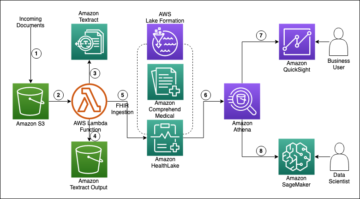
Pesquisas nos últimos anos mostraram que os modelos de aprendizado de máquina (ML) são vulneráveis a entradas adversárias, onde um adversário pode criar entradas para alterar estrategicamente a saída do modelo (em classificação de imagem, reconhecimento de falaou detecção de fraude). Por exemplo, imagine que você implementou um modelo que identifica seus funcionários com base em imagens de seus rostos. Conforme demonstrado no whitepaper Acessórios para um crime: ataques reais e furtivos ao reconhecimento facial de última geração, funcionários mal-intencionados podem aplicar modificações sutis, mas cuidadosamente projetadas, à sua imagem e enganar o modelo para autenticá-los como outros funcionários. Obviamente, essas informações adversárias – especialmente se houver uma quantidade significativa delas – podem ter um impacto devastador nos negócios.
Idealmente, queremos detectar cada vez que uma entrada adversária é enviada ao modelo para quantificar como as entradas adversárias estão impactando seu modelo e negócios. Para este fim, uma ampla classe de métodos analisa as entradas individuais do modelo para verificar o comportamento adversário. No entanto, a investigação activa em ML adversário levou a inputs adversários cada vez mais sofisticados, muitos dos quais são conhecidos por tornarem a detecção ineficaz. A razão para esta deficiência é que é difícil tirar conclusões a partir de uma opinião individual sobre se ela é contraditória ou não. Para este fim, uma classe recente de métodos concentra-se em verificações em nível de distribuição, analisando múltiplas entradas ao mesmo tempo. A ideia principal por trás desses novos métodos é que considerar múltiplas entradas ao mesmo tempo permite uma análise estatística mais poderosa que não é possível com entradas individuais. Porém, diante de um adversário determinado e com profundo conhecimento do modelo, mesmo esses métodos avançados de detecção podem falhar.
No entanto, podemos derrotar até mesmo esses adversários determinados, fornecendo informações adicionais aos métodos de defesa. Especificamente, em vez de apenas analisar as entradas do modelo, a análise das representações latentes coletadas das camadas intermediárias em uma rede neural profunda fortalece significativamente a defesa.
Nesta postagem, orientamos você sobre como detectar entradas adversárias usando Monitor de modelo do Amazon SageMaker e Depurador do Amazon SageMaker para um modelo de classificação de imagens hospedado em Amazon Sage Maker.
Para reproduzir as diferentes etapas e resultados listados nesta postagem, clone o repositório detectando amostras adversárias usando o Sagemaker em sua instância de notebook do Amazon SageMaker e execute o notebook.
Detectando entradas adversárias
Mostramos como detectar entradas adversárias usando as representações coletadas de uma rede neural profunda. As quatro imagens a seguir mostram a imagem de treinamento original à esquerda (retirada do conjunto de dados Tiny ImageNet) e três imagens produzidas pelo ataque Projected Gradient Descent (PGD) [1] com diferentes parâmetros de perturbação ϵ. O modelo usado aqui foi o ResNet18. O parâmetro ϵ define a quantidade de ruído adversário adicionado às imagens. A imagem original (esquerda) foi prevista corretamente como classe 67 (goose). As imagens 2, 3 e 4 modificadas adversamente são previstas incorretamente como classe 51 (mantis) pelo modelo ResNet18. Também podemos ver que as imagens geradas com ϵ pequeno são perceptualmente indistinguíveis da imagem de entrada original.

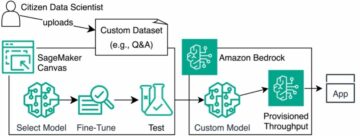
A seguir, criamos um conjunto de imagens normais e adversárias e usamos Incorporação de vizinho estocástico distribuído em t (t-SNE [2]) para comparar visualmente suas distribuições. t-SNE é um método de redução de dimensionalidade que mapeia dados de alta dimensão em um espaço bidimensional ou tridimensional. Cada ponto de dados na imagem a seguir apresenta uma imagem de entrada. Os pontos de dados laranja apresentam as entradas normais obtidas do conjunto de teste, e os pontos de dados azuis indicam as imagens adversárias correspondentes geradas com um épsilon de 2. Se as entradas normais e adversárias forem distinguíveis, esperaríamos clusters separados na visualização t-SNE. Como ambos pertencem ao mesmo cluster, isso significa que uma técnica de detecção que se concentra apenas nas mudanças na distribuição de entradas do modelo não consegue distinguir essas entradas.

