Se você opera em um país com vários idiomas oficiais ou em várias regiões, seus arquivos de áudio podem conter idiomas diferentes. Os participantes podem estar falando idiomas totalmente diferentes ou podem alternar entre idiomas. Considere uma chamada de atendimento ao cliente para relatar um problema em uma área com uma população multilíngue substancial. Embora a conversa possa começar em um idioma, é possível que o cliente mude para outro idioma para descrever o problema, dependendo do nível de conforto ou das preferências de uso de outros idiomas. Da mesma forma, o representante de atendimento ao cliente pode fazer a transição entre os idiomas enquanto transmite instruções de operação ou solução de problemas.
Com um mínimo de 3 segundos de áudio, Amazon Transcribe pode identificar automaticamente e gerar transcrições com eficiência nos idiomas falados no áudio sem a necessidade de humanos para especificar os idiomas. Isso se aplica a vários casos de uso, como transcrição de chamadas de clientes, conversão de correio de voz em texto, captura de interações de reuniões, rastreamento de comunicações de fóruns de usuários ou monitoramento de produção de conteúdo de mídia e fluxos de trabalho de localização.
Esta postagem descreve as etapas para transcrever um arquivo de áudio multilíngue usando o Amazon Transcribe. Discutimos como disponibilizar arquivos de áudio para o Amazon Transcribe e habilitar a transcrição de arquivos de áudio multilíngues ao chamar as APIs do Amazon Transcribe.
Visão geral da solução
O Amazon Transcribe é um serviço da AWS que facilita a conversão de fala em texto. Adicionar funcionalidade de fala a texto a qualquer aplicativo é simples com a ajuda do Amazon Transcribe, um serviço de reconhecimento de fala automatizado (ASR). Você pode receber entrada de áudio usando o Amazon Transcribe, criar transcrições claras que são fáceis de ler e revisar, aumentar a precisão com personalização e filtrar informações para proteger a privacidade do cliente.
A solução também utiliza Serviço de armazenamento simples da Amazon (Amazon S3), um serviço de armazenamento de objetos criado para armazenar e recuperar qualquer quantidade de dados de qualquer lugar. É um serviço de armazenamento simples que oferece durabilidade, disponibilidade, desempenho, segurança e escalabilidade praticamente ilimitada a um custo muito baixo. Ao armazenar dados no Amazon S3, você trabalha com recursos conhecidos como baldes e objetos. Um balde é um recipiente para objetos. Um objeto é um arquivo e qualquer metadado que descreva o arquivo.
Nesta postagem, orientamos você pelas seguintes etapas para implementar uma solução de transcrição de áudio multilíngue:
- Crie um bucket do S3.
- Carregue seu arquivo de áudio para o balde.
- Crie o trabalho de transcrição.
- Revise a saída do trabalho.
Pré-requisitos
Para este passo a passo, você deve ter os seguintes pré-requisitos:
O Amazon Transcribe oferece a opção de armazenar a saída transcrita em um bucket S3 gerenciado por serviço ou gerenciado pelo cliente. Para esta postagem, o Amazon Transcribe grava os resultados em um bucket do S3 gerenciado por serviço.
Observe que o Amazon Transcribe é um serviço regional e os endpoints da API do Amazon Transcribe que estão sendo chamados precisam estar na mesma região que os buckets do S3.
Crie um bucket S3 para armazenar seus arquivos de entrada de áudio
Para criar seu bucket S3, conclua as seguintes etapas:
- No console do Amazon S3, escolha Criar balde.

- Escolha Nome do intervalo, insira um nome globalmente exclusivo para o depósito.
- Escolha Região AWS, escolha a mesma região dos endpoints da API do Amazon Transcribe.
