Esta postagem fornece orientação sobre como criar soluções analíticas escaláveis para casos de uso da indústria de jogos usando Sem servidor Amazon Redshift. Ele aborda como usar uma arquitetura conceitual e lógica para alguns dos casos de uso mais populares da indústria de jogos, como análise de eventos, recomendações de compra no jogo, medição da satisfação do jogador, análise de dados de telemetria e muito mais. Esta postagem também discute a arte do possível com inovações mais recentes nos serviços da AWS em relação a streaming, aprendizado de máquina (ML), compartilhamento de dados e recursos sem servidor.
Nossos clientes de jogos nos dizem que seus principais objetivos de negócios incluem o seguinte:
- Maior receita de compras no aplicativo
- Alta receita média por usuário e valor vitalício
- Aderência aprimorada com melhor experiência de jogo
- Maior produtividade do evento e alto ROI
Nossos clientes de jogos também nos dizem que, ao criar soluções de análise, eles desejam o seguinte:
- Modelo de código baixo ou sem código – Soluções prontas para uso são preferidas à criação de soluções personalizadas.
- Desacoplado e escalável – Serviços sem servidor, dimensionados automaticamente e totalmente gerenciados são preferidos em relação aos serviços gerenciados manualmente. Cada serviço deve ser facilmente substituível, aprimorado com pouca ou nenhuma dependência. As soluções devem ser flexíveis para escalar para cima e para baixo.
- Portabilidade para vários canais – As soluções devem ser compatíveis com a maioria dos canais de endpoint, como PC, dispositivos móveis e plataformas de jogos.
- Flexível e fácil de usar – As soluções devem fornecer dados menos restritivos, de fácil acesso e prontos para uso. Eles também devem fornecer desempenho ideal com ajuste baixo ou nenhum.
Arquitetura de referência analítica para organizações de jogos
Nesta seção, discutimos como as organizações de jogos podem usar uma arquitetura de hub de dados para atender às necessidades analíticas de uma empresa, que requer os mesmos dados em vários níveis de granularidade e formatos diferentes e é padronizado para consumo mais rápido. A hub de dados é um centro de troca de dados que constitui um hub de repositórios de dados e é apoiado por serviços de engenharia de dados, governança de dados, segurança e monitoramento.
Um hub de dados contém dados em vários níveis de granularidade e geralmente não é integrado. Diferencia-se de um data lake por oferecer dados pré-validados e padronizados, permitindo um consumo mais simples pelos usuários. Data hubs e data lakes podem coexistir em uma organização, complementando-se mutuamente. Os hubs de dados estão mais focados em permitir que as empresas consumam dados padronizados de maneira rápida e fácil. Os data lakes são mais focados em armazenar e manter todos os dados de uma organização em um só lugar. E, ao contrário dos armazéns de dados, que são principalmente armazenamentos analíticos, um hub de dados é uma combinação de todos os tipos de repositórios — analíticos, transacionais, operacionais, de referência e serviços de E/S de dados, juntamente com processos de governança. Um data warehouse é um dos componentes de um hub de dados.
