As redes neurais aprendem por meio de números, então cada palavra será mapeada em vetores para representar uma palavra específica. A camada de incorporação pode ser considerada uma tabela de pesquisa que armazena embeddings de palavras e os recupera usando índices.
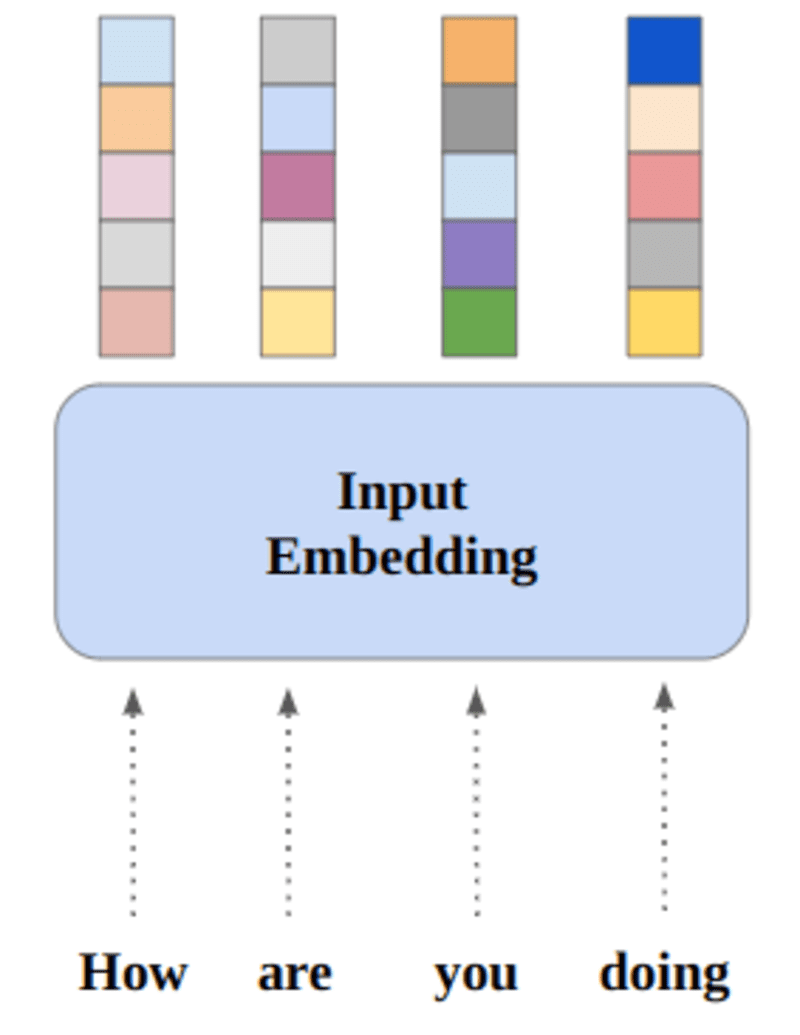
Palavras que têm o mesmo significado serão próximas em termos de distância euclidiana/similaridade de cosseno. por exemplo, na representação da palavra abaixo, “sábado”, “domingo” e “segunda-feira” está associado ao mesmo conceito, portanto podemos ver que as palavras resultam semelhantes.

A determinação da posição da palavra, por que precisamos determinar a posição da palavra? como o codificador do transformador não tem recorrência como as redes neurais recorrentes, devemos adicionar algumas informações sobre as posições nos embeddings de entrada. Isso é feito usando codificação posicional. Os autores do artigo usaram as seguintes funções para modelar a posição de uma palavra.
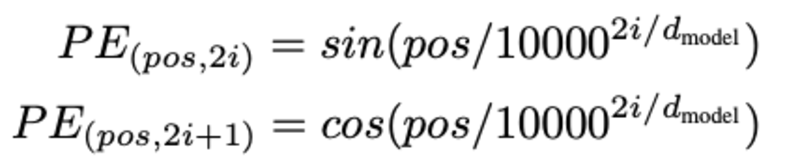
Tentaremos explicar a codificação posicional.
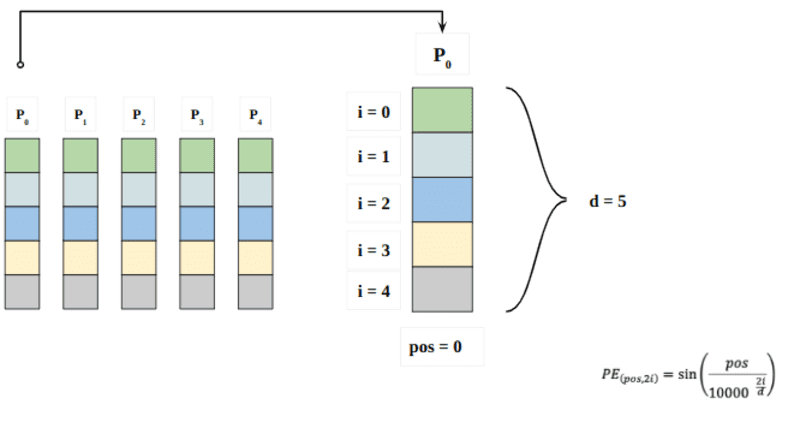
Aqui “pos” refere-se à posição da “palavra” na sequência. P0 refere-se à incorporação de posição da primeira palavra; “d” significa o tamanho da incorporação de palavra/token. Neste exemplo d=5. Finalmente, “i” refere-se a cada uma das 5 dimensões individuais da incorporação (ou seja, 0, 1,2,3,4)
se “i” variar na equação acima, você obterá um monte de curvas com frequências variadas. Lendo os valores de incorporação de posição em relação a diferentes frequências, fornecendo valores diferentes em diferentes dimensões de incorporação para P0 e P4.
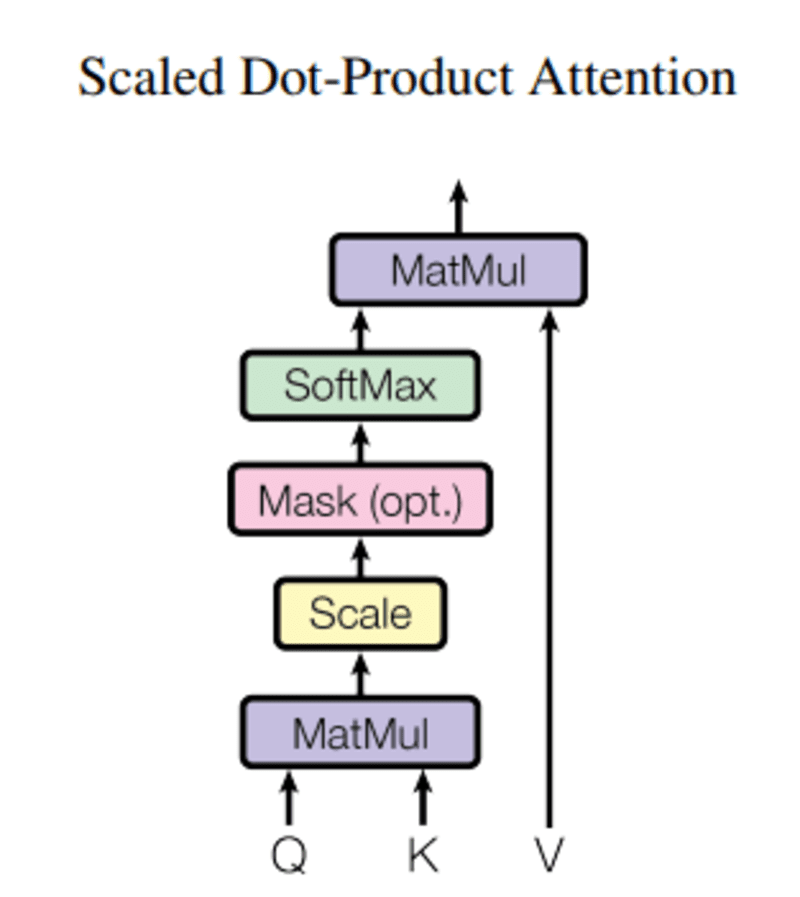
Neste curso consulta, Q representa uma palavra vetorial, o teclas K são todas as outras palavras na frase, e valor V representa o vetor da palavra.
O objetivo da atenção é calcular a importância do termo-chave em comparação com o termo de consulta relacionado à mesma pessoa/coisa ou conceito.
No nosso caso, V é igual a Q.
O mecanismo de atenção nos dá a importância da palavra em uma frase.
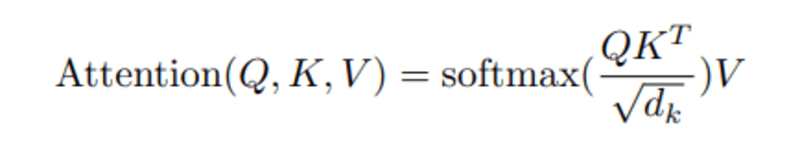
Quando calculamos o produto escalar normalizado entre a consulta e as chaves, obtemos um tensor que representa a importância relativa de cada uma das outras palavras para a consulta.
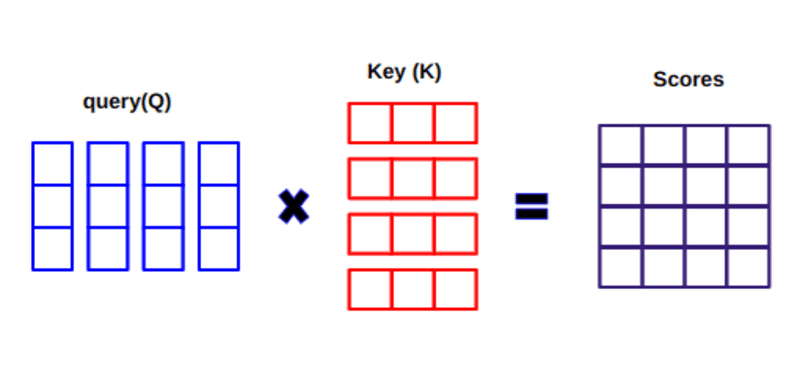
Ao calcular o produto escalar entre Q e KT, tentamos estimar como os vetores (ou seja, palavras entre a consulta e as chaves) estão alinhados e retornam um peso para cada palavra na frase.
Em seguida, normalizamos o resultado ao quadrado de d_k e a função softmax regulariza os termos e os redimensiona entre 0 e 1.
Finalmente, multiplicamos o resultado (ou seja, pesos) pelo valor (ou seja, todas as palavras) para reduzir a importância das palavras não relevantes e focar apenas nas palavras mais importantes.
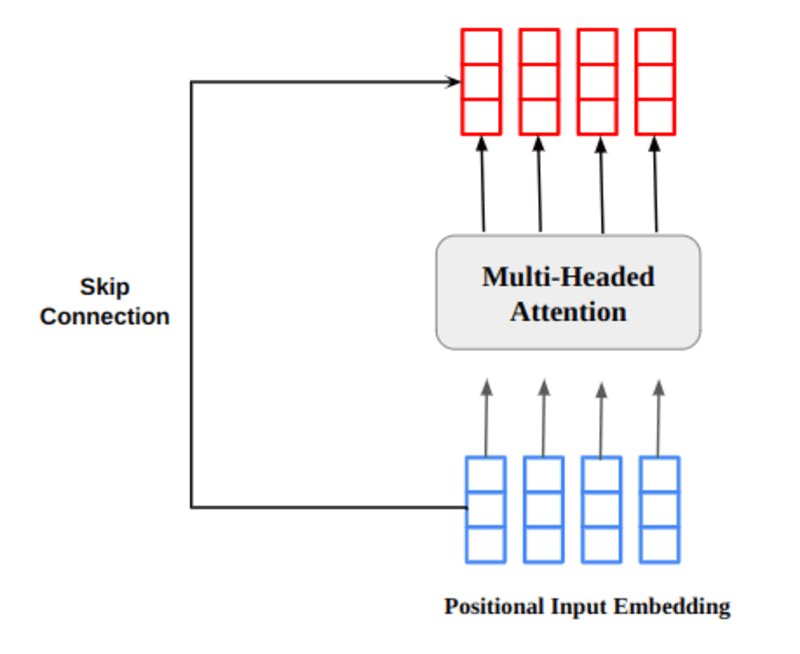
O vetor de saída de atenção com múltiplas cabeças é adicionado à incorporação de entrada posicional original. Isso é chamado de conexão residual/conexão de salto. A saída da conexão residual passa pela normalização da camada. A saída residual normalizada é passada através de uma rede feed-forward pontual para processamento adicional.
A máscara é uma matriz do mesmo tamanho das pontuações de atenção preenchida com valores 0 e infinitos negativos.
