As organizações optaram por construir data lakes em cima de Serviço de armazenamento simples da Amazon (Amazon S3) por muitos anos. Um data lake é a escolha mais popular para as organizações armazenarem todos os seus dados organizacionais gerados por diferentes equipes, entre domínios de negócios, de todos os formatos diferentes e até mesmo ao longo do histórico. De acordo com um estudo, a empresa média está vendo o volume de seus dados crescer a uma taxa superior a 50% ao ano, geralmente gerenciando uma média de 33 fontes de dados exclusivas para análise.
As equipes geralmente tentam replicar milhares de trabalhos de bancos de dados relacionais com o mesmo padrão de extração, transformação e carregamento (ETL). Há muito esforço em manter os estados de trabalho e agendar esses trabalhos individuais. Essa abordagem ajuda as equipes a adicionar tabelas com poucas alterações e também mantém o status do trabalho com o mínimo de esforço. Isso pode levar a uma grande melhoria no cronograma de desenvolvimento e no rastreamento dos trabalhos com facilidade.
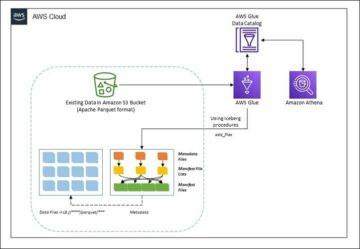
Nesta postagem, mostramos como replicar facilmente todos os seus armazenamentos de dados relacionais em um data lake transacional de maneira automatizada com um único trabalho ETL usando Apache Iceberg e Cola AWS.
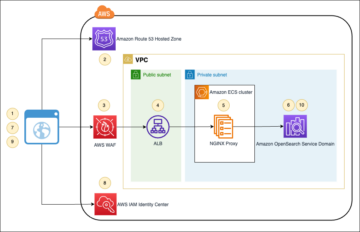
Arquitetura da solução
Os data lakes são geralmente organizado usando baldes S3 separados para três camadas de dados: a camada bruta contendo dados em sua forma original, a camada de estágio contendo dados processados intermediários otimizados para consumo e a camada analítica contendo dados agregados para casos de uso específicos. Na camada bruta, as tabelas geralmente são organizadas com base em suas fontes de dados, enquanto as tabelas na camada de estágio são organizadas com base nos domínios de negócios aos quais pertencem.
Esta postagem fornece um Formação da Nuvem AWS modelo que implanta um trabalho do AWS Glue que lê um caminho do Amazon S3 para uma fonte de dados da camada bruta do data lake e ingere os dados em tabelas Apache Iceberg na camada de palco usando Suporte do AWS Glue para estruturas de data lake. O trabalho espera que as tabelas na camada bruta sejam estruturadas da maneira Serviço de migração de banco de dados AWS (AWS DMS) os ingere: esquema, tabela e arquivos de dados.
Esta solução usa Armazenamento de parâmetros do AWS Systems Manager para configuração de mesa. Você deve modificar este parâmetro especificando as tabelas que deseja processar e como, incluindo informações como chave primária, partições e o domínio de negócios associado. O trabalho usa essas informações para criar automaticamente um banco de dados (se ainda não existir) para cada domínio de negócios, criar as tabelas Iceberg e executar o carregamento de dados.
Finalmente, podemos usar Amazona atena para consultar os dados nas tabelas Iceberg.
O diagrama a seguir ilustra essa arquitetura.

Essa implementação tem as seguintes considerações:
- Todas as tabelas da fonte de dados devem ter uma chave primária para serem replicadas usando esta solução. A chave primária pode ser uma única coluna ou uma chave composta com mais de uma coluna.
- Se o data lake contiver tabelas que não precisem de upserts ou não tenham uma chave primária, você poderá excluí-las da configuração do parâmetro e implementar processos ETL tradicionais para ingeri-las no data lake. Isso está fora do escopo deste post.
- Se houver fontes de dados adicionais que precisam ser ingeridas, você pode implantar várias pilhas do CloudFormation, uma para lidar com cada fonte de dados.
- O trabalho do AWS Glue foi projetado para processar dados em duas fases: o carregamento inicial executado após o AWS DMS concluir a tarefa de carregamento completo e o carregamento incremental executado em uma programação que aplica arquivos de captura de dados alterados (CDC) capturados pelo AWS DMS. O processamento incremental é executado usando um Marcador de trabalho do AWS Glue.
Há nove etapas para concluir este tutorial:
- Configure um endpoint de origem para o AWS DMS.
- Implante a solução usando o AWS CloudFormation.
- Revise a tarefa de replicação do AWS DMS.
- Opcionalmente, adicione permissões para criptografia e descriptografia ou Formação AWS Lake.
- Revise a configuração da tabela no Parameter Store.
- Execute o carregamento de dados inicial.
- Execute o carregamento de dados incremental.
- Monitore a ingestão da tabela.
- Programe o carregamento incremental de dados em lote.
Pré-requisitos
Antes de iniciar este tutorial, você já deve estar familiarizado com o Iceberg. Caso contrário, você pode começar replicando uma única tabela seguindo as instruções em Implemente um UPSERT baseado em CDC em um data lake usando Apache Iceberg e AWS Glue. Além disso, configure o seguinte:
Configurar um endpoint de origem para o AWS DMS
Antes de criarmos nossa tarefa do AWS DMS, precisamos configurar um endpoint de origem para se conectar ao banco de dados de origem:
- No console do AWS DMS, escolha Pontos finais no painel de navegação.
- Escolha Criar ponto final.
- Se seu banco de dados estiver em execução no Amazon RDS, escolha Selecione a instância de banco de dados RDS, em seguida, escolha a instância na lista. Caso contrário, escolha o mecanismo de origem e forneça as informações de conexão por meio de Gerenciador de segredos da AWS ou manualmente.
- Escolha Identificador de terminal, insira um nome para o terminal; por exemplo, source-postgresql.
- Escolha Criar ponto final.
Implante a solução usando AWS CloudFormation
Crie uma pilha do CloudFormation usando o modelo fornecido. Conclua as seguintes etapas:
- Escolha Pilha de lançamento:

- Escolha Próximo.
- Forneça um nome de pilha, como
transactionaldl-postgresql. - Digite os parâmetros necessários:
- DMSS3EndpointIAMRoleARN – O ARN da função IAM para AWS DMS para gravar dados no Amazon S3.
- ReplicaçãoInstanceArn – O ARN da instância de replicação do AWS DMS.
- S3BucketStage – O nome do bucket existente usado para a camada de estágio do data lake.
- S3BaldeCola – O nome do depósito S3 existente para armazenar scripts do AWS Glue.
- S3BucketRaw – O nome do depósito existente usado para a camada bruta do data lake.
- FonteEndpointArn – O ARN do endpoint do AWS DMS que você criou anteriormente.
- Sourcename – O identificador arbitrário da fonte de dados a replicar (por exemplo,
postgres). Isso é usado para definir o caminho S3 do data lake (camada bruta) onde os dados serão armazenados.
- Não modifique os seguintes parâmetros:
- FonteS3BucketBlog – O nome do depósito no qual o script AWS Glue fornecido está armazenado.
- FonteS3BucketPrefix – O nome do prefixo do depósito no qual o script do AWS Glue fornecido está armazenado.
- Escolha Próximo duas vezes.
- Selecionar Eu reconheço que o AWS CloudFormation pode criar recursos IAM com nomes personalizados.
- Escolha Criar pilha.
Após aproximadamente 5 minutos, a pilha do CloudFormation é implantada.
Revise a tarefa de replicação do AWS DMS
A implantação do AWS CloudFormation criou um endpoint de destino do AWS DMS para você. Devido a duas configurações de endpoint específicas, os dados serão ingeridos conforme necessário no Amazon S3.
- No console do AWS DMS, escolha Pontos finais no painel de navegação.
- Pesquise e escolha o endpoint que começa com
dmsIcebergs3endpoint. - Revise as configurações do endpoint:
DataFormaté especificado comoparquet.TimestampColumnNameirá adicionar a colunalast_update_timecom a data de criação dos registros no Amazon S3.

A implantação também cria uma tarefa de replicação do AWS DMS que começa com dmsicebergtask.
- Escolha Tarefas de replicação no painel de navegação e procure a tarefa.
Você verá que o Tipo de Tarefa está marcado como Carga total, replicação contínua. O AWS DMS executará um carregamento completo inicial dos dados existentes e, em seguida, criará arquivos incrementais com alterações realizadas no banco de dados de origem.
No Regras de Mapeamento guia, existem dois tipos de regras:
- Uma regra de seleção com o nome do esquema de origem e as tabelas que serão ingeridas do banco de dados de origem. Por padrão, ele usa o banco de dados de amostra fornecido nos pré-requisitos,
dms_sample, e todas as tabelas com a palavra-chave %. - Duas regras de transformação que incluem nos arquivos de destino no Amazon S3 o nome do esquema e o nome da tabela como colunas. Isso é usado por nosso trabalho do AWS Glue para saber a quais tabelas correspondem os arquivos no data lake.
Para saber mais sobre como personalizar isso para suas próprias fontes de dados, consulte Regras e ações de seleção.

Vamos alterar algumas configurações para finalizar a preparação da nossa tarefa.
- No Opções menu, escolha modificar.
- No Configurações da Tarefa seção, sob Parar a tarefa após a conclusão do carregamento completo, escolha Parar depois de aplicar as alterações em cache.
