Todos os dias, os dispositivos da Amazon processam e analisam bilhões de transações de remessas globais, estoque, capacidade, suprimentos, vendas, marketing, produtores e equipes de atendimento ao cliente. Esses dados são usados na aquisição de inventário de dispositivos para atender às demandas dos clientes da Amazon. Com os volumes de dados exibindo uma taxa de crescimento percentual de dois dígitos ano a ano e a pandemia de COVID interrompendo a logística global em 2021, tornou-se mais crítico dimensionar e gerar dados quase em tempo real.
Esta postagem mostra como migramos para um data lake sem servidor criado na AWS que consome dados automaticamente de várias fontes e formatos diferentes. Além disso, criou mais oportunidades para nossos cientistas e engenheiros de dados usarem serviços de IA e aprendizado de máquina (ML) para alimentar e analisar dados continuamente.
Desafios e preocupações de design
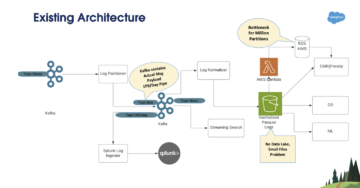
Nossa arquitetura herdada usada principalmente Amazon Elastic Compute Nuvem (Amazon EC2) para extrair os dados de várias fontes de dados heterogêneas internas e APIs REST com a combinação de Serviço de armazenamento simples da Amazon (Amazon S3) para carregar os dados e Amazon RedShift para posterior análise e geração dos pedidos de compra.
Descobrimos que essa abordagem resultou em algumas deficiências e, portanto, levou a melhorias nas seguintes áreas:
- Velocidade do desenvolvedor – Devido à falta de unificação e descoberta de esquema, que são os principais motivos para falhas de tempo de execução, os desenvolvedores geralmente gastam tempo lidando com problemas operacionais e de manutenção.
- AMPLIAR – A maioria desses conjuntos de dados é compartilhada em todo o mundo. Portanto, devemos atender aos limites de dimensionamento ao consultar os dados.
- Manutenção mínima da infraestrutura – O processo atual abrange várias computações, dependendo da fonte de dados. Portanto, reduzir a manutenção da infraestrutura é fundamental.
- Capacidade de resposta a alterações na fonte de dados – Nosso sistema atual obtém dados de vários armazenamentos e serviços de dados heterogêneos. Qualquer atualização desses serviços leva meses de ciclos de desenvolvedor. Os tempos de resposta para essas fontes de dados são essenciais para nossos principais interessados. Portanto, devemos adotar uma abordagem orientada a dados para selecionar uma arquitetura de alto desempenho.
- Armazenamento e redundância – Devido aos armazenamentos e modelos de dados heterogêneos, era um desafio armazenar os diferentes conjuntos de dados de várias equipes de partes interessadas nos negócios. Portanto, ter controle de versão junto com dados incrementais e diferenciais para comparar fornecerá uma capacidade notável de gerar planos mais otimizados
- Fugitivo e acessibilidade – Devido à natureza volátil da logística, algumas equipes de stakeholders de negócios precisam analisar os dados sob demanda e gerar o plano ideal quase em tempo real para os pedidos de compra. Isso introduz a necessidade de pesquisar e enviar os dados para acesso e análise quase em tempo real.
Estratégia de implementação
Com base nesses requisitos, mudamos as estratégias e passamos a analisar cada questão para identificar a solução. Arquitetonicamente, escolhemos um modelo sem servidor, e a linha de ação da arquitetura do data lake refere-se a todas as lacunas arquitetônicas e recursos desafiadores que determinamos como parte das melhorias. Do ponto de vista operacional, projetamos um novo modelo de responsabilidade compartilhada para ingestão de dados usando Cola AWS em vez de serviços internos (APIs REST) projetados no Amazon EC2 para extrair os dados. Nós também usamos AWS Lambda para processamento de dados. Então nós escolhemos Amazona atena como nosso serviço de consulta. Para otimizar e melhorar ainda mais a velocidade do desenvolvedor para nossos consumidores de dados, adicionamos Amazon DynamoDB como um armazenamento de metadados para diferentes fontes de dados que chegam ao data lake. Essas duas decisões conduziram todas as decisões de design e implementação que tomamos.
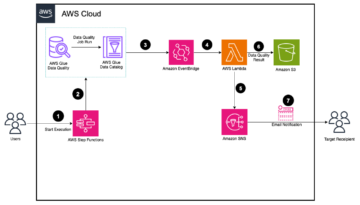
O diagrama a seguir ilustra a arquitetura

Nas seções a seguir, veremos cada componente da arquitetura com mais detalhes à medida que avançamos no fluxo do processo.
