Hoje, temos o prazer de anunciar que o modelo básico de linguagem GPT-NeoXT-Chat-Base-20B da Together Computer está disponível para clientes que usam JumpStart do Amazon SageMaker. GPT-NeoXT-Chat-Base-20B é um modelo de código aberto para construir bots de conversação. Você pode facilmente experimentar este modelo e usá-lo com o JumpStart. JumpStart é o hub de aprendizado de máquina (ML) de Amazon Sage Maker que fornece acesso a modelos de base, além de algoritmos integrados e modelos de solução de ponta a ponta para ajudá-lo a começar a usar o ML rapidamente.
Nesta postagem, explicamos como implantar o GPT-NeoXT-Chat-Base-20B modelar e invocar o modelo dentro de um OpenChatKit shell interativo. Esta demonstração fornece um chatbot de modelo básico de código aberto para uso em seu aplicativo.
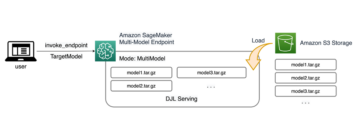
Os modelos JumpStart usam Deep Java Serving que usa a Deep Java Library (DJL) com bibliotecas de alta velocidade para otimizar modelos e minimizar a latência para inferência. A implementação subjacente no JumpStart segue uma implementação semelhante à seguinte caderno. Como cliente do hub de modelo JumpStart, você obtém desempenho aprimorado sem precisar manter o script de modelo fora do SageMaker SDK. Os modelos JumpStart também alcançam uma postura de segurança aprimorada com endpoints que permitem o isolamento da rede.
Modelos de fundação no SageMaker
O JumpStart fornece acesso a uma variedade de modelos de hubs de modelos populares, incluindo Hugging Face, PyTorch Hub e TensorFlow Hub, que você pode usar em seu fluxo de trabalho de desenvolvimento de ML no SageMaker. Avanços recentes em ML deram origem a uma nova classe de modelos conhecida como modelos de fundação, que normalmente são treinados em bilhões de parâmetros e são adaptáveis a uma ampla categoria de casos de uso, como resumo de texto, geração de arte digital e tradução de idiomas. Como esses modelos são caros para treinar, os clientes desejam usar modelos de fundação pré-treinados existentes e ajustá-los conforme necessário, em vez de treinar esses modelos por conta própria. O SageMaker fornece uma lista selecionada de modelos que você pode escolher no console do SageMaker.
Agora você pode encontrar modelos de fundação de diferentes provedores de modelo no JumpStart, permitindo que você comece a usar modelos de fundação rapidamente. Você pode encontrar modelos de base com base em diferentes tarefas ou provedores de modelo e revisar facilmente as características do modelo e os termos de uso. Você também pode experimentar esses modelos usando um widget de IU de teste. Quando você deseja usar um modelo de base em escala, pode fazê-lo facilmente sem sair do SageMaker usando notebooks pré-construídos de fornecedores de modelos. Como os modelos são hospedados e implantados na AWS, você pode ter certeza de que seus dados, sejam eles usados para avaliar ou usar o modelo em escala, nunca serão compartilhados com terceiros.
Modelo de fundação GPT-NeoXT-Chat-Base-20B
Juntos Computador desenvolveu o GPT-NeoXT-Chat-Base-20B, um modelo de linguagem de 20 bilhões de parâmetros, ajustado a partir do modelo GPT-NeoX da ElutherAI com mais de 40 milhões de instruções, com foco em interações no estilo de diálogo. Além disso, o modelo é ajustado em várias tarefas, como resposta a perguntas, classificação, extração e resumo. O modelo é baseado no conjunto de dados OIG-43M que foi criado em colaboração com LAION e Ontocord.