Dessa forma, podemos controlar a carga inicial e a geração de arquivos incrementais como duas etapas diferentes. Usamos essa abordagem de duas etapas para executar o trabalho do AWS Glue uma vez a cada etapa.
- Debaixo Registros de tarefas, escolha Ativar logs do CloudWatch.
- Escolha Salvar.
- Aguarde cerca de 1 minuto para que o status da tarefa de migração do banco de dados seja exibido como Pronto.
Adicione permissões para criptografia e descriptografia ou Lake Formation
Opcionalmente, você pode adicionar permissões para criptografia e descriptografia ou Lake Formation.
Adicionar permissões de criptografia e descriptografia
Se seus buckets S3 usados para as camadas brutas e de estágio forem criptografados usando Serviço de gerenciamento de chaves AWS (AWS KMS), você precisa adicionar permissões para permitir que o trabalho do AWS Glue acesse os dados:
Adicionar permissões de formação do lago
Se você estiver gerenciando permissões usando o Lake Formation, precisará permitir que seu trabalho do AWS Glue crie os bancos de dados e tabelas de seu domínio por meio da função IAM GlueJobRole.
- Conceda permissões para criar bancos de dados (para obter instruções, consulte Criando um Banco de Dados).
- Conceda permissões SUPER ao
defaultbase de dados. - Conceder permissões de localização de dados.
- Se você criar bancos de dados manualmente, conceda permissões em todos os bancos de dados para criar tabelas. Referir-se Concedendo permissões de tabela usando o console do Lake Formation e o método de recurso nomeado or Concedendo permissões do Data Catalog usando o método LF-TBAC de acordo com o seu caso de uso.
Depois de concluir a etapa posterior de execução do carregamento de dados inicial, certifique-se de incluir também permissões para que os consumidores consultem as tabelas. A função de trabalho se tornará a proprietária de todas as tabelas criadas e o administrador do data lake poderá realizar concessões para usuários adicionais.
Revise a configuração da tabela no Parameter Store
O trabalho do AWS Glue que executa a ingestão de dados em tabelas Iceberg usa a especificação de tabela fornecida no Parameter Store. Conclua as etapas a seguir para revisar o armazenamento de parâmetros que foi configurado automaticamente para você. Se necessário, modifique de acordo com suas próprias necessidades.
- No console Parameter Store, escolha Meus parâmetros no painel de navegação.
A pilha do CloudFormation criou dois parâmetros:
iceberg-configpara configurações de trabalhoiceberg-tablespara configuração de mesa
- Escolha o parâmetro mesas-iceberg.
A estrutura JSON contém informações que o AWS Glue usa para ler dados e gravar as tabelas Iceberg no domínio de destino:
- Um objeto por tabela – O nome do objeto é criado usando o nome do esquema, um ponto e o nome da tabela; por exemplo,
schema.table. - chave primária – Isso deve ser especificado para cada tabela de origem. Você pode fornecer uma única coluna ou uma lista de colunas separadas por vírgulas (sem espaços).
- partiçãoCols – Isso opcionalmente particiona colunas para tabelas de destino. Se você não deseja criar tabelas particionadas, forneça uma string vazia. Caso contrário, forneça uma única coluna ou uma lista separada por vírgulas de colunas a serem usadas (sem espaços).
- Se você quiser usar sua própria fonte de dados, use o seguinte código JSON e substitua o texto em CAPS do modelo fornecido. Se você estiver usando a fonte de dados de amostra fornecida, mantenha as configurações padrão:
{ "SCHEMA_NAME.TABLE_NAME_1": { "primaryKey": "ONLY_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "" }, "SCHEMA_NAME.TABLE_NAME_2": { "primaryKey": "FIRST_PRIMARY_KEY,SECOND_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "PARTITION_COLUMN_ONE,PARTITION_COLUMN_TWO" }
}- Escolha Salvar as alterações .
Execute o carregamento inicial de dados
Agora que a configuração necessária foi concluída, ingerimos os dados iniciais. Esta etapa inclui três partes: ingerir os dados do banco de dados relacional de origem na camada bruta do data lake, criar as tabelas Iceberg na camada de estágio do data lake e verificar os resultados usando o Athena.
Ingerir dados na camada bruta do data lake
Para ingerir dados da fonte de dados relacional (PostgreSQL se você estiver usando o exemplo fornecido) para nosso data lake transacional usando o Iceberg, conclua as seguintes etapas:
- No console do AWS DMS, escolha Tarefas de migração de banco de dados no painel de navegação.
- Selecione a tarefa de replicação que você criou e no Opções menu, escolha Reiniciar/Retomar.
- Aguarde cerca de 5 minutos para que a tarefa de replicação seja concluída. Você pode monitorar as tabelas ingeridas no Estatísticas guia da tarefa de replicação.