AWS Glue para ETL
Para atender à demanda do cliente e, ao mesmo tempo, oferecer suporte à escala das fontes de dados de novos negócios, era fundamental para nós ter um alto grau de agilidade, escalabilidade e capacidade de resposta na consulta de várias fontes de dados.
O AWS Glue é um serviço de integração de dados sem servidor que facilita para os usuários analíticos descobrir, preparar, mover e integrar dados de várias fontes. Você pode usá-lo para análises, ML e desenvolvimento de aplicativos. Ele também inclui ferramentas adicionais de produtividade e DataOps para criação, execução de tarefas e implementação de fluxos de trabalho de negócios.
Com o AWS Glue, você pode descobrir e conectar-se a mais de 70 fontes de dados diversas e gerenciar seus dados em um catálogo de dados centralizado. Você pode criar, executar e monitorar visualmente pipelines de extração, transformação e carregamento (ETL) para carregar dados em seus data lakes. Além disso, você pode pesquisar e consultar imediatamente dados catalogados usando o Athena, Amazon EMR e Espectro Amazon Redshift.
O AWS Glue facilitou a conexão com os dados em vários armazenamentos de dados, editou e limpou os dados conforme necessário e carregou os dados em um armazenamento provisionado pela AWS para uma visualização unificada. Os trabalhos do AWS Glue podem ser agendados ou chamados sob demanda para extrair dados do recurso do cliente e do data lake.
Algumas responsabilidades desses trabalhos são as seguintes:
- Extraindo e convertendo uma entidade de origem em uma entidade de dados
- Enriqueça os dados para conter ano, mês e dia para uma melhor catalogação e inclua um ID instantâneo para uma melhor consulta
- Execute validação de entrada e geração de caminho para Amazon S3
- Associar os metadados acreditados com base no sistema de origem
Consultar APIs REST de serviços internos é um dos nossos principais desafios e, considerando a infraestrutura mínima, queríamos usá-los neste projeto. Os conectores do AWS Glue nos ajudaram a cumprir o requisito e o objetivo. Para consultar dados de APIs REST e outras fontes de dados, usamos os módulos PySpark e JDBC.
O AWS Glue oferece suporte a uma ampla variedade de tipos de conexão. Para mais detalhes, consulte Tipos de conexão e opções para ETL no AWS Glue.
Caçamba S3 como zona de aterrissagem
Usamos um balde S3 como a zona de aterrissagem imediata dos dados extraídos, que são processados e otimizados posteriormente.
Lambda como gatilho ETL do AWS Glue
Habilitamos as notificações de eventos do S3 no bucket do S3 para acionar o Lambda, que particiona ainda mais nossos dados. Os dados são particionados em InputDataSetName, Year, Month e Date. Qualquer processador de consulta executado sobre esses dados examinará apenas um subconjunto de dados para melhor otimização de custo e desempenho. Nossos dados podem ser armazenados em vários formatos, como CSV, JSON e Parquet.
Os dados brutos não são ideais para a maioria dos nossos casos de uso para gerar o plano ideal porque geralmente possuem duplicatas ou tipos de dados incorretos. Mais importante ainda, os dados estão em vários formatos, mas modificamos rapidamente os dados e observamos ganhos significativos de desempenho de consulta ao usar o formato Parquet. Aqui, usamos uma das dicas de desempenho em As 10 principais dicas de ajuste de desempenho para o Amazon Athena.
Trabalhos do AWS Glue para ETL
Queríamos melhor segregação e acessibilidade de dados, então optamos por ter um bucket S3 diferente para melhorar ainda mais o desempenho. Usamos os mesmos trabalhos do AWS Glue para transformar e carregar ainda mais os dados no bucket S3 necessário e uma parte dos metadados extraídos no DynamoDB.
DynamoDB como armazenamento de metadados
Agora que temos os dados, várias partes interessadas nos negócios os consomem ainda mais. Isso nos deixa com duas perguntas: quais dados de origem residem no data lake e qual versão. Escolhemos o DynamoDB como nosso armazenamento de metadados, que fornece os detalhes mais recentes aos consumidores para consultar os dados de forma eficaz. Cada conjunto de dados em nosso sistema é identificado exclusivamente pelo ID do instantâneo, que podemos pesquisar em nosso armazenamento de metadados. Os clientes acessam esse armazenamento de dados com uma API.
Amazon S3 como data lake
Para melhor qualidade de dados, extraímos os dados enriquecidos em outro bucket do S3 com o mesmo trabalho do AWS Glue.