Além do ajuste fino mencionado acima, o GPT-NeoXT-Chat-Base-20B-v0.16 também passou por um ajuste fino adicional por meio de uma pequena quantidade de dados de feedback. Isso permite que o modelo se adapte melhor às preferências humanas nas conversas. O GPT-NeoXT-Chat-Base-20B foi projetado para uso em aplicativos de chatbot e pode não funcionar bem em outros casos de uso fora do escopo pretendido. Juntos, Ontocord e LAION colaboraram para lançar o OpenChatKit, uma alternativa de código aberto ao ChatGPT com um conjunto comparável de recursos. O OpenChatKit foi lançado sob uma licença Apache-2.0, concedendo acesso completo ao código-fonte, pesos do modelo e conjuntos de dados de treinamento. Existem várias tarefas nas quais o OpenChatKit se destaca imediatamente. Isso inclui tarefas de resumo, tarefas de extração que permitem extrair informações estruturadas de documentos não estruturados e tarefas de classificação para classificar uma frase ou parágrafo em diferentes categorias.
Vamos explorar como podemos usar o modelo GPT-NeoXT-Chat-Base-20B no JumpStart.
Visão geral da solução
Você pode encontrar o código que mostra a implantação de GPT-NeoXT-Chat-Base-20B no SageMaker e um exemplo de como usar o modelo implantado de maneira conversacional usando o shell de comando a seguir Bloco de notas do GitHub.
Nas seções a seguir, expandimos cada etapa detalhadamente para implantar o modelo e, em seguida, usá-lo para resolver diferentes tarefas:
- Configure os pré-requisitos.
- Selecione um modelo pré-treinado.
- Recupere artefatos e implante um endpoint.
- Consulte o endpoint e analise uma resposta.
- Use um shell OpenChatKit para interagir com seu endpoint implantado.
Pré-requisitos de configuração
Este notebook foi testado em uma instância ml.t3.medium em Estúdio Amazon SageMaker com o kernel Python 3 (Data Science) e em uma instância de notebook SageMaker com o kernel conda_python3.
Antes de executar o notebook, use o seguinte comando para concluir algumas etapas iniciais necessárias para a configuração:
Selecione um modelo pré-treinado
Configuramos uma sessão do SageMaker como de costume usando o Boto3 e, em seguida, selecionamos o ID do modelo que queremos implantar:
Recupere artefatos e implante um endpoint
Com o SageMaker, podemos realizar inferências no modelo pré-treinado, mesmo sem ajustá-lo primeiro em um novo conjunto de dados. Começamos recuperando o instance_type, image_uri e model_uri para o modelo pré-treinado. Para hospedar o modelo pré-treinado, criamos uma instância de sábio.modelo.modelo e implantá-lo. O código a seguir usa ml.g5.24xlarge para o endpoint de inferência. O método de implantação pode levar alguns minutos.
Consultar o endpoint e analisar a resposta
A seguir, mostramos um exemplo de como invocar um endpoint com um subconjunto dos hiperparâmetros:
A seguir, a resposta que obtemos:
Aqui, fornecemos o argumento de carga útil "stopping_criteria": ["<human>"], o que resultou na resposta do modelo terminando com a geração da sequência de palavras <human>. O script do modelo JumpStart aceitará qualquer lista de strings como palavras de parada desejadas, converta essa lista em uma lista válida argumento de palavra-chave stops_criteria para a API de geração de transformadores e para a geração de texto quando a sequência de saída contém quaisquer palavras de parada especificadas. Isso é útil por dois motivos: primeiro, o tempo de inferência é reduzido porque o endpoint não continua a gerar texto indesejado além das palavras de parada e, segundo, isso evita que o modelo OpenChatKit tenha alucinações com respostas humanas e bot adicionais até que outros critérios de parada sejam atendidos .
Use um shell OpenChatKit para interagir com seu endpoint implantado
O OpenChatKit fornece um shell de linha de comando para interagir com o chatbot. Nesta etapa, você cria uma versão desse shell que pode interagir com seu endpoint implantado. Fornecemos uma simplificação básica dos scripts de inferência neste repositório OpenChatKit que podem interagir com nosso endpoint implantado do SageMaker.
Existem dois componentes principais para isso:
- Um interpretador de shell (
JumpStartOpenChatKitShell) que permite invocações de inferência iterativas do endpoint do modelo - Um objeto de conversa (
Conversation) que armazena interações humanas/chatbot anteriores localmente dentro do shell interativo e formata adequadamente as conversas anteriores para um contexto de inferência futuro
A Conversation O objeto é importado como está do repositório OpenChatKit. O código a seguir cria um interpretador de shell personalizado que pode interagir com seu endpoint. Esta é uma versão simplificada da implementação do OpenChatKit. Incentivamos você a explorar o repositório OpenChatKit para ver como pode usar recursos mais detalhados, como streaming de token, modelos de moderação e geração aumentada de recuperação, dentro desse contexto. O contexto deste notebook se concentra em demonstrar um chatbot viável mínimo com um terminal JumpStart; você pode adicionar complexidade conforme necessário a partir daqui.
Uma breve demonstração para mostrar o JumpStartOpenChatKitShell é mostrado no vídeo a seguir.
O trecho a seguir mostra como o código funciona:
Agora você pode iniciar este shell como um loop de comando. Isso emitirá repetidamente um prompt, aceitará entrada, analisará o comando de entrada e despachará ações. Como o shell resultante pode ser utilizado em um loop infinito, este notebook fornece uma fila de comandos padrão (cmdqueue) como uma lista enfileirada de linhas de entrada. Porque a última entrada é o comando /quit, o shell sairá após o esgotamento da fila. Para interagir dinamicamente com este chatbot, remova o cmdqueue.
Exemplo 1: o contexto da conversa é mantido
O prompt a seguir mostra que o chatbot é capaz de reter o contexto da conversa para responder a perguntas de acompanhamento:
Exemplo 2: Classificação de sentimentos
No exemplo a seguir, o chatbot realizou uma tarefa de classificação identificando os sentimentos da frase. Como você pode ver, o chatbot conseguiu classificar sentimentos positivos e negativos com sucesso.
Exemplo 3: Tarefas de resumo
Em seguida, tentamos tarefas de resumo com o chatbot shell. O exemplo a seguir mostra como o texto longo sobre Amazon Comprehend foi resumido a uma frase e o chatbot foi capaz de responder a perguntas de acompanhamento no texto:
Exemplo 4: extrair informações estruturadas de texto não estruturado
No exemplo a seguir, usamos o chatbot para criar uma tabela de markdown com cabeçalhos, linhas e colunas para criar um plano de projeto usando as informações fornecidas em linguagem de formato livre:
Exemplo 5: Comandos como entrada para chatbot
Também podemos fornecer entrada como comandos como /hyperparameters para ver os valores dos hiperparâmetros e /quit para sair do shell de comando:
Esses exemplos mostraram apenas algumas das tarefas nas quais o OpenChatKit se destaca. Incentivamos você a experimentar vários prompts e ver o que funciona melhor para o seu caso de uso.
limpar
Depois de testar o endpoint, certifique-se de excluir o endpoint de inferência do SageMaker e o modelo para evitar cobranças.
Conclusão
Nesta postagem, mostramos como testar e usar o modelo GPT-NeoXT-Chat-Base-20B usando o SageMaker e criar aplicativos de chatbot interessantes. Experimente o modelo de fundação no SageMaker hoje e deixe-nos saber seus comentários!
Esta orientação é apenas para fins informativos. Você ainda deve realizar sua própria avaliação independente e tomar medidas para garantir a conformidade com suas próprias práticas e padrões específicos de controle de qualidade e com as regras, leis, regulamentos, licenças e termos de uso locais que se aplicam a você, seu conteúdo e o modelo de terceiros mencionado nesta orientação. A AWS não tem controle ou autoridade sobre o modelo de terceiros mencionado nesta orientação e não faz representações ou garantias de que o modelo de terceiros é seguro, livre de vírus, operacional ou compatível com seu ambiente de produção e padrões. A AWS não faz representações, garantias ou garantias de que qualquer informação nesta orientação resultará em um determinado resultado ou resultado.