O diagrama a seguir é uma arquitetura de referência de hub de dados de análise conceitual. Essa arquitetura se assemelha a uma abordagem hub-and-spoke. Os repositórios de dados representam o hub. Processos externos são os raios que alimentam dados de e para o hub. Essa arquitetura de referência combina parcialmente um hub de dados e um data lake para permitir serviços de análise abrangentes.
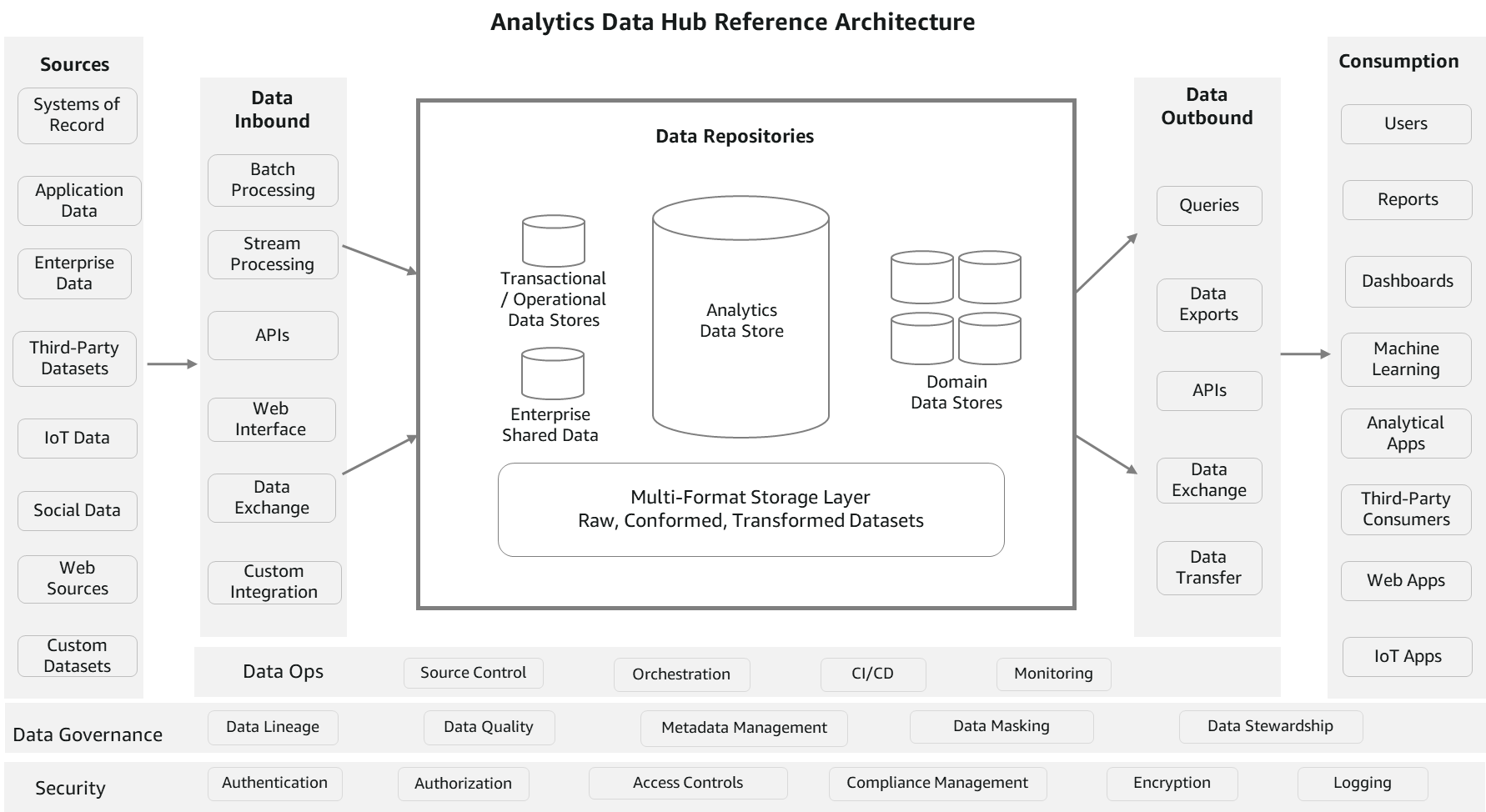
Vejamos os componentes da arquitetura com mais detalhes.
Fontes
Os dados podem ser carregados de várias fontes, como sistemas de registro, dados gerados de aplicativos, armazenamentos de dados operacionais, dados e metadados de referência em toda a empresa, dados de fornecedores e parceiros, dados gerados por máquina, fontes sociais e fontes da web. Os dados de origem geralmente estão em formatos estruturados ou semiestruturados, que são altamente e pouco formatados, respectivamente.
entrada de dados
Esta seção consiste em componentes para processar e carregar os dados de várias fontes em repositórios de dados. Pode ser em modo batch, contínuo, pub/sub ou qualquer outro
integração personalizada. Tecnologias ETL (extrair, transformar e carregar), serviços de streaming, APIs e interfaces de troca de dados são os principais componentes desse pilar. Ao contrário dos processos de ingestão, os dados podem ser transformados de acordo com as regras de negócios antes do carregamento. Você pode aplicar regras de qualidade de dados técnicos ou comerciais e também carregar dados brutos. Essencialmente, ele fornece a flexibilidade de colocar os dados em repositórios em sua forma mais utilizável.
Repositórios de dados
Esta seção consiste em um grupo de armazenamentos de dados, que inclui armazéns de dados, armazenamentos de dados transacionais ou operacionais, armazenamentos de dados de referência, armazenamentos de dados de domínio que abrigam exibições de negócios criadas especificamente e conjuntos de dados corporativos (armazenamento de arquivos). O componente de armazenamento de arquivos geralmente é um componente comum entre um hub de dados e um data lake para evitar a duplicação de dados e fornecer abrangência. Os dados também podem ser compartilhados entre todos esses repositórios sem movimentação física com recursos, como compartilhamento de dados e consultas federadas. No entanto, a cópia e duplicação de dados são permitidas considerando várias necessidades de consumo em termos de formatos e latência.
Saída de dados
Os dados geralmente são consumidos usando consultas estruturadas para necessidades analíticas. Além disso, os conjuntos de dados são acessados para ML, exportação de dados e necessidades de publicação. Esta seção consiste em componentes para consultar os dados, exportar, trocar e APIs. Em termos de implementação, as mesmas tecnologias podem ser utilizadas tanto para o inbound quanto para o outbound, mas as funções são diferentes. No entanto, não é obrigatório usar as mesmas tecnologias. Esses processos não exigem muita transformação porque os dados já estão padronizados e quase prontos para serem consumidos. O foco está na facilidade de consumo e na integração com os serviços consumidores.
