Este artigo foi publicado como parte do Blogathon de Ciência de Dados
Introdução
Data Science é um esporte de equipe, temos membros agregando valor em todo o ciclo de vida de analytics / data science para que possa conduzir a transformação resolvendo problemas de negócios desafiadores.
Temos vários membros da equipe em uma equipe de ciência de dados: engenheiros de dados que criam a base de todos os dados que é consumido por analistas para explorar e fazer análises descritivas de modelos de ML avançados criados por cientistas de dados - visualizados por engenheiros de BI e implantados por engenheiros de ML. Todos eles devem trabalhar em conjunto para conduzir com sucesso o programa de ciência de dados de uma organização.
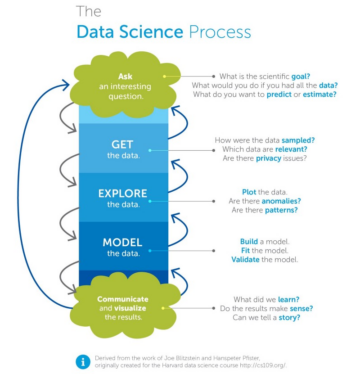
Um mapa de partes interessadas típico para a equipe de ciência de dados é mencionado abaixo:

1 imagem
Conteúdo:
- Por que um cientista de dados precisa conhecer os conceitos de engenharia de dados?
- Conceito 1 - Data Warehouse e Data Lakes
- Conceito 2 - Data ETL / Pipelines
- Conceito 3 - Governança e qualidade de dados
- Conceito 4 - Regulamentação e ética de dados
Agora a questão - se temos engenheiros de dados campeões na equipe por que os cientistas de dados precisam conhecer esses conceitos de engenharia / gerenciamento de dados?
- Eles são consumidores dos dados, portanto para criar soluções analíticas robustas com aqueles dados - saber quando e como os dados são coletados, armazenados e preparados os ajuda a obter as formas e ferramentas certas para extrair dados, derivar insights e modelos de design
- As equipes de ciência de dados podem precisar interagir regularmente com a engenharia de dados equipes para obter novos dados, compartilhe informações de dados adicionais para tabelas derivadas - conhecer esses conceitos permite ter uma conversa mais eficiente
- Tem havido uma maior ênfase no uso de dados com consentimento e de acordo com os regulamentos. As equipes de ciência de dados devem estar (já estão) intimamente envolvidas com as regulamentações de dados, portanto, ter esse conhecimento seria ajudar para se manter em conformidade e reduzir o risco de regulamentos de dados
Em poucas palavras, as equipes de ciência de dados precisam desempenhar seu papel de conseguir derivar com eficiência o melhor valor de (big) dados sem comprometer as regulamentações de dados, e conhecer os conceitos de engenharia de dados os ajuda a fazer isso melhor.
Com esse contexto, vamos pular direto para uma visão dos conceitos das lentes dos cientistas de dados!
Data Warehouse e Data Lakes
O que os cientistas de dados podem não saber:
Enquanto aprendem a projetar painéis e criar modelos, os cientistas de dados estão mais familiarizados com isso, com base nos dados armazenados em data warehouses e provenientes de data lakes. Os cientistas de dados podem não saber quais são as melhores técnicas para consultar dados do warehouse e qual é a melhor maneira de olhar para esses dados de forma holística.
Fundamentos chave[I]
- O data warehouse é a fonte centralizada de banco de dados verdade criado a partir de várias fontes (cada departamento ainda pode ter seu próprio warehouse) (por exemplo, dados do setor de serviços financeiros, como transações de cartão de crédito)
- Normalmente tendo uma estrutura desnormalizada (para consultas mais rápidas) e cada tabela foi preparada e estruturada para um caso de negócios em potencial
- Os Data Lakes são uma etapa antes dos data warehouses onde os dados brutos (incluindo os não estruturados) são armazenados, todos os dados são mantidos, mesmo que sua finalidade ainda não tenha sido definida. (por exemplo, notas dos médicos na área da saúde)
Como isso ajuda os cientistas de dados[Ii]
- Um modelo de ML / solução analítica é tão bom quanto seus dados, por isso é fundamental que os cientistas de dados conheçam as origens dos dados
- Na maioria dos projetos de ciência de dados, 80% do tempo é gasto na preparação de dados, portanto, o conhecimento do armazenamento de dados e a capacidade de entender / criar / solicitar conjuntos de dados / datamarts prontos para análise podem ajudar a aumentar a eficiência e reduzir os prazos do projeto
- Data lakes podem ajudar cientistas de dados em exercícios de descoberta para identificar dados para casos de uso
Data ETL (Extract Transform Load) / Pipelines
O que os cientistas de dados podem não saber:
Os dados coletados e apresentados para análise geralmente têm muitas etapas de pré-processamento e transferência envolvidas antes de chegarem ao data warehouse ou ao arquivo de análise. A maioria dos cientistas de dados durante o aprendizado de ML / AI pode ter usado dados já preparados, o que elimina a necessidade, mas no design real de ML em um setor, muitas vezes, o cientista de dados precisa preparar e modificar os dados de acordo com o caso de uso - eles definitivamente precisam saber o que foram os dados que foram coletados e como eles terminaram em um campo específico (por exemplo, gênero Nulo significa que o uso não queria compartilhá-lo ou significa que os dados não estavam disponíveis ou ambos - a equipe de engenharia de dados teria essas respostas)
Fundamentos chave[III]
- ETL = “extrair, transformar e carregar” são as etapas de engenharia de dados necessárias na preparação dos dados, seja para armazená-los em um warehouse ou para usá-los para um modelo de ML / caso de uso analítico
- Envolve obter dados de uma fonte (por exemplo, Adobe analytics no site que está armazenado na nuvem da Adobe) para preparar um feed de dados a partir dele e, em seguida, transformá-lo em um formato que seja relevante para o negócio (integração com o ID exclusivo do cliente da organização , por exemplo, alterar a moeda para $ da moeda local) e, em seguida, carregá-lo em uma ou várias tabelas no data warehouse / lago. Às vezes, a transformação é feita após o carregamento desses dados e é chamada de ELT.
- Um pipeline de dados é uma série de conexões e etapas pelas quais os dados se movem de um local para outro
- O feed de dados é um bloco de dados que é ingerido no data warehouse periodicamente por meio de processos ETL
Como isso ajuda os cientistas de dados
- Modelos de ML / soluções de análise não são feitos apenas para uma única vez, mas precisam ser constantemente atualizados e atualizados - para isso, o ML e os pipelines de dados precisam
- Os conceitos de ETL de dados podem ser aplicados no pré-processamento de ML para tornar códigos e fluxos de trabalho prontos para produção que podem ser usados durante a implementação de ML
- O conhecimento dos processos de ETL pode ajudar na compreensão da linhagem de dados e na interpretação correta dos dados (por exemplo, o conhecimento dos dados de 'Idade' foi coletado no ponto de venda manualmente ou automatizado e o mapeamento aplicado para faixas de idade antes do armazenamento pode ajudar a projetar melhor os modelos de ML)

2 imagem
Governança e qualidade de dados
O que os cientistas de dados podem não saber:
Os dados são a base de todas as soluções analíticas, se até mesmo uma parte do conjunto de dados for alterada, ele danifica completamente qualquer modelo downstream etc. criado, muitas vezes não há verificações para verificar logicamente a consistência dos dados para um determinado contexto (por exemplo, Se repentinamente, receita por cliente aumenta de US $ 100 para US $ 800 sem qualquer mudança no ambiente de negócios, então isso levaria a pontuações de ML erradas e painéis incorretos). Portanto, uma equipe de ciência de dados deve trabalhar em estreita colaboração com a equipe de governança e engenharia de dados para definir verificações ao longo de todos os caminhos críticos para garantir que todos os modelos e análises obtenham os dados corretos de forma consistente.
Fundamentos chave[IV]
- Governança de dados é um termo mais amplo usado para definir como as organizações gerenciam os objetivos, escopo, propriedade, privacidade e segurança dos dados, incluindo dados e processos padronizados
- A qualidade dos dados é um subconjunto da governança de dados com foco no monitoramento contínuo dos dados para integridade, consistência e planos para lidar com irregularidades de dados
- Por exemplo, se uma organização tiver que ingerir dados de mídia social, a governança de dados conduzirá toda a avaliação e planejamento sob a governança de dados e, em seguida, avaliará os dados recebidos usando a qualidade dos dados.
Como isso ajuda os cientistas de dados
- A qualidade dos dados ajuda a criar soluções analíticas robustas e manter a reputação e a confiança das equipes de ciência de dados
- Ele evita retrabalho e decisões de negócios erradas se proativamente identificados e resolvidos em conjunto por equipes de TI, ciência de dados e negócios
- É como o monitoramento de saída de modelo, mas, neste caso, os dados de entrada para um data warehouse são monitorados de perto para alertar sobre qualquer irregularidade

3 imagem
Regulamentações de dados e ética
O que os cientistas de dados podem não saber:
Os dados usados podem ser restringidos por legalidades e até mesmo os modelos de ML criados podem ter preconceitos e usar os dados de uma forma não intencional, às vezes não cumprindo os padrões éticos. Quaisquer implicações legais ou incidentes com a imagem da marca podem ser motivados pelo trabalho realizado por uma equipe de ciência de dados. Como a equipe de ciência de dados assumiu a liderança no tratamento de dados e soluções analíticas desses dados, eles são responsáveis por seu impacto. Surpreendentemente, muitas equipes de análise não sabem disso e não estão preparadas para isso. O consentimento do usuário pode não ter sido coletado para o caso de uso utilizado pela equipe do DS.
Fundamentos chave[V]
- Os regulamentos de dados referem-se às regras que regem a coleta, divulgação, armazenamento, uso e liberação de dados no final de seu ciclo de uso (por exemplo, GDPR, CCPA)
- Ética de dados refere-se ao uso ético, transparência, não preconceito e uso correto de dados (por exemplo, não usar dados de estratos sociais para rejeitar empréstimos de clientes, mesmo que determinado estrato possa ter histórico de pagamento incorreto)
Como isso ajuda os cientistas de dados
- Evita os riscos legais, de marca e de reputação decorrentes do uso de dados da maneira certa
- Ajuda a desenvolver modelos amigáveis ao cliente que podem servir como exemplos em toda a organização
- Gerenciar melhor o acesso ao compartilhamento de dados confidenciais entre as equipes para evitar o compartilhamento de dados em mãos erradas, ajudando assim em um design de estratégia de governança de dados melhor
Pensamentos de Encerramento
Pilha de análise: reúne tudo - Combina todos os elementos (4 mencionados aqui) em uma única entidade que a equipe analítica consome para produzir resultados. Normalmente, seria o seguinte, com algumas variações.

4 imagem
Uma equipe de ciência de dados deve se concentrar nesses quatro fatores para construir uma prática resiliente e estável e continuar agregando valor ao negócio com alta qualidade.
Referências
[I] https://www.talend.com/resources/data-lake-vs-data-warehouse/
[Ii] https://towardsdatascience.com/data-warehouse-68ec63eecf78
[III] https://www.snowflake.com/guides/etl-pipeline
[IV] https://www.collibra.com/blog/data-quality-vs-data-governance
[V] https://www.datascience-pm.com/10-data-science-ethics-questions/
Fontes de imagem-
- Image 1: https://medium.com/co-learning-lounge/job-roles-in-data-science-10e790ea21b5
- Image 2: https://towardsdatascience.com/scalable-efficient-big-data-analytics-machine-learning-pipeline-architecture-on-cloud-4d59efc092b5
- Imagem 3: https://www.edq.com/blog/data-quality-vs-data-governance/
- Imagem 4: https://www.tellius.com/the-modern-data-analytics-stack/
Artigo por Ashwin Kumar | Líder e cruzado de ciência de dados | Linkedin
As mídias mostradas neste artigo não são propriedade da Analytics Vidhya e são usadas a critério do autor.
- &
- Acesso
- Adicional
- adobe
- AI
- Todos os Produtos
- análise
- analítica
- artigo
- Automatizado
- MELHOR
- construir
- negócio
- CCPA
- alterar
- Cheques
- Na nuvem
- código
- confiança
- Coneções
- consentimento
- Consumidores
- crédito
- cartão de crédito
- Moeda
- dados,
- qualidade de dados
- ciência de dados
- cientista de dados
- compartilhamento de dados
- data warehouse
- armazéns de dados
- banco de dados
- Design
- desenvolver
- DID
- Divulgações
- descoberta
- dirigido
- eficiência
- Engenharia
- Engenheiros
- Meio Ambiente
- etc.
- ética
- financeiro
- serviços financeiros
- Foco
- formulário
- formato
- Foundation
- Fundamentos
- RGPD
- Gênero
- Bom estado, com sinais de uso
- governo
- Manipulação
- saúde
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- Alta
- história
- Como funciona o dobrador de carta de canal
- HTTPS
- identificar
- imagem
- Impacto
- Incluindo
- Crescimento
- indústria
- INFORMAÇÕES
- insights
- integração
- envolvido
- IT
- saltar
- Conhecimento
- conduzir
- aprendizagem
- Legal
- carregar
- Empréstimos
- local
- localização
- de grupos
- mapa,
- Mídia
- Membros
- ML
- modelo
- monitoração
- movimentos
- planejamento
- ponto de venda
- política de privacidade
- Agenda
- projeto
- projetos
- qualidade
- Cru
- dados não tratados
- reduzir
- regulamentos
- Resultados
- receita
- Risco
- regras
- Promoção
- Ciência
- cientistas
- segurança
- Série
- Serviços
- conjunto
- Partilhar
- So
- Redes Sociais
- meios de comunicação social
- Soluções
- Desporto
- padrões
- ficar
- armazenamento
- loja
- Estratégia
- tempo
- Transações
- Transformação
- transformando
- Transparência
- valor
- Ver
- Armazém
- Site
- O que é a
- QUEM
- Atividades: