As organizações usam seus dados para resolver problemas complexos começando pequenos, executando experimentos iterativos e refinando a solução. Embora o poder dos experimentos não possa ser ignorado, as organizações devem ser cautelosas quanto ao custo-benefício de tais experimentos. Se o tempo for gasto criando a infraestrutura subjacente para permitir experimentos, isso aumentará ainda mais o custo.
Os desenvolvedores precisam de um ambiente de desenvolvimento integrado (IDE) para exploração de dados e depuração de fluxos de trabalho e diferentes perfis de computação para executar esses fluxos de trabalho. Se você escolher Amazon EMR para tais casos de uso, você pode usar um IDE chamado Estúdio Amazon EMR para exploração de dados, transformação, controle de versão e depuração e execute trabalhos do Spark para processar grandes volumes de dados. Implantando Amazon EMR no Amazon EKS simplifica o gerenciamento, reduz custos e melhora o desempenho. No entanto, um engenheiro de dados ou administrador de TI precisa gastar tempo criando a infraestrutura subjacente, configurando a segurança e criando um endpoint gerenciado para os usuários se conectarem. Isso significa que esses projetos precisam esperar até que esses especialistas criem a infraestrutura.
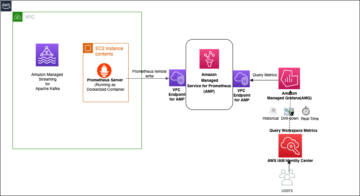
Nesta postagem, mostramos como um engenheiro de dados ou administrador de TI pode usar o Arquitetura de referência do AWS Analytics (ARA) para acelerar a implantação da infraestrutura, economizando tempo e dinheiro gastos por sua organização nesses experimentos de análise de dados. Usamos a biblioteca para implantar um Amazon Elastic Kubernetes (Amazon EKS), configure-o para usar o Amazon EMR no EKS e implante um cluster virtual e endpoints gerenciados e EMR Studio. Você pode então executar trabalhos no cluster virtual ou executar análise exploratória de dados com Cadernos Jupyter no Amazon EMR Studio e Amazon EMR no EKS. A arquitetura abaixo representa a infraestrutura que você implantará com a AWS Analytics Reference Architecture.

Pré-requisitos
Para acompanhar, você precisa ter uma conta da AWS inicializada com o Kit de desenvolvimento em nuvem da AWS (AWSCDK). Para obter instruções, consulte Bootstrapping. O tutorial a seguir usa TypeScript e requer a versão 2 ou posterior do AWS CDK. Se você não tiver o AWS CDK instalado, consulte Instalar o AWS CDK.
Configurar um projeto do AWS CDK
Para implantar recursos usando o ARA, primeiro você precisa configurar um projeto AWS CDK e instalar a biblioteca ARA. Conclua as seguintes etapas:
- Crie uma pasta chamada emr-eks-app:
- Inicialize um projeto do AWS CDK em um diretório vazio e execute o seguinte comando:
- Instale a biblioteca ARA:
- Em lib/emr-eks-app.ts, importe a biblioteca ARA da seguinte maneira. A primeira linha chama a biblioteca ARA, a segunda define as políticas do AWS Identity and Access Management (IAM):
Crie e defina um cluster EKS e capacidade de computação
Para criar um EMR no EKS cluster virtual, primeiro você precisa implantar um cluster EKS. A biblioteca ARA define uma construção chamada EmrEksCluster. A construção provisiona um cluster EKS, permite Papéis IAM para contas de serviço, e implanta um conjunto de controladores de suporte, como o controlador do gerenciador de certificados (necessário para o endpoint gerenciado usado pelo Amazon EMR Studio), bem como um dimensionador automático de cluster para ter um cluster elástico e economizar custos quando nenhum trabalho é enviado ao cluster .