Consumo
Este pilar consiste em vários canais de consumo para as necessidades analíticas da empresa. Inclui usuários de inteligência de negócios (BI), relatórios prontos e interativos, painéis, cargas de trabalho de ciência de dados, Internet das Coisas (IoT), aplicativos da Web e consumidores de dados de terceiros. Entidades de consumo populares em muitas organizações são consultas, relatórios e cargas de trabalho de ciência de dados. Como existem vários armazenamentos de dados mantendo dados em diferentes granularidades e formatos para atender às necessidades do consumidor, esses componentes de consumo dependem de catálogos de dados para encontrar a fonte certa.
Gestão de dados
A governança de dados é a chave para o sucesso de uma arquitetura de referência de hub de dados. Constitui componentes como gerenciamento de metadados, qualidade de dados, linhagem, mascaramento e administração, que são necessários para a manutenção organizada do hub de dados. O gerenciamento de metadados ajuda a organizar o catálogo de metadados técnicos e comerciais, e os consumidores podem fazer referência a esse catálogo para saber quais dados estão disponíveis em qual repositório e em qual granularidade, formato, proprietários, frequência de atualização e assim por diante. Juntamente com o gerenciamento de metadados, a qualidade dos dados é importante para aumentar a confiança dos consumidores. Isso inclui limpeza de dados, validação, conformidade e controles de dados.
Segurança e monitoramento
O acesso de usuários e aplicativos deve ser controlado em vários níveis. Começa com autenticação, autorizando quem e o que deve ser acessado, gerenciamento de políticas, criptografia e aplicação de regras de conformidade de dados. Ele também inclui componentes de monitoramento para registrar a atividade para auditoria e análise.
Arquitetura de solução de hub de dados analíticos na AWS
A arquitetura de referência a seguir fornece uma pilha da AWS para os componentes da solução.
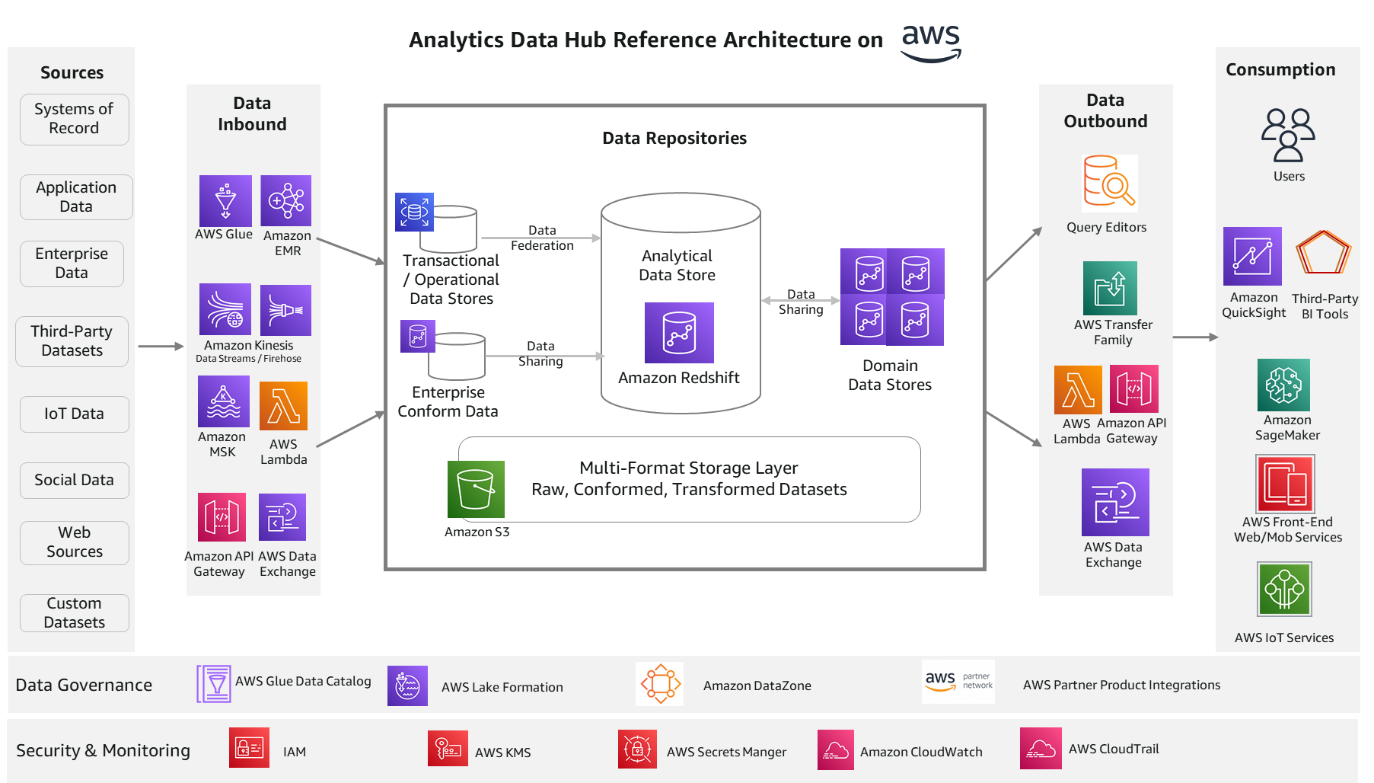
Vamos examinar cada componente novamente e os serviços relevantes da AWS.
