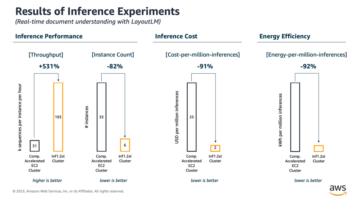
Ta trzyczęściowa seria demonstruje, jak używać grafowych sieci neuronowych (GNN) i Amazon Neptun do generowania rekomendacji filmowych za pomocą IMDb i Box Office Mojo Movies/TV/OTT licencjonowany pakiet danych, który zapewnia szeroki zakres metadanych związanych z rozrywką, w tym ponad 1 miliard ocen użytkowników; napisy dla ponad 11 milionów członków obsady i ekipy; 9 milionów tytułów filmowych, telewizyjnych i rozrywkowych; oraz globalne raporty kasowe z ponad 60 krajów. Wielu klientów mediów i rozrywki AWS licencjonuje dane IMDb za pośrednictwem Wymiana danych AWS aby usprawnić odkrywanie treści oraz zwiększyć zaangażowanie i utrzymanie klientów.
In Część 1, omówiliśmy zastosowania sieci GNN oraz sposób przekształcania i przygotowywania naszych danych IMDb do wykonywania zapytań. W tym poście omawiamy proces używania Neptuna do generowania osadzania, które posłużyło do przeprowadzenia wyszukiwania poza katalogiem w części 3. My też przechodzimy Amazonka Neptuna ML, funkcja uczenia maszynowego (ML) Neptune oraz kod, którego używamy w naszym procesie programowania. W części 3 omówimy, jak zastosować osadzanie grafu wiedzy w przypadku użycia wyszukiwania spoza katalogu.
Omówienie rozwiązania
Duże połączone zestawy danych często zawierają cenne informacje, które mogą być trudne do wyodrębnienia przy użyciu zapytań opartych wyłącznie na ludzkiej intuicji. Techniki uczenia maszynowego mogą pomóc znaleźć ukryte korelacje na wykresach z miliardami relacji. Te korelacje mogą być pomocne przy polecaniu produktów, przewidywaniu zdolności kredytowej, identyfikowaniu oszustw i wielu innych przypadkach użycia.
Neptune ML umożliwia budowanie i trenowanie użytecznych modeli ML na dużych wykresach w ciągu godzin zamiast tygodni. Aby to osiągnąć, Neptune ML wykorzystuje technologię GNN obsługiwaną przez Amazon Sage Maker oraz Biblioteka głębokich grafów (DGL) (który jest open-source). Sieci GNN to wschodząca dziedzina sztucznej inteligencji (na przykład zob Kompleksowa ankieta dotycząca grafowych sieci neuronowych). Aby zapoznać się z praktycznym samouczkiem dotyczącym używania GNN z DGL, zobacz Nauka grafowych sieci neuronowych za pomocą Deep Graph Library.
W tym poście pokazujemy, jak używać Neptuna w naszym potoku do generowania osadzania.
Poniższy diagram przedstawia ogólny przepływ danych IMDb od pobrania do generowania osadzania.
