Procurando extrair dados de documentos digitalizados? Tentar Nanoredes™ avançado Scanner OCR baseado em IA extrair e organizar informações de Documentos escaneados automaticamente.
Introdução
À medida que o mundo passou de papéis e manuscritos para documentos digitais por conveniência, a importância de converter imagens e documentos digitalizados em dados significativos disparou.
Para acompanhar a necessidade de extração de dados de documentos altamente precisas, inúmeras instalações de pesquisa e corporações (ou seja, Google, AWS, Nanonets etc.) concentraram-se profundamente nas tecnologias nas áreas de visão computacional e Processamento de Linguagem Natural (PNL).
O florescimento das tecnologias de aprendizagem profunda garantiu um salto gigantesco no tipo de dados que podem ser extraídos; não estamos mais limitados a extrair apenas texto, mas também outras estruturas de dados, como tabelas e pares de valores-chave. Muitas soluções agora oferecem diversos produtos para atender às necessidades de indivíduos e proprietários de empresas na extração de dados de documentos.
Este artigo se aprofunda na tecnologia atual usada para extração de dados de documentos digitalizados, seguido por um breve tutorial prático em Python. Também veremos algumas das soluções populares atualmente no mercado que oferecem as melhores ofertas neste campo.

O que é extração de dados?
A extração de dados é o processo de conversão de dados não estruturados em informações interpretáveis por programas para permitir o processamento posterior de dados por humanos. Aqui listamos vários dos tipos de dados mais comuns a serem extraídos de documentos digitalizados.
Dados de texto
A tarefa mais comum e importante na extração de dados de documentos digitalizados é a extração de texto. Este processo, embora aparentemente simples, é na verdade muito difícil, uma vez que os documentos digitalizados são frequentemente apresentados no formato de imagens. Além disso, os métodos de extração são altamente dependentes dos tipos de texto. Embora o texto esteja presente em formatos impressos densos na maior parte do tempo, a capacidade de extrair texto esparso de documentos menos digitalizados ou de cartas manuscritas com estilos drasticamente variados é igualmente importante. Tal processo permitirá que os programas convertam imagens em texto codificado por máquina, onde poderemos organizá-los ainda mais a partir de dados não estruturados (sem formatação específica) em dados estruturados para análise posterior.
Tabelas
Os formulários tabulares são a abordagem mais popular para armazenamento de dados, pois o formato é facilmente interpretável pelo olho humano. O processo de extração de tabelas de documentos digitalizados requer tecnologia além da detecção de caracteres – é preciso detectar as linhas e outros recursos visuais para realizar uma extração de tabela adequada e converter ainda mais essas informações em dados estruturados para posterior cálculo. Os métodos de visão computacional (descritos em detalhes nas seções a seguir) são muito usados para obter extração de tabelas de alta precisão.

Pares de valores-chave
Um formato alternativo que frequentemente adotamos em documentos para armazenamento de dados são os pares chave-valor (KVPs).

KVPs são essencialmente dois itens de dados – uma chave e um valor – vinculados como um só. A chave é usada como um identificador exclusivo para o valor a ser recuperado. Um exemplo clássico de KVP é o dicionário, onde os vocabulários são as chaves e as definições correspondentes são os valores. Esses pares, embora geralmente despercebidos, estão sendo usados com muita frequência em documentos: perguntas em pesquisas como nome, idade e preços de itens em faturas são todas implicitamente KVPs.
No entanto, ao contrário das tabelas, os KVPs geralmente existem em formatos desconhecidos e às vezes são parcialmente manuscritos. Por exemplo, as chaves podem ser pré-impressas em caixas e os valores podem ser escritos à mão no preenchimento do formulário. Portanto, encontrar as estruturas subjacentes para realizar automaticamente a extração de KVP é um processo de pesquisa contínuo, mesmo para as instalações e laboratórios mais avançados.
figuras
Finalmente, também é muito importante extrair ou capturar dados a partir de figuras em um documento digitalizado. Indicadores estatísticos, como gráficos de pizza e de barras, geralmente incluem informações cruciais para documentos. Um bom processo de extração de dados deve ser capaz de inferir das legendas e dos números para extrair parcialmente os dados das figuras para uso posterior.
Procurando extrair dados de documentos digitalizados? Dê Nanonets™ um giro para maior precisão, maior flexibilidade, pós-processamento e um amplo conjunto de integrações!
Tecnologias por trás da extração de dados
A extração de dados gira em torno de dois processos principais: Reconhecimento óptico de caracteres (OCR) seguido por Processamento de Linguagem Natural (PNL).
A extração de OCR é o processo de conversão de imagens de texto em texto codificado por máquina, enquanto a última é a análise das palavras para inferir significados. Freqüentemente acompanhadas do OCR estão outras técnicas de visão computacional, como detecção de caixas e linhas, para extrair os tipos de dados mencionados acima, como tabelas e KVPs, para uma extração mais abrangente.
As principais melhorias por trás do pipeline de extração de dados estão intimamente ligadas aos avanços na aprendizagem profunda que contribuíram enormemente para os campos da visão computacional e do processamento de linguagem natural (PNL).
O que é aprendizado profundo?
O aprendizado profundo tem um papel importante por trás do entusiasmo da era da inteligência artificial e tem sido constantemente empurrado para a vanguarda em inúmeras aplicações. Na engenharia tradicional, nosso objetivo é projetar um sistema/função que gere uma saída a partir de uma determinada entrada; a aprendizagem profunda, por outro lado, depende das entradas e saídas para encontrar a relação intermediária que pode ser estendida a novos dados invisíveis através dos chamados rede neural.
Uma rede neural ou um perceptron multicamadas (MLP), é uma arquitetura de aprendizado de máquina inspirada na forma como o cérebro humano aprende. A rede contém neurônios, que imitam neurônios biológicos e “ativam” quando recebem informações diferentes. Conjuntos de neurônios formam camadas, e múltiplas camadas são empilhadas juntas para formar uma rede para servir aos propósitos de previsão de múltiplas formas (ou seja, classificações de imagens ou caixas delimitadoras para detecções de objetos).

No campo da visão computacional, um tipo de variação de rede neural é fortemente aplicado – redes neurais convolucionais (CNNs). Em vez de camadas tradicionais, uma CNN adota núcleos convolucionais que deslizam através de tensores (ou vetores de alta dimensão) para extração de características. No final, acompanhadas de camadas de rede tradicionais, as CNNs são muito bem-sucedidas em tarefas relacionadas a imagens e formaram a base para extração de OCR e detecção de outros recursos.
Por outro lado, a PNL depende de outro conjunto de redes, que se concentra em dados de séries temporais. Ao contrário das imagens, onde uma imagem é independente uma da outra, a previsão de texto pode ser amplamente beneficiada se as palavras anteriores ou posteriores também forem levadas em consideração. Nos últimos anos, uma família de redes, nomeadamente memórias de longo e curto prazo (LSTMs), que utiliza resultados anteriores como entradas para prever os resultados atuais. LSTMs bilaterais também foram frequentemente adotados para melhorar o resultado da previsão, onde os resultados anteriores e posteriores foram considerados. Nos últimos anos, no entanto, um conceito de transformadores que utiliza um mecanismo de atenção está começando a surgir devido à sua maior flexibilidade, levando a melhores resultados do que as redes tradicionais que lidam com séries temporais sequenciais.
Aplicações de extração de dados
O principal objetivo da extração de dados é converter dados de documentos não estruturados em formatos estruturados, nos quais uma recuperação altamente precisa de textos, figuras e estruturas de dados pode ser muito útil para análises numéricas e contextuais. Essas análises podem ser muito úteis, especialmente para empresas:
O negócio
As grandes empresas e grandes organizações lidam diariamente com milhares de documentos com formatos semelhantes – os grandes bancos recebem inúmeras candidaturas idênticas e as equipas de investigação têm de analisar pilhas de formulários para realizar análises estatísticas. Portanto, a automação da etapa inicial de extração de dados de documentos reduz significativamente a redundância de recursos humanos e permite que os trabalhadores se concentrem na análise de dados e na revisão de aplicativos em vez de digitar informações.
- Verificando aplicativos — As empresas recebem toneladas de inscrições, sejam elas manuscritas ou apenas por meio de formulários de inscrição. Na maioria das vezes, esses aplicativos podem ser acompanhados de identificações pessoais para fins de verificação. Documentos de identidade digitalizados, como passaportes ou cartões, geralmente vêm em lotes com formatos semelhantes. Portanto, um extrator de dados bem escrito pode converter rapidamente os dados (textos, tabelas, figuras, KVPs) em textos compreensíveis por máquina, o que poderia reduzir substancialmente as horas de trabalho nessas tarefas e focar na seleção de aplicativos em vez da extração.
- Reconciliação de Pagamento — Reconciliação de pagamentos é o processo de comparação de extratos bancários para garantir a correspondência de números entre contas, que gira fortemente em torno da extração de dados de documentos — uma questão desafiadora para uma empresa com tamanho considerável e diversas fontes de fluxo de receitas. A extração de dados pode facilitar esse processo e permitir que os funcionários se concentrem em dados incorretos e explorem possíveis eventos fraudulentos sobre o fluxo de caixa.
- Análise Estatística — O feedback dos clientes ou participantes de experimentos é usado por empresas e organizações para melhorar seus produtos e serviços, e uma avaliação abrangente do feedback geralmente precisará de uma análise estatística. No entanto, os dados da pesquisa podem existir em vários formatos ou ocultos entre textos com vários formatos. A extração de dados poderia facilitar o processo, apontando dados óbvios de documentos em lotes, facilitando o processo de localização de processos úteis e, em última análise, aumentando a eficiência.
- Compartilhando registros anteriores — Dos cuidados de saúde à mudança de serviços bancários, as grandes indústrias exigem frequentemente informações de novos clientes que podem já existir noutros locais. Por exemplo, um paciente que muda de hospital devido a uma mudança pode ter registros médicos pré-existentes que podem ser úteis para o novo hospital. Nesses casos, um bom software de extração de dados é útil, pois basta que o indivíduo traga um histórico digitalizado de registros para o novo hospital para preencher automaticamente todas as informações. Isto não só seria conveniente, mas também poderia evitar riscos extensos, especialmente no setor de saúde, de importantes registros de pacientes serem ignorados.
Procurando extrair dados de documentos digitalizados? Dê Nanonets™ um giro para maior precisão, maior flexibilidade, pós-processamento e um amplo conjunto de integrações!
Tutoriais
Para fornecer uma visão mais clara sobre como realizar a extração de dados, mostramos dois conjuntos de métodos para realizar a extração de dados de documentos digitalizados.
Construindo do zero
Pode-se construir um mecanismo OCR simples de extração de dados por meio do mecanismo PyTesseract da seguinte forma:
try: from PIL import Image
except ImportError: import Image
import pytesseract # If you don't have tesseract executable in your PATH, include the following:
pytesseract.pytesseract.tesseract_cmd = r'<full_path_to_your_tesseract_executable>'
# Example tesseract_cmd = r'C:Program Files (x86)Tesseract-OCRtesseract' # Simple image to string
print(pytesseract.image_to_string(Image.open('test.png'))) # List of available languages
print(pytesseract.get_languages(config='')) # French text image to string
print(pytesseract.image_to_string(Image.open('test-european.jpg'), lang='fra')) # In order to bypass the image conversions of pytesseract, just use relative or absolute image path
# NOTE: In this case you should provide tesseract supported images or tesseract will return error
print(pytesseract.image_to_string('test.png')) # Batch processing with a single file containing the list of multiple image file paths
print(pytesseract.image_to_string('images.txt')) # Timeout/terminate the tesseract job after a period of time
try: print(pytesseract.image_to_string('test.jpg', timeout=2)) # Timeout after 2 seconds print(pytesseract.image_to_string('test.jpg', timeout=0.5)) # Timeout after half a second
except RuntimeError as timeout_error: # Tesseract processing is terminated pass # Get bounding box estimates
print(pytesseract.image_to_boxes(Image.open('test.png'))) # Get verbose data including boxes, confidences, line and page numbers
print(pytesseract.image_to_data(Image.open('test.png'))) # Get information about orientation and script detection
print(pytesseract.image_to_osd(Image.open('test.png'))) # Get a searchable PDF
pdf = pytesseract.image_to_pdf_or_hocr('test.png', extension='pdf')
with open('test.pdf', 'w+b') as f: f.write(pdf) # pdf type is bytes by default # Get HOCR output
hocr = pytesseract.image_to_pdf_or_hocr('test.png', extension='hocr') # Get ALTO XML output
xml = pytesseract.image_to_alto_xml('test.png')Para obter mais informações sobre o código, você pode conferir o oficial documentação.
Em palavras simples, o código extrai dados como textos e caixas delimitadoras de uma determinada imagem. Embora bastante útil, o mecanismo não é tão forte quanto os fornecidos por soluções avançadas devido ao seu poder computacional substancial para treinamento.
