Hoje, centenas de milhares de clientes usam data lakes para análise e aprendizado de máquina. No entanto, os engenheiros de dados precisam limpar e preparar esses dados antes que possam ser usados. Os dados subjacentes devem ser precisos e recentes para que o cliente tome decisões de negócios confiáveis. Caso contrário, os consumidores de dados perdem a confiança nos dados e tomam decisões inadequadas ou incorretas. É uma tarefa comum para engenheiros de dados avaliar se os dados são precisos e recentes ou não. Hoje existem várias ferramentas de qualidade de dados. No entanto, ferramentas comuns de qualidade de dados geralmente requerem processos manuais para monitorar a qualidade dos dados.
O AWS Glue Data Quality é um recurso de visualização do Cola AWS que mede e monitora a qualidade dos dados de Serviço de armazenamento simples da Amazon (Amazon S3) data lakes e trabalhos de extração, transformação e carregamento (ETL) do AWS Glue. Este é um recurso de visualização aberta, portanto já está ativado em sua conta no Regiões disponíveis. Você pode definir e medir facilmente as verificações de qualidade de dados no console do AWS Glue Studio sem escrever códigos. Ele simplifica sua experiência de gerenciamento de qualidade de dados.
Esta postagem é a parte 2 de uma série de quatro postagens para explicar como o AWS Glue Data Quality funciona. Confira o post anterior desta série:
Nesta postagem, mostramos como criar um trabalho do AWS Glue que mede e monitora a qualidade dos dados de um pipeline de dados. Também mostramos como agir com base nos resultados de qualidade de dados.
Visão geral da solução
Vamos considerar um exemplo de caso de uso em que um engenheiro de dados precisa criar um pipeline de dados para ingerir os dados de uma zona bruta para uma zona selecionada em um data lake. Como engenheiro de dados, uma de suas principais responsabilidades — junto com a extração, transformação e carregamento de dados — é validar a qualidade dos dados. A identificação antecipada de problemas de qualidade de dados ajuda a evitar a colocação de dados incorretos na zona selecionada e a evitar incidentes árduos de corrupção de dados.
Nesta postagem, você aprenderá como configurar facilmente construídas em e personalizadas verificações de validação de dados em seu trabalho do AWS Glue para evitar que dados incorretos corrompam os dados downstream de alta qualidade.
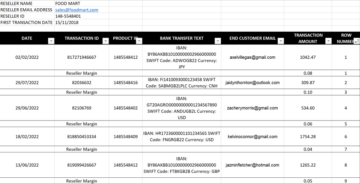
O conjunto de dados usado para esta postagem é gerado sinteticamente; a captura de tela a seguir mostra um exemplo dos dados.

Configure recursos com AWS CloudFormation
Esta postagem inclui um Formação da Nuvem AWS modelo para uma configuração rápida. Você pode revisá-lo e personalizá-lo para atender às suas necessidades.
O modelo CloudFormation gera os seguintes recursos:
- Um bucket do Amazon Simple Storage Service (Amazon S3) (
gluedataqualitystudio-*). - Os seguintes prefixos e objetos no bucket do S3:
datalake/raw/customer/customer.csvdatalake/curated/customer/scripts/sparkHistoryLogs/temporary/
- Gerenciamento de acesso e identidade da AWS (IAM) usuários, funções e políticas. A função IAM (
GlueDataQualityStudio-*) tem permissão para ler e gravar no bucket do S3. - AWS Lambda funções e políticas IAM exigidas por essas funções para criar e excluir esta pilha.
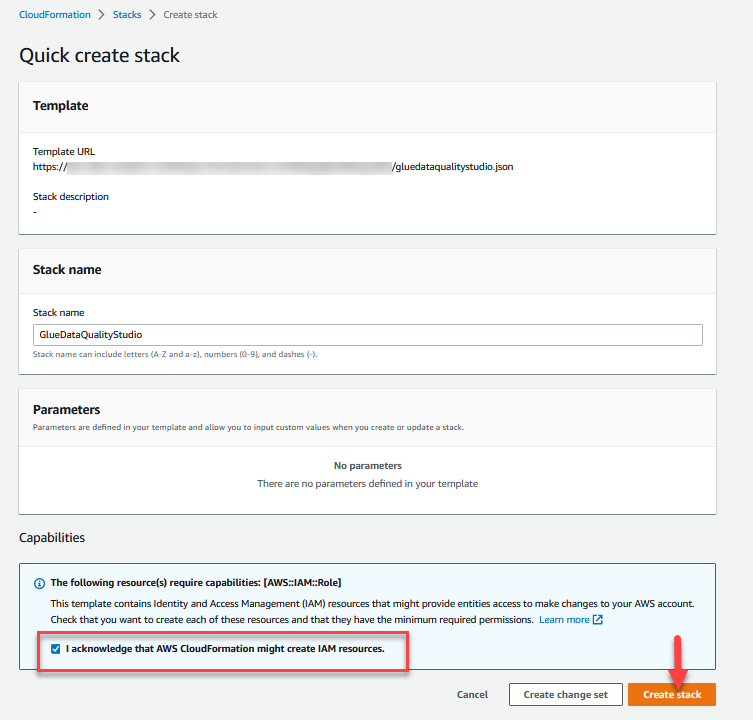
Para criar seus recursos, conclua as seguintes etapas:
- Entre no Console AWS CloudFormation no
us-east-1Região. - Escolha Pilha de Lançamento:

- Selecionar Reconheço que o AWS CloudFormation pode criar recursos do IAM.
