Góra lodowa Apache to format otwartej tabeli dla bardzo dużych analitycznych zestawów danych, który przechwytuje metadane dotyczące stanu zestawów danych w miarę ich ewolucji i zmian w czasie. Dodaje tabele do silników obliczeniowych, w tym Spark, Trino, PrestoDB, Flink i Hive, używając wysokowydajnego formatu tabeli, który działa podobnie jak tabela SQL. Iceberg stał się bardzo popularny dzięki obsłudze transakcji ACID w jeziorach danych oraz funkcjom takim jak ewolucja schematu i partycji, podróże w czasie i wycofywanie zmian.
Integracja Apache Iceberg jest obsługiwana przez usługi analityczne AWS, w tym Amazon EMR, Amazonka Atena, Klej AWS. Amazon EMR może dostarczać klastry z Spark, Hive, Trino i Flink, które mogą obsługiwać Iceberg. Począwszy od wersji Amazon EMR 6.5.0, możesz użyj Iceberg z klastrem EMR bez konieczności wykonywania akcji bootstrap. Na początku 2022 roku AWS ogłosił ogólną dostępność transakcji Athena ACID, obsługiwanych przez Apache Iceberg. Niedawno wydany Silnik zapytań Athena w wersji 3 zapewnia lepszą integrację z formatem tabeli Iceberg. Klej AWS 3.0 i nowsze obsługuje platformę Apache Iceberg dla jezior danych.
W tym poście omawiamy, czego klienci oczekują od nowoczesnych jezior danych i jak Apache Iceberg pomaga zaspokajać potrzeby klientów. Następnie przechodzimy przez rozwiązanie umożliwiające zbudowanie wysokowydajnego i ewoluującego jeziora danych Iceberg Usługa Amazon Simple Storage (Amazon S3) i przetwarzaj dane przyrostowe, uruchamiając instrukcje SQL wstawiania, aktualizowania i usuwania. Na koniec pokazujemy, jak dostosować wydajność procesu, aby poprawić wydajność odczytu i zapisu.
Jak Apache Iceberg odpowiada na potrzeby klientów w zakresie nowoczesnych jezior danych
Coraz więcej klientów buduje jeziora danych z danymi ustrukturyzowanymi i nieustrukturyzowanymi, aby wspierać wielu użytkowników, aplikacje i narzędzia analityczne. Istnieje zwiększone zapotrzebowanie na jeziora danych obsługujące takie funkcje jak bazy danych, takie jak transakcje ACID, aktualizacje i usuwanie rekordów, podróże w czasie i wycofywanie zmian. Apache Iceberg został zaprojektowany do obsługi tych funkcji w ekonomicznych jeziorach danych w skali petabajtów na Amazon S3.
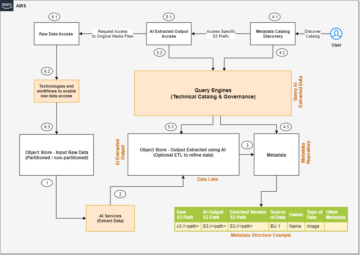
Apache Iceberg odpowiada na potrzeby klientów, przechwytując bogate metadane dotyczące zestawu danych w momencie tworzenia poszczególnych plików danych. Istnieją trzy warstwy w architekturze tabeli Iceberg: katalog Iceberg, warstwa metadanych i warstwa danych, jak pokazano na poniższym rysunku (źródło).

Katalog Iceberg przechowuje wskaźnik metadanych do pliku metadanych bieżącej tabeli. Gdy zapytanie wybierające odczytuje tabelę Iceberg, aparat zapytań najpierw przechodzi do katalogu Iceberg, a następnie pobiera lokalizację bieżącego pliku metadanych. Za każdym razem, gdy następuje aktualizacja tabeli Iceberg, tworzona jest nowa migawka tabeli, a wskaźnik metadanych wskazuje bieżący plik metadanych tabeli.
Poniżej znajduje się przykładowy katalog Iceberg z implementacją AWS Glue. Możesz zobaczyć nazwę bazy danych, lokalizację (ścieżkę S3) tabeli Iceberg oraz lokalizację metadanych.

Warstwa metadanych ma trzy typy plików: plik metadanych, listę manifestów i plik manifestu w hierarchii. Na szczycie hierarchii znajduje się plik metadanych, w którym przechowywane są informacje o schemacie tabeli, informacje o partycjach i migawki. Migawka wskazuje na listę manifestu. Lista manifestów zawiera informacje o każdym pliku manifestu, który tworzy migawkę, takie jak lokalizacja pliku manifestu, partycje, do których należy, oraz dolne i górne granice kolumn partycji dla plików danych, które śledzi. Plik manifestu śledzi pliki danych, a także dodatkowe szczegóły dotyczące każdego pliku, takie jak format pliku. Wszystkie trzy pliki działają w hierarchii, aby śledzić migawki, schematy, partycjonowanie, właściwości i pliki danych w tabeli Iceberg.