In lib/emr-eks-app.ts, adicione a seguinte linha:
Para saber mais sobre as propriedades que você pode personalizar, consulte EmrEksClusterProps. Existem dois parâmetros obrigatórios em EmrEksCluster construção: A primeira é eksAdminRoleArn role é obrigatório e é o papel que você usa para interagir com o plano de controle do Kubernetes. Esta função deve ter permissões administrativas para criar ou atualizar o cluster. O segundo parâmetro é autoscaling, este parâmetro permite selecionar o mecanismo de escalonamento automático, seja carpinteiro or Autoescalador de cluster Kubernetes nativo. Neste blog, usaremos o Karpenter e recomendamos seu uso devido ao escalonamento automático mais rápido, gerenciamento e provisionamento de nós simplificados. Agora você está pronto para definir a capacidade de computação.
Uma maneira de definir nós de trabalho no Amazon EKS é usar grupos de nós gerenciados. Usamos um grupo de nós chamado tooling, que hospeda o coredns, controlador de entrada, gerente de certificado, carpinteiro e qualquer outro pod necessário para a execução de EMR em trabalhos EKS ou ManagedEndpoint. Também definimos padrão Karpenter Provedores que definem a capacidade a ser usada para trabalhos enviados pelo EMR no EKS. Esses provedores são otimizados para diferentes casos de uso do Spark (trabalhos críticos, trabalho não crítico, experimentação e sessões interativas). A construção também permite que você envie seu próprio provisionador definido por um manifesto do Kubernetes por meio de um método chamado addKarpenterProvisioner. Vamos discutir os Provisioners predefinidos.
Configurações de provisionadores padrão
Os provisionadores padrão são definidos para experimentação rápida e são sempre criado por padrão. No entanto, se você não quiser usá-los, poderá definir o defaultNodeGroups parâmetro para false no EmrEksCluster propriedades no momento da criação. Os Provisioners são definidos da seguinte forma e são criados em cada uma das sub-redes usadas pelo Amazon EKS:
- Provisionador crítico – É dedicado a dar suporte a trabalhos com SLAs agressivos e com prazo limitado. O provisionador usa Instâncias On-Demand, que não são paradas, ao contrário das Instâncias Spot, e seu ciclo de vida segue por um dos trabalhos. Os nós usam armazenamentos de instância, que são discos NVMe fisicamente conectados ao host, que oferecem uma alta taxa de transferência de E/S que permite melhor desempenho do Spark, porque é usado como armazenamento temporário para derramamento e embaralhamento de disco. Os tipos de instância usados no nó são da família m6gd. As instâncias usam o AWS Graviton processador, que oferece melhor preço/desempenho do que os processadores x86. Para usar este provisionador em seus trabalhos, você pode usar o seguinte exemplo de configuração, que é referenciado no substituição de configuração do EMR no envio do trabalho EKS.
- Provisionador não crítico – Este Provisioner aproveita Instâncias Spot para economizar custos para trabalhos que não são sensíveis ao tempo ou trabalhos que são usados para experimentos. Este nó usa instâncias spot porque os trabalhos não são críticos e podem ser interrompidos. Essas instâncias podem ser interrompidas se a instância for recuperada. Os tipos de instâncias utilizadas no nó são da família m6gd, o driver é On-Demand e os executores são instâncias on spot.
- Provisionador de notebook – O Provisioner é para executar endpoints gerenciados que são usados pelo Amazon EMR Studio para exploração de dados usando o Amazon EMR no EKS. As instâncias são da família t3 e são On-Demand para driver e Spot Instances para executores para manter o custo baixo. Se as instâncias do executor forem interrompidas, novas serão iniciadas pelo Karpenter. Se as instâncias do executor forem interrompidas com muita frequência, você pode definir suas próprias instâncias que usam instâncias sob demanda.
Os seguintes link fornece mais detalhes sobre como cada um dos provisionadores é definido. Uma propriedade de importação definida nos Provisioners padrão é uma para cada AZ. Isso é importante porque permite reduzir o custo de transferência de rede inter-AZ quando o Spark executa um shuffle.
