W ciągu ostatnich 10 lat wielu graczy opracowało systemy pojazdów autonomicznych (AV) wykorzystujące głębokie sieci neuronowe (DNN). Systemy te ewoluowały od prostych systemów opartych na regułach do zaawansowanych systemów wspomagania kierowcy (ADAS) i w pełni autonomicznych pojazdów. Te systemy wymagają petabajtów danych i tysięcy jednostek obliczeniowych (procesorów wirtualnych i procesorów graficznych) do uczenia.
W tym poście omówiono podejścia do kompilacji, różne jednostki funkcjonalne ADAS, podejścia projektowe do budowania potoku modułowego oraz wyzwania związane z budowaniem systemu ADAS.
Metody i projektowanie szkoleń DNN
Systemy AV są zbudowane z głębokich sieci neuronowych. Jeśli chodzi o projektowanie systemu AV, istnieją dwa główne podejścia. Różnica polega na sposobie uczenia DNN i granicy systemu.
- Szkolenie modułowe – Dzięki modułowej konstrukcji rurociągu system jest podzielony na poszczególne jednostki funkcjonalne (na przykład percepcję, lokalizację, przewidywanie i planowanie). Jest to powszechny paradygmat projektowania stosowany przez wielu dostawców systemów AV. Dzięki podziale całego systemu na poszczególne moduły można je budować i trenować niezależnie.
- Szkolenie od końca do końca – To podejście obejmuje trenowanie modelu DNN, który pobiera surowe dane z czujników jako dane wejściowe i wysyła polecenie jazdy. Jest to architektura monolityczna, badana głównie przez badaczy. Architektura DNN jest zazwyczaj oparta na uczeniu się przez wzmacnianie (RL) w oparciu o system nagród/kar lub uczeniu się przez imitację (IL) poprzez obserwację człowieka prowadzącego pojazd. Chociaż ogólna architektura jest prosta, trudno jest zinterpretować i zdiagnozować monolit. Jednak adnotacje są tanie, ponieważ system uczy się na podstawie danych zebranych na podstawie ludzkich zachowań.
Oprócz tych dwóch podejść, naukowcy badają również podejście hybrydowe, które trenuje dwa różne DNN, które są połączone reprezentacją pośrednią.
W tym poście wyjaśniono funkcje oparte na podejściu modułowego potoku.
Poziomy automatyzacji
SAE International (wcześniej nazywane Towarzystwem Inżynierów Motoryzacyjnych) Norma J3016 definiuje sześć poziomów automatyzacji jazdy i jest najczęściej cytowanym źródłem automatyzacji jazdy. Zakres ten waha się od poziomu 0 (brak automatyzacji) do poziomu 5 (pełna automatyzacja jazdy), jak pokazano w poniższej tabeli.
| poziom | Imię | Cecha |
| 0 | Brak automatyzacji jazdy | Popędy ludzkie |
| 1 | Pomoc w prowadzeniu pojazdu | Popędy ludzkie |
| 2 | Częściowa automatyzacja jazdy | Popędy ludzkie |
| 3 | Warunkowa automatyzacja jazdy | Dyski systemowe z człowiekiem jako kopią zapasową |
| 4 | Wysoka automatyzacja jazdy | Dyski systemowe |
| 5 | Pełna automatyzacja jazdy | Dyski systemowe |
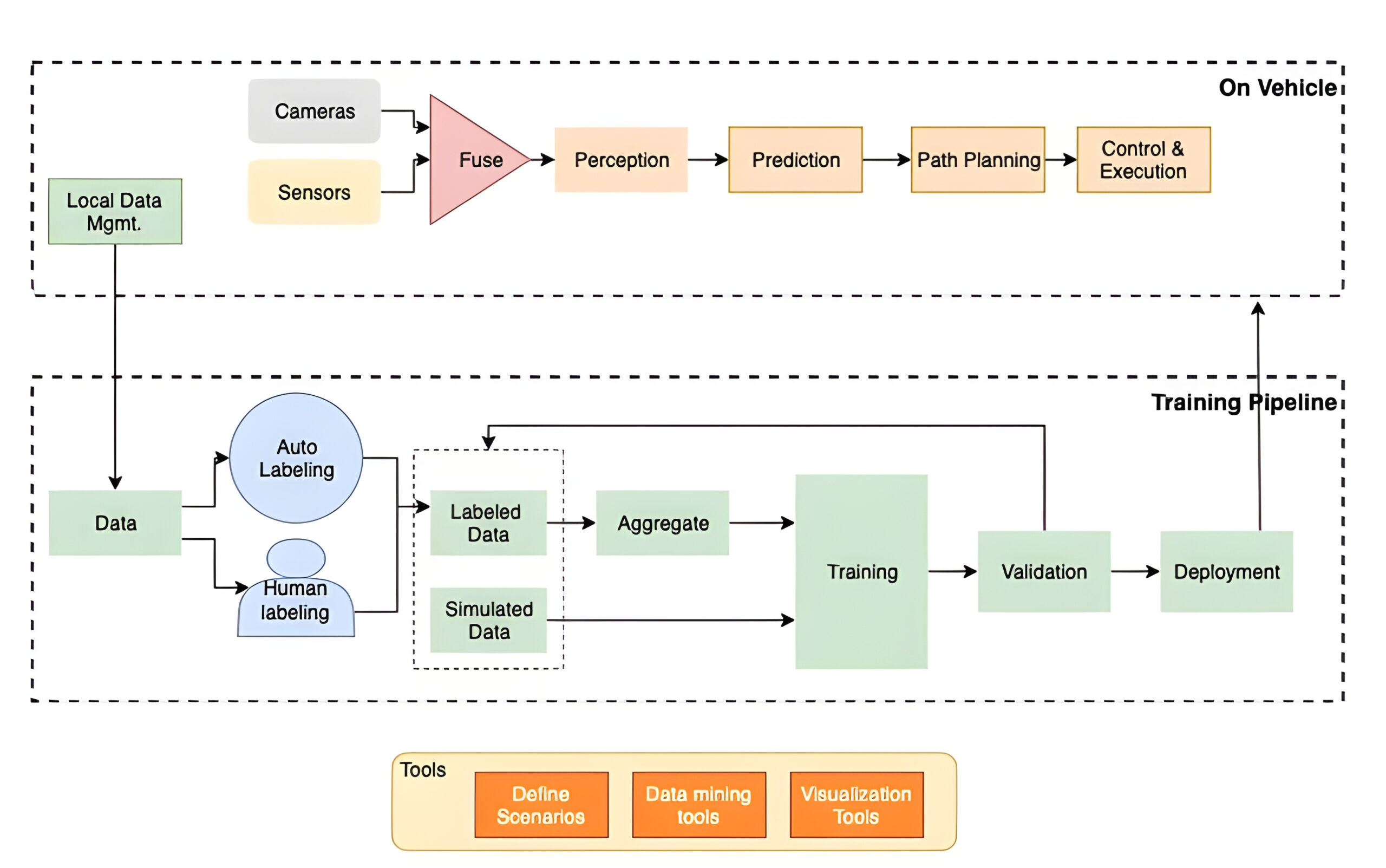
Funkcje modułowe
Poniższy diagram zawiera przegląd projektowania funkcji modułowych.

Na wyższych poziomach automatyzacji (poziom 2 i wyższy) system AD spełnia wiele funkcji:
- Zbieranie danych – System AV zbiera informacje o otoczeniu pojazdu w czasie rzeczywistym z centymetrową dokładnością. Pojazd jest wyposażony w różne urządzenia, a funkcje tych urządzeń są różne i krzyżują się na wiele sposobów. AV to wciąż rozwijająca się przestrzeń i nie ma konsensusu ani standaryzacji typów czujników i podłączonych urządzeń. Oprócz wymienionych tutaj urządzeń pojazdy mogą być również wyposażone w GPS do nawigacji oraz korzystać z map i bezwładnościowych jednostek pomiarowych (IMU) do pomiaru przyspieszenia liniowego i kątowego. W zależności od rodzaju systemu ADAS zobaczysz kombinację następujących urządzeń:
- Aparaty – Urządzenia wizualne koncepcyjnie podobne do ludzkiej percepcji. Obsługuje wysoką rozdzielczość, ale źle ocenia głębokość i radzi sobie z ekstremalnymi warunkami pogodowymi.
- LiDAR – Drogie urządzenia dostarczające danych o otoczeniu w postaci chmury punktów 3D. Zapewnia dokładne oszacowanie głębokości i prędkości.
- Ultradźwięki – Małe, niedrogie czujniki, ale dobrze sprawdzają się tylko na krótkich dystansach.
- Radar – Obsługuje długie i krótkie zasięgi i działa dobrze przy słabej widoczności i ekstremalnych warunkach pogodowych.
- Fuzja danych – Wiele urządzeń wchodzących w skład systemu AV dostarcza sygnały, ale ma swoje ograniczenia; jednak sygnały przesyłane przez urządzenia dostarczają informacji uzupełniających. Systemy audio-wideo łączą dane z urządzeń, które są ze sobą zintegrowane, tworząc kompleksową percepcję. Ten zintegrowany zestaw danych służy do uczenia DNN.
- Postrzeganie – Systemy AV analizują surowe dane zebrane z urządzeń w celu skonstruowania informacji o otoczeniu wokół pojazdu, w tym o przeszkodach, znakach drogowych i innych obiektach. To się nazywa postrzeganie sceny drogowej lub po prostu postrzeganie. Polega na wykrywaniu obiektów i klasyfikowaniu ich jako pobliskich pojazdów, pieszych, sygnalizacji świetlnej i znaków drogowych. Ta funkcja mierzy głębokość i wykonuje wykrywanie pasa ruchu, szacowanie krzywizny pasa ruchu, wykrywanie krawężników i okluzję. Informacje te są kluczowe dla planowania trasy i optymalizacji trasy.
- Lokalizacja i mapowanie – Aby bezpiecznie obsługiwać i optymalizować pojazd, systemy AV wymagają zrozumienia lokalizacji obiektów wykrytych przez percepcję. System AV konstruuje mapę 3D i aktualizuje pozycję pojazdu głównego (pojazd ego) i jego okolice na mapie. Śledzi wykryte obiekty i ich aktualną lokalizację. Zaawansowane systemy przewidują kinematykę poruszających się obiektów.
- Przepowiednia – Dzięki informacjom zebranym z innych modułów systemy AV przewidują, jak zmieni się otoczenie w najbliższej przyszłości. DNN działający na pojeździe przewiduje położenie pojazdu ego i interakcje z otaczającym obiektem poprzez projekcję stanów kinematycznych w czasie (pozycja, prędkość, przyspieszenie, szarpnięcie). Może przewidywać potencjalne wykroczenia drogowe i kolizje lub grożące kolizją.
- Planowanie ścieżki – Ta funkcja jest odpowiedzialna za wyznaczanie możliwych tras, którymi pojazd może się zająć w ramach następnej akcji, na podstawie danych wejściowych pochodzących z percepcji, lokalizacji i przewidywania. Aby zaplanować najlepszą możliwą trasę, system AV wykorzystuje lokalizację, mapy, dane GPS i prognozy jako dane wejściowe. Niektóre systemy AV konstruują widok z lotu ptaka, rzutując kinematykę pojazdu ego i innych obiektów na statyczną trasę, aby zapewnić mapę 3D. Niektóre łączą również dane z innych pojazdów. Ogólnie rzecz biorąc, funkcja planowania znajduje optymalną trasę spośród wszystkich możliwych, mając na celu maksymalizację komfortu kierowcy (na przykład płynne i ostre zakręty, zwalnianie lub gwałtowne zatrzymywanie się na znakach stop).
- Kontrola i wykonanie – Wykorzystuje dane wejściowe z narzędzia do planowania trasy, aby wykonywać czynności przyspieszania, zwalniania, zatrzymywania i obracania kierownicą. Zadaniem kontrolera jest utrzymanie zaplanowanej trajektorii.
- Potok szkoleń – DNN dostarczające prognozy dotyczące pojazdu muszą zostać przeszkolone. Zwykle są szkoleni w trybie offline z danymi zebranymi z pojazdów. Szkolenie wymaga tysięcy jednostek obliczeniowych przez dłuższy czas. Ilość danych wymaganych do trenowania i wymagana moc obliczeniowa różnią się w zależności od architektury modelu i dostawcy systemu AV. Aby wyszkolić sieci DNN, dostawca systemu AV wymaga oznaczonych danych, które są częściowo opatrzone adnotacjami przez ludzi, a częściowo zautomatyzowane. Zazwyczaj informacje umożliwiające identyfikację osób (PII), takie jak numer rejestracyjny i twarz, są anonimizowane poprzez zamazanie. Wielu dostawców uzupełnia oznaczone dane za pomocą symulacji. Zapewnia możliwość generowania danych dla określonych scenariuszy i rozszerzania danych rzeczywistych. Dostawcy systemów AV wykorzystują również narzędzia do wydobywania odpowiednich danych w celu szkolenia, dostrajania i obsługi przypadków brzegowych. Wytrenowane modele są sprawdzane pod kątem dokładności za pomocą symulacji offline. Niektórzy dostawcy stosują strategię modelu uśpionego i wdrażają modele kandydujące (uśpione) obok modeli produkcyjnych. Chociaż prognozy z uśpionych modeli nie są wykorzystywane do sterowania pojazdem, pomagają one dostawcom zweryfikować dokładność modelu w rzeczywistych scenariuszach.
Wyzwania
Sieci DNN dla obciążeń antywirusowych muszą być szkolone przy użyciu ogromnych ilości danych. Potrzebujesz infrastruktury obliczeniowej, która jest skalowalna, aby szkolić sieci DNN, obsługiwać duże ilości danych szkoleniowych i uwzględniać czynniki optymalizujące szkolenie za pomocą modeli i równoległości danych.
Szkolenie z dużą ilością danych
Systemy AV zbierają duże ilości danych z urządzeń podłączonych do pojazdu. W zależności od dostawcy systemu AV, flota pojazdów waha się od kilku do tysięcy pojazdów. Oto niektóre typowe wyzwania, z którymi może spotkać się dostawca systemu AV:
- Gromadzenie, wstępne przetwarzanie i przechowywanie petabajtów danych – Każdy pojazd zbiera ponad 40 TB danych na każde 8 godzin jazdy.
- Identyfikacja odpowiednich danych reprezentacji z ogromnej ilości danych – Jest to niezbędne do zmniejszenia błędów w zbiorach danych, tak aby typowe scenariusze (jazda z normalną prędkością z przeszkodami) nie powodowały nierównowagi klasowej. Aby uzyskać większą dokładność, sieci DNN wymagają dużych ilości zróżnicowanych danych dobrej jakości.
- Objętość skrzyń narożnych – Modele ML muszą obsługiwać szeroką gamę przypadków narożnych. Jest to niezbędne do zapewnienia bezpieczeństwa systemu AV.
- Czas na trening – Biorąc pod uwagę ogromną ilość danych, czas szkolenia to często wiele dni, a nawet tygodni. Zmniejsza to szybkość rozwoju i zdolność do szybkiej awarii.
Aby sprostać wyzwaniu związanemu z dużą wartością, możesz skorzystać z Amazon Sage Maker funkcja równoległości danych rozproszonych (SMDDP). SageMaker to w pełni zarządzana usługa uczenia maszynowego (ML). Dzięki równoległości danych duża ilość danych jest dzielona na partie. Bloki danych są wysyłane do wielu procesorów lub procesorów graficznych zwanych węzłami, a wyniki są łączone. Każdy węzeł ma kopię DNN. SageMaker opracował rozproszona biblioteka danych równoległych, który dzieli dane na węzeł i optymalizuje komunikację między węzłami. Możesz użyć SageMaker Python SDK, aby uruchomić zadanie z równoległością danych przy minimalnych modyfikacjach skryptu szkoleniowego. Równoległość danych obsługuje popularne platformy głębokiego uczenia się PyTorch, PyTorch Lightening, TensorFlow i Hugging Face Transformers.
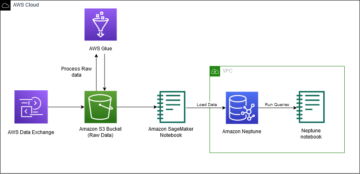
Firma motoryzacyjna Hyundai wykorzystała równoległość danych SageMaker, aby skrócić czas szkolenia swoich autonomicznych modeli jazdy i osiągnęła ponad 90% skalowalność dzięki ośmiu instancjom, z których każda ma 8 procesorów graficznych. Poniższy diagram ilustruje tę architekturę.

Aby uzyskać więcej informacji, zobacz Hyundai skraca czas szkolenia modeli ML dla modeli jazdy autonomicznej za pomocą Amazon SageMaker.
Aby uzyskać więcej informacji na temat rozproszonego szkolenia z SageMaker, zapoznaj się z filmem AWS re:Invent 2020 Szybkie szkolenie i niemal liniowe skalowanie dzięki DataParallel w Amazon SageMaker i Nauka stojąca za silnikami szkolenia rozproszonego Amazon SageMaker.
Etykietowanie dużej ilości danych
Potok szkoleniowy wymaga dużej ilości zestawów danych z etykietami. Jednym z typowych wyzwań, przed którymi stoją nasi klienci, jest opracowanie narzędzi do adnotacji do oznaczania obrazu, wideo i czujnika (na przykład chmury punktów 3D); niestandardowe przepływy pracy do wykrywania obiektów; i zadania segmentacji semantycznej. Potrzebujesz możliwości dostosowania przepływów pracy.
Amazon SageMaker Ground Prawda to w pełni zarządzana usługa etykietowania danych, która zapewnia elastyczność tworzenia niestandardowych przepływów pracy i zarządzania nimi. Dzięki Ground Truth możesz etykietować dane obrazu, wideo i chmury punktów w celu wykrywania obiektów, śledzenia obiektów i zadań segmentacji semantycznej. Możesz przenieść dane zebrane z pojazdów i przechowywane na terenie do AWS za pomocą mechanizmu przesyłania danych, takiego jak Brama pamięci masowej AWS, AWS Direct Connect, Synchronizacja danych AWS, Śnieżka AWSlub Rodzina transferów AWS. Po wstępnym przetworzeniu danych (takich jak rozmycie twarzy i tablic rejestracyjnych) oczyszczony zestaw danych jest gotowy do etykietowania. Ground Truth obsługuje fuzję danych czujnika LiDAR z wejściami wideo z kamer. Możesz zdecydować się na użycie ludzkich adnotatorów Amazon Mechanical Turk, zaufanych dostawców zewnętrznych lub własnych prywatnych pracowników.
Na poniższym rysunku przedstawiamy architekturę referencyjną do wstępnego przetwarzania danych Partia AWS i używając Ground Truth do etykietowania zestawów danych.

Aby uzyskać więcej informacji, zobacz Notatki terenowe: automatyzacja pozyskiwania i etykietowania danych na potrzeby rozwoju pojazdów autonomicznych i Etykietowanie danych do śledzenia obiektów 3D i łączenia czujników w Amazon SageMaker Ground Truth.
Aby uzyskać więcej informacji na temat korzystania z funkcji Ground Truth do etykietowania danych chmury punktów 3D, zobacz Użyj funkcji Ground Truth do etykietowania chmur punktów 3D.
Infrastruktura szkoleniowa
W miarę dojrzewania systemów AV, sieci DNN muszą zostać przeszkolone w zakresie obsługi wielu przypadków brzegowych (na przykład ludzi chodzących po autostradach), a model staje się złożony i duży. Powoduje to szkolenie DNN z większą ilością danych z eksploracji zarejestrowanych danych lub poprzez symulacje w celu obsługi nowszych scenariuszy. Wymaga to większej mocy obliczeniowej i skalowania infrastruktury obliczeniowej.
Aby zaspokoić potrzeby obliczeniowe dla obciążeń ML, SageMaker zapewnia wiele typów instancji do szkolenia. Każda rodzina jest przeznaczona do kilku określonych obciążeń; możesz wybrać na podstawie konfiguracji vCPU, GPU, pamięci, pamięci masowej i sieci instancji. Aby uzyskać pełny, kompleksowy rozwój AV, firmy w dużej mierze polegają na rodzinach m, c, g i p.
Niektórzy z naszych klientów używają naszych systemów Deep Learning AMI (DLAMI) do uruchamiania rozwiązań opartych na procesorach graficznych NVIDIA Elastyczna chmura obliczeniowa Amazon (Amazon EC2) instancje w rodzinie p. Każda generacja instancji z rodziny EC2 p integruje najnowszą technologię NVIDIA, w tym instancje p2 (Tesla K80), instancje p3 (Volta V100) i instancje p4d (Ampere A100).
Poniższy rysunek podsumowuje dostępne instancje:

Kiedy DNN są złożone i nie mieszczą się w pamięci jednego GPU, możesz użyć SageMaker biblioteka równoległości modelu. Spowoduje to podział warstw na procesory graficzne i instancje. Możesz użyć biblioteki do automatycznego partycjonowania modeli TensorFlow i PyTorch na wiele procesorów graficznych i wielu węzłów przy minimalnych zmianach kodu.
MLOps
Jeśli chodzi o operacjonalizację, od analityków danych przeprowadzających eksperymenty na poprawionych modelach po wdrażanie w tysiącach pojazdów, dostawcy systemów AV potrzebują zestawu narzędzi, które działają kompleksowo bezproblemowo dla różnych potrzeb:
- Gromadzenie i przekształcanie danych na dużą skalę
- Zautomatyzowana analiza i ocena modeli
- Standaryzacja potoków danych
- Umiejętność definiowania i przeprowadzania eksperymentów dla analityków danych
- Monitorowanie wydajności modelu
- Ustanowienie powtarzalnego procesu i wyeliminowanie interwencji człowieka dzięki kompleksowej automatyzacji
- Zautomatyzowane wdrażanie modelu, które umożliwia szybkie wdrażanie przeszkolonego modelu w milionach pojazdów
SageMaker zapewnia kompleksowe narzędzia MLOps. Analitycy danych mogą korzystać Eksperymenty Amazon SageMaker, który automatycznie śledzi dane wejściowe, parametry, konfiguracje i wyniki iteracji jako próby. Możesz dalej przypisywać, grupować i organizować te próby w eksperymenty. Monitor modelu Amazon SageMaker pomaga stale monitorować jakość modeli ML w czasie rzeczywistym. Możesz skonfigurować automatyczne alerty, aby powiadamiać o odchyleniach w jakości modelu, takich jak dryf danych i anomalie. Jeśli chodzi o orkiestrację, możesz wybierać spośród wielu opcji, w tym SageMaker Pipelines SDK, Funkcje kroków AWS, Przepływ powietrza Apache zarządzany przez Amazon (Amazon MWAA) oraz narzędzia typu open source, takie jak Kubeflow.
Wnioski
W tym poście omówiliśmy podejścia do kompilacji i różne jednostki funkcjonalne ADAS, ujednoliconą strukturę do budowy potoku modułowego oraz wyzwania związane z budowaniem systemu ADAS. Udostępniliśmy architektury referencyjne i linki do studiów przypadków i postów na blogach, które wyjaśniają, w jaki sposób nasi klienci wykorzystują SageMaker i inne usługi AWS do budowy skalowalnego systemu AV. Proponowane rozwiązania mogą pomóc naszym klientom sprostać wyzwaniom podczas budowy skalowalnego systemu AV. W późniejszym poście szczegółowo omówimy DNN używane przez systemy ADAS.
O autorach
 Shreyas Subramanian jest głównym architektem rozwiązań specjalizującym się w sztucznej inteligencji/uczeniu maszynowym i pomaga klientom, korzystając z uczenia maszynowego, rozwiązywać ich problemy biznesowe za pomocą platformy AWS. Shreyas ma doświadczenie w optymalizacji na dużą skalę i uczeniu maszynowym oraz wykorzystywaniu uczenia maszynowego i uczenia się przez wzmacnianie do przyspieszania zadań optymalizacyjnych.
Shreyas Subramanian jest głównym architektem rozwiązań specjalizującym się w sztucznej inteligencji/uczeniu maszynowym i pomaga klientom, korzystając z uczenia maszynowego, rozwiązywać ich problemy biznesowe za pomocą platformy AWS. Shreyas ma doświadczenie w optymalizacji na dużą skalę i uczeniu maszynowym oraz wykorzystywaniu uczenia maszynowego i uczenia się przez wzmacnianie do przyspieszania zadań optymalizacyjnych.
 Gopi Krishnamurthy jest starszym architektem rozwiązań AI/ML w Amazon Web Services z siedzibą w Nowym Jorku. Współpracuje z dużymi klientami z branży motoryzacyjnej jako ich zaufany doradca przy przekształcaniu ich obciążeń uczenia maszynowego i migracji do chmury. Jego główne zainteresowania to deep learning i technologie serverless. Poza pracą lubi spędzać czas z rodziną i zgłębiać różne gatunki muzyczne.
Gopi Krishnamurthy jest starszym architektem rozwiązań AI/ML w Amazon Web Services z siedzibą w Nowym Jorku. Współpracuje z dużymi klientami z branży motoryzacyjnej jako ich zaufany doradca przy przekształcaniu ich obciążeń uczenia maszynowego i migracji do chmury. Jego główne zainteresowania to deep learning i technologie serverless. Poza pracą lubi spędzać czas z rodziną i zgłębiać różne gatunki muzyczne.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/modular-functions-design-for-advanced-driver-assistance-systems-adas-on-aws/
- 10
- 100
- 1998
- 2020
- 3d
- a
- A100
- zdolność
- O nas
- powyżej
- nagle
- przyśpieszyć
- przyspieszenie
- przyśpieszenie
- precyzja
- dokładny
- osiągnięty
- w poprzek
- Działania
- działania
- Ad
- ADA
- dodatek
- adres
- zaawansowany
- doradca
- Po
- AI / ML
- Wszystkie kategorie
- Chociaż
- Amazonka
- Amazon EC2
- Amazon Sage Maker
- Amazon Web Services
- ilość
- analiza
- w czasie rzeczywistym sprawiają,
- i
- Angular
- Apache
- podejście
- awanse
- architektura
- na około
- Wsparcie
- przywiązany
- zautomatyzowane
- automatycznie
- automatyzacja
- Automatyzacja
- motoryzacyjny
- autonomiczny
- pojazd autonomiczny
- pojazdy autonomiczne
- AV
- dostępny
- AWS
- AWS re: Invent
- tło
- Łazienka
- na podstawie
- bo
- za
- BEST
- Ulepsz Swój
- pomiędzy
- Duży
- Bloki
- Blog
- Najnowsze wpisy
- budować
- Budowanie
- wybudowany
- biznes
- nazywa
- kamery
- kandydat
- Pojemność
- walizka
- Case Studies
- Etui
- wyzwanie
- wyzwania
- zmiana
- Zmiany
- tani
- Dodaj
- cytowane
- Miasto
- klasa
- Chmura
- kod
- zbierać
- kolekcja
- zbiera
- połączenie
- połączony
- komfort
- wspólny
- Komunikacja
- Firmy
- sukcesy firma
- uzupełniający
- kompleks
- wszechstronny
- obliczać
- computing
- Koncepcyjnie
- Warunki
- Prowadzenie
- prowadzenia
- konfiguracje
- połączony
- Zgoda
- Rozważać
- skonstruować
- bez przerwy
- kontrola
- kontroler
- rdzeń
- Corner
- pokryty
- obejmuje
- Stwórz
- Aktualny
- zwyczaj
- Klientów
- dostosować
- dane
- zbiory danych
- Dni
- głęboko
- głębokie nurkowanie
- głęboka nauka
- głębokie sieci neuronowe
- Definiuje
- wymagania
- W zależności
- rozwijać
- wdrażanie
- Wdrożenie
- głębokość
- Wnętrze
- zaprojektowany
- detale
- wykryte
- Wykrywanie
- rozwinięty
- oprogramowania
- urządzenia
- zdiagnozować
- różnica
- różne
- kierować
- dystrybuowane
- szkolenia rozproszone
- inny
- nie
- na dół
- rysunek
- kierowca
- jazdy
- każdy
- krawędź
- efektywność
- eliminując
- Umożliwia
- spotkanie
- koniec końców
- Inżynierowie
- silniki
- zapewnić
- Środowisko
- wyposażony
- niezbędny
- Eter (ETH)
- ewaluację
- Parzyste
- Każdy
- ewoluowały
- ewoluuje
- przykład
- egzekucja
- drogi
- Wyjaśniać
- Objaśnia
- odkryj
- zbadane
- Exploring
- skrajny
- Twarz
- w obliczu
- twarze
- Czynniki
- FAIL
- rodzin
- członków Twojej rodziny
- Moda
- FAST
- Cecha
- kilka
- Postać
- znajduje
- dopasować
- FLOTA
- Elastyczność
- następujący
- dawniej
- Framework
- Ramy
- od
- pełny
- w pełni
- funkcjonować
- funkcjonalny
- Funkcje
- dalej
- fuzja
- przyszłość
- Generować
- generacja
- dany
- cel
- będzie
- dobry
- GPS
- GPU
- GPU
- Ziemia
- Zarządzanie
- garstka
- uchwyt
- Prowadzenie
- Ciężko
- mający
- pomoc
- pomaga
- tutaj
- Wysoki
- wyższy
- autostrady
- gospodarz
- GODZINY
- W jaki sposób
- Jednak
- HTML
- HTTPS
- olbrzymi
- człowiek
- Ludzie
- Hybrydowy
- Hyundai
- obraz
- brak równowagi
- Natychmiastowy
- in
- zawierać
- Włącznie z
- niezależnie
- indywidualny
- tani
- Informacja
- Infrastruktura
- wkład
- przykład
- zintegrowany
- Integruje się
- Interakcje
- zainteresowania
