Neste post, demonstramos Kubeflow na AWS (uma distribuição de Kubeflow específica da AWS) e o valor que ela agrega ao Kubeflow de código aberto por meio da integração de serviços AWS altamente otimizados, nativos da nuvem e prontos para empresas.
Kubeflow é a plataforma de aprendizado de máquina (ML) de código aberto dedicada a tornar as implantações de fluxos de trabalho de ML no Kubernetes simples, portáteis e escaláveis. O Kubeflow fornece muitos componentes, incluindo um painel central, notebooks Jupyter multiusuário, Kubeflow Pipelines, KFServing e Katib, bem como operadores de treinamento distribuídos para TensorFlow, PyTorch, MXNet e XGBoost, para criar fluxos de trabalho de ML simples, escaláveis e portáteis .
A AWS lançou recentemente o Kubeflow v1.4 como parte de sua própria distribuição Kubeflow (chamada Kubeflow na AWS), que simplifica as tarefas de ciência de dados e ajuda a criar sistemas de ML altamente confiáveis, seguros, portáteis e escaláveis com despesas operacionais reduzidas por meio de integrações com serviços gerenciados da AWS . Você pode usar essa distribuição do Kubeflow para criar sistemas de ML com base em Serviço Amazon Elastic Kubernetes (Amazon EKS) para criar, treinar, ajustar e implantar modelos de ML para uma ampla variedade de casos de uso, incluindo visão computacional, processamento de linguagem natural, tradução de fala e modelagem financeira.
Desafios com o Kubeflow de código aberto
Quando você usa um projeto Kubeflow de código aberto, ele implementa todos os componentes do plano de controle e do plano de dados do Kubeflow nos nós do trabalhador do Kubernetes. Os serviços de componentes do Kubeflow são implantados como parte do plano de controle do Kubeflow e todas as implantações de recursos relacionadas ao Jupyter, treinamento de modelo, ajuste e hospedagem são implantadas no plano de dados do Kubeflow. O plano de controle e o plano de dados do Kubeflow podem ser executados no mesmo ou em nós do trabalhador Kubernetes diferentes. Esta postagem se concentra nos componentes do plano de controle do Kubeflow, conforme ilustrado no diagrama a seguir.

Esse modelo de implantação pode não fornecer uma experiência pronta para a empresa devido aos seguintes motivos:
- Todos os componentes de infraestrutura de levantamento pesado do plano de controle do Kubeflow, incluindo banco de dados, armazenamento e autenticação, são implementados no próprio nó do trabalhador do cluster Kubernetes. Isso dificulta a implementação de uma arquitetura de design de plano de controle Kubeflow altamente disponível com um estado persistente no caso de falha do nó do trabalhador.
- Os artefatos gerados pelo plano de controle do Kubeflow (como instâncias MySQL, logs de pod ou armazenamento MinIO) crescem com o tempo e precisam de volumes de armazenamento redimensionáveis com recursos de monitoramento contínuo para atender à crescente demanda de armazenamento. Como o plano de controle do Kubeflow compartilha recursos com cargas de trabalho do plano de dados do Kubeflow (por exemplo, para trabalhos de treinamento, pipelines e implantações), dimensionar e dimensionar corretamente o cluster e os volumes de armazenamento do Kubernetes podem se tornar desafiadores e resultar em aumento do custo operacional.
- O Kubernetes restringe o tamanho do arquivo de log, com a maioria das instalações mantendo o limite mais recente de 10 MB. Por padrão, os logs do pod ficam inacessíveis depois que atingem esse limite superior. Os logs também podem ficar inacessíveis se os pods forem despejados, travados, excluídos ou agendados em um nó diferente, o que pode afetar a disponibilidade do log do aplicativo e os recursos de monitoramento.
Kubeflow na AWS
O Kubeflow na AWS fornece um caminho claro para usar o Kubeflow, com os seguintes serviços da AWS:
- Balanceador de carga de aplicativo para gerenciamento de tráfego externo seguro por HTTPS
- Amazon CloudWatch para gerenciamento de log persistente
- AWS Cognito para autenticação de usuário com Transport Layer Security (TLS)
- Contêineres de aprendizado profundo da AWS para imagens de servidor de notebook Jupyter altamente otimizadas
- Sistema de arquivos elástico da Amazon (Amazon EFS) ou Amazon FSx para Lustre para uma solução de armazenamento de arquivos simples, escalável e sem servidor para aumentar o desempenho do treinamento
- Amazon EKS para clusters Kubernetes gerenciados
- Serviço de banco de dados relacional da Amazon (Amazon RDS) para pipelines altamente escaláveis e um repositório de metadados
- Gerenciador de segredos da AWS para proteger os segredos necessários para acessar seus aplicativos
- Serviço de armazenamento simples da Amazon (Amazon S3) para um armazenamento de artefatos de pipeline fácil de usar
Essas integrações de serviço da AWS com o Kubeflow (conforme mostrado no diagrama a seguir) nos permitem separar partes críticas do plano de controle do Kubeflow do Kubernetes, fornecendo um design seguro, escalável, resiliente e com custo otimizado.

Vamos discutir os benefícios de cada integração de serviço e suas soluções em segurança, execução de pipelines de ML e armazenamento.