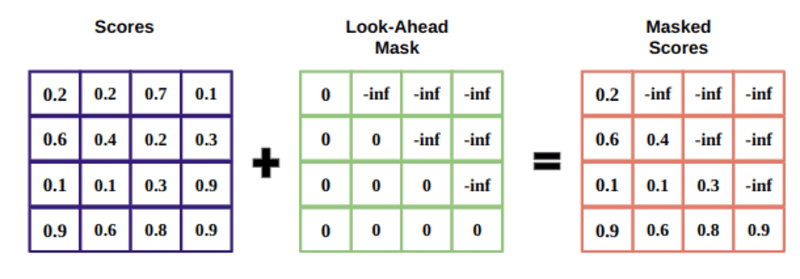
A razão para a máscara é que, uma vez obtido o softmax das pontuações mascaradas, os infinitos negativos chegam a zero, deixando zero pontuações de atenção para tokens futuros.
Isso diz ao modelo para não colocar foco nessas palavras.
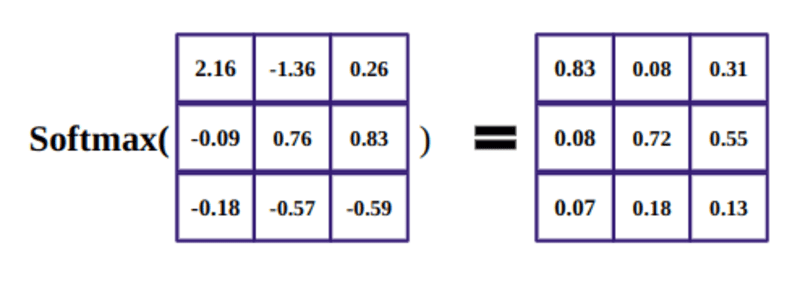
O objetivo da função softmax é pegar números reais (positivos e negativos) e transformá-los em números positivos que somam 1.
Ravikumar Naduvin está ocupado construindo e compreendendo tarefas de PNL usando PyTorch.
Óptimo estado. Original. Republicado com permissão.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://www.kdnuggets.com/2023/01/concepts-know-getting-transformer.html?utm_source=rss&utm_medium=rss&utm_campaign=concepts-you-should-know-before-getting-into-transformer
- 1
- a
- Sobre
- acima
- adicionado
- contra
- alinhado
- Todos os Produtos
- e
- associado
- por WhatsApp.
- autores
- Porque
- antes
- abaixo
- entre
- Prédio
- Monte
- chamado
- casas
- Fechar
- comparado
- Computar
- computação
- conceito
- conceitos
- da conexão
- Determinar
- determinando
- diferente
- dimensões
- DOT
- cada
- estimativa
- exemplo
- Explicação
- preenchida
- Finalmente
- Primeiro nome
- Foco
- seguinte
- função
- funções
- mais distante
- futuro
- ter
- obtendo
- GitHub
- dá
- Dando
- vai
- agarrar
- Como funciona o dobrador de carta de canal
- HTTPS
- importância
- importante
- in
- Índices
- Individual
- INFORMAÇÕES
- entrada
- KDnuggetsGenericName
- Chave
- chaves
- Saber
- camada
- APRENDER
- partida
- pesquisa
- máscara
- Matriz
- significado
- significa
- mecanismo
- modelo
- a maioria
- você merece...
- negativo
- rede
- redes
- Neural
- redes neurais
- PNL
- números
- original
- Outros
- Papel
- particular
- passou
- permissão
- platão
- Inteligência de Dados Platão
- PlatãoData
- posição
- abertas
- positivo
- em processamento
- Produto
- propósito
- colocar
- pytorch
- Leitura
- reais
- razão
- reincidência
- reduzir
- refere-se
- relacionado
- representar
- representação
- representa
- resultar
- resultando
- retorno
- mesmo
- sentença
- Seqüência
- rede de apoio social
- semelhante
- Tamanho
- So
- alguns
- Quadrada
- lojas
- mesa
- Tire
- tarefas
- conta
- condições
- A
- pensamento
- Através da
- para
- Tokens
- transformadores
- VIRAR
- compreensão
- us
- valor
- Valores
- peso
- qual
- precisarão
- Word
- palavras
- zefirnet
- zero







