Gartner, Inc. szacuje, że złe koszty danych organizacjom średnio 12.9 mln USD rocznie.
Codziennie mamy do czynienia z petabajtami danych, a problemy z jakością danych są powszechne w przypadku tak ogromnych ilości danych. Złe dane kosztują organizacje pieniądze, reputację i czas. Dlatego bardzo ważne jest ciągłe monitorowanie i sprawdzanie jakości danych.
Złe dane obejmują niedokładne informacje, brakujące dane, nieprawidłowe informacje, niezgodne dane i zduplikowane dane. Złe dane spowodują nieprawidłową analizę danych, co skutkuje złymi decyzjami i nieskutecznymi strategiami.
Jakość danych Experian wykazała, że przeciętna firma traci 12% swoich przychodów z powodu niewystarczających danych. Poza pieniędzmi firmy ponoszą również stratę straconego czasu.
Identyfikacja anomalii w danych przed ich przetworzeniem pomoże organizacjom uzyskać bardziej wartościowy wgląd w zachowania klientów i pomoże obniżyć koszty.
Biblioteka wielkich oczekiwań pomaga organizacjom weryfikować i potwierdzać takie anomalie w danych dzięki ponad 200 łatwo dostępnym gotowym regułom.
Great Expectations to biblioteka Pythona typu open source, która pomaga nam w sprawdzaniu poprawności danych. Wielkie oczekiwania dostarczyć zestaw metod lub funkcji do pomóc inżynierom danych szybko zweryfikować dany zestaw danych.
W tym artykule przyjrzymy się krokom związanym z weryfikacją danych przez bibliotekę Great Expectations.
GE jest jak testy jednostkowe dla danych. GE zapewnia twierdzenia zwane Oczekiwaniami, aby zastosować pewne reguły do testowanych danych. Na przykład identyfikator/numer polisy nie powinien być pusty w przypadku dokumentu polisy ubezpieczeniowej. Aby skonfigurować i uruchomić GE, musisz wykonać poniższe czynności. Chociaż istnieje wiele sposobów pracy z GE (przy użyciu interfejsu CLI), w tym artykule wyjaśnię programowy sposób konfigurowania rzeczy. Cały kod źródłowy wyjaśniony w tym artykule jest dostępny w this GitHub repo.
Krok 1: Skonfiguruj konfigurację danych
GE ma koncepcję sklepów. Magazyny to nic innego jak fizyczna lokalizacja na dysku, w której można przechowywać oczekiwania (reguły/twierdzenia), szczegóły przebiegu, szczegóły punktu kontrolnego, wyniki walidacji i dokumenty danych (statyczne wersje HTML wyników walidacji). Kliknij tutaj aby dowiedzieć się więcej o sklepach.
GE obsługuje różne backendy sklepów. W tym artykule używamy zaplecza magazynu plików i ustawień domyślnych. GE obsługuje inne backendy sklepów, takie jak AWS (Amazon Web Services) S3, Azure Blobs, PostgreSQL itp. dowiedz się więcej o backendach. Poniższy fragment kodu przedstawia bardzo prostą konfigurację danych:
STORE_FOLDER = "/Users/saisyam/work/github/great-expectations-sample/ge_data"
#Setup data config
data_context_config = DataContextConfig( datasources = {}, store_backend_defaults = FilesystemStoreBackendDefaults(root_directory=STORE_FOLDER)
) context = BaseDataContext(project_config = data_context_config)
Powyższa konfiguracja używa zaplecza magazynu plików z wartościami domyślnymi. GE automatycznie utworzy niezbędne foldery potrzebne do realizacji oczekiwań. W następnym kroku dodamy źródła danych.