Sobre os autores
 Rachna Chadha é Arquiteto Principal de Soluções AI/ML em Contas Estratégicas na AWS. Rachna é uma otimista que acredita que o uso ético e responsável da IA pode melhorar a sociedade no futuro e trazer prosperidade econômica e social. Em seu tempo livre, Rachna gosta de passar o tempo com sua família, fazer caminhadas e ouvir música.
Rachna Chadha é Arquiteto Principal de Soluções AI/ML em Contas Estratégicas na AWS. Rachna é uma otimista que acredita que o uso ético e responsável da IA pode melhorar a sociedade no futuro e trazer prosperidade econômica e social. Em seu tempo livre, Rachna gosta de passar o tempo com sua família, fazer caminhadas e ouvir música.
 Dr. é um Cientista Aplicado com o Algoritmos integrados do Amazon SageMaker equipe. Seus interesses de pesquisa incluem algoritmos de aprendizado de máquina escaláveis, visão computacional, séries temporais, processos não paramétricos bayesianos e processos gaussianos. Seu PhD é pela Duke University e ele publicou artigos em NeurIPS, Cell e Neuron.
Dr. é um Cientista Aplicado com o Algoritmos integrados do Amazon SageMaker equipe. Seus interesses de pesquisa incluem algoritmos de aprendizado de máquina escaláveis, visão computacional, séries temporais, processos não paramétricos bayesianos e processos gaussianos. Seu PhD é pela Duke University e ele publicou artigos em NeurIPS, Cell e Neuron.
 Dr. é um cientista aplicado sênior com algoritmos integrados do Amazon SageMaker e ajuda a desenvolver algoritmos de aprendizado de máquina. Ele obteve seu PhD pela University of Illinois Urbana-Champaign. Ele é um pesquisador ativo em aprendizado de máquina e inferência estatística e publicou muitos artigos em conferências NeurIPS, ICML, ICLR, JMLR, ACL e EMNLP.
Dr. é um cientista aplicado sênior com algoritmos integrados do Amazon SageMaker e ajuda a desenvolver algoritmos de aprendizado de máquina. Ele obteve seu PhD pela University of Illinois Urbana-Champaign. Ele é um pesquisador ativo em aprendizado de máquina e inferência estatística e publicou muitos artigos em conferências NeurIPS, ICML, ICLR, JMLR, ACL e EMNLP.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoAiStream. Inteligência de Dados Web3. Conhecimento Amplificado. Acesse aqui.
- Cunhando o Futuro com Adryenn Ashley. Acesse aqui.
- Compre e venda ações em empresas PRE-IPO com PREIPO®. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/gpt-neoxt-chat-base-20b-foundation-model-for-chatbot-applications-is-now-available-on-amazon-sagemaker/
- :tem
- :é
- :não
- $UP
- 1
- 100
- 12
- 13
- 15%
- 20
- 23
- 30
- 40
- 50
- 500
- 7
- 9
- a
- Capaz
- Sobre
- ACEITAR
- Acesso
- Segundo
- Contas
- Alcançar
- ações
- ativo
- adaptar
- adicionar
- Adição
- Adicional
- Adicionalmente
- avançado
- avanços
- AI
- AI / ML
- algoritmos
- permitir
- permite
- tb
- alternativa
- am
- Amazon
- Amazon Comprehend
- Amazon Sage Maker
- Amazon Web Services
- quantidade
- an
- análise
- analisar
- e
- Anunciar
- responder
- qualquer
- api
- APIs
- app
- Aplicação
- aplicações
- aplicado
- Aplicar
- adequadamente
- aproximadamente
- SOMOS
- argumento
- Arte
- AS
- avaliação
- certo
- At
- aumentado
- autoridade
- disponível
- evitar
- AWS
- baseado
- Bayesiano
- BE
- Porque
- antes
- acredita
- MELHOR
- Melhor
- Pós
- bilhões
- Bot
- bots
- Caixa
- trazer
- construir
- construídas em
- by
- CAN
- capacidades
- capital
- casas
- casos
- Categorias
- Categoria
- características
- acusações
- chatbot
- ChatGPT
- Escolha
- Cidades
- classe
- classificação
- classificar
- código
- colaborou
- colaboração
- colunas
- comum
- comparável
- compatível
- completar
- complexidade
- componentes
- compreender
- computador
- Visão de Computador
- Preocupações
- conferências
- cônsul
- Recipiente
- contém
- conteúdo
- contexto
- continuar
- ao controle
- Conversa
- conversação
- conversas
- converter
- Legal
- crio
- criado
- cria
- Criar
- critérios
- comissariada
- personalizadas
- cliente
- Clientes
- D.C.