Para esta postagem, usamos os Provisioners padrão, então você não precisa adicionar nenhuma linha de código para esta seção. Se você quiser adicionar seus próprios Provisioners, você pode aproveitar o método addKarpenterProvisioner para aplicar seus próprios manifestos. Você pode usar métodos auxiliares em Utils classe como readYamlDocument para ler o documento YAML e loadYaml carregar arquivos YAML e passá-los como argumentos para addKarpenterProvisioner método.
Implante o cluster virtual e uma função de execução
Um cluster virtual é um namespace do Kubernetes com o qual o Amazon EMR está registrado; quando você envia uma tarefa, os pods de driver e executor são executados no namespace associado. o EmrEksCluster construct oferece um método chamado addEmrVirtualCluster, que cria o cluster virtual para você. O método leva EmrVirtualClusterOptions como parâmetro, que possui os seguintes atributos:
- nome – O nome do seu cluster virtual.
- criarNamespace – Um campo opcional que cria o namespace EKS. Isso é do tipo Boolean e, por padrão, não cria um namespace EKS separado, portanto, seu cluster virtual é criado no namespace padrão.
- eksNamespace – O nome do namespace EKS a ser vinculado ao cluster EMR virtual. Se nenhum namespace for fornecido, a construção usará o namespace padrão.
- In
lib/emr-eks-app.ts, adicione a seguinte linha para criar seu cluster virtual:Agora criamos a função de execução, que é uma função do IAM usada pelo driver e pelo executor para interagir com os serviços da AWS. Antes de podermos criar a função de execução para o Amazon EMR, precisamos primeiro criar o
ManagedPolicy. Observe que no código a seguir, criamos uma política para permitir o acesso ao bucket do Amazon Simple Storage Service (Amazon S3) e aos logs do Amazon CloudWatch. - In
lib/emr-eks-app.ts, adicione a seguinte linha para criar a política:Se você quiser usar o Catálogo de dados do AWS Glue, adicione sua permissão na política anterior.
Agora criamos a função de execução para Amazon EMR no EKS usando a política definida na etapa anterior usando o
createExecutionRolemétodo de instância. Os pods de driver e executor podem então assumir essa função para acessar e processar dados. O escopo da função é definido de forma que apenas os pods no namespace do cluster virtual possam assumi-la. Para saber mais sobre a condição implementada por este método para restringir o acesso à função apenas para pods criados pelo Amazon EMR no EKS no namespace do cluster virtual, consulte Usar funções de execução de trabalho com o Amazon EMR no EKS. - In
lib/emr-eks-app.ts, adicione a seguinte linha para criar a função de execução:O código anterior produz uma função do IAM chamada
execRoleJobcom a política IAM definida ememrekspolicye com escopo para o namespacedataanalysis. - Por fim, geramos parâmetros importantes para a execução do trabalho:
Implante o Amazon EMR Studio e provisione usuários
Para implantar um EMR Studio para exploração de dados e criação de trabalhos, a biblioteca ARA tem uma construção chamada NotebookPlatform. Essa construção permite implantar quantos EMR Studios forem necessários (dentro do limite da conta) e configurá-los com o modo de autenticação adequado para você e atribuir usuários a eles. Para saber mais sobre os modos de autenticação disponíveis no Amazon EMR Studio, consulte Escolha um modo de autenticação para o Amazon EMR Studio.
A construção cria todas as funções e políticas do IAM necessárias para o Amazon EMR Studio. Ele também cria um bucket S3 onde todos os notebooks são armazenados pelo Amazon EMR Studio. O balde é criptografado com um chave gerenciada pelo cliente (CMK) gerado pela pilha do AWS CDK. As etapas a seguir mostram como criar seu próprio EMR Studio com a construção.
A construção da plataforma do notebook leva NotebookPlatformProps como uma propriedade, que permite definir seu EMR Studio, um namespace, o nome do EMR Studio e seu modo de autenticação.
- In
lib/emr-eks-app.ts, adicione a seguinte linha:Para esta postagem, usamos usuários do IAM para que você possa reproduzi-lo facilmente em sua própria conta. No entanto, se você já tiver federação IAM ou logon único (SSO) em vigor, poderá usá-los em vez de usuários IAM. Para saber mais sobre os parâmetros de
NotebookPlatformProps, referir-se NotebookPlatformProps.Em seguida, precisamos criar e atribuir usuários ao Amazon EMR Studio. Para isso, o constructo possui um método chamado
addUserque obtém uma lista de usuários e os atribui ao Amazon EMR Studio no caso de SSO ou atualiza a política do IAM para permitir o acesso ao Amazon EMR Studio para os usuários do IAM fornecidos. O usuário também pode ter vários endpoints gerenciados e cada usuário pode ter sua versão do Amazon EMR definida. Eles podem usar um conjunto diferente de instâncias do Amazon Elastic Compute Cloud (Amazon EC2) e permissões diferentes usando funções de execução de trabalho. - In
lib/emr-eks-app.ts, adicione a seguinte linha:No código anterior, por uma questão de brevidade, reutilizamos a mesma política IAM que criamos na função de execução.
Observe que a construção otimiza o número de terminais gerenciados que são criados. Se dois endpoints tiverem o mesmo nome, apenas um será criado.
- Agora que definimos nossa implantação, podemos implantá-la:
Você pode encontrar um projeto de amostra que contém todas as etapas do passo a passo no seguinte GitHub repositório.
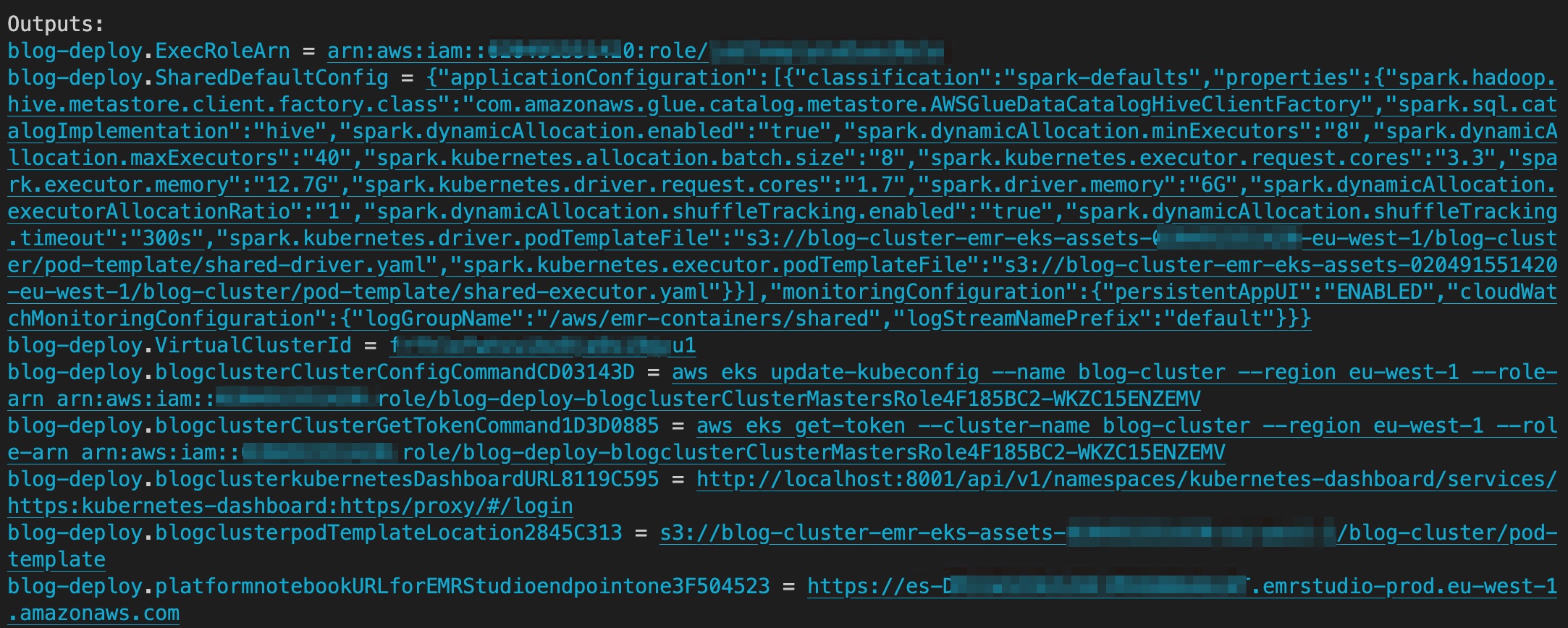
Quando a implantação estiver concluída, a saída conterá o bucket S3 contendo os ativos para podTemplate, o link para o EMR Studio e o ID do cluster virtual do EMR Studio. A captura de tela a seguir mostra a saída do AWS CDK após a conclusão da implantação.