Autenticação segura de usuários do Kubeflow com o Amazon Cognito
A segurança na nuvem na AWS é a mais alta prioridade, e estamos investindo na integração total da segurança do Kubeflow diretamente nos serviços de segurança de responsabilidade compartilhada da AWS, como os seguintes:
- Application Load Balancer (ALB) para gerenciamento de tráfego externo
- Gerenciador de certificados da AWS (ACM) para suportar TLS
- Papéis IAM para contas de serviço (IRSA) para controle de acesso refinado no nível do Kubernetes Pod
- Serviço de gerenciamento de chaves AWS (AWS KMS) para gerenciamento de chaves de criptografia de dados
- Escudo AWS para proteção contra DDoS
Nesta seção, nos concentramos na integração do plano de controle do AWS Kubeflow com o Amazon Cognito. O Amazon Cognito elimina a necessidade de gerenciar e manter uma solução nativa Dex (provedor OpenID Connect (OIDC) de código aberto com suporte de LDAP local) para autenticação de usuários e facilita o gerenciamento de segredos.
Você também pode usar o Amazon Cognito para adicionar a inscrição do usuário, login e controle de acesso à interface do usuário do Kubeflow de maneira rápida e fácil. O Amazon Cognito é dimensionado para milhões de usuários e oferece suporte ao login com provedores de identidade social (IdPs), como Facebook, Google e Amazon, e IdPs corporativos via SAML 2.0. Isso reduz a complexidade na configuração do Kubeflow, tornando-o operacionalmente enxuto e mais fácil de operar para obter o isolamento multiusuário.
Vejamos um fluxo de autenticação multiusuário com integrações do Amazon Cognito, ALB e ACM com Kubeflow na AWS. Há vários componentes-chave como parte dessa integração. O Amazon Cognito é configurado como um IdP com um retorno de chamada de autenticação configurado para rotear a solicitação para o Kubeflow após a autenticação do usuário. Como parte da configuração do Kubeflow, um recurso de entrada do Kubernetes é criado para gerenciar o tráfego externo para o serviço Istio Gateway. O AWS ALB Ingress Controller provisiona um load balancer para essa entrada. Nós usamos Amazon Route 53 para configurar um DNS público para o domínio registrado e criar certificados usando o ACM para habilitar a autenticação TLS no balanceador de carga.
O diagrama a seguir mostra o fluxo de trabalho típico do usuário para fazer login no Amazon Cognito e ser redirecionado para o Kubeflow em seu respectivo namespace.

O fluxo de trabalho contém as seguintes etapas:
- O usuário envia uma solicitação HTTPS para o painel central do Kubeflow hospedado por trás de um balanceador de carga. O Route 53 resolve o FQDN para o registro de alias do ALB.
- Se o cookie não estiver presente, o load balancer redirecionará o usuário para o endpoint de autorização do Amazon Cognito para que o Amazon Cognito possa autenticar o usuário.
- Depois que o usuário é autenticado, o Amazon Cognito o envia de volta ao load balancer com um código de concessão de autorização.
- O load balancer apresenta o código de concessão de autorização ao endpoint do token do Amazon Cognito.
- Ao receber um código de concessão de autorização válido, o Amazon Cognito fornece o token de ID e o token de acesso ao load balancer.
- Depois que o load balancer autentica um usuário com êxito, ele envia o token de acesso ao endpoint de informações do usuário do Amazon Cognito e recebe as declarações do usuário. O balanceador de carga assina e adiciona declarações de usuário ao cabeçalho HTTP
x-amzn-oidc-*em um formato de solicitação de token da Web JSON (JWT). - A solicitação do balanceador de carga é enviada ao pod do Istio Ingress Gateway.
- Usando um filtro enviado, o Istio Gateway decodifica o
x-amzn-oidc-datavalor, recupera o campo de email e adiciona o cabeçalho HTTP personalizadokubeflow-userid, que é usado pela camada de autorização do Kubeflow. - As políticas de controle de acesso baseadas em recursos do Istio são aplicadas à solicitação recebida para validar o acesso ao painel do Kubeflow. Se qualquer um deles estiver inacessível ao usuário, uma resposta de erro será enviada de volta. Se a solicitação for validada, ela será encaminhada ao serviço Kubeflow apropriado e fornecerá acesso ao painel do Kubeflow
Armazenamento de artefatos e metadados de componentes do Kubeflow persistentes com Amazon RDS e Amazon S3
O Kubeflow na AWS oferece integração com Serviço de banco de dados relacional da Amazon (Amazon RDS) em Kubeflow Pipelines e AutoML (secretário) para armazenamento de metadados persistente e Amazon S3 no Kubeflow Pipelines para armazenamento de artefato persistente. Vamos continuar a discutir o Kubeflow Pipelines com mais detalhes.
O Kubeflow Pipelines é uma plataforma para criar e implantar fluxos de trabalho de ML portáteis e escaláveis. Esses fluxos de trabalho podem ajudar a automatizar pipelines de ML complexos usando componentes Kubeflow integrados e personalizados. O Kubeflow Pipelines inclui o Python SDK, um compilador DSL para converter o código Python em uma configuração estática, um serviço Pipelines que executa pipelines a partir da configuração estática e um conjunto de controladores para executar os contêineres nos pods do Kubernetes necessários para concluir o pipeline.