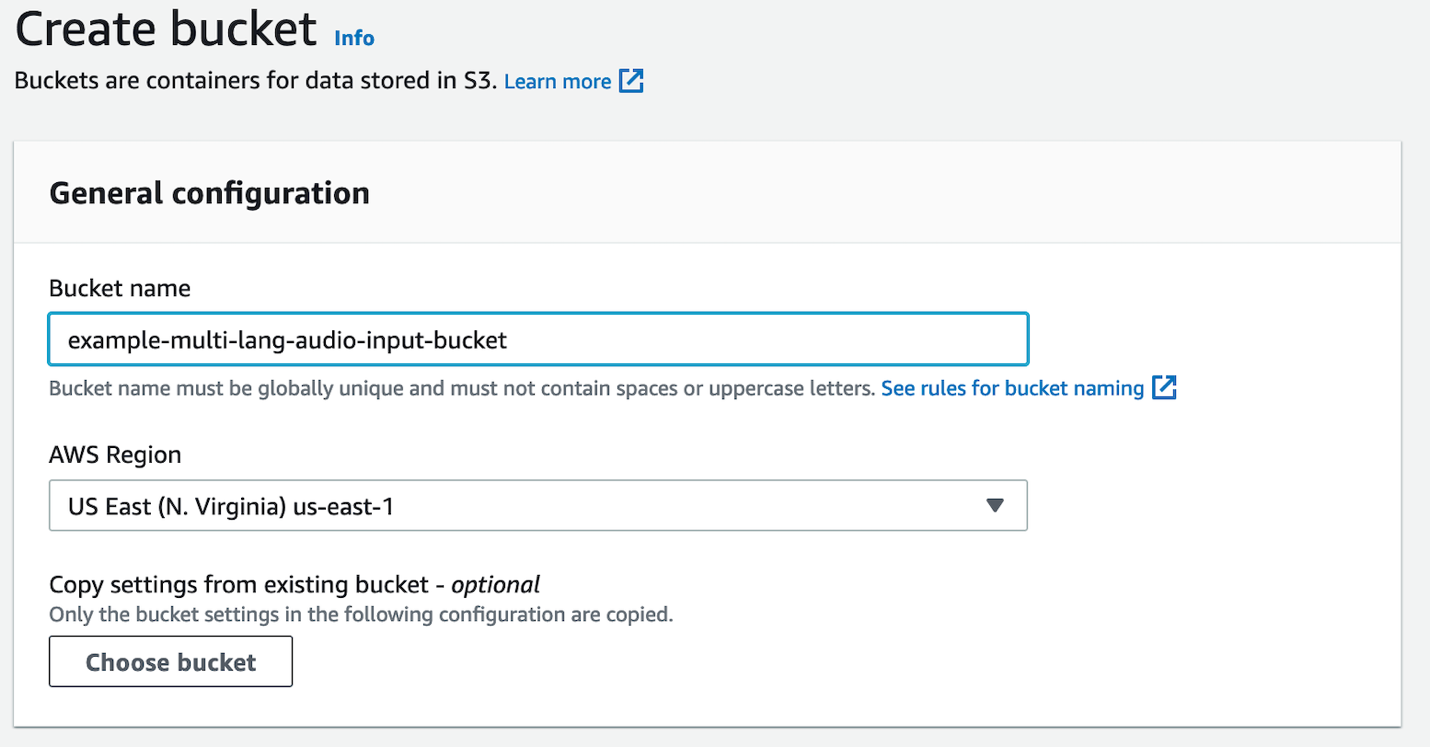
- Deixe todos os padrões como estão.
- Escolha Criar balde.
Carregue seu arquivo de áudio para o balde S3
Carregue seu arquivo de áudio multilíngue para o bucket S3 em sua conta da AWS. Para o propósito deste exercício, usamos o seguinte exemplo arquivo de áudio multilíngue. Ele captura uma chamada de suporte ao cliente envolvendo os idiomas inglês e espanhol.
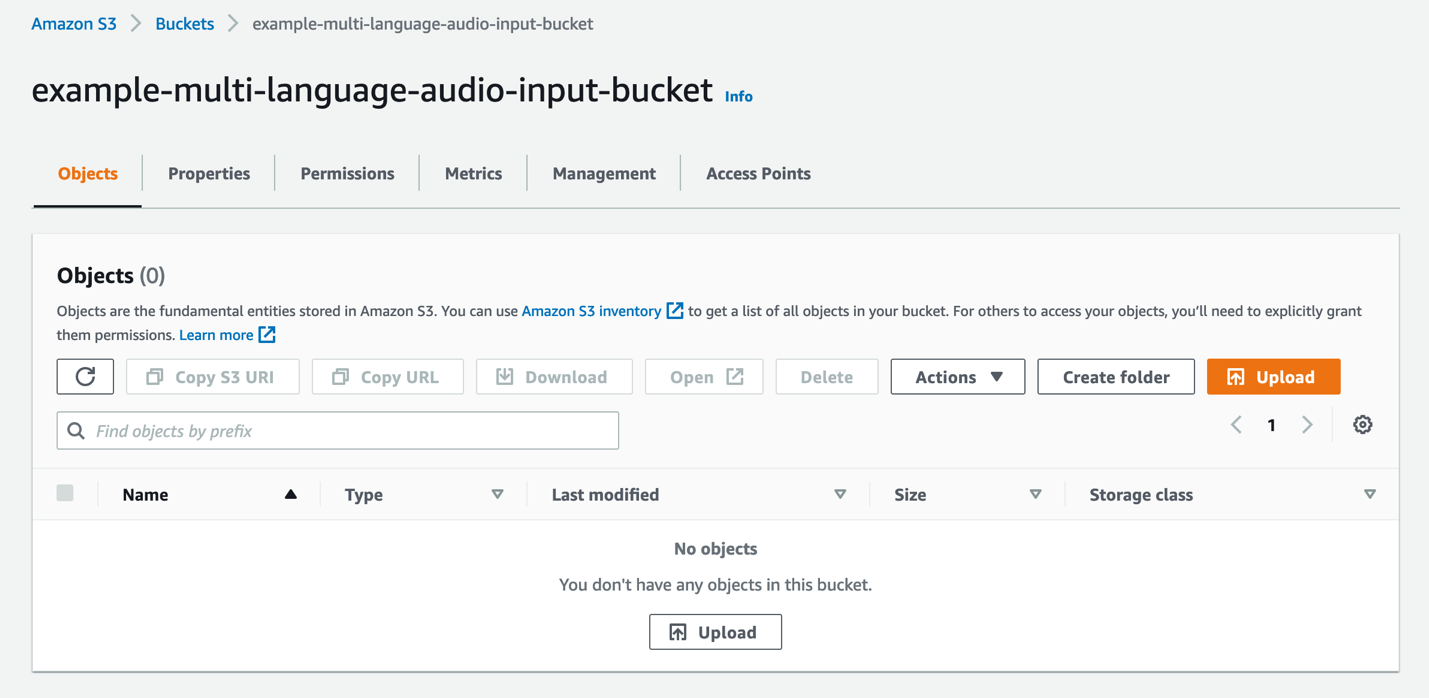
- No console do Amazon S3, escolha Baldes no painel de navegação.
- Escolha o balde que você criou anteriormente para armazenar os arquivos de áudio de entrada.
- Escolha Escolher arquivo.
- Escolha Adicionar arquivos.
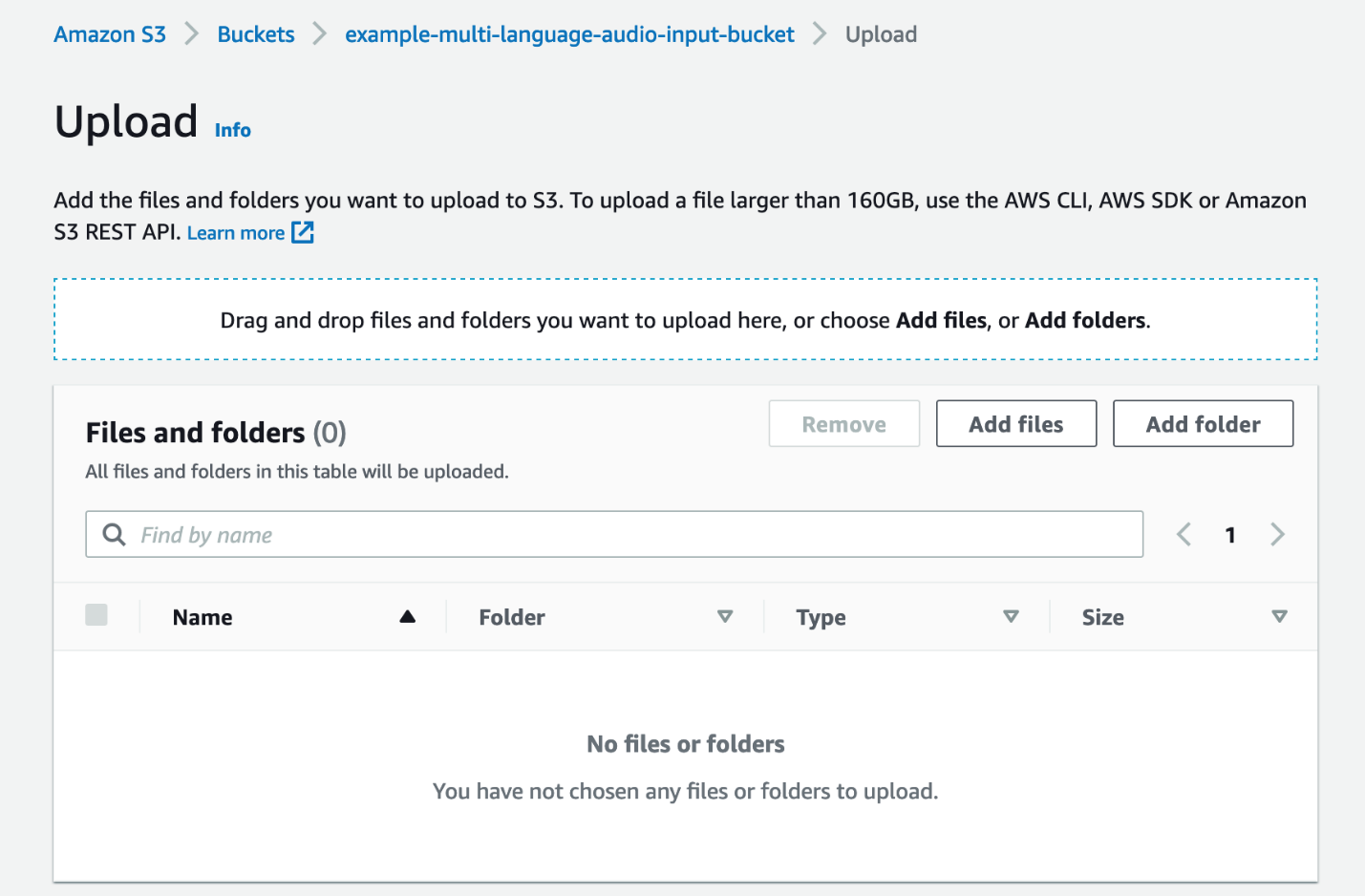
- Escolha o arquivo de áudio que deseja transcrever do seu computador local.
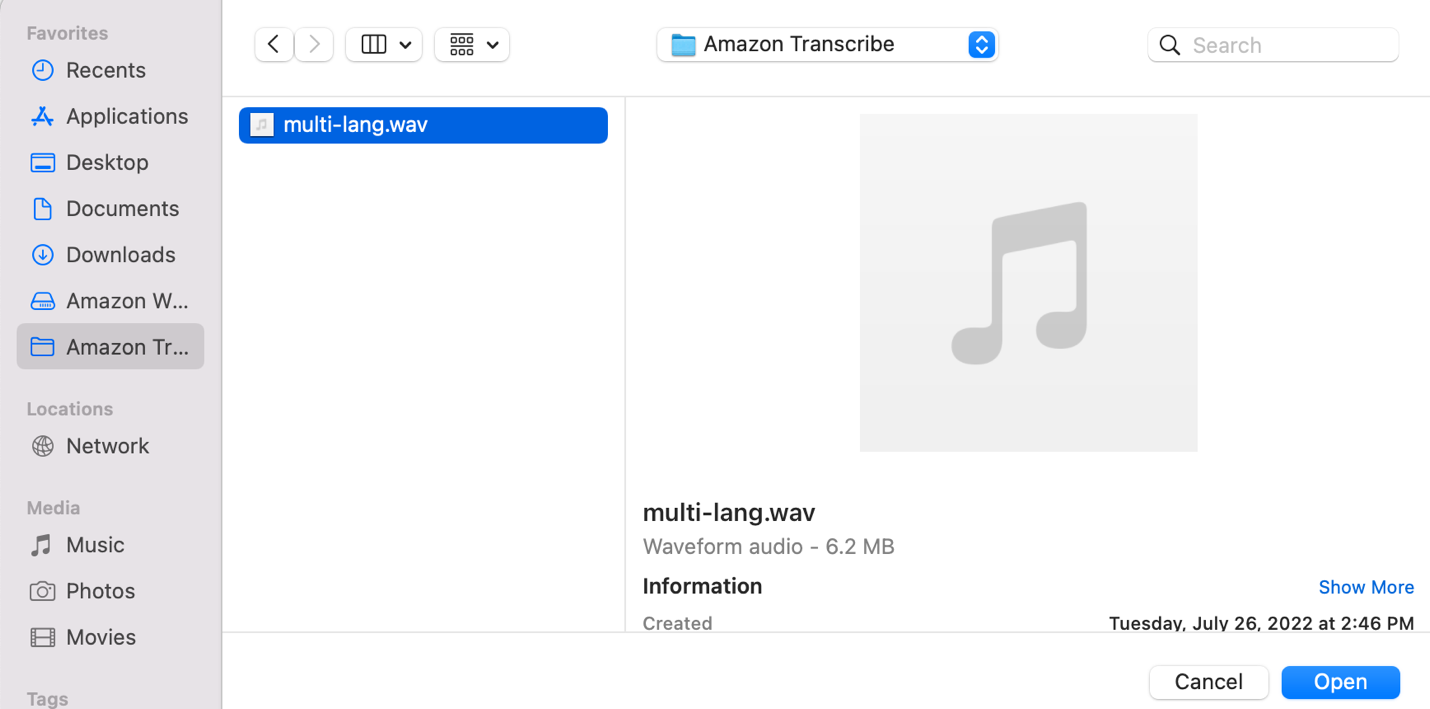
- Escolha Escolher arquivo.
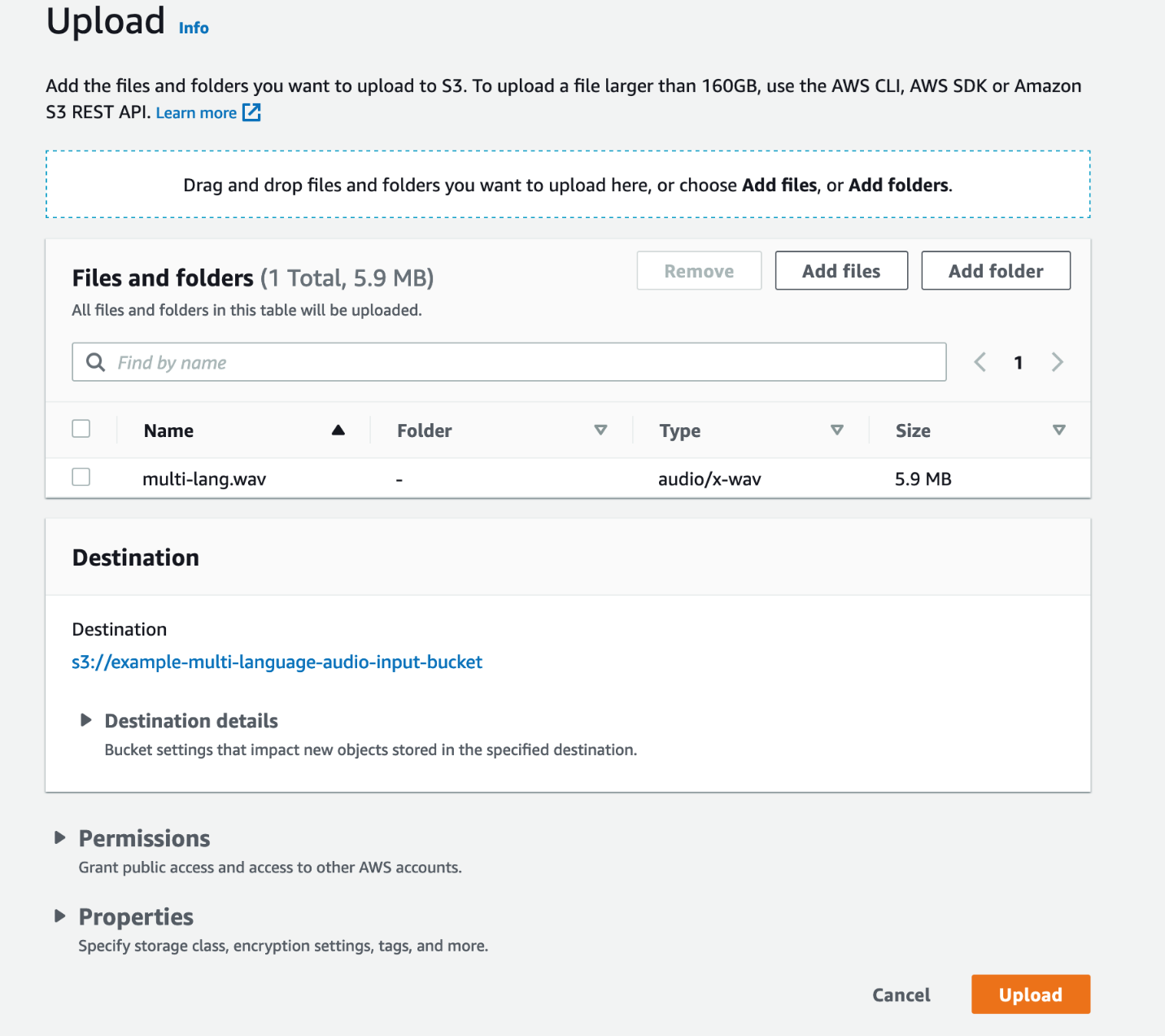
Seu arquivo de áudio estará disponível em breve no bucket S3.
Criar o trabalho de transcrição
Com o arquivo de áudio carregado, agora criamos um trabalho de transcrição.
- No console do Amazon Transcribe, escolha Trabalhos de transcrição no painel de navegação.
- Escolha Criar emprego.

- Escolha Nome, insira um nome exclusivo para o trabalho.
Este também será o nome do arquivo de transcrição de saída. - Escolha Opções de linguagem, selecione Identificação automática de vários idiomas.
Esse recurso permite que o Amazon Transcribe identifique e transcreva automaticamente todos os idiomas falados no arquivo de áudio.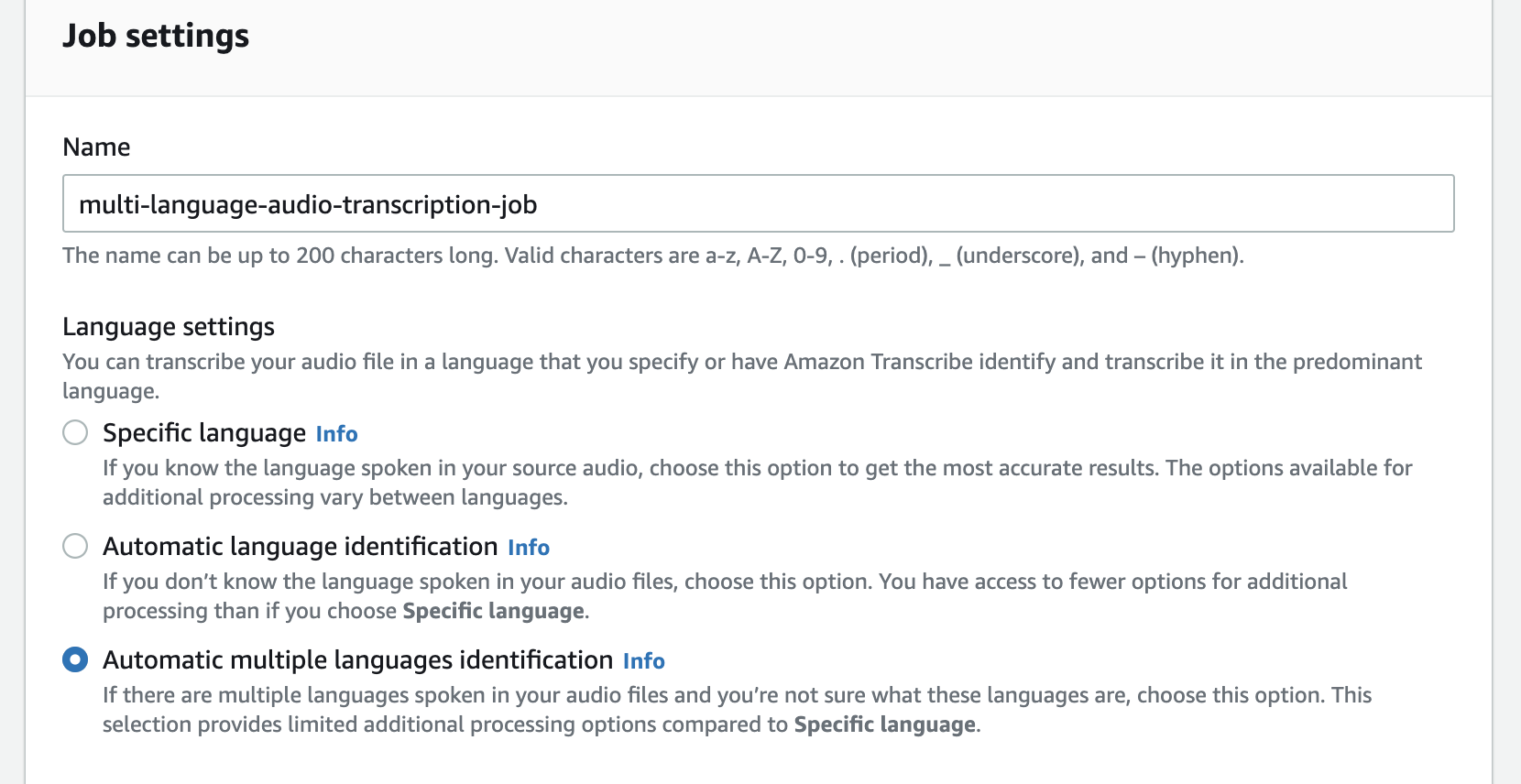
- Escolha Opções de idioma para identificação automática de idioma, deixe-o desmarcado.
O Amazon Transcribe identifica e transcreve automaticamente todos os idiomas falados no áudio. Para melhorar a precisão da transcrição, você pode opcionalmente selecionar dois ou mais idiomas que você sabe que foram falados no áudio.
