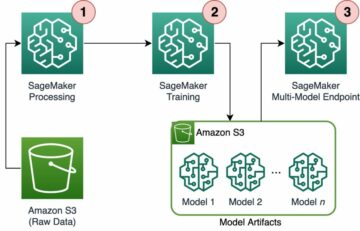
Amazon SageMaker Studio can help you build, train, debug, deploy, and monitor your models and manage your machine learning (ML) workflows. Amazon SageMaker Pipelines enables you to build a secure, scalable, and flexible MLOps platform within Studio.
In this post, we explain how to run PySpark processing jobs within a pipeline. This enables anyone that wants to train a model using Pipelines to also preprocess training data, postprocess inference data, or evaluate models using PySpark. This capability is especially relevant when you need to process large-scale data. In addition, we showcase how to optimize your PySpark steps using configurations and Spark UI logs.
Pipelines is an Amazon SageMaker tool for building and managing end-to-end ML pipelines. It’s a fully managed on-demand service, integrated with SageMaker and other AWS services, and therefore creates and manages resources for you. This ensures that instances are only provisioned and used when running the pipelines. Furthermore, Pipelines is supported by the SageMaker Python SDK, letting you track your data lineage and reuse steps by caching them to ease development time and cost. A SageMaker pipeline can use processing steps to process data or perform model evaluation.
When processing large-scale data, data scientists and ML engineers often use PySpark, an interface for Apache Spark in Python. SageMaker provides prebuilt Docker images that include PySpark and other dependencies needed to run distributed data processing jobs, including data transformations and feature engineering using the Spark framework. Although those images allow you to quickly start using PySpark in processing jobs, large-scale data processing often requires specific Spark configurations in order to optimize the distributed computing of the cluster created by SageMaker.
In our example, we create a SageMaker pipeline running a single processing step. For more information about what other steps you can add to a pipeline, refer to Pipeline Steps.
SageMaker Processing library
SageMaker Processing can run with specific frameworks (for example, SKlearnProcessor, PySparkProcessor, or Hugging Face). Independent of the framework used, each ProcessingStep requires the following:
- Step name – The name to be used for your SageMaker pipeline step
- Step arguments – The arguments for your
ProcessingStep
Additionally, you can provide the following:
- The configuration for your step cache in order to avoid unnecessary runs of your step in a SageMaker pipeline
- A list of step names, step instances, or step collection instances that the
ProcessingStepdepends on - The display name of the
ProcessingStep - A description of the
ProcessingStep - Property files
- Retry policies
The arguments are handed over to the ProcessingStep. You can use the sagemaker.spark.PySparkProcessor or sagemaker.spark.SparkJarProcessor class to run your Spark application inside of a processing job.
Each processor comes with its own needs, depending on the framework. This is best illustrated using the PySparkProcessor, where you can pass additional information to optimize the ProcessingStep further, for instance via the configuration parameter when running your job.
Run SageMaker Processing jobs in a secure environment
It’s best practice to create a private Amazon VPC and configure it so that your jobs aren’t accessible over the public internet. SageMaker Processing jobs allow you to specify the private subnets and security groups in your VPC as well as enable network isolation and inter-container traffic encryption using the NetworkConfig.VpcConfig request parameter of the CreateProcessingJob API. We provide examples of this configuration using the SageMaker SDK in the next section.
PySpark ProcessingStep within SageMaker Pipelines
For this example, we assume that you have Studio deployed in a secure environment already available, including VPC, VPC endpoints, security groups, AWS Identity and Access Management (IAM) roles, and AWS Key Management Service (AWS KMS) keys. We also assume that you have two buckets: one for artifacts like code and logs, and one for your data. The basic_infra.yaml file provides example AWS CloudFormation code to provision the necessary prerequisite infrastructure. The example code and deployment guide is also available on GitHub.
As an example, we set up a pipeline containing a single ProcessingStep in which we’re simply reading and writing the abalone dataset using Spark. The code samples show you how to set up and configure the ProcessingStep.
We define parameters for the pipeline (name, role, buckets, and so on) and step-specific settings (instance type and count, framework version, and so on). In this example, we use a secure setup and also define subnets, security groups, and the inter-container traffic encryption. For this example, you need a pipeline execution role with SageMaker full access and a VPC. See the following code:
{ "pipeline_name": "ProcessingPipeline", "trial": "test-blog-post", "pipeline_role": "arn:aws:iam::<ACCOUNT_NUMBER>:role/<PIPELINE_EXECUTION_ROLE_NAME>", "network_subnet_ids": [ "subnet-<SUBNET_ID>", "subnet-<SUBNET_ID>" ], "network_security_group_ids": [ "sg-<SG_ID>" ], "pyspark_process_volume_kms": "arn:aws:kms:<REGION_NAME>:<ACCOUNT_NUMBER>:key/<KMS_KEY_ID>", "pyspark_process_output_kms": "arn:aws:kms:<REGION_NAME>:<ACCOUNT_NUMBER>:key/<KMS_KEY_ID>", "pyspark_helper_code": "s3://<INFRA_S3_BUCKET>/src/helper/data_utils.py", "spark_config_file": "s3://<INFRA_S3_BUCKET>/src/spark_configuration/configuration.json", "pyspark_process_code": "s3://<INFRA_S3_BUCKET>/src/processing/process_pyspark.py", "process_spark_ui_log_output": "s3://<DATA_S3_BUCKET>/spark_ui_logs/{}", "pyspark_framework_version": "2.4", "pyspark_process_name": "pyspark-processing", "pyspark_process_data_input": "s3a://<DATA_S3_BUCKET>/data_input/abalone_data.csv", "pyspark_process_data_output": "s3a://<DATA_S3_BUCKET>/pyspark/data_output", "pyspark_process_instance_type": "ml.m5.4xlarge", "pyspark_process_instance_count": 6, "tags": { "Project": "tag-for-project", "Owner": "tag-for-owner" }
}
To demonstrate, the following code example runs a PySpark script on SageMaker Processing within a pipeline by using the PySparkProcessor:
# import code requirements
# standard libraries import
import logging
import json # sagemaker model import
import sagemaker
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.pipeline_experiment_config import PipelineExperimentConfig
from sagemaker.workflow.steps import CacheConfig
from sagemaker.processing import ProcessingInput
from sagemaker.workflow.steps import ProcessingStep
from sagemaker.workflow.pipeline_context import PipelineSession
from sagemaker.spark.processing import PySparkProcessor from helpers.infra.networking.networking import get_network_configuration
from helpers.infra.tags.tags import get_tags_input
from helpers.pipeline_utils import get_pipeline_config def create_pipeline(pipeline_params, logger): """ Args: pipeline_params (ml_pipeline.params.pipeline_params.py.Params): pipeline parameters logger (logger): logger Returns: () """ # Create SageMaker Session sagemaker_session = PipelineSession() # Get Tags tags_input = get_tags_input(pipeline_params["tags"]) # get network configuration network_config = get_network_configuration( subnets=pipeline_params["network_subnet_ids"], security_group_ids=pipeline_params["network_security_group_ids"] ) # Get Pipeline Configurations pipeline_config = get_pipeline_config(pipeline_params) # setting processing cache obj logger.info("Setting " + pipeline_params["pyspark_process_name"] + " cache configuration 3 to 30 days") cache_config = CacheConfig(enable_caching=True, expire_after="p30d") # Create PySpark Processing Step logger.info("Creating " + pipeline_params["pyspark_process_name"] + " processor") # setting up spark processor processing_pyspark_processor = PySparkProcessor( base_job_name=pipeline_params["pyspark_process_name"], framework_version=pipeline_params["pyspark_framework_version"], role=pipeline_params["pipeline_role"], instance_count=pipeline_params["pyspark_process_instance_count"], instance_type=pipeline_params["pyspark_process_instance_type"], volume_kms_key=pipeline_params["pyspark_process_volume_kms"], output_kms_key=pipeline_params["pyspark_process_output_kms"], network_config=network_config, tags=tags_input, sagemaker_session=sagemaker_session ) # setting up arguments run_ags = processing_pyspark_processor.run( submit_app=pipeline_params["pyspark_process_code"], submit_py_files=[pipeline_params["pyspark_helper_code"]], arguments=[ # processing input arguments. To add new arguments to this list you need to provide two entrances: # 1st is the argument name preceded by "--" and the 2nd is the argument value # setting up processing arguments "--input_table", pipeline_params["pyspark_process_data_input"], "--output_table", pipeline_params["pyspark_process_data_output"] ], spark_event_logs_s3_uri=pipeline_params["process_spark_ui_log_output"].format(pipeline_params["trial"]), inputs = [ ProcessingInput( source=pipeline_params["spark_config_file"], destination="/opt/ml/processing/input/conf", s3_data_type="S3Prefix", s3_input_mode="File", s3_data_distribution_type="FullyReplicated", s3_compression_type="None" ) ], ) # create step pyspark_processing_step = ProcessingStep( name=pipeline_params["pyspark_process_name"], step_args=run_ags, cache_config=cache_config, ) # Create Pipeline pipeline = Pipeline( name=pipeline_params["pipeline_name"], steps=[ pyspark_processing_step ], pipeline_experiment_config=PipelineExperimentConfig( pipeline_params["pipeline_name"], pipeline_config["trial"] ), sagemaker_session=sagemaker_session ) pipeline.upsert( role_arn=pipeline_params["pipeline_role"], description="Example pipeline", tags=tags_input ) return pipeline def main(): # set up logging logger = logging.getLogger(__name__) logger.setLevel(logging.INFO) logger.info("Get Pipeline Parameter") with open("ml_pipeline/params/pipeline_params.json", "r") as f: pipeline_params = json.load(f) print(pipeline_params) logger.info("Create Pipeline") pipeline = create_pipeline(pipeline_params, logger=logger) logger.info("Execute Pipeline") execution = pipeline.start() return execution if __name__ == "__main__": main()
As shown in the preceding code, we’re overwriting the default Spark configurations by providing configuration.json as a ProcessingInput. We use a configuration.json file that was saved in Amazon Simple Storage Service (Amazon S3) with the following settings:
[ { "Classification":"spark-defaults", "Properties":{ "spark.executor.memory":"10g", "spark.executor.memoryOverhead":"5g", "spark.driver.memory":"10g", "spark.driver.memoryOverhead":"10g", "spark.driver.maxResultSize":"10g", "spark.executor.cores":5, "spark.executor.instances":5, "spark.yarn.maxAppAttempts":1 "spark.hadoop.fs.s3a.endpoint":"s3.<region>.amazonaws.com", "spark.sql.parquet.fs.optimized.comitter.optimization-enabled":true } }
]
We can update the default Spark configuration either by passing the file as a ProcessingInput or by using the configuration argument when running the run() function.
The Spark configuration is dependent on other options, like the instance type and instance count chosen for the processing job. The first consideration is the number of instances, the vCPU cores that each of those instances have, and the instance memory. You can use Spark UIs or CloudWatch instance metrics and logs to calibrate these values over multiple run iterations.
In addition, the executor and driver settings can be optimized even further. For an example of how to calculate these, refer to Best practices for successfully managing memory for Apache Spark applications on Amazon EMR.
Next, for driver and executor settings, we recommend investigating the committer settings to improve performance when writing to Amazon S3. In our case, we’re writing Parquet files to Amazon S3 and setting “spark.sql.parquet.fs.optimized.comitter.optimization-enabled” to true.
If needed for a connection to Amazon S3, a regional endpoint “spark.hadoop.fs.s3a.endpoint” can be specified within the configurations file.
In this example pipeline, the PySpark script spark_process.py (as shown in the following code) loads a CSV file from Amazon S3 into a Spark data frame, and saves the data as Parquet back to Amazon S3.
Note that our example configuration is not proportionate to the workload because reading and writing the abalone dataset could be done on default settings on one instance. The configurations we mentioned should be defined based on your specific needs.
# import requirements
import argparse
import logging
import sys
import os
import pandas as pd # spark imports
from pyspark.sql import SparkSession
from pyspark.sql.functions import (udf, col)
from pyspark.sql.types import StringType, StructField, StructType, FloatType from data_utils import( spark_read_parquet, Unbuffered
) sys.stdout = Unbuffered(sys.stdout) # Define custom handler
logger = logging.getLogger(__name__)
handler = logging.StreamHandler(sys.stdout)
handler.setFormatter(logging.Formatter("%(asctime)s %(message)s"))
logger.addHandler(handler)
logger.setLevel(logging.INFO) def main(data_path): spark = SparkSession.builder.appName("PySparkJob").getOrCreate() spark.sparkContext.setLogLevel("ERROR") schema = StructType( [ StructField("sex", StringType(), True), StructField("length", FloatType(), True), StructField("diameter", FloatType(), True), StructField("height", FloatType(), True), StructField("whole_weight", FloatType(), True), StructField("shucked_weight", FloatType(), True), StructField("viscera_weight", FloatType(), True), StructField("rings", FloatType(), True), ] ) df = spark.read.csv(data_path, header=False, schema=schema) return df.select("sex", "length", "diameter", "rings") if __name__ == "__main__": logger.info(f"===============================================================") logger.info(f"================= Starting pyspark-processing =================") parser = argparse.ArgumentParser(description="app inputs") parser.add_argument("--input_table", type=str, help="path to the channel data") parser.add_argument("--output_table", type=str, help="path to the output data") args = parser.parse_args() df = main(args.input_table) logger.info("Writing transformed data") df.write.csv(os.path.join(args.output_table, "transformed.csv"), header=True, mode="overwrite") # save data df.coalesce(10).write.mode("overwrite").parquet(args.output_table) logger.info(f"================== Ending pyspark-processing ==================") logger.info(f"===============================================================")
To dive into optimizing Spark processing jobs, you can use the CloudWatch logs as well as the Spark UI. You can create the Spark UI by running a Processing job on a SageMaker notebook instance. You can view the Spark UI for the Processing jobs running within a pipeline by running the history server within a SageMaker notebook instance if the Spark UI logs were saved within the same Amazon S3 location.
Clean up
If you followed the tutorial, it’s good practice to delete resources that are no longer used to stop incurring charges. Make sure to delete the CloudFormation stack that you used to create your resources. This will delete the stack created as well as the resources it created.
Conclusion
In this post, we showed how to run a secure SageMaker Processing job using PySpark within SageMaker Pipelines. We also demonstrated how to optimize PySpark using Spark configurations and set up your Processing job to run in a secure networking configuration.
As a next step, explore how to automate the entire model lifecycle and how customers built secure and scalable MLOps platforms using SageMaker services.
About the Authors
 Maren Suilmann is a Data Scientist at AWS Professional Services. She works with customers across industries unveiling the power of AI/ML to achieve their business outcomes. Maren has been with AWS since November 2019. In her spare time, she enjoys kickboxing, hiking to great views, and board game nights.
Maren Suilmann is a Data Scientist at AWS Professional Services. She works with customers across industries unveiling the power of AI/ML to achieve their business outcomes. Maren has been with AWS since November 2019. In her spare time, she enjoys kickboxing, hiking to great views, and board game nights.
 Maira Ladeira Tanke is an ML Specialist at AWS. With a background in data science, she has 9 years of experience architecting and building ML applications with customers across industries. As a technical lead, she helps customers accelerate their achievement of business value through emerging technologies and innovative solutions. In her free time, Maira enjoys traveling and spending time with her family someplace warm.
Maira Ladeira Tanke is an ML Specialist at AWS. With a background in data science, she has 9 years of experience architecting and building ML applications with customers across industries. As a technical lead, she helps customers accelerate their achievement of business value through emerging technologies and innovative solutions. In her free time, Maira enjoys traveling and spending time with her family someplace warm.
 Pauline Ting is Data Scientist in the AWS Professional Services team. She supports customers in achieving and accelerating their business outcome by developing AI/ML solutions. In her spare time, Pauline enjoys traveling, surfing, and trying new dessert places.
Pauline Ting is Data Scientist in the AWS Professional Services team. She supports customers in achieving and accelerating their business outcome by developing AI/ML solutions. In her spare time, Pauline enjoys traveling, surfing, and trying new dessert places.
 Donald Fossouo is a Sr Data Architect in the AWS Professional Services team, mostly working with Global Finance Service. He engages with customers to create innovative solutions that address customer business problems and accelerate the adoption of AWS services. In his spare time, Donald enjoys reading, running, and traveling.
Donald Fossouo is a Sr Data Architect in the AWS Professional Services team, mostly working with Global Finance Service. He engages with customers to create innovative solutions that address customer business problems and accelerate the adoption of AWS services. In his spare time, Donald enjoys reading, running, and traveling.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- Platoblockchain. Web3 Metaverse Intelligence. Knowledge Amplified. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/run-secure-processing-jobs-using-pyspark-in-amazon-sagemaker-pipelines/
- :is
- $UP
- 1
- 10
- 100
- 2019
- 5G
- 9
- a
- About
- accelerate
- accelerating
- access
- accessible
- Achieve
- achievement
- achieving
- across
- addition
- Additional
- Additional Information
- address
- Adoption
- AI/ML
- already
- Although
- Amazon
- Amazon SageMaker
- Amazon SageMaker Pipelines
- and
- anyone
- Apache
- Apache Spark
- api
- app
- Application
- applications
- ARE
- argument
- arguments
- AS
- At
- automate
- available
- avoid
- AWS
- back
- background
- based
- BE
- because
- BEST
- board
- build
- builder
- Building
- built
- business
- by
- cache
- calculate
- CAN
- case
- Channel
- charges
- chosen
- class
- classification
- Cluster
- code
- collection
- COM
- computing
- Configuration
- configurations
- connection
- consideration
- Cost
- could
- create
- created
- creates
- Creating
- custom
- customer
- Customers
- data
- data processing
- data science
- data scientist
- Days
- Default
- defined
- demonstrate
- demonstrated
- dependent
- Depending
- depends
- deploy
- deployed
- deployment
- description
- developing
- Development
- Display
- distributed
- distributed computing
- distributed data processing
- Docker
- driver
- each
- either
- emerging
- emerging technologies
- enable
- enables
- encryption
- end-to-end
- Endpoint
- Engineering
- Engineers
- ensures
- Entire
- Environment
- error
- especially
- Ether (ETH)
- evaluate
- evaluation
- Even
- example
- examples
- execute
- execution
- experience
- Explain
- explore
- Face
- family
- Feature
- File
- Files
- finance
- First
- flexible
- followed
- following
- For
- FRAME
- Framework
- Free
- from
- FS
- full
- fully
- function
- functions
- further
- Furthermore
- game
- get
- Global
- good
- great
- Group’s
- guide
- Hadoop
- Have
- height
- help
- helps
- hiking
- history
- How
- How To
- HTML
- http
- HTTPS
- IAM
- ICS
- Identity
- images
- import
- imports
- improve
- in
- include
- Including
- independent
- industries
- info
- information
- Infrastructure
- innovative
- input
- instance
- integrated
- Interface
- Internet
- isolation
- IT
- iterations
- ITS
- Job
- Jobs
- jpg
- json
- Key
- keys
- large-scale
- lead
- learning
- Length
- letting
- libraries
- lifecycle
- like
- List
- loads
- location
- longer
- machine
- machine learning
- make
- manage
- managed
- management
- manages
- managing
- Memory
- mentioned
- message
- ML
- MLOps
- model
- models
- Monitor
- more
- multiple
- name
- names
- necessary
- Need
- needed
- needs
- network
- networking
- New
- next
- notebook
- November
- number
- of
- on
- On-Demand
- ONE
- Optimize
- optimized
- optimizing
- Options
- order
- OS
- Other
- Outcome
- output
- own
- owner
- pandas
- parameter
- parameters
- pass
- Passing
- path
- perform
- performance
- pipeline
- Places
- plato
- Plato Data Intelligence
- PlatoData
- Post
- power
- practice
- practices
- private
- problems
- process
- processing
- Processor
- professional
- project
- properties
- provide
- provides
- providing
- provision
- public
- Python
- quickly
- Read
- Reading
- recommend
- regional
- relevant
- request
- Requirements
- requires
- Resources
- return
- returns
- Role
- roles
- Run
- running
- sagemaker
- SageMaker Pipelines
- same
- Save
- scalable
- Science
- Scientist
- scientists
- Section
- secure
- security
- service
- Services
- session
- set
- setting
- settings
- setup
- Sex
- should
- show
- showcase
- shown
- Simple
- simply
- since
- single
- So
- Solutions
- Spark
- specialist
- specific
- specified
- Spending
- SQL
- stack
- standard
- start
- Starting
- Step
- Steps
- Stop
- storage
- studio
- subnets
- Successfully
- Supported
- Supports
- team
- Technical
- Technologies
- that
- The
- their
- Them
- therefore
- These
- Through
- time
- to
- tool
- track
- traffic
- Train
- Training
- transformations
- transformed
- Traveling
- trial
- true
- tutorial
- types
- ui
- unveiling
- Update
- use
- value
- Values
- version
- via
- View
- views
- warm
- WELL
- What
- which
- will
- with
- within
- workflow
- workflows
- working
- works
- write
- writing
- yaml
- years
- Your
- zephyrnet