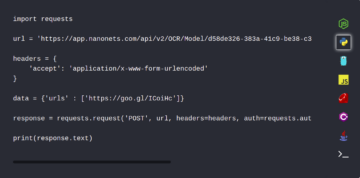
Usando a API de documentos do Google
def async_detect_document(gcs_source_uri, gcs_destination_uri):
"""OCR with PDF/TIFF as source files on GCS""" import json import re from google.cloud import vision from google.cloud import storage # Supported mime_types are: 'application/pdf' and 'image/tiff' mime_type = 'application/pdf' # How many pages should be grouped into each json output file. batch_size = 2 client = vision.ImageAnnotatorClient() feature = vision.Feature( type_=vision.Feature.Type.DOCUMENT_TEXT_DETECTION) gcs_source = vision.GcsSource(uri=gcs_source_uri) input_config = vision.InputConfig( gcs_source=gcs_source, mime_type=mime_type) gcs_destination = vision.GcsDestination(uri=gcs_destination_uri) output_config = vision.OutputConfig( gcs_destination=gcs_destination, batch_size=batch_size) async_request = vision.AsyncAnnotateFileRequest( features=[feature], input_config=input_config, output_config=output_config) operation = client.async_batch_annotate_files( requests=[async_request]) print('Waiting for the operation to finish.') operation.result(timeout=420) # Once the request has completed and the output has been # written to GCS, we can list all the output files. storage_client = storage.Client() match = re.match(r'gs://([^/]+)/(.+)', gcs_destination_uri) bucket_name = match.group(1) prefix = match.group(2) bucket = storage_client.get_bucket(bucket_name) # List objects with the given prefix. blob_list = list(bucket.list_blobs(prefix=prefix)) print('Output files:') for blob in blob_list: print(blob.name) # Process the first output file from GCS. # Since we specified batch_size=2, the first response contains # the first two pages of the input file. output = blob_list[0] json_string = output.download_as_string() response = json.loads(json_string) # The actual response for the first page of the input file. first_page_response = response['responses'][0] annotation = first_page_response['fullTextAnnotation'] # Here we print the full text from the first page. # The response contains more information: # annotation/pages/blocks/paragraphs/words/symbols # including confidence scores and bounding boxes print('Full text:n') print(annotation['text'])Em última análise, a IA de documentos do Google permite extrair inúmeras informações de documentos com alta precisão. Além disso, o serviço também é oferecido para usos específicos, incluindo extração de texto para imagens normais e selvagens.
Por favor, consulte SUA PARTICIPAÇÃO FAZ A DIFERENÇA para mais.
Soluções atuais que oferecem extração de dados
Além de grandes corporações com APIs para extração de dados de documentos, existem diversas soluções que fornecem alta precisão PDFOCR Serviços. Apresentamos diversas opções de PDF OCR especializadas em diferentes aspectos, bem como alguns protótipos de pesquisas recentes que parecem fornecer resultados promissores*:
*Nota lateral: Existem vários serviços de OCR direcionados a tarefas como imagens em estado selvagem. Ignoramos esses serviços porque atualmente estamos nos concentrando apenas na leitura de documentos PDF.
- API do Google — Como um dos maiores provedores de serviços on-line, o Google oferece resultados impressionantes na extração de documentos com sua tecnologia pioneira de visão computacional. Pode-se usar seus serviços gratuitamente se o uso for muito baixo, mas o preço aumenta à medida que as chamadas de API aumentam.
- Leitor Profundo — Deep Reader é um trabalho de pesquisa publicado na Conferência ACCV 2019. Ele incorpora várias arquiteturas de rede de última geração para executar tarefas como correspondência de documentos, recuperação de texto e remoção de ruído de imagens. Existem recursos adicionais, como tabelas e extração de pares de valores-chave, que permitem que os dados sejam recuperados e salvos de maneira organizada.
- Nanonets ™ — Com uma equipe de aprendizado profundo altamente qualificada, o Nanonets™ PDF OCR é totalmente independente de modelos e regras. Portanto, Nanonets™ não só pode funcionar em tipos específicos de PDFs, como também pode ser aplicado em qualquer tipo de documento para recuperação de texto.
Procurando extrair dados de documentos digitalizados? Dê Nanonets™ um giro para maior precisão, maior flexibilidade, pós-processamento e um amplo conjunto de integrações!
Conclusão
Concluindo, este artigo apresenta uma explicação completa sobre a extração de dados de documentos digitalizados, incluindo os desafios por trás disso e a tecnologia necessária para este processo.
Dois tutoriais de métodos diferentes são apresentados, e soluções atuais que os oferecem prontos para uso também são apresentadas para referência.
- 2019
- Sobre
- absoluto
- Conta
- preciso
- Alcançar
- Adição
- Adicional
- avançado
- avanços
- AI
- algoritmos
- Todos os Produtos
- já
- alternativa
- análise
- análise
- Outro
- api
- APIs
- Aplicação
- aplicações
- abordagem
- arquitetura
- por aí
- artigo
- artificial
- inteligência artificial
- por WhatsApp.
