- Wejścia
- spostrzeżenia
- zainstalować
- Instalacja
- przykład
- zainteresowany
- zainteresowania
- Wprowadzenie
- IT
- JEGO
- Praca
- Oferty pracy
- jpg
- json
- Notebook Jupyter
- Trzymać
- Klawisz
- Wiedzieć
- znany
- Labs
- język
- Języki
- duży
- największym
- uruchomić
- UCZYĆ SIĘ
- nauka
- najmniej
- Długość
- poziom
- życie
- lubić
- Linia
- linie
- językoznawstwo
- Lista
- lokalnie
- usytuowany
- lokalizacja
- wysoki
- długo
- długoterminowy
- od
- kocha
- maszyna
- uczenie maszynowe
- kierownik
- wiele
- wyraźny
- max
- Może..
- wymowny
- Spotkanie
- wspomina
- Menu
- Metryka
- minuty
- brakujący
- ML
- model
- modele
- monitor
- jeszcze
- większość
- MONTAż
- film
- dużo
- musi
- Nazwa
- mianowicie
- Naturalny
- Język naturalny
- Przetwarzanie języka naturalnego
- Nawigacja
- niezbędny
- Potrzebować
- potrzebne
- wymagania
- ujemny
- sieci
- NeuroIPS
- Neutralny
- Nowości
- Nowe produkty
- Następny
- nlp
- Północ
- noty
- notatnik
- laptopy
- już dziś
- numer
- Cele
- uzyskać
- of
- on
- ONE
- tylko
- koncepcja
- or
- oryginalny
- Inne
- ludzkiej,
- wydajność
- koniec
- Zastąp
- własny
- właściciele
- Pakiety
- par
- chleb
- Papiery
- parametry
- część
- szczególny
- szczególnie
- przechodzić
- ścieżka
- Ludzie
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- okres
- uporczywość
- Zwroty
- plato
- Analiza danych Platona
- PlatoDane
- do przyjęcia
- punkt
- populacja
- pozytywny
- Post
- power
- mocny
- przewidzieć
- przewidywanie
- Urządzenie prognozujące
- poprzednio
- pierwotny
- Główny
- druk
- problemy
- wygląda tak
- przetwarzanie
- Produkty
- Profil
- Postęp
- Sprawdzony
- zapewniać
- pod warunkiem,
- zapewnia
- publiczny
- opublikowany
- Python
- jakość
- zapytania
- pytanie
- pytania
- szybko
- przypadkowy
- zasięg
- Surowy
- gotowy
- w czasie rzeczywistym
- otrzymać
- niedawny
- uznanie
- rozpoznać
- rozpoznawanie
- polecić
- Zalecana
- w sprawie
- region
- związane z
- wydany
- polegać
- pamiętać
- składnica
- wymagać
- wymagany
- Wymaga
- Badania naukowe
- badacz
- Mieszkańcy
- Zasoby
- odpowiedź
- Odpowiedzi
- ograniczać
- Efekt
- powrót
- powraca
- przeglądu
- Rudzik
- Rola
- run
- bieganie
- s
- sagemaker
- taki sam
- skanować
- Naukowiec
- Szukaj
- druga
- Sekcja
- bezpieczeństwo
- widzieć
- wybór
- senior
- wyrok
- sentyment
- Serie
- usługa
- Usługi
- Sesja
- zestaw
- Zestawy
- ustawienie
- kilka
- Short
- powinien
- pokazał
- Targi
- Prosty
- Rozmiar
- rozmiary
- mały
- Migawka
- So
- Obserwuj Nas
- Sieć społecznościowa
- kilka
- Źródło
- Południe
- specyficzny
- dzielić
- Stanford
- sztywny
- początek
- rozpoczęty
- Stan
- statystyczny
- Rynek
- Ewolucja krok po kroku
- Cel
- Nadal
- przechowywanie
- sklep
- Struktura
- zbudowany
- studio
- Oszałamiający
- taki
- wsparcie
- Utrzymany
- otaczający
- system
- systemy
- Brać
- cel
- Zadanie
- zadania
- szablon
- test
- generowanie tekstu
- niż
- że
- Połączenia
- Strefa
- Stolica
- Informacje
- Źródło
- Państwo
- Zachód
- świat
- ich
- Im
- następnie
- w nim
- Te
- one
- to
- tych
- trzy
- Przez
- czas
- Szereg czasowy
- do
- Żetony
- Top
- tematy
- Kontakt
- śledzić
- tradycyjny
- Pociąg
- przeszkolony
- Trening
- Trylion
- prawdziwy
- drugiej
- rodzaj
- typy
- ui
- zrozumienie
- uniwersytet
- Nowości
- przesłanych
- URI
- posługiwać się
- przypadek użycia
- używany
- Użytkownik
- za pomocą
- użyteczność
- uprawomocnienie
- wartość
- Wartości
- różnorodność
- wersja
- vincent
- widoczny
- Tom
- kłęby
- W
- chcieć
- była
- Droga..
- we
- sieć
- usługi internetowe
- DOBRZE
- Zachód
- Co
- Co to jest
- jeśli chodzi o komunikację i motywację
- czy
- który
- Podczas
- KIM
- szeroki
- Szeroki zasięg
- szerszy
- Wikipedia
- będzie
- w
- w ciągu
- Wygrał
- słowo
- pracował
- pracujący
- świat
- by
- ty
- Twój
- zefirnet