Warstwa danych zawiera poszczególne pliki danych tabeli Iceberg. Iceberg obsługuje szeroką gamę formatów plików, w tym Parquet, ORC i Avro. Ponieważ tabela Iceberg śledzi poszczególne pliki danych, a nie tylko wskazuje lokalizację partycji z plikami danych, izoluje operacje zapisu od operacji odczytu. Możesz zapisać pliki danych w dowolnym momencie, ale tylko jawnie zatwierdzić zmianę, co spowoduje utworzenie nowej wersji plików migawek i metadanych.
Omówienie rozwiązania
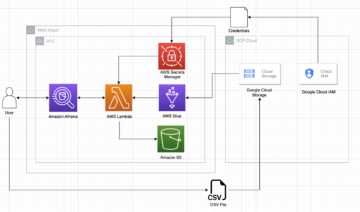
W tym poście przeprowadzimy Cię przez rozwiązanie umożliwiające zbudowanie wydajnego jeziora danych Apache Iceberg na Amazon S3; przetwarzać dane przyrostowe za pomocą instrukcji SQL wstawiania, aktualizowania i usuwania; i dostosuj tabelę Iceberg, aby poprawić wydajność odczytu i zapisu. Poniższy diagram ilustruje architekturę rozwiązania.

Aby zademonstrować to rozwiązanie, używamy Recenzje klientów Amazon zestaw danych w zasobniku S3 (s3://amazon-reviews-pds/parquet/). W rzeczywistym przypadku byłyby to surowe dane przechowywane w wiaderku S3. Możemy sprawdzić rozmiar danych za pomocą następującego kodu w pliku Interfejs wiersza poleceń AWS (CLI AWS):
Całkowita liczba obiektów to 430, a całkowity rozmiar to 47.4 GiB.
Aby skonfigurować i przetestować to rozwiązanie, wykonujemy następujące ogólne kroki:
- Skonfiguruj wiadro S3 w strefie nadzorowanej, aby przechowywać przekonwertowane dane w formacie tabeli Iceberg.
- Uruchom klaster EMR z odpowiednimi konfiguracjami dla Apache Iceberg.
- Utwórz notatnik w EMR Studio.
- Skonfiguruj sesję Spark dla Apache Iceberg.
- Konwertuj dane do formatu tabeli Iceberg i przenieś dane do wybranej strefy.
- Uruchamiaj zapytania wstawiania, aktualizowania i usuwania w Athenie, aby przetwarzać dane przyrostowe.
- Przeprowadź strojenie wydajności.
Wymagania wstępne
Aby postępować zgodnie z tym przewodnikiem, musisz mieć plik Konto AWS ze związkiem AWS Zarządzanie tożsamością i dostępem (IAM), która ma wystarczający dostęp do udostępniania wymaganych zasobów.
Skonfiguruj wiadro S3 dla danych Iceberg w nadzorowanej strefie w jeziorze danych
Wybierz region, w którym chcesz utworzyć zasobnik S3 i podaj unikalną nazwę:
Uruchom klaster EMR, aby uruchamiać zadania Iceberg przy użyciu platformy Spark
Możesz utworzyć klaster EMR z Konsola zarządzania AWS, Amazon EMR CLI lub Zestaw programistyczny AWS Cloud (CDK AWS). W tym poście przeprowadzimy Cię przez proces tworzenia klastra EMR z poziomu konsoli.
- W konsoli Amazon EMR wybierz Utwórz klaster.
- Dodaj Opcje zaawansowane.
- W razie zamówieenia projektu Konfiguracja oprogramowania, wybierz najnowszą wersję Amazon EMR. Od stycznia 2023 r. najnowsza wersja to 6.9.0. Góra lodowa wymaga wersji 6.5.0 i nowszych.
- Wybierz Brama JupyterEnterprise i Iskra jako oprogramowanie do zainstalowania.
- W razie zamówieenia projektu Edytuj ustawienia oprogramowania, Wybierz Wprowadź konfigurację I wejdź
[{"classification":"iceberg-defaults","properties":{"iceberg.enabled":true}}]. - Pozostałe ustawienia pozostaw domyślne i wybierz Następna.

- W razie zamówieenia projektu sprzęt komputerowy, użyj ustawienia domyślnego.
- Dodaj Następna.
- W razie zamówieenia projektu Nazwa klastra, Wpisz imię. Używamy
iceberg-blog-cluster. - Pozostałe ustawienia pozostaw bez zmian i wybierz Następna.
- Dodaj Utwórz klaster.
Utwórz notatnik w EMR Studio
Teraz przeprowadzimy Cię przez proces tworzenia notatnika w EMR Studio z poziomu konsoli.
- Na konsoli IAM utwórz rolę usługi EMR Studio.
- W konsoli Amazon EMR wybierz Studio EM.
- Dodaj Rozpocznij.
Połączenia Rozpocznij strona pojawi się w nowej karcie.
- Dodaj Utwórz studio w nowej zakładce.
- Wpisz imię. Korzystamy ze studia Iceberg.
- Wybierz tę samą sieć VPC i podsieć, co w przypadku klastra EMR, oraz domyślną grupę zabezpieczeń.
- Dodaj Zarządzanie tożsamością i dostępem AWS (IAM) w celu uwierzytelnienia i wybierz właśnie utworzoną rolę usługi EMR Studio.
- Wybierz ścieżkę S3 dla Kopie zapasowe obszarów roboczych.
- Dodaj Utwórz studio.
- Po utworzeniu Studio wybierz adres URL dostępu do Studio.
- Na pulpicie nawigacyjnym EMR Studio wybierz Utwórz obszar roboczy.
- Wprowadź nazwę obszaru roboczego. Używamy
iceberg-workspace. - Rozszerzać Zaawansowana konfiguracja i wybierz Dołącz Workspace do klastra EMR.
- Wybierz utworzony wcześniej klaster EMR.
- Dodaj Utwórz obszar roboczy.
- Wybierz nazwę obszaru roboczego, aby otworzyć nową kartę.
W okienku nawigacji znajduje się notatnik, który ma taką samą nazwę jak Obszar roboczy. W naszym przypadku jest to góra lodowa-workspace.
- Otwórz notatnik.
- Po wyświetleniu monitu o wybranie jądra wybierz Iskra.
Skonfiguruj sesję Spark dla Apache Iceberg
Użyj poniższego kodu, podając własną nazwę zasobnika S3:
Ustawia to następujące konfiguracje sesji Spark:
- iskra.sql.katalog.demo – Rejestruje katalog Spark o nazwie demo, który wykorzystuje wtyczkę katalogu Iceberg Spark.
- spark.sql.catalog.demo.catalog-impl – Katalog demonstracyjny Spark wykorzystuje AWS Glue jako katalog fizyczny do przechowywania bazy danych Iceberg i informacji o tabelach.
- spark.sql.catalog.demo.magazyn – Katalog demonstracyjny Spark przechowuje wszystkie metadane Iceberg i pliki danych w ścieżce głównej zdefiniowanej przez tę właściwość:
s3://iceberg-curated-blog-data. - spark.sql.rozszerzenia – Dodaje obsługę rozszerzeń Iceberg Spark SQL, co pozwala na uruchamianie procedur Iceberg Spark i niektórych poleceń SQL tylko dla Iceberg (użyjesz tego w późniejszym kroku).
- spark.sql.catalog.demo.io-impl – Iceberg umożliwia użytkownikom zapisywanie danych do Amazon S3 przez S3FileIO. AWS Glue Data Catalog domyślnie używa tego FileIO, a inne katalogi mogą ładować to FileIO przy użyciu właściwości katalogu io-impl.
Konwertuj dane do formatu tabeli Iceberg
Możesz użyć Spark na Amazon EMR lub Athena, aby załadować tabelę Iceberg. W sesji Spark notatnika EMR Studio Workspace uruchom następujące polecenia, aby załadować dane:
Po uruchomieniu kodu powinieneś znaleźć dwa prefiksy utworzone w ścieżce S3 hurtowni danych (s3://iceberg-curated-blog-data/reviews.db/all_reviews): dane i metadane.
Przetwarzaj dane przyrostowe za pomocą instrukcji SQL wstawiania, aktualizowania i usuwania w Athenie
Athena to bezserwerowy mechanizm zapytań, którego można używać do wykonywania zadań związanych z odczytem, zapisem, aktualizacją i optymalizacją tabel Iceberg. Aby zademonstrować, w jaki sposób format jeziora danych Apache Iceberg obsługuje przyrostowe pozyskiwanie danych, uruchamiamy instrukcje SQL wstawiania, aktualizowania i usuwania w jeziorze danych.
Przejdź do konsoli Athena i wybierz Edytor zapytań. Jeśli używasz edytora zapytań Athena po raz pierwszy, musisz to zrobić skonfiguruj lokalizację wyniku zapytania być kubełkiem S3, który utworzyłeś wcześniej. Powinieneś być w stanie zobaczyć, że tabela review.all_reviews jest dostępna do zapytania. Uruchom następującą kwerendę, aby sprawdzić, czy tabela Iceberg została pomyślnie załadowana:
Przetwarzaj dane przyrostowe, uruchamiając instrukcje SQL wstawiania, aktualizowania i usuwania:
Podnoszenie wydajności
W tej sekcji omawiamy różne sposoby poprawy wydajności odczytu i zapisu Apache Iceberg.
Skonfiguruj właściwości tabeli Apache Iceberg
Apache Iceberg to format tabeli, który obsługuje właściwości tabeli w celu skonfigurowania zachowania tabeli, takiego jak odczyt, zapis i katalog. Możesz poprawić wydajność odczytu i zapisu w tabelach Iceberg, dostosowując właściwości tabeli.
Na przykład, jeśli zauważysz, że zapisujesz zbyt wiele małych plików dla tabeli Iceberg, możesz skonfigurować rozmiar pliku zapisu, aby zapisywać mniej plików, ale o większym rozmiarze, aby poprawić wydajność zapytań.
| Nieruchomość | Domyślnie | Opis |
| write.target-file-size-bytes | 536870912 (512 MB) | Kontroluje rozmiar plików generowanych do celu o tyle bajtów |
Użyj następującego kodu, aby zmienić format tabeli:
Partycjonowanie i sortowanie
Aby zapytanie działało szybko, im mniej danych jest odczytywanych, tym lepiej. Iceberg korzysta z bogatych metadanych przechwytywanych w czasie zapisu i ułatwia takie techniki, jak planowanie skanowania, partycjonowanie, oczyszczanie i statystyki na poziomie kolumn, takie jak wartości minimalne/maksymalne, w celu pominięcia plików danych, które nie mają pasujących rekordów. Przeprowadzimy Cię przez proces planowania skanowania zapytań i partycjonowania w Iceberg oraz w jaki sposób używamy ich do poprawy wydajności zapytań.
Planowanie skanowania zapytań
W przypadku danego zapytania pierwszym krokiem w mechanizmie zapytań jest planowanie skanowania, czyli proces znajdowania plików w tabeli potrzebnych do zapytania. Planowanie w tabeli Iceberg jest bardzo wydajne, ponieważ bogate metadane Iceberg mogą być używane do czyszczenia plików metadanych, które nie są potrzebne, oprócz filtrowania plików danych, które nie zawierają pasujących danych. W naszych testach zaobserwowaliśmy, że Athena skanowała 50% lub mniej danych dla danego zapytania w tabeli Iceberg w porównaniu z oryginalnymi danymi przed konwersją do formatu Iceberg.
Istnieją dwa rodzaje filtrowania:
- Filtrowanie metadanych – Iceberg wykorzystuje dwa poziomy metadanych do śledzenia plików w migawce: listę manifestów i pliki manifestów. Najpierw używa listy manifestów, która działa jako indeks plików manifestów. Podczas planowania Iceberg filtruje manifesty przy użyciu zakresu wartości partycji na liście manifestów bez odczytywania wszystkich plików manifestów. Następnie używa wybranych plików manifestu, aby pobrać pliki danych.
- Filtrowanie danych – Po wybraniu listy plików manifestu, Iceberg wykorzystuje dane partycji i statystyki na poziomie kolumn dla każdego pliku danych przechowywanego w plikach manifestu do filtrowania plików danych. Podczas planowania predykaty zapytania są konwertowane na predykaty dotyczące danych partycji i stosowane w pierwszej kolejności do filtrowania plików danych. Następnie statystyki kolumn, takie jak liczba wartości na poziomie kolumny, liczba wartości pustych, dolne i górne granice, są używane do odfiltrowywania plików danych, które nie pasują do predykatu zapytania. Używając górnych i dolnych granic do filtrowania plików danych w czasie planowania, Iceberg znacznie poprawia wydajność zapytań.
Partycjonowanie i sortowanie
Partycjonowanie to sposób grupowania rekordów z tymi samymi wartościami kolumn kluczy razem na piśmie. Zaletą partycjonowania są szybsze zapytania, które uzyskują dostęp tylko do części danych, jak wyjaśniono wcześniej w części dotyczącej planowania skanowania zapytań: filtrowanie danych. Iceberg upraszcza partycjonowanie, wspierając ukryte partycjonowanie, w taki sposób, w jaki Iceberg tworzy wartości partycji, pobierając wartość kolumny i opcjonalnie ją przekształcając.
