Esta postagem do blog é de coautoria de Guillermo Ribeiro, Cientista de Dados Sr. da Cepsa.
O aprendizado de máquina (ML) evoluiu rapidamente de uma tendência da moda emergindo de ambientes acadêmicos e departamentos de inovação para se tornar um meio essencial de agregar valor a empresas em todos os setores. Essa transição de experimentos em laboratórios para solução de problemas do mundo real em ambientes de produção anda de mãos dadas com MLOps, ou a adaptação do DevOps ao mundo do ML.
O MLOps ajuda a simplificar e automatizar o ciclo de vida completo de um modelo de ML, concentrando-se nos conjuntos de dados de origem, na reprodutibilidade do experimento, no código do algoritmo de ML e na qualidade do modelo.
At Cepsa, uma empresa global de energia, usamos o ML para resolver problemas complexos em nossas linhas de negócios, desde a manutenção preditiva de equipamentos industriais até o monitoramento e a melhoria dos processos petroquímicos em nossas refinarias.
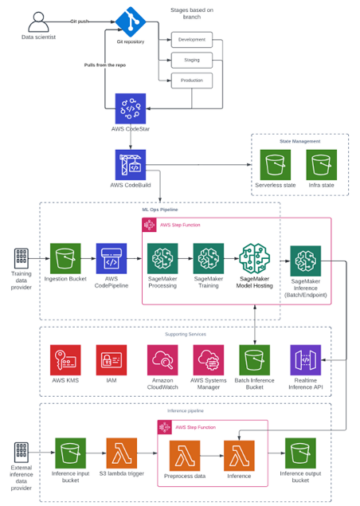
Neste post, discutimos como construímos nossa arquitetura de referência para MLOps usando os seguintes serviços-chave da AWS:
- Amazon Sage Maker, um serviço para criar, treinar e implantar modelos de ML
- Funções de etapa da AWS, um serviço de fluxo de trabalho visual de baixo código sem servidor usado para orquestrar e automatizar processos
- Amazon Event Bridge, um barramento de eventos sem servidor
- AWS Lambda, um serviço de computação sem servidor que permite executar código sem provisionar ou gerenciar servidores
Também explicamos como aplicamos essa arquitetura de referência para inicializar novos projetos de ML em nossa empresa.
O desafio
Durante os últimos 4 anos, várias linhas de negócios da Cepsa iniciaram projetos de ML, mas logo começaram a surgir alguns problemas e limitações.
Não tínhamos uma arquitetura de referência para ML, então cada projeto seguiu um caminho de implementação diferente, realizando treinamento e implantação de modelos ad hoc. Sem um método comum para lidar com o código e os parâmetros do projeto e sem um registro de modelo de ML ou sistema de versão, perdemos a rastreabilidade entre conjuntos de dados, código e modelos.
Também detectamos espaço para melhorias na maneira como operamos os modelos em produção, porque não monitoramos os modelos implantados e, portanto, não tínhamos meios de rastrear o desempenho do modelo. Como consequência, geralmente retreinávamos modelos com base em cronogramas, porque não tínhamos as métricas corretas para tomar decisões de retreinamento informadas.
A solução
A partir dos desafios que tivemos que superar, projetamos uma solução geral que visava desacoplar preparação de dados, treinamento de modelos, inferência e monitoramento de modelos, e apresentava um registro de modelos centralizado. Dessa forma, simplificamos o gerenciamento de ambientes em várias contas da AWS, ao mesmo tempo em que introduzimos a rastreabilidade centralizada do modelo.
Nossos cientistas de dados e desenvolvedores usam Nuvem AWS9 (um IDE na nuvem para escrever, executar e depurar código) para manipulação de dados e experimentação de ML e GitHub como repositório de código Git.
Um fluxo de trabalho de treinamento automático usa o código criado pela equipe de ciência de dados para treinar modelos no SageMaker e registrar modelos de saída no registro de modelos.
Um fluxo de trabalho diferente gerencia a implantação do modelo: ele obtém a referência do registro do modelo e cria um endpoint de inferência usando Recursos de hospedagem de modelos do SageMaker.
Implementamos fluxos de trabalho de treinamento e implantação de modelo usando o Step Functions, pois ele fornece uma estrutura flexível que permite a criação de fluxos de trabalho específicos para cada projeto e orquestra diferentes serviços e componentes da AWS de maneira direta.
Modelo de consumo de dados
Na Cepsa, usamos uma série de data lakes para atender a diversas necessidades de negócios, e todos esses data lakes compartilham um modelo comum de consumo de dados que facilita aos engenheiros de dados e cientistas de dados encontrar e consumir os dados de que precisam.
Para lidar facilmente com custos e responsabilidades, os ambientes de data lake são completamente separados dos aplicativos de produtores e consumidores de dados e implantados em diferentes contas da AWS pertencentes a uma organização comum da AWS.
Os dados usados para treinar modelos de ML e os dados usados como entrada de inferência para modelos treinados são disponibilizados a partir dos diferentes data lakes por meio de um conjunto de APIs bem definidas usando Gateway de API da Amazon, um serviço para criar, publicar, manter, monitorar e proteger APIs em escala. O back-end da API usa Amazona atena (um serviço de consulta interativa para analisar dados usando SQL padrão) para acessar dados que já estão armazenados em Serviço de armazenamento simples da Amazon (Amazon S3) e catalogado no Cola AWS Catálogo de Dados.
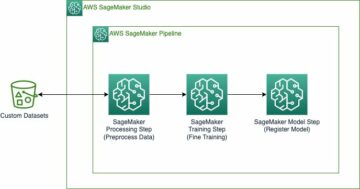
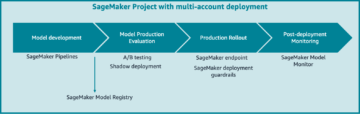
O diagrama a seguir fornece uma visão geral da arquitetura MLOps da Cepsa.

Treinamento de modelo
O processo de treinamento é independente para cada modelo e gerenciado por um Fluxo de trabalho padrão do Step Functions, o que nos dá flexibilidade para modelar processos com base em diferentes requisitos de projeto. Temos um template base definido que reutilizamos na maioria dos projetos, realizando pequenos ajustes quando necessário. Por exemplo, alguns proprietários de projetos decidiram adicionar portões manuais para aprovar implantações de novos modelos de produção, enquanto outros proprietários de projetos implementaram seus próprios mecanismos de detecção de erros e novas tentativas.
Também realizamos transformações nos conjuntos de dados de entrada usados para treinamento do modelo. Para isso, usamos funções do Lambda que são integradas nos fluxos de trabalho de treinamento. Em alguns cenários em que são necessárias transformações de dados mais complexas, executamos nosso código em Serviço Amazon Elastic Container (Amazon ECS) em AWS Fargate, um mecanismo de computação sem servidor para executar contêineres.
Nossa equipe de ciência de dados usa algoritmos personalizados com frequência, por isso aproveitamos a capacidade de use contêineres personalizados no treinamento de modelo do SageMaker, depender Registro do Amazon Elastic Container (Amazon ECR), um registro de contêiner totalmente gerenciado que facilita o armazenamento, o gerenciamento, o compartilhamento e a implantação de imagens de contêiner.
A maioria dos nossos projetos de ML é baseada na biblioteca Scikit-learn, por isso estendemos o padrão Contêiner SageMaker Scikit-learn para incluir as variáveis de ambiente necessárias para o projeto, como as informações do repositório Git e as opções de implantação.
Com essa abordagem, nossos cientistas de dados só precisam se concentrar no desenvolvimento do algoritmo de treinamento e especificar as bibliotecas exigidas pelo projeto. Quando eles enviam alterações de código para o repositório Git, nosso sistema CI/CD (Jenkins hospedado na AWS) cria o contêiner com o código de treinamento e as bibliotecas. Esse contêiner é enviado para o Amazon ECR e, finalmente, passado como um parâmetro para a invocação de treinamento do SageMaker.
Quando o processo de treinamento é concluído, o modelo resultante é armazenado no Amazon S3, uma referência é adicionada ao registro do modelo e todas as informações e métricas coletadas são salvas no catálogo de experimentos. Isso garante total reprodutibilidade, pois o código do algoritmo e as bibliotecas são vinculados ao modelo treinado junto com os dados associados ao experimento.
O diagrama a seguir ilustra o processo de treinamento e retreinamento do modelo.

Implantação de modelo
A arquitetura é flexível e permite implantações automáticas e manuais dos modelos treinados. O fluxo de trabalho do implantador de modelo é invocado automaticamente por meio de um evento que o treinamento do SageMaker publica no EventBridge após o término do treinamento, mas também pode ser invocado manualmente, se necessário, passando a versão correta do modelo do registro do modelo. Para obter mais informações sobre invocação automática, consulte Automatizando o Amazon SageMaker com o Amazon EventBridge.
O fluxo de trabalho do implementador do modelo recupera as informações do modelo do registro do modelo e usa Formação da Nuvem AWS, uma infraestrutura gerenciada como serviço de código, para implantar o modelo em um endpoint de inferência em tempo real ou realizar inferência em lote com um conjunto de dados de entrada armazenado, dependendo dos requisitos do projeto.
Sempre que um modelo é implementado com sucesso em qualquer ambiente, o registro do modelo é atualizado com uma nova tag indicando em quais ambientes o modelo está sendo executado no momento. Sempre que um terminal é removido, sua tag também é excluída do registro do modelo.
O diagrama a seguir mostra o fluxo de trabalho para implantação e inferência do modelo.

Experimentos e registro de modelos
Armazenar todos os experimentos e versões de modelos em um único local e ter um repositório de código centralizado nos permite dissociar o treinamento e a implantação de modelos e usar diferentes contas da AWS para cada projeto e ambiente.
Todas as entradas de experimento armazenam o ID de confirmação do código de treinamento e inferência, para que tenhamos rastreabilidade completa de todo o processo de experimentação e possamos comparar facilmente diferentes experimentos. Isso nos impede de realizar trabalho duplicado na fase de exploração científica de algoritmos e modelos e nos permite implantar nossos modelos em qualquer lugar, independentemente da conta e do ambiente em que o modelo foi treinado. Isso também vale para modelos treinados em nosso ambiente de experimentação AWS Cloud9.
Em suma, temos pipelines de treinamento e implantação de modelo totalmente automatizados e temos a flexibilidade de executar implantações manuais rápidas de modelo quando algo não está funcionando corretamente ou quando uma equipe precisa de um modelo implantado em um ambiente diferente para fins de experimentação.
Um caso de uso detalhado: projeto YET Dragon
O projeto YET Dragon visa melhorar o desempenho produtivo da planta petroquímica da Cepsa em Xangai. Para atingir este objetivo, estudamos minuciosamente o processo de produção, procurando as etapas menos eficientes. Nosso objetivo era aumentar a eficiência do rendimento dos processos mantendo a concentração de componentes exatamente abaixo de um limite.
Para simular este processo, construímos quatro modelos aditivos generalizados ou GAM, modelos lineares cuja resposta depende de funções suaves de variáveis preditoras, para prever os resultados de dois processos de oxidação, um processo de concentração e o rendimento mencionado. Também construímos um otimizador para processar os resultados dos quatro modelos GAM e encontrar as melhores otimizações que poderiam ser aplicadas na planta.
Embora nossos modelos sejam treinados com dados históricos, às vezes a planta pode operar em circunstâncias que não foram registradas no conjunto de dados de treinamento; esperamos que nossos modelos de simulação não funcionem bem nesses cenários, então também construímos dois modelos de detecção de anomalias usando algoritmos de Isolation Forests, que determinam a distância dos pontos de dados para o restante dos dados para detectar as anomalias. Esses modelos nos ajudam a detectar tais situações para desativar os processos automatizados de otimização sempre que isso acontecer.
Os processos químicos industriais são altamente variáveis e os modelos de ML precisam estar bem alinhados com a operação da planta, por isso é necessário retreinamento frequente e rastreabilidade dos modelos implantados em cada situação. O YET Dragon foi nosso primeiro projeto de otimização de ML a apresentar um registro de modelo, reprodutibilidade total dos experimentos e um processo de treinamento automatizado totalmente gerenciado.
Agora, o pipeline completo que coloca um modelo em produção (transformação de dados, treinamento de modelo, rastreamento de experimentos, registro de modelo e implantação de modelo) é independente para cada modelo de ML. Isso nos permite melhorar os modelos de forma iterativa (por exemplo, adicionar novas variáveis ou testar novos algoritmos) e conectar os estágios de treinamento e implantação a diferentes gatilhos.
Os resultados e melhorias futuras
Atualmente, podemos treinar, implantar e rastrear automaticamente os seis modelos de ML usados no projeto YET Dragon e já implantamos mais de 30 versões para cada um dos modelos de produção. Essa arquitetura MLOps foi estendida para centenas de modelos de ML em outros projetos da empresa.
Planejamos continuar lançando novos projetos do YET com base nessa arquitetura, que diminuiu a duração média do projeto em 25%, graças à redução do tempo de bootstrap e à automação dos pipelines de ML. Também estimamos uma economia de cerca de € 300,000 por ano graças ao aumento de rendimento e concentração que é resultado direto do projeto YET Dragon.
A evolução de curto prazo dessa arquitetura MLOps é no sentido de monitoramento de modelos e testes automatizados. Planejamos testar automaticamente a eficiência do modelo em relação aos modelos implantados anteriormente antes que um novo modelo seja implantado. Também estamos trabalhando na implementação de monitoramento de modelo e monitoramento de desvio de dados de inferência com Monitor de modelo do Amazon SageMaker, a fim de automatizar o retreinamento do modelo.
Conclusão
As empresas enfrentam o desafio de levar seus projetos de ML para a produção de forma automatizada e eficiente. Automatizar o ciclo de vida completo do modelo de ML ajuda a reduzir o tempo do projeto e garante melhor qualidade do modelo e implantações mais rápidas e frequentes na produção.
Ao desenvolver uma arquitetura MLOps padronizada que foi adotada por diferentes negócios em toda a empresa, nós da Cepsa conseguimos acelerar a inicialização do projeto de ML e melhorar a qualidade do modelo de ML, fornecendo uma estrutura confiável e automatizada sobre a qual nossas equipes de ciência de dados podem inovar mais rapidamente .
Para obter mais informações sobre MLOps no SageMaker, visite Amazon SageMaker para MLOps e confira outros casos de uso de clientes no Blog do AWS Machine Learning.
Sobre os autores
 Guilhermo Ribeiro Jiménez é um cientista de dados sênior na Cepsa com doutorado. em Física Nuclear. Ele tem 6 anos de experiência com projetos de ciência de dados, principalmente na indústria de telecomunicações e energia. Atualmente lidera equipes de cientistas de dados no departamento de Transformação Digital da Cepsa, com foco no dimensionamento e produção de projetos de aprendizado de máquina.
Guilhermo Ribeiro Jiménez é um cientista de dados sênior na Cepsa com doutorado. em Física Nuclear. Ele tem 6 anos de experiência com projetos de ciência de dados, principalmente na indústria de telecomunicações e energia. Atualmente lidera equipes de cientistas de dados no departamento de Transformação Digital da Cepsa, com foco no dimensionamento e produção de projetos de aprendizado de máquina.
 Guillermo Menéndez Curral é arquiteto de soluções na AWS Energy and Utilities. Ele tem mais de 15 anos de experiência projetando e construindo aplicativos SW e atualmente fornece orientação arquitetônica para clientes da AWS no setor de energia, com foco em análise e aprendizado de máquina.
Guillermo Menéndez Curral é arquiteto de soluções na AWS Energy and Utilities. Ele tem mais de 15 anos de experiência projetando e construindo aplicativos SW e atualmente fornece orientação arquitetônica para clientes da AWS no setor de energia, com foco em análise e aprendizado de máquina.
- Coinsmart. A melhor troca de Bitcoin e criptografia da Europa.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. ACESSO LIVRE.
- CryptoHawk. Radar Altcoin. Teste grátis.
- Fonte: https://aws.amazon.com/blogs/machine-learning/how-cepsa-used-amazon-sagemaker-and-aws-step-functions-to-industrialize-their-ml-projects-and-operate- seus modelos em escala/
- "
- 000
- 100
- 15 anos
- a
- habilidade
- Sobre
- Acesso
- Conta
- Alcançar
- em
- Ad
- adicionado
- Vantagem
- contra
- algoritmo
- algoritmos
- Todos os Produtos
- permite
- já
- Amazon
- entre
- analítica
- analisar
- qualquer lugar
- api
- APIs
- aplicações
- aplicado
- abordagem
- aprovar
- arquitetônico
- arquitetura
- por aí
- associado
- automatizar
- Automatizado
- Automático
- automaticamente
- automatizando
- Automação
- disponível
- AWS
- Porque
- tornando-se
- antes
- ser
- abaixo
- MELHOR
- Blog
- construir
- Prédio
- Constrói
- negócio
- negócios
- casas
- casos
- centralizada
- certo
- desafiar
- desafios
- químico
- Na nuvem
- código
- commit
- comum
- Empresa
- completar
- completamente
- integrações
- componente
- componentes
- Computar
- concentração
- Contato
- consumir
- consumidor
- consumo
- Recipiente
- Containers
- custos
- poderia
- cobrir
- crio
- cria
- criação
- Atualmente
- personalizadas
- cliente
- Clientes
- dados,
- ciência de dados
- cientista de dados
- decidido
- decisões
- Dependendo
- depende
- implantar
- implantado
- desenvolvimento
- Implantações
- projetado
- concepção
- detalhado
- detectou
- Detecção
- Determinar
- desenvolvedores
- em desenvolvimento
- diferente
- digital
- Transformação Digital
- diretamente
- discutir
- dragão
- cada
- facilmente
- eficiência
- eficiente
- emergente
- permite
- Ponto final
- energia
- Motor
- Engenheiros
- Meio Ambiente
- equipamento
- estimado
- Evento
- evolução
- exatamente
- exemplo
- esperar
- vasta experiência
- experimentar
- exploração
- enfrentando
- RÁPIDO
- mais rápido
- Característica
- destaque
- Finalmente
- Primeiro nome
- Flexibilidade
- flexível
- Foco
- seguinte
- Quadro
- da
- cheio
- funções
- futuro
- Portões
- Geral
- Git
- GitHub
- Global
- meta
- manipular
- ter
- ajudar
- ajuda
- altamente
- histórico
- detém
- hospedado
- hospedagem
- Como funciona o dobrador de carta de canal
- HTTPS
- Centenas
- imagens
- implementação
- implementado
- melhorar
- melhoria
- melhorar
- Em outra
- incluir
- Crescimento
- de treinadores em Entrevista Motivacional
- independentemente
- industrial
- indústria
- INFORMAÇÕES
- informado
- Infraestrutura
- Inovação
- entrada
- integrado
- interativo
- introduzindo
- isolamento
- questões
- IT
- Guarda
- manutenção
- Chave
- de lançamento
- principal
- aprendizagem
- Biblioteca
- linhas
- localização
- procurando
- máquina
- aprendizado de máquina
- moldadas
- a manter
- manutenção
- fazer
- FAZ
- gerencia
- gerenciados
- gestão
- maneira
- manual
- manualmente
- significa
- Métrica
- ML
- modelo
- modelos
- Monitore
- monitoração
- mais
- a maioria
- múltiplo
- Cria
- operar
- operação
- otimização
- Opções
- ordem
- organização
- Outros
- próprio
- proprietários
- Passagem
- atuação
- realização
- fase
- Física
- pontos
- predizer
- problemas
- processo
- processos
- produtor
- Produção
- projeto
- projetos
- fornecido
- fornece
- fornecendo
- publicar
- propósito
- fins
- empurrado
- qualidade
- em tempo real
- reduzir
- cadastre-se
- registrado
- confiável
- repositório
- requeridos
- Requisitos
- resposta
- responsabilidades
- DESCANSO
- resultando
- Resultados
- Execute
- corrida
- Escala
- dimensionamento
- Ciência
- Cientista
- cientistas
- seguro
- Série
- Serverless
- serviço
- Serviços
- conjunto
- Xangai
- Partilhar
- assistência técnica de curto e longo prazo
- simples
- simulação
- solteiro
- situação
- SIX
- So
- solução
- Soluções
- alguns
- algo
- específico
- velocidade
- Estágio
- padrão
- começado
- armazenamento
- loja
- simplificar
- entraram com sucesso
- .
- Target
- Profissionais
- equipes
- Telco
- teste
- ensaio
- A
- A fonte
- assim sendo
- completamente
- limiar
- Através da
- tempo
- vezes
- para
- Rastreabilidade
- pista
- Rastreamento
- Training
- Transformação
- transformações
- transição
- para
- us
- usar
- geralmente
- utilitários
- valor
- versão
- bem definido
- enquanto
- sem
- Atividades:
- fluxos de trabalho
- trabalhar
- mundo
- escrita
- ano
- anos
- Produção