Enviar trabalhos

Como estamos usando os Provisioners padrão, usaremos o podTemplate que é definido pela construção disponível no Repositório GitHub ARA. Eles são carregados para você pela construção em um bucket do S3 chamado <clustername>-emr-eks-assets; você só precisa consultá-los em seu trabalho do Spark. Neste trabalho, você também usa os parâmetros do trabalho na saída ao final da implantação do AWS CDK. Esses parâmetros permitem que você use o Catálogo de dados do AWS Glue e implemente as melhores práticas do Spark no Kubernetes, como dynamicAllocation e colocação de vagens. No fim de cdk deploy O ARA produzirá configurações de amostra de trabalho com as melhores práticas listadas antes que você pode usar para enviar um trabalho. Você pode enviar um trabalho da seguinte maneira.
Uma execução de tarefa é uma unidade de trabalho, como um arquivo Spark JAR que é enviado ao EMR no cluster EKS. Iniciamos um trabalho usando o start-job-run comando. Observe que você pode usar SparkSubmitParameters para especificar o caminho do Amazon S3 para o modelo de pod, conforme mostrado no seguinte comando:
O código assume os seguintes valores:
- – O ID do cluster virtual EMR
- – O nome do seu trabalho do Spark
- – A função de execução que você criou
- – O Amazon S3 URI do seu trabalho do Spark
- – O URI do Amazon S3 do modelo de pod do driver, que você obtém da saída do AWS CDK
- – O Amazon S3 URI do modelo de pod do executor
- – O nome do grupo de logs do CloudWatch
- – Seu prefixo de fluxo de log do CloudWatch
Você pode acessar o console do Amazon EMR para verificar o status do seu trabalho e visualizar os logs. Você também pode verificar o status executando o describe-job-run comando:
Explorar dados usando o Amazon EMR Studio
Nesta seção, mostramos como você pode criar um espaço de trabalho no Amazon EMR Studio e se conectar ao endpoint gerenciado do Amazon EKS a partir do espaço de trabalho. Na saída, use o link para o Amazon EMR Studio para navegar até a implantação do EMR Studio. Você deve entrar com o IAM nome de usuário você forneceu no addUser método.
Crie um espaço de trabalho
Para criar um espaço de trabalho, conclua as seguintes etapas:
- Faça login no EMR Studio criado pelo AWS CDK.
- Escolha Criar espaço de trabalho.
- Insira um nome de espaço de trabalho e uma descrição opcional.
- Selecionar Permitir Colaboração no espaço de trabalho se você quiser trabalhar com outros usuários do Studio neste espaço de trabalho em tempo real.
- Escolha Criar espaço de trabalho.

Depois de criar o espaço de trabalho, escolha-o na lista de espaços de trabalho para abrir o ambiente JupyterLab.
A captura de tela a seguir mostra a aparência do terminal. Para obter mais informações sobre a interface do usuário, consulte Entenda a interface do usuário do Workspace.
Conecte-se a um EMR no endpoint gerenciado por EKS
Você pode se conectar facilmente ao endpoint gerenciado EMR no EKS a partir do espaço de trabalho.
- No painel de navegação, no Clusters menus, selecione Cluster EMR no EKS para Tipo de cluster.
Os clusters virtuais aparecem no menu suspenso EMR Cluster on EKS e o endpoint aparece no menu suspenso Endpoint. Se houver vários endpoints, eles aparecerão aqui e você poderá alternar facilmente entre os endpoints no Workspace. - Selecione o endpoint apropriado e escolha Attach.

Trabalhar com um bloco de notas
Agora você pode abrir um notebook e conectar-se a um kernel preferido para realizar suas tarefas. Por exemplo, você pode selecionar um kernel PySpark, conforme mostrado na captura de tela a seguir.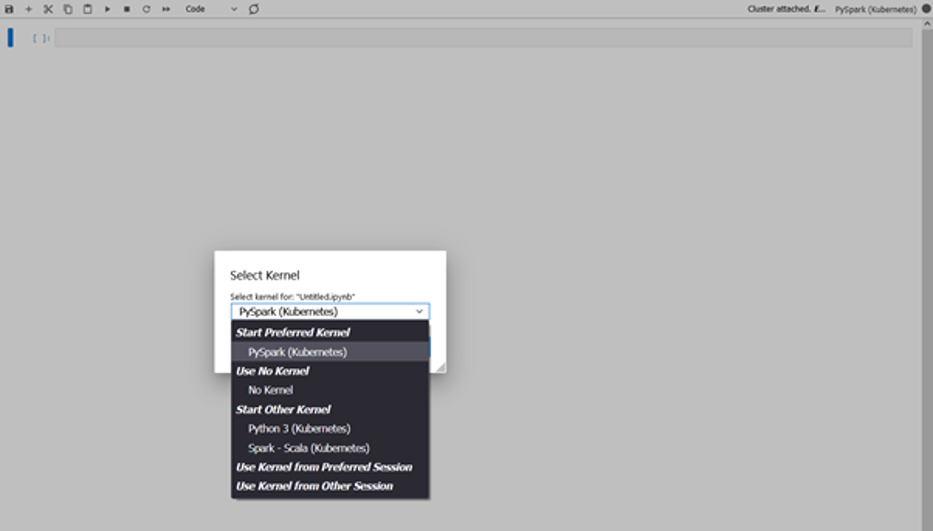
Explore seus dados
A primeira etapa de nosso exercício de exploração de dados é criar uma sessão Spark e, em seguida, carregar o conjunto de dados de táxi de Nova York do balde S3 em um quadro de dados. Use o bloco de código a seguir para carregar os dados em um quadro de dados. Copie o URI do Amazon S3 para o local onde o conjunto de dados reside no Amazon S3.
Depois de carregarmos os dados em um quadro de dados, substituímos os dados do current_date coluna com a data atual atual, conte o número de linhas e salve os dados em um arquivo Parquet:
A captura de tela a seguir mostra o resultado de nosso notebook em execução no Amazon EMR Studio e com o PySpark em execução no Amazon EMR no EKS.
limpar
Para limpar após esta postagem, execute cdk destroy.
Conclusão
Nesta postagem, mostramos como você pode usar o ARA para implantar rapidamente uma infraestrutura de análise de dados e começar a experimentar com seus dados. Você pode encontrar o exemplo completo referenciado nesta postagem no Repositório GitHub. A arquitetura de referência do AWS Analytics implementa o padrão comum do Analytics e as melhores práticas da AWS para oferecer construções prontas para uso em seus experimentos. Um dos padrões é a malha de dados, que você pode consultar como usar neste no blog.
Você também pode explorar outros construções oferecidas nesta biblioteca para experimentar os serviços do AWS Analytics antes de fazer a transição de sua carga de trabalho para produção.
Sobre os autores
 Lotfi Mouhib é arquiteto de soluções sênior e trabalha para a equipe do setor público da Amazon Web Services. Ele ajuda os clientes do setor público em toda a EMEA a concretizar suas ideias, criar novos serviços e inovar para os cidadãos. Em seu tempo livre, Lotfi gosta de andar de bicicleta e correr.
Lotfi Mouhib é arquiteto de soluções sênior e trabalha para a equipe do setor público da Amazon Web Services. Ele ajuda os clientes do setor público em toda a EMEA a concretizar suas ideias, criar novos serviços e inovar para os cidadãos. Em seu tempo livre, Lotfi gosta de andar de bicicleta e correr.
 Sandipan Bhaumik é Arquiteto de Soluções Senior Analytics Specialist baseado em Londres. Ele trabalhou com clientes em diferentes setores, como bancos e serviços financeiros, saúde, energia e serviços públicos, manufatura e varejo, ajudando-os a resolver desafios complexos com plataformas de dados em grande escala. Na AWS, ele se concentra em contas estratégicas no Reino Unido e na Irlanda e ajuda os clientes a acelerar sua jornada para a nuvem e inovar usando análises da AWS e serviços de aprendizado de máquina. Ele adora jogar badminton e ler livros.
Sandipan Bhaumik é Arquiteto de Soluções Senior Analytics Specialist baseado em Londres. Ele trabalhou com clientes em diferentes setores, como bancos e serviços financeiros, saúde, energia e serviços públicos, manufatura e varejo, ajudando-os a resolver desafios complexos com plataformas de dados em grande escala. Na AWS, ele se concentra em contas estratégicas no Reino Unido e na Irlanda e ajuda os clientes a acelerar sua jornada para a nuvem e inovar usando análises da AWS e serviços de aprendizado de máquina. Ele adora jogar badminton e ler livros.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/accelerate-your-data-exploration-and-experimentation-with-the-aws-analytics-reference-architecture-library/
- 1
- 10
- 100
- 11
- 6G
- 7
- 9
- a
- Sobre
- acelerar
- Acesso
- gerenciamento de acesso
- Conta
- Contas
- em
- ações
- Adiciona
- administrativo
- Depois de
- agressivo
- Todos os Produtos
- alocação
- permite
- já
- Apesar
- Amazon
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- análise
- analítica
- e
- apache
- app
- aparecer
- Aplicar
- apropriado
- arquitetura
- argumentos
- Ativos
- associado
- anexar
- atributos
- Autenticação
- autoria
- auto
- disponível
- AWS
- Cola AWS
- AWS Identity and Access Management (IAM)
- Bancário
- baseado
- Porque
- antes
- abaixo
- MELHOR
- melhores práticas
- Melhor
- entre
- Bloquear
- Blog
- Livros
- construir
- construtor
- chamado
- chamadas
- Capacidade
- casas
- casos
- catálogo
- cauteloso
- CD
- certificado
- desafios
- verificar
- Escolha
- Cidadãos
- classe
- classificação
- cliente
- Na nuvem
- Agrupar
- código
- Coluna
- COM
- comum
- completar
- integrações
- Computar
- condição
- Contato
- cônsul
- construir
- contém
- ao controle
- controlador
- Custo
- custos
- crio
- criado
- cria
- Criar
- criação
- crítico
- Atual
- Clientes
- personalizar
- dados,
- análise de dados
- Análise de Dados
- engenheiro de dados
- Data
- datetime
- dedicado
- Padrão
- Define
- implantar
- Implantação
- desenvolvimento
- implanta
- descrição
- detalhes
- Desenvolvimento
- diferente
- discutir
- documento
- Não faz
- não
- motorista
- cada
- facilmente
- efeito
- ou
- EMEA
- habilitado
- permite
- permitindo
- criptografada
- Ponto final
- engenheiro
- Meio Ambiente
- Éter (ETH)
- exemplo
- execução
- Exercício
- experimentar
- especialistas
- exploração
- Análise exploratória de dados
- explorar
- fábrica
- família
- mais rápido
- Federação
- campo
- Envie o
- Arquivos
- financeiro
- serviços financeiros
- Encontre
- Primeiro nome
- concentra-se
- seguir
- seguinte
- segue
- QUADRO
- da
- cheio
- funções
- mais distante
- gerado
- ter
- GitHub
- Go
- Grupo
- Do grupo
- Hadoop
- saúde
- ajuda
- ajuda
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- Alta
- Colméia
- hospedeiro
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTML
- HTTPS
- IAM
- idéias
- Dados de identificação:
- gerenciamento de identidade e acesso
- Gerenciamento de Identidade e Acesso (IAM)
- executar
- implementado
- implementa
- importar
- importante
- melhora
- in
- indústrias
- INFORMAÇÕES
- Infraestrutura
- inovar
- instalar
- instância
- em vez disso
- instruções
- integrado
- interagir
- interativo
- Interface
- interrompido
- Irlanda
- IT
- Trabalho
- Empregos
- viagem
- json
- Guarda
- Kubernetes
- grande
- em grande escala
- APRENDER
- aprendizagem
- Alavancagem
- Biblioteca
- LIMITE
- Line
- linhas
- LINK
- ligado
- Lista
- Listado
- carregar
- localização
- London
- OLHARES
- Baixo
- máquina
- aprendizado de máquina
- gerenciados
- de grupos
- Gerente
- obrigatório
- fabrica
- muitos
- significa
- mecanismo
- Memória
- Menu
- método
- métodos
- Moda
- dinheiro
- mais
- múltiplo
- nome
- Nomeado
- Navegar
- Navegação
- necessário
- você merece...
- necessário
- Cria
- rede
- Novo
- New York
- nó
- nós
- caderno
- laptops
- número
- oferecer
- oferecido
- Oferece
- ONE
- aberto
- otimizado
- Otimiza
- organização
- organizações
- Outros
- próprio
- pão
- parâmetro
- parâmetros
- caminho
- padrão
- padrões
- atuação
- permissão
- permissões
- Fisicamente
- Lugar
- plataforma
- Plataformas
- platão
- Inteligência de Dados Platão
- PlatãoData
- jogar
- vagens
- políticas
- Privacidade
- Publique
- poder
- práticas
- preferido
- anterior
- problemas
- processo
- Subcontratante
- Produção
- Perfis
- projeto
- projetos
- Propriedades
- propriedade
- fornecido
- fornece
- provisão
- público
- rapidamente
- rápido
- Leia
- Leitura
- pronto
- reais
- em tempo real
- perceber
- recomendar
- registros
- reduzir
- reduz
- registrado
- substituir
- representar
- solicitar
- exige
- Recursos
- restringir
- resultar
- varejo
- Tipo
- papéis
- Execute
- corrida
- saquê
- mesmo
- Salvar
- poupança
- Segundo
- Seção
- setor
- segurança
- senior
- sensível
- serviço
- Serviços
- Sessão
- conjunto
- mostrar
- mostrando
- Shows
- embaralhar
- assinar
- simples
- simplificada
- solteiro
- Tamanho
- pequeno
- So
- solução
- Soluções
- RESOLVER
- Faísca
- especialista
- gastar
- gasto
- Spot
- SQL
- pilha
- começo
- começado
- Comece
- declarações
- Status
- Passo
- Passos
- parou
- armazenamento
- armazenadas
- lojas
- Estratégico
- transmitir canais
- estudo
- estúdios
- submissão
- enviar
- apresentado
- sub-redes
- tal
- adequado
- fornecidas
- Apoiar
- Interruptor
- toma
- tarefas
- Profissionais
- modelo
- temporário
- terminal
- A
- do Reino Unido
- deles
- Através da
- Taxa de transferência
- tempo
- para
- também
- Total
- transferência
- Transformação
- transição
- verdadeiro
- tutorial
- tipos
- Datilografado
- Uk
- subjacente
- unidade
- Atualizar
- Atualizações
- carregado
- URI
- usar
- Utilizador
- Interface de Usuário
- usuários
- utilitários
- valor
- Valores
- versão
- controle de versão
- Ver
- Virtual
- volume
- esperar
- web
- serviços web
- O Quê
- qual
- precisarão
- dentro
- Atividades:
- trabalhou
- trabalhador
- fluxos de trabalho
- trabalhar
- escrever
- yaml
- investimentos
- zefirnet