A limpeza de dados é uma etapa muito importante e crítica em seu projeto de ciência de dados. O sucesso do modelo de máquina depende de como você pré-processa os dados. Se você subestimar e pular o pré-processamento do seu conjunto de dados, o modelo não terá um bom desempenho e você perderá muito tempo procurando entender por que ele não funciona tão bem quanto você esperaria.
Ultimamente, comecei a criar cábulas para agilizar minhas atividades de ciência de dados, em especial um resumo com noções básicas de limpeza de dados. Nesta postagem e cábula, vou mostrar cinco aspectos diferentes que caracterizam as etapas de pré-processamento do seu projeto de ciência de dados.

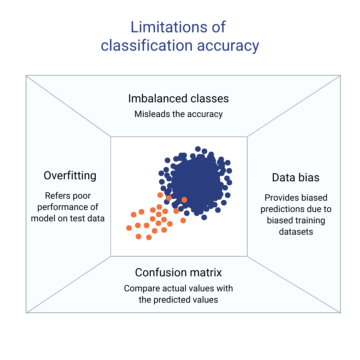
Nesta folha de dicas, vamos desde a detecção e tratamento de dados ausentes, lidando com duplicatas e encontrando soluções para duplicatas, detecção de valores discrepantes, codificação de rótulos e codificação one-hot de recursos categóricos, até transformações, como normalização MinMax e normalização padrão. Além disso, este guia explora os métodos fornecidos por três das bibliotecas Python mais populares, Pandas, Scikit-Learn e Seaborn para exibir gráficos.
Aprender esses truques do Python ajudará você a extrair o máximo de informações possível do conjunto de dados e, conseqüentemente, o modelo de aprendizado de máquina será capaz de ter um desempenho melhor aprendendo com uma entrada limpa e pré-processada.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://www.kdnuggets.com/2023/02/data-cleaning-python-cheat-sheet.html?utm_source=rss&utm_medium=rss&utm_campaign=data-cleaning-with-python-cheat-sheet
- a
- Capaz
- atividades
- e
- aspectos
- fundamentos básicos
- começou
- Melhor
- caracterizar
- Limpeza
- Consequentemente
- crio
- crítico
- dados,
- ciência de dados
- lidar
- depende
- Detecção
- diferente
- exibindo
- Não faz
- duplicatas
- esperar
- façanhas
- extrato
- Funcionalidades
- descoberta
- da
- Go
- vai
- guia
- Manipulação
- ajudar
- Como funciona o dobrador de carta de canal
- HTTPS
- importante
- in
- INFORMAÇÕES
- entrada
- IT
- KDnuggetsGenericName
- O rótulo
- aprendizagem
- bibliotecas
- perder
- lote
- máquina
- aprendizado de máquina
- métodos
- desaparecido
- modelo
- mais
- a maioria
- Mais populares
- pandas
- particular
- realizar
- platão
- Inteligência de Dados Platão
- PlatãoData
- Popular
- possível
- Publique
- projeto
- fornecido
- Python
- Ciência
- scikit-learn
- seaborn
- pesquisar
- mostrar
- Soluções
- velocidade
- padrão
- Passo
- Passos
- sucesso
- tal
- RESUMO
- A
- O Básico
- três
- tempo
- para
- transformações
- truques
- compreender
- precisarão
- Atividades:
- seria
- investimentos
- zefirnet