Vamos dar uma olhada mais de perto nas representações de camadas produzidas por diferentes camadas no modelo ResNet18. ResNet18 consiste em 18 camadas; na imagem a seguir, visualizamos os embeddings t-SNE para as representações de seis dessas camadas.

Como mostra a figura anterior, as entradas naturais e adversárias tornam-se mais distinguíveis para camadas mais profundas do modelo ResNet18.
Com base nessas observações, utilizamos um método estatístico que mede a distinguibilidade com testes de hipóteses. O método consiste em um teste de duas amostras utilização discrepância média máxima (MMD). MMD é uma métrica baseada em kernel para medir a similaridade entre duas distribuições que geram os dados. Um teste de duas amostras pega dois conjuntos que contêm entradas extraídas de duas distribuições e determina se essas distribuições são iguais. Comparamos a distribuição das entradas observadas nos dados de treinamento e a comparamos com a distribuição das entradas recebidas durante a inferência.
Nosso método usa essas entradas para estimar o valor p usando MMD. Se o valor p for maior que um limite de significância específico do usuário (5% no nosso caso), concluímos que ambas as distribuições são diferentes. O limite ajusta a compensação entre falsos positivos e falsos negativos. Um limite mais alto, como 10%, diminui a taxa de falsos negativos (há menos casos em que ambas as distribuições eram diferentes, mas o teste não conseguiu indicar isso). No entanto, também resulta em mais falsos positivos (o teste indica que ambas as distribuições são diferentes, mesmo quando esse não é o caso). Por outro lado, um limite mais baixo, como 1%, resulta em menos falsos positivos, mas em mais falsos negativos.
Em vez de aplicar este método apenas nas entradas brutas do modelo (imagens), usamos as representações latentes produzidas pelas camadas intermediárias do nosso modelo. Para explicar sua natureza probabilística, aplicamos o teste de hipótese 100 vezes em 100 entradas naturais selecionadas aleatoriamente e 100 entradas adversárias selecionadas aleatoriamente. Em seguida, reportamos a taxa de detecção como a porcentagem de testes que resultaram em um evento de detecção de acordo com nosso limite de significância de 5%. A taxa de detecção mais alta é uma indicação mais forte de que as duas distribuições são diferentes. Este procedimento nos dá as seguintes taxas de detecção:
- Camada 1: 3%
- Camada 4: 7%
- Camada 8: 84%
- Camada 12: 95%
- Camada 14: 100%
- Camada 15: 100%
Nas camadas iniciais, a taxa de detecção é bastante baixa (menos de 10%), mas aumenta para 100% nas camadas mais profundas. Usando o teste estatístico, o método pode detectar com segurança entradas adversárias em camadas mais profundas. Muitas vezes é suficiente simplesmente usar as representações geradas pela penúltima camada (a última camada antes da camada de classificação em um modelo). Para entradas adversárias mais sofisticadas, é útil usar representações de outras camadas e agregar as taxas de detecção.
Visão geral da solução
Na seção anterior, vimos como detectar entradas adversárias usando representações da penúltima camada. A seguir, mostramos como automatizar esses testes no SageMaker usando Model Monitor e Debugger. Para este exemplo, primeiro treinamos um modelo ResNet18 de classificação de imagem no pequeno conjunto de dados ImageNet. Em seguida, implantamos o modelo no SageMaker e criamos uma programação personalizada do Model Monitor que executa o teste estatístico. Depois, executamos inferência com entradas normais e adversárias para ver quão eficaz é o método.
Capture tensores usando o Debugger
Durante o treinamento do modelo, utilizamos o Debugger para capturar representações geradas pela penúltima camada, que são utilizadas posteriormente para derivar informações sobre a distribuição das entradas normais. Debugger é um recurso do SageMaker que permite capturar e analisar informações como parâmetros do modelo, gradientes e ativações durante o treinamento do modelo. Esses tensores de parâmetro, gradiente e ativação são carregados em Serviço de armazenamento simples da Amazon (Amazon S3) enquanto o treinamento está em andamento. Você pode configurar regras que os analisam em busca de problemas como overfitting e desaparecimento de gradientes. Para nosso caso de uso, queremos capturar apenas a penúltima camada do modelo (.*avgpool_output) e os resultados do modelo (previsões). Especificamos uma configuração de gancho do Debugger que define uma expressão regular para as representações da camada a serem coletadas. Também especificamos um save_interval que instrui o Debugger a coletar esses dados durante a fase de validação a cada 100 passes de encaminhamento. Veja o seguinte código:
Execute o treinamento do SageMaker
Passamos a configuração do Debugger para o estimador SageMaker e iniciamos o treinamento:
Implantar um modelo de classificação de imagens
Após a conclusão do treinamento do modelo, implantamos o modelo como um endpoint no SageMaker. Nós especificamos um roteiro de inferência que define o model_fn e transform_fn funções. Essas funções especificam como o modelo é carregado e como os dados recebidos precisam ser pré-processados para realizar a inferência do modelo. Para nosso caso de uso, permitimos que o Debugger capture dados relevantes durante a inferência. No model_fn função, especificamos um gancho Debugger e um save_config que especifica que para cada solicitação de inferência, as entradas do modelo (imagens), as saídas do modelo (previsões) e a penúltima camada são registradas (.*avgpool_output). Em seguida, registramos o gancho no modelo. Veja o seguinte código:
Agora implantamos o modelo, o que podemos fazer no notebook de duas maneiras. Podemos ligar pytorch_estimator.deploy() ou crie um modelo PyTorch que aponte para os arquivos de artefato do modelo no Amazon S3 que foram criados pelo trabalho de treinamento do SageMaker. Neste post, fazemos o último. Isso nos permite passar variáveis de ambiente para o contêiner Docker, que é criado e implantado pelo SageMaker. Precisamos da variável de ambiente tensors_output para informar ao script onde fazer upload dos tensores coletados pelo SageMaker Debugger durante a inferência. Veja o seguinte código:
A seguir, implantamos o preditor em um tipo de instância ml.m5.xlarge:
Crie uma programação personalizada do Model Monitor
Quando o endpoint estiver instalado e funcionando, criamos uma programação personalizada do Model Monitor. Isto é um Trabalho de processamento do SageMaker que é executado em um intervalo periódico (como de hora em hora ou diariamente) e analisa os dados de inferência. O Model Monitor fornece um contêiner pré-configurado que analisa e detecta desvios de dados. Em nosso caso, queremos personalizá-lo para buscar os dados do Debugger e executar o teste MMD de duas amostras nas representações da camada recuperadas.
Para personalizá-lo, primeiro definimos o objeto Model Monitor, que especifica em qual tipo de instância esses trabalhos serão executados e a localização de nosso contêiner Model Monitor personalizado:
Queremos executar esse trabalho de hora em hora, então especificamos CronExpressionGenerator.hourly() e os locais de saída para onde os resultados da análise são carregados. Para isso precisamos definir ProcessingOutput para a saída do processamento do SageMaker:
Vamos examinar mais de perto o que nosso contêiner Model Monitor personalizado está executando. Nós criamos um roteiro de avaliação, que carrega os dados capturados pelo Debugger. Também criamos um objeto de teste, o que nos permite acessar, consultar e filtrar os dados que o Debugger salvou. Com o objeto de teste, podemos iterar as etapas salvas durante as fases de inferência e treinamento trial.steps(mode).
Primeiro, buscamos as saídas do modelo (trial.tensor("ResNet_output_0")) bem como a penúltima camada (trial.tensor_names(regex=".*avgpool_output")). Fazemos isso para as fases de inferência e validação do treinamento (modes.EVAL e modes.PREDICT). Os tensores da fase de validação servem como uma estimativa da distribuição normal, que então usamos para comparar a distribuição dos dados de inferência. Criamos uma classe LADIS (Detectando distribuições de entrada adversárias por meio de estatísticas em camadas). Esta classe fornece as funcionalidades relevantes para realizar o teste de duas amostras. Ele pega a lista de tensores das fases de inferência e validação e executa o teste de duas amostras. Ele retorna uma taxa de detecção, que é um valor entre 0–100%. Quanto maior o valor, maior a probabilidade de os dados de inferência seguirem uma distribuição diferente. Além disso, calculamos uma pontuação para cada amostra que indica a probabilidade de uma amostra ser adversária e as 100 principais amostras são registradas, para que os usuários possam inspecioná-las posteriormente. Veja o seguinte código:
Teste contra entradas adversárias
Agora que nosso cronograma personalizado do Model Monitor foi implantado, podemos produzir alguns resultados de inferência.
Primeiro, executamos com dados do conjunto de validação e depois com entradas adversárias:
Podemos então verificar a exibição do Model Monitor em Estúdio Amazon SageMaker ou uso Amazon CloudWatch logs para ver se um problema foi encontrado.

A seguir, usamos as entradas adversárias no modelo hospedado no SageMaker. Usamos o conjunto de dados de teste do conjunto de dados Tiny ImageNet e aplicamos o ataque PGD, que introduz perturbações no nível do pixel de forma que o modelo não reconhece as classes corretas. Nas imagens a seguir, a coluna da esquerda mostra duas imagens de teste originais, a coluna do meio mostra suas versões perturbadas pelo adversário e a coluna da direita mostra a diferença entre as duas imagens.

Agora podemos verificar o status do Model Monitor e ver que algumas das imagens de inferência foram extraídas de uma distribuição diferente.

Resultados e ação do usuário
O trabalho personalizado do Model Monitor determina pontuações para cada solicitação de inferência, o que indica a probabilidade de a amostra ser adversária de acordo com o teste MMD. Essas pontuações são coletadas para todas as solicitações de inferência. A pontuação com o número da etapa do Debugger correspondente é registrada em um arquivo JSON e carregada no Amazon S3. Após a conclusão do trabalho de monitoramento de modelo, baixamos o arquivo JSON, recuperamos os números das etapas e usamos o Debugger para recuperar as entradas do modelo correspondentes para essas etapas. Isso nos permite inspecionar as imagens que foram detectadas como adversárias.
O bloco de código a seguir representa as duas primeiras imagens que foram identificadas como as mais prováveis de serem adversárias:
Em nosso exemplo de execução de teste, obtemos a seguinte saída. A imagem da água-viva foi prevista incorretamente como uma laranja e a imagem do camelo como um panda. Obviamente, o modelo falhou nessas entradas e nem sequer previu uma classe de imagem semelhante, como peixinho dourado ou cavalo. Para comparação, também mostramos as amostras naturais correspondentes do conjunto de testes no lado direito. Podemos observar que as perturbações aleatórias introduzidas pelo atacante são bem visíveis no fundo de ambas as imagens.


O trabalho personalizado do Model Monitor publica a taxa de detecção no CloudWatch, para que possamos investigar como essa taxa mudou ao longo do tempo. Uma mudança significativa entre dois pontos de dados pode indicar que um adversário estava tentando enganar o modelo em um período de tempo específico. Além disso, você também pode representar graficamente o número de solicitações de inferência processadas em cada trabalho do Model Monitor e a taxa de detecção de linha de base, que é calculada no conjunto de dados de validação. A taxa básica geralmente é próxima de 0 e serve apenas como uma métrica de comparação.
A captura de tela a seguir mostra as métricas geradas por nossas execuções de teste, que executaram três trabalhos de monitoramento de modelo durante 3 horas. Cada trabalho processa aproximadamente 200 a 300 solicitações de inferência por vez. A taxa de detecção é de 100% entre 5h e 00h e cai depois.

Além disso, também podemos inspecionar as distribuições das representações geradas pelas camadas intermediárias do modelo. Com o Debugger, podemos acessar os dados da fase de validação do trabalho de treinamento e os tensores da fase de inferência, e usar t-SNE para visualizar sua distribuição para determinadas classes previstas. Veja o seguinte código:
Em nosso caso de teste, obtemos a seguinte visualização t-SNE para a segunda classe de imagem. Podemos observar que as amostras adversárias estão agrupadas de forma diferente das naturais.