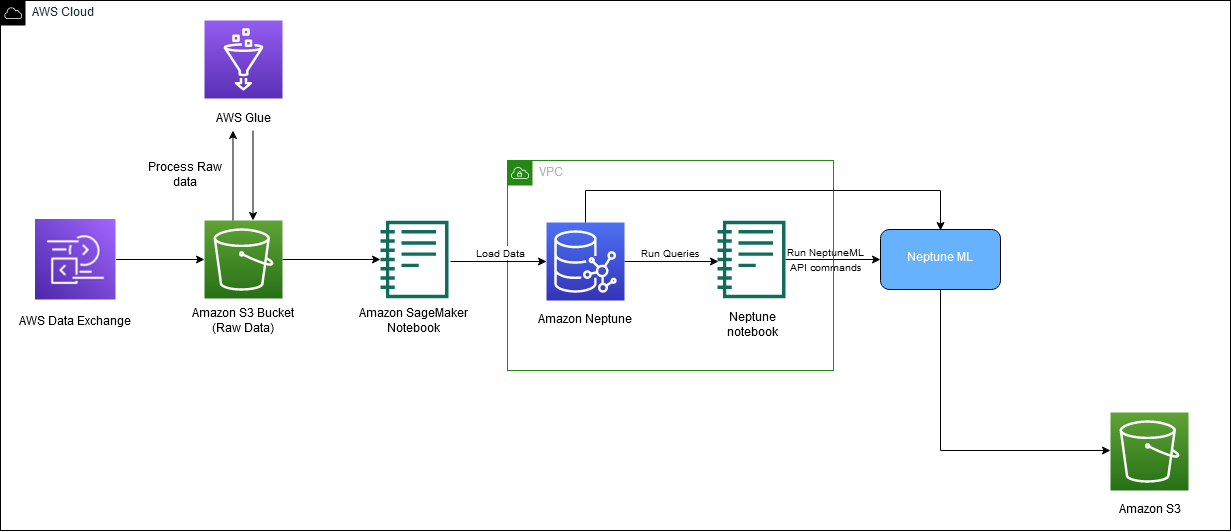
Do wdrożenia rozwiązania wykorzystujemy następujące usługi AWS:
W tym poście przeprowadzimy Cię przez następujące ogólne kroki:
- Skonfiguruj zmienne środowiskowe
- Utwórz zadanie eksportu.
- Utwórz zadanie przetwarzania danych.
- Prześlij ofertę szkolenia.
- Pobierz osadzone elementy.
Kod dla poleceń Neptune ML
W ramach implementacji tego rozwiązania używamy następujących komend:
Używamy pliki neptune_ml export aby sprawdzić status lub rozpocząć proces eksportu Neptune ML oraz neptune_ml training aby rozpocząć i sprawdzić stan zadania szkolenia modelu Neptune ML.
Aby uzyskać więcej informacji na temat tych i innych poleceń, zobacz Używanie magii stołu warsztatowego Neptuna w swoich notatnikach.
Wymagania wstępne
Aby śledzić ten post, powinieneś mieć:
- An Konto AWS
- Znajomość SageMaker, Amazon S3 i AWS CloudFormation
- Dane wykresu załadowane do gromady Neptuna (patrz Część 1 po więcej informacji)
Skonfiguruj zmienne środowiskowe
Zanim zaczniemy, musisz skonfigurować swoje środowisko, ustawiając następujące zmienne: s3_bucket_uri i processed_folder. s3_bucket_uri to nazwa wiadra użytego w części 1 i processed_folder to lokalizacja Amazon S3 dla danych wyjściowych z zadania eksportu.
Utwórz zadanie eksportu
W części 1 stworzyliśmy notatnik SageMaker i usługę eksportu, aby wyeksportować nasze dane z klastra Neptune DB do Amazon S3 w wymaganym formacie.
Teraz, gdy nasze dane są załadowane i usługa eksportu jest utworzona, musimy utworzyć zadanie eksportu, aby je uruchomić. Aby to zrobić, używamy NeptuneExportApiUri i utwórz parametry zadania eksportu. W poniższym kodzie używamy zmiennych expo i export_params. Zestaw expo dla Twojej NeptuneExportApiUri wartość, którą można znaleźć na stronie Wyjścia zakładka stosu CloudFormation. Do export_params, używamy punktu końcowego klastra Neptuna i podajemy wartość dla outputS3path, czyli lokalizację Amazon S3 dla danych wyjściowych z zadania eksportu.
Aby przesłać zadanie eksportu, użyj następującego polecenia:
Aby sprawdzić status zadania eksportu, użyj następującego polecenia:
Po zakończeniu zadania ustaw processed_folder zmienna dostarczająca lokalizację Amazon S3 przetworzonych wyników:
Utwórz zadanie przetwarzania danych
Po zakończeniu eksportu tworzymy zadanie przetwarzania danych w celu przygotowania danych do procesu szkolenia Neptune ML. Można to zrobić na kilka różnych sposobów. W tym kroku możesz zmienić job_name i modelType zmienne, ale wszystkie inne parametry muszą pozostać takie same. Główną częścią tego kodu jest tzw modelType parametr, którym mogą być heterogeniczne modele grafów (heterogeneous) lub wykresy wiedzy (kge).
