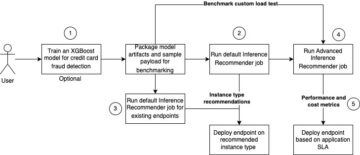
Today we are excited to announce that Together Computer’s GPT-NeoXT-Chat-Base-20B language foundation model is available for customers using Amazon SageMaker JumpStart. GPT-NeoXT-Chat-Base-20B is an open-source model to build conversational bots. You can easily try out this model and use it with JumpStart. JumpStart is the machine learning (ML) hub of Amazon SageMaker that provides access to foundation models in addition to built-in algorithms and end-to-end solution templates to help you quickly get started with ML.
In this post, we walk through how to deploy the GPT-NeoXT-Chat-Base-20B model and invoke the model within an OpenChatKit interactive shell. This demonstration provides an open-source foundation model chatbot for use within your application.
JumpStart models use Deep Java Serving that uses the Deep Java Library (DJL) with deep speed libraries to optimize models and minimize latency for inference. The underlying implementation in JumpStart follows an implementation that is similar to the following notebook. As a JumpStart model hub customer, you get improved performance without having to maintain the model script outside of the SageMaker SDK. JumpStart models also achieve improved security posture with endpoints that enable network isolation.
Foundation models in SageMaker
JumpStart provides access to a range of models from popular model hubs, including Hugging Face, PyTorch Hub, and TensorFlow Hub, which you can use within your ML development workflow in SageMaker. Recent advances in ML have given rise to a new class of models known as foundation models, which are typically trained on billions of parameters and are adaptable to a wide category of use cases, such as text summarization, generating digital art, and language translation. Because these models are expensive to train, customers want to use existing pre-trained foundation models and fine-tune them as needed, rather than train these models themselves. SageMaker provides a curated list of models that you can choose from on the SageMaker console.
You can now find foundation models from different model providers within JumpStart, enabling you to get started with foundation models quickly. You can find foundation models based on different tasks or model providers, and easily review model characteristics and usage terms. You can also try out these models using a test UI widget. When you want to use a foundation model at scale, you can do so easily without leaving SageMaker by using pre-built notebooks from model providers. Because the models are hosted and deployed on AWS, you can rest assured that your data, whether used for evaluating or using the model at scale, is never shared with third parties.
GPT-NeoXT-Chat-Base-20B foundation model
Together Computer developed GPT-NeoXT-Chat-Base-20B, a 20-billion-parameter language model, fine-tuned from ElutherAI’s GPT-NeoX model with over 40 million instructions, focusing on dialog-style interactions. Additionally, the model is tuned on several tasks, such as question answering, classification, extraction, and summarization. The model is based on the OIG-43M dataset that was created in collaboration with LAION and Ontocord.
In addition to the aforementioned fine-tuning, GPT-NeoXT-Chat-Base-20B-v0.16 has also undergone further fine-tuning via a small amount of feedback data. This allows the model to better adapt to human preferences in the conversations. GPT-NeoXT-Chat-Base-20B is designed for use in chatbot applications and may not perform well for other use cases outside of its intended scope. Together, Ontocord and LAION collaborated to release OpenChatKit, an open-source alternative to ChatGPT with a comparable set of capabilities. OpenChatKit was launched under an Apache-2.0 license, granting complete access to the source code, model weights, and training datasets. There are several tasks that OpenChatKit excels at out of the box. This includes summarization tasks, extraction tasks that allow extracting structured information from unstructured documents, and classification tasks to classify a sentence or paragraph into different categories.
Let’s explore how we can use the GPT-NeoXT-Chat-Base-20B model in JumpStart.
Solution overview
You can find the code showing the deployment of GPT-NeoXT-Chat-Base-20B on SageMaker and an example of how to use the deployed model in a conversational manner using the command shell in the following GitHub notebook.
In the following sections, we expand each step in detail to deploy the model and then use it to solve different tasks:
- Set up prerequisites.
- Select a pre-trained model.
- Retrieve artifacts and deploy an endpoint.
- Query the endpoint and parse a response.
- Use an OpenChatKit shell to interact with your deployed endpoint.
Set up prerequisites
This notebook was tested on an ml.t3.medium instance in Amazon SageMaker Studio with the Python 3 (Data Science) kernel and in a SageMaker notebook instance with the conda_python3 kernel.
