Nos últimos anos, as empresas acumularam enormes quantidades de dados. Os volumes de dados aumentaram a um ritmo sem precedentes, passando de terabytes para petabytes e, por vezes, exabytes de dados. Cada vez mais, muitas empresas estão construindo data lakes altamente escaláveis, disponíveis, seguros e flexíveis na AWS que podem lidar com conjuntos de dados extremamente grandes. Depois que os data lakes são produzidos, para medir a eficácia do data lake e comunicar as lacunas ou realizações aos grupos de negócios, as equipes de dados empresariais precisam de ferramentas para extrair insights operacionais do data lake. Esses insights ajudam a responder questões importantes como:
- A última vez que uma tabela foi atualizada
- A contagem total de tabelas em cada banco de dados
- O crescimento projetado de uma determinada tabela
- A tabela consultada com mais frequência vs. tabelas menos consultadas
Nesta postagem, apresento uma solução para construir um painel de métricas operacionais (como a captura de tela a seguir) para sua empresa Cola AWS Catálogo de dados na AWS.

Visão geral da solução
Esta postagem mostra como coletar informações de metadados dos recursos do AWS Glue Data Catalog do seu data lake (bancos de dados e tabelas) e construir um painel operacional com base nesses dados.
O diagrama a seguir ilustra a arquitetura e as etapas gerais da solução.

As etapas são as seguintes:
- Um programa Python coletor de dados é executado de acordo com uma programação e coleta detalhes de metadados sobre bancos de dados e tabelas do Catálogo de Dados corporativo.
- Os atributos de dados principais a seguir são coletados para cada tabela e banco de dados no seu catálogo de dados do AWS Glue.
| Tabela de dados | Dados do banco de dados |
| Tablename | Nome do banco de dados |
| Nome do banco de dados | CriarTempo |
| Proprietário | Recurso Compartilhado |
| CriarTempo | Proprietário de recursos compartilhados |
| Tempo de atualização | SharedResourceDatabaseName |
| Último tempo de acesso | Localização |
| Tipo de tabela | Descrição |
| Retenção | |
| Criado por | |
| Está registrado com LakeFormation | |
| Localização | |
| TamanhoInMBOnS3 | |
| ArquivoTotalS3 |
- O programa lê a localização dos arquivos de cada tabela e calcula o número de arquivos em Serviço de armazenamento simples da Amazon (Amazon S3) e o tamanho em MB.
- Todos os dados das tabelas e bancos de dados são armazenados em um bucket S3 para análise downstream. O programa é executado todos os dias e cria novos arquivos particionados por ano, mês e dia no Amazon S3.
- Rastreamos os dados criados na Etapa 4 usando um rastreador AWS Glue.
- O rastreador cria um banco de dados externo e tabelas para nosso conjunto de dados gerado para análise downstream.
- Podemos consultar os dados extraídos com Amazona atena.
- Usamos AmazonQuickSight para construir nosso painel de métricas operacionais e obter insights sobre o conteúdo e uso de nosso data lake.
Para simplificar, este programa rastreia e coleta dados do Catálogo de Dados somente para a região us-east-1.
Visão geral do passo a passo
A explicação passo a passo inclui as seguintes etapas:
- Configure seu conjunto de dados.
- Implante os principais recursos da solução com um Formação da Nuvem AWS modelo e configurar e acionar o trabalho do AWS Glue.
- Rastreie o conjunto de dados de metadados e crie tabelas externas no Catálogo de Dados.
- Crie uma visualização e consulte os dados por meio do Athena.
- Configure e importe dados para o QuickSight para criar um painel de métricas operacionais para o Catálogo de Dados.
Configure seu conjunto de dados
Usamos o data lake AWS COVID-19 para análise. Este data lake é composto por dados em um bucket S3 legível publicamente.
Para disponibilizar os dados do data lake AWS COVID-19 em sua conta AWS, crie uma pilha CloudFormation usando o seguinte modelo. Se você estiver conectado à sua conta da AWS, o seguinte link preenche a maior parte do formulário de criação de pilha para você. Certifique-se de alterar a região para us-east-1. Para obter instruções sobre como criar uma pilha do CloudFormation, consulte COMECE AGORA.
Este modelo cria um banco de dados COVID-19 em seu catálogo de dados e tabelas que apontam para o data lake público AWS COVID-19. Você não precisa hospedar os dados em sua conta e pode contar com a AWS para atualizar os dados à medida que os conjuntos de dados são atualizados por meio de Troca de dados da AWS.
Para obter mais informações sobre o conjunto de dados COVID-19, consulte Um data lake público para análise de dados da COVID-19.
Seu ambiente talvez já tenha conjuntos de dados existentes no Catálogo de Dados. O programa também coleta os atributos mencionados acima para esses conjuntos de dados, que podem ser usados para análise.
Implante seus recursos
Para facilitar o início, criamos um modelo CloudFormation que configura automaticamente alguns componentes principais da solução:
- Um trabalho do AWS Glue (programa Python) acionado com base em uma programação
- A Gerenciamento de acesso e identidade da AWS (IAM) exigida pelo trabalho do AWS Glue para que o trabalho possa coletar e armazenar detalhes sobre bancos de dados e tabelas no Data Catalog
- Um novo bucket S3 para o trabalho do AWS Glue para armazenar os arquivos de dados
- Um novo banco de dados no Catálogo de Dados para armazenar nossas tabelas de dados de métricas
O código-fonte do trabalho do AWS Glue e do modelo CloudFormation estão disponíveis no GitHub repo.
Você deve primeiro fazer download do código Python do AWS Glue em GitHub e carregue-o em um bucket S3 existente. O caminho deste arquivo precisa ser fornecido ao executar a pilha do CloudFormation.
- Inicie a pilha:

- Forneça valores para seus parâmetros conforme mostrado na captura de tela a seguir.

Depois que a pilha for implantada com sucesso, você poderá verificar os recursos criados na pilha Recursos aba.

Você pode verificar e verificar a configuração e o acionador do trabalho do AWS Glue, que é agendado de acordo com o horário especificado.
Agora que verificamos que a pilha foi configurada com sucesso, podemos executar nosso trabalho do AWS Glue manualmente e coletar atributos-chave para nossa análise.
- No console do AWS Glue, escolha AWS Glue Studio no painel de navegação.

- No console do AWS Glue Studio, clique em Jobs e selecione o
DataCollectortrabalho e execute o trabalho.
O trabalho do AWS Glue coleta dados e os armazena no bucket S3 criado para nós por meio do AWS CloudFormation. O trabalho cria pastas separadas para dados de banco de dados e tabela, conforme mostrado na captura de tela a seguir.

Rastrear e configurar tabelas externas para os dados de métricas
Siga estas etapas para criar tabelas no banco de dados usando AWS Glue crawlers nos dados armazenados no Amazon S3. Observe que o banco de dados foi criado para nós usando a pilha CloudFormation.
- No console AWS Glue, em Bases de dados no painel de navegação, escolha Tabelas.
- Escolha Adicionar tabelas.
- Escolha Adicione tabelas usando um rastreador.
- Insira um nome para o rastreador e escolha Próximo.
- Escolha Adicionar rastreador, escolha Criar tipo de origem.
- Especifique o tipo de origem do rastreador escolhendo Armazenamento de dados e escolha Próximo.
- No Adicionar um armazenamento de dados seção, para Escolha um armazenamento de dados, escolha S3.
- Escolha Dados de rastreamento em, selecione Caminho especificado.
- Escolha Incluir caminho, insira o caminho para o
tablespasta gerada pelo trabalho do AWS Glue:s3://<data bucket created using CFN>/datalake/tables/.
- Quando perguntado se você deseja criar outro armazenamento de dados, selecione Não e depois escolha Próximo.
- No Escolha uma função IAM página, selecione Escolha uma função IAM existente.
- Escolha Papel do IAM, escolha a função do IAM criada por meio da pilha do CloudFormation.
- Escolha Próximo.
- No saída página, para banco de dados, escolha o banco de dados AWS Glue que você criou anteriormente.
- Escolha Próximo.
- Revise suas seleções e escolha Acabamento.
- Selecione o rastreador que você acabou de criar e escolha Executar rastreador.
O rastreador deve levar apenas alguns minutos para ser concluído. Durante a execução, mensagens de status podem aparecer informando que o sistema está tentando executar o rastreador e, na verdade, está executando o rastreador. Você pode escolher o ícone de atualização para verificar o status atual do rastreador.
- No painel de navegação, escolha Tabelas.
A mesa chamada tables, que foi criado pelo rastreador, deve ser listado.

Consultar dados com Athena
Esta seção demonstra como consultar essas tabelas usando o Athena. Athena é um serviço de consulta interativo e sem servidor que facilita a análise dos dados no data lake COVID-19 da AWS. O Athena oferece suporte a SQL, uma linguagem comum que os analistas de dados usam para analisar dados estruturados. Para consultar os dados, conclua as seguintes etapas:
- Faça login no console do Athena.
- Se esta for a primeira vez que você usa o Athena, você deve especifique um local de resultado da consulta no Amazon S3.
- No menu suspenso, escolha o
datalake360dbbase de dados. - Insira suas consultas e explore os conjuntos de dados.
Configure e importe dados para o QuickSight e crie um painel de métricas operacionais
Configurar QuickSight antes de importar o conjunto de dados e certifique-se de ter pelo menos 512 MB de capacidade do SPICE. Para mais informações, veja Gerenciando a capacidade do SPICE.
Antes de continuar, certifique-se de que sua conta do QuickSight tenha permissões do IAM para acessar o Athena (consulte Autorizando conexões com o Amazon Athena) e Amazon S3.
Vamos primeiro criar nossos conjuntos de dados.
- No console QuickSight, escolha Conjuntos de dados no painel de navegação.
- Escolha Novo conjunto de dados.
- Escolha Athena na lista de fontes de dados.
- Escolha Nome da fonte de dados, Insira o nome.

- Escolha banco de dados, escolha o banco de dados que você configurou na etapa anterior (
datalake360db). - Escolha Tabelas, selecione bases de dados.

- Conclua a criação do seu conjunto de dados.
- Repita os mesmos passos para criar um
tablesconjunto de dados.
Agora você edita o conjunto de dados do banco de dados.
- Na lista de conjuntos de dados, escolha o
databasesconjunto de dados. - Escolha Editar conjunto de dados.

- alterar o
createtimetipo de campo da string até a data.
- Insira o formato de data como
yy/MM/dd HH:mm:ss. - Escolha Atualizar.

- Da mesma forma, altere os campos do conjunto de dados das tabelas
createtime,updatetimeelastaccessedtimepara o tipo de data. - Escolha Salvar e publicar para salvar as alterações no conjunto de dados.
A seguir, adicionamos campos calculados para a contagem de databases e tables.
- Para o
tablesconjunto de dados, escolha Adicionar cálculo.
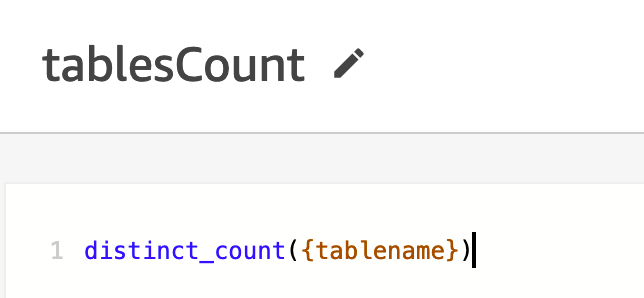
- Adicione o campo calculado
tablesCountasdistinct_count({tablename}.
- Da mesma forma, adicione um novo campo calculado
databasesCountasdistinct_count({databasename}.
Agora vamos criar uma nova análise.
- No painel de navegação, escolha Análise.
- Escolha o
tablesconjunto de dados. - Escolha Crie análises.

Vamos criar nosso primeiro visual para a contagem do número de bancos de dados e tabelas em nosso Data Lake Data Catalog.
- Crie um novo visual e adicione
databasesCountda lista de campos.
Isso nos fornece uma contagem de bancos de dados em nosso Catálogo de Dados.
- Da mesma forma, adicione um visual para exibir o número total de tabelas usando o método
tablesCountcampo.
Vamos criar um segundo visual para o número total de arquivos no Amazon S3 e o tamanho total de armazenamento no Amazon S3.
- Semelhante à etapa anterior, adicionamos um novo visual e escolhemos o
totalfilesons3esizeinmbons3campos para exibir detalhes de armazenamento relacionados ao Amazon S3.
Vamos criar outro visual para verificar quais são os conjuntos de dados menos usados.
- Adicione um visual usando o
LastAccessTimeelemento de dados.
Por fim, vamos criar mais um visual para verificar se os bancos de dados estão recursos compartilhados de contas diferentes.
- Selecione os
databasesconjunto de dados. - Criamos um tipo visual de tabela e adicionamos
databasename,sharedresourceedescriptioncampos.
Agora você tem uma ideia de quais tipos de recursos visuais são possíveis usando esses dados. A captura de tela a seguir é um exemplo de painel finalizado.

limpar
Para evitar cobranças contínuas, exclua as pilhas do CloudFormation e os arquivos de saída no Amazon S3 que você criou durante a implantação. Você precisa excluir os dados nos buckets do S3 antes de excluí-los.
Conclusão
Nesta postagem, mostramos como você pode configurar um painel de métricas operacionais para seu Catálogo de Dados. Configuramos nosso programa para coletar os principais elementos de dados sobre nossas tabelas e bancos de dados do AWS Glue Data Catalog. Em seguida, usamos esse conjunto de dados para construir nosso painel de métricas operacionais e obter insights sobre nosso data lake.
Sobre os autores
 Sachin Thakkar é arquiteto de soluções sênior da Amazon Web Services, trabalhando com um dos principais integradores de sistemas globais (GSI). Ele traz mais de 22 anos de experiência como Arquiteto de TI e Consultor de Tecnologia para grandes instituições. Sua área de foco é em Data & Analytics. A Sachin fornece orientação arquitetônica e oferece suporte ao parceiro GSI na criação de soluções estratégicas do setor na AWS
Sachin Thakkar é arquiteto de soluções sênior da Amazon Web Services, trabalhando com um dos principais integradores de sistemas globais (GSI). Ele traz mais de 22 anos de experiência como Arquiteto de TI e Consultor de Tecnologia para grandes instituições. Sua área de foco é em Data & Analytics. A Sachin fornece orientação arquitetônica e oferece suporte ao parceiro GSI na criação de soluções estratégicas do setor na AWS
- '
- &
- 100
- 107
- 9
- Acesso
- Conta
- Amazon
- Amazon Web Services
- análise
- analítica
- arquitetura
- ÁREA
- AWS
- construir
- Prédio
- negócio
- Capacidade
- alterar
- acusações
- código
- comum
- Coneções
- consultor
- conteúdo
- Covid-19
- Criar
- Atual
- painel de instrumentos
- dados,
- lago data
- banco de dados
- bases de dados
- dia
- Empreendimento
- Meio Ambiente
- vasta experiência
- Campos
- Primeiro nome
- primeira vez
- Foco
- formulário
- formato
- Global
- Growth
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTTPS
- IAM
- ÍCONE
- idéia
- Dados de identificação:
- indústria
- INFORMAÇÕES
- insights
- instituições
- interativo
- IT
- Trabalho
- Empregos
- Chave
- língua
- grande
- principal
- Lista
- localização
- a medida
- Métrica
- Navegação
- parceiro
- Agenda
- público
- Python
- Recursos
- Execute
- corrida
- Escala
- Serverless
- Serviços
- conjunto
- simples
- Tamanho
- So
- Soluções
- SQL
- começado
- Status
- armazenamento
- loja
- lojas
- Estratégico
- suportes
- .
- Equipar
- tempo
- us
- Ver
- web
- serviços web
- ano
- anos