- dados,
- ciência de dados
- conjuntos de dados
- profundo
- deep learning
- Padrão
- Demo
- demonstrando
- Dependendo
- implantar
- implantado
- desenvolvimento
- descrição
- projetado
- desejado
- detalhe
- Determinar
- desenvolver
- desenvolvido
- desenvolvedores
- Desenvolvimento
- desenvolve
- diferente
- digital
- Art digitais
- Expedição
- do
- Estivador
- Container Docker
- documento
- INSTITUCIONAIS
- parece
- Não faz
- dominante
- Duque
- Universidade Duke
- duração
- dinamicamente
- cada
- facilmente
- Econômico
- elementos
- outro
- permitir
- permitindo
- encorajar
- end-to-end
- Ponto final
- garantir
- Todo
- entidades
- entidade
- Meio Ambiente
- Éter (ETH)
- considerações éticas
- avaliação
- Mesmo
- examinar
- exemplo
- exemplos
- animado
- existente
- saída
- Expandir
- caro
- explorar
- extrato
- Extração
- Rosto
- família
- longe
- Favorito
- medo
- Característica
- Funcionalidades
- retornos
- poucos
- Arquivos
- Encontre
- Primeiro nome
- concentra-se
- focando
- seguinte
- segue
- Escolha
- Foundation
- da
- mais distante
- futuro
- gerar
- gerando
- geração
- ter
- dado
- vai
- Bom estado, com sinais de uso
- concessão
- garantias
- orientações
- Ter
- ter
- he
- cabeçalhos
- ajudar
- ajuda
- sua experiência
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- caminhadas
- sua
- hospedeiro
- hospedado
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- HTTPS
- Hub
- humano
- i
- ICLR
- ID
- identificar
- if
- Illinois
- imagem
- implementação
- melhorar
- melhorado
- in
- em profundidade
- incluir
- inclui
- Incluindo
- de treinadores em Entrevista Motivacional
- INFORMAÇÕES
- Informativa
- do estado inicial,
- entrada
- inputs
- insights
- instalar
- instância
- instruções
- Pretendido
- interagir
- interações
- interativo
- interessante
- interesses
- para dentro
- isolamento
- emitem
- IT
- ESTÁ
- Java
- Empregos
- jpg
- apenas por
- Chave
- Tipo
- Saber
- conhecido
- língua
- Idiomas
- grande
- Sobrenome
- Latência
- lançamento
- lançado
- Leis
- aprendizagem
- partida
- bibliotecas
- Biblioteca
- Licença
- licenças
- como
- Line
- linhas
- Lista
- Escuta
- local
- localmente
- longo
- lote
- máquina
- aprendizado de máquina
- a Principal
- a manter
- fazer
- maneira
- muitos
- Posso..
- medidas
- média
- menções
- método
- milhão
- mínimo
- minimizar
- minutos
- ML
- modelo
- modelos
- moderação
- modificada
- mais
- manhã
- Música
- natural
- Linguagem Natural
- Processamento de linguagem natural
- você merece...