Após alguns minutos, a tarefa termina com a mensagem Carga completa concluída.
- No console do Amazon S3, escolha o bucket que você definiu como a camada bruta.
Sob o prefixo S3 definido no AWS DMS (por exemplo, postgres), você deverá ver uma hierarquia de pastas com a seguinte estrutura:
- Esquema
- Nome da mesa
LOAD00000001.parquetLOAD0000000N.parquet
- Nome da mesa

Se seu bucket S3 estiver vazio, revise Solução de problemas de tarefas de migração no AWS Database Migration Service antes de executar o trabalho do AWS Glue.
Criar e ingerir dados em tabelas Iceberg
Antes de executar o trabalho, vamos navegar pelo script do trabalho do AWS Glue fornecido como parte da pilha do CloudFormation para entender seu comportamento.
- No console do AWS Glue Studio, escolha Empregos no painel de navegação.
- Pesquise a vaga que começa com
IcebergJob-e um sufixo do nome da pilha do CloudFormation (por exemplo,IcebergJob-transactionaldl-postgresql). - Escolha o trabalho.

O script de trabalho obtém a configuração necessária do Parameter Store. A função getConfigFromSSM() retorna configurações relacionadas ao trabalho, como buckets de origem e destino, de onde os dados precisam ser lidos e gravados. a variável ssmparam_table_values contêm informações relacionadas à tabela, como domínio de dados, nome da tabela, colunas de partição e chave primária das tabelas que precisam ser ingeridas. Veja o seguinte código Python:
# Main application
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'stackName'])
SSM_PARAMETER_NAME = f"{args['stackName']}-iceberg-config"
SSM_TABLE_PARAMETER_NAME = f"{args['stackName']}-iceberg-tables" # Parameters for job
rawS3BucketName, rawBucketPrefix, stageS3BucketName, warehouse_path = getConfigFromSSM(SSM_PARAMETER_NAME)
ssm_param_table_values = json.loads(ssmClient.get_parameter(Name = SSM_TABLE_PARAMETER_NAME)['Parameter']['Value'])
dropColumnList = ['db','table_name', 'schema_name','Op', 'last_update_time', 'max_op_date']O script usa um nome de catálogo arbitrário para Iceberg que é definido como my_catalog. Isso é implementado no Catálogo de dados do AWS Glue usando configurações do Spark, portanto, uma operação SQL apontando para my_catalog será aplicada no Catálogo de dados. Veja o seguinte código:
catalog_name = 'my_catalog'
errored_table_list = [] # Iceberg configuration
spark = SparkSession.builder .config('spark.sql.warehouse.dir', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') .config(f'spark.sql.catalog.{catalog_name}.warehouse', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}.catalog-impl', 'org.apache.iceberg.aws.glue.GlueCatalog') .config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') .getOrCreate()
O script itera sobre as tabelas definidas no Parameter Store e executa a lógica para detectar se a tabela existe e se os dados recebidos são um carregamento inicial ou um upsert:
# Iteration over tables stored on Parameter Store
for key in ssm_param_table_values: # Get table data isTableExists = False schemaName, tableName = key.split('.') logger.info(f'Processing table : {tableName}')A initialLoadRecordsSparkSQL() A função carrega os dados iniciais quando nenhuma coluna de operação está presente nos arquivos S3. O AWS DMS adiciona esta coluna apenas aos arquivos de dados Parquet produzidos pela replicação contínua (CDC). O carregamento de dados é realizado usando o comando INSERT INTO com SparkSQL. Veja o seguinte código:
sqltemp = Template(""" INSERT INTO $catalog_name.$dbName.$tableName ($insertTableColumnList) SELECT $insertTableColumnList FROM insertTable $partitionStrSQL """)
SQLQUERY = sqltemp.substitute( catalog_name = catalog_name, dbName = dbName, tableName = tableName, insertTableColumnList = insertTableColumnList[ : -1], partitionStrSQL = partitionStrSQL) logger.info(f'****SQL QUERY IS : {SQLQUERY}')
spark.sql(SQLQUERY)
Agora executamos o trabalho do AWS Glue para inserir os dados iniciais nas tabelas Iceberg. A pilha do CloudFormation adiciona o --datalake-formats parâmetro, adicionando as bibliotecas Iceberg necessárias ao trabalho.
- Escolha Executar trabalho.
- Escolha Execuções de trabalho para monitorar o estado. Aguarde até que o status seja Executado com sucesso.
Verifique os dados carregados
Para confirmar se a tarefa processou os dados conforme o esperado, conclua as seguintes etapas:
- No console Athena, escolha Editor de consulta no painel de navegação.
- verificar
AwsDataCatalogé selecionado como fonte de dados. - Debaixo banco de dados, escolha o domínio de dados que deseja explorar, com base na configuração definida no armazenamento de parâmetros. Se estiver usando o banco de dados de amostra fornecido, use
sports.
Debaixo Tabelas e visualizações, podemos ver a lista de tabelas que foram criadas pelo trabalho do AWS Glue.
- Escolha o menu de opções (três pontos) ao lado do primeiro nome da tabela e escolha Visualizar dados.
Você pode ver os dados carregados nas tabelas do Iceberg. 
Executar carregamento de dados incremental
Agora começamos a capturar as alterações de nosso banco de dados relacional e aplicá-las ao data lake transacional. Essa etapa também é dividida em três partes: capturar as alterações, aplicá-las nas tabelas Iceberg e verificar os resultados.
Capturar alterações do banco de dados relacional
Devido à configuração que especificamos, a tarefa de replicação parou após a execução da fase de carga total. Agora reiniciamos a tarefa para adicionar arquivos incrementais com alterações na camada bruta do data lake.
- No console do AWS DMS, selecione a tarefa que criamos e executamos anteriormente.
- No Opções menu, escolha CV .
- Escolha Iniciar tarefa para começar a capturar as alterações.
- Para acionar a criação de um novo arquivo no data lake, execute inserções, atualizações ou exclusões nas tabelas de seu banco de dados de origem usando sua ferramenta de administração de banco de dados preferida. Se estiver usando o banco de dados de amostra fornecido, você pode executar os seguintes comandos SQL:
UPDATE dms_sample.nfl_stadium_data_upd
SET seatin_capacity=93703
WHERE team = 'Los Angeles Rams' and sport_location_id = '31'; update dms_sample.mlb_data set bats = 'R'
where mlb_id=506560 and bats='L'; update dms_sample.sporting_event set start_date = current_date where id=11 and sold_out=0;
- Na página de detalhes da tarefa do AWS DMS, escolha o Estatísticas da tabela guia para ver as alterações capturadas.

- Abra a camada bruta do data lake para encontrar um novo arquivo contendo as alterações incrementais dentro do prefixo de cada tabela, por exemplo, sob o
sporting_eventprefixo.
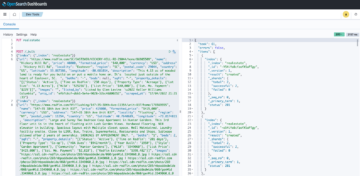
O registro com alterações para o sporting_event tabela se parece com a captura de tela a seguir.

Observe a Op coluna no início identificada com uma atualização (U). Além disso, o segundo valor de data/hora é a coluna de controle adicionada pelo AWS DMS com a hora em que a alteração foi capturada.

Aplicar alterações nas tabelas Iceberg usando o AWS Glue
Agora, executamos o trabalho do AWS Glue novamente e ele processará automaticamente apenas os novos arquivos incrementais, pois o marcador de trabalho está ativado. Vamos revisar como funciona.
A dedupCDCRecords() A função executa a desduplicação de dados porque várias alterações em um único ID de registro podem ser capturadas no mesmo arquivo de dados no Amazon S3. A desduplicação é realizada com base no last_update_time coluna adicionada pelo AWS DMS que indica o carimbo de data/hora de quando a alteração foi capturada. Veja o seguinte código Python:
def dedupCDCRecords(inputDf, keylist): IDWindowDF = Window.partitionBy(*keylist).orderBy(inputDf.last_update_time).rangeBetween(-sys.maxsize, sys.maxsize) inputDFWithTS = inputDf.withColumn('max_op_date', max(inputDf.last_update_time).over(IDWindowDF)) NewInsertsDF = inputDFWithTS.filter('last_update_time=max_op_date').filter("op='I'") UpdateDeleteDf = inputDFWithTS.filter('last_update_time=max_op_date').filter("op IN ('U','D')") finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf) return finalInputDFNa linha 99, o upsertRecordsSparkSQL() A função executa o upsert de maneira semelhante ao carregamento inicial, mas desta vez com um comando SQL MERGE.
Revise as alterações aplicadas
Abra o console do Athena e execute uma consulta que selecione os registros alterados no banco de dados de origem. Se estiver usando o banco de dados de amostra fornecido, use uma das seguintes consultas SQL:
SELECT * FROM "sports"."nfl_stadiu_data_upd"
WHERE team = 'Los Angeles Rams' and sport_location_id = 31
LIMIT 1;

Monitorar ingestão de tabelas
O script de trabalho do AWS Glue é codificado com simples Manipulação de exceção do Python para capturar erros durante o processamento de uma tabela específica. O marcador de trabalho é salvo depois que cada tabela termina o processamento com êxito, para evitar o reprocessamento de tabelas se a execução do trabalho for repetida para as tabelas com erros.