Serviços de entrada de dados
Cola AWS e Amazon EMR serviços são ideais para processamento em lote. Eles escalam automaticamente e são capazes de processar a maioria dos formatos de dados padrão do setor. Fluxos de dados do Amazon Kinesis, Mangueira de incêndio de dados do Amazon Kinesis e Amazon Managed Streaming para Apache Kafka (Amazon MSK) permite que você crie aplicativos de processo de streaming. Esses serviços de streaming se integram bem com o Streaming do Amazon Redshift recurso. Isso ajuda você a processar fontes em tempo real, dados de IoT e dados de canais online. Você também pode ingerir dados com ferramentas de terceiros, como Informatica, dbt e Matallion.
Você pode criar APIs RESTful e APIs WebSocket usando Gateway de API da Amazon e AWS Lambda, que permitirá a comunicação bidirecional em tempo real com fontes da web, sociais e IoT. Troca de dados da AWS ajuda na assinatura de dados de terceiros no AWS Marketplace. A subscrição e o acesso aos dados são totalmente geridos com este serviço. Consulte a respectiva documentação de serviço para obter mais detalhes.
Serviços de repositório de dados
Amazon RedShift é o serviço de armazenamento de dados recomendado para cargas de trabalho OLAP (Online Analytical Processing), como data warehouses em nuvem, data marts e outros armazenamentos de dados analíticos. Esse serviço é o núcleo dessa arquitetura de referência na AWS e pode atender à maioria das necessidades analíticas prontas para uso. Você pode usar SQL simples para analisar dados estruturados e semiestruturados em data warehouses, data marts, bancos de dados operacionais e data lakes para oferecer o melhor desempenho de preço em qualquer escala. O Compartilhamento de dados do Amazon Redshift O recurso fornece acesso instantâneo, granular e de alto desempenho sem cópias e movimentação de dados em vários data warehouses do Amazon Redshift na mesma ou em diferentes contas da AWS e entre regiões.
Para facilitar o uso, o Amazon Redshift oferece uma opção sem servidor. Sem servidor Amazon Redshift provisiona automaticamente e dimensiona de forma inteligente a capacidade do data warehouse para fornecer desempenho rápido até mesmo para as cargas de trabalho mais exigentes e imprevisíveis, e você paga apenas pelo que usa. Basta carregar seus dados e começar a consultar imediatamente no Amazon Redshift Query Editor ou em sua ferramenta de BI favorita e continuar aproveitando o melhor desempenho de preço e os recursos familiares de SQL em um ambiente de administração zero e fácil de usar.
Serviço de banco de dados relacional da Amazon (Amazon RDS) é um serviço totalmente gerenciado para criar armazenamentos de dados transacionais e operacionais. Você pode escolher entre muitos mecanismos populares, como MySQL, PostgreSQL, MariaDB, Oracle e SQL Server. Com o Amazon Redshift consulta federada recurso, você pode consultar dados transacionais e operacionais no local sem mover os dados. O recurso de consulta federada suporta atualmente Amazon RDS para PostgreSQL, Edição compatível com Amazon Aurora PostgreSQL, Amazon RDS para MySQL e Edição compatível com o Amazon Aurora MySQL.
Serviço de armazenamento simples da Amazon (Amazon S3) é o serviço recomendado para camadas de armazenamento multiformato na arquitetura. Ele oferece escalabilidade, disponibilidade de dados, segurança e desempenho líderes do setor. As organizações geralmente armazenam dados no Amazon S3 usando formatos de arquivo abertos. Os formatos de arquivo abertos permitem a análise dos mesmos dados do Amazon S3 usando vários componentes da camada de processamento e consumo. Os dados no Amazon S3 podem ser facilmente consultados no local usando SQL com Espectro Amazon Redshift. Ele ajuda você a consultar e recuperar dados estruturados e semiestruturados de arquivos no Amazon S3 sem precisar carregar os dados. Vários data warehouses do Amazon Redshift podem consultar simultaneamente os mesmos conjuntos de dados no Amazon S3 sem a necessidade de fazer cópias dos dados para cada data warehouse.