- necessário
- negativo
- rede
- networking
- NeuroIPS
- nunca
- Novo
- novos produtos
- notícias
- PNL
- não
- caderno
- laptops
- agora
- objeto
- of
- Azeitonas
- on
- ONE
- só
- open source
- operacional
- Otimize
- Opções
- or
- Outros
- A Nossa
- Fora
- Resultado
- delineado
- saída
- lado de fora
- Acima de
- próprio
- papéis
- parâmetros
- particular
- partes
- passado
- realizar
- atuação
- Frases
- Pizza
- plano
- platão
- Inteligência de Dados Platão
- PlatãoData
- Jogar
- Popular
- positivo
- Publique
- práticas
- Predictor
- preferências
- pré-requisitos
- impede
- anterior
- Diretor
- prioridade
- processos
- em processamento
- Produção
- Produtos
- projeto
- prosperidade
- fornecer
- fornecido
- fornecedores
- fornece
- publicado
- fins
- Python
- pytorch
- qualidade
- questão
- Frequentes
- rapidamente
- alcance
- em vez
- em tempo real
- razões
- recentemente
- receita
- reconhecimento
- reconhecendo
- Reduzido
- Refatorar
- regulamentos
- liberar
- remover
- REPETIDAMENTE
- repositório
- requeridos
- pesquisa
- investigador
- resposta
- respostas
- responsável
- DESCANSO
- resultar
- resultando
- reter
- retorno
- rever
- Subir
- regras
- Execute
- s
- sábio
- Inferência do SageMaker
- dizer
- escalável
- Escala
- digitalização
- Ciência
- Cientista
- escopo
- Scripts
- Sdk
- Pesquisar
- Segundo
- seções
- seguro
- segurança
- Vejo
- doadores,
- AUTO
- senior
- sentença
- sentimento
- Seqüência
- Série
- serviço
- Serviços
- de servir
- Sessão
- conjunto
- Conjuntos
- instalação
- vários
- compartilhado
- concha
- Baixo
- rede de apoio social
- mostrar
- mostrar
- mostrada
- mostrou
- mostrando
- Shows
- semelhante
- simplificada
- SIX
- pequeno
- So
- Redes Sociais
- As redes sociais
- Sociedade
- solução
- Soluções
- RESOLVER
- alguns
- fonte
- código fonte
- específico
- especificada
- velocidade
- Passar
- propagação
- padrões
- começo
- começado
- estatístico
- Passo
- Passos
- Ainda
- Dê um basta
- lojas
- Estratégico
- de streaming
- estrutura
- estruturada
- entraram com sucesso
- tal
- RESUMO
- Suportado
- certo
- mesa
- Tire
- Tarefa
- tarefas
- Profissionais
- técnicas
- dizer
- modelos
- fluxo tensor
- condições
- teste
- testadores
- geração de texto
- do que
- que
- A
- O capital
- O Futuro
- as informações
- A fonte
- Eles
- si mesmos
- então
- Lá.
- Este
- Terceiro
- terceiro
- De terceiros
- isto
- Através da
- tempo
- Séries temporais
- para
- hoje
- juntos
- token
- Trem
- treinado
- Training
- transformadores
- Tradução
- experimentado
- verdadeiro
- tentar
- dois
- tipo
- tipicamente
- ui
- para
- subjacente
- compreensão
- universidade
- até
- sobre
- URI
- us
- Uso
- usar
- caso de uso
- usava
- utilização
- utilizado
- Valores
- variedade
- vário
- versão
- via
- viável
- Vídeo
- visão
- queremos
- quente
- foi
- Washington
- we
- Clima
- web
- serviços web
- semanas
- boas-vindas
- BEM
- O Quê
- O que é a
- quando
- se
- qual
- QUEM
- Largo
- mais largo
- precisarão
- de
- dentro
- sem
- Word
- palavras
- de gestão de documentos
- trabalho
- escrever
- Você
- investimentos
- zefirnet