A Interface de linha de comando da AWS (AWS CLI) fornece um get-job-bookmark comando para AWS Glue que fornece informações sobre o status do marcador para cada tabela processada.
- No console do AWS Glue Studio, escolha o trabalho ETL.
- Escolha o Execuções de trabalho guia e copie o ID de execução da tarefa.
- Execute o seguinte comando em um terminal autenticado para a AWS CLI, substituindo
<GLUE_JOB_RUN_ID>na linha 1 com o valor que você copiou. Se sua pilha do CloudFormation não for nomeadatransactionaldl-postgresql, forneça o nome do seu trabalho na linha 2 do script:
jobrun=<GLUE_JOB_RUN_ID>
jobname=IcebergJob-transactionaldl-postgresql
aws glue get-job-bookmark --job-name jobname --run-id $jobrunNesta solução, quando o processamento de uma tabela causa uma exceção, o trabalho do AWS Glue não falhará de acordo com essa lógica. Em vez disso, a tabela será adicionada a uma matriz que será impressa após a conclusão do trabalho. Nesse cenário, o trabalho será marcado como com falha após tentar processar o restante das tabelas detectadas na fonte de dados brutos. Desta forma, tabelas sem erros não precisam esperar até que o usuário identifique e resolva o problema nas tabelas conflitantes. O usuário pode detectar rapidamente execuções de trabalho que tiveram problemas usando o status de execução de trabalho do AWS Glue e identificar quais tabelas específicas estão causando o problema usando os logs do CloudWatch para a execução do trabalho.
- O script de trabalho implementa esse recurso com o seguinte código Python:
# Performed for every table try: # Table processing logic except Exception as e: logger.info(f'There is an issue with table: {tableName}') logger.info(f'The exception is : {e}') errored_table_list.append(tableName) continue job.commit()
if (len(errored_table_list)): logger.info('Total number of errored tables are ',len(errored_table_list)) logger.info('Tables that failed during processing are ', *errored_table_list, sep=', ') raise Exception(f'***** Some tables failed to process.')A captura de tela a seguir mostra como os logs do CloudWatch procuram tabelas que causam erros no processamento.

Alinhado com o Lente de análise de dados do AWS Well-Architected Framework práticas, você pode adaptar mecanismos de controle mais sofisticados para identificar e notificar as partes interessadas quando erros aparecem nos pipelines de dados. Por exemplo, você pode usar um Amazon DynamoDB tabela de controle para armazenar todas as tabelas e execuções de trabalho com erros, ou usando Serviço de notificação simples da Amazon (Amazon SNS) para enviar alertas aos operadores quando determinados critérios são atendidos.
Agendar carregamento incremental de dados em lote
A pilha do CloudFormation implanta um Amazon Event Bridge regra (desativada por padrão) que pode acionar a execução do trabalho do AWS Glue em uma programação. Para fornecer sua própria programação e habilitar a regra, conclua as seguintes etapas:
- No console do EventBridge, escolha Regras no painel de navegação.
- Pesquise a regra prefixada com o nome de sua pilha do CloudFormation seguida por
JobTrigger(por exemplo,transactionaldl-postgresql-JobTrigger-randomvalue). - Escolha a regra.
- Debaixo Calendário de eventos, escolha Editar.
A programação padrão é configurada para disparar a cada hora.
- Forneça a programação em que deseja executar o trabalho.
- Além disso, você pode usar um Expressão cron do EventBridge selecionando Um cronograma refinado.

- Ao terminar de configurar a expressão cron, escolha Próximo três vezes e, finalmente, escolha regra de atualização para salvar as alterações.
A regra é criada desativada por padrão para permitir que você execute o carregamento de dados inicial primeiro.
- Ative a regra escolhendo permitir.
Você pode usar o do Paciente guia para visualizar invocações de regras ou diretamente no AWS Glue Execução de trabalho Detalhes.
Conclusão
Depois de implantar esta solução, você automatizou a ingestão de suas tabelas em uma única fonte de dados relacional. As organizações que usam um data lake como plataforma de dados central geralmente precisam lidar com várias, às vezes até dezenas de fontes de dados. Além disso, cada vez mais casos de uso exigem que as organizações implementem recursos transacionais no data lake. Você pode usar esta solução para acelerar a adoção de tais recursos em todas as suas fontes de dados relacionais para habilitar novos casos de uso de negócios, automatizando o processo de implementação para obter mais valor de seus dados.
Sobre os autores
 Luís Gerardo Baeza é arquiteto de big data no laboratório de dados da Amazon Web Services (AWS). Ele tem 12 anos de experiência ajudando organizações nos setores de saúde, financeiro e educação a adotar programas de arquitetura corporativa, computação em nuvem e recursos de análise de dados. Luis atualmente ajuda organizações em toda a América Latina a acelerar iniciativas estratégicas de dados.