Serviços de saída de dados
O Amazon Redshift vem com o workbench de análise baseado na web Editor de consultas V2.0, que ajuda você a executar consultas, explorar dados, criar notebooks SQL e colaborar em dados com suas equipes no SQL por meio de uma interface comum. Família AWS Transfer ajuda a transferir arquivos com segurança usando os protocolos SFTP, FTPS, FTP e AS2. Ele oferece suporte a milhares de usuários simultâneos e é um serviço de baixo código totalmente gerenciado. Semelhante aos processos de entrada, você pode utilizar Gateway de API da Amazon e AWS Lambda para extração de dados usando o API de dados Amazon Redshift. E Troca de dados da AWS ajuda a publicar seus dados para terceiros para consumo por meio do AWS Marketplace.
serviços de consumo
AmazonQuickSight é o serviço recomendado para criar relatórios e painéis. Ele permite que você crie painéis interativos, visualizações e análises avançadas com insights de ML. Amazon Sage Maker é a plataforma ML para todas as suas necessidades de carga de trabalho de ciência de dados. Ele ajuda você a criar, treinar e implantar modelos que consomem os dados de repositórios no hub de dados. Você pode usar Amazon front-end web e móvel serviços e AWS IoT serviços para criar aplicativos de endpoint da web, móveis e IoT para consumir dados fora do hub de dados.
Serviços de governança de dados
A Catálogo de dados do AWS Glue e Formação AWS Lake são os principais serviços de governança de dados que a AWS oferece atualmente. Esses serviços ajudam a gerenciar metadados centralmente para todos os repositórios de dados e gerenciar controles de acesso. Eles também ajudam na classificação de dados e podem lidar automaticamente com alterações de esquema. Você pode usar Zona de dados da Amazon para descobrir e compartilhar dados em escala através dos limites organizacionais com governança integrada e controles de acesso. A AWS está investindo neste espaço para fornecer uma experiência mais unificada para os serviços da AWS. Existem muitos produtos de parceiros, como Collibra, Alation, Amorphic, Informatica e outros, que você também pode usar para funções de governança de dados com os serviços da AWS.
Serviços de segurança e monitoramento
Gerenciamento de acesso e identidade da AWS (AWS IAM) gerencia identidades para serviços e recursos da AWS. Você pode definir usuários, grupos, funções e políticas para gerenciamento de acesso refinado de sua força de trabalho e cargas de trabalho. Serviço de gerenciamento de chaves AWS (AWS KMS) gerencia chaves AWS ou chaves gerenciadas pelo cliente para seus aplicativos. Amazon CloudWatch e AWS CloudTrail ajudam a fornecer recursos de monitoramento e auditoria. Você pode coletar métricas e eventos e analisá-los para eficiência operacional.
Nesta postagem, discutimos os serviços AWS mais comuns para os respectivos componentes da solução. No entanto, você não está limitado apenas a esses serviços. Existem muitos outros serviços da AWS para casos de uso específicos que podem ser mais apropriados para suas necessidades do que discutimos aqui. Você pode entrar em contato com os arquitetos de soluções do AWS Analytics para obter orientação adequada.
Arquiteturas de exemplo para casos de uso de jogos
Nesta seção, discutimos arquiteturas de exemplo para dois casos de uso de jogos.
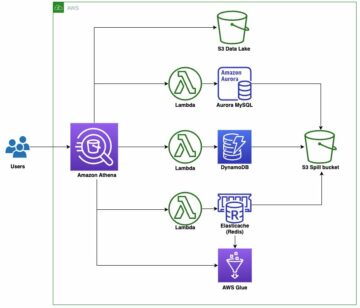
Análise de eventos do jogo
Os eventos no jogo (também chamados de eventos cronometrados ou ao vivo) incentivam o envolvimento do jogador por meio da empolgação e da expectativa. Os eventos incentivam os jogadores a interagir com o jogo, aumentando a satisfação do jogador e a receita com as compras no jogo. Os eventos tornaram-se cada vez mais importantes, especialmente à medida que os jogos deixam de ser peças estáticas de entretenimento para serem jogados, passando a oferecer conteúdo dinâmico e variável por meio do uso de serviços que usam informações para tomar decisões sobre o jogo enquanto o jogo está sendo jogado. Isso permite que os jogos mudem conforme os jogadores jogam e influenciem o que funciona e o que não funciona, e dá a qualquer jogo uma vida útil potencialmente infinita.
Essa capacidade dos eventos do jogo de oferecer novos conteúdos e atividades dentro de uma estrutura familiar é como você mantém os jogadores envolvidos e jogando por meses a anos. Os jogadores podem desfrutar de novas experiências e desafios dentro da estrutura ou mundo familiar que eles aprenderam a amar.
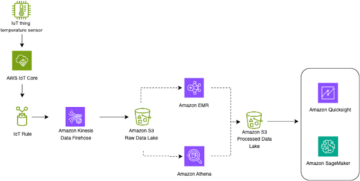
O exemplo a seguir mostra como essa arquitetura pode aparecer, incluindo alterações para oferecer suporte a várias seções do processo, como dividir os dados em contêineres separados para acomodar escalabilidade, estorno e propriedade.
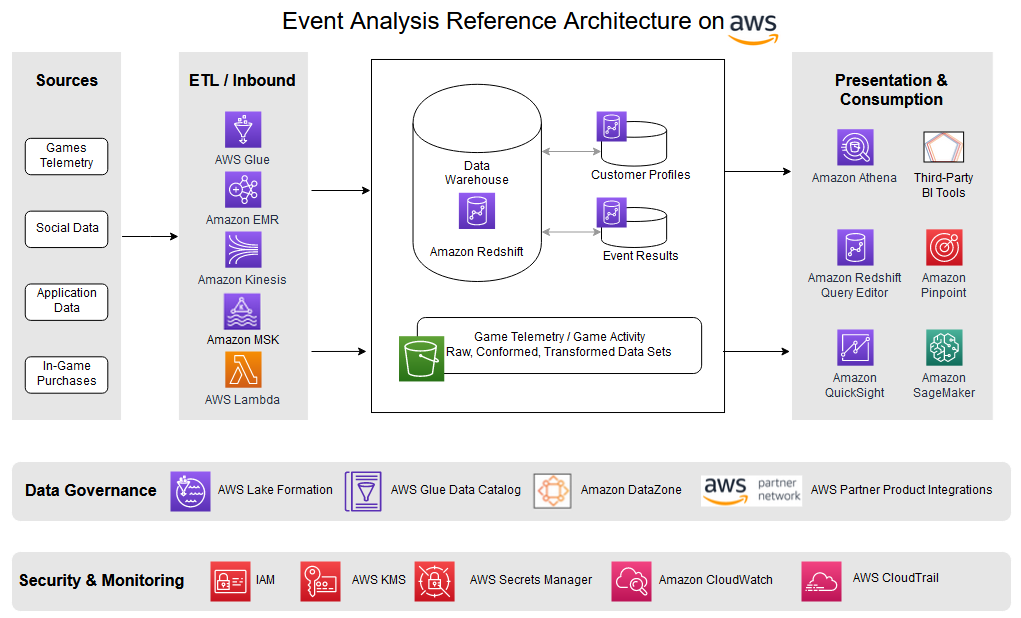
Para entender completamente como os eventos são vistos pelos jogadores e tomar decisões sobre eventos futuros, é necessário obter informações sobre como o último evento foi realmente realizado. Isso significa coletar muitos dados enquanto os jogadores jogam para criar indicadores-chave de desempenho (KPIs) que medem a eficácia e a satisfação do jogador com cada evento. Isso requer análises que medem especificamente cada evento e capturam, analisam, relatam e medem a experiência do jogador para cada evento. Esses KPIs incluem o seguinte:
- Interações iniciais do fluxo do usuário – Quais ações os usuários estão realizando após receberem ou baixarem uma atualização de evento em um jogo. Existem pontos de desistência claros ou gargalos que estão afastando as pessoas do evento?
- Monetização – Quando, o quê e onde os usuários estão gastando dinheiro no evento, seja comprando moedas do jogo, respondendo a anúncios, promoções e assim por diante.
- economia do jogo – Como os usuários podem ganhar e gastar moedas ou bens virtuais durante um evento, usando dinheiro do jogo, trocas ou escambo.
- Atividade no jogo – Vitórias do jogador, derrotas, aumento de nível, vitórias em competições ou conquistas do jogador dentro do evento.
- Interações de usuário para usuário – Convites, brindes, chats (privados e em grupo), desafios, etc. durante um evento.
Esses são apenas alguns dos KPIs e métricas essenciais para a modelagem preditiva de eventos à medida que o jogo adquire novos jogadores, mantendo os usuários existentes envolvidos, engajados e jogando.
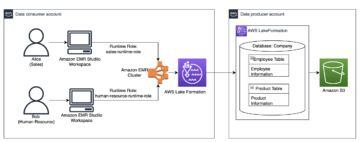
Análise de atividade no jogo
A análise de atividade no jogo analisa essencialmente qualquer atividade significativa e intencional que o jogador possa mostrar, com o objetivo de tentar entender quais ações são tomadas, seu tempo e resultados. Isso inclui informações situacionais sobre os jogadores, incluindo onde eles estão jogando (tanto geográfico quanto cultural), com que frequência, por quanto tempo, o que eles realizam em cada login e outras atividades.
O exemplo a seguir mostra como essa arquitetura pode aparecer, incluindo alterações para dar suporte a várias seções do processo, como dividir os dados em armazéns separados. A abordagem de warehouse multicluster ajuda a dimensionar a carga de trabalho de forma independente, oferece flexibilidade ao modelo de estorno implementado e oferece suporte à propriedade de dados descentralizada.

