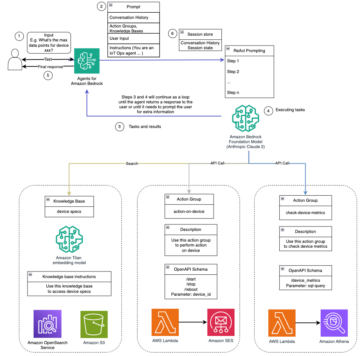
Amazon Sage Maker zapewnia pakiet wbudowane algorytmy, wstępnie wytrenowane modele, gotowe szablony rozwiązań aby pomóc naukowcom zajmującym się danymi i praktykom uczenia maszynowego (ML) rozpocząć szybkie szkolenie i wdrażanie modeli ML. Możesz używać tych algorytmów i modeli zarówno do uczenia nadzorowanego, jak i nienadzorowanego. Mogą przetwarzać różne typy danych wejściowych, w tym tabelaryczne, graficzne i tekstowe.
Od dzisiaj SageMaker udostępnia cztery nowe wbudowane algorytmy modelowania danych tabelarycznych: LightGBM, CatBoost, AutoGluon-Tabular i TabTransformer. Możesz używać tych popularnych, najnowocześniejszych algorytmów zarówno do zadań klasyfikacji tabelarycznej, jak i regresji. Są dostępne za pośrednictwem wbudowane algorytmy na konsoli SageMaker, a także przez Amazon SageMaker JumpStart Interfejs użytkownika wewnątrz Studio Amazon SageMaker.
Poniżej znajduje się lista czterech nowych wbudowanych algorytmów wraz z linkami do ich dokumentacji, przykładowych notatników i źródła.
| Dokumenty | Przykładowe notebooki | Źródło |
| Algorytm LightGBM | Regresja, Klasyfikacja | LekkiGBM |
| Algorytm CatBoost | Regresja, Klasyfikacja | KotBoost |
| Algorytm tabelaryczny AutoGluon | Regresja, Klasyfikacja | AutoGluon-Tabela |
| Algorytm TabTransformer | Regresja, Klasyfikacja | Karta Transformator |
W kolejnych sekcjach przedstawiamy krótki opis techniczny każdego algorytmu oraz przykłady uczenia modelu za pomocą pakietu SageMaker SDK lub SageMaker Jumpstart.
LekkiGBM
LekkiGBM to popularna i wydajna implementacja open-source algorytmu Gradient Boosting Decision Tree (GBDT). GBDT to nadzorowany algorytm uczenia, który próbuje dokładnie przewidzieć zmienną docelową, łącząc zestaw oszacowań z zestawu prostszych i słabszych modeli. LightGBM wykorzystuje dodatkowe techniki, aby znacznie poprawić wydajność i skalowalność konwencjonalnego GBDT.
KotBoost
KotBoost to popularna i wydajna implementacja open source algorytmu GBDT. W CatBoost wprowadzono dwa krytyczne postępy algorytmiczne: implementację zwiększania uporządkowanego, alternatywę dla klasycznego algorytmu sterowaną permutacją oraz innowacyjny algorytm przetwarzania cech kategorycznych. Obie techniki zostały stworzone w celu zwalczania przesunięcia predykcyjnego spowodowanego przez specjalny rodzaj wycieku docelowego obecnego we wszystkich obecnie istniejących implementacjach algorytmów zwiększania gradientu.
AutoGluon-Tabela
AutoGluon-Tabela to projekt AutoML o otwartym kodzie źródłowym opracowany i utrzymywany przez Amazon, który wykonuje zaawansowane przetwarzanie danych, głębokie uczenie i wielowarstwowe składanie stosów. Automatycznie rozpoznaje typ danych w każdej kolumnie, zapewniając solidne wstępne przetwarzanie danych, w tym specjalną obsługę pól tekstowych. AutoGluon pasuje do różnych modeli, od gotowych, wzmocnionych drzew po niestandardowe modele sieci neuronowych. Modele te są zestawiane w nowatorski sposób: modele są układane w wiele warstw i trenowane w sposób warstwowy, co gwarantuje, że nieprzetworzone dane można przełożyć na wysokiej jakości predykcje w określonym czasie. Nadmierne dopasowanie jest łagodzone w trakcie tego procesu, dzieląc dane na różne sposoby z uważnym śledzeniem przykładów, które nie są złożone. AutoGluon jest zoptymalizowany pod kątem wydajności, a jego gotowe użycie osiągnęło kilka pozycji w pierwszej trójce i pierwszej dziesiątce w konkursach data science.
Karta Transformator
Karta Transformator to nowatorska, głęboka architektura modelowania danych tabelarycznych do nadzorowanego uczenia się. TabTransformer jest zbudowany na transformatorach opartych na samouważności. Warstwy Transformer przekształcają osadzenia cech kategorialnych w solidne osadzenia kontekstowe, aby osiągnąć wyższą dokładność przewidywania. Ponadto osadzania kontekstowe, których nauczył się od TabTransformer, są wysoce odporne na brakujące i zaszumione funkcje danych oraz zapewniają lepszą interpretację. Ten model jest produktem najnowszych Nauka o Amazonii Badania (papier i urzędnik blogu tutaj) i został szeroko przyjęty przez społeczność ML, z różnymi implementacjami innych firm (Keras, AutoGluon,) oraz funkcje mediów społecznościowych, takie jak tweety, w kierunku nauki o danych, średnie i Kaggle.
Korzyści z wbudowanych algorytmów SageMaker
Podczas wybierania algorytmu dla konkretnego typu problemu i danych, najłatwiej jest użyć wbudowanego algorytmu programu SageMaker, ponieważ wiąże się to z następującymi głównymi korzyściami:
- Wbudowane algorytmy nie wymagają kodowania, aby rozpocząć przeprowadzanie eksperymentów. Jedyne dane wejściowe, które musisz podać, to dane, hiperparametry i zasoby obliczeniowe. Pozwala to na szybsze przeprowadzanie eksperymentów i mniejsze obciążenie związane ze śledzeniem wyników i zmianami w kodzie.
- Wbudowane algorytmy są dostarczane z równoległością w wielu instancjach obliczeniowych i wsparciem GPU od razu dla wszystkich odpowiednich algorytmów (niektóre algorytmy mogą nie być uwzględnione ze względu na nieodłączne ograniczenia). Jeśli masz dużo danych do trenowania swojego modelu, większość wbudowanych algorytmów można łatwo skalować w celu zaspokojenia zapotrzebowania. Nawet jeśli masz już wstępnie wytrenowany model, nadal może być łatwiej użyć jego odpowiednika w programie SageMaker i wprowadzić hiperparametry, które już znasz, niż przenieść go i samodzielnie napisać skrypt szkoleniowy.
- Jesteś właścicielem powstałych artefaktów modelu. Możesz wziąć ten model i wdrożyć go w SageMaker dla kilku różnych wzorców wnioskowania (sprawdź wszystkie dostępne typy wdrożeń) oraz łatwe skalowanie i zarządzanie punktami końcowymi. Możesz też wdrożyć go w dowolnym innym miejscu.
Zobaczmy teraz, jak wytrenować jeden z tych wbudowanych algorytmów.
Trenuj wbudowany algorytm za pomocą pakietu SageMaker SDK
Aby wytrenować wybrany model, musimy uzyskać identyfikator URI tego modelu, a także skrypt szkoleniowy i obraz kontenera używany do trenowania. Na szczęście te trzy dane wejściowe zależą wyłącznie od nazwy modelu, wersji (lista dostępnych modeli znajduje się w Tabela dostępnych modeli JumpStart) oraz typ instancji, na której chcesz trenować. Widać to w następującym fragmencie kodu:
Połączenia train_model_id zmiany w lightgbm-regression-model jeśli mamy do czynienia z problemem regresji. Identyfikatory dla wszystkich innych modeli przedstawionych w tym poście są wymienione w poniższej tabeli.
| Model | Rodzaj problemu | ID modelu |
| LekkiGBM | Klasyfikacja | lightgbm-classification-model |
| . | Regresja | lightgbm-regression-model |
| KotBoost | Klasyfikacja | catboost-classification-model |
| . | Regresja | catboost-regression-model |
| AutoGluon-Tabela | Klasyfikacja | autogluon-classification-ensemble |
| . | Regresja | autogluon-regression-ensemble |
| Karta Transformator | Klasyfikacja | pytorch-tabtransformerclassification-model |
| . | Regresja | pytorch-tabtransformerregression-model |
Następnie określamy, gdzie znajduje się nasz wkład Usługa Amazon Simple Storage (Amazonka S3). W tym przykładzie używamy publicznego przykładowego zestawu danych. Definiujemy również, dokąd chcemy skierować nasze dane wyjściowe, i pobieramy domyślną listę hiperparametrów potrzebnych do trenowania wybranego modelu. Możesz zmienić ich wartość według własnych upodobań.
Na koniec tworzymy instancję SageMakera Estimator ze wszystkimi pobranymi danymi wejściowymi i uruchom zadanie szkoleniowe za pomocą .fit, przekazując jej nasz treningowy identyfikator URI zestawu danych. The entry_point podany skrypt ma nazwę transfer_learning.py (tak samo dla innych zadań i algorytmów), a kanał danych wejściowych przekazywany do .fit musi być nazwany training.
Pamiętaj, że możesz trenować wbudowane algorytmy za pomocą Automatyczne dostrajanie modelu SageMaker w celu wybrania optymalnych hiperparametrów i dalszej poprawy wydajności modelu.
Trenuj wbudowany algorytm za pomocą programu SageMaker JumpStart
Możesz także trenować dowolne z tych wbudowanych algorytmów za pomocą kilku kliknięć za pomocą interfejsu użytkownika SageMaker JumpStart. JumpStart to funkcja programu SageMaker, która umożliwia trenowanie i wdrażanie wbudowanych algorytmów i wstępnie wytrenowanych modeli z różnych platform ML i centrów modeli za pośrednictwem interfejsu graficznego. Umożliwia także wdrażanie w pełni rozwiniętych rozwiązań ML, które łączą modele ML i różne inne usługi AWS w celu rozwiązania docelowego przypadku użycia.
Aby uzyskać więcej informacji, zobacz Uruchom klasyfikację tekstu za pomocą Amazon SageMaker JumpStart, korzystając z modeli TensorFlow Hub i Hugging Face.
Wnioski
W tym poście ogłosiliśmy wprowadzenie czterech nowych, potężnych wbudowanych algorytmów dla ML dla tabelarycznych zestawów danych, które są teraz dostępne w SageMaker. Dostarczyliśmy opis techniczny tego, czym są te algorytmy, a także przykładowe zadanie szkoleniowe dla LightGBM przy użyciu SDK SageMaker.
Przynieś własny zestaw danych i wypróbuj te nowe algorytmy w SageMaker, a także zapoznaj się z przykładowymi notatnikami, aby korzystać z wbudowanych algorytmów dostępnych w GitHub.
O autorach
![]() Dr Xin Huang jest naukowcem w zakresie wbudowanych algorytmów Amazon SageMaker JumpStart i Amazon SageMaker. Koncentruje się na tworzeniu skalowalnych algorytmów uczenia maszynowego. Jego zainteresowania badawcze dotyczą przetwarzania języka naturalnego, wyjaśnialnego głębokiego uczenia się na danych tabelarycznych oraz solidnej analizy nieparametrycznego klastrowania przestrzenno-czasowego. Opublikował wiele artykułów na konferencjach ACL, ICDM, KDD oraz Royal Statistical Society: Series A.
Dr Xin Huang jest naukowcem w zakresie wbudowanych algorytmów Amazon SageMaker JumpStart i Amazon SageMaker. Koncentruje się na tworzeniu skalowalnych algorytmów uczenia maszynowego. Jego zainteresowania badawcze dotyczą przetwarzania języka naturalnego, wyjaśnialnego głębokiego uczenia się na danych tabelarycznych oraz solidnej analizy nieparametrycznego klastrowania przestrzenno-czasowego. Opublikował wiele artykułów na konferencjach ACL, ICDM, KDD oraz Royal Statistical Society: Series A.
![]() Dr Ashish Khetan jest starszym naukowcem z wbudowanymi algorytmami Amazon SageMaker JumpStart i Amazon SageMaker i pomaga opracowywać algorytmy uczenia maszynowego. Jest aktywnym badaczem uczenia maszynowego i wnioskowania statystycznego oraz opublikował wiele artykułów na konferencjach NeurIPS, ICML, ICLR, JMLR, ACL i EMNLP.
Dr Ashish Khetan jest starszym naukowcem z wbudowanymi algorytmami Amazon SageMaker JumpStart i Amazon SageMaker i pomaga opracowywać algorytmy uczenia maszynowego. Jest aktywnym badaczem uczenia maszynowego i wnioskowania statystycznego oraz opublikował wiele artykułów na konferencjach NeurIPS, ICML, ICLR, JMLR, ACL i EMNLP.
 Joao Moura jest specjalistą ds. rozwiązań AI/ML w Amazon Web Services. Koncentruje się głównie na przypadkach użycia NLP i pomaga klientom zoptymalizować szkolenie i wdrażanie modelu Deep Learning. Jest również aktywnym zwolennikiem rozwiązań ML typu low-code oraz sprzętu wyspecjalizowanego w ML.
Joao Moura jest specjalistą ds. rozwiązań AI/ML w Amazon Web Services. Koncentruje się głównie na przypadkach użycia NLP i pomaga klientom zoptymalizować szkolenie i wdrażanie modelu Deep Learning. Jest również aktywnym zwolennikiem rozwiązań ML typu low-code oraz sprzętu wyspecjalizowanego w ML.
- Coinsmart. Najlepsza w Europie giełda bitcoinów i kryptowalut.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. DARMOWY DOSTĘP.
- CryptoJastrząb. Radar Altcoin. Bezpłatna wersja próbna.
- Źródło: https://aws.amazon.com/blogs/machine-learning/new-built-in-amazon-sagemaker-algorithms-for-tabular-data-modeling-lightgbm-catboost-autogluon-tabular-and-tabtransformer/
- "
- 100
- a
- Osiągać
- osiągnięty
- w poprzek
- aktywny
- Dodatkowy
- zaawansowany
- zaliczki
- przed
- algorytm
- algorytmiczny
- Algorytmy
- Wszystkie kategorie
- pozwala
- już
- alternatywny
- Amazonka
- Amazon Web Services
- analiza
- ogłosił
- odpowiedni
- stosowany
- architektura
- POWIERZCHNIA
- automatycznie
- automatycznie
- dostępny
- AWS
- bo
- Korzyści
- Ulepsz Swój
- Wzmocnione
- pobudzanie
- Pudełko
- wbudowany
- ostrożny
- walizka
- powodowany
- zmiana
- klasyczny
- klasyfikacja
- kod
- Kodowanie
- Kolumna
- jak
- społeczność
- Konkursy
- obliczać
- konferencje
- Konsola
- Pojemnik
- Stwórz
- stworzony
- krytyczny
- Obecnie
- zwyczaj
- Klientów
- dane
- analiza danych
- nauka danych
- czynienia
- decyzja
- głęboko
- Kreowanie
- wykazać
- rozwijać
- wdrażanie
- Wdrożenie
- opis
- rozwijać
- rozwinięty
- rozwijanie
- różne
- Doker
- każdy
- z łatwością
- efektywność
- wydajny
- Punkt końcowy
- Szacunki
- przykład
- przykłady
- Przede wszystkim system został opracowany
- Twarz
- Cecha
- Korzyści
- Łąka
- koncentruje
- koncentruje
- następujący
- Ramy
- od
- dalej
- Ponadto
- GPU
- Prowadzenie
- sprzęt komputerowy
- wysokość
- pomoc
- pomoc
- pomaga
- tutaj
- wysokiej jakości
- wyższy
- wysoko
- W jaki sposób
- How To
- HTTPS
- Piasta
- obraz
- realizacja
- podnieść
- włączony
- Włącznie z
- Informacja
- nieodłączny
- Innowacyjny
- wkład
- przykład
- zainteresowania
- Interfejs
- IT
- Praca
- dziennik
- Wiedzieć
- język
- uruchomić
- dowiedziałem
- nauka
- linki
- Lista
- Katalogowany
- maszyna
- uczenie maszynowe
- poważny
- i konserwacjami
- sposób
- Media
- średni
- ML
- model
- modele
- jeszcze
- większość
- wielokrotność
- Naturalny
- sieć
- Optymalizacja
- zoptymalizowane
- Option
- Inne
- własny
- właściciel
- szczególny
- Przechodzący
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- Popularny
- mocny
- przewidzieć
- przepowiednia
- Przewidywania
- teraźniejszość
- Problem
- wygląda tak
- przetwarzanie
- Produkt
- projekt
- zapewniać
- pod warunkiem,
- zapewnia
- publiczny
- opublikowany
- szybko
- nośny
- Surowy
- rozpoznaje
- region
- wymagać
- Badania naukowe
- Zasoby
- wynikły
- Efekt
- run
- bieganie
- taki sam
- Skalowalność
- skalowalny
- Skala
- skalowaniem
- nauka
- Naukowiec
- Naukowcy
- Sdk
- wybrany
- Serie
- Seria A
- Usługi
- zestaw
- kilka
- przesunięcie
- Prosty
- So
- Obserwuj Nas
- Media społecznościowe
- Społeczeństwo
- rozwiązanie
- Rozwiązania
- ROZWIĄZANIA
- kilka
- specjalny
- specjalista
- stos
- początek
- rozpoczęty
- state-of-the-art
- statystyczny
- Nadal
- przechowywanie
- wsparcie
- cel
- ukierunkowane
- zadania
- Techniczny
- Techniki
- Połączenia
- innych firm
- trzy
- Przez
- poprzez
- czas
- już dziś
- razem
- Śledzenie
- Pociąg
- Trening
- Przekształcać
- typy
- ui
- wyjątkowy
- posługiwać się
- przypadków użycia
- wartość
- różnorodny
- wersja
- sposoby
- sieć
- usługi internetowe
- Co
- w ciągu
- Twój