- Automação
- disponível
- AWS
- fundo
- Bank
- bancos
- base
- ser
- MELHOR
- Pós
- O maior
- fronteira
- Caixa
- construir
- negócio
- negócios
- Cartões
- casos
- dinheiro
- fluxo de caixa
- certo
- desafios
- desafiante
- charts
- Finalizar compra
- clássico
- Na nuvem
- CNN
- código
- como
- comum
- Empresas
- Empresa
- completamente
- completando
- compreensivo
- computação
- computador
- conceito
- Conferência
- confiança
- conectado
- constantemente
- contém
- contribuiu
- facilidade
- Conveniente
- conversões
- núcleo
- Corporações
- Correspondente
- poderia
- crucial
- Atual
- Atualmente
- cliente
- Clientes
- dados,
- informática
- armazenamento de dados
- acordo
- descrito
- Design
- detalhe
- Detecção
- diferente
- difícil
- digital
- INSTITUCIONAIS
- facilmente
- eficiência
- colaboradores
- Motor
- Engenharia
- especialmente
- essencialmente
- estimativas
- etc.
- avaliação
- eventos
- exemplo
- Exceto
- experimentar
- explorar
- extenso
- Extractos
- família
- Característica
- Funcionalidades
- retornos
- Campos
- descoberta
- Primeiro nome
- Flexibilidade
- fluxo
- Foco
- focado
- concentra-se
- focando
- seguinte
- Frente
- formulário
- formato
- formas
- Gratuito
- Francês
- Cumprir
- cheio
- mais distante
- meta
- Bom estado, com sinais de uso
- maior
- grandemente
- Manipulação
- mãos em
- cabeça
- saúde
- setor de saúde
- útil
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- Alta
- superior
- altamente
- história
- hospitais
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTTPS
- humano
- Recursos Humanos
- Humanos
- imagem
- importância
- importante
- melhorar
- incluir
- Incluindo
- Passiva
- Crescimento
- Individual
- indivíduos
- indústrias
- indústria
- INFORMAÇÕES
- entrada
- inspirado
- Inteligência
- emitem
- IT
- Trabalho
- Chave
- chaves
- Laboratório
- língua
- Idiomas
- grande
- principal
- APRENDER
- aprendizagem
- Line
- Lista
- longo
- máquina
- aprendizado de máquina
- principal
- Maioria
- homem
- maneira
- mercado
- Match
- correspondente
- médico
- métodos
- mais
- a maioria
- Mais populares
- em movimento
- múltiplo
- nomeadamente
- natural
- Cria
- rede
- redes
- normal
- números
- numeroso
- oferecer
- oferecido
- oferecendo treinamento para distância
- Ofertas
- Oferece
- oficial
- contínuo
- online
- operação
- Opções
- ordem
- organizações
- Organizado
- Outros
- proprietários
- participantes
- pagamento
- realização
- significativo
- pessoal
- Pioneirismo
- Popular
- potencial
- poder
- predizer
- predição
- presente
- bastante
- anterior
- preço
- processo
- processos
- em processamento
- Produtos
- Agenda
- Programas
- promissor
- fornecer
- fornecendo
- fins
- rapidamente
- RE
- Leitor
- Leitura
- receber
- reconciliação
- registros
- reduzir
- em relação a
- relacionamento
- solicitar
- requerer
- requeridos
- exige
- pesquisa
- Recursos
- resposta
- Resultados
- retorno
- riscos
- exploração
- segundo
- serviço
- Serviços
- conjunto
- vários
- Baixo
- assistência técnica de curto e longo prazo
- semelhante
- simples
- desde
- Tamanho
- Software
- sólido
- Soluções
- alguns
- especializado
- Spin
- estado-da-arte
- declarações
- estatístico
- armazenamento
- transmitir canais
- mais forte,
- estruturada
- substancial
- bem sucedido
- Suportado
- Vistorias
- visadas
- tarefas
- Profissionais
- técnicas
- Tecnologias
- Equipar
- teste
- o mundo
- assim sendo
- milhares
- Através da
- tempo
- vezes
- juntos
- toneladas
- para
- tradicional
- Training
- tutoriais
- tipos
- compreender
- único
- usar
- geralmente
- valor
- vário
- Verificação
- Ver
- visão
- se
- enquanto
- dentro
- sem
- palavras
- Atividades:
- trabalhadores
- mundo
- seria
- XML
- anos