Os metadados do Kubeflow Pipelines para experimentos e execuções de pipeline são armazenados no MySQL, e artefatos, incluindo pacotes e métricas de pipeline, são armazenados no MinIO.
Conforme mostrado no diagrama a seguir, o Kubeflow na AWS permite armazenar os seguintes componentes com serviços gerenciados da AWS:
- Metadados de pipeline no Amazon RDS – O Amazon RDS oferece uma arquitetura de implantação Multi-AZ escalável, altamente disponível e confiável com um mecanismo de failover automatizado integrado e capacidade redimensionável para um banco de dados relacional padrão do setor, como o MySQL. Ele gerencia tarefas comuns de administração de banco de dados sem precisar provisionar infraestrutura ou manter software.
- Artefatos de pipeline no Amazon S3 – O Amazon S3 oferece escalabilidade, disponibilidade de dados, segurança e desempenho líderes do setor e pode ser usado para atender às suas necessidades requisitos de conformidade.
Essas integrações ajudam a descarregar o gerenciamento e a manutenção do armazenamento de metadados e artefatos do Kubeflow autogerenciado para os serviços gerenciados pela AWS, que são mais fáceis de configurar, operar e dimensionar.

Suporte para sistemas de arquivos distribuídos com Amazon EFS e Amazon FSx
O Kubeflow se baseia no Kubernetes, que fornece uma infraestrutura para processamento de dados distribuído em larga escala, incluindo treinamento e ajuste de grandes modelos com uma rede profunda com milhões ou até bilhões de parâmetros. Para oferecer suporte a esses sistemas de ML de processamento de dados distribuídos, o Kubeflow na AWS oferece integração com os seguintes serviços de armazenamento:
- Amazon EFS – Um sistema de arquivos distribuído, nativo da nuvem e de alto desempenho, que você pode gerenciar por meio de um Driver CSI do Amazon EFS. O Amazon EFS fornece
ReadWriteManymodo de acesso, e agora você pode usá-lo para montar em pods (Jupyter, treinamento de modelo, ajuste de modelo) em execução em um plano de dados do Kubeflow para fornecer um espaço de trabalho persistente, escalável e compartilhável que aumenta e diminui automaticamente à medida que você adiciona e remove arquivos com não há necessidade de gestão. - Amazon FSx para Lustre – Um sistema de arquivos otimizado para cargas de trabalho com uso intensivo de computação, como computação de alto desempenho e ML, que você pode gerenciar por meio do Driver CSI do Amazon FSx. FSx for Lustre fornece
ReadWriteManymodo de acesso também, e você pode usá-lo para armazenar dados de treinamento em cache com conectividade direta ao Amazon S3 como armazenamento de apoio, que pode ser usado para dar suporte a servidores de notebook Jupyter ou treinamento distribuído em execução em um plano de dados Kubeflow. Com essa configuração, você não precisa transferir dados para o sistema de arquivos antes de usar o volume. O FSx for Luster fornece latências consistentes de submilissegundos e alta simultaneidade, e pode ser dimensionado para TB/s de taxa de transferência e milhões de IOPS.
Opções de implantação do Kubeflow
A AWS oferece várias opções de implantação do Kubeflow:
- Implantação com o Amazon Cognito
- Implantação com Amazon RDS e Amazon S3
- Implantação com Amazon Cognito, Amazon RDS e Amazon S3
- Implantação de baunilha
Para obter detalhes sobre integração de serviços e complementos disponíveis para cada uma dessas opções, consulte Opções de implantação. Você pode ajustar a opção que melhor se adapta ao seu caso de uso.
Na seção a seguir, percorremos as etapas para instalar a distribuição do AWS Kubeflow v1.4 no Amazon EKS. Em seguida, usamos o exemplo de pipeline XGBoost existente disponível no painel de IU central do Kubeflow para demonstrar a integração e o uso do AWS Kubeflow com Amazon Cognito, Amazon RDS e Amazon S3, com o Secrets Manager como complemento.
Pré-requisitos
Para este passo a passo, você deve ter os seguintes pré-requisitos:
- An Conta da AWS.
- Um cluster existente do Amazon EKS. Deve ser a versão 1.19 ou superior do Kubernetes. Para criação automatizada de clusters usando extl, Ver Criar um cluster do Amazon EKS e use a opção eksctl.
Instale as ferramentas a seguir na máquina cliente usada para acessar seu cluster Kubernetes. Você pode usar Nuvem AWS9, um ambiente de desenvolvimento integrado (IDE) baseado em nuvem para a configuração do cluster Kubernetes.
- Interface de linha de comando da AWS (AWS CLI) – Uma ferramenta de linha de comando para interagir com os serviços da AWS. Para instruções de instalação, consulte Instalação, atualização e desinstalação do AWS CLI.
- extl > 0.56 – Uma ferramenta de linha de comando para trabalhar com clusters do Amazon EKS que automatiza muitas tarefas individuais.
- kubectl – Uma ferramenta de linha de comando para trabalhar com clusters Kubernetes.
- git – Um software de controle de versão distribuído.
- Python 3.8 + – O ambiente de programação Python.
- pip – O gerenciador de pacotes para Python.
- personalizar a versão 3.2.0 – Uma ferramenta de linha de comando para customizar objetos Kubernetes por meio de um arquivo de customização.
Instale o Kubeflow na AWS
Configure o kubectl para que você possa se conectar a um cluster do Amazon EKS:
Vários controladores no uso de implantação do Kubeflow Papéis IAM para contas de serviço (IRSA). Um provedor OIDC deve existir para que seu cluster use IRSA. Crie um provedor OIDC e associe-o ao cluster do Amazon EKS executando o seguinte comando, se o cluster ainda não tiver um:
Clone o repositório de manifestos da AWS e o repositório de manifestos do Kubeflow e verifique os respectivos branches de lançamento:
Para obter mais informações sobre essas versões, consulte Versões e versões.
Configurar Amazon RDS, Amazon S3 e Secrets Manager
Você cria recursos do Amazon RDS e do Amazon S3 antes de implantar os manifestos do Kubeflow. Usamos scripts Python automatizados que cuidam da criação do bucket do S3, do banco de dados RDS e dos segredos necessários no Secrets Manager. Ele também edita os arquivos de configuração necessários para que o pipeline do Kubeflow e o AutoML sejam configurados corretamente para o banco de dados RDS e o bucket do S3 durante a instalação do Kubeflow.
Crie um usuário IAM com permissões para permitir GetBucketLocation e acesso de leitura e gravação a objetos em um bucket do S3 no qual você deseja armazenar os artefatos do Kubeflow. Use o AWS_ACCESS_KEY_ID e AWS_SECRET_ACCESS_KEY do usuário do IAM no código a seguir:
Configurar o Amazon Cognito como provedor de autenticação
Nesta seção, criamos um domínio personalizado no Route 53 e no ALB para rotear o tráfego externo para o Kubeflow Istio Gateway. Usamos o ACM para criar um certificado para habilitar a autenticação TLS no ALB e no Amazon Cognito para manter o grupo de usuários e gerenciar a autenticação do usuário.
Substitua os seguintes valores em
- route53.rootDomain.name – O domínio registrado. Vamos supor que este domínio seja
example.com. - route53.rootDomain.hostedZoneId – Se o seu domínio for gerenciado no Route53, insira o ID da zona hospedada encontrado nos detalhes da zona hospedada. Pule esta etapa se seu domínio for gerenciado por outro provedor de domínio.
- route53.subDomain.name – O nome do subdomínio onde você deseja hospedar o Kubeflow (por exemplo,
platform.example.com). Para obter mais informações sobre subdomínios, consulte Como implantar o Kubeflow com AWS Cognito como IdP. - cluster.nome – O nome do cluster e onde o Kubeflow está implementado.
- cluster.região – A região do cluster em que o Kubeflow está implantado (por exemplo,
us-west-2). - cognitoUserpool.nome – O nome do grupo de usuários do Amazon Cognito (por exemplo,
kubeflow-users).
O arquivo de configuração se parece com o seguinte código:
Execute o script para criar os recursos:
O script atualiza o config.yaml arquivo com os nomes de recursos, IDs e ARNs que ele criou. Parece algo como o seguinte código:
Crie manifestos e implante o Kubeflow
Implante o Kubeflow usando o seguinte comando:
Atualize o domínio com o endereço ALB
A implantação cria um balanceador de carga de aplicativos da AWS gerenciado pelo ingresso. Atualizamos as entradas DNS para o subdomínio no Route 53 com o DNS do balanceador de carga. Execute o seguinte comando para verificar se o balanceador de carga está provisionado (isso leva cerca de 3 a 5 minutos):
Se o ADDRESS campo estiver vazio após alguns minutos, verifique os logs de alb-ingress-controller. Para obter instruções, consulte ALB não provisiona.
Quando o balanceador de carga for provisionado, copie o nome DNS do balanceador de carga e substitua o endereço por kubeflow.alb.dns in ${kubeflow_manifest_dir}/tests/e2e/utils/cognito_bootstrap/config.yaml. A seção Kubeflow do arquivo de configuração se parece com o seguinte código:
Execute o script a seguir para atualizar as entradas DNS do subdomínio no Route 53 com o DNS do balanceador de carga provisionado:
guia de solução de problemas
Se você tiver problemas durante a instalação, consulte o guia de solução de problemas ou comece de novo seguindo a seção “Limpar” neste blog.
Passo a passo do caso de uso
Agora que concluímos a instalação dos componentes necessários do Kubeflow, vamos vê-los em ação usando um dos exemplos existentes fornecidos pelo Kubeflow Pipelines no painel.
Acesse o painel do Kubeflow usando o Amazon Cognito
Para começar, vamos acessar o painel do Kubeflow. Como usamos o Amazon Cognito como IdP, use as informações fornecidas no arquivo README oficial. Primeiro, criamos alguns usuários no console do Amazon Cognito. Esses são os usuários que farão login no painel central. Próximo, criar um perfil para o usuário que você criou. Em seguida, você poderá acessar o painel através da página de login em https://kubeflow.platform.example.com.

A captura de tela a seguir mostra nosso painel do Kubeflow.

Executar o pipeline
No painel do Kubeflow, escolha Dutos no nome de navegação. Você deve ver quatro exemplos fornecidos pelo Kubeflow Pipelines que podem ser executados diretamente para explorar vários recursos do Pipelines.
Para este post, usamos o exemplo XGBoost chamado [Demo] XGBoost – Treinamento de modelo iterativo. Você pode encontrar o código-fonte em GitHub. Este é um pipeline simples que usa o XGBoost/Train e XGBoost/Predict Componentes de pipeline do Kubeflow para treinar iterativamente um modelo até que as métricas sejam consideradas boas com base nas métricas especificadas.
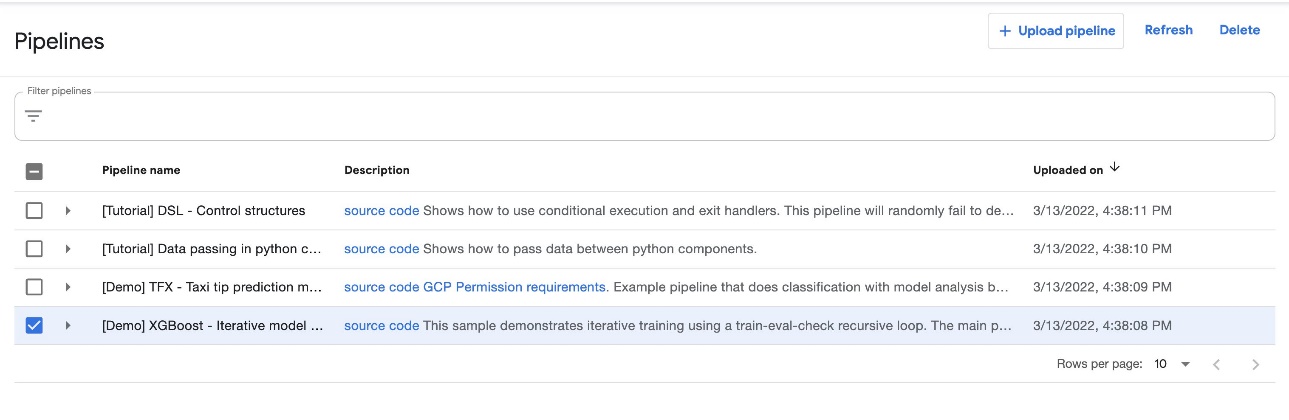
Para executar o pipeline, conclua as etapas a seguir:
- Selecione o pipeline e escolha Criar experimento.

- Debaixo Detalhes do experimento, insira um nome (para esta postagem,
demo-blog) e descrição opcional. - Escolha Próximo.

- Debaixo Detalhes da execução¸ escolha o pipeline e a versão do pipeline.
- Escolha Executar nome, Insira o nome.
- Escolha Experiência, escolha a experiência que você criou.
- Escolha Tipo de corrida, selecione Único.
- Escolha Início.

Depois que o pipeline começar a ser executado, você verá a conclusão dos componentes (em alguns segundos). Nesta fase, você pode escolher qualquer um dos componentes concluídos para ver mais detalhes.

Acesse os artefatos no Amazon S3
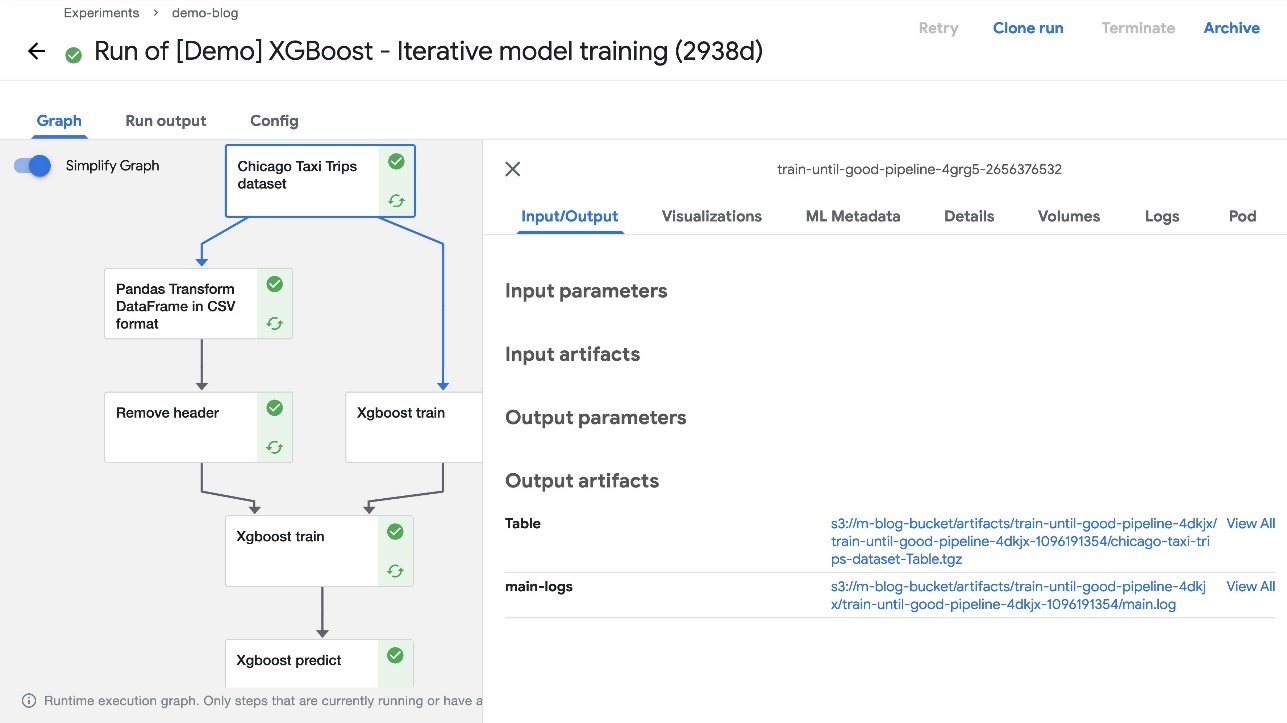
Ao implantar o Kubeflow, especificamos que o Kubeflow Pipelines deve usar o Amazon S3 para armazenar seus artefatos. Isso inclui todos os artefatos de saída de pipeline, execuções em cache e gráficos de pipeline — todos os quais podem ser usados para visualizações avançadas e avaliação de desempenho.
Quando a execução do pipeline for concluída, você poderá ver os artefatos no bucket do S3 que você criou durante a instalação. Para confirmar isso, escolha qualquer componente concluído do pipeline e verifique o Input / Output seção sobre o padrão Gráfico aba. As URLs do artefato devem apontar para o bucket do S3 que você especificou durante a implantação.
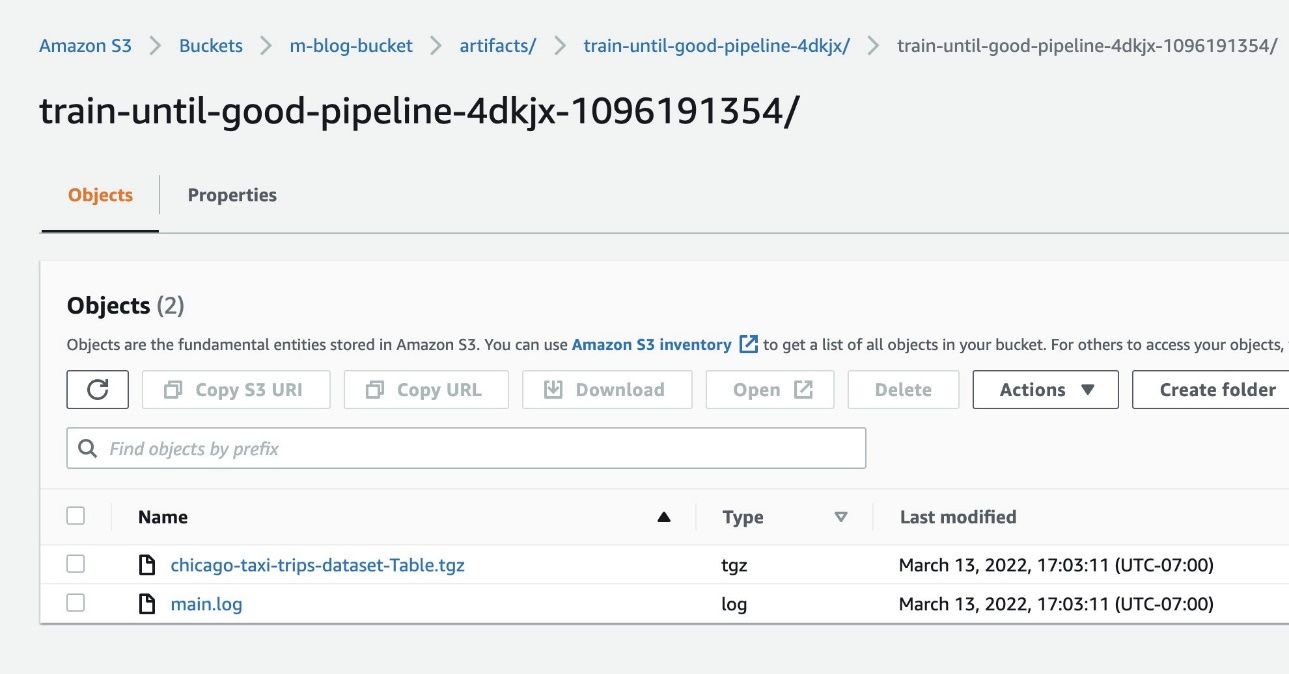
Para confirmar que os recursos foram adicionados ao Amazon S3, também podemos verificar o bucket do S3 em nossa conta da AWS por meio do console do Amazon S3.

A captura de tela a seguir mostra nossos arquivos.
Verificar metadados de ML no Amazon RDS
Também integramos o Kubeflow Pipelines ao Amazon RDS durante a implantação, o que significa que todos os metadados do pipeline devem ser armazenados no Amazon RDS. Isso inclui qualquer informação de tempo de execução, como o status de uma tarefa, disponibilidade de artefatos, propriedades customizadas associadas à execução ou artefatos e muito mais.
Para verificar a integração do Amazon RDS, siga as etapas fornecidas no arquivo README oficial. Especificamente, conclua as seguintes etapas:
- Obtenha o nome de usuário e a senha do Amazon RDS do segredo que foi criado durante a instalação:
- Use estas credenciais para se conectar ao Amazon RDS de dentro do cluster:
- Quando o prompt do MySQL é aberto, podemos verificar o
mlpipelinesbanco de dados da seguinte forma: - Agora podemos ler o conteúdo de tabelas específicas, para ter certeza de que podemos ver informações de metadados sobre os experimentos que executaram os pipelines:
limpar
Para desinstalar o Kubeflow e excluir os recursos da AWS que você criou, conclua as etapas a seguir:
- Exclua a entrada e o balanceador de carga gerenciado pela entrada executando o seguinte comando:
- Exclua o restante dos componentes do Kubeflow:
- Exclua os recursos da AWS criados por scripts:
- Recursos criados para integração Amazon RDS e Amazon S3. Certifique-se de ter o arquivo de configuração criado pelo script em
${kubeflow_manifest_dir}/tests/e2e/utils/rds-s3/metadata.yaml: - Recursos criados para integração do Amazon Cognito. Certifique-se de ter o arquivo de configuração criado pelo script em
${kubeflow_manifest_dir}/tests/e2e/utils/cognito_bootstrap/config.yaml:
- Recursos criados para integração Amazon RDS e Amazon S3. Certifique-se de ter o arquivo de configuração criado pelo script em
- Se você criou um cluster dedicado do Amazon EKS para Kubeflow usando eksctl, pode excluí-lo com o seguinte comando:
Resumo
Neste post, destacamos o valor que o Kubeflow na AWS oferece por meio de integrações de serviços nativas gerenciadas pela AWS para cargas de trabalho de IA e ML seguras, escaláveis e prontas para empresas. Você pode escolher entre várias opções de implantação para instalar o Kubeflow na AWS com várias integrações de serviço. O caso de uso nesta postagem demonstrou a integração do Kubeflow com Amazon Cognito, Secrets Manager, Amazon RDS e Amazon S3. Para começar a usar o Kubeflow na AWS, consulte as opções de implantação integradas à AWS disponíveis em Kubeflow na AWS.
A partir da v1.3, você pode seguir o Repositório do AWS Labs para rastrear todas as contribuições da AWS para o Kubeflow. Você também pode nos encontrar no Kubeflow #AWS Canal Slack; seus comentários nos ajudarão a priorizar os próximos recursos para contribuir com o projeto Kubeflow.
Sobre os autores
 Kanwaljit Khurmi é arquiteto de soluções especialista em IA/ML na Amazon Web Services. Ele trabalha com o produto, a engenharia e os clientes da AWS para fornecer orientação e assistência técnica, ajudando-os a melhorar o valor de suas soluções de ML híbridas ao usar a AWS. A Kanwaljit é especializada em ajudar os clientes com aplicativos em contêiner e de aprendizado de máquina.
Kanwaljit Khurmi é arquiteto de soluções especialista em IA/ML na Amazon Web Services. Ele trabalha com o produto, a engenharia e os clientes da AWS para fornecer orientação e assistência técnica, ajudando-os a melhorar o valor de suas soluções de ML híbridas ao usar a AWS. A Kanwaljit é especializada em ajudar os clientes com aplicativos em contêiner e de aprendizado de máquina.
 Meghna Baijal é um engenheiro de software com IA da AWS, tornando mais fácil para os usuários integrarem suas cargas de trabalho de Machine Learning na AWS criando produtos e plataformas de ML, como Deep Learning Containers, Deep Learning AMIs, AWS Controllers for Kubernetes (ACK) e Kubeflow na AWS . Fora do trabalho, ela gosta de ler, viajar e brincar com a pintura.
Meghna Baijal é um engenheiro de software com IA da AWS, tornando mais fácil para os usuários integrarem suas cargas de trabalho de Machine Learning na AWS criando produtos e plataformas de ML, como Deep Learning Containers, Deep Learning AMIs, AWS Controllers for Kubernetes (ACK) e Kubeflow na AWS . Fora do trabalho, ela gosta de ler, viajar e brincar com a pintura.
 Suraj Kota é um Engenheiro de Software especializado em infraestrutura de Machine Learning. Ele cria ferramentas para iniciar e dimensionar facilmente a carga de trabalho de machine learning na AWS. Ele trabalhou nos AWS Deep Learning Containers, Deep Learning AMI, SageMaker Operators for Kubernetes e outras integrações de código aberto, como Kubeflow.
Suraj Kota é um Engenheiro de Software especializado em infraestrutura de Machine Learning. Ele cria ferramentas para iniciar e dimensionar facilmente a carga de trabalho de machine learning na AWS. Ele trabalhou nos AWS Deep Learning Containers, Deep Learning AMI, SageMaker Operators for Kubernetes e outras integrações de código aberto, como Kubeflow.
- Coinsmart. A melhor troca de Bitcoin e criptografia da Europa.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. ACESSO LIVRE.
- CryptoHawk. Radar Altcoin. Teste grátis.
- Fonte: https://aws.amazon.com/blogs/machine-learning/build-and-deploy-a-scalable-machine-learning-system-on-kubernetes-with-kubeflow-on-aws/
- "
- 10
- 100
- 420
- 7
- Sobre
- Acesso
- Conta
- Açao Social
- Adicionar
- endereço
- admin
- administração
- Afiliados
- AI
- Todos os Produtos
- já
- Amazon
- Amazon Web Services
- Outro
- Aplicação
- aplicações
- apropriado
- arquitetura
- por aí
- Jurídico
- autenticado
- autentica
- Autenticação
- autorização
- automatizar
- Automatizado
- automatiza
- disponibilidade
- disponível
- AWS
- tornam-se
- Benefícios
- MELHOR
- bilhões
- Blog
- fronteira
- construir
- Prédio
- Constrói
- construídas em
- capacidades
- Capacidade
- Cuidado
- casos
- CD
- certificado
- certificados
- desafiante
- Finalizar compra
- Escolha
- reivindicações
- classe
- código
- comum
- completando
- integrações
- componente
- computador
- computação
- Configuração
- Contato
- Conectividade
- cônsul
- Containers
- contém
- conteúdo
- continuar
- contribuir
- ao controle
- controlador
- direitos autorais
- poderia
- crio
- criado
- cria
- Criar
- criação
- Credenciais
- crítico
- personalizadas
- Clientes
- painel de instrumentos
- dados,
- informática
- ciência de dados
- banco de dados
- DDoS
- dedicado
- Demanda
- demonstrar
- demonstraram
- implantar
- implantado
- Implantação
- desenvolvimento
- Implantações
- implanta
- Design
- detalhe
- detalhes
- Desenvolvimento
- Dex
- diferente
- diretamente
- diretamente
- discutir
- distribuído
- distribuição
- dns
- Não faz
- domínio
- facilmente
- fácil de usar
- eco
- permitir
- criptografia
- Ponto final
- engenheiro
- Engenharia
- Entrar
- Empreendimento
- Meio Ambiente
- avaliação
- Evento
- exemplo
- existente
- vasta experiência
- experimentar
- explorar
- Falha
- Funcionalidades
- retornos
- financeiro
- Primeiro nome
- caber
- fluxo
- Foco
- concentra-se
- seguir
- seguinte
- formato
- encontrado
- recentes
- obtendo
- Git
- GitHub
- Bom estado, com sinais de uso
- Cresça:
- Crescente
- ajudar
- ajuda
- ajuda
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- Alta
- superior
- Destaque
- altamente
- hospedagem
- HTTPS
- HÍBRIDO
- Dados de identificação:
- Impacto
- executar
- melhorar
- Inc.
- inclui
- Incluindo
- aumentou
- Individual
- líder da indústria
- info
- INFORMAÇÕES
- Infraestrutura
- instalar
- integrado
- integração
- integrações
- investir
- isolamento
- questões
- IT
- se
- Empregos
- manutenção
- Chave
- Laboratório
- língua
- grande
- lançado
- aprendizagem
- facelift
- Line
- carregar
- local
- máquina
- aprendizado de máquina
- a manter
- FAZ
- Fazendo
- gerencia
- gerenciados
- de grupos
- Gerente
- Métrica
- milhões
- ML
- modelo
- modelos
- monitoração
- mais
- a maioria
- nomes
- natural
- Navegação
- líquido
- rede
- nós
- caderno
- número
- Oferece
- aberto
- open source
- abre
- operadores
- otimizado
- Opção
- Opções
- Outros
- próprio
- Senha
- atuação
- plataforma
- Plataformas
- ponto
- políticas
- piscina
- presente
- prioridade
- em processamento
- Produto
- Produtos
- Programação
- projeto
- proteger
- fornecer
- fornece
- fornecendo
- público
- rapidamente
- alcançar
- Leitura
- razões
- registro
- registrado
- liberar
- solicitar
- requeridos
- Requisitos
- recurso
- Recursos
- resposta
- DESCANSO
- Rota
- Execute
- corrida
- AMPLIAR
- escalável
- Escala
- dimensionamento
- Ciência
- Sdk
- SEC
- segundo
- seguro
- segurança
- Serverless
- serviço
- Serviços
- conjunto
- instalação
- ações
- Sinais
- simples
- Tamanho
- folga
- dormir
- So
- Redes Sociais
- Software
- Engenheiro de Software
- sólido
- solução
- Soluções
- alguns
- algo
- código fonte
- especialista
- especializado
- especializada
- especificamente
- Etapa
- começo
- começado
- começa
- Estado
- Status
- armazenamento
- loja
- entraram com sucesso
- ajuda
- suportes
- .
- sistemas
- tarefas
- Dados Técnicos:
- A fonte
- Através da
- tempo
- token
- ferramenta
- ferramentas
- topo
- pista
- tráfego
- Training
- transferência
- Tradução
- transporte
- Viagens
- ui
- Atualizar
- Atualizações
- us
- usar
- usuários
- validado
- valor
- variedade
- vário
- verificar
- visão
- volume
- web
- serviços web
- QUEM
- dentro
- sem
- Atividades:
- trabalhou
- trabalhar
- trabalho