Zadanie eksportu obejmuje również training-data-configuration.json. Użyj tego pliku, aby dodać lub usunąć dowolne węzły lub krawędzie, których nie chcesz udostępniać do uczenia (na przykład, jeśli chcesz przewidzieć połączenie między dwoma węzłami, możesz usunąć to łącze w tym pliku konfiguracyjnym). W tym poście na blogu używamy oryginalnego pliku konfiguracyjnego. Aby uzyskać dodatkowe informacje, zob Edycja pliku konfiguracyjnego treningu.
Utwórz zadanie przetwarzania danych za pomocą następującego kodu:
Aby sprawdzić status zadania eksportu, użyj następującego polecenia:
Prześlij ofertę szkolenia
Po zakończeniu zadania przetwarzania możemy rozpocząć pracę szkoleniową, w której tworzymy nasze osadzenia. Zalecamy typ instancji ml.m5.24xlarge, ale możesz go zmienić, aby dostosować go do swoich potrzeb obliczeniowych. Zobacz następujący kod:
Drukujemy zmienną training_results, aby uzyskać identyfikator zadania szkoleniowego. Użyj następującego polecenia, aby sprawdzić stan swojego zadania:
%neptune_ml training status --job-id {training_results['id']} --store-to training_status_results
Pobierz osadzone elementy
Ostatnim krokiem po zakończeniu zadania szkoleniowego jest pobranie surowych osadzeń. Poniższe kroki pokazują, jak pobrać osadzenie utworzone za pomocą KGE (możesz użyć tego samego procesu dla RGCN).
W poniższym kodzie używamy neptune_ml.get_mapping() i get_embeddings() aby pobrać plik mapowania (mapping.info) i surowy plik osadzania (entity.npy). Następnie musimy zmapować odpowiednie osadzenia na odpowiadające im identyfikatory.
Aby pobrać numery RGCN, wykonaj ten sam proces z nową nazwą zadania szkoleniowego, przetwarzając dane z parametrem modelType ustawionym na heterogeneous, a następnie wytrenuj swój model z parametrem modelName ustawionym na rgcn widzieć tutaj po więcej szczegółów. Gdy to się skończy, zadzwoń pod numer tel get_mapping i get_embeddings funkcje pobierania nowego mapowanie.informacje i jednostka.npy pliki. Po uzyskaniu plików encji i mapowania proces tworzenia pliku CSV jest identyczny.
Na koniec prześlij swoje osadzenie do wybranej lokalizacji Amazon S3:
Upewnij się, że pamiętasz tę lokalizację S3, będziesz musiał jej użyć w części 3.
Sprzątać
Po zakończeniu korzystania z rozwiązania pamiętaj o wyczyszczeniu wszelkich zasobów, aby uniknąć bieżących opłat.
Wnioski
W tym poście omówiliśmy, jak używać Neptune ML do trenowania osadzania GNN z danych IMDb.
Niektóre powiązane zastosowania osadzania wykresów wiedzy to koncepcje, takie jak wyszukiwanie poza katalogiem, rekomendacje treści, reklamy ukierunkowane, przewidywanie brakujących linków, wyszukiwanie ogólne i analiza kohortowa. Wyszukiwanie poza katalogiem to proces wyszukiwania treści, które nie są Twoją własnością, oraz znajdowania lub polecania treści znajdujących się w Twoim katalogu, które są jak najbardziej zbliżone do tego, czego szukał użytkownik. W części 3 zagłębimy się w wyszukiwanie poza katalogiem.
O autorach
 Mateusz Rodos jest Data Scientist I pracuje w Amazon ML Solutions Lab. Specjalizuje się w budowaniu potoków uczenia maszynowego, które obejmują pojęcia takie jak przetwarzanie języka naturalnego i widzenie komputerowe.
Mateusz Rodos jest Data Scientist I pracuje w Amazon ML Solutions Lab. Specjalizuje się w budowaniu potoków uczenia maszynowego, które obejmują pojęcia takie jak przetwarzanie języka naturalnego i widzenie komputerowe.
 Divya Bhargawi jest Data Scientist i Media and Entertainment Vertical Lead w Amazon ML Solutions Lab, gdzie rozwiązuje problemy biznesowe o dużej wartości dla klientów AWS za pomocą uczenia maszynowego. Zajmuje się rozumieniem obrazu/wideo, systemami rekomendacji opartymi na grafach wiedzy, predykcyjnymi przypadkami użycia reklamy.
Divya Bhargawi jest Data Scientist i Media and Entertainment Vertical Lead w Amazon ML Solutions Lab, gdzie rozwiązuje problemy biznesowe o dużej wartości dla klientów AWS za pomocą uczenia maszynowego. Zajmuje się rozumieniem obrazu/wideo, systemami rekomendacji opartymi na grafach wiedzy, predykcyjnymi przypadkami użycia reklamy.
 Gaurav Rele jest analitykiem danych w Amazon ML Solution Lab, gdzie współpracuje z klientami AWS z różnych branż, aby przyspieszyć korzystanie z uczenia maszynowego i usług AWS Cloud w celu rozwiązywania ich problemów biznesowych.
Gaurav Rele jest analitykiem danych w Amazon ML Solution Lab, gdzie współpracuje z klientami AWS z różnych branż, aby przyspieszyć korzystanie z uczenia maszynowego i usług AWS Cloud w celu rozwiązywania ich problemów biznesowych.
 Karana Sindwaniego jest Data Scientist w Amazon ML Solutions Lab, gdzie buduje i wdraża modele głębokiego uczenia. Specjalizuje się w dziedzinie widzenia komputerowego. W wolnym czasie lubi piesze wędrówki.
Karana Sindwaniego jest Data Scientist w Amazon ML Solutions Lab, gdzie buduje i wdraża modele głębokiego uczenia. Specjalizuje się w dziedzinie widzenia komputerowego. W wolnym czasie lubi piesze wędrówki.
 Sodżi Adeszina jest naukowcem stosowanym w AWS, gdzie opracowuje modele oparte na grafowych sieciach neuronowych do uczenia maszynowego na zadaniach grafowych z aplikacjami do oszustw i nadużyć, grafów wiedzy, systemów rekomendujących i nauk przyrodniczych. W wolnym czasie lubi czytać i gotować.
Sodżi Adeszina jest naukowcem stosowanym w AWS, gdzie opracowuje modele oparte na grafowych sieciach neuronowych do uczenia maszynowego na zadaniach grafowych z aplikacjami do oszustw i nadużyć, grafów wiedzy, systemów rekomendujących i nauk przyrodniczych. W wolnym czasie lubi czytać i gotować.
 Widja Sagar Rawipati jest menedżerem w Amazon ML Solutions Lab, gdzie wykorzystuje swoje ogromne doświadczenie w wielkoskalowych systemach rozproszonych i swoją pasję do uczenia maszynowego, aby pomóc klientom AWS z różnych branż przyspieszyć wdrażanie sztucznej inteligencji i chmury.
Widja Sagar Rawipati jest menedżerem w Amazon ML Solutions Lab, gdzie wykorzystuje swoje ogromne doświadczenie w wielkoskalowych systemach rozproszonych i swoją pasję do uczenia maszynowego, aby pomóc klientom AWS z różnych branż przyspieszyć wdrażanie sztucznej inteligencji i chmury.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/part-2-power-recommendations-and-search-using-an-imdb-knowledge-graph/
- 1
- 10
- 100
- 11
- 116
- 7
- 9
- a
- O nas
- nadużycie
- przyśpieszyć
- w poprzek
- Dodatkowy
- Dodatkowe informacje
- Przyjęcie
- Reklama
- Po
- AI
- Wszystkie kategorie
- sam
- Amazonka
- Laboratorium rozwiązań Amazon ML
- analiza
- i
- aplikacje
- stosowany
- Aplikuj
- właściwy
- POWIERZCHNIA
- sztuczny
- sztuczna inteligencja
- AWS
- na podstawie
- pomiędzy
- Miliard
- miliardy
- Blog
- Pudełko
- box office
- budować
- Budowanie
- Buduje
- biznes
- wezwanie
- walizka
- Etui
- katalog
- wyzwania
- zmiana
- Opłaty
- ZOBACZ
- Zamknij
- Chmura
- adopcja chmury
- usługi w chmurze
- Grupa
- kod
- Kohorta
- kompletny
- wszechstronny
- komputer
- Wizja komputerowa
- computing
- Koncepcje
- Prowadzenie
- systemu
- połączony
- zawartość
- Odpowiedni
- kraje
- Stwórz
- stworzony
- kredyt
- Kredyty
- klient
- Zaangażowanie klienta
- Klientów
- dane
- analiza danych
- naukowiec danych
- zbiory danych
- głęboko
- głęboka nauka
- głębiej
- wdraża się
- detale
- oprogramowania
- rozwija się
- tak jak
- różne
- odkrycie
- dyskutować
- omówione
- dystrybuowane
- systemy rozproszone
- nie
- pobieranie
- bądź
- wschodzących
- Punkt końcowy
- zaręczynowy
- rozrywka
- jednostka
- Środowisko
- Eter (ETH)
- przykład
- doświadczenie
- eksport
- wyciąg
- Cecha
- kilka
- pole
- filet
- Akta
- Znajdź
- znalezieniu
- pływ
- obserwuj
- następujący
- format
- oszustwo
- od
- pełny
- Funkcje
- Ogólne
- Generować
- generacja
- otrzymać
- Globalne
- Go
- wykres
- wykresy
- hands-on
- Ciężko
- pomoc
- pomocny
- Ukryty
- na wysokim szczeblu
- GODZINY
- W jaki sposób
- How To
- HTML
- HTTPS
- człowiek
- identiques
- identyfikacja
- wdrożenia
- wykonawczych
- podnieść
- in
- obejmuje
- Włącznie z
- Zwiększać
- wskaźnik
- przemysł
- Informacje
- Informacja
- przykład
- zamiast
- Inteligencja
- angażować
- IT
- Praca
- json
- Klawisz
- wiedza
- laboratorium
- język
- duży
- na dużą skalę
- Nazwisko
- prowadzić
- nauka
- wykorzystuje
- Biblioteka
- Licencja
- życie
- Life Sciences
- LINK
- linki
- lokalizacja
- maszyna
- uczenie maszynowe
- Główny
- WYKONUJE
- kierownik
- wiele
- mapa
- mapowanie
- Media
- średni
- Użytkownicy
- Metadane
- milion
- brakujący
- ML
- model
- modele
- jeszcze
- film
- Nazwa
- Naturalny
- Przetwarzanie języka naturalnego
- Potrzebować
- wymagania
- Neptun
- oparty na sieci
- sieci
- sieci neuronowe
- Nowości
- węzły
- notatnik
- Biurowe
- trwający
- oryginalny
- Inne
- ogólny
- własny
- pakiet
- parametr
- parametry
- część
- pasja
- rurociąg
- plato
- Analiza danych Platona
- PlatoDane
- możliwy
- Post
- power
- powered
- przewidzieć
- przewidywanie
- Przygotować
- problemy
- wygląda tak
- przetwarzanie
- Produkty
- Profil
- zapewniać
- zapewnia
- zasięg
- Oceny
- Surowy
- Czytający
- polecić
- Rekomendacja
- zalecenia
- polecający
- związane z
- Relacje
- pozostawać
- pamiętać
- usunąć
- Raportowanie
- wymagany
- Zasoby
- Efekt
- retencja
- sagemaker
- taki sam
- NAUKI
- Naukowiec
- Szukaj
- poszukiwania
- Serie
- usługa
- Usługi
- zestaw
- ustawienie
- powinien
- pokazać
- rozwiązanie
- Rozwiązania
- ROZWIĄZANIA
- Rozwiązuje
- specjalizuje się
- stos
- początek
- Rynek
- Ewolucja krok po kroku
- Cel
- sklep
- Zatwierdź
- taki
- Garnitur
- Badanie
- systemy
- ukierunkowane
- zadania
- Techniki
- Technologia
- Połączenia
- Strefa
- ich
- Przez
- czas
- tytuły
- do
- Pociąg
- Trening
- Przekształcać
- prawdziwy
- Tutorial
- tv
- zrozumienie
- posługiwać się
- przypadek użycia
- Użytkownik
- Cenny
- wartość
- Naprawiono
- wersja
- pionowe
- wizja
- sposoby
- tygodni
- Co
- który
- szeroki
- Szeroki zasięg
- będzie
- pracujący
- działa
- Twój
- zefirnet