A solução basicamente registra informações para ajudar a entender o comportamento de seus jogadores, o que pode levar a insights que aumentam a retenção de jogadores existentes e a aquisição de novos. Isso pode fornecer a capacidade de fazer o seguinte:
- Forneça recomendações de compra no jogo
- Medir as tendências dos jogadores a curto prazo e ao longo do tempo
- Planeje eventos nos quais os jogadores se envolverão
- Entenda quais partes do seu jogo são mais bem-sucedidas e quais são menos
Você pode usar esse conhecimento para tomar decisões sobre futuras atualizações do jogo, fazer recomendações de compra no jogo, determinar quando e como a economia do jogo pode precisar ser equilibrada e até mesmo permitir que os jogadores mudem de personagem ou joguem conforme o jogo progride injetando isso informações e decisões que as acompanham de volta ao jogo.
Conclusão
Essa arquitetura de referência, embora mostre exemplos de apenas alguns tipos de análise, fornece um caminho tecnológico mais rápido para habilitar aplicativos de análise de jogos. A abordagem hub/spoke desacoplada traz agilidade e flexibilidade para implementar diferentes abordagens para análise e compreensão do desempenho de aplicativos de jogos. Os serviços específicos da AWS descritos nesta arquitetura fornecem recursos abrangentes para coletar, armazenar, medir, analisar e relatar métricas de jogos e eventos com facilidade. Isso ajuda você a realizar análises no jogo com eficiência, análise de eventos, medir a satisfação do jogador e fornecer recomendações personalizadas para os jogadores, organizar eventos com eficiência e aumentar as taxas de retenção.
Obrigado por ler o post. Se você tiver quaisquer comentários ou perguntas, por favor, deixe-os nos comentários.
Sobre os autores
 Satesh Sonti é um arquiteto de soluções especialista em análise sênior com sede em Atlanta, especializado na construção de plataformas de dados corporativos, armazenamento de dados e soluções de análise. Ele tem mais de 16 anos de experiência na construção de ativos de dados e na liderança de programas complexos de plataforma de dados para clientes bancários e de seguros em todo o mundo.
Satesh Sonti é um arquiteto de soluções especialista em análise sênior com sede em Atlanta, especializado na construção de plataformas de dados corporativos, armazenamento de dados e soluções de análise. Ele tem mais de 16 anos de experiência na construção de ativos de dados e na liderança de programas complexos de plataforma de dados para clientes bancários e de seguros em todo o mundo.
 Tânia Rodes é um Arquiteto de Soluções Sênior baseado em San Francisco, focado em clientes de jogos com ênfase em análise, dimensionamento e aprimoramento de desempenho de jogos e sistemas de suporte. Ela tem mais de 25 anos de experiência em arquitetura corporativa e de soluções, especializada em grandes organizações empresariais em várias linhas de negócios, incluindo jogos, bancos, saúde, ensino superior e governos estaduais.
Tânia Rodes é um Arquiteto de Soluções Sênior baseado em San Francisco, focado em clientes de jogos com ênfase em análise, dimensionamento e aprimoramento de desempenho de jogos e sistemas de suporte. Ela tem mais de 25 anos de experiência em arquitetura corporativa e de soluções, especializada em grandes organizações empresariais em várias linhas de negócios, incluindo jogos, bancos, saúde, ensino superior e governos estaduais.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/how-gaming-companies-can-use-amazon-redshift-serverless-to-build-scalable-analytical-applications-faster-and-easier/
- :é
- $UP
- 100
- a
- habilidade
- Capaz
- Sobre
- Acesso
- gerenciamento de acesso
- acessadas
- acomodar
- Contas
- realizações
- Adquire
- aquisição
- em
- ações
- atividades
- atividade
- endereço
- administração
- anúncios
- avançado
- Depois de
- Todos os Produtos
- Permitindo
- já
- Amazon
- Amazon RDS
- entre
- análise
- Análises
- analítica
- analisar
- e
- antecipação
- apache
- api
- APIs
- aparecer
- Aplicação
- aplicações
- Aplicar
- Aplicando
- abordagem
- se aproxima
- apropriado
- Aplicativos
- arquitetura
- SOMOS
- por aí
- Arte
- AS
- Ativos
- At
- Atlanta
- auditoria
- aurora
- Autenticação
- auto
- automaticamente
- disponibilidade
- disponível
- média
- evitar
- AWS
- Mercado da AWS
- em caminho duplo
- Bancário
- baseado
- BE
- Porque
- tornam-se
- antes
- ser
- MELHOR
- Melhor
- entre
- gargalos
- limites
- Caixa
- Quebra
- Traz
- construir
- Prédio
- construídas em
- negócio
- inteligência de negócios
- negócios