W naszym przypadku użycia najpierw uruchamiamy następujące zapytanie w tabeli Iceberg, która nie jest podzielona na partycje. Następnie dzielimy tabelę Iceberg według kategorii recenzji, które zostaną użyte w warunku zapytania WHERE do odfiltrowania rekordów. W przypadku partycjonowania zapytanie może przeskanować znacznie mniej danych. Zobacz następujący kod:
Uruchom następującą instrukcję select na niepartycjonowanej tabeli all_reviews w porównaniu z tabelą partycjonowaną, aby zobaczyć różnicę w wydajności:
Poniższa tabela przedstawia poprawę wydajności partycjonowania danych, z około 50% poprawą wydajności i 70% mniejszą liczbą skanowanych danych.
| Nazwa zbioru danych | Niepartycjonowany zestaw danych | Partycjonowany zestaw danych |
| Czas działania (sekundy) | 8.20 | 4.25 |
| Zeskanowane dane (MB) | 131.55 | 33.79 |
Zwróć uwagę, że czas działania to średni czas działania z wieloma uruchomieniami w naszym teście.
Zauważyliśmy dobrą poprawę wydajności po partycjonowaniu. Można to jednak jeszcze bardziej poprawić, używając statystyk na poziomie kolumny z plików manifestu Iceberg. Aby efektywnie wykorzystywać statystyki na poziomie kolumn, chcesz dalej sortować swoje rekordy na podstawie wzorców zapytań. Sortowanie całego zestawu danych przy użyciu kolumn, które są często używane w zapytaniach, spowoduje zmianę kolejności danych w taki sposób, że każdy plik danych będzie zawierał unikatowy zakres wartości dla określonych kolumn. Jeśli te kolumny są używane w warunku zapytania, umożliwia to aparatom zapytań dalsze pomijanie plików danych, umożliwiając w ten sposób jeszcze szybsze wykonywanie zapytań.
Kopiowanie przy zapisie a odczyt przy scalaniu
Podczas wdrażania aktualizacji i usuwania w tabelach Góra lodowa w jeziorze danych istnieją dwa podejścia zdefiniowane przez właściwości tabeli Góra lodowa:
- Kopiuj przy zapisie – Przy takim podejściu, gdy w tabeli Iceberg zostaną wprowadzone zmiany, aktualizowane lub usuwane, pliki danych powiązane z rekordami, których to dotyczy, zostaną zduplikowane i zaktualizowane. Rekordy zostaną zaktualizowane lub usunięte ze zduplikowanych plików danych. Zostanie utworzony nowy zrzut tabeli Iceberg, wskazujący na nowszą wersję plików danych. To sprawia, że ogólnie zapisuje wolniej. Mogą wystąpić sytuacje, w których potrzebne są współbieżne zapisy z konfliktami, więc musi nastąpić ponowna próba, co jeszcze bardziej wydłuża czas zapisu. Z drugiej strony, podczas odczytu danych nie jest potrzebny żaden dodatkowy proces. Zapytanie pobierze dane z najnowszej wersji plików danych.
- Scalanie przy czytaniu – Przy takim podejściu, gdy w tabeli Iceberg nastąpi aktualizacja lub usunięcie, istniejące pliki danych nie zostaną nadpisane; zamiast tego zostaną utworzone nowe pliki usuwania w celu śledzenia zmian. W przypadku usunięć zostanie utworzony nowy plik usuwania z usuniętymi rekordami. Podczas odczytywania tabeli Iceberg plik usuwania zostanie zastosowany do pobranych danych w celu odfiltrowania rekordów usuwania. W przypadku aktualizacji zostanie utworzony nowy plik usuwania, aby oznaczyć zaktualizowane rekordy jako usunięte. Następnie zostanie utworzony nowy plik dla tych rekordów, ale ze zaktualizowanymi wartościami. Podczas odczytywania tabeli Góra lodowa zarówno usunięte, jak i nowe pliki zostaną zastosowane do pobranych danych, aby odzwierciedlić najnowsze zmiany i uzyskać prawidłowe wyniki. Tak więc w przypadku kolejnych zapytań nastąpi dodatkowy krok w celu scalenia plików danych z usunięciem i nowymi plikami, co zwykle wydłuży czas zapytania. Z drugiej strony zapisy mogą być szybsze, ponieważ nie ma potrzeby ponownego zapisywania istniejących plików danych.
Aby przetestować wpływ obu podejść, możesz uruchomić następujący kod w celu ustawienia właściwości tabeli Góra lodowa:
Uruchom instrukcje SQL update, delete i select w Athenie, aby pokazać różnice w czasie wykonywania między kopiowaniem przy zapisie a scalaniem przy odczycie:
Poniższa tabela zawiera podsumowanie środowisk uruchomieniowych zapytań.
| Pytanie | Kopiowanie przy zapisie | Łączenie przy czytaniu | ||||
| Aktualizacja | DELETE | SELECT | Aktualizacja | DELETE | SELECT | |
| Czas działania (sekundy) | 66.251 | 116.174 | 97.75 | 10.788 | 54.941 | 113.44 |
| Zeskanowane dane (MB) | 494.06 | 3.07 | 137.16 | 494.06 | 3.07 | 137.16 |
Zwróć uwagę, że czas działania to średni czas działania z wieloma uruchomieniami w naszym teście.
Jak pokazują wyniki naszych testów, zawsze istnieją kompromisy w tych dwóch podejściach. To, które podejście zastosować, zależy od przypadków użycia. Podsumowując, rozważania sprowadzają się do opóźnienia odczytu i zapisu. Możesz skorzystać z poniższej tabeli i dokonać właściwego wyboru.
| . | Kopiowanie przy zapisie | Łączenie przy czytaniu |
| ZALETY | Szybsze odczyty | Szybciej pisze |
| Wady | Drogie pisma | Większe opóźnienie przy odczytach |
| Kiedy używać | Dobre do częstych odczytów, rzadkich aktualizacji i usuwania lub dużych aktualizacji wsadowych | Dobre dla tabel z częstymi aktualizacjami i usunięciami |
Zagęszczanie danych
Jeśli rozmiar pliku danych jest mały, w tabeli Iceberg mogą znajdować się tysiące lub miliony plików. To radykalnie zwiększa operacje we/wy i spowalnia zapytania. Ponadto Iceberg śledzi każdy plik danych w zbiorze danych. Więcej plików danych prowadzi do większej liczby metadanych. To z kolei zwiększa narzut i operacje we/wy podczas odczytu plików metadanych. Aby poprawić wydajność zapytań, zaleca się kompaktowanie małych plików danych do większych plików danych.
Podczas aktualizowania i usuwania rekordów w tabeli Iceberg, jeśli stosowane jest podejście odczytu przy scalaniu, może dojść do wielu małych usunięć lub nowych plików danych. Uruchomienie kompaktowania spowoduje połączenie wszystkich tych plików i utworzenie nowszej wersji pliku danych. Eliminuje to konieczność ich uzgadniania podczas odczytów. Zaleca się wykonywanie regularnych zadań zagęszczania, aby mieć jak najmniejszy wpływ na odczyty przy jednoczesnym zachowaniu większej szybkości zapisu.
Uruchom następującą komendę zagęszczania danych, a następnie uruchom zapytanie wybierające z platformy Athena:
W poniższej tabeli porównano czas działania przed i po zagęszczeniu danych. Możesz zobaczyć około 40% poprawę wydajności.
| Pytanie | Przed zagęszczaniem danych | Po zagęszczeniu danych |
| Czas działania (sekundy) | 97.75 | 32.676 sekund |
| Zeskanowane dane (MB) | 137.16 M | 189.19 M |
Zauważ, że zapytania wybierające działały na all_reviews table po operacjach aktualizacji i usuwania, przed i po zagęszczaniu danych. Czas działania to średni czas działania z wieloma przebiegami w naszym teście.
Sprzątać
Po wykonaniu instrukcji rozwiązania w celu wykonania przypadków użycia wykonaj następujące kroki, aby oczyścić zasoby i uniknąć dalszych kosztów:
- Usuń tabele i bazę danych AWS Glue z Atheny lub uruchom następujący kod w swoim notatniku:
- W konsoli EMR Studio wybierz Przestrzenie robocze w okienku nawigacji.
- Wybierz utworzony obszar roboczy i wybierz Usuń.
- W konsoli EMR przejdź do Studios strona.
- Wybierz Studio, które utworzyłeś i wybierz Usuń.
- W konsoli EMR wybierz Klastry w okienku nawigacji.
- Wybierz klaster i wybierz Zakończyć.
- Usuń wiadro S3 i wszelkie inne zasoby utworzone w ramach wymagań wstępnych dla tego posta.
Wnioski
W tym poście przedstawiliśmy platformę Apache Iceberg i sposób, w jaki pomaga ona rozwiązać niektóre wyzwania, z którymi borykamy się w nowoczesnym jeziorze danych. Następnie przedstawiliśmy rozwiązanie do przetwarzania przyrostowych danych w jeziorze danych przy użyciu Apache Iceberg. Na koniec głęboko zagłębiliśmy się w dostrajanie wydajności, aby poprawić wydajność odczytu i zapisu w naszych przypadkach użycia.
Mamy nadzieję, że ten post zawiera przydatne informacje, które pomogą Ci zdecydować, czy chcesz wdrożyć Apache Iceberg w swoim rozwiązaniu Data Lake.
O autorach
 Flora Wu jest starszym architektem-rezydentem w AWS Data Lab. Pomaga klientom korporacyjnym w tworzeniu strategii analizy danych i budowaniu rozwiązań przyspieszających wyniki biznesowe. W wolnym czasie gra w tenisa, tańczy salsę i podróżuje.
Flora Wu jest starszym architektem-rezydentem w AWS Data Lab. Pomaga klientom korporacyjnym w tworzeniu strategii analizy danych i budowaniu rozwiązań przyspieszających wyniki biznesowe. W wolnym czasie gra w tenisa, tańczy salsę i podróżuje.
 Daniel Li jest starszym architektem rozwiązań w Amazon Web Services. Koncentruje się na pomaganiu klientom w opracowywaniu, wdrażaniu i wdrażaniu usług i strategii w chmurze. Kiedy nie pracuje, lubi spędzać czas na świeżym powietrzu z rodziną.
Daniel Li jest starszym architektem rozwiązań w Amazon Web Services. Koncentruje się na pomaganiu klientom w opracowywaniu, wdrażaniu i wdrażaniu usług i strategii w chmurze. Kiedy nie pracuje, lubi spędzać czas na świeżym powietrzu z rodziną.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-a-data-lake-to-support-incremental-data-processing/
- 10
- 100
- 11
- 2022
- 2023
- 7
- 9
- a
- Zdolny
- O nas
- powyżej
- przyśpieszyć
- dostęp
- zarządzanie dostępem
- Działania
- Dzieje Apostolskie
- dodatek
- Dodatkowy
- adres
- Adresy
- Dodaje
- przyjąć
- Korzyść
- Po
- przed
- Wszystkie kategorie
- pozwala
- zawsze
- Amazonka
- Amazon EMR
- Amazon Web Services
- Analityczny
- analityka
- i
- ogłosił
- Apache
- aplikacje
- stosowany
- podejście
- awanse
- właściwy
- architektura
- powiązany
- Uwierzytelnianie
- dostępność
- dostępny
- średni
- uniknąć
- AWS
- Klej AWS
- na podstawie
- bo
- stają się
- zanim
- korzyści
- Ulepsz Swój
- pomiędzy
- większe
- Bootstrap
- budować
- Budowanie
- biznes
- przechwytuje
- Przechwytywanie
- walizka
- Etui
- katalog
- katalogi
- Kategoria
- wyzwania
- zmiana
- Zmiany
- ZOBACZ
- wybór
- Dodaj
- klasyfikacja
- Chmura
- usługi w chmurze
- Grupa
- kod
- Kolumna
- kolumny
- połączyć
- jak
- popełnić
- w porównaniu
- kompletny
- obliczać
- równoległy
- warunek
- konfiguracje
- Rozważania
- Konsola
- Konwersja
- przeliczone
- opłacalne
- Koszty:
- mógłby
- Stwórz
- stworzony
- tworzy
- kurator
- Aktualny
- klient
- Klientów
- Taniec
- tablica rozdzielcza
- dane
- Analityka danych
- Jezioro danych
- analiza danych
- hurtownia danych
- Baza danych
- zbiory danych
- głęboko
- głębokie nurkowanie
- Domyślnie
- zdefiniowane
- Demo
- wykazać
- zależy
- zaprojektowany
- detale
- rozwijać
- oprogramowania
- różnica
- różne
- dyskutować
- nie
- na dół
- dramatycznie
- Spadek
- podczas
- każdy
- Wcześniej
- Wcześnie
- redaktor
- faktycznie
- wydajny
- bądź
- eliminuje
- włączony
- umożliwiając
- kończy się
- silnik
- silniki
- Wchodzę
- Enterprise
- klienci korporacyjni
- Eter (ETH)
- Parzyste
- ewolucja
- ewoluuje
- ewoluuje
- przykład
- Przede wszystkim system został opracowany
- istnieje
- wyjaśnione
- rozszerzenia
- dodatkowy
- ułatwia
- członków Twojej rodziny
- FAST
- szybciej
- Korzyści
- Postać
- filet
- Akta
- filtrować
- filtracja
- filtry
- W końcu
- Znajdź
- i terminów, a
- pierwszy raz
- koncentruje
- obserwuj
- następujący
- format
- Framework
- częsty
- od
- dalej
- Ponadto
- Ogólne
- wygenerowane
- otrzymać
- dany
- Goes
- dobry
- bardzo
- Zarządzanie
- ręka
- zdarzyć
- pomoc
- pomoc
- pomaga
- Ukryty
- hierarchia
- na wysokim szczeblu
- wysoka wydajność
- wydajny
- Ul
- nadzieję
- W jaki sposób
- How To
- Jednak
- HTML
- HTTPS
- IAM
- tożsamość
- zarządzanie tożsamością i dostępem
- Rezultat
- wpływ
- wdrożenia
- realizacja
- wykonawczych
- podnieść
- ulepszony
- poprawa
- poprawia
- in
- Włącznie z
- Zwiększać
- wzrosła
- Zwiększenia
- wskaźnik
- indywidualny
- Informacja
- zainstalować
- zamiast
- integracja
- wprowadzono
- Izoluje
- IT
- styczeń
- Oferty pracy
- Klawisz
- laboratorium
- jezioro
- duży
- większe
- Utajenie
- firmy
- Najnowsze wydanie
- warstwa
- nioski
- prowadzić
- poziomy
- LIMIT
- Linia
- Lista
- mało
- załadować
- lokalizacja
- robić
- WYKONUJE
- i konserwacjami
- wiele
- znak
- rynek
- Mecz
- dopasowywanie
- Łączyć
- Metadane
- może
- miliony
- Nowoczesne technologie
- jeszcze
- ruch
- wielokrotność
- Nazwa
- O imieniu
- Nawigacja
- Nawigacja
- Potrzebować
- potrzebne
- wymagania
- Nowości
- notatnik
- przedmiot
- koncepcja
- działanie
- operacje
- optymalizacja
- Optymalizacja
- zamówienie
- oryginalny
- Inne
- na zewnątrz
- ogólny
- własny
- chleb
- część
- ścieżka
- wzory
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- fizyczny
- planowanie
- plato
- Analiza danych Platona
- PlatoDane
- gra
- wtyczka
- zwrotnica
- Popularny
- możliwy
- Post
- powered
- warunki wstępne
- procedury
- wygląda tak
- przetwarzanie
- produkować
- niska zabudowa
- własność
- zapewniać
- zapewnia
- że
- zaopatrzenie
- zasięg
- Surowy
- surowe dane
- Czytaj
- Czytający
- real
- niedawno
- Zalecana
- dokumentacja
- odzwierciedlić
- region
- rejestry
- regularny
- zwolnić
- wydany
- pozostały
- wymagany
- Wymaga
- Zasoby
- dalsze
- Efekt
- Recenzje
- Bogaty
- Rola
- korzeń
- run
- bieganie
- taki sam
- skanować
- sekund
- Sekcja
- bezpieczeństwo
- wybrany
- wybierając
- Bezserwerowe
- usługa
- Usługi
- Sesja
- zestaw
- Zestawy
- ustawienie
- w panelu ustawień
- powinien
- pokazać
- Targi
- Prosty
- sytuacje
- Rozmiar
- zwalnia
- mały
- Migawka
- So
- Tworzenie
- rozwiązanie
- Rozwiązania
- kilka
- Iskra
- specyficzny
- prędkość
- Spędzanie
- SQL
- Startowy
- Stan
- Zestawienie sprzedaży
- oświadczenia
- statystyki
- Ewolucja krok po kroku
- Cel
- Nadal
- przechowywanie
- sklep
- przechowywany
- sklep
- strategie
- Strategia
- zbudowany
- dane ustrukturyzowane i nieustrukturyzowane
- studio
- podsieci
- kolejny
- Z powodzeniem
- taki
- wystarczający
- PODSUMOWANIE
- wsparcie
- Utrzymany
- Wspierający
- podpory
- stół
- trwa
- biorąc
- cel
- zadania
- Techniki
- tenis
- test
- Testowanie
- Testy
- Połączenia
- Informacje
- Państwo
- ich
- a tym samym
- tysiące
- trzy
- Przez
- czas
- podróż w czasie
- do
- razem
- także
- narzędzia
- Top
- Kwota produktów:
- śledzić
- transakcje
- transformatorowy
- podróżować
- Podróżowanie
- SKRĘCAĆ
- typy
- dla
- wyjątkowy
- Aktualizacja
- zaktualizowane
- Nowości
- aktualizowanie
- URL
- posługiwać się
- przypadek użycia
- Użytkownicy
- zazwyczaj
- VAL
- wartość
- Wartości
- zweryfikować
- wersja
- chodził
- solucja
- Magazyn
- zegarki
- sposoby
- sieć
- usługi internetowe
- Co
- czy
- który
- Podczas
- szeroki
- Szeroki zasięg
- będzie
- bez
- Praca
- pracujący
- działa
- by
- napisać
- pisanie
- Twój
- zefirnet