Rastreador do AWS Glue
Os rastreadores são o “molho secreto” que nos permite responder às mudanças de esquema. Ao longo do processo, optamos por tornar cada etapa o mais independente possível de esquema, o que permite que qualquer alteração de esquema flua até chegar ao AWS Glue. Com um rastreador, poderíamos manter as alterações agnósticas que ocorrem no esquema. Isso nos ajudou a rastrear automaticamente os dados do Amazon S3 e gerar o esquema e as tabelas.
Catálogo de dados do AWS Glue
O Data Catalog nos ajudou a manter o catálogo como um índice para a localização, esquema e métricas de tempo de execução dos dados no Amazon S3. As informações no Catálogo de Dados são armazenadas como tabelas de metadados, onde cada tabela especifica um único armazenamento de dados.
Athena para consultas SQL
Athena é um serviço de consulta interativo que facilita a análise de dados no Amazon S3 usando SQL padrão. O Athena é sem servidor, portanto, não há infraestrutura para gerenciar e você paga apenas pelas consultas executadas. Consideramos a estabilidade operacional e o aumento da velocidade do desenvolvedor como nossos principais fatores de melhoria.
Otimizamos ainda mais o processo de consulta do Athena para que os usuários possam inserir os valores e as consultas para obter dados do Athena criando o seguinte:
- An Kit de desenvolvimento em nuvem da AWS (AWS CDK) para criar a infraestrutura Athena e Gerenciamento de acesso e identidade da AWS Funções (IAM) para acessar os buckets S3 do data lake e o Catálogo de dados de qualquer conta
- Uma biblioteca para que o cliente possa fornecer uma função IAM, consulta, formato de dados e local de saída para iniciar uma consulta Athena e obter o status e o resultado da consulta executada no bucket de sua escolha.
Consultar o Athena é um processo de duas etapas:
- IniciarQueryExecution – Isso inicia a execução da consulta e obtém o ID da execução. Os usuários podem fornecer o local de saída onde a saída da consulta será armazenada.
- GetQueryExecution – Isso obtém o status da consulta porque a execução é assíncrona. Quando bem-sucedido, você pode consultar a saída em um arquivo S3 ou via API.
O método auxiliar para iniciar a execução da consulta e obter o resultado estaria na biblioteca.
Serviço de metadados do data lake
Esse serviço é desenvolvido de forma personalizada e interage com o DynamoDB para obter os metadados (nome do conjunto de dados, ID do instantâneo, string de partição, carimbo de data/hora e link S3 dos dados) na forma de uma API REST. Quando o esquema é descoberto, os clientes usam o Athena como processador de consulta para consultar os dados.
Como todos os conjuntos de dados têm um ID de instantâneo e são particionados, a consulta de junção não resulta em uma verificação completa da tabela, mas apenas em uma verificação de partição no Amazon S3. Usamos o Athena como nosso processador de consultas devido à facilidade de não gerenciar nossa infraestrutura de consultas. Mais tarde, se sentirmos que precisamos de algo mais, podemos usar o Redshift Spectrum ou o Amazon EMR.
Conclusão
As equipes da Amazon Devices descobriram um valor significativo migrando para uma arquitetura de data lake usando o AWS Glue, que permitiu que várias partes interessadas em negócios globais ingerissem dados de maneiras mais produtivas. Isso permitiu que as equipes gerassem o plano ideal para fazer pedidos de compra de dispositivos, analisando os diferentes conjuntos de dados quase em tempo real com a lógica de negócios apropriada para resolver os problemas da cadeia de suprimentos, demanda e previsão.
Do ponto de vista operacional, o investimento já começou a dar frutos:
- Ele padronizou nossos mecanismos de ingestão, armazenamento e recuperação, economizando tempo de integração. Antes da implementação desse sistema, um conjunto de dados levava 1 mês para ser integrado. Devido à nossa nova arquitetura, conseguimos integrar 15 novos conjuntos de dados em menos de 2 meses, o que melhorou nossa agilidade em 70%.
- Ele removeu gargalos de dimensionamento, criando um sistema homogêneo que pode ser dimensionado rapidamente para milhares de execuções.
- A solução adicionou validação de esquema e qualidade de dados antes de aceitar quaisquer entradas e rejeitá-las se forem descobertas violações de qualidade de dados.
- Ele facilitou a recuperação de conjuntos de dados, ao mesmo tempo em que suporta simulações futuras e casos de uso de back tester que exigem entradas com controle de versão. Isso tornará os modelos de lançamento e teste mais simples.
- A solução criou uma infraestrutura comum que pode ser facilmente estendida a outras equipes em DIAL com problemas semelhantes com casos de uso de ingestão, armazenamento e recuperação de dados.
- Nossos custos operacionais caíram quase 90%.
- Esse data lake pode ser acessado com eficiência por nossos cientistas e engenheiros de dados para realizar outras análises e ter uma abordagem preditiva como uma oportunidade futura de gerar planos precisos para os pedidos de compra.
As etapas nesta postagem podem ajudá-lo a planejar uma estratégia de dados moderna semelhante usando serviços gerenciados pela AWS para ingerir dados de diferentes fontes, criar catálogos de metadados automaticamente, compartilhar dados perfeitamente entre o data lake e o data warehouse e criar alertas no evento de uma falha de fluxo de trabalho de dados orquestrados.
Sobre os autores
 Avinash Kolluri é Arquiteto de Soluções Sênior na AWS. Ele trabalha em Amazon Alexa e dispositivos para arquitetar e projetar soluções distribuídas modernas. Sua paixão é criar soluções econômicas e altamente escaláveis na AWS. Em seu tempo livre, ele gosta de cozinhar receitas de fusão e viajar.
Avinash Kolluri é Arquiteto de Soluções Sênior na AWS. Ele trabalha em Amazon Alexa e dispositivos para arquitetar e projetar soluções distribuídas modernas. Sua paixão é criar soluções econômicas e altamente escaláveis na AWS. Em seu tempo livre, ele gosta de cozinhar receitas de fusão e viajar.
 Vipul Verma é engenheiro de software sênior da Amazon.com. Ele está na Amazon desde 2015, resolvendo desafios do mundo real por meio da tecnologia que impacta e melhora diretamente a vida dos clientes da Amazon. Nas horas vagas, gosta de fazer caminhadas.
Vipul Verma é engenheiro de software sênior da Amazon.com. Ele está na Amazon desde 2015, resolvendo desafios do mundo real por meio da tecnologia que impacta e melhora diretamente a vida dos clientes da Amazon. Nas horas vagas, gosta de fazer caminhadas.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/how-amazon-devices-scaled-and-optimized-real-time-demand-and-supply-forecasts-using-serverless-analytics/
- 1
- 10
- 100
- 2021
- 70
- a
- habilidade
- Capaz
- Acesso
- acessadas
- acessibilidade
- credenciado
- preciso
- em
- Açao Social
- adicionado
- Adicional
- AI
- Alexa
- Todos os Produtos
- permite
- já
- Amazon
- amazon alexa
- Amazon EC2
- Amazon EMR
- Amazon.com
- análise
- analítica
- analisar
- análise
- e
- Outro
- api
- APIs
- Aplicação
- Desenvolvimento de Aplicações
- abordagem
- apropriado
- arquitetônico
- arquitetura
- áreas
- autoria
- automaticamente
- AWS
- Cola AWS
- em caminho duplo
- baseado
- Porque
- antes
- Melhor
- entre
- bilhões
- construir
- construído
- negócio
- chamado
- Capacidade
- casos
- catálogo
- catálogos
- centralizada
- cadeia
- desafios
- desafiante
- Alterações
- escolha
- escolheu
- cliente
- clientes
- Na nuvem
- COM
- combinação
- comum
- comparar
- componente
- Computar
- Contato
- da conexão
- considerado
- considerando
- consumir
- Consumidores
- continuamente
- cozinha
- núcleo
- Custo
- relação custo-benefício
- custos
- poderia
- Covid
- rastreador
- crio
- criado
- Criar
- crítico
- Atual
- personalizadas
- cliente
- Atendimento ao Cliente
- Clientes
- ciclos
- dados,
- integração de dados
- lago data
- informática
- qualidade de dados
- estratégia de dados
- data warehouse
- orientado por dados
- conjuntos de dados
- Data
- dia
- lidar
- decisão
- decisões
- Grau
- Demanda
- demandas
- Dependendo
- Design
- projetado
- detalhe
- detalhes
- determinado
- desenvolvido
- Developer
- desenvolvedores
- Desenvolvimento
- Dispositivos/Instrumentos
- diferente
- diretamente
- descobrir
- descoberto
- descoberta
- distribuído
- diferente
- Não faz
- duplicatas
- cada
- facilmente
- efetivamente
- eficientemente
- ou
- habilitado
- permite
- engenheiro
- Engenheiros
- enriquecido
- entidade
- Éter (ETH)
- Evento
- Cada
- extrato
- extrair os dados
- fatores
- Falha
- Caído
- Funcionalidades
- poucos
- Envie o
- fluxo
- seguinte
- segue
- Previsão
- formulário
- formato
- encontrado
- da
- cheio
- mais distante
- Além disso
- fusão
- futuro
- Ganhos
- gerar
- gerando
- geração
- ter
- obtendo
- Global
- negócio global
- globo
- meta
- Growth
- ter
- ajudar
- ajudou
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- Alta
- alta performance
- altamente
- caminhadas
- Como funciona o dobrador de carta de canal
- HTML
- HTTPS
- IAM
- ideal
- identificado
- identificar
- Dados de identificação:
- Imediato
- imediatamente
- Impacto
- implementação
- implementação
- melhorar
- melhorado
- melhoria
- melhorias
- in
- incluir
- inclui
- aumentando
- índice
- INFORMAÇÕES
- Infraestrutura
- entrada
- em vez disso
- integrar
- integração
- interativo
- interage
- interno
- Introduz
- inventário
- investimento
- emitem
- questões
- IT
- Trabalho
- Empregos
- juntar
- json
- Chave
- Falta
- lago
- aterrissagem
- mais recente
- de lançamento
- aprendizagem
- Legado
- Biblioteca
- vida
- limites
- Line
- LINK
- carregar
- localização
- logística
- olhar
- máquina
- aprendizado de máquina
- moldadas
- a manter
- manutenção
- fazer
- FAZ
- gerencia
- gestão
- Marketing
- Conheça
- metadados
- método
- Métrica
- mínimo
- ML
- modelo
- modelos
- EQUIPAMENTOS
- modificada
- Módulos
- Monitore
- Mês
- mês
- mais
- a maioria
- mover
- em movimento
- múltiplo
- nome
- Natureza
- você merece...
- necessário
- Novo
- notificações
- A bordo
- Onboarding
- ONE
- operando
- operacional
- oportunidades
- Oportunidade
- ideal
- otimização
- Otimize
- otimizado
- Opções
- ordens
- Outros
- pandemia
- parte
- paixão
- caminho
- Pagar
- percentagem
- realizar
- atuação
- perspectiva
- Lugar
- plano
- planos
- platão
- Inteligência de Dados Platão
- PlatãoData
- possível
- Publique
- Preparar
- principalmente
- primário
- problemas
- processo
- em processamento
- Subcontratante
- Produtores
- produtivo
- produtividade
- projeto
- fornecer
- fornece
- compra
- Empurrando
- qualidade
- Frequentes
- rapidamente
- Taxa
- Cru
- dados não tratados
- alcançar
- mundo real
- em tempo real
- razões
- Receitas
- redução
- refere-se
- notável
- Removido
- requeridos
- requerimento
- Requisitos
- recurso
- resposta
- responsabilidades
- responsabilidade
- responsivo
- DESCANSO
- resultar
- Tipo
- papéis
- Execute
- corrida
- vendas
- mesmo
- poupança
- AMPLIAR
- escalável
- Escala
- dimensionamento
- digitalização
- programado
- cientistas
- sem problemas
- Pesquisar
- seções
- senior
- Serverless
- serviço
- Serviços
- Partilhar
- compartilhado
- Envios
- Shows
- periodo
- semelhante
- simples
- desde
- solteiro
- Instantâneo
- So
- Software
- Engenheiro de Software
- solução
- Soluções
- RESOLVER
- Resolvendo
- algo
- fonte
- Fontes
- vãos
- Espectro
- gasto
- SQL
- Estabilidade
- partes interessadas
- partes interessadas
- padrão
- começo
- começado
- Comece
- começa
- Status
- Passo
- Passos
- armazenamento
- loja
- armazenadas
- lojas
- estratégias
- Estratégia
- bem sucedido
- tal
- supply
- cadeia de suprimentos
- Apoiar
- suportes
- .
- mesa
- Tire
- toma
- equipes
- Equipar
- modelo
- ensaio
- A
- A fonte
- deles
- assim sendo
- milhares
- Através da
- todo
- tempo
- vezes
- timestamp
- dicas
- para
- topo
- Transações
- Transformar
- Viagens
- desencadear
- tipos
- unificado
- Atualizações
- us
- usar
- usuários
- validação
- valor
- Valores
- variedade
- vário
- Velocidade
- versão
- via
- Ver
- Violações
- volátil
- volumes
- querido
- Armazém
- maneiras
- O Quê
- qual
- enquanto
- Largo
- precisarão
- de gestão de documentos
- fluxos de trabalho
- trabalho
- seria
- ano
- investimentos
- zefirnet