Before you run the notebook, use the following command to complete some initial steps required for setup:
Select a pre-trained model
We set up a SageMaker session like usual using Boto3 and then select the model ID that we want to deploy:
Retrieve artifacts and deploy an endpoint
With SageMaker, we can perform inference on the pre-trained model, even without fine-tuning it first on a new dataset. We start by retrieving the instance_type, image_uri, and model_uri for the pre-trained model. To host the pre-trained model, we create an instance of sagemaker.model.Model and deploy it. The following code uses ml.g5.24xlarge for the inference endpoint. The deploy method may take a few minutes.
Query the endpoint and parse the response
Next, we show you an example of how to invoke an endpoint with a subset of the hyperparameters:
The following is the response that we get:
Here, we have provided the payload argument "stopping_criteria": ["<human>"], which has resulted in the model response ending with the generation of the word sequence <human>. The JumpStart model script will accept any list of strings as desired stop words, convert this list to a valid stopping_criteria keyword argument to the transformers generate API, and stop text generation when the output sequence contains any specified stop words. This is useful for two reasons: first, inference time is reduced because the endpoint doesn’t continue to generate undesired text beyond the stop words, and second, this prevents the OpenChatKit model from hallucinating additional human and bot responses until other stop criteria are met.
Use an OpenChatKit shell to interact with your deployed endpoint
OpenChatKit provides a command line shell to interact with the chatbot. In this step, you create a version of this shell that can interact with your deployed endpoint. We provide a bare-bones simplification of the inference scripts in this OpenChatKit repository that can interact with our deployed SageMaker endpoint.
There are two main components to this:
- A shell interpreter (
JumpStartOpenChatKitShell) that allows for iterative inference invocations of the model endpoint - A conversation object (
Conversation) that stores previous human/chatbot interactions locally within the interactive shell and appropriately formats past conversations for future inference context
The Conversation object is imported as is from the OpenChatKit repository. The following code creates a custom shell interpreter that can interact with your endpoint. This is a simplified version of the OpenChatKit implementation. We encourage you to explore the OpenChatKit repository to see how you can use more in-depth features, such as token streaming, moderation models, and retrieval augmented generation, within this context. The context of this notebook focuses on demonstrating a minimal viable chatbot with a JumpStart endpoint; you can add complexity as needed from here.
A short demo to showcase the JumpStartOpenChatKitShell is shown in the following video.
The following snippet shows how the code works:
You can now launch this shell as a command loop. This will repeatedly issue a prompt, accept input, parse the input command, and dispatch actions. Because the resulting shell may be utilized in an infinite loop, this notebook provides a default command queue (cmdqueue) as a queued list of input lines. Because the last input is the command /quit, the shell will exit upon exhaustion of the queue. To dynamically interact with this chatbot, remove the cmdqueue.
Example 1: Conversation context is retained
The following prompt shows that the chatbot is able to retain the context of the conversation to answer follow-up questions:
Example 2: Classification of sentiments
In the following example, the chatbot performed a classification task by identifying the sentiments of the sentence. As you can see, the chatbot was able to classify positive and negative sentiments successfully.
Example 3: Summarization tasks
Next, we tried summarization tasks with the chatbot shell. The following example shows how the long text about Amazon Comprehend was summarized to one sentence and the chatbot was able to answer follow-up questions on the text:
Example 4: Extract structured information from unstructured text
In the following example, we used the chatbot to create a markdown table with headers, rows, and columns to create a project plan using the information that is provided in free-form language:
Example 5: Commands as input to chatbot
We can also provide input as commands like /hyperparameters to see hyperparameters values and /quit to quit the command shell:
These examples showcased just some of the tasks that OpenChatKit excels at. We encourage you to try various prompts and see what works best for your use case.
Clean up
After you have tested the endpoint, make sure you delete the SageMaker inference endpoint and the model to avoid incurring charges.
Conclusion
In this post, we showed you how to test and use the GPT-NeoXT-Chat-Base-20B model using SageMaker and build interesting chatbot applications. Try out the foundation model in SageMaker today and let us know your feedback!
This guidance is for informational purposes only. You should still perform your own independent assessment, and take measures to ensure that you comply with your own specific quality control practices and standards, and the local rules, laws, regulations, licenses and terms of use that apply to you, your content, and the third-party model referenced in this guidance. AWS has no control or authority over the third-party model referenced in this guidance, and does not make any representations or warranties that the third-party model is secure, virus-free, operational, or compatible with your production environment and standards. AWS does not make any representations, warranties or guarantees that any information in this guidance will result in a particular outcome or result.
About the authors
 Rachna Chadha is a Principal Solutions Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that the ethical and responsible use of AI can improve society in the future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
Rachna Chadha is a Principal Solutions Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that the ethical and responsible use of AI can improve society in the future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
 Dr. Kyle Ulrich is an Applied Scientist with the Amazon SageMaker built-in algorithms team. His research interests include scalable machine learning algorithms, computer vision, time series, Bayesian non-parametrics, and Gaussian processes. His PhD is from Duke University and he has published papers in NeurIPS, Cell, and Neuron.
Dr. Kyle Ulrich is an Applied Scientist with the Amazon SageMaker built-in algorithms team. His research interests include scalable machine learning algorithms, computer vision, time series, Bayesian non-parametrics, and Gaussian processes. His PhD is from Duke University and he has published papers in NeurIPS, Cell, and Neuron.
 Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoAiStream. Web3 Data Intelligence. Knowledge Amplified. Access Here.
- Minting the Future w Adryenn Ashley. Access Here.
- Buy and Sell Shares in PRE-IPO Companies with PREIPO®. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/gpt-neoxt-chat-base-20b-foundation-model-for-chatbot-applications-is-now-available-on-amazon-sagemaker/
- :has
- :is
- :not
- $UP
- 1
- 100
- 12
- 13
- 15%
- 20
- 23
- 30
- 40
- 50
- 500
- 7
- 9
- a
- Able
- About
- Accept
- access
- According
- Accounts
- Achieve
- actions
- active
- adapt
- add
- addition
- Additional
- Additionally
- advanced
- advances
- AI
- AI/ML
- algorithms
- allow
- allows
- also
- alternative
- am
- Amazon
- Amazon Comprehend
- Amazon SageMaker
- Amazon Web Services
- amount
- an
- analysis
- analyze
- and
- Announce
- answer
- any
- api
- APIs
- app
- Application
- applications
- applied
- Apply
- appropriately
- approximately
- ARE
- argument
- Art
- AS
- assessment
- assured
- At
- augmented
- authority
- available
- avoid
- AWS
- based
- Bayesian
- BE
- because
- before
- believes
- BEST
- Better
- Beyond
- billions
- Bot
- bots
- Box
- bring
- build
- built-in
- by
- CAN
- capabilities
- capital
- case
- cases
- categories
- Category
- characteristics
- charges
- chatbot
- ChatGPT
- Choose
- City
- class
- classification
- Classify
- code
- collaborated
- collaboration
- Columns
- Common
- comparable
- compatible
- complete
- complexity
- components
- comprehend
- computer
- Computer Vision
- Concerns
- conferences
- Console
- Container
- contains
- content
- context
- continue
- control
- Conversation
- conversational
- conversations
- convert
- Cool
- create
- created
- creates
- Creating
- criteria
- curated
- custom
- customer
- Customers
- D.C.
- data
- data science
- datasets
- deep
- deep learning
- Default
- Demo
- demonstrating
- Depending
- deploy
- deployed
- deployment
- description
- designed
- desired
- detail
- Determine
- develop
- developed
- developers
- Development
- develops
- different
- digital
- Digital Art
- Dispatch
- do
- Docker
- Docker Container
- document
- documents
- does
- Doesn’t
- dominant
- Duke
- duke university
- duration
- dynamically
- each
- easily
- Economic
- elements
- else
- enable
- enabling
- encourage
- end-to-end
- Endpoint
- ensure
- Entire
- entities
- entity
- Environment
- Ether (ETH)
- ethical
- evaluating
- Even
- examine
- example
- examples
- excited
- existing
- Exit
- Expand
- expensive
- explore
- extract
- extraction
- Face
- family
- far
- Favorite
- fear
- Feature
- Features
- feedback
- few
- Files
- Find
- First
- focuses
- focusing
- following
- follows
- For
- Foundation
- from
- further
- future
- generate
- generating
- generation
- get
- given
- going
- good
- granting
- guarantees
- guidance
- Have
- having
- he
- headers
- help
- helps
- her
- here
- hiking
- his
- host
- hosted
- How
- How To
- HTML
- HTTPS
- Hub
- human
- i
- ICLR
- ID
- identifying
- if
- illinois
- image
- implementation
- improve
- improved
- in
- in-depth
- include
- includes
- Including
- independent
- information
- Informational
- initial
- input
- inputs
- insights
- install
- instance
- instructions
- intended
- interact
- interactions
- interactive
- interesting
- interests
- into
- isolation
- issue
- IT
- ITS
- Java
- Jobs
- jpg
- just
- Key
- Kind
- Know
- known
- language
- Languages
- large
- Last
- Latency
- launch
- launched
- Laws
- learning
- leaving
- libraries
- Library
- License
- licenses
- like
- Line
- lines
- List
- Listening
- local
- locally
- Long
- Lot
- machine
- machine learning
- Main
- maintain
- make
- manner
- many
- May..
- measures
- medium
- mentions
- method
- million
- minimal
- minimize
- minutes
- ML
- model
- models
- moderation
- modified
- more
- morning
- Music
- Natural
- Natural Language
- Natural Language Processing
- Need
- needed
- negative
- network
- networking
- NeurIPS
- never
- New
- new products
- news
- nlp
- no
- notebook
- notebooks
- now
- object
- of
- Olives
- on
- ONE
- only
- open source
- operational
- Optimize
- Options
- or
- Other
- our
- out
- Outcome
- outlined
- output
- outside
- over
- own
- papers
- parameters
- particular
- parties
- past
- perform
- performance
- phrases
- Pizza
- plan
- plato
- Plato Data Intelligence
- PlatoData
- Play
- Popular
- positive
- Post
- practices
- Predictor
- preferences
- prerequisites
- prevents
- previous
- Principal
- priority
- processes
- processing
- Production
- Products
- project
- prosperity
- provide
- provided
- providers
- provides
- published
- purposes
- Python
- pytorch
- quality
- question
- Questions
- quickly
- range
- rather
- real-time
- reasons
- recent
- recipe
- recognition
- recognizing
- Reduced
- Refactor
- regulations
- release
- remove
- REPEATEDLY
- repository
- required
- research
- researcher
- response
- responses
- responsible
- REST
- result
- resulting
- retain
- return
- review
- Rise
- rules
- Run
- s
- sagemaker
- SageMaker Inference
- say
- scalable
- Scale
- scan
- Science
- Scientist
- scope
- scripts
- sdk
- Search
- Second
- sections
- secure
- security
- see
- selection
- SELF
- senior
- sentence
- sentiment
- Sequence
- Series
- service
- Services
- serving
- session
- set
- Sets
- setup
- several
- shared
- Shell
- Short
- should
- show
- showcase
- showcased
- showed
- shown
- Shows
- similar
- simplified
- SIX
- small
- So
- Social
- Social networking
- Society
- solution
- Solutions
- SOLVE
- some
- Source
- source code
- specific
- specified
- speed
- Spending
- spread
- standards
- start
- started
- statistical
- Step
- Steps
- Still
- Stop
- stores
- Strategic
- streaming
- structure
- structured
- Successfully
- such
- SUMMARY
- Supported
- sure
- table
- Take
- Task
- tasks
- team
- techniques
- tell
- templates
- tensorflow
- terms
- test
- testers
- text generation
- than
- that
- The
- The Capital
- The Future
- the information
- The Source
- Them
- themselves
- then
- There.
- These
- Third
- third parties
- third-party
- this
- Through
- time
- Time Series
- to
- today
- together
- token
- Train
- trained
- Training
- transformers
- Translation
- tried
- true
- try
- two
- type
- typically
- ui
- under
- underlying
- understanding
- university
- until
- upon
- URI
- us
- Usage
- use
- use case
- used
- using
- utilized
- Values
- variety
- various
- version
- via
- viable
- Video
- vision
- want
- warm
- was
- washington
- we
- Weather
- web
- web services
- Weeks
- welcome
- WELL
- What
- What is
- when
- whether
- which
- WHO
- wide
- wider
- will
- with
- within
- without
- Word
- words
- workflow
- works
- write
- you
- Your
- zephyrnet