Luís Gerardo Baeza é arquiteto de big data no laboratório de dados da Amazon Web Services (AWS). Ele tem 12 anos de experiência ajudando organizações nos setores de saúde, financeiro e educação a adotar programas de arquitetura corporativa, computação em nuvem e recursos de análise de dados. Luis atualmente ajuda organizações em toda a América Latina a acelerar iniciativas estratégicas de dados.
 SaiKiran Reddy Aenugu é arquiteto de dados no laboratório de dados da Amazon Web Services (AWS). Ele tem 10 anos de experiência na implementação de processos de carregamento, transformação e visualização de dados. Atualmente, a SaiKiran ajuda organizações na América do Norte a adotar arquiteturas de dados modernas, como data lakes e data mesh. Tem experiência nos setores de varejo, aéreo e financeiro.
SaiKiran Reddy Aenugu é arquiteto de dados no laboratório de dados da Amazon Web Services (AWS). Ele tem 10 anos de experiência na implementação de processos de carregamento, transformação e visualização de dados. Atualmente, a SaiKiran ajuda organizações na América do Norte a adotar arquiteturas de dados modernas, como data lakes e data mesh. Tem experiência nos setores de varejo, aéreo e financeiro.
 Narendra Merla é arquiteto de dados no laboratório de dados da Amazon Web Services (AWS). Ele tem 12 anos de experiência em projetar e produzir pipelines de dados em tempo real e orientados a lotes e criar data lakes em ambientes de nuvem e locais. Narendra atualmente ajuda organizações na América do Norte a construir e projetar arquiteturas de dados robustas e tem experiência nos setores de telecomunicações e finanças.
Narendra Merla é arquiteto de dados no laboratório de dados da Amazon Web Services (AWS). Ele tem 12 anos de experiência em projetar e produzir pipelines de dados em tempo real e orientados a lotes e criar data lakes em ambientes de nuvem e locais. Narendra atualmente ajuda organizações na América do Norte a construir e projetar arquiteturas de dados robustas e tem experiência nos setores de telecomunicações e finanças.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/automate-replication-of-relational-sources-into-a-transactional-data-lake-with-apache-iceberg-and-aws-glue/
- 1
- 10
- 100
- 102
- 107
- 7
- a
- Sobre
- acelerar
- Acesso
- Segundo
- reconhecer
- em
- adaptar
- adicionado
- Adicional
- Adicionalmente
- Adiciona
- admin
- administração
- adotar
- Adoção
- Depois de
- companhia aérea
- Todos os Produtos
- já
- Amazon
- Amazona atena
- Amazon RDS
- Amazon Web Services
- Amazon Web Services (AWS)
- América
- análise
- analítica
- e
- Angeles
- apache
- aparecer
- Aplicação
- aplicado
- Aplicando
- abordagem
- aproximadamente
- arquitetura
- Ordem
- associado
- autenticado
- automatizar
- Automatizado
- automaticamente
- automatizando
- média
- evitar
- AWS
- Formação da Nuvem AWS
- Cola AWS
- baseado
- morcegos
- Porque
- tornam-se
- antes
- Começo
- Grande
- Big Data
- construir
- construtor
- Prédio
- negócio
- Pode obter
- capacidades
- tampas
- capturar
- Capturar
- casas
- casos
- catálogo
- luta
- Causar
- causas
- causando
- CDC
- central
- certo
- alterar
- Alterações
- escolha
- Escolha
- escolha
- escolhido
- Na nuvem
- computação em nuvem
- código
- Coluna
- colunas
- Empresa
- completar
- computação
- Configuração
- configurações
- Confirmar
- Conflitante
- CONTATE-NOS
- da conexão
- Considerações
- cônsul
- Consumidores
- consumo
- contém
- continuar
- contínuo
- ao controle
- poderia
- crio
- criado
- cria
- Criar
- criação
- critérios
- Atualmente
- personalizadas
- cliente
- personalizar
- dados,
- Análise de Dados
- lago data
- Plataforma de dados
- banco de dados
- bases de dados
- Data
- Padrão
- definido
- implantar
- implantado
- Implantação
- desenvolvimento
- implanta
- Design
- projetado
- concepção
- detalhes
- detectou
- Desenvolvimento
- diferente
- diretamente
- inválido
- dividido
- Não faz
- domínio
- domínios
- não
- durante
- cada
- Mais cedo
- facilmente
- Educação
- esforço
- ou
- permitir
- habilitado
- criptografada
- criptografia
- Ponto final
- Motor
- Entrar
- Empreendimento
- ambientes
- erros
- Éter (ETH)
- Mesmo
- Cada
- exemplo
- excede
- Exceto
- exceção
- existente
- existe
- esperado
- espera
- vasta experiência
- explorar
- extensões
- extrato
- fracassado
- familiar
- Moda
- Característica
- poucos
- Envie o
- Arquivos
- Finalmente
- financiar
- financeiro
- Encontre
- acabamento
- Primeiro nome
- seguido
- seguinte
- Para os consumidores
- formulário
- treinamento
- Quadro
- da
- cheio
- função
- gerado
- geração
- ter
- conceder
- subsídios
- Crescente
- manipular
- saúde
- ajuda
- ajuda
- hierarquia
- história
- segurando
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- HTTPS
- enorme
- IAM
- identificado
- identificador
- identifica
- identificar
- executar
- implementação
- implementado
- implementação
- implementa
- melhoria
- in
- incluir
- inclui
- Incluindo
- Entrada
- indicam
- Individual
- INFORMAÇÕES
- do estado inicial,
- iniciativas
- Inserções
- introspecção
- instância
- em vez disso
- instruções
- Nível intermediário
- emitem
- questões
- IT
- iteração
- Trabalho
- Empregos
- json
- Guarda
- Chave
- chaves
- Saber
- laboratório
- lago
- latino
- América Latina
- camada
- camadas
- conduzir
- APRENDER
- bibliotecas
- LIMITE
- Line
- Lista
- carregar
- carregamento
- cargas
- localização
- olhar
- OLHARES
- os
- Los Angeles
- lote
- a Principal
- mantém
- fazer
- gerenciados
- de grupos
- Gerente
- gestão
- manualmente
- muitos
- mapeamento
- marcado
- Menu
- ir
- mensagem
- poder
- migração
- mínimo
- minuto
- minutos
- EQUIPAMENTOS
- modificar
- Monitore
- monitoração
- mais
- a maioria
- Mais populares
- múltiplo
- nome
- Nomeado
- nomes
- Navegar
- Navegação
- você merece...
- necessário
- Cria
- Novo
- Próximo
- Norte
- América do Norte
- notificação
- número
- objeto
- objetos
- ONE
- contínuo
- OP
- operação
- otimizado
- Opções
- organizacional
- organizações
- Organizado
- original
- de outra forma
- lado de fora
- próprio
- proprietário
- pão
- parâmetro
- parâmetros
- parte
- peças
- caminho
- padrão
- realizar
- realização
- executa
- significativo
- permissões
- fase
- plataforma
- platão
- Inteligência de Dados Platão
- PlatãoData
- Popular
- Publique
- Postgresql
- práticas
- preferido
- pré-requisitos
- presente
- primário
- Problema
- processo
- processos
- em processamento
- Produzido
- Programas
- fornecer
- fornecido
- fornece
- Python
- rapidamente
- aumentar
- Taxa
- Cru
- dados não tratados
- Leia
- em tempo real
- registro
- registros
- substituir
- replicado
- réplica
- requerer
- requeridos
- recurso
- Recursos
- DESCANSO
- Resultados
- varejo
- retorno
- Retorna
- rever
- uma conta de despesas robusta
- Tipo
- Regra
- regras
- Execute
- corrida
- mesmo
- Salvar
- cenário
- cronograma
- escopo
- Scripts
- Pesquisar
- Segundo
- Setores
- visto
- selecionado
- selecionando
- doadores,
- separado
- Serviços
- conjunto
- contexto
- Configurações
- rede de apoio social
- mostrar
- Shows
- semelhante
- simples
- desde
- solteiro
- So
- solução
- Resolve
- alguns
- sofisticado
- fonte
- Fontes
- espaços
- Faísca
- específico
- especificação
- especificada
- Esportes
- SQL
- pilha
- Pilhas
- Etapa
- partes interessadas
- começo
- começado
- Comece
- começa
- Unidos
- estatística
- Status
- Passo
- Passos
- parou
- armazenamento
- loja
- armazenadas
- lojas
- Estratégico
- estrutura
- estruturada
- estudo
- entraram com sucesso
- tal
- super
- ajuda
- sistemas
- mesa
- Target
- Tarefa
- tarefas
- Profissionais
- equipes
- telecom
- modelo
- terminal
- A
- A fonte
- deles
- milhares
- três
- Através da
- tempo
- linha do tempo
- vezes
- timestamp
- para
- ferramenta
- topo
- Total
- Rastreamento
- tradicional
- transacional
- Transformar
- Transformação
- desencadear
- tutorial
- tipos
- para
- compreender
- único
- Atualizar
- Atualizações
- usar
- caso de uso
- Utilizador
- usuários
- geralmente
- valor
- verificação
- Ver
- visualização
- volume
- esperar
- Armazém
- web
- serviços web
- qual
- precisarão
- dentro
- sem
- trabalho
- escrever
- escrito
- yaml
- ano
- anos
- investimentos
- zefirnet