Resumo
Neste post, mostramos como usar um teste de duas amostras usando discrepância média máxima para detectar entradas adversárias. Demonstramos como você pode implantar esses mecanismos de detecção usando o Debugger e o Model Monitor. Este fluxo de trabalho permite monitorar seus modelos hospedados no SageMaker em escala e detectar entradas adversárias automaticamente. Para saber mais sobre isso, confira nosso GitHub repo.
Referências
[1] Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras e Adrian Vladu. Rumo a modelos de aprendizagem profunda resistentes a ataques adversários. Em Conferência Internacional sobre Representações de Aprendizagem 2018.
[2] Laurens van der Maaten e Geoffrey Hinton. Visualizando dados usando t-SNE. Journal of Machine Learning Research, 9:2579–2605, 2008. URL http://www.jmlr.org/papers/v9/vandermaaten08a.html.
Sobre os autores
 Natalie Rauschmayr é Cientista Aplicada Sênior na AWS, onde ajuda os clientes a desenvolver aplicativos de aprendizado profundo.
Natalie Rauschmayr é Cientista Aplicada Sênior na AWS, onde ajuda os clientes a desenvolver aplicativos de aprendizado profundo.
 Yigitcan Kaya é estudante de doutorado do quinto ano na Universidade de Maryland e estagiário científico aplicado na AWS, trabalhando em segurança de aprendizado de máquina e aplicações de aprendizado de máquina para segurança.
Yigitcan Kaya é estudante de doutorado do quinto ano na Universidade de Maryland e estagiário científico aplicado na AWS, trabalhando em segurança de aprendizado de máquina e aplicações de aprendizado de máquina para segurança.
 Bilal Zafar é um cientista aplicado na AWS, trabalhando em justiça, explicabilidade e segurança em aprendizado de máquina.
Bilal Zafar é um cientista aplicado na AWS, trabalhando em justiça, explicabilidade e segurança em aprendizado de máquina.
 Sergul Aydore é cientista aplicado sênior na AWS e trabalha com privacidade e segurança em aprendizado de máquina
Sergul Aydore é cientista aplicado sênior na AWS e trabalha com privacidade e segurança em aprendizado de máquina
- Coinsmart. A melhor troca de Bitcoin e criptografia da Europa.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. ACESSO LIVRE.
- CryptoHawk. Radar Altcoin. Teste grátis.
- Fonte: https://aws.amazon.com/blogs/machine-learning/detect-adversarial-inputs-using-amazon-sagemaker-model-monitor-and-amazon-sagemaker-debugger/
- "
- 10
- 100
- 67
- 9
- Sobre
- Acesso
- Segundo
- Conta
- ativo
- Adicional
- avançado
- Todos os Produtos
- Amazon
- quantidade
- análise
- aplicações
- Aplicando
- aproximadamente
- AWS
- fundo
- Linha de Base
- base
- tornam-se
- ser
- Bloquear
- negócio
- chamada
- capturar
- casos
- alterar
- Cheques
- classe
- aulas
- classificação
- mais próximo
- código
- coletar
- Coluna
- Computar
- Conferência
- Configuração
- Recipiente
- contribuir
- criado
- Crime
- personalizadas
- Clientes
- dados,
- mais profunda
- Defesa
- demonstraram
- implantar
- implantado
- detectou
- Detecção
- desenvolver
- diferente
- difícil
- Ecrã
- distribuição
- Estivador
- Não faz
- Eficaz
- colaboradores
- permitir
- Ponto final
- Meio Ambiente
- estimativa
- Evento
- exemplo
- esperar
- Rosto
- rostos
- Característica
- Figura
- Primeiro nome
- concentra-se
- seguinte
- para a frente
- encontrado
- QUADRO
- cheio
- função
- mais distante
- gerando
- vai
- maior
- ajuda
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- superior
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTTPS
- idéia
- imagem
- Impacto
- índice
- Individual
- INFORMAÇÕES
- entrada
- investigar
- emitem
- questões
- IT
- Trabalho
- Empregos
- revista
- Chave
- Conhecimento
- conhecido
- Rótulos
- grande
- APRENDER
- aprendizagem
- levou
- Nível
- Provável
- Lista
- Listado
- localização
- locais
- máquina
- aprendizado de máquina
- mapas
- Maryland
- Métrica
- MIT
- ML
- modelo
- modelos
- Monitore
- monitoração
- mais
- a maioria
- múltiplo
- natural
- Natureza
- rede
- Ruído
- normal
- caderno
- número
- números
- Outros
- percentagem
- fase
- ponto
- possível
- poderoso
- predizer
- predição
- Previsões
- presente
- política de privacidade
- Privacidade e segurança
- processos
- produzir
- Produzido
- fornece
- fornecendo
- Preços
- Cru
- reconhecer
- cadastre-se
- regular
- relevante
- Denunciar
- repositório
- solicitar
- pedidos
- pesquisa
- Resultados
- Retorna
- regras
- Execute
- corrida
- Escala
- Cientista
- segurança
- selecionado
- conjunto
- periodo
- semelhante
- simples
- SIX
- pequeno
- So
- alguns
- sofisticado
- Espaço
- especificamente
- começo
- estado-da-arte
- estatístico
- estatística
- stats
- Status
- armazenamento
- estudante
- teste
- ensaio
- testes
- Através da
- tempo
- topo
- para
- Training
- julgamento
- universidade
- us
- usar
- usuários
- geralmente
- valor
- visível
- visualização
- Vulnerável
- O Quê
- se
- enquanto
- Whitepaper
- Wikipedia
- trabalhar
- seria
- ano
- anos