Plato Data Intelligence. Vertical Search. Ai
Plato’s Ai and advanced automation curates the latest sector intelligence with insights into the people, companies and culture driving innovation today.
Signup for Free. Get Access Now.
Plato Web3 DefiX Gateway. Access all your dApps in one place.
Connect with the thousands of dApps via a single and secure interface.
Your Gateway to the world of Decentralized Finance.
Plato OpenAi. Driving Smart Search.
By employing a completely new methodology related to search and Intelligence, we enable deep and authentic connectivity to today’s most innovative technology sectors. The platform provides an ultra-secure environment to consume sector-specific real-time data intelligence. Plato is accessible across 23 languages and 27 verticals.


Understanding Crypto-to-Crypto Exchanges: An Explanation By TradingView News – CryptoInfoNet

Consensys files lawsuit against SEC over Ethereum status

BDAG at $0.006; TRX’s Bullish Price Trend Amid BTC Halving
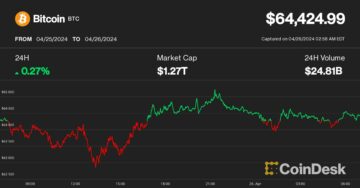
Bitcoin Stable Above $64K While ETF Outflows Hit $200M

‘Violent to the Upside’: This Catalyst Could See Bitcoin Explode by up to 1,486%, Says Strike CEO Jack Mallers – The Daily Hodl
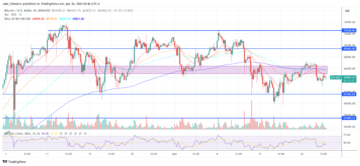
Crypto Bull Run Set To Return Next Week, Predicts Arthur Hayes


Meta, The Parent Company Of Facebook, Continues To Face Significant Financial Losses With Its Metaverse Project – CryptoInfoNet

First Cross-Chain Dog Meme Coin Presale Exceeds Soft Cap Target – Next 1000x Crypto Gem?

CME Group’s MD to Join Compagnie Financière Tradition to Lead Digitalization

Rare ‘Epic Sat’ From Bitcoin Halving Sells for $2.1 Million – Unchained
Consensys Sues the SEC Over Ether’s Status as a Security – Unchained

Apple Cuts Production of $3.5k MR Headset Due to Low Demand

How Developers Can Securely Take Advantage of Generative AI – PrimaFelicitas



Consensys Sues the SEC: Calls Its Authority over Ethereum “Unlawful”

Marathon Digital Ramps up Bitcoin Mining Goals, Targets 50 EH/s Hash Rate for 2024
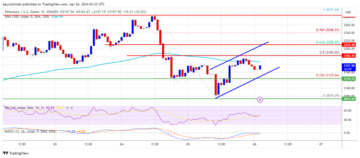
Ethereum Price Faces Crucial Test: Will $3,200 Withstand The Pressure?
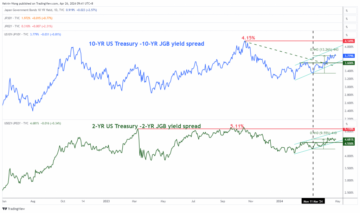
USD/JPY: Persistent JPY bearish trend intact despite growing intervention risk – MarketPulse

JCB enables JCB Contactless acceptance at Taichung MRT in Taiwan
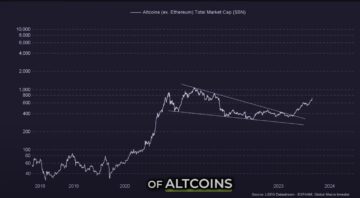
Ethereum, Solana and Altcoins Approaching ‘Banana Zone,’ According to Macro Guru Raoul Pal – Here’s His Outlook – The Daily Hodl

Jeff Martin Auctioneers to Manage Sale of Sabine Mining Company Assets for North American Coal
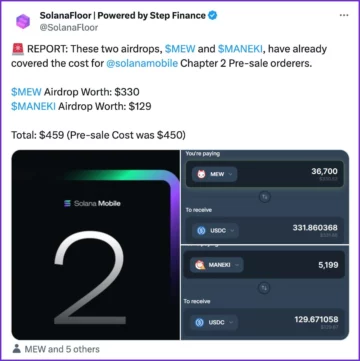
Solana ‘Chapter 2’ Airdrops Could Cover the Price of the Phone – Decrypt

FBI warns US citizens against using ‘unregistered crypto money transmitting services’

BitcoinOS Posts “Game-Changing” Whitepaper To Get Rollups On Bitcoin

UK Law Enforcement Agencies Can Now Seize Crypto More Easily as New Rules Take Effect
![[After Long Silence] Binance Assures PH Users Following SEC Demand; Google, Apple Urged to Hear All Sides | BitPinas](https://platoaistream.net/wp-content/uploads/2024/04/after-long-silence-binance-assures-ph-users-following-sec-demand-google-apple-urged-to-hear-all-sides-bitpinas-360x189.png)
Ethereum Game ‘MetalCore’ Adding MON Token Rewards From ‘Pixelmon’ – Decrypt

Meme coin Dog Go To The Moon surpasses $500 million market cap

Terraform Labs to restrict US access, withdraw $23 million of liquidity following SEC ruling

Payments Giant Stripe Reenters Crypto With USDC on Ethereum, Solana and Polygon – Decrypt

Immutable zkEVM Offering Up to $50 Million in Token Rewards to Ethereum Gamers – Decrypt

Franklin Templeton tokenizes $380 million US government money fund on Polygon, Stellar

Meta Enormous AI Spending Overshadows Solid Q1 Earnings

This Was CZ’s Biggest Mistake, According to Binance Co-Founder He Yi

Crypto Gets Second Chance: Stripe Re-enters the Sector with Stablecoins

Consensys sues SEC, seeks court declaration that Ethereum is not a security

Grayscale Bitcoin Trust (GBTC) Faces Continued Outflow Spree

‘ETH Should Not Be Treated as a Security’ — Consensys Sues SEC Over Ethereum Regulations

Fearless Crypto Whales Capitalize on Ripple’s XRP Turbulence With Multimillion-Dollar Buys

Dogeverse Merges the Best of Meme Coins with Advanced Bridging Technology – ClayBro Presale Reviews

‘Crypto Is Back’, Says Stripe Co-Founder John Collison

Crypto boasts over 400 million active wallets, suggesting more investor confidence

Eesee and Blockpass Enhance Digital Asset Marketplace with New Compliance Solutions

Slothana Raises $15M and Shiba Inu Secures $12M: Which Meme Coin Can Make You The Most Gains?

Consensys Sues SEC In Bid To ‘Defend Ethereum’ – The Defiant



Consensys sues SEC over Ethereum classification, claims regulatory overreach

Why Memecoins Are Bad for the Crypto Industry, Explains a16z CTO

Cryptopunk #635 Achieves $12.41M Sale, Joins Ranks of Top Priciest NFTs

DAR Announces April 2024 Crypto Exchange Vetting Results: Key Insights

Tokenization Trends: Franklin Templeton On-Chain Government Money

RACE Partners with DFNS and Bridge to Revolutionize On-Chain RWAs
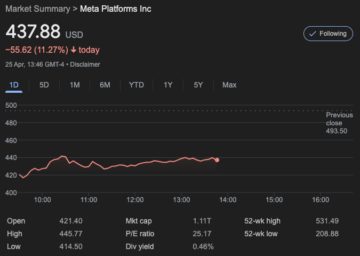
Cleo Capital’s Take on Meta: Bullish on AI, Bearish on Metaverse

Cboe to End Crypto Exchange in Plans to Consolidate Services
Top Crypto Gainers Today Apr 25 – EOS, Alchemy Pay, XDC Network, Rollbit token
New Cryptocurrency Releases, Listings, & Presales Today – BlockDrop, Vatra INU, Verum Coin

Bitcoin and Ethereum Prices Tumble as GDP Data Comes In Weaker Than Expected – The Defiant

BlackRock iShares Bitcoin Trust (IBIT) Sees Zero Inflows, Ending 71-Day Streak

Next Step in the Evolution of On-Chain Analysis: New, Granular Cohorts for Key On-Chain Metrics
Solana Price Plummets Amidst Market Crash: Can SOL Make a Comeback?

Top 10 Reasons to Attend Blockchain Futurist Conference – CryptoCurrencyWire

Bloomberg: Reasons Behind Bitcoin Traders’ Waning Bullishness

Cambridge Isotope Laboratories (CIL) Shows Long-Term Commitment to Xenia, Ohio, Facility With New Land Purchase

Black Spade Donates Art and Jewellery Collection To Hong Kong Red Cross

Bitcoin Price Recovery Is Halted At $68,000 As It Continues To Fall

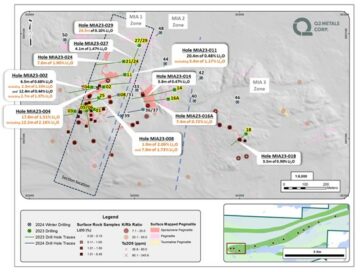
Q2 Metals Announces Assay Results from Its 2023 Inaugural Drill Program at the Mia Lithium Property, James Bay Territory, Quebec, Canada

NVIDIA Acquires GPU Orchestration Software Provider Run:ai for $700 Million

Mazda Production and Sales Results for March 2024 and for April 2023 through March 2024

BounceBit (BB) Megadrop Now Open: Participate by Subscribing to BNB Locked Products or Completing Web3 Quests

NodeMonkes leads NFT sales with over US$1 million in a day

MHI Begins Operation of SOEC Test Module the Next-Generation High-Efficiency Hydrogen Production Technology at Takasago Hydrogen Park



Bitcoin Mining Decentralization Not Great, Says Ordinals Creator – Unchained

GAC Honda to Begin Sales of All-new e:NP2, the Second Model of e:N Series

Exness Wins ‘Best Trading Conditions 2024’ at UF Awards LATAM 2024

Stablecoin Bill Could Be Ready for the U.S. House Soon Says Top Democrat Maxine Waters: Bloomberg
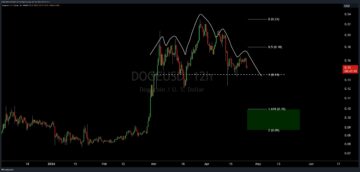
Head & Shoulders Alert: Dogecoin Could See A Price Crash Soon


Liquidations Exceed $200 Million As Bitcoin Falls Below $64K – CryptoInfoNet
BNB Chain to Enable Native Staking on BNB Smart Chain (BSC) following Beacon Chain Sunset

Negative Nirvana? Decoding The First Bitcoin Funding Rate Dip Of 2024

Cointelegraph Reports Meta’s 15% Drop Due To Disappointing Outlook And Increased Investments In AI And Metaverse – CryptoInfoNet


Bitcoin Will Still Hit $150,000 By Year-End Despite ETF Hype Dying Down — Standard Chartered

DogeMob Set to Enhance User Engagement and Utility Within its Ecosystem With Key Developments
EOS Price Analysis: Gains Could Accelerate Above $1 | Live Bitcoin News

Here’s What Will Drive Bitcoin to $150K After the Halving: Standard Chartered
Litecoin (LTC) Price Analysis: Can Bulls Hold This Key Support? | Live Bitcoin News


Honda Reaches Basic Agreement with Asahi Kasei on Collaboration for Production of Battery Separators for Automotive Batteries in Canada
Plato Delivers Authenticity in an Ad-Free Environment.
Plato delivers an immersive UI / UX experience via a proprietary Hashtagging algorithm that is optimized for search. Using our technology, we organically generated over 5M users since launching our beta in April of 2020. Plato identifies and organizes both public and private data sources that makes accessing this information faster and more efficient. By layering information with highly contextual and validated data sets, we create an authentic and value driven user experience.
Plato Defi Gateway.
Your Access to the world of Decentralized Finance.
Vertical Specific Search
Your Vertical. Your Edge.
Plato Empowers Discovery
Plato was designed to seamlessly connect users with hundreds of sector specific applications by providing an ultra-safe and secure environment for vertical real-time data intelligence through an intuitive and content-rich user experience.
Intuitive User Friendly UI / UX
While our Ai and machine learning automates and curates both structured and unstructured data, Plato’s modern interface quickly and easily connects users to hundreds of Decentralized Applications and associated data.
The Evolution of Search
Plato identifies and organizes both public and private data sources and makes accessing this information faster and more efficient, while driving open analytics across our entire data ecosystem.
Plato Delivers Contextual Relevancy
Plato was created to change the way business sector information is gathered and processed. By utilizing today’s most innovative technology tools, we connect users to the information that is driving today’s markets into the future.
Smarter Faster Insights
Features and Applications
Plato Data Engine
Our data engine utilizes the latest in machine learning to provide deep sector relevant data through vetted and consensus-driven sources, and our proprietary hash-tagging engine is at the core of a consensus driven search experience that eliminates the need to go to multiple sites and applications.
Plato Framework
The modularity of our framework allows our development team to quickly integrate new data streams and to rapidly develop and deploy plug-in utility applications to drive both user consumption and engagement, creating sector-specific intelligence via an Ai powered Search Engine.
Vertical Search & Ai
Plato is a vertical Search platform with artificial intelligence that optimizes data curation from multiple verified sources that are specific to today’s most active technology sectors like Blockchain, Cyber Security, Fintech and Artificial Intelligence. New sectors are integrated as desired with advanced automation tools.
DaaS / Sectors
-
Plato drives both discovery and connectivity across the following verticals: Aerospace, Ai, AR/VR, Automotive, Aviation, Big Data, Blockchain, Cannabis, Crowdfunding, CyberSecurity, Ecommerce, Edtech, Esports, Fintech, Gaming, IOT, Payments, Private Equity, Quantum, SaaS, SPACs, Startups, Venture Capital.
Multilingual Support
Technology has opened up real-time access to data as it happens anywhere in the world, with the only limitation being linguistic differences in language and culture and unification of messaging. To ensure availability of relevant data for all users, Plato is accessible and indexed across 23 Languages making true conversational search a reality.
PlatoAiStream
Plato delivers custom news streams for access to the information most relevant to you, chosen from hundreds of curated channels and available in 26+ Different Languages. Immediate access to the latest exchange data and pricing. Technical, Fundamental and Social Data. Multi Transitional Indexing. With Plato Ai AudioStream, you create your own broadcast channel.
Modular Integration
Distributed Trainable Ai
Data Ingestion and Analysis
Structured and unstructured data is ingested from a variety of vertically relevant sources through our API appliance.
Data Interpretation
Data is extracted and processed while our engine distills it into reportable and contextually relevant intelligence.
Parsing and Indexing
Vertical Data is indexed via consensus driven algorithms to optimize contextual relevancy, fluency and coherence.
Validation and Formatting
Data is synthesized, validated and formatted for optimal delivery and publishing.
Syndication and Distribution
New Nodes of Data are updated automatically and syndicated globally.
Engagement and Monetization
Engagement is managed in realtime with Freemium to Premium upgrades on the fly.