- Escolha Tipo de modelo, apenas o Modelo geral opção está disponível no momento da redação deste post.
- Escolha Dados de entrada, escolha Navegar S3.
- Escolha o arquivo de origem de áudio que carregamos anteriormente.
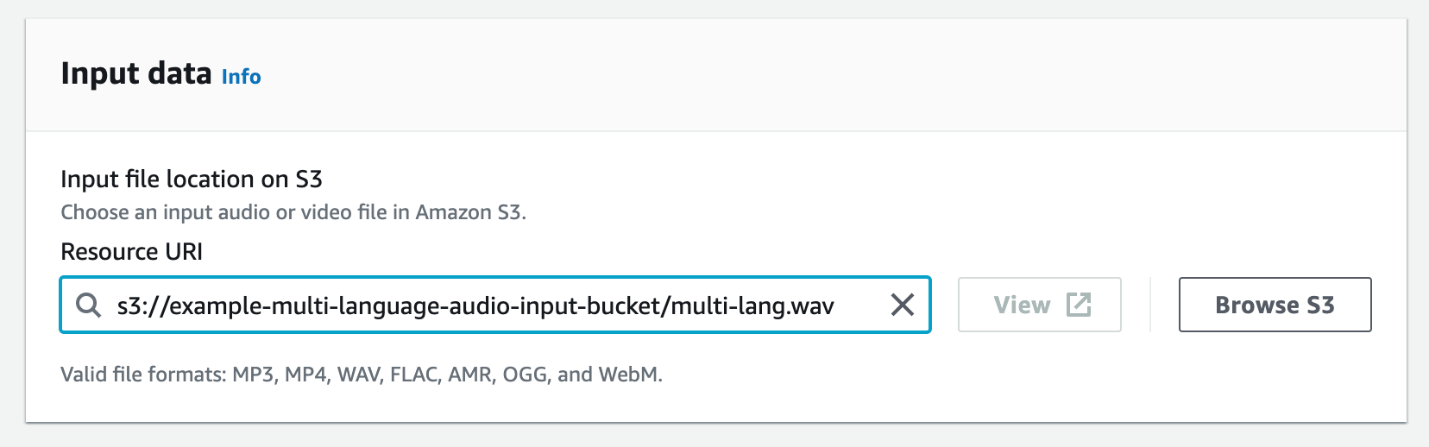
- Escolha Dados de saída, você pode selecionar Bucket S3 gerenciado por serviço or Bucket S3 especificado pelo cliente. Para esta postagem, selecione Bucket S3 gerenciado por serviço.
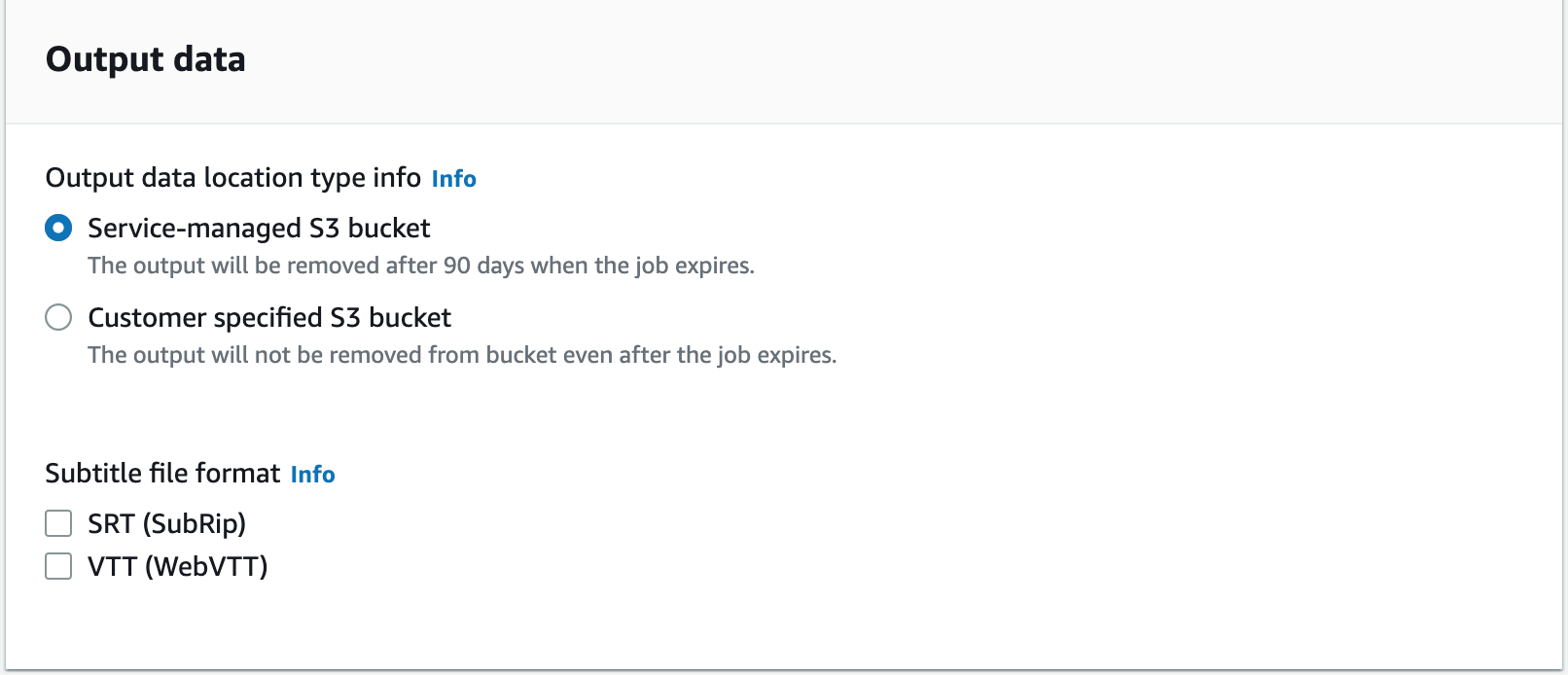
- Escolha Próximo.
- Escolha Criar emprego.
Revise a saída do trabalho
Quando o trabalho de transcrição estiver concluído, abra o trabalho de transcrição.![]()
Desloque-se até o Visualização da transcrição seção. A transcrição do áudio é exibida no Texto aba. A transcrição inclui as partes em inglês e espanhol da conversa.![]()
Opcionalmente, você pode baixar uma cópia da transcrição como um arquivo JSON, que pode ser usado para mais análise pós-chamada.
limpar
Para evitar cobranças futuras, esvazie e exclua o depósito S3 que você criou para armazenar o arquivo de fonte de áudio de entrada. Certifique-se de ter os arquivos armazenados em outro lugar, pois isso removerá permanentemente todos os objetos contidos no depósito. No console do Amazon Transcribe, selecione e exclua o trabalho criado anteriormente para a transcrição.
Conclusão
Nesta postagem, criamos um fluxo de trabalho de ponta a ponta para automatizar a identificação e a transcrição de arquivos de áudio multilíngues, sem escrever nenhum código. Usamos a nova funcionalidade do Amazon Transcribe para identificar automaticamente diferentes idiomas em um arquivo de áudio e transcrever cada idioma corretamente.
Para mais informações, consulte Identificação de idioma com trabalhos de transcrição em lote.
Sobre os autores
![]() Murtuza Bootwala é Arquiteto de Soluções Sênior na AWS com interesse em tecnologias AI/ML. Ele gosta de trabalhar com os clientes para ajudá-los a alcançar seus resultados de negócios. Fora do trabalho, gosta de atividades ao ar livre e de passar tempo com a família.
Murtuza Bootwala é Arquiteto de Soluções Sênior na AWS com interesse em tecnologias AI/ML. Ele gosta de trabalhar com os clientes para ajudá-los a alcançar seus resultados de negócios. Fora do trabalho, gosta de atividades ao ar livre e de passar tempo com a família.
![]() Victor Red é apaixonado por IA/ML e desenvolvimento de software. Ele ajudou a colocar o Amazon Alexa em funcionamento nos EUA e no México. Ele também trouxe o Amazon Textract para os parceiros da AWS e deu início ao AWS Contact Center Intelligence (CCI). Atualmente, ele é o líder global de tecnologia para parceiros de IA de conversação.
Victor Red é apaixonado por IA/ML e desenvolvimento de software. Ele ajudou a colocar o Amazon Alexa em funcionamento nos EUA e no México. Ele também trouxe o Amazon Textract para os parceiros da AWS e deu início ao AWS Contact Center Intelligence (CCI). Atualmente, ele é o líder global de tecnologia para parceiros de IA de conversação.
![]() Babu Srinivasan é um AWS Senior Specialist SA (Language AI Services) baseado em Chicago. Ele se concentra no Amazon Transcribe (fala em texto), ajudando nossos clientes a usar serviços de IA para resolver problemas de negócios. Fora do trabalho, ele gosta de trabalhar com madeira e fazer shows de mágica.
Babu Srinivasan é um AWS Senior Specialist SA (Language AI Services) baseado em Chicago. Ele se concentra no Amazon Transcribe (fala em texto), ajudando nossos clientes a usar serviços de IA para resolver problemas de negócios. Fora do trabalho, ele gosta de trabalhar com madeira e fazer shows de mágica.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/automatically-identify-languages-in-multi-lingual-audio-using-amazon-transcribe/
- 100
- a
- Sobre
- Conta
- precisão
- Alcançar
- em
- atividades
- AI
- Serviços de IA
- AI / ML
- Alexa
- Todos os Produtos
- Apesar
- Amazon
- amazontext
- Amazon Transcribe
- quantidade
- e
- Outro
- qualquer lugar
- api
- APIs
- Aplicação
- ÁREA
- auditivo
- automatizar
- Automatizado
- Automático
- automaticamente
- disponibilidade
- disponível
- AWS
- baseado
- Porque
- ser
- entre
- Trazido
- construído
- negócio
- chamada
- chamado
- chamada
- chamadas
- capturas
- Capturar
- Cuidado
- casos
- Centralização de
- alterar
- acusações
- Chicago
- Escolha
- remover filtragem
- cliente
- código
- conforto
- Comunicações
- completar
- computador
- Considerar
- cônsul
- Contacto
- contact center
- Recipiente
- conteúdo
- Conversa
- conversação
- IA conversacional
- converter
- Custo
- poderia
- país
- crio
- criado
- Atualmente
- cliente
- Atendimento ao Cliente
- Suporte ao cliente
- Clientes
- personalização
- dados,
- defaults
- Dependendo
- descreve
- Desenvolvimento
- diferente
- discutir
- down
- download
- durabilidade
- cada
- eficientemente
- ou
- em outro lugar
- permitir
- permite
- end-to-end
- Inglês
- Entrar
- inteiramente
- Éter (ETH)
- Exercício
- família
- factível
- Característica
- Envie o
- Arquivos
- filtro
- concentra-se
- seguinte
- Fórum
- da
- funcionalidade
- mais distante
- futuro
- gerar
- ter
- Global
- Globalmente
- Solo
- ajudar
- ajudou
- ajuda
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- HTTPS
- Humanos
- identificação
- identifica
- identificar
- executar
- melhorar
- in
- inclui
- Crescimento
- líder da indústria
- INFORMAÇÕES
- entrada
- instruções
- Inteligência
- interações
- interesse
- IT
- Trabalho
- json
- Saber
- conhecido
- língua
- Idiomas
- líder
- Deixar
- Nível
- local
- Localização
- Baixo
- mágica
- fazer
- FAZ
- gerenciados
- Mídia
- reunião
- metadados
- México
- poder
- mínimo
- monitoração
- mais
- múltiplo
- nome
- Navegação
- você merece...
- necessitando
- Novo
- objeto
- objetos
- Oferece
- oficial
- ONE
- aberto
- operar
- operando
- Opção
- Opções
- Outros
- lado de fora
- pão
- participantes
- Parceiros
- apaixonado
- atuação
- realização
- permanentemente
- platão
- Inteligência de Dados Platão
- PlatãoData
- população
- Publique
- preferências
- pré-requisitos
- anteriormente
- política de privacidade
- Problema
- problemas
- Produção
- proteger
- fornecer
- propósito
- Leia
- reconhecimento
- região
- regional
- regiões
- remover
- Denunciar
- representante
- Recursos
- Resultados
- rever
- corrida
- SA
- mesmo
- AMPLIAR
- segundo
- Seção
- segurança
- serviço
- Serviços
- Em breve
- rede de apoio social
- Shows
- semelhante
- simples
- Software
- desenvolvimento de software
- solução
- Soluções
- RESOLVER
- fonte
- Espanhol
- falando
- especialista
- especificada
- discurso
- Reconhecimento de Voz
- Passar
- Passos
- armazenamento
- loja
- armazenadas
- substancial
- tal
- ajuda
- Interruptor
- tecnologia
- Tecnologias
- A
- deles
- Através da
- tempo
- para
- Rastreamento
- Cópia
- transição
- único
- ilimitado
- carregado
- us
- Uso
- usar
- Utilizador
- vário
- praticamente
- Passo a passo
- qual
- enquanto
- precisarão
- dentro
- sem
- Atividades:
- fluxos de trabalho
- trabalhar
- escrever
- escrita
- investimentos
- zefirnet