To drugi post z dwuczęściowej serii, w której proponuję praktyczny przewodnik dla organizacji, dzięki któremu możesz ocenić jakość modeli podsumowań tekstowych dla swojej domeny.
Aby zapoznać się z wprowadzeniem do podsumowania tekstu, omówieniem tego samouczka oraz czynnościami tworzenia planu bazowego dla naszego projektu (określanego również jako sekcja 1), wróć do pierwszy post.
Ten post jest podzielony na trzy sekcje:
- Sekcja 2: Generowanie podsumowań za pomocą modelu zerowego
- Sekcja 3: Trenuj model podsumowujący
- Sekcja 4: Ocena wytrenowanego modelu
Sekcja 2: Generowanie podsumowań za pomocą modelu zerowego
W tym poście używamy pojęcia nauka zero-shot (ZSL), co oznacza, że używamy modelu, który został przeszkolony do podsumowywania tekstu, ale nie widzieliśmy żadnych przykładów zbiór danych arXiv. To trochę tak, jak malowanie portretu, kiedy jedyne, co robiłeś w swoim życiu, to malowanie pejzaży. Wiesz, jak malować, ale możesz nie być zaznajomiony z zawiłościami malarstwa portretowego.
W tej sekcji używamy następujących notatnik.
Dlaczego uczenie się od zera?
ZSL stał się popularny w ciągu ostatnich lat, ponieważ umożliwia korzystanie z najnowocześniejszych modeli NLP bez szkolenia. A ich wydajność bywa wręcz zdumiewająca: Grupa Robocza ds. Badań nad Wielką Nauką niedawno wydali swój model T0pp (wymawiane „T Zero Plus Plus”), który został przeszkolony specjalnie do badania uczenia się wielozadaniowości typu zero-shot. Często może przewyższać modele sześciokrotnie większe na Ławka DUŻA benchmark i może przewyższyć te GPT-3 (16 razy większy) w kilku innych testach NLP.
Kolejną zaletą ZSL jest to, że do jego użycia potrzebne są tylko dwa wiersze kodu. Wypróbowując to, tworzymy drugą linię bazową, której używamy do ilościowego określenia wzrostu wydajności modelu po dostrojeniu modelu w naszym zestawie danych.
Skonfiguruj proces uczenia się zero-shot
Aby korzystać z modeli ZSL, możemy użyć Hugging Face API potoku. Ten interfejs API umożliwia nam korzystanie z modelu podsumowania tekstu z zaledwie dwoma wierszami kodu. Zajmuje się głównymi etapami przetwarzania w modelu NLP:
- Wstępnie przetwórz tekst do formatu zrozumiałego dla modelu.
- Przekaż wstępnie przetworzone dane wejściowe do modelu.
- Przetwarzaj wstępnie prognozy modelu, aby nadać im sens.
Wykorzystuje modele podsumowań, które są już dostępne na Przytulanie piasty modelu twarzy.
Aby z niego skorzystać, uruchom następujący kod:
Otóż to! Kod pobiera model podsumowania i tworzy podsumowania lokalnie na komputerze. Jeśli zastanawiasz się, jakiego modelu używa, możesz to sprawdzić w Kod źródłowy lub użyj następującego polecenia:
Po uruchomieniu tego polecenia widzimy, że domyślny model podsumowania tekstu nazywa się sshleifer/distilbart-cnn-12-6:
![]()
Możemy znaleźć karta modelu dla tego modelu na stronie Hugging Face, gdzie możemy również zobaczyć, że model został wytrenowany na dwóch zestawach danych: Zbiór danych CNN Dailymail oraz Zestaw danych ekstremalnych podsumowań (XSum). Warto zauważyć, że ten model nie jest zaznajomiony z zestawem danych arXiv i jest używany tylko do podsumowywania tekstów, które są podobne do tych, na których był szkolony (głównie artykuły z wiadomościami). Liczby 12 i 6 w nazwie modelu odnoszą się odpowiednio do liczby warstw kodera i warstw dekodera. Wyjaśnienie, co to jest, wykracza poza zakres tego samouczka, ale możesz przeczytać więcej na ten temat w poście Przedstawiamy BART autorstwa Sama Shleifera, który stworzył model.
W przyszłości używamy domyślnego modelu, ale zachęcam do wypróbowania różnych wstępnie wytrenowanych modeli. Wszystkie modele nadające się do podsumowania można znaleźć na stronie Witryna Hugging Face. Aby użyć innego modelu, możesz określić nazwę modelu podczas wywoływania interfejsu Pipeline API:
Podsumowanie ekstrakcyjne a abstrakcyjne
Nie rozmawialiśmy jeszcze o dwóch możliwych, ale różnych podejściach do podsumowania tekstu: ekstraktowy vs abstrahujący. Podsumowanie ekstrakcyjne to strategia łączenia fragmentów tekstu zaczerpniętych z tekstu w streszczenie, podczas gdy podsumowanie abstrakcyjne polega na parafrazowaniu korpusu za pomocą nowych zdań. Większość modeli podsumowań opiera się na modelach generujących nowy tekst (są to modele generowania języka naturalnego, takie jak na przykład GPT-3). Oznacza to, że modele podsumowań generują również nowy tekst, co czyni je abstrakcyjnymi modelami podsumowania.
Generuj podsumowania zero-shot
Teraz, gdy wiemy, jak go używać, chcemy go użyć w naszym testowym zestawie danych — tym samym zestawie danych, którego używaliśmy w sekcja 1 aby utworzyć linię bazową. Możemy to zrobić za pomocą następującej pętli:
Używamy min_length i max_length parametry do kontrolowania podsumowania generowanego przez model. W tym przykładzie ustawiamy min_length do 5, ponieważ chcemy, aby tytuł miał co najmniej pięć słów. Szacując streszczenia referencji (rzeczywiste tytuły artykułów naukowych), ustalamy, że 20 może być rozsądną wartością dla max_length. Ale znowu, to tylko pierwsza próba. Gdy projekt jest w fazie eksperymentów, te dwa parametry można i należy zmienić, aby sprawdzić, czy zmienia się wydajność modelu.
Dodatkowe parametry
Jeśli znasz już generowanie tekstu, możesz wiedzieć, że istnieje wiele innych parametrów wpływających na tekst generowany przez model, takich jak wyszukiwanie wiązki, próbkowanie i temperatura. Te parametry zapewniają większą kontrolę nad generowanym tekstem, na przykład sprawiają, że tekst jest bardziej płynny i mniej powtarzalny. Techniki te nie są dostępne w interfejsie Pipeline API — możesz zobaczyć w Kod źródłowy że min_length i max_length są jedynymi parametrami, które są brane pod uwagę. Jednak po przeszkoleniu i wdrożeniu własnego modelu mamy dostęp do tych parametrów. Więcej na ten temat w sekcji 4 tego postu.
Ocena modelu
Po wygenerowaniu podsumowań zerowych możemy ponownie użyć naszej funkcji ROUGE, aby porównać podsumowania kandydatów z podsumowaniami referencyjnymi:
Uruchomienie tego obliczenia na podsumowaniach, które zostały wygenerowane za pomocą modelu ZSL, daje nam następujące wyniki:
![]()
Porównując je z naszym punktem odniesienia, widzimy, że ten model ZSL w rzeczywistości działa gorzej niż nasza prosta heurystyka polegająca na wzięciu tylko pierwszego zdania. Znowu nie jest to nieoczekiwane: chociaż ten model wie, jak podsumowywać artykuły prasowe, nigdy nie spotkał się z przykładem podsumowania abstraktu naukowego artykułu badawczego.
Porównanie linii bazowej
Stworzyliśmy teraz dwie linie bazowe: jedną przy użyciu prostej heurystyki, a drugą z modelem ZSL. Porównując wyniki ROUGE, widzimy, że prosta heurystyka obecnie przewyższa model uczenia głębokiego.
![]()
W następnej sekcji wykorzystamy ten sam model głębokiego uczenia się i spróbujemy poprawić jego wydajność. Robimy to, trenując go na zbiorze danych arXiv (ten krok jest również nazywany strojenie). Korzystamy z tego, że już wie, jak ogólnie streszczać tekst. Następnie pokazujemy mu wiele przykładów naszego zestawu danych arXiv. Modele uczenia głębokiego są wyjątkowo dobre w identyfikowaniu wzorców w zestawach danych po ich przeszkoleniu, więc oczekujemy, że model będzie lepszy w tym konkretnym zadaniu.
Sekcja 3: Trenuj model podsumowujący
W tej sekcji trenujemy model, którego używaliśmy do podsumowań zerowych w sekcji 2 (sshleifer/distilbart-cnn-12-6) w naszym zbiorze danych. Chodzi o to, aby nauczyć modela, jak wyglądają streszczenia streszczeń prac naukowych, pokazując mu wiele przykładów. Z biegiem czasu model powinien rozpoznawać wzorce w tym zbiorze danych, co pozwoli mu tworzyć lepsze podsumowania.
Warto jeszcze raz zauważyć, że jeśli masz dane oznaczone etykietami, a mianowicie teksty i odpowiadające im podsumowania, powinieneś użyć ich do uczenia modelu. Tylko w ten sposób model może nauczyć się wzorców określonego zestawu danych.
Pełny kod do szkolenia modelu jest poniżej notatnik.
Ustaw pracę szkoleniową
Ponieważ trenowanie modelu uczenia głębokiego na laptopie zajęłoby kilka tygodni, używamy Amazon Sage Maker zamiast tego szkolenia. Aby uzyskać więcej informacji, zobacz Trenuj model z Amazon SageMaker. W tym poście pokrótce podkreślam zalety korzystania z tych zadań szkoleniowych, poza tym, że pozwalają nam korzystać z instancji obliczeniowych GPU.
Załóżmy, że mamy klaster instancji GPU, których możemy użyć. W takim przypadku prawdopodobnie chcemy utworzyć obraz Dockera, aby uruchomić szkolenie, abyśmy mogli łatwo replikować środowisko szkoleniowe na innych komputerach. Następnie instalujemy wymagane pakiety, a ponieważ chcemy korzystać z kilku instancji, musimy również skonfigurować szkolenia rozproszone. Po zakończeniu szkolenia chcemy szybko wyłączyć te komputery, ponieważ są one kosztowne.
Wszystkie te kroki są od nas abstrahowane podczas korzystania z zadań szkoleniowych. W rzeczywistości możemy trenować model w taki sam sposób, jak opisano, określając parametry uczenia, a następnie wywołując tylko jedną metodę. SageMaker zajmuje się resztą, w tym zatrzymywaniem instancji GPU po zakończeniu szkolenia, aby nie ponosić żadnych dalszych kosztów.
Ponadto Hugging Face i AWS ogłosiły partnerstwo na początku 2022 r., które jeszcze bardziej ułatwia trenowanie modeli Hugging Face w programie SageMaker. Ta funkcja jest dostępna dzięki opracowaniu Hugging Face Kontenery AWS Deep Learning (DLC). Kontenery te obejmują Transformatory Hugging Face, Tokenizery i bibliotekę Datasets, która pozwala nam używać tych zasobów do zadań szkoleniowych i wnioskowania. Aby uzyskać listę dostępnych obrazów DLC, zobacz dostępne Przytulanie twarzy do głębokiego uczenia się Obrazy kontenerów. Są utrzymywane i regularnie aktualizowane za pomocą poprawek bezpieczeństwa. Możemy znaleźć wiele przykładów, jak trenować modele Hugging Face za pomocą tych DLC i Przytulanie Face Pythona SDK w następującym GitHub repo.
Używamy jednego z tych przykładów jako szablonu, ponieważ robi prawie wszystko, czego potrzebujemy do naszego celu: wytrenuj model podsumowujący na określonym zestawie danych w sposób rozproszony (przy użyciu więcej niż jednej instancji GPU).
Jedną rzeczą, którą musimy jednak wziąć pod uwagę, jest to, że ten przykład używa zestawu danych bezpośrednio z centrum zestawów danych Hugging Face. Ponieważ chcemy podać własne, niestandardowe dane, musimy nieco poprawić notatnik.
Przekaż dane do pracy szkoleniowej
Aby uwzględnić fakt, że posiadamy własny zbiór danych, musimy użyć kanały. Aby uzyskać więcej informacji, zobacz W jaki sposób Amazon SageMaker udostępnia informacje szkoleniowe.
Osobiście uważam ten termin za nieco mylący, więc zawsze myślę mapowanie kiedy słyszę kanały, ponieważ pomaga mi lepiej wizualizować to, co się dzieje. Pozwólcie, że wyjaśnię: jak już się dowiedzieliśmy, praca szkoleniowa tworzy klaster Elastyczna chmura obliczeniowa Amazon (Amazon EC2) instancje i kopiuje na nie obraz Docker. Jednak nasze zbiory danych są przechowywane w Usługa Amazon Simple Storage (Amazon S3) i nie można uzyskać do niego dostępu za pomocą tego obrazu Docker. Zamiast tego zadanie szkoleniowe musi skopiować dane z Amazon S3 do wstępnie zdefiniowanej ścieżki lokalnie w tym obrazie platformy Docker. Sposób, w jaki to robi, polega na tym, że informujemy zadanie szkoleniowe, gdzie dane znajdują się w Amazon S3 i gdzie na obrazie Docker dane powinny zostać skopiowane, aby zadanie szkoleniowe miało do nich dostęp. My mapa lokalizacja Amazon S3 ze ścieżką lokalną.
Ustawiamy ścieżkę lokalną w sekcji hiperparametrów zadania szkoleniowego:
![]()
Następnie, wywołując metodę fit(), która rozpoczyna szkolenie, informujemy zadanie szkoleniowe, w którym znajdują się dane w Amazon S3:
![]()
Zwróć uwagę, że nazwa folderu po /opt/ml/input/data pasuje do nazwy kanału (datasets). Dzięki temu zadanie szkoleniowe może skopiować dane z Amazon S3 do ścieżki lokalnej.
Rozpocznij szkolenie
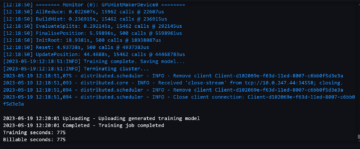
Jesteśmy teraz gotowi do rozpoczęcia pracy szkoleniowej. Jak wspomniano wcześniej, robimy to, wywołując fit() metoda. Zadanie szkoleniowe trwa około 40 minut. Możesz śledzić postępy i zobaczyć dodatkowe informacje na konsoli SageMaker.
![]()
Po zakończeniu zadania szkoleniowego nadszedł czas na ocenę naszego nowo wytrenowanego modelu.
Sekcja 4: Ocena wytrenowanego modelu
Ocena naszego wytrenowanego modelu jest bardzo podobna do tego, co zrobiliśmy w sekcji 2, gdzie ocenialiśmy model ZSL. Wywołujemy model i generujemy podsumowania kandydatów i porównujemy je z podsumowaniami referencyjnymi, obliczając wyniki ROUGE. Ale teraz model znajduje się w Amazon S3 w pliku o nazwie model.tar.gz (aby znaleźć dokładną lokalizację, możesz sprawdzić zadanie szkoleniowe na konsoli). Jak więc uzyskać dostęp do modelu w celu wygenerowania podsumowań?
Mamy dwie opcje: wdrożyć model w punkcie końcowym SageMaker lub pobrać go lokalnie, podobnie jak w sekcji 2 z modelem ZSL. W tym samouczku ja wdrożyć model w punkcie końcowym SageMaker ponieważ jest to wygodniejsze i wybierając mocniejszą instancję dla punktu końcowego, możemy znacznie skrócić czas wnioskowania. Repozytorium GitHub zawiera notatnik który pokazuje, jak ocenić model lokalnie.
Wdróż model
Zwykle bardzo łatwo jest wdrożyć wyszkolony model w SageMaker (zobacz ponownie następujący przykład na GitHub z Przytulanie twarzy). Po przeszkoleniu modelu możemy zadzwonić estimator.deploy() a SageMaker robi resztę za nas w tle. Ponieważ w naszym samouczku przełączamy się z jednego notatnika do drugiego, musimy najpierw zlokalizować zadanie szkoleniowe i powiązany model, zanim będziemy mogli je wdrożyć:
![]()
Po pobraniu lokalizacji modelu możemy wdrożyć go w punkcie końcowym SageMaker:
Wdrożenie w programie SageMaker jest proste, ponieważ wykorzystuje on Zestaw narzędzi do wnioskowania o przytulaniu twarzy SageMaker, biblioteka typu open source do obsługi modeli Transformers w programie SageMaker. Zwykle nie musimy nawet dostarczać skryptu wnioskowania; zestaw narzędzi zajmuje się tym. W takim przypadku jednak zestaw narzędzi ponownie korzysta z interfejsu Pipeline API i, jak omówiliśmy w sekcji 2, interfejs Pipeline API nie pozwala nam korzystać z zaawansowanych technik generowania tekstu, takich jak wyszukiwanie wiązki i próbkowanie. Aby uniknąć tego ograniczenia, zapewniamy nasze niestandardowy skrypt wnioskowania.