- Comprar
- by
- chamado
- CAN
- capacidades
- Capacidade
- capturar
- casos
- catálogo
- catálogos
- Centralização de
- desafios
- alterar
- Alterações
- mudança
- canais
- personagem
- Escolha
- classificação
- remover filtragem
- clientes
- Na nuvem
- colaborar
- coletar
- combinação
- combina
- comentários
- comum
- Comunicação
- Empresas
- compatível
- competição
- integrações
- compliance
- componente
- componentes
- compreensivo
- conceptual
- concorrente
- confiança
- considerando
- consumir
- consumida
- consumidor
- Consumidores
- consumo
- Containers
- contém
- conteúdo
- continuar
- contínuo
- controlado
- controles
- núcleo
- cobre
- crio
- Criar
- cultural
- moedas
- Atualmente
- cliente
- Clientes
- personalizado
- dados,
- análise de dados
- Data Exchange
- lago data
- Plataforma de dados
- qualidade de dados
- ciência de dados
- compartilhamento de dados
- armazenamento de dados
- data warehouse
- armazéns de dados
- banco de dados
- bases de dados
- conjuntos de dados
- Descentralizada
- decisões
- entregar
- exigente
- Dependência
- implantar
- descrito
- detalhe
- detalhes
- Determinar
- diferente
- descobrir
- discutir
- discutido
- documentação
- Não faz
- domínio
- down
- download
- durante
- dinâmico
- cada
- ganhar
- facilidade de utilização
- mais fácil
- facilmente
- fácil
- fácil de usar
- economia
- editor
- Educação
- eficácia
- eficiência
- eficientemente
- ou
- ênfase
- permitir
- permite
- permitindo
- encorajar
- criptografia
- Ponto final
- engajar
- contratado
- COMPROMETIMENTO
- Engenharia
- Motores
- aprimorada
- desfrutar
- Empreendimento
- Entretenimento
- entidades
- Meio Ambiente
- especialmente
- essencialmente
- Éter (ETH)
- Mesmo
- Evento
- eventos
- exemplo
- exemplos
- exchange
- Excitação
- existente
- vasta experiência
- Experiências
- explorar
- exportar
- externo
- extrato
- familiar
- RÁPIDO
- mais rápido
- Favorito
- Característica
- Funcionalidades
- retornos
- alimentação
- poucos
- Envie o
- Arquivos
- descoberta
- Primeiro nome
- Flexibilidade
- flexível
- fluxo
- Foco
- focado
- seguinte
- Escolha
- Para os consumidores
- formulário
- formato
- Quadro
- Francisco
- Frequência
- recentes
- da
- totalmente
- funções
- mais distante
- futuro
- jogo futuro
- jogo
- Games
- jogos
- Indústria do jogo
- coleta
- gerado
- geográfico
- ter
- dá
- globo
- meta
- bens
- governo
- Governos
- Grupo
- Do grupo
- crescido
- orientações
- manipular
- Ter
- ter
- saúde
- pesado
- ajudar
- ajuda
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- Alta
- alta performance
- superior
- Ensino superior
- altamente
- habitação
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTML
- HTTPS
- Hub
- IAM
- ideal
- identidades
- Dados de identificação:
- executar
- implementação
- implementado
- importante
- in
- in-game
- incluir
- inclui
- Incluindo
- Crescimento
- aumentando
- independentemente
- indicadores
- indústria
- líder da indústria
- influência
- INFORMAÇÕES
- e inovações
- insights
- instantâneos
- com seguro
- integrar
- integrado
- integração
- Inteligência
- interagir
- interativo
- Interface
- interfaces de
- Internet
- internet das coisas
- investir
- envolvido
- iot
- IT
- ESTÁ
- jpg
- Guarda
- manutenção
- Chave
- chaves
- Saber
- lago
- grande
- Latência
- mais recente
- camada
- camadas
- conduzir
- principal
- aprendizagem
- Deixar
- níveis
- tempo de vida
- garantia vitalícia
- como
- Limitado
- linhas
- pequeno
- viver
- Eventos ao vivo
- carregar
- carregamento
- lógico
- longo
- olhar
- OLHARES
- perdas
- lote
- gosta,
- Baixo
- máquina
- aprendizado de máquina
- manutenção
- fazer
- gerencia
- gerenciados
- de grupos
- gestão
- obrigatório
- manualmente
- muitos
- marketplace
- significativo
- significa
- a medida
- medição
- metadados
- Métrica
- poder
- ML
- Móvel Esteira
- Moda
- modelo
- modelagem
- modelos
- dinheiro
- monitoração
- mês
- mais
- a maioria
- Mais populares
- movimento
- em movimento
- múltiplo
- MySQL
- você merece...
- Cria
- Novo
- laptops
- objetivos
- of
- oferecer
- oferecendo treinamento para distância
- Oferece
- on
- ONE
- online
- aberto
- operacional
- ideal
- Opção
- oráculo
- organização
- organizacional
- organizações
- Organizado
- Outros
- proprietários
- propriedade
- partes
- parceiro
- Parceiros
- peças
- caminho
- Pagar
- PC
- Pessoas
- realizar
- atuação
- Fisicamente
- peças
- Pilar
- Lugar
- plataforma
- Plataformas
- platão
- Inteligência de Dados Platão
- PlatãoData
- Jogar
- desempenhado
- jogador
- players
- jogar
- por favor
- pontos
- políticas
- Privacidade
- