Niedawno ogłosiliśmy ogólną dostępność Amazon OpenSearch bez serwera , nowa opcja dla Usługa Amazon OpenSearch co ułatwia obsługę zadań związanych z wyszukiwaniem i analizą na dużą skalę bez konieczności konfigurowania, zarządzania lub skalowania klastrów OpenSearch. Dzięki OpenSearch Serverless uzyskujesz takie same interaktywne milisekundowe czasy odpowiedzi jak w przypadku usługi OpenSearch przy prostocie środowiska bezserwerowego.
W tym poście dowiesz się, jak przeprowadzić migrację istniejących indeksów z domeny klastra zarządzanej przez usługę OpenSearch do kolekcji bezserwerowej za pomocą Logstash.
Dzięki domenom OpenSearch w ciągu kilku minut otrzymujesz dedykowane, bezpieczne klastry, które są konfigurowane i optymalizowane pod kątem Twoich obciążeń. Masz pełną kontrolę nad konfiguracją zasobów obliczeniowych, pamięci i pamięci masowej w klastrach, aby zoptymalizować koszty i wydajność aplikacji. OpenSearch Serverless zapewnia jeszcze prostszy sposób uruchamiania zadań związanych z wyszukiwaniem i analizą — bez konieczności myślenia o klastrach. Po prostu tworzysz kolekcję i grupę indeksów i możesz rozpocząć pozyskiwanie danych i wykonywanie zapytań.
Omówienie rozwiązania
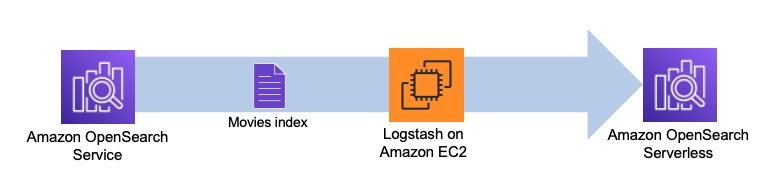
Logstash to oprogramowanie typu open source, które zapewnia ETL (wyodrębnianie, przekształcanie i ładowanie) danych. Możesz skonfigurować Logstash, aby łączył się ze źródłem i miejscem docelowym za pomocą wtyczek wejściowych i wyjściowych. W międzyczasie konfigurujesz filtry, które mogą przekształcać Twoje dane. Ten post przeprowadzi Cię przez kroki potrzebne do skonfigurowania Logstash w celu połączenia domeny usługi OpenSearch (dane wejściowe) z kolekcją OpenSearch Serverless (dane wyjściowe).
Wtyczki źródłowe i docelowe ustawiasz w pliku konfiguracyjnym Logstash. Plik konfiguracyjny zawiera sekcje dla Input, Filter, Output. Po skonfigurowaniu Logstash wyśle żądanie do domeny usługi OpenSearch i odczyta dane zgodnie z zapytaniem wprowadzonym w input Sekcja. Po odczytaniu danych z usługi OpenSearch możesz opcjonalnie przesłać je do następnego etapu Filter do przekształceń, takich jak dodanie lub usunięcie pola z danych wejściowych lub aktualizacja pola o inne wartości. W tym przykładzie nie użyjesz Filter podłącz. Dalej jest Output podłącz. Wersja oprogramowania Logstash typu open source (Logstash OSS) zapewnia wygodny sposób korzystania z masowego interfejsu API do przesyłania danych do kolekcji. OpenSearch Serverless obsługuje logstash-output-opensearch wtyczka wyjściowa, która obsługuje AWS Zarządzanie tożsamością i dostępem (IAM) poświadczenia do kontroli dostępu do danych.
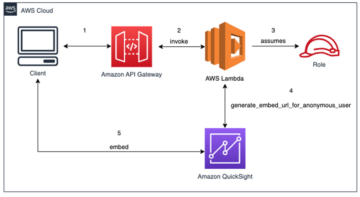
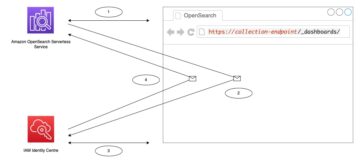
Poniższy diagram ilustruje przepływ pracy naszego rozwiązania.
Wymagania wstępne
Zanim zaczniesz, upewnij się, że spełniłeś następujące wymagania wstępne:
- Zanotuj numer ARN domeny usługi OpenSearch, nazwę użytkownika i hasło.
- Utwórz kolekcję OpenSearch Serverless. Jeśli dopiero zaczynasz korzystać z OpenSearch Serverless, zobacz Loguj analitykę w łatwy sposób dzięki Amazon OpenSearch Serverless aby uzyskać szczegółowe informacje na temat konfigurowania kolekcji.
Skonfiguruj Logstash oraz wtyczki wejściowe i wyjściowe dla OpenSearch
Wykonaj następujące kroki, aby skonfigurować Logstash i swoje wtyczki:
- Do pobrania
logstash-oss-with-opensearch-output-plugin. (W tym przykładzie użyto dystrybucji dla macos-x64. W przypadku innych dystrybucji zapoznaj się z plikiem artefakty.) - Wyodrębnij pobrany plik tar:
- Zaktualizuj
logstash-output-opensearchdodatek do najnowszej wersji: - Instalacja
logstash-input-opensearchpodłącz:
Przetestuj wtyczkę
Przejdźmy do działania i zobaczmy, jak działa wtyczka. Poniższy plik konfiguracyjny pobiera dane z pliku movies indeks w Twojej domenie usługi OpenSearch i indeksuje te dane w Twojej kolekcji OpenSearch Serverless z tą samą nazwą indeksu, movies.
Utwórz nowy plik i dodaj następującą zawartość, a następnie zapisz plik jako opensearch-serverless-migration.conf. Podaj wartości dla punktu końcowego domeny usługi OpenSearch w obszarze HOST, USERNAME, HASŁO input sekcji oraz szczegóły punktu końcowego kolekcji OpenSearch Serverless w sekcji HOST oraz REGION, AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY output
Możesz określić zapytanie w pliku input sekcja poprzedniej konfiguracji. The match_all zapytanie pasuje do wszystkich danych w pliku movies indeks. Możesz zmienić zapytanie, jeśli chcesz wybrać podzbiór danych. Zapytania można również użyć do zrównoleglenia przesyłania danych przez uruchomienie wielu procesów Logstash z konfiguracjami określającymi różne wycinki danych. Możesz także zrównoleglać, uruchamiając procesy Logstash na wielu indeksach, jeśli je masz.
Uruchom Logstasha
Użyj następującego polecenia, aby uruchomić Logstash:
Po uruchomieniu polecenia Logstash pobierze dane z indeksu źródłowego Twojej domeny usługi OpenSearch i zapisze je w indeksie docelowym w kolekcji OpenSearch Serverless. Po zakończeniu przesyłania danych Logstash wyłącza się. Zobacz następujący kod:
Sprawdź dane w OpenSearch Serverless
Możesz sprawdzić, czy Logstash skopiował wszystkie Twoje dane, porównując liczbę dokumentów w Twojej domenie i w Twojej kolekcji. Uruchom następujące zapytanie z pliku Narzędzia deweloperskie zakładka lub z curl, postmanlub podobnego klienta HTTP. Poniższe zapytanie pomaga przeszukać wszystkie dokumenty z movies index i zwraca najwyższe dokumenty wraz z liczbą. Domyślnie OpenSearch zwróci liczbę dokumentów maksymalnie do 10,000 XNUMX. Dodanie track_total_hits flag pomaga uzyskać dokładną liczbę dokumentów, jeśli liczba dokumentów przekracza 10,000 XNUMX.
Wnioski
W tym poście przeprowadziłeś migrację danych z domeny usługi OpenSearch do kolekcji OpenSearch Serverless przy użyciu wtyczek wejściowych i wyjściowych OpenSearch firmy Logstash.
Bądź na bieżąco z serią postów skupiających się na różnych dostępnych opcjach tworzenia skutecznych rozwiązań do analizy dzienników i wyszukiwania przy użyciu rozwiązania OpenSearch Serverless. Możesz również odnieść się do Rozpoczęcie pracy z Amazon OpenSearch Serverless warsztaty, aby dowiedzieć się więcej o OpenSearch Serverless.
Jeśli masz uwagi dotyczące tego posta, prześlij je w sekcji komentarzy. Jeśli masz pytania dotyczące tego posta, rozpocznij nowy wątek na stronie Forum Amazon OpenSearch Service or skontaktuj się z pomocą techniczną AWS.
O autorach
 Prashanta Agrawala jest starszym architektem rozwiązań specjalizujących się w wyszukiwaniu w usłudze Amazon OpenSearch. Ściśle współpracuje z klientami, pomagając im w migracji obciążeń do chmury, a obecnym klientom dostraja ich klastry w celu uzyskania lepszej wydajności i obniżenia kosztów. Zanim dołączył do AWS, pomagał różnym klientom w korzystaniu z OpenSearch i Elasticsearch w przypadkach użycia wyszukiwania i analizy dzienników. Kiedy nie pracuje, można go znaleźć w podróży i odkrywaniu nowych miejsc. Krótko mówiąc, lubi robić Jedz → Podróżuj → Powtarzaj.
Prashanta Agrawala jest starszym architektem rozwiązań specjalizujących się w wyszukiwaniu w usłudze Amazon OpenSearch. Ściśle współpracuje z klientami, pomagając im w migracji obciążeń do chmury, a obecnym klientom dostraja ich klastry w celu uzyskania lepszej wydajności i obniżenia kosztów. Zanim dołączył do AWS, pomagał różnym klientom w korzystaniu z OpenSearch i Elasticsearch w przypadkach użycia wyszukiwania i analizy dzienników. Kiedy nie pracuje, można go znaleźć w podróży i odkrywaniu nowych miejsc. Krótko mówiąc, lubi robić Jedz → Podróżuj → Powtarzaj.
 Jona Handlera (@_searchgeek) jest starszym głównym architektem rozwiązań w Amazon Web Services z siedzibą w Palo Alto w Kalifornii. Jon ściśle współpracuje z zespołami CloudSearch i Elasticsearch, udzielając pomocy i wskazówek szerokiemu gronu klientów, którzy mają obciążenia związane z wyszukiwaniem, które chcą przenieść do chmury AWS. Przed dołączeniem do AWS kariera Jona jako programisty obejmowała cztery lata kodowania wielkoskalowej wyszukiwarki e-commerce.
Jona Handlera (@_searchgeek) jest starszym głównym architektem rozwiązań w Amazon Web Services z siedzibą w Palo Alto w Kalifornii. Jon ściśle współpracuje z zespołami CloudSearch i Elasticsearch, udzielając pomocy i wskazówek szerokiemu gronu klientów, którzy mają obciążenia związane z wyszukiwaniem, które chcą przenieść do chmury AWS. Przed dołączeniem do AWS kariera Jona jako programisty obejmowała cztery lata kodowania wielkoskalowej wyszukiwarki e-commerce.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/migrate-your-indexes-to-amazon-opensearch-serverless-with-logstash/
- 000
- 10
- 100
- 28
- 39
- 7
- a
- O nas
- dostęp
- Stosownie
- Osiągać
- Działania
- Po
- przed
- Agent
- Wszystkie kategorie
- Amazonka
- Amazon Web Services
- analityka
- i
- ogłosił
- api
- aplikacje
- dostępność
- dostępny
- AWS
- na podstawie
- zanim
- Ulepsz Swój
- pomiędzy
- szeroki
- budować
- CA
- Kariera
- Etui
- CD
- zmiana
- klient
- dokładnie
- Chmura
- Grupa
- kod
- Kodowanie
- kolekcja
- kolekcje
- komentarze
- porównanie
- kompletny
- Zakończony
- obliczać
- systemu
- Skontaktuj się
- zawartość
- kontrola
- Wygodny
- Koszty:
- Stwórz
- Listy uwierzytelniające
- Klientów
- dane
- dostęp do danych
- dedykowane
- Domyślnie
- miejsce przeznaczenia
- detale
- Deweloper
- różne
- niepełnosprawny
- dokument
- dokumenty
- robi
- domena
- domeny
- na dół
- jeść
- ecommerce
- Efektywne
- bądź
- Elasticsearch
- Punkt końcowy
- silnik
- Środowisko
- Eter (ETH)
- Parzyste
- EVER
- przykład
- przekracza
- Przede wszystkim system został opracowany
- Exploring
- wyciąg
- informacja zwrotna
- pole
- filet
- filtry
- Znajdź
- skupienie
- następujący
- od
- pełny
- Ogólne
- otrzymać
- miejsce
- Zarządzanie
- mający
- pomoc
- pomógł
- pomaga
- W jaki sposób
- How To
- HTTPS
- IAM
- tożsamość
- in
- włączony
- wskaźnik
- indeksy
- Indeksy
- Informacje
- wkład
- zainstalować
- interaktywne
- IT
- łączący
- Wiedzieć
- na dużą skalę
- firmy
- UCZYĆ SIĘ
- załadować
- Główny
- robić
- WYKONUJE
- zarządzanie
- zarządzane
- maksymalny
- Pamięć
- migrować
- milisekunda
- minuty
- jeszcze
- ruch
- Kino
- wielokrotność
- Nazwa
- Potrzebować
- Nowości
- Następny
- open source
- Oprogramowanie typu open source
- Optymalizacja
- zoptymalizowane
- Option
- Opcje
- Oss
- Inne
- Palo Alto
- Hasło
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- rurociąg
- Miejsca
- plato
- Analiza danych Platona
- PlatoDane
- wtyczka
- wtyczki
- Post
- Wiadomości
- warunki wstępne
- Główny
- Wcześniejszy
- procesów
- zapewniać
- zapewnia
- że
- położyć
- pytania
- zasięg
- Czytaj
- niedawno
- region
- rejestr
- Usunięto
- usuwanie
- powtarzać
- zażądać
- Zasoby
- odpowiedź
- powrót
- powraca
- run
- biegacz
- bieganie
- taki sam
- Zapisz
- Skala
- Szukaj
- Wyszukiwarka
- Sekcja
- działy
- bezpieczne
- Serie
- Bezserwerowe
- usługa
- Usługi
- zestaw
- Short
- zamknąć
- Zamyka
- podobny
- prostota
- po prostu
- Tworzenie
- rozwiązanie
- Rozwiązania
- Źródło
- specjalista
- STAGE
- początek
- rozpoczęty
- Cel
- przechowywanie
- Zatwierdź
- Z powodzeniem
- taki
- podpory
- Zespoły
- Połączenia
- Źródło
- ich
- Przez
- czasy
- do
- Top
- przenieść
- Przekształcać
- przemiany
- podróżować
- Podróżowanie
- prawdziwy
- dla
- Aktualizacja
- aktualizowanie
- posługiwać się
- Użytkownik
- Wartości
- różnorodny
- zweryfikować
- wersja
- przez
- sieć
- usługi internetowe
- który
- KIM
- będzie
- bez
- workflow
- pracujący
- działa
- warsztat
- warsztaty
- napisać
- lat
- Twój
- zefirnet