Krok 2: skonfiguruj konfigurację źródła danych
Firma GE obsługuje trzy typy źródeł danych:
- Pandy
- Iskra
- SQLAlchemy
Konfiguracja źródła danych mówi firmie GE, aby używała określonego mechanizmu wykonawczego do przetwarzania dostarczonego zestawu danych. Na przykład, jeśli skonfigurujesz swoje źródło danych do korzystania z mechanizmu wykonawczego Pandas, musisz dostarczyć ramkę danych Pandas z danymi do GE, aby spełnić Twoje oczekiwania. Poniżej znajduje się przykład wykorzystania Pand jako źródła danych:
datasource_config = { "name": "sales_datasource", "class_name": "Datasource", "module_name": "great_expectations.datasource", "execution_engine": { "module_name": "great_expectations.execution_engine", "class_name": "PandasExecutionEngine", }, "data_connectors": { "default_runtime_data_connector_name": { "class_name": "RuntimeDataConnector", "module_name": "great_expectations.datasource.data_connector", "batch_identifiers": ["default_identifier_name"], }, },
}
context.add_datasource(**datasource_config)
Sprawdź ta dokumentacja aby uzyskać więcej informacji o źródłach danych.
Krok 3: Utwórz Pakiet Oczekiwania i Dodaj Oczekiwania
Ten krok jest kluczową częścią. W tym kroku stworzymy pakiet i dodamy do niego oczekiwania. Możesz rozważyć pakiet jako grupę oczekiwań, które będą działać jako partia. Oczekiwania, które tutaj tworzymy, mają na celu zweryfikowanie przykładowego raportu sprzedaży. Możesz pobrać plik sprzedaż.csv plik.
Poniższy fragment kodu pokazuje, jak utworzyć pakiet i dodać oczekiwania. Do naszego apartamentu dodamy dwa oczekiwania.
# Create expectations suite and add expectations
suite = context.create_expectation_suite(expectation_suite_name="sales_suite", overwrite_existing=True) expectation_config_1 = ExpectationConfiguration( expectation_type="expect_column_values_to_be_in_set", kwargs={ "column": "product_group", "value_set": ["PG1", "PG2", "PG3", "PG4", "PG5", "PG6"] }
) suite.add_expectation(expectation_configuration=expectation_config_1) expectation_config_2 = ExpectationConfiguration( expectation_type="expect_column_values_to_be_unique", kwargs={ "column": "id" }
) suite.add_expectation(expectation_configuration=expectation_config_2)
context.save_expectation_suite(suite, "sales_suite")
Pierwsze oczekiwanie „expect_column_values_to_be_in_set” sprawdza, czy wartości w kolumnie (grupa_produktów) są równe którejkolwiek z wartości w danym zestawie wartości. Drugie oczekiwanie sprawdza, czy wartości kolumny „id” są unikalne.
Po dodaniu i zapisaniu oczekiwań możemy teraz uruchomić te oczekiwania na zbiorze danych, który zobaczymy w kroku 4.
Krok 4: Załaduj i sprawdź poprawność danych
W tym kroku załadujemy nasz plik CSV do pandas.DataFrame i utworzymy punkt kontrolny, aby uruchomić oczekiwania, które stworzyliśmy powyżej.
# load and validate data
df = pd.read_csv("./sales.csv") batch_request = RuntimeBatchRequest( datasource_name="sales_datasource", data_connector_name="default_runtime_data_connector_name", data_asset_name="product_sales", runtime_parameters={"batch_data":df}, batch_identifiers={"default_identifier_name":"default_identifier"}
) checkpoint_config = { "name": "product_sales_checkpoint", "config_version": 1, "class_name":"SimpleCheckpoint", "expectation_suite_name": "sales_suite"
}
context.add_checkpoint(**checkpoint_config)
results = context.run_checkpoint( checkpoint_name="product_sales_checkpoint", validations=[ {"batch_request": batch_request} ]
)
Tworzymy żądanie wsadowe dla naszych danych, podając nazwę źródła danych, co powie GE, aby użył określonego silnika wykonawczego, w naszym przypadku Pandas. Tworzymy konfigurację punktu kontrolnego, a następnie sprawdzamy poprawność naszego żądania wsadowego względem punktu kontrolnego. Możesz dodać wiele żądań partii, jeśli oczekiwania dotyczą danych w partii w jednym punkcie kontrolnym. Metoda `run_checkpoint` zwraca wynik w formacie JSON i może być wykorzystana do dalszego przetwarzania lub analizy.
Efekt
Po spełnieniu oczekiwań dotyczących naszego zbioru danych firma GE tworzy statyczny pulpit nawigacyjny w formacie HTML z wynikami dla naszego punktu kontrolnego. Wyniki zawierają liczbę ocenionych oczekiwań, pomyślne oczekiwania, nieudane oczekiwania i procenty sukcesu. Rekordy, które nie spełniają podanych oczekiwań, zostaną wyróżnione na stronie. Poniżej znajduje się próbka pomyślnego wykonania:
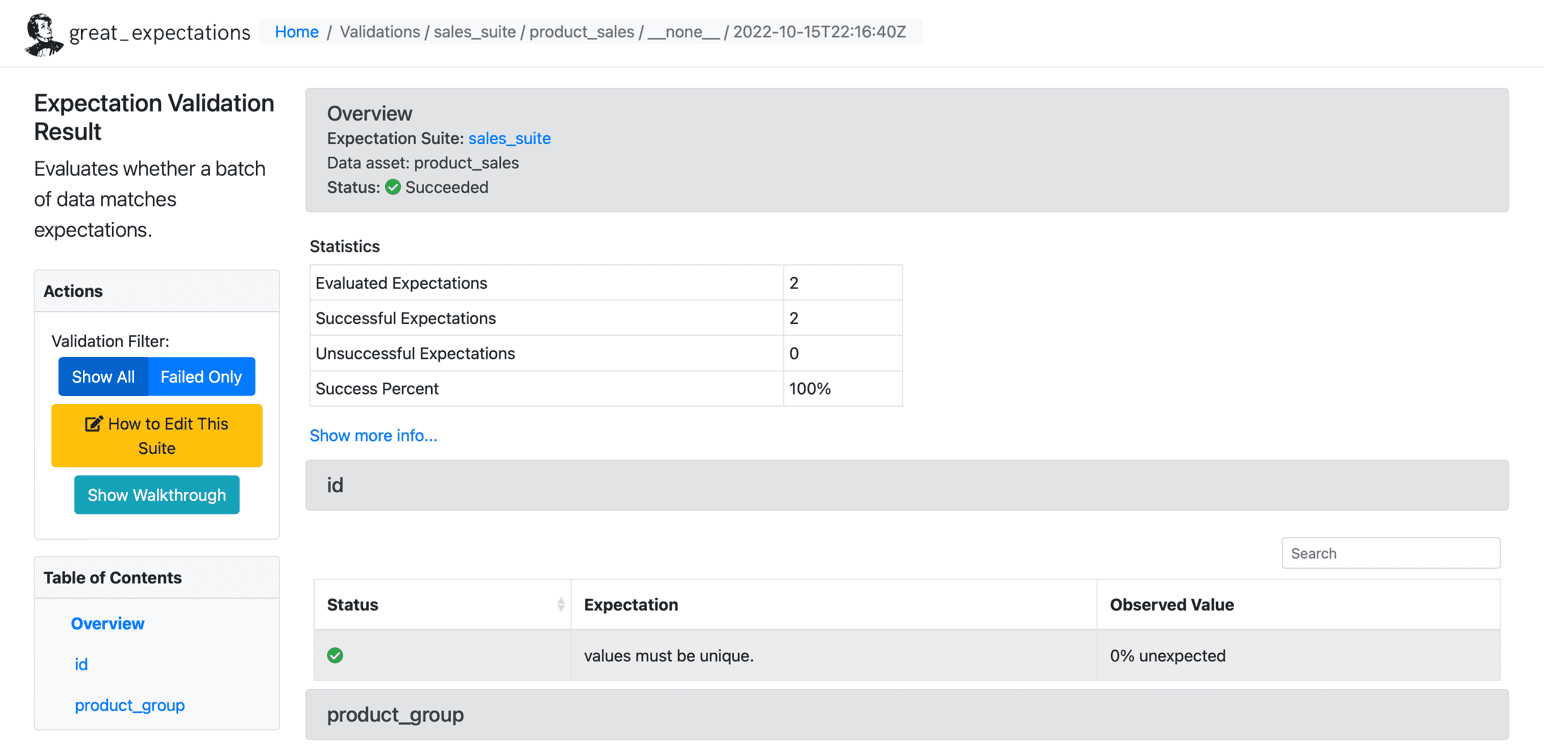
źródło: wielkie nadzieje
Poniżej znajduje się próbka nieudanych oczekiwań:
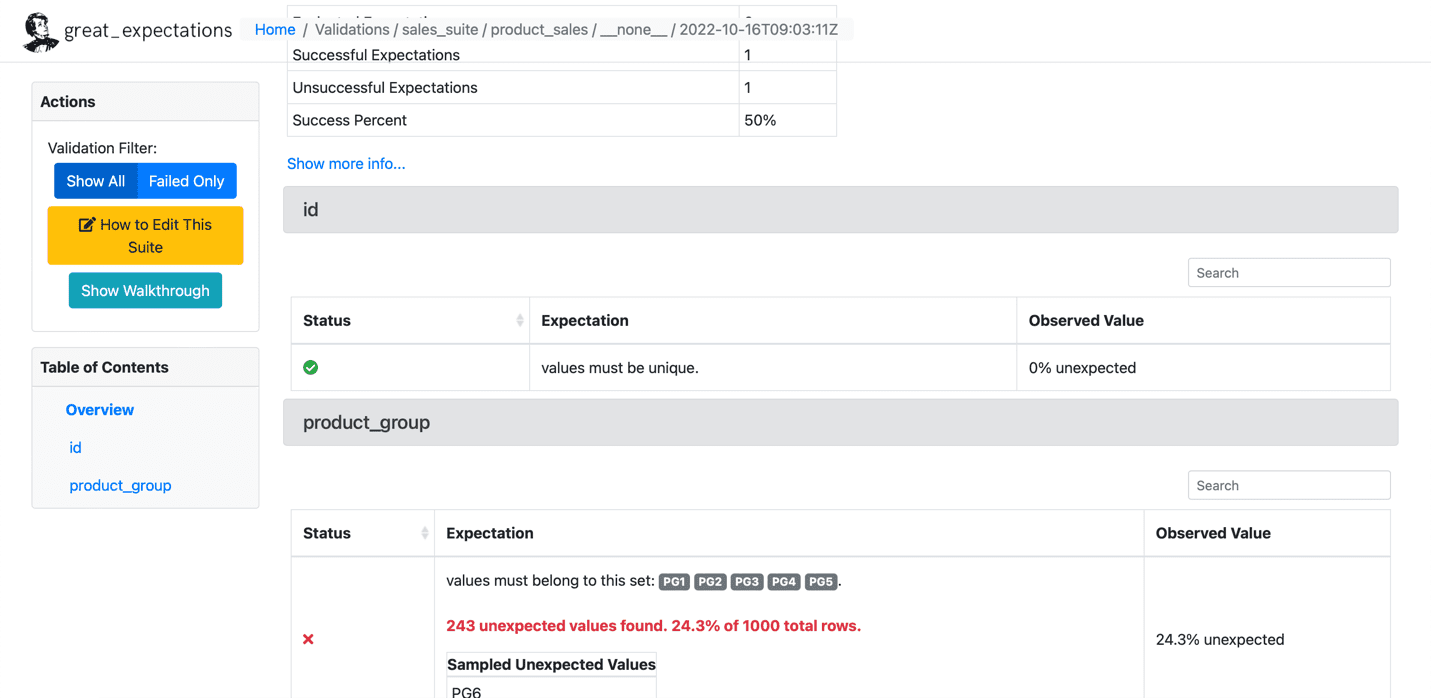
źródło: wielkie nadzieje
Skonfigurowaliśmy GE w czterech krokach i pomyślnie przeprowadziliśmy oczekiwania dotyczące danego zbioru danych. Firma GE oferuje bardziej zaawansowane funkcje, takie jak pisanie niestandardowych oczekiwań, które omówimy w przyszłych artykułach. Wiele organizacji intensywnie korzysta z usług GE, aby dostosowywać wymagania swoich klientów i tworzyć niestandardowe oczekiwania.
Saisyama Dampuriego ma ponad 18 lat doświadczenia w tworzeniu oprogramowania i jest pasjonatem odkrywania nowych technologii i narzędzi. Obecnie pracuje jako Sr. Cloud Architect w Anblicks, TX, USA. Nie kodując, będzie zajęty fotografią, gotowaniem i podróżowaniem.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://www.kdnuggets.com/2023/01/overcome-data-quality-issues-great-expectations.html?utm_source=rss&utm_medium=rss&utm_campaign=overcome-your-data-quality-issues-with-great-expectations
- 1
- 11
- 18 +
- 9
- a
- O nas
- powyżej
- w dodatku
- zaawansowany
- przed
- Wszystkie kategorie
- Amazonka
- Amazon Web Services
- analiza
- analityka
- i
- osobno
- Aplikuj
- artykuł
- towary
- automatycznie
- dostępny
- średni
- AWS
- Lazur
- Backend
- Łazienka
- złe dane
- zanim
- poniżej
- nazywa
- walizka
- Wykrywanie urządzeń szpiegujących
- klientów
- Chmura
- kod
- Kodowanie
- Kolumna
- wspólny
- Firmy
- sukcesy firma
- pojęcie
- systemu
- Rozważać
- kontekst
- gotowanie
- Koszty:
- pokrywa
- Stwórz
- stworzony
- tworzy
- istotny
- Obecnie
- zwyczaj
- klient
- zachowanie klienta
- dostosować
- codziennie
- tablica rozdzielcza
- dane
- analiza danych
- jakość danych
- zbiór danych
- sprawa
- Decyzje
- Domyślnie
- detale
- oprogramowania
- dokument
- pobieranie
- silnik
- Szacunki
- itp
- Eter (ETH)
- oceniane
- przykład
- wykonać
- egzekucja
- oczekiwanie
- oczekiwania
- doświadczenie
- Wyjaśniać
- wyjaśnione
- Exploring
- Failed
- Korzyści
- filet
- i terminów, a
- obserwuj
- Forbes
- format
- znaleziono
- FRAME
- od
- Funkcje
- dalej
- przyszłość
- Wzrost
- ge
- dany
- wspaniały
- Zarządzanie
- pomoc
- pomaga
- tutaj
- Podświetlony
- W jaki sposób
- How To
- HTML
- HTTPS
- olbrzymi
- ważny
- in
- niedokładny
- Inc
- obejmuje
- Informacja
- spostrzeżenia
- ubezpieczenie
- zaangażowany
- problemy
- IT
- json
- Knuggety
- UCZYĆ SIĘ
- Biblioteka
- załadować
- lokalizacja
- Popatrz
- Traci
- od
- wiele
- Mecz
- metoda
- metody
- milion
- brakujący
- pieniądze
- monitor
- jeszcze
- wielokrotność
- Nazwa
- niezbędny
- Potrzebować
- potrzebne
- Nowości
- Nowe technologie
- Następny
- numer
- open source
- organizacji
- Inne
- Przezwyciężać
- pandy
- część
- namiętny
- fotografia
- fizyczny
- plato
- Analiza danych Platona
- PlatoDane
- polityka
- postgresql
- wygląda tak
- przetwarzanie
- programowy
- zapewniać
- pod warunkiem,
- zapewnia
- że
- Python
- jakość
- szybko
- dokumentacja
- Zredukowany
- raport
- reputacja
- zażądać
- wywołań
- wymagania
- dalsze
- wynikły
- Efekt
- powraca
- dochód
- reguły
- run
- sole
- druga
- Usługi
- zestaw
- ustawienie
- powinien
- Targi
- Prosty
- pojedynczy
- Tworzenie
- rozwoju oprogramowania
- kilka
- Źródło
- Kod źródłowy
- Źródła
- specyficzny
- Ewolucja krok po kroku
- Cel
- sklep
- sklep
- strategie
- sukces
- udany
- Z powodzeniem
- taki
- apartament
- podpory
- Technologies
- mówi
- test
- Testy
- Połączenia
- Źródło
- ich
- rzeczy
- trzy
- czas
- do
- narzędzia
- Podróżowanie
- TX
- typy
- dla
- wyjątkowy
- jednostka
- us
- USD
- posługiwać się
- UPRAWOMOCNIĆ
- uprawomocnienie
- Cenny
- Wartości
- różnorodny
- zweryfikować
- kłęby
- sposoby
- sieć
- usługi internetowe
- czy
- który
- Podczas
- będzie
- Praca
- pracujący
- napisać
- pisanie
- lat
- Twój
- zefirnet

![Jak przyspieszyć zapytania SQL za pomocą indeksów [Python Edition] - KDnuggets](https://platoaistream.net/wp-content/uploads/2023/08/how-to-speed-up-sql-queries-using-indexes-python-edition-kdnuggets-360x203.png)