- Pośredni
- na świecie
- interwencja
- dotyczy
- IT
- iteracje
- Praca
- Klawisz
- KubeFlow
- Etykieta
- etykietowanie
- Tor
- duży
- w dużej mierze
- Nazwisko
- firmy
- uruchomić
- nioski
- nauka
- poziom
- poziomy
- Biblioteka
- Licencja
- sprawa
- oświetlenie
- Ograniczenia
- linki
- Katalogowany
- Localization
- lokalizacja
- długo
- niski
- maszyna
- uczenie maszynowe
- Główny
- utrzymać
- zarządzanie
- zarządzane
- wiele
- mapa
- mapowanie
- Mapy
- dojrzały
- Maksymalizuj
- zmierzyć
- środków
- mechaniczny
- mechanizm
- Pamięć
- metody
- może
- migrować
- miliony
- minimalny
- Górnictwo
- ML
- MLOps
- model
- modele
- Modyfikacje
- Modułowa
- Moduły
- monitor
- Monolityczny
- jeszcze
- większość
- ruch
- Silnik
- wielokrotność
- Muzyka
- Nawigacja
- Blisko
- Potrzebować
- wymagania
- sieci
- sieci
- Nerwowy
- sieci neuronowe
- Nowości
- I Love New York
- nowy jork
- Następny
- węzeł
- węzły
- normalna
- Uwagi
- numer
- Nvidia
- przedmiot
- Wykrywanie obiektów
- obiekty
- Przeszkody
- nieaktywny
- ONE
- open source
- działać
- Optymalny
- optymalizacja
- Optymalizacja
- Optymalizuje
- Opcje
- orkiestracja
- Inne
- zewnętrzne
- ogólny
- przegląd
- własny
- paradygmat
- Parallel
- parametry
- część
- ścieżka
- postrzeganie
- wykonać
- wykonuje
- okres
- Osobiście
- pii
- rurociąg
- krok po kroku
- planowany
- planowanie
- Platforma
- plato
- Analiza danych Platona
- PlatoDane
- gracze
- punkt
- Popularny
- position
- możliwy
- Post
- Wiadomości
- potencjał
- power
- przewidzieć
- przepowiednia
- Przewidywania
- Prognozy
- Główny
- prywatny
- wygląda tak
- Produkcja
- zaproponowane
- zapewniać
- pod warunkiem,
- dostawca
- dostawców
- zapewnia
- że
- Python
- płomień
- jakość
- dane dotyczące jakości
- szybko
- zasięg
- Surowy
- surowe dane
- RE
- gotowy
- real
- Prawdziwy świat
- w czasie rzeczywistym
- nagrany
- zmniejszyć
- zmniejsza
- uczenie się wzmacniania
- polegać
- powtarzalne
- reprezentacja
- wymagać
- wymagany
- Wymaga
- Badacze
- Rozkład
- odpowiedzialny
- Efekt
- Trasa
- trasy
- bieganie
- bezpiecznie
- Bezpieczeństwo
- sagemaker
- skalowalny
- Skala
- skalowaniem
- scenariusze
- scena
- nauka
- Naukowcy
- Sdk
- płynnie
- segmentacja
- senior
- czujniki
- Bezserwerowe
- usługa
- Usługi
- zestaw
- ostry
- Short
- pokazane
- Sygnały
- znaki
- podobny
- Prosty
- po prostu
- symulacja
- SIX
- powolny
- mały
- So
- Społeczeństwo
- Rozwiązania
- ROZWIĄZANIA
- kilka
- Źródło
- Typ przestrzeni
- specjalista
- specyficzny
- prędkość
- wydać
- dzielić
- Dzieli
- Zjednoczone
- kierownica
- Ewolucja krok po kroku
- Nadal
- Stop
- przechowywanie
- przechowywany
- Strategia
- badania naukowe
- taki
- wsparcie
- podpory
- otaczający
- system
- systemy
- stół
- Brać
- trwa
- zadania
- Technologies
- Technologia
- tensorflow
- Tesla
- Połączenia
- Informacje
- ich
- innych firm
- tysiące
- Przez
- czas
- do
- razem
- narzędzia
- Śledzenie
- ruch drogowy
- Pociąg
- przeszkolony
- Trening
- pociągi
- trajektoria
- przenieść
- Przekształcać
- Transformacja
- Transformatory
- Próby
- wyzwalać
- zaufany
- typy
- typowy
- zazwyczaj
- zrozumienie
- Ujednolicony
- jednostek
- Nowości
- posługiwać się
- wykorzystać
- wykorzystany
- UPRAWOMOCNIĆ
- zatwierdzony
- wartość
- różnorodny
- pojazd
- Pojazdy
- Prędkość
- sprzedawców
- przez
- Wideo
- Zobacz i wysłuchaj
- Naruszenia
- widoczność
- Tom
- kłęby
- chodzący
- sposoby
- Pogoda
- sieć
- usługi internetowe
- tygodni
- Koło
- który
- Podczas
- szeroki
- Szeroki zasięg
- będzie
- Praca
- przepływów pracy
- Siła robocza
- działa
- by
- lat
- Wydajność
- Twój
- youtube
- zefirnet