Czy kiedykolwiek czekałeś na tę jedną drogą paczkę z napisem „wysłano”, ale nie masz pojęcia, gdzie ona jest? Historia śledzenia przestała się aktualizować pięć dni temu i prawie straciłeś nadzieję. Ale poczekaj, 11 dni później masz go na wyciągnięcie ręki. Żałujesz, że identyfikowalność nie mogła być lepsza, aby uwolnić Cię od całego niespokojnego oczekiwania. W tym miejscu pojawia się „obserwowalność”.
W środowisku technicznym chciałbyś uniknąć takiej sytuacji w swoim oprogramowaniu lub systemach danych. W ten sposób przyjmujesz narzędzia monitorujące, które zbierają logi i metryki twoich systemów i informują cię o ich stanie wewnętrznym. Monitorowanie działa najlepiej, gdy chcesz, aby Twoje systemy informowały Cię o błędzie, gdzie i kiedy wystąpił, ale nie mówią, jak rozwiązać błąd.
Ponad dekadę temu narzędziom do monitorowania brakowało kontekstu i przewidywania podstawowych problemów systemowych, a zespoły byłyby ograniczone do debugowania codziennych błędów operacyjnych. Dziś pracujemy i żyjemy w rozproszonym świecie mikrousług i potoki danych; nawet stosowanie wielu narzędzi do monitorowania nie pomoże Ci odpowiedzieć na pytania biznesowe, takie jak „Dlaczego moja aplikacja zawsze działa wolno?” lub „Na jakim etapie wystąpił problem i jak głęboko znajduje się on w stosie?” lub „Jak mogę poprawić ogólną wydajność środowiska?” Konieczne staje się proaktywne podejmowanie tych decyzji oraz ogólny wgląd w swoje systemy, aplikacje i dane.
To zdjęcie blogu przez Etsy została opublikowana dziesięć lat temu i stwierdza sam fakt w drugim akapicie:
„Metryki aplikacji są zwykle najtrudniejsze, ale najważniejsze z tych trzech. Są one bardzo specyficzne dla Twojej firmy i zmieniają się wraz ze zmianami aplikacji (a Etsy bardzo się zmienia).”
Jak więc mierzyć wszystko i cokolwiek? Zaczynamy od obserwowalności.
Co to jest obserwowalność?
Termin „obserwowalność” był wymyślony przez Rudolfa Emila Kálmána w 1960 roku w jego artykule inżynierskim opisującym matematyczne systemy sterowania. Zdefiniował to jako miarę tego, jak dobrze stany wewnętrzne systemu można wywnioskować ze znajomości jego wyjść zewnętrznych. Ale czy to nie brzmi jak monitorowanie? Zasadniczo tak, to jest monitorowanie.
W dzisiejszych czasach obserwowalność stała się dość gorącym tematem. Według kilku badań rynkowych jest to platforma warta miliardy dolarów. Wiele organizacji przyjęło tę koncepcję i wykorzystało ją jako ramy dla kompleksowej widoczności swoich rozproszonych systemów i potoków. Obserwowalność jest jednak mylona z monitorowaniem. Na razie mogę powiedzieć, że monitorowanie jest podzbiorem obserwowalności, gdzie obserwowalność to jeden wielki termin ogólny.
Obserwowalność umożliwia rozproszone śledzenie poprzez gromadzenie i agregowanie śladów, dzienników i metryk. Zobaczmy, co wnioskują:
- Ślady: Kiedy system otrzymuje żądanie, ślady informują o tym, w jaki sposób żądanie przepływa przez cały cykl życia, od źródła do miejsca docelowego. Ślady są reprezentowane przez „rozpiętości”. Ślad to drzewo rozpiętości, a rozpiętość to pojedyncza operacja w obrębie śladu. Pomagają zlokalizować błędy, opóźnienia lub wąskie gardła w systemie.
- Dzienniki: Są to generowane maszynowo zdarzenia ze znacznikiem czasu, które informują o operacjach lub zmianach, które zaszły w systemie. Dzienniki są często używane do wyszukiwania tych błędów lub zmian w systemie.
- Metryka: Zapewniają one ilościowy wgląd w wykorzystanie procesora, pamięci, dysku oraz działanie systemu w określonym czasie.
