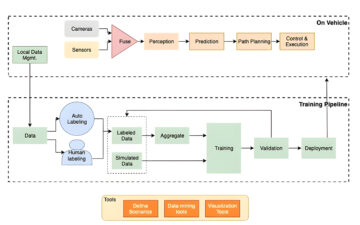
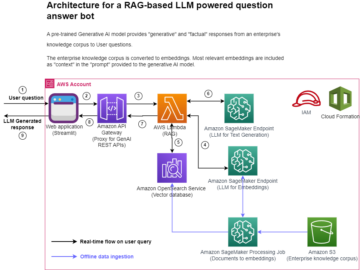
W wizji komputerowej segmentacja semantyczna polega na zaklasyfikowaniu każdego piksela na obrazie do klasy ze znanego zestawu etykiet, tak aby piksele o tej samej etykiecie miały pewne cechy. Generuje maskę segmentacji obrazów wejściowych. Na przykład poniższe obrazy przedstawiają maskę segmentacji cat etykieta.
 |
 |
W listopadzie 2018, Amazon Sage Maker ogłosił uruchomienie algorytmu segmentacji semantycznej SageMaker. Za pomocą tego algorytmu możesz trenować swoje modele za pomocą publicznego zestawu danych lub własnego zestawu danych. Popularne zestawy danych segmentacji obrazów obejmują zestaw danych Common Objects in Context (COCO) i PASCAL Visual Object Classes (PASCAL VOC), ale klasy ich etykiet są ograniczone i możesz chcieć trenować model na obiektach docelowych, które nie są uwzględnione w publiczne zbiory danych. W takim przypadku możesz użyć Amazon SageMaker Ground Prawda oznaczyć własny zbiór danych.
W tym poście przedstawiam następujące rozwiązania:
- Używanie Ground Truth do oznaczania zbioru danych segmentacji semantycznej
- Przekształcenie wyników z Ground Truth do wymaganego formatu wejściowego dla wbudowanego algorytmu segmentacji semantycznej SageMaker
- Używanie algorytmu segmentacji semantycznej do trenowania modelu i przeprowadzania wnioskowania
Oznaczanie danych segmentacji semantycznej
Aby zbudować model uczenia maszynowego do segmentacji semantycznej, musimy oznaczyć zbiór danych na poziomie piksela. Ground Truth daje możliwość korzystania z ludzkich adnotatorów poprzez Amazon Mechanical Turk, zewnętrzni dostawcy lub własna prywatna siła robocza. Aby dowiedzieć się więcej o pracownikach, zapoznaj się z Twórz siły robocze i zarządzaj nimi. Jeśli nie chcesz samodzielnie zarządzać personelem zajmującym się etykietowaniem, Amazon SageMaker Ground Truth Plus to kolejna świetna opcja jako nowa usługa etykietowania danych „pod klucz”, która umożliwia szybkie tworzenie wysokiej jakości zestawów danych szkoleniowych i zmniejsza koszty nawet o 40%. W tym poście pokazuję, jak ręcznie oznaczyć zestaw danych za pomocą funkcji automatycznego segmentowania Ground Truth i etykietowania crowdsource z siłą roboczą Mechanical Turk.
Ręczne etykietowanie z Ground Truth
W grudniu 2019 r. Ground Truth dodał funkcję automatycznego segmentowania do interfejsu użytkownika etykietowania z segmentacją semantyczną, aby zwiększyć przepustowość etykietowania i poprawić dokładność. Aby uzyskać więcej informacji, zobacz Automatyczna segmentacja obiektów podczas wykonywania etykietowania segmentacji semantycznej za pomocą Amazon SageMaker Ground Truth. Dzięki tej nowej funkcji możesz przyspieszyć proces etykietowania zadań segmentacji. Zamiast rysować ciasno dopasowany wielokąt lub używać narzędzia pędzla do uchwycenia obiektu na obrazie, rysujesz tylko cztery punkty: w najwyższym, najniższym, lewym i prawym punkcie obiektu. Ground Truth przyjmuje te cztery punkty jako dane wejściowe i wykorzystuje algorytm Deep Extreme Cut (DEXTR) do utworzenia ściśle dopasowanej maski wokół obiektu. Aby zapoznać się z samouczkiem dotyczącym używania Ground Truth do oznaczania semantycznej segmentacji obrazu, zobacz Segmentacja semantyczna obrazu. Poniżej znajduje się przykład tego, jak narzędzie automatycznej segmentacji automatycznie generuje maskę segmentacji po wybraniu czterech skrajnych punktów obiektu.


Etykietowanie crowdsourcingowe z siłą roboczą Mechanical Turk
Jeśli masz duży zestaw danych i nie chcesz samodzielnie etykietować setek lub tysięcy obrazów, możesz użyć Mechanical Turk, który zapewnia skalowalną, ludzką siłę roboczą na żądanie do wykonywania zadań, które ludzie mogą wykonywać lepiej niż komputery. Oprogramowanie Mechanical Turk formalizuje oferty pracy dla tysięcy pracowników, którzy chcą wykonywać pracę fragmentaryczną w dogodnym dla nich czasie. Oprogramowanie pobiera również wykonaną pracę i kompiluje ją dla Ciebie, wnioskodawcy, który płaci pracownikom za satysfakcjonującą pracę (tylko). Aby rozpocząć korzystanie z Mechanical Turk, zapoznaj się z Wprowadzenie do Amazon Mechanical Turk.
Utwórz zadanie etykietowania
Poniżej znajduje się przykład zadania etykietowania Mechanical Turk dla zestawu danych żółwia morskiego. Zbiór danych o żółwiach morskich pochodzi z konkursu Kaggle Wykrywanie twarzy żółwia morskiegoi wybrałem 300 obrazów zestawu danych do celów demonstracyjnych. Żółw morski nie jest powszechną klasą w publicznych zbiorach danych, więc może reprezentować sytuację, która wymaga etykietowania ogromnego zbioru danych.
- W konsoli SageMaker wybierz Etykietowanie zadań w okienku nawigacji.
- Dodaj Utwórz zadanie etykietowania.
- Wpisz nazwę swojej pracy.
- W razie zamówieenia projektu Konfiguracja danych wejściowych, Wybierz Zautomatyzowana konfiguracja danych.
To generuje manifest danych wejściowych. - W razie zamówieenia projektu Lokalizacja S3 dla wejściowych zestawów danych, wprowadź ścieżkę do zbioru danych.

- W razie zamówieenia projektu Kategoria zadaniawybierz Obraz.
- W razie zamówieenia projektu Wybór zadań, Wybierz Segmentacja semantyczna.

- W razie zamówieenia projektu Rodzaje pracowników, Wybierz Amazon Mechanical Turk.
- Skonfiguruj ustawienia dotyczące limitu czasu zadania, czasu wygaśnięcia zadania i ceny za zadanie.

- Dodaj etykietę (dla tego posta
sea turtle) i podać instrukcje dotyczące etykietowania. - Dodaj Stwórz.

Po skonfigurowaniu zadania etykietowania możesz sprawdzić postęp etykietowania w konsoli SageMaker. Gdy zostanie oznaczony jako ukończony, możesz wybrać zadanie, aby sprawdzić wyniki i wykorzystać je w kolejnych krokach.

Transformacja zbioru danych
Po uzyskaniu danych wyjściowych z Ground Truth możesz użyć wbudowanych algorytmów programu SageMaker do trenowania modelu na tym zestawie danych. Najpierw musisz przygotować oznaczony zestaw danych jako żądany interfejs wejściowy dla algorytmu segmentacji semantycznej SageMaker.
Żądane kanały danych wejściowych
Semantyczna segmentacja SageMaker oczekuje, że Twój zestaw danych treningowych będzie przechowywany na Usługa Amazon Simple Storage (Amazonka S3). Oczekuje się, że zbiór danych w Amazon S3 będzie prezentowany w dwóch kanałach, jeden dla train i jeden dla validation, używając czterech katalogów, dwóch dla obrazów i dwóch dla adnotacji. Oczekuje się, że adnotacje będą nieskompresowanymi obrazami PNG. Zestaw danych może również zawierać mapę etykiet opisującą sposób tworzenia mapowań adnotacji. Jeśli nie, algorytm używa wartości domyślnej. Na potrzeby wnioskowania punkt końcowy akceptuje obrazy z image/jpeg Typ zawartości. Poniżej przedstawiono wymaganą strukturę kanałów danych:
Każdy obraz JPG w katalogach pociągu i walidacji ma odpowiedni obraz etykiety PNG o tej samej nazwie w train_annotation i validation_annotation katalogi. Ta konwencja nazewnictwa pomaga algorytmowi powiązać etykietę z odpowiadającym jej obrazem podczas uczenia. Pociąg, train_annotation, walidacja i validation_annotation kanały są obowiązkowe. Adnotacje to jednokanałowe obrazy PNG. Format działa tak długo, jak metadane (tryby) w obrazie pomagają algorytmowi odczytać obrazy adnotacji do jednokanałowej 8-bitowej liczby całkowitej bez znaku.
Dane wyjściowe z zadania etykietowania Ground Truth
Dane wyjściowe wygenerowane z zadania etykietowania Ground Truth mają następującą strukturę folderów:
Maski segmentacyjne są zapisywane w s3://turtle2022/labelturtles/annotations/consolidated-annotation/output. Każdy obraz adnotacji to plik .png nazwany na podstawie indeksu obrazu źródłowego i czasu zakończenia oznaczania tego obrazu. Na przykład poniżej znajduje się obraz źródłowy (Image_1.jpg) i jego maska segmentacji wygenerowana przez pracowników Mechanical Turk (0_2022-02-10T17:41:04.724225.png). Zauważ, że indeks maski jest inny niż numer w nazwie obrazu źródłowego.
 |
 |
Manifest wyjściowy z zadania etykietowania znajduje się w /manifests/output/output.manifest plik. Jest to plik JSON, a każdy wiersz rejestruje mapowanie między obrazem źródłowym a jego etykietą i innymi metadanymi. Poniższy wiersz JSON rejestruje mapowanie między pokazanym obrazem źródłowym a jego adnotacją:
Obraz źródłowy nazywa się Image_1.jpg, a nazwa adnotacji to 0_2022-02-10T17:41: 04.724225.png. Aby przygotować dane jako wymagane formaty kanałów danych algorytmu segmentacji semantycznej SageMaker, musimy zmienić nazwę adnotacji tak, aby miała taką samą nazwę jak źródłowe obrazy JPG. Musimy też podzielić zbiór danych na train i validation katalogi dla obrazów źródłowych i adnotacji.
Przekształć dane wyjściowe z zadania etykietowania Ground Truth na żądany format wejściowy
Aby przekształcić dane wyjściowe, wykonaj następujące czynności:
- Pobierz wszystkie pliki z zadania etykietowania z Amazon S3 do katalogu lokalnego:
- Przeczytaj plik manifestu i zmień nazwy adnotacji na takie same, jak w przypadku obrazów źródłowych:
- Podziel zestawy danych pociągu i walidacji:
- Utwórz katalog w wymaganym formacie dla kanałów danych algorytmu segmentacji semantycznej:
- Przenieś obrazy pociągu i walidacji oraz ich adnotacje do utworzonych katalogów.
- W przypadku obrazów użyj następującego kodu:
- W przypadku adnotacji użyj następującego kodu:
- Prześlij zestawy danych pociągów i walidacji oraz ich zestawy danych adnotacji do Amazon S3:
Trening modelu segmentacji semantycznej SageMaker
W tej sekcji omówimy etapy szkolenia modelu segmentacji semantycznej.
Postępuj zgodnie z przykładowym notatnikiem i skonfiguruj kanały danych
Możesz postępować zgodnie z instrukcjami w Algorytm segmentacji semantycznej jest teraz dostępny w Amazon SageMaker aby zaimplementować algorytm segmentacji semantycznej w oznaczonym zbiorze danych. Ta próbka notatnik pokazuje kompletny przykład wprowadzający algorytm. W zeszycie dowiesz się, jak trenować i hostować model segmentacji semantycznej przy użyciu w pełni splotowej sieci (FCN) algorytm wykorzystujący Zbiór danych Pascal VOC na trening. Ponieważ nie planuję trenować modelu z zestawu danych Pascal VOC, pominąłem krok 3 (przygotowanie danych) w tym notatniku. Zamiast tego stworzyłem bezpośrednio train_channel, train_annotation_channe, validation_channel, validation_annotation_channel przy użyciu lokalizacji S3, w których przechowywałem moje obrazy i adnotacje:
Dostosuj hiperparametry do własnego zestawu danych w estymatorze SageMaker
Śledziłem notatnik i utworzyłem obiekt estymatora SageMaker (ss_estimator) do trenowania mojego algorytmu segmentacji. Jedną z rzeczy, które musimy dostosować do nowego zestawu danych, jest ss_estimator.set_hyperparameters: musimy się zmienić num_classes=21 do num_classes=2 (turtle i background) i ja też się zmieniłam epochs=10 do epochs=30 ponieważ 10 służy tylko do celów demonstracyjnych. Następnie użyłem instancji p3.2xlarge do trenowania modelu poprzez ustawienie instance_type="ml.p3.2xlarge". Szkolenie ukończone w 8 minut. Najlepsze MIoU (Mean Intersection over Union) 0.846 osiąga się w epoce 11 z a pix_acc (odsetek pikseli w obrazie, które są prawidłowo sklasyfikowane) 0.925, co jest całkiem dobrym wynikiem dla tego małego zbioru danych.
Wyniki wnioskowania modelowego
Hostowałem model na taniej instancji ml.c5.xlarge:
Na koniec przygotowałem zestaw testowy 10 obrazów żółwi, aby zobaczyć wynik wnioskowania wytrenowanego modelu segmentacji:
Poniższe obrazy przedstawiają wyniki.

Maski segmentacyjne żółwi morskich wyglądają dokładnie i jestem zadowolony z tego wyniku przeszkolonego na 300-obrazowym zbiorze danych oznaczonym przez pracowników Mechanical Turk. Możesz także zapoznać się z innymi dostępnymi sieciami, takimi jak sieć analizująca sceny piramidowe (PSP) or DeepLab-V3 w przykładowym notesie z zestawem danych.
Sprzątać
Po zakończeniu usuń punkt końcowy, aby uniknąć ponoszenia dalszych kosztów:
Wnioski
W tym poście pokazałem, jak dostosować etykietowanie danych segmentacji semantycznej i trenowanie modeli za pomocą SageMaker. Po pierwsze, możesz skonfigurować zadanie etykietowania za pomocą narzędzia do automatycznej segmentacji lub użyć siły roboczej Mechanical Turk (a także innych opcji). Jeśli masz więcej niż 5,000 obiektów, możesz również użyć automatycznego oznaczania danych. Następnie przekształcasz dane wyjściowe z zadania etykietowania Ground Truth na wymagane formaty wejściowe dla wbudowanego szkolenia segmentacji semantycznej SageMaker. Następnie możesz użyć instancji przyspieszonego przetwarzania (takiej jak p2 lub p3), aby wytrenować model segmentacji semantycznej z następującymi notatnik i wdróż model w bardziej opłacalnym wystąpieniu (takim jak ml.c5.xlarge). Na koniec możesz przejrzeć wyniki wnioskowania w testowym zestawie danych za pomocą kilku wierszy kodu.
Zacznij korzystać z segmentacji semantycznej SageMaker etykietowanie danych i model szkolenia z Twoim ulubionym zbiorem danych!
O autorze
 Kary Yang jest analitykiem danych w AWS Professional Services. Jej pasją jest pomaganie klientom w osiąganiu ich celów biznesowych dzięki usługom chmurowym AWS. Pomogła organizacjom w tworzeniu rozwiązań ML w wielu branżach, takich jak produkcja, motoryzacja, zrównoważony rozwój środowiska i lotnictwo.
Kary Yang jest analitykiem danych w AWS Professional Services. Jej pasją jest pomaganie klientom w osiąganiu ich celów biznesowych dzięki usługom chmurowym AWS. Pomogła organizacjom w tworzeniu rozwiązań ML w wielu branżach, takich jak produkcja, motoryzacja, zrównoważony rozwój środowiska i lotnictwo.
- Coinsmart. Najlepsza w Europie giełda bitcoinów i kryptowalut.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. DARMOWY DOSTĘP.
- CryptoJastrząb. Radar Altcoin. Bezpłatna wersja próbna.