Pierwsza ocena
Do pierwszej oceny naszego nowo wytrenowanego modelu używamy tych samych parametrów, co w sekcji 2 z modelem zerowym, aby wygenerować podsumowania kandydatów. Pozwala to na porównanie jabłek do jabłek:
Porównujemy podsumowania generowane przez model z podsumowaniami referencyjnymi:
![]()
To zachęcające! Nasza pierwsza próba trenowania modelu, bez strojenia hiperparametrów, znacząco poprawiła wyniki ROUGE.
![]()
Druga ocena
Teraz nadszedł czas na użycie bardziej zaawansowanych technik, takich jak wyszukiwanie wiązki i próbkowanie, aby poeksperymentować z modelem. Aby uzyskać szczegółowe wyjaśnienie, co robi każdy z tych parametrów, zobacz Jak generować tekst: przy użyciu różnych metod dekodowania do generowania języka za pomocą Transformers. Wypróbujmy to z półlosowym zestawem wartości dla niektórych z tych parametrów:
Uruchamiając nasz model z tymi parametrami, otrzymujemy następujące wyniki:
![]()
To nie wyszło tak, jak się spodziewaliśmy — wyniki ROUGE w rzeczywistości nieznacznie spadły. Nie pozwól jednak, aby zniechęciło to do wypróbowania różnych wartości tych parametrów. W rzeczywistości jest to punkt, w którym kończymy fazę konfiguracji i przechodzimy do fazy eksperymentów projektu.
Podsumowanie i kolejne kroki
Zakończyliśmy przygotowania do fazy eksperymentów. W tej dwuczęściowej serii pobraliśmy i przygotowaliśmy nasze dane, stworzyliśmy linię bazową za pomocą prostej heurystyki, stworzyliśmy kolejną linię bazową przy użyciu uczenia zerowego, a następnie wytrenowaliśmy nasz model i zauważyliśmy znaczny wzrost wydajności. Teraz nadszedł czas, aby pobawić się każdą częścią, którą stworzyliśmy, aby stworzyć jeszcze lepsze podsumowania. Rozważ następujące:
- Wstępnie przetwarzaj dane prawidłowo – Na przykład usuń przerywniki i znaki interpunkcyjne. Nie lekceważ tej części — w wielu projektach dotyczących analizy danych wstępne przetwarzanie danych jest jednym z najważniejszych aspektów (jeśli nie najważniejszym), a naukowcy zajmujący się danymi zwykle spędzają większość czasu na tym zadaniu.
- Wypróbuj różne modele – W naszym tutorialu wykorzystaliśmy standardowy model do podsumowania (
sshleifer/distilbart-cnn-12-6), ale wiele więcej modeli są dostępne, których możesz użyć do tego zadania. Jeden z nich może lepiej pasować do twojego przypadku użycia. - Wykonaj strojenie hiperparametrów – Podczas uczenia modelu wykorzystaliśmy pewien zestaw hiperparametrów (szybkość uczenia się, liczba epok itd.). Te parametry nie są ustalone w kamieniu — wręcz przeciwnie. Należy zmienić te parametry, aby zrozumieć, w jaki sposób wpływają one na wydajność modelu.
- Użyj różnych parametrów do generowania tekstu – Zrobiliśmy już jedną rundę tworzenia podsumowań z różnymi parametrami, aby wykorzystać wyszukiwanie wiązki i próbkowanie. Wypróbuj różne wartości i parametry. Aby uzyskać więcej informacji, zobacz Jak generować tekst: przy użyciu różnych metod dekodowania do generowania języka za pomocą Transformers.
Mam nadzieję, że dotarłeś do końca i ten samouczek okazał się przydatny.
O autorze
![]() Heiko Hotza jest starszym architektem rozwiązań w zakresie sztucznej inteligencji i uczenia maszynowego oraz kieruje społecznością przetwarzania języka naturalnego (NLP) w ramach AWS. Przed objęciem tego stanowiska był szefem Data Science w dziale obsługi klienta Amazon w UE. Heiko pomaga naszym klientom odnieść sukces w ich podróży AI/ML w AWS i współpracował z organizacjami z wielu branż, w tym ubezpieczeń, usług finansowych, mediów i rozrywki, opieki zdrowotnej, mediów i produkcji. W wolnym czasie Heiko jak najwięcej podróżuje.
Heiko Hotza jest starszym architektem rozwiązań w zakresie sztucznej inteligencji i uczenia maszynowego oraz kieruje społecznością przetwarzania języka naturalnego (NLP) w ramach AWS. Przed objęciem tego stanowiska był szefem Data Science w dziale obsługi klienta Amazon w UE. Heiko pomaga naszym klientom odnieść sukces w ich podróży AI/ML w AWS i współpracował z organizacjami z wielu branż, w tym ubezpieczeń, usług finansowych, mediów i rozrywki, opieki zdrowotnej, mediów i produkcji. W wolnym czasie Heiko jak najwięcej podróżuje.
- Coinsmart. Najlepsza w Europie giełda bitcoinów i kryptowalut.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. DARMOWY DOSTĘP.
- CryptoJastrząb. Radar Altcoin. Bezpłatna wersja próbna.
- Źródło: https://aws.amazon.com/blogs/machine-learning/part-2-set-up-a-text-summarization-project-with-hugging-face-transformers/
- "
- &
- 100
- 2022
- 7
- 84
- 9
- O nas
- ABSTRACT
- dostęp
- Konto
- dodatek
- Dodatkowy
- zaawansowany
- Korzyść
- AI
- Wszystkie kategorie
- już
- Chociaż
- Amazonka
- ogłosił
- Inne
- api
- na około
- towary
- dostępny
- AWS
- tło
- Baseline
- Belka
- stają się
- jest
- Benchmark
- korzyści
- Bit
- wezwanie
- który
- zmiana
- kod
- społeczność
- obliczać
- komputery
- pojęcie
- Konsola
- Pojemniki
- zawiera
- kontrola
- Wygodny
- Koszty:
- mógłby
- tworzy
- Tworzenie
- zwyczaj
- Obsługa klienta
- Klientów
- dane
- nauka danych
- rozwijać
- oprogramowania
- ZROBIŁ
- różne
- dystrybuowane
- Doker
- Nie
- domena
- na dół
- pliki do pobrania
- z łatwością
- zachęcać
- Punkt końcowy
- rozrywka
- Środowisko
- EU
- wszystko
- przykład
- oczekiwać
- Wyciągi
- Twarz
- budżetowy
- usługi finansowe
- i terminów, a
- dopasować
- obserwuj
- następujący
- format
- Naprzód
- znaleziono
- funkcjonować
- Funkcjonalność
- dalej
- Ogólne
- Generować
- generacja
- GitHub
- będzie
- dobry
- GPU
- poprowadzi
- głowa
- opieki zdrowotnej
- pomaga
- Atrakcja
- W jaki sposób
- How To
- HTTPS
- pomysł
- identyfikacja
- obraz
- ważny
- podnieść
- zawierać
- Włącznie z
- Zwiększać
- przemysłowa
- wpływ
- Informacja
- zainstalować
- ubezpieczenie
- zawiłości
- IT
- Praca
- Oferty pracy
- Klawisz
- krajobraz
- język
- laptopa
- większe
- Wyprowadzenia
- UCZYĆ SIĘ
- dowiedziałem
- nauka
- Biblioteka
- Lista
- miejscowy
- lokalnie
- lokalizacja
- długo
- maszyna
- uczenie maszynowe
- maszyny
- WYKONUJE
- produkcja
- Media
- nic
- ML
- model
- modele
- jeszcze
- większość
- mianowicie
- Naturalny
- aktualności
- notatnik
- numer
- z naszej
- Opcje
- zamówienie
- organizacji
- Inne
- Papier
- Współpraca
- Łatki
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- faza
- Grać
- punkt
- Popularny
- możliwy
- mocny
- Przewidywania
- projekt
- projektowanie
- zaproponować
- zapewniać
- zapewnia
- cel
- jakość
- szybko
- rozsądny
- rozpoznać
- wymagany
- Badania naukowe
- Zasoby
- REST
- Efekt
- okrągły
- run
- bieganie
- nauka
- Naukowcy
- Szukaj
- bezpieczeństwo
- rozsądek
- Serie
- usługa
- Usługi
- służąc
- zestaw
- znaczący
- podobny
- Prosty
- SIX
- So
- Rozwiązania
- swoiście
- wydać
- początek
- rozpocznie
- state-of-the-art
- przechowywanie
- Strategia
- udany
- Przełącznik
- Techniki
- test
- Przez
- czas
- Tytuł
- Trening
- zazwyczaj
- zrozumieć
- us
- posługiwać się
- zazwyczaj
- wykorzystać
- wartość
- Strona internetowa
- Co
- KIM
- Wikipedia
- w ciągu
- bez
- słowa
- Praca
- odrobić
- pracował
- wartość
- lat
- zero