Atrybuty te wzbogacają ramy monitorowania o identyfikowalność. Traceability zapewnia soczewkę do śledzenia żądania, które wysyła wywołanie do twojego systemu, jak długo trwa przejście od jednego komponentu do drugiego, jakie inne usługi wywołuje, czy zgłasza jakiś błąd, jakie dzienniki tworzy, jaki jest jego stan jest w trakcie, kiedy się zaczął i zakończył, jaka jest oś czasu, w jakim pozostała w Twoim systemie itp. Zbierając, agregując i analizując te ślady, możesz podejmować wartościowe, świadome decyzje, takie jak oś czasu klienta w witrynie handlu elektronicznego , jak długo zajęło im wyszukiwanie produktu, jak długo oglądali produkt, czy strona HTML załadowała pełne szczegóły, takie jak obrazy lub osadzone filmy, ile czasu zajęło systemowi uwierzytelnienie i przetworzenie płatności itp.
Co osiągamy dzięki obserwowalności w środowisku rozproszonym?
Ewolucja systemów rozproszonych rozpoczęła się, gdy organizacje zaczęły odchodzić od swojej scentralizowanej architektury monolitycznej do rozproszonej i zdecentralizowanej architektury mikrousług. Jest to wciąż praca w toku, w której wiele organizacji przyjmuje mikroserwisowy charakter systemów i aplikacji. A wszystko to można przypisać big danych i skalowanie. Zarządzanie rozproszonym środowiskiem wymaga ciągłego uczenia się, dodatkowej siły roboczej, zmian w strukturach i zasadach, zarządzania IT i tak dalej. To rzeczywiście duża zmiana.
Wcześniej, w ograniczonym środowisku monolitycznym, sprzęt, oprogramowanie, dane i bazy danych znajdowały się pod jednym dachem. Wraz z pojawieniem się dużych zbiorów danych w 2000 roku, systemy monitorowania i skalowania zaczęły budzić ogromne obawy. Często organizacje stosowały różne narzędzia do monitorowania, aby zaspokoić potrzeby różnych aplikacji. W rezultacie wkrótce stał się kosztem operacyjnym ze słabą odpornością, widocznością i niezawodnością.
Wszystkie te kwestie dały podstawę do przyjęcia obserwowalności. Obecnie istnieje wiele narzędzi umożliwiających obserwację dla bezpieczeństwa, sieci, aplikacji i potoków danych do rozproszonego śledzenia w złożonym środowisku. Współistnieją ze swoim kuzynem, narzędziami monitorującymi, i wykorzystują zbieranie informacji od swojego kuzyna oraz agregację z dodatkowymi informacjami z własnych danych śledzenia.
We wszystkich tych systemach jest wiele ruchomych elementów, których ślady uchwycone mogą zilustrować historię 5 W: kiedy, gdzie, dlaczego, co i jak. Na przykład wchodzisz na stronę DATAVERSITY o 1:43, aby przeczytać kilka postów na blogu. Kiedy trafisz na dataversity.net, żądanie HTTP zostanie zarejestrowane w systemie. Rozpoczynasz wyszukiwanie wpisu na blogu i trafiasz na wpis Data Governance, w którym spędzasz 17 minut na czytaniu tego wpisu, a następnie zamykasz kartę o 2:00
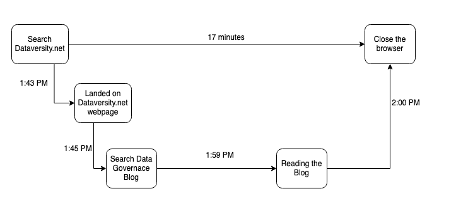
Będą również inne wywołania do systemu sieciowego w celu przechwytywania pakietów sieciowych. Narzędzia obserwowalności zbierają wszystkie rozpiętości i łączą je w ślad lub ślady, umożliwiając zobaczenie ścieżki, którą uformował podczas swojego cyklu życia. Jeśli masz problem, taki jak opóźnienie sieci lub usterka systemu, teraz łatwiej jest przeanalizować (obrać cebulę) i debugować problem (błąd w której warstwie).
Teraz, w dużym rozproszonym środowisku, gdy Twoje aplikacje otrzymują miliony żądań, dane śledzenia rosną w ogromnych ilościach. Gromadzenie i analizowanie tych śladów jest kosztowne ze względu na zużycie pamięci masowej i transfer danych. Tak więc, aby zaoszczędzić koszty, dane śledzenia są próbkowane, ponieważ w większości przypadków zespoły inżynierów potrzebują tylko niektórych elementów, aby zbadać, co poszło nie tak lub jaki jest wzorzec błędu.
Dzięki temu małemu przykładowi rozumiemy, że uzyskujemy znacznie głębszy wgląd w nasze systemy. Tak więc, biorąc pod uwagę większą skalę systemów, zespoły inżynierów mogą przechwytywać próbkowane dane i pracować na nich w celu ulepszenia obecnej struktury systemu, zastosowania lub wycofania nowych komponentów, dodania kolejnej warstwy bezpieczeństwa, usunięcia wąskich gardeł i tak dalej.
Czy organizacje powinny wybrać obserwowalność?
Wszyscy powinniśmy zrozumieć, że ostatecznymi celami są lepsze wrażenia użytkownika i większa satysfakcja użytkownika. A droga do osiągnięcia tych celów może być łatwiejsza dzięki zautomatyzowanej i proaktywnej strukturze obserwowalności. Ustanowienie kultury ciągłego doskonalenia i optymalizacji jest uważane za optymalne podejście biznesowe i przywódcze.
W epoce transformacji cyfrowej obserwowalność stała się koniecznością dla firmy, która chce odnieść sukces na swojej cyfrowej drodze. Zapewniając wnikliwe ślady, obserwowalność umożliwia również kierowanie się danymi, a nie tylko kierowanie nimi.
Wnioski
Chociaż używaliśmy terminów monitorowanie i obserwowalność zamiennie, zauważyliśmy, że podczas gdy monitorowanie pomaga w uzyskaniu informacji o kondycji systemu i zdarzeniach w nim zachodzących, obserwowalność ułatwia wyciąganie wniosków na podstawie dowodów zebranych z głębszych warstw rozwiązania końcowego. środowisko końcowe.
Obserwowalność jest i może być również postrzegana jako element ram zarządzania danymi. W tej generacji, w której stale rosnąca ilość danych znajduje się w sieci sprzętu komputerowego, ważne jest, aby architektury były jak najprostsze. I najwyraźniej zarządzanie środowiskiem staje się zadaniem niemożliwym do wykonania. W związku z tym wdrożenie odpowiednich i zautomatyzowanych zasad i zasad zarządzania w celu uporządkowania dużej siatki systemów, potoków i danych wymaga działania wcześniej niż później.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://www.dataversity.net/observability-traceability-for-distributed-systems/
- 1
- 11
- a
- Zdolny
- O nas
- Stosownie
- Osiągać
- osiągnięcia
- Działania
- Dodatkowy
- Dodatkowe informacje
- przyjąć
- przyjęty
- Przyjęcie
- nadejście
- Wszystkie kategorie
- pozwala
- zawsze
- w czasie rzeczywistym sprawiają,
- Analizując
- i
- Inne
- odpowiedź
- Zastosowanie
- aplikacje
- Aplikuj
- podejście
- właściwy
- architektura
- atrybuty
- uwierzytelniać
- zautomatyzowane
- uniknąć
- na podstawie
- Gruntownie
- bo
- stają się
- staje się
- rozpoczął
- BEST
- Ulepsz Swój
- Duży
- Big Data
- Blog
- Najnowsze wpisy
- wąskie gardła
- biznes
- wezwanie
- Połączenia
- zdobyć
- Etui
- scentralizowane
- zmiana
- Zmiany
- Dodaj
- Zamknij
- zbierać
- Zbieranie
- towar
- kompletny
- kompleks
- składnik
- składniki
- pojęcie
- Troska
- zmieszany
- za
- wobec
- konsumpcja
- kontekst
- ciągły
- kontrola
- Koszty:
- mógłby
- CPU
- kultura
- Aktualny
- klient
- dane
- sterowane danymi
- Bazy danych
- WSZECHSTRONNOŚĆ DANYCH
- dzień do dnia
- Dni
- dekada
- Zdecentralizowane
- Decyzje
- głęboko
- głębiej
- zdefiniowane
- opisać
- miejsce przeznaczenia
- detale
- ZROBIŁ
- różne
- cyfrowy
- cyfrowy Transformacja
- dystrybuowane
- systemy rozproszone
- Nie
- na dół
- podczas
- e-commerce
- łatwiej
- osadzone
- ogarnięcie
- umożliwiając
- koniec końców
- Inżynieria
- Środowisko
- błąd
- Błędy
- ustanowienie
- itp
- Parzyste
- wydarzenia
- EVER
- stale rosnący
- wszystko
- dowód
- ewolucja
- przykład
- drogi
- doświadczenie
- zewnętrzny
- ułatwia
- Przepływy
- utworzony
- Framework
- Ramy
- od
- generacja
- otrzymać
- Go
- Gole
- zarządzanie
- większy
- Rośnie
- się
- Wydarzenie
- sprzęt komputerowy
- Zdrowie
- pomoc
- pomaga
- historia
- Dobranie (Hit)
- nadzieję
- HOT
- W jaki sposób
- How To
- Jednak
- HTML
- HTTPS
- olbrzymi
- zdjęcia
- wykonawczych
- ważny
- niemożliwy
- podnieść
- poprawa
- in
- Informacja
- poinformowany
- spostrzeżenia
- wewnętrzny
- badać
- inwokuje
- problem
- problemy
- IT
- Zarządzanie zasobami IT
- podróż
- Trzymać
- wiedza
- krajobraz
- duży
- większe
- Utajenie
- warstwa
- nioski
- Przywództwo
- nauka
- obiektywy
- Dźwignia
- wifecycwe
- Ograniczony
- Linia
- relacja na żywo
- załadować
- długo
- Partia
- zrobiony
- robić
- WYKONUJE
- Dokonywanie
- zarządzanie
- i konserwacjami
- zarządzający
- wiele
- rynek
- matematyczny
- Maksymalna szerokość
- zmierzyć
- Pamięć
- Metryka
- mikroserwisy
- miliony
- minuty
- monitorowanie
- Monolityczny
- większość
- ruch
- przeniesienie
- wielokrotność
- Must-have
- Natura
- niezbędny
- Potrzebować
- wymagania
- netto
- sieć
- system sieciowy
- Nowości
- ONE
- działanie
- operacyjny
- operacje
- Optymalny
- optymalizacja
- organizacji
- Inne
- ogólny
- własny
- Papier
- ścieżka
- Wzór
- płatność
- spostrzegany
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- wykonywania
- okres
- sztuk
- Platforma
- plato
- Analiza danych Platona
- PlatoDane
- Grać
- polityka
- biedny
- możliwy
- Post
- Wiadomości
- Proaktywne
- Problem
- wygląda tak
- Produkt
- Postęp
- zapewniać
- zapewnia
- że
- opublikowany
- ilościowy
- pytania
- raczej
- Czytaj
- Czytający
- otrzymać
- otrzymuje
- niezawodność
- usunąć
- reprezentowane
- zażądać
- wywołań
- Wymaga
- sprężystość
- ograniczony
- dalsze
- Rosnąć
- dach
- reguły
- klientów
- Zapisz
- Skala
- skalowaniem
- Szukaj
- poszukiwania
- druga
- bezpieczeństwo
- Usługi
- kilka
- powinien
- Targi
- Prosty
- pojedynczy
- powolny
- mały
- So
- Tworzenie
- ROZWIĄZANIA
- kilka
- Wkrótce
- Dźwięk
- Źródło
- rozpiętości
- specyficzny
- wydać
- stos
- STAGE
- początek
- rozpoczęty
- Stan
- Zjednoczone
- został
- Nadal
- zatrzymany
- przechowywanie
- Historia
- Struktura
- udany
- system
- systemy
- Brać
- trwa
- Zadanie
- Zespoły
- Techniczny
- REGULAMIN
- Połączenia
- Informacje
- Źródło
- ich
- a tym samym
- trzy
- Przez
- poprzez
- czas
- Oś czasu
- do
- już dziś
- narzędzia
- aktualny
- wyśledzić
- Możliwość śledzenia
- Rysunek kalkowy
- Śledzenie
- przenieść
- Transformacja
- parasol
- dla
- zasadniczy
- zrozumieć
- aktualizowanie
- Stosowanie
- Użytkownik
- Doświadczenie użytkownika
- zazwyczaj
- Cenny
- różnorodny
- Filmy
- widoczność
- istotny
- Tom
- czekać
- Czekanie
- Strona internetowa
- Co
- Co to jest
- który
- Podczas
- będzie
- w ciągu
- Praca
- Siła robocza
- działa
- świat
- by
- Źle
- Twój
- zefirnet