- Źródło: https://aws.amazon.com/blogs/machine-learning/semantic-segmentation-data-labeling-and-model-training-using-amazon-sagemaker/
- '
- "
- 000
- 10
- 100
- 11
- 2019
- a
- O nas
- przyśpieszyć
- przyśpieszony
- dokładny
- Osiągać
- osiągnięty
- w poprzek
- w dodatku
- Lotnictwo
- algorytm
- Algorytmy
- Wszystkie kategorie
- Amazonka
- ogłosił
- Inne
- na około
- Współpracownik
- zautomatyzowane
- automatycznie
- motoryzacyjny
- dostępny
- AWS
- tło
- bo
- BEST
- Ulepsz Swój
- pomiędzy
- budować
- wbudowany
- biznes
- zdobyć
- walizka
- pewien
- zmiana
- kanały
- Dodaj
- klasa
- Klasy
- sklasyfikowany
- Chmura
- usługi w chmurze
- kod
- wspólny
- konkurencja
- kompletny
- komputer
- komputery
- computing
- pewność siebie
- Konsola
- zawartość
- wygoda
- Odpowiedni
- opłacalne
- Koszty:
- Stwórz
- stworzony
- Klientów
- dostosować
- dane
- naukowiec danych
- głęboko
- wykazać
- rozwijać
- różne
- bezpośrednio
- rysunek
- podczas
- każdy
- Umożliwia
- koniec końców
- Punkt końcowy
- Wchodzę
- środowiskowy
- ustanowiony
- przykład
- Z wyjątkiem
- spodziewany
- oczekuje
- odkryj
- skrajny
- Twarz
- Cecha
- i terminów, a
- obserwuj
- następujący
- format
- od
- wygenerowane
- Gole
- dobry
- szary
- wspaniały
- Zaoszczędzić
- pomógł
- pomoc
- pomaga
- wysokiej jakości
- hostowane
- W jaki sposób
- How To
- HTTPS
- człowiek
- Ludzie
- Setki
- obraz
- zdjęcia
- wdrożenia
- podnieść
- zawierać
- włączony
- Zwiększać
- wskaźnik
- przemysłowa
- Informacja
- wkład
- przykład
- Interfejs
- skrzyżowanie
- wprowadzenie
- IT
- Praca
- Oferty pracy
- znany
- Etykieta
- etykietowanie
- Etykiety
- duży
- uruchomić
- UCZYĆ SIĘ
- nauka
- poziom
- Ograniczony
- Linia
- linie
- Lista
- miejscowy
- lokalizacja
- lokalizacji
- długo
- Popatrz
- maszyna
- uczenie maszynowe
- zarządzanie
- obowiązkowe
- ręcznie
- produkcja
- mapa
- mapowanie
- maska
- Maski
- masywny
- mechaniczny
- może
- ML
- model
- modele
- jeszcze
- wielokrotność
- Nazwy
- nazywania
- Nawigacja
- sieć
- sieci
- Następny
- notatnik
- numer
- Oferty
- Option
- Opcje
- organizacji
- Inne
- własny
- namiętny
- procent
- wykonywania
- zwrotnica
- Wielokąt
- Popularny
- Przygotować
- bardzo
- Cena
- prywatny
- wygląda tak
- produkować
- profesjonalny
- zapewniać
- zapewnia
- publiczny
- cele
- szybko
- RE
- dokumentacja
- reprezentować
- wymagany
- Wymaga
- Efekt
- przeglądu
- taki sam
- skalowalny
- Naukowiec
- SEA
- segmentacja
- wybrany
- usługa
- Usługi
- zestaw
- ustawienie
- Share
- pokazać
- pokazane
- Prosty
- sytuacja
- mały
- So
- Tworzenie
- Rozwiązania
- dzielić
- rozpoczęty
- przechowywanie
- Zrównoważony rozwój
- cel
- zadania
- zespół
- test
- Połączenia
- Źródło
- rzecz
- innych firm
- tysiące
- Przez
- wydajność
- czas
- narzędzie
- Pociąg
- Trening
- Przekształcać
- unia
- posługiwać się
- uprawomocnienie
- sprzedawców
- wizja
- KIM
- Praca
- pracowników
- Siła robocza
- działa
- Twój