Plato Data Intelligence. Vertical Search. Ai
Plato’s Ai and advanced automation curates the latest sector intelligence with insights into the people, companies and culture driving innovation today.
Signup for Free. Get Access Now.
Plato Web3 DefiX Gateway. Access all your dApps in one place.
Connect with the thousands of dApps via a single and secure interface.
Your Gateway to the world of Decentralized Finance.
Plato OpenAi. Driving Smart Search.
By employing a completely new methodology related to search and Intelligence, we enable deep and authentic connectivity to today’s most innovative technology sectors. The platform provides an ultra-secure environment to consume sector-specific real-time data intelligence. Plato is accessible across 23 languages and 27 verticals.



Top Trader Unveils Crypto Holdings Following Last Week’s Crash, Says Altcoin Recovery Now on Accelerated Timeline – The Daily Hodl

Overview Of UEX.Finance Cryptocurrency Exchange – CryptoInfoNet
Canadian dollar extends losses as Canada’s inflation rises – MarketPulse

Trust Wallet Warning: High-Risk Zero-Day iMessage Exploit Targeting iOS Users

XRP About to Face Huge Selling Pressure? — These 3 Warning Signs Could Send Ripple’s XRP Crashing

Acuity Trading and Excent Capital Partner for Market Analytics Integration

Polkadot eyes $8.8 million sponsorship deal with Lionel Messi’s Inter Miami




FMAS:24 Session Spotlight – Gold, South African Rand & The 2024 Financial Markets Outlook

Exploding Gold Sales at Pawnshops Offers Lesson for Bitcoin Bulls

Saakuru Labs Secures $2.4 Million in Funding to Fuel the Adoption of the Saakuru Protocol

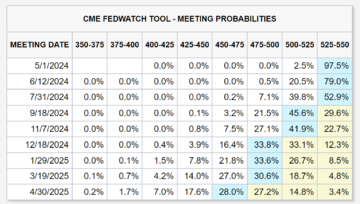
‘We Sold Everything Last Night’, Reveals Crypto Research Firm
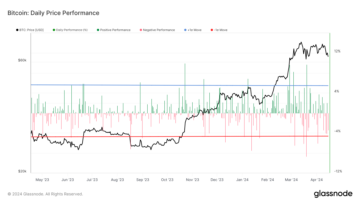
Bitcoin’s April plunge: On track for worst month since August down 11%
Vara Network’s Actor Model to Turbocharge Adoption of Blockchain Applications | Live Bitcoin News

How Soon Could Chiliz (CHZ) Hit the $1 Mark Amid Market Trends?

Gold’s Outlook: Goldman Says $2,700 by Year End, Citi Says $3,000 Within 6-18 Months

‘A Masterpiece’ – Tether CEO Hints at New Fully Non-Custodial Tokenization Platform From Top Stablecoin Issuer – The Daily Hodl
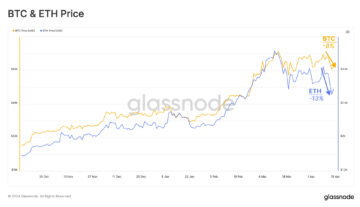

Bitcoin Price Slips Below $62,000 as Pre-Halving Momentum Stalls – Decrypt
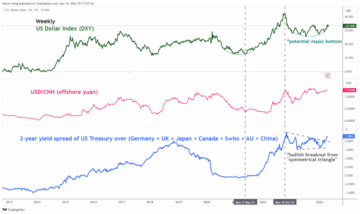
Currency war and geopolitical risk are deadly concoctions for risk assets – MarketPulse
Cashing In on Memes: Top Meme Coin Pick for April 2024



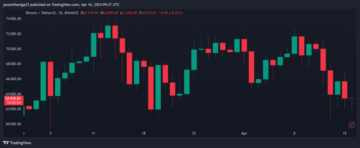
What Lies Ahead For Bitcoin As Halving Approaches in 3 Days?

P2E Space Nation Introduces ‘Cosmorathon’ for $OIK Airdrop | BitPinas

Major Crypto Exchange CEO Predicts Impact of Bitcoin Halving 2024


Trust Wallet releases advisory on zero-day exploit exposing iOS users

Solana Renaissance Hackathon PH: Local Demo Day Winners | BitPinas
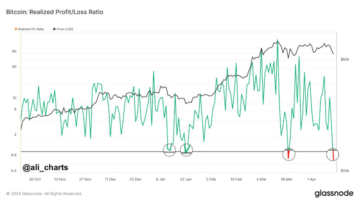
Bitcoin Investors In The Red: Losses Trump Profits As Ratio Dips Below 1

Bitcoin Funds Saw $110 Million Weekly Outflows – Unchained

SAG-AFTRA Approves Deal Curbing AI in Music Production

Mitsubishi Corporation Announces Participation in a DAC Project in Louisiana, USA

Create Music Using AI and Deep Learning – PrimaFelicitas
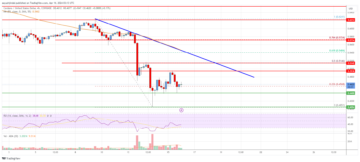
Cardano (ADA) Price Analysis: Bears In Action Below $0.52 | Live Bitcoin News
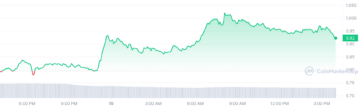
5 Best Cheap Crypto to Buy Now Under 1 Dollar April 15

Samsung Secures $6.4 Billion in US Government Grants for Chip Manufacturing Expansion in Texas

OKX Latest Exchange to Roll out Mainnet of an Ethereum Layer 2 Blockchain – Unchained
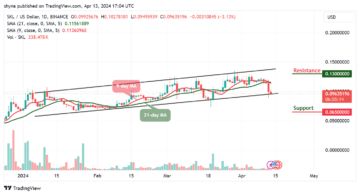
Skale Network Price Prediction for Today, April 15 – SKL Technical Analysis

The Crypto Investor’s Guide to DePIN Tokens – Bitcoin Market Journal


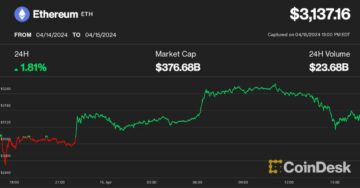
Ether, Altcoins Remain Under Pressure Following Volatile Weekend

Curve Founder Michael Egorov Faced Liquidation Amid Weekend Altcoin Crash: Report – The Daily Hodl

How to Buy Gift Cards with Bitcoin + 100 Other Cryptos | BitPay

Current Bonk Value: Live BONK Price Chart, Market Capitalization, And Latest Updates – CryptoInfoNet

Vitalik Buterin’s RailGun advocacy triggers sharp rise in privacy tokens
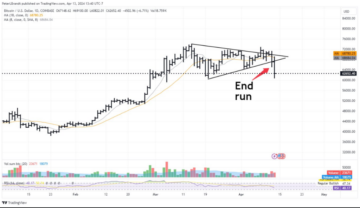
Bitcoin Completes ‘End Run,’ Analyst Says – Here’s What It Means


Folding the Yen: How a Humble QR Code is Unifying Asian Payments

Ethereum Funds Notch Fifth Week of Losses—Will Hong Kong ETFs Snap the Streak? – Decrypt

Adidas Releasing $2,500 Solana NFT Sneakers in Move-to-Earn Game ‘Stepn’ – Decrypt
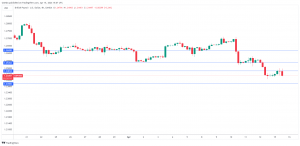

Telegram-Linked Toncoin On The Cusp Of Surpassing Ripple’s XRP As TON Becomes 8th-Largest Crypto
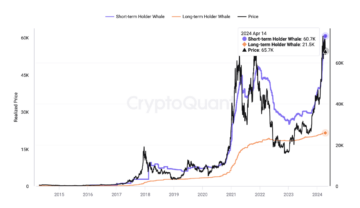
Bitcoin Rebounds After Nearing Cost Basis Of Short-Term Whales
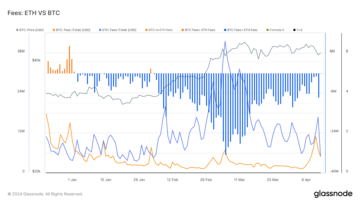
Bitcoin sees record fees in 2024 as halving approaches

SimpleMiners Using User-Friendly Solutions to Revolutionize Crypto Mining

Samsung secures $6.4B grant from US gov’t to expand chip manufacturing in Texas

Bitcoin Could Skyrocket to $650K If This Happens, According to Willy Woo

Bitcoin’s sharp downturn linked to futures liquidations: Bitfinex

Top 5 Cryptocurrencies With High Growth Potential in 2024: BlockDAG Leads With 30,000x ROI Along With PIKA, ETH, SOL, & AVAX

VALR, South Africa’s Leading Crypto Exchange, Receives Regulatory License as Crypto Asset Service Provider (CASP)

Gen AI Music Hits 20% Success Rate in Commercial Briefs

The 2024 Bitcoin Halving: CNBC Explains Why This Time Is Different

Is It Wise for E-Commerce Stores to Accept Crypto As Payment?

Dogwifhat’s Future Valuation: WIF & BUDZ Predictions and Analysis for Cryptocurrency Investors

Bitcoin Price Correction of 15-25% Post-Halving Predicted by Delta Blockchain Fund Founder


Binance Official Pleads Not Guilty to Money Laundering Charges in Nigeria – CryptoCurrencyWire


Shiba Inu Records Largest Burn in a Month as 650,000,000 SHIB Moves to Dead Wallet

How to Cash Out Crypto in Ireland Without Paying Taxes
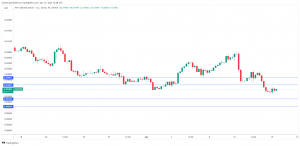
Euro ends slide as industrial production rebounds – MarketPulse

Satoshi Smackdown: Alleged Creator Of Bitcoin Withdraws Lawsuit Against Critic – CryptoInfoNet


Big CIO Show 2024 Paves the Way for Next-Gen Technological Leadership in AI


Whales Move 452,869,591 XRP to 3 Top Exchanges Amid 5% Gain


IRS Expects Surge in Crypto Tax Crime Cases as Tax Season Concludes
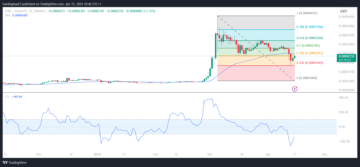
This Pattern Signals Shiba Inu Return to $0.000045 As SHIB Slumped 48% Since March


Binance Executive Nadeem Arjarwalla Traced to Kenya After Escape from Nigerian Custody

Axie Infinity Launches Play-to-Airdrop With Weekly 10K AXS Rewards | BitPinas

Shiba Inu: Five Rules To Invest in Shibarium Projects From Lucie

Make Your Move: BRISE, BEFE, and CENX Are the Best Crypto Investments Now | Live Bitcoin News
BRISE, BEFE, and CENX: Your Secret Weapons for Crypto Price Skyrocketing | Live Bitcoin News

Hong Kong Markets Regulator Approves Bitcoin and Ethereum Spot ETFs – Unchained


Smart Contract Hacking Costs Ex-Engineer $12M and His Freedom

Bitcoin, crypto market tumbles as Iran-Israel tensions escalate

Promoting unity across Singapore through insightful conversations


Wider Risks of Online Piracy in Singapore Continue to be Felt as Singapore Courts Order More Sites Blocked
Plato Delivers Authenticity in an Ad-Free Environment.
Plato delivers an immersive UI / UX experience via a proprietary Hashtagging algorithm that is optimized for search. Using our technology, we organically generated over 5M users since launching our beta in April of 2020. Plato identifies and organizes both public and private data sources that makes accessing this information faster and more efficient. By layering information with highly contextual and validated data sets, we create an authentic and value driven user experience.
Plato Defi Gateway.
Your Access to the world of Decentralized Finance.
Vertical Specific Search
Your Vertical. Your Edge.
Plato Empowers Discovery
Plato was designed to seamlessly connect users with hundreds of sector specific applications by providing an ultra-safe and secure environment for vertical real-time data intelligence through an intuitive and content-rich user experience.
Intuitive User Friendly UI / UX
While our Ai and machine learning automates and curates both structured and unstructured data, Plato’s modern interface quickly and easily connects users to hundreds of Decentralized Applications and associated data.
The Evolution of Search
Plato identifies and organizes both public and private data sources and makes accessing this information faster and more efficient, while driving open analytics across our entire data ecosystem.
Plato Delivers Contextual Relevancy
Plato was created to change the way business sector information is gathered and processed. By utilizing today’s most innovative technology tools, we connect users to the information that is driving today’s markets into the future.
Smarter Faster Insights
Features and Applications
Plato Data Engine
Our data engine utilizes the latest in machine learning to provide deep sector relevant data through vetted and consensus-driven sources, and our proprietary hash-tagging engine is at the core of a consensus driven search experience that eliminates the need to go to multiple sites and applications.
Plato Framework
The modularity of our framework allows our development team to quickly integrate new data streams and to rapidly develop and deploy plug-in utility applications to drive both user consumption and engagement, creating sector-specific intelligence via an Ai powered Search Engine.
Vertical Search & Ai
Plato is a vertical Search platform with artificial intelligence that optimizes data curation from multiple verified sources that are specific to today’s most active technology sectors like Blockchain, Cyber Security, Fintech and Artificial Intelligence. New sectors are integrated as desired with advanced automation tools.
DaaS / Sectors
-
Plato drives both discovery and connectivity across the following verticals: Aerospace, Ai, AR/VR, Automotive, Aviation, Big Data, Blockchain, Cannabis, Crowdfunding, CyberSecurity, Ecommerce, Edtech, Esports, Fintech, Gaming, IOT, Payments, Private Equity, Quantum, SaaS, SPACs, Startups, Venture Capital.
Multilingual Support
Technology has opened up real-time access to data as it happens anywhere in the world, with the only limitation being linguistic differences in language and culture and unification of messaging. To ensure availability of relevant data for all users, Plato is accessible and indexed across 23 Languages making true conversational search a reality.
PlatoAiStream
Plato delivers custom news streams for access to the information most relevant to you, chosen from hundreds of curated channels and available in 26+ Different Languages. Immediate access to the latest exchange data and pricing. Technical, Fundamental and Social Data. Multi Transitional Indexing. With Plato Ai AudioStream, you create your own broadcast channel.
Modular Integration
Distributed Trainable Ai
Data Ingestion and Analysis
Structured and unstructured data is ingested from a variety of vertically relevant sources through our API appliance.
Data Interpretation
Data is extracted and processed while our engine distills it into reportable and contextually relevant intelligence.
Parsing and Indexing
Vertical Data is indexed via consensus driven algorithms to optimize contextual relevancy, fluency and coherence.
Validation and Formatting
Data is synthesized, validated and formatted for optimal delivery and publishing.
Syndication and Distribution
New Nodes of Data are updated automatically and syndicated globally.
Engagement and Monetization
Engagement is managed in realtime with Freemium to Premium upgrades on the fly.