Drodzy czytelnicy,
Na tym blogu będę omawiał dzielenie na części zarówno teoretycznie, jak i praktycznie w Pythonie.
Więc zacznijmy…
UWAGA: Do implementacji lepiej użyć Python IDLE, ponieważ wynikiem jest rysunek drzewa, który pojawia się w osobnym oknie.
agenda
- Co to jest chrupanie?
- Gdzie stosuje się krojenie?
- Rodzaje krojenia
- Implementacja fragmentacji w Pythonie
- Efekt
Co to jest chrupanie?
Chunking definiuje się jako proces przetwarzania języka naturalnego służący do identyfikacji części mowy i krótkich fraz występujących w danym zdaniu.
Wspominając nasze stare dobre lekcje gramatyki angielskiej w szkole, zwróć uwagę, że istnieje osiem części mowy, a mianowicie rzeczownik, czasownik, przymiotnik, przysłówek, przyimek, spójnik, zaimek i wykrzyknik. Ponadto w powyższej definicji fragmentacji krótkie frazy odnoszą się do fraz utworzonych przez włączenie którejkolwiek z tych części mowy.
Na przykład porcjowanie można wykonać, aby zidentyfikować, a tym samym pogrupować frazy rzeczownikowe lub same rzeczowniki, przymiotniki lub frazy przymiotnikowe i tak dalej. Rozważ poniższe zdanie:
“Zjadłem hamburgery i ciastka na śniadanie.”
W tym przypadku, jeśli chcemy pogrupować lub podzielić frazy rzeczownikowe, otrzymamy „burgery”, „ciasta” i „obiad”, które są rzeczownikami lub grupami rzeczownikowymi zdania.
Gdzie stosuje się krojenie?
Dlaczego mielibyśmy chcieć się czegoś nauczyć, nie wiedząc, gdzie jest to powszechnie używane?! Przyjrzenie się omówionym w tej części bloga aplikacjom pomoże Ci pozostać ciekawym do końca!
Chunking służy do uzyskania wymaganych fraz z danego zdania. Jednak tagowanie POS może być używane tylko do wykrywania części mowy, do których należy każde słowo w zdaniu.
Kiedy mamy mnóstwo opisów lub modyfikacji wokół konkretnego słowa lub frazy, która nas interesuje, używamy fragmentacji, aby uchwycić tylko wymaganą frazę, ignorując resztę wokół niej. W związku z tym fragmentacja toruje drogę do pogrupowania wymaganych fraz i wykluczenia wszystkich modyfikatorów wokół nich, które nie są niezbędne do naszej analizy. Podsumowując, fragmentacja pomaga nam wyodrębnić ważne słowa z długich opisów. Zatem fragmentacja jest krokiem w ekstrakcji informacji.
Co ciekawe, ten proces porcjowania w NLP jest rozszerzony na różne inne zastosowania; na przykład, aby pogrupować owoce określonej kategorii, powiedzmy owoce bogate w białka jako grupę, owoce bogate w witaminy jako inną grupę i tak dalej. Poza tym dzielenie na kawałki może być również używane do grupowania podobnych samochodów, na przykład samochodów obsługujących automatyczną skrzynię biegów w jedną grupę, a innych, które obsługują ręczną skrzynię biegów w inną porcję i tak dalej.
Rodzaje porcjowania
Ogólnie rzecz biorąc, istnieją dwa rodzaje fragmentacji:
- Dzielenie się
- Krojenie w dół
Dzielenie się:
Tutaj nie nurkujemy głęboko; zamiast tego jesteśmy zadowoleni z przeglądu informacji. To po prostu pomaga nam uzyskać krótkie wyobrażenie o danych.
Dzielenie się:
W przeciwieństwie do poprzedniego typu podziału na części, podział na części pomaga nam uzyskać szczegółowe informacje.
Tak więc, jeśli chcesz tylko uzyskać wgląd, rozważ „podział na kawałki”, w przeciwnym razie wolisz „podział na części”.
Implementacja fragmentacji w Pythonie
Wyobraź sobie sytuację, w której chcesz wyodrębnić wszystkie czasowniki z podanego tekstu do analizy. Dlatego w tym przypadku musimy wziąć pod uwagę dzielenie fraz czasownikowych. Dzieje się tak dlatego, że naszym celem jest wyodrębnienie wszystkich fraz czasownikowych z danego fragmentu tekstu. Chunking odbywa się za pomocą wyrażeń regularnych.
Nie martw się, jeśli po raz pierwszy spotykasz się z terminem „wyrażenia regularne”. Poniższa tabela jest tutaj, na ratunek:
|
|
|
|
|
|
|
|
|
|
|
|
Powyższa tabela zawiera najczęściej używane wyrażenia regularne. Wyrażenia regularne są bardzo przydatne w wierszu poleceń, zwłaszcza podczas usuwania, lokalizowania, zmiany nazwy lub przenoszenia plików.
W każdym razie do tej implementacji będziemy używać tylko plików *. Zapraszamy do zapoznania się z powyższą tabelą w celu zapoznania się z symbolem!
Będziemy wykonywać chunking przy użyciu nltk, najpopularniejszej biblioteki NLP. Więc najpierw zaimportujmy go.
importuj nltk
Rozważmy poniższy przykładowy tekst, który stworzyłem samodzielnie. Zachęcamy do zastąpienia poniższego przykładowym tekstem, który chcesz zaimplementować fragmentowanie!
sample_text=""" Rama zabił Ravanę, aby ocalić Sitę z Lanki. Legenda Ramajany jest najpopularniejszym indyjskim eposem. Wiele filmów i seriali zostało już nakręconych w kilku językach tutaj, w Indiach, na podstawie Ramajany. """
Oczywiście dane muszą zostać poddane tokenizacji zdań, a następnie tokenizacji słów, zanim przejdziemy dalej. Tokenizacja to nic innego jak proces rozbijania danego fragmentu tekstu na mniejsze jednostki, takie jak zdania w przypadku tokenizacji zdań i słowa w przypadku tokenizacji słów.
Po tokenizacji, dla każdego słowa wykonywane jest znakowanie POS (część mowy), w którym zostanie zidentyfikowana część mowy każdego słowa. Teraz interesuje nas tylko część mowy czasownika i chcemy ją wyodrębnić.
Dlatego określ interesującą nas część mowy za pomocą wymaganego wyrażenia regularnego w następujący sposób:
VB: {}
tokenized=nltk.sent_tokenize(sample_text) for i in tokenized:words=nltk.word_tokenize(i) # print(words) tagged_words=nltk.pos_tag(words) # print(tagged_words) chunkGram=r"""VB: {}" "" chunkParser=nltk.RegexpParser(chunkGram) chunked=chunkParser.parse(tagged_words) chunked.draw()
Wyrażenie regularne (RE) jest ujęte w nawiasy kątowe (), które z kolei są ujęte w nawiasy klamrowe ({ i }).
UWAGA: Określ RE zgodnie z wymaganym POS
VB oznacza czasownik POS. Kropka następująca po VB oznacza dopasowanie dowolnego znaku następującego po VB. Znak zapytania po kropce oznacza, że dowolny znak po B musi wystąpić tylko raz lub nie może wystąpić wcale. Jednak z tabeli, którą widzieliśmy wcześniej, ten znak jest opcjonalny. Wyrażenie regularne umieściliśmy w ramce w ten sposób, ponieważ w NLTK wyrażenia czasownikowe zawierają następujące znaczniki POS:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Zatem wyrażenia czasownikowe mogą należeć do dowolnego z powyższych POS. Dlatego wyrażenie regularne jest ujęte w ramkę VB.? który obejmuje wszystkie powyższe kategorie. Pakiet RegexpParser służy do sprawdzenia, czy POS spełnia nasz wymagany wzorzec, o którym wspominaliśmy wcześniej przy użyciu RE.
Cały kod można zobaczyć w następujący sposób:
import nltk nltk.download('averaged_perceptron_tagger') sample_text=""" Rama zabił Ravanę, aby ocalić Sitę z Lanki. Legenda Ramajany to najpopularniejszy epos indyjski. Nakręcono tu już wiele filmów i seriali w kilku językach w Indiach na podstawie Ramajany. """ tokenized=nltk.sent_tokenize(sample_text) for i in tokenized:words=nltk.word_tokenize(i) # print(words) tagged_words=nltk.pos_tag(words) # print(tagged_words) chunkGram =r"""VB: {}""" chunkParser=nltk.RegexpParser(chunkGram) chunked=chunkParser.parse(tagged_words) chunked.draw()
Efekt


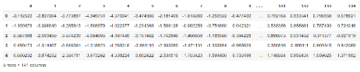
Ostatecznie otrzymujemy drzewiastą postać POS słów wraz ze słowami, których POS pasuje do danego RE. Migawkę danych wyjściowych uzyskanych dla przekazanego przez nas przykładowego tekstu można zobaczyć na powyższych rysunkach.
Zauważ, że słowa, które spełniają nasze RE tylko dla fraz czasownikowych, są wyraźnie zaznaczone w wynikach. W związku z tym podział fraz czasownikowych został pomyślnie przeprowadzony.
Mam nadzieję, że mój artykuł był dla Ciebie przydatny.
Dziękujemy!
Referencje
1. Implementacja fragmentacji w Pythonie
3. Pełna lista POS dostępnych w NLP
O mnie
Jestem Nithyashree V, student ostatniego roku informatyki i inżynierii BTech. Uwielbiam uczyć się takich fajnych technologii i wprowadzać je w życie, szczególnie obserwując, jak pomagają nam rozwiązywać trudne problemy społeczeństwa. Moje zainteresowania to sztuczna inteligencja, nauka o danych i przetwarzanie języka naturalnego.
Oto mój profil na LinkedIn: Mój LinkedIn
Możesz przeczytać inne moje artykuły na temat Analytics Vidhya z tutaj.
- "
- 7
- Wszystkie kategorie
- analiza
- analityka
- aplikacje
- na około
- artykuł
- towary
- sztuczna inteligencja
- Blog
- Śniadanie
- samochody
- kod
- przyjście
- wspólny
- Computer Science
- dane
- nauka danych
- Inżynieria
- Angielski
- ekstrakcja
- i terminów, a
- pierwszy raz
- Nasz formularz
- Darmowy
- Sprzęt
- dobry
- chwycić
- Gramatyka
- Zarządzanie
- tutaj
- Podświetlony
- W jaki sposób
- HTTPS
- pomysł
- zidentyfikować
- Włącznie z
- Indie
- Informacja
- ekstrakcja informacji
- Inteligencja
- odsetki
- IT
- język
- Języki
- UCZYĆ SIĘ
- nauka
- Biblioteka
- Linia
- Lista
- miłość
- znak
- Mecz
- Media
- Najbardziej popularne posty
- Kino
- mianowicie
- Język naturalny
- Przetwarzanie języka naturalnego
- nlp
- Inne
- Pozostałe
- Wzór
- Zwroty
- Popularny
- PoS
- teraźniejszość
- Profil
- Python
- RE
- czytelnicy
- REST
- Szkoła
- nauka
- Short
- Migawka
- So
- ROZWIĄZANIA
- Spot
- pobyt
- student
- wsparcie
- Technologies
- czas
- tokenizacja
- us
- Co to jest
- w ciągu
- słowa
- rok
- zero