- Escolha Criar pilha e aguarde a conclusão da etapa de criação da pilha.
Implementar a solução
Para começar a configurar sua solução, conclua as seguintes etapas:
- No Console do AWS Glue Studio, escolha Empregos no painel de navegação.
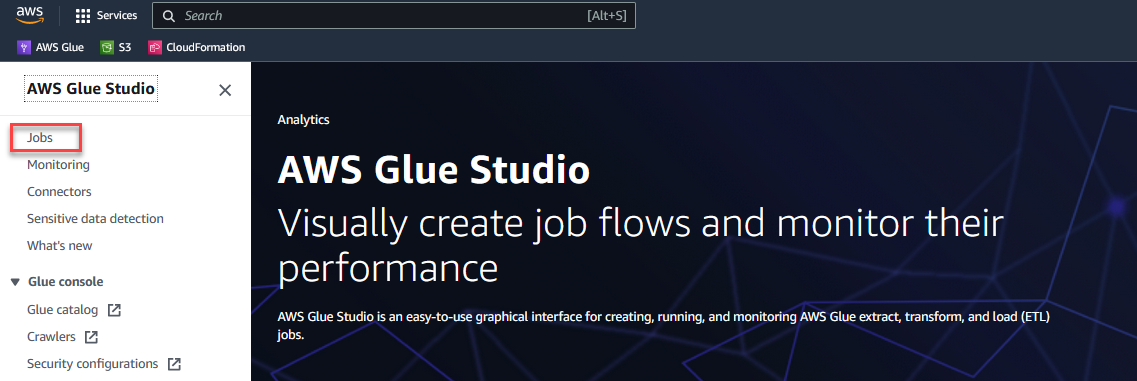
- Selecionar Visual com uma tela em branco e escolha Crie.
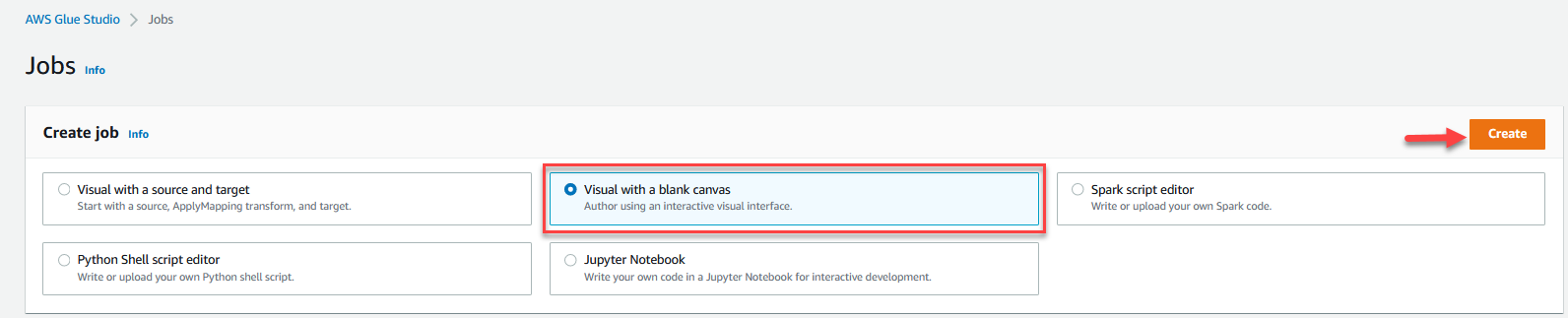
- Escolha o Detalhes do trabalho guia para configurar o trabalho.
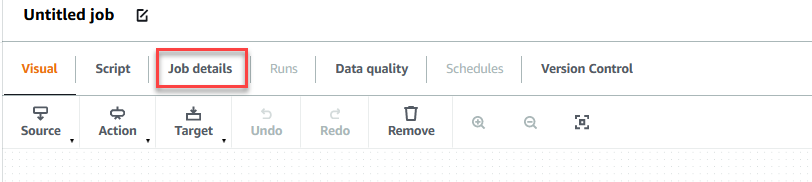
- Escolha Nome, entrar
GlueDataQualityStudio. - Escolha Papel IAM, escolha a função que começa com
GlueDataQualityStudio-*. - Escolha Versão de cola, escolha Cola 3.0.
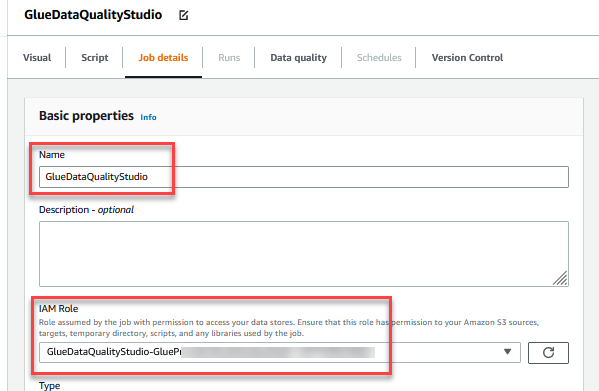
- Escolha Marcador de emprego, escolha Desabilitar. Isso permite que você execute este trabalho várias vezes com o mesmo conjunto de dados de entrada.
- Escolha Número de tentativas, entrar
0.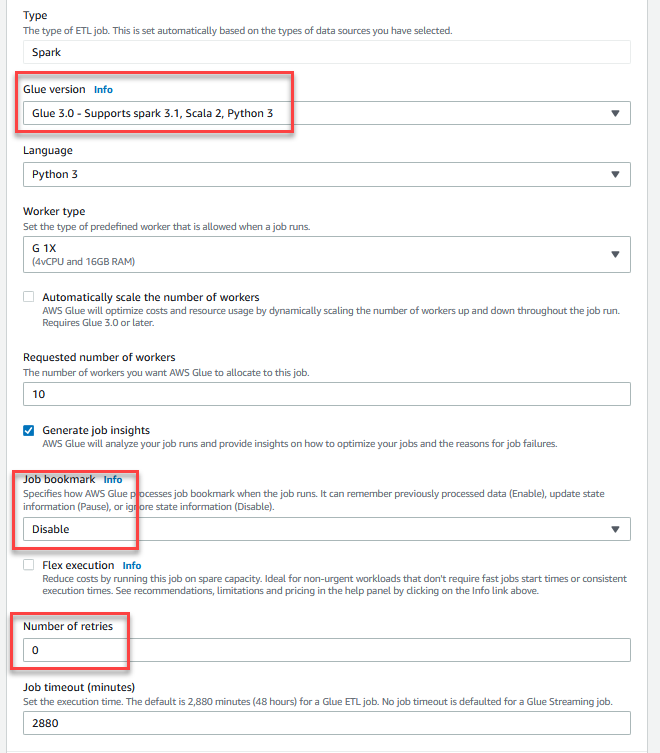
- No Propriedades avançadas seção, forneça o bucket S3 criado pelo modelo CloudFormation (começando com
gluedataqualitystudio-*).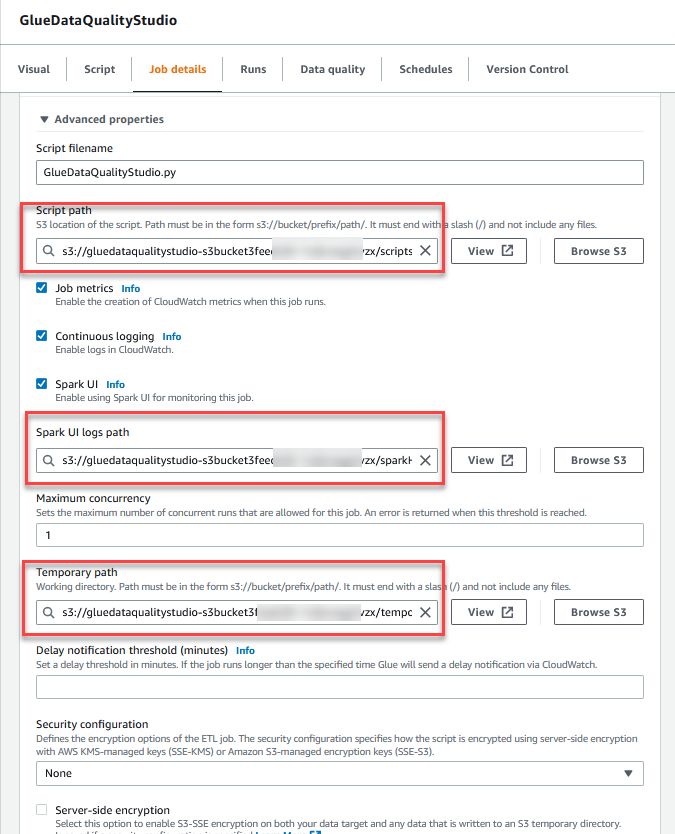
- Escolha Salvar.
- Depois que o trabalho for salvo, escolha o visual guia e no fonte menu, escolha Amazon S3.
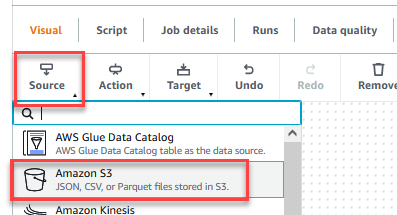
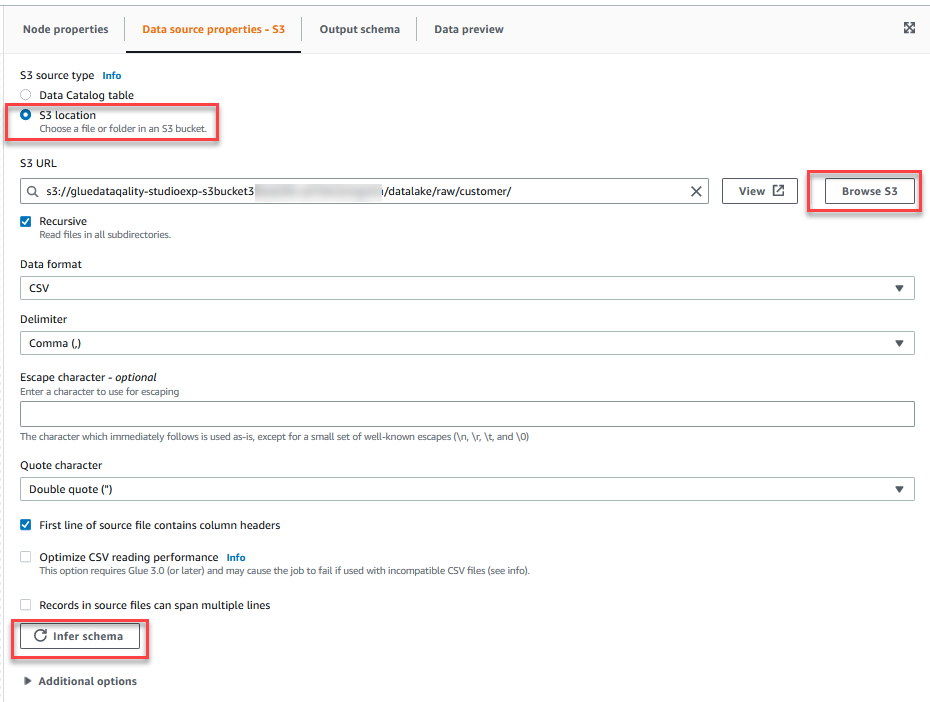
- No Propriedades da fonte de dados - S3 guia, para Tipo de fonte S3, selecione Localização S3.
- Escolha Navegar S3 e navegue até o prefixo
/datalake/raw/customer/no balde S3 começando comgluedataqualitystudio-*. - Escolha Inferir esquema.
- No Açao Social menu, escolha Avalie a qualidade dos dados.
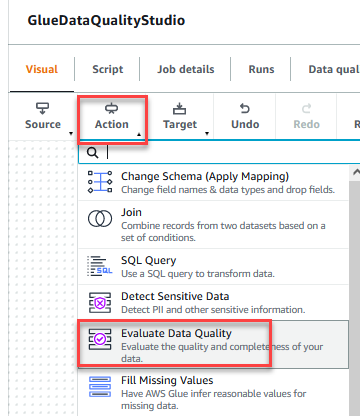
- Escolha o Avalie a qualidade dos dados nó.
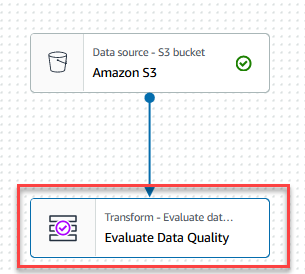
No Transformar guia, agora você pode começar a criar regras de qualidade de dados. A primeira regra que você cria é verificar seCustomer_IDé único e não nulo usando oisPrimaryKeyregra. - No Tipos de regras guia do Construtor de regras DQDL, procurar por
isprimarykeye escolha o sinal de mais.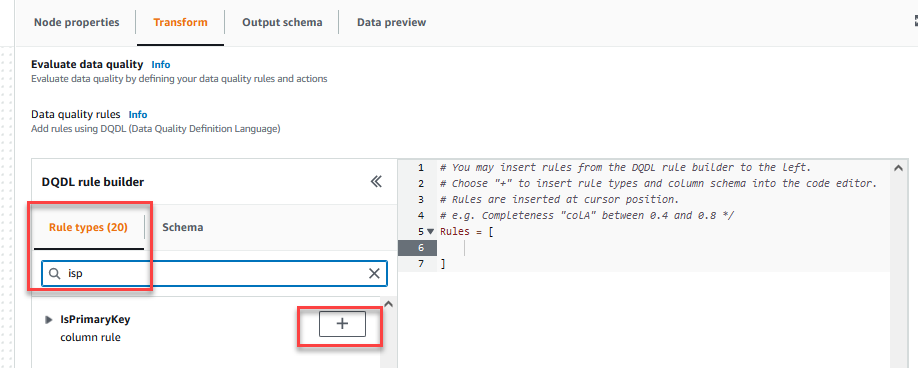
- No Esquema guia do Construtor de regras DQDL, escolha o sinal de mais ao lado de
Customer_ID. - No editor de regras, exclua
id.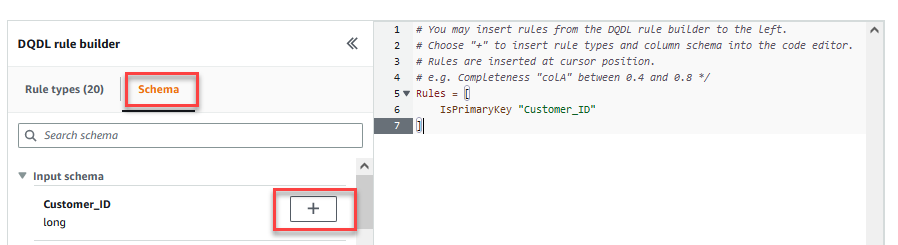
A próxima regra que adicionamos verifica se oFirst_Nameo valor da coluna está presente em todas as linhas. - Você também pode inserir as regras de qualidade de dados diretamente no editor de regras. Adicione uma vírgula (,) e digite
IsComplete "First_Name",após a primeira regra.
Em seguida, você adiciona uma regra personalizada para validar que nenhuma linha existe semTelephoneorEmail. - Insira a seguinte regra personalizada no editor de regras:

O recurso Avaliar qualidade de dados fornece ações para gerenciar o resultado de uma tarefa com base nos resultados de qualidade da tarefa. - Para esta postagem, selecione Falha no trabalho quando a qualidade dos dados falha e escolha Falha no trabalho sem carregar o destino dados, ações. No Configuração de saída de qualidade de dados seção, escolha Navegar S3 e navegue até o prefixo
dqresultsno balde S3 começando comgluedataqualitystudio-*.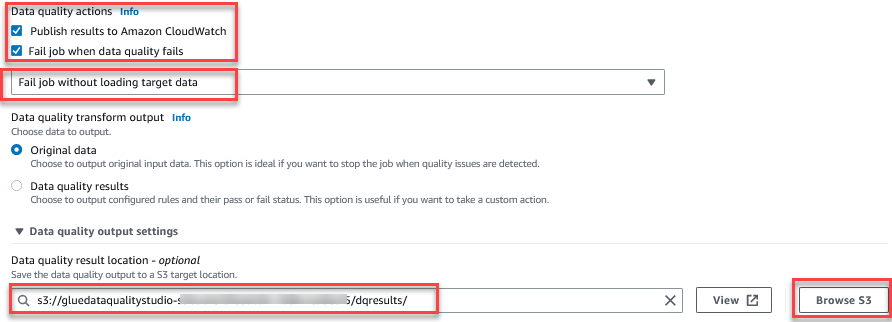
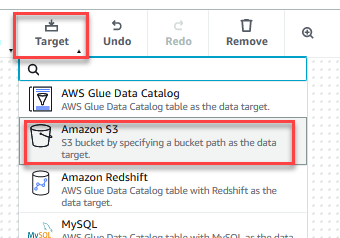
- No Target menu, escolha Amazon S3.
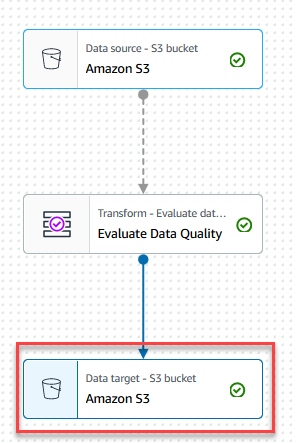
- Escolha o Destino de dados – bucket do S3 nó.
- No Propriedades do alvo de dados - S3 guia, para Formato, escolha Parquete, E para Tipo de compressão, escolha Mal-humorado.
- Escolha Local de destino do S3, escolha Navegar S3 e navegue até o prefixo
/datalake/curated/customer/no balde S3 começando comgluedataqualitystudio-*.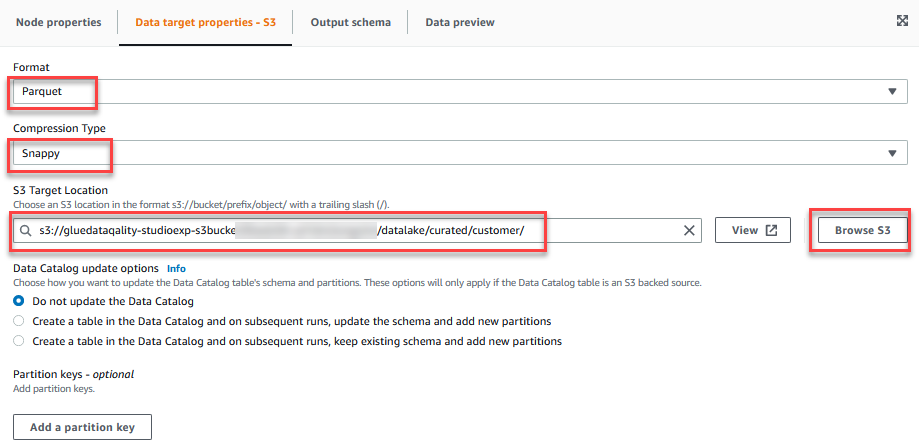
- Escolha Salvar, Em seguida, escolha Execute.
 Você pode visualizar os detalhes da execução da tarefa na guia Execuções. Em nosso exemplo, a tarefa falha com a mensagem de erro “AssertionError: The job failed due to fail DQ rules for node: .”
Você pode visualizar os detalhes da execução da tarefa na guia Execuções. Em nosso exemplo, a tarefa falha com a mensagem de erro “AssertionError: The job failed due to fail DQ rules for node: .”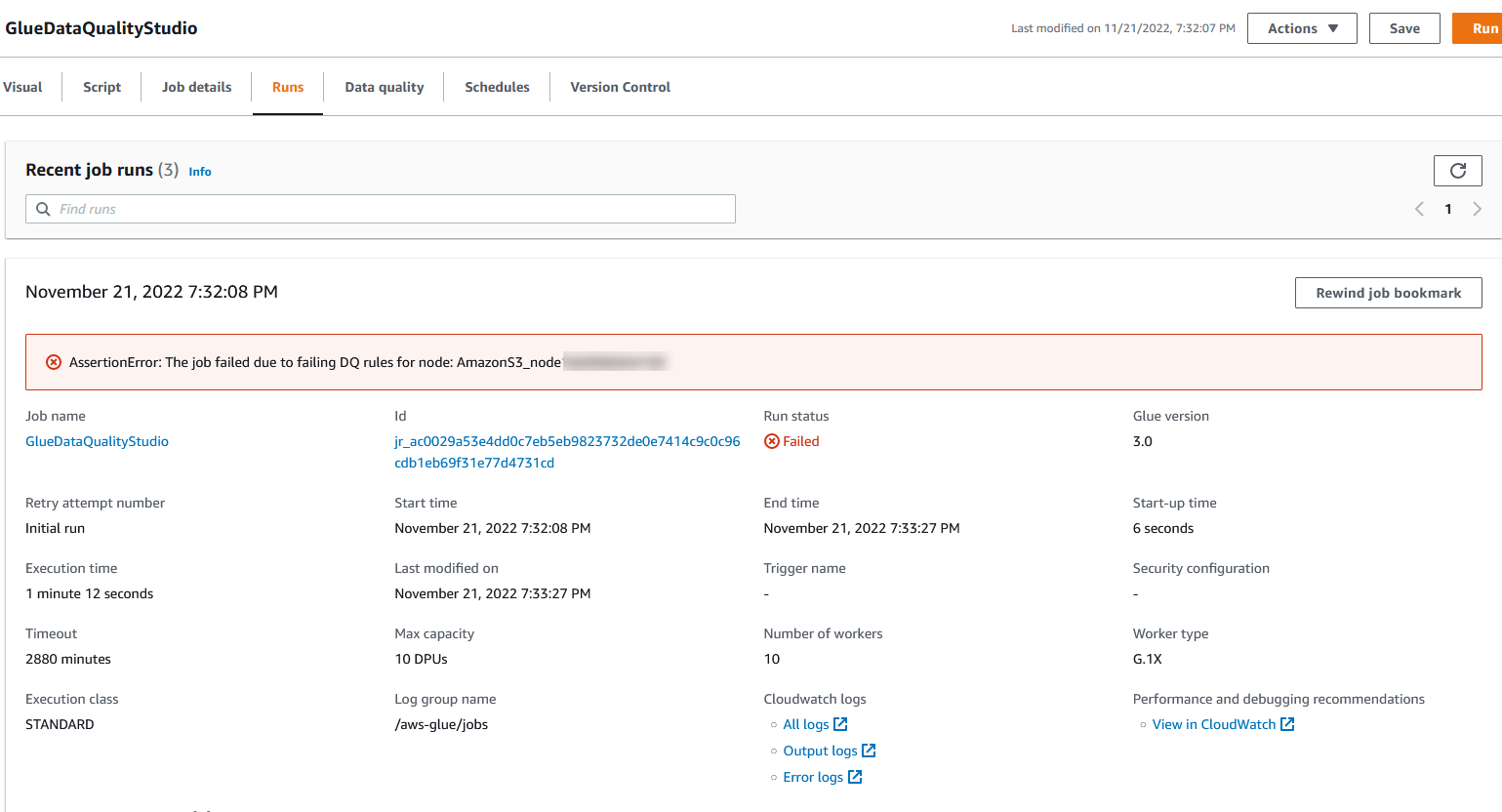 Você pode revisar o resultado da qualidade de dados na guia Qualidade de dados. Em nosso exemplo, a validação da qualidade de dados personalizada falhou porque uma das linhas no conjunto de dados não tinha
Você pode revisar o resultado da qualidade de dados na guia Qualidade de dados. Em nosso exemplo, a validação da qualidade de dados personalizada falhou porque uma das linhas no conjunto de dados não tinha TelephoneorEmailvalor. Avaliar resultados de qualidade de dados também é gravado no bucket do S3 no formato JSON com base no parâmetro de localização do resultado de qualidade de dados do nó.
Avaliar resultados de qualidade de dados também é gravado no bucket do S3 no formato JSON com base no parâmetro de localização do resultado de qualidade de dados do nó. - Navegar para
dqresultsprefixo sob o balde S3 começandogluedataqualitystudio-*. Você verá que o resultado da qualidade de dados é particionado por data.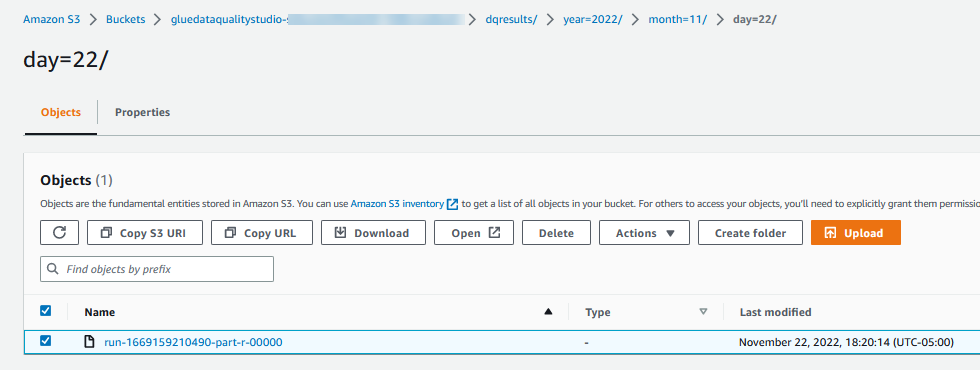
A seguir está a saída do arquivo JSON. Você pode usar essa saída de arquivo para criar painéis de visualização de qualidade de dados personalizados.

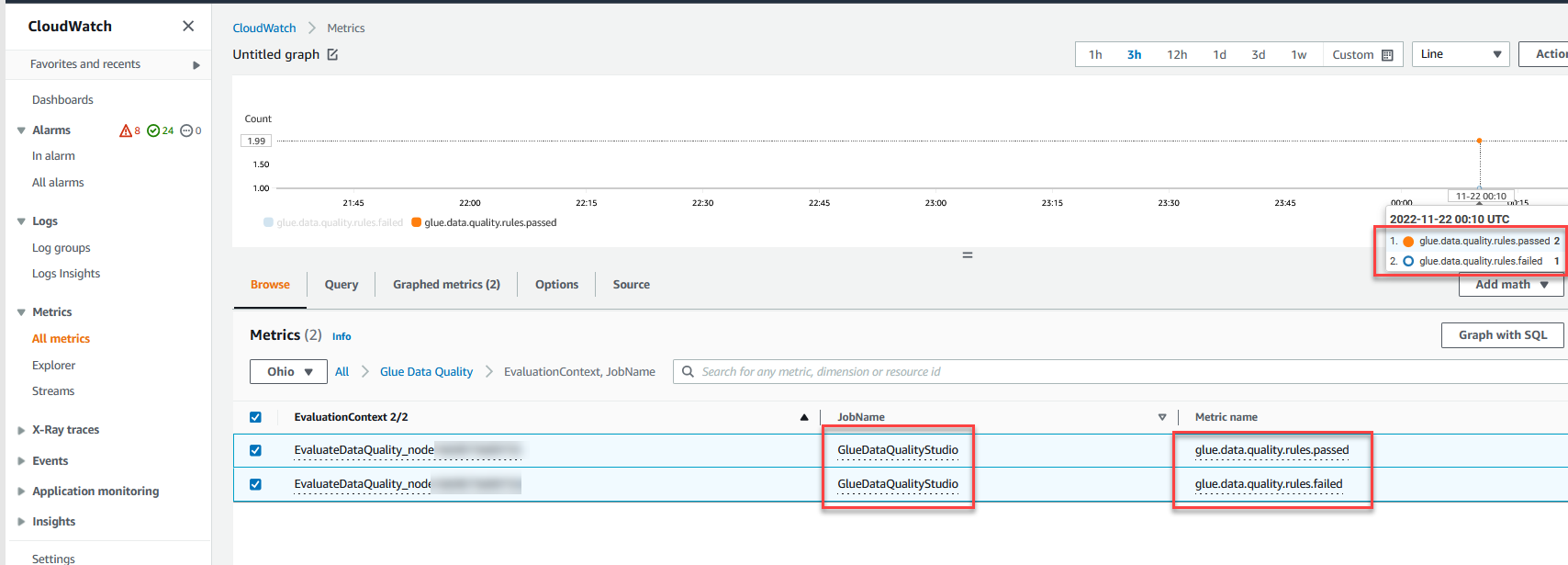
Você também pode monitorar o Avalie a qualidade dos dados nó através Amazon CloudWatch métricas e definir alarmes para enviar notificações sobre resultados de qualidade de dados. Para saber mais sobre como configurar alarmes do CloudWatch, consulte Usando alarmes do Amazon CloudWatch.
limpar
Para evitar cobranças futuras e limpar funções e políticas não utilizadas, exclua os recursos que você criou:
- Excluir o
GlueDataQualityStudiotrabalho que você criou como parte desta postagem. - No console do AWS CloudFormation, exclua o
GlueDataQualityStudiopilha.
Conclusão
O AWS Glue Data Quality oferece uma maneira fácil de medir e monitorar a qualidade dos dados de seu pipeline ETL. Nesta postagem, você aprendeu como tomar as ações necessárias com base nos resultados de qualidade de dados, o que o ajuda a manter altos padrões de dados e a tomar decisões de negócios confiáveis.
Para saber mais sobre o AWS Glue Data Quality, confira a documentação:
Sobre os autores
 Deenbandhu Prasad é um Senior Analytics Specialist na AWS, especializado em serviços de big data. Ele é apaixonado por ajudar os clientes a criar uma arquitetura de dados moderna na Nuvem AWS. Ele ajudou clientes de todos os tamanhos a implementar soluções de gerenciamento de dados, data warehouse e data lake.
Deenbandhu Prasad é um Senior Analytics Specialist na AWS, especializado em serviços de big data. Ele é apaixonado por ajudar os clientes a criar uma arquitetura de dados moderna na Nuvem AWS. Ele ajudou clientes de todos os tamanhos a implementar soluções de gerenciamento de dados, data warehouse e data lake.
 Yannis Mentekidis é engenheiro de desenvolvimento de software sênior na equipe do AWS Glue.
Yannis Mentekidis é engenheiro de desenvolvimento de software sênior na equipe do AWS Glue.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/getting-started-with-aws-glue-data-quality-for-etl-pipelines/
- 1
- 100
- 7
- a
- Sobre
- Acesso
- Conta
- preciso
- reconhecer
- Açao Social
- ações
- Depois de
- Todos os Produtos
- permite
- já
- Amazon
- analítica
- e
- arquitetura
- AWS
- Formação da Nuvem AWS
- Cola AWS
- Mau
- dados incorretos
- baseado
- Porque
- antes
- Grande
- Big Data
- construir
- Prédio
- negócio
- casas
- acusações
- verificar
- Cheques
- Escolha
- Na nuvem
- Coluna
- comum
- completar
- confiante
- Considerar
- cônsul
- Consumidores
- Corrupção
- crio
- criado
- criação
- comissariada
- personalizadas
- cliente
- Clientes
- personalizar
- dados,
- lago data
- gestão de dados
- Data
- decisões
- detalhes
- Desenvolvimento
- diretamente
- documentação
- facilmente
- editor
- engenheiro
- Engenheiros
- Entrar
- erro
- Éter (ETH)
- avaliar
- exemplo
- existe
- vasta experiência
- Explicação
- extrato
- fracassado
- falha
- Característica
- Envie o
- Primeiro nome
- seguinte
- formato
- da
- funções
- futuro
- gerado
- gera
- obtendo
- ajudou
- ajuda
- ajuda
- Alta
- alta qualidade
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTML
- HTTPS
- Centenas
- identificar
- Dados de identificação:
- executar
- in
- inclui
- entrada
- questões
- IT
- Trabalho
- Empregos
- json
- Chave
- lago
- APRENDER
- aprendido
- aprendizagem
- carregar
- carregamento
- localização
- perder
- máquina
- aprendizado de máquina
- a manter
- fazer
- gerencia
- de grupos
- gestão
- manual
- a medida
- medidas
- Menu
- mensagem
- Métrica
- poder
- EQUIPAMENTOS
- Monitore
- monitores
- mais
- múltiplo
- Navegar
- Navegação
- necessário
- Cria
- Próximo
- nó
- notificações
- objetos
- Oferece
- ONE
- aberto
- de outra forma
- pão
- parâmetro
- parte
- apaixonado
- permissão
- oleoduto
- colocação
- platão
- Inteligência de Dados Platão
- PlatãoData
- mais
- políticas
- Publique
- Preparar
- presente
- evitar
- visualização
- anterior
- primário
- processos
- Propriedades
- fornecer
- fornece
- qualidade
- Links
- Cru
- Leia
- recentemente
- região
- requerer
- requeridos
- Recursos
- resultar
- Resultados
- rever
- Tipo
- papéis
- LINHA
- Regra
- regras
- Execute
- mesmo
- Pesquisar
- Seção
- Série
- serviço
- Serviços
- conjunto
- contexto
- instalação
- mostrar
- Shows
- assinar
- simples
- tamanhos
- So
- Software
- desenvolvimento de software
- solução
- Soluções
- fonte
- especialista
- especializando
- pilha
- padrões
- começo
- começado
- Comece
- Passo
- Passos
- armazenamento
- estudo
- terno
- sinteticamente
- Tire
- Target
- Tarefa
- Profissionais
- modelo
- A
- milhares
- Através da
- vezes
- para
- hoje
- ferramentas
- Transformar
- transformando
- Confiança
- para
- subjacente
- único
- não usado
- usar
- caso de uso
- usuários
- geralmente
- VALIDAR
- validação
- valor
- vário
- Ver
- visualização
- esperar
- se
- qual
- precisarão
- sem
- trabalho
- escrever
- escrita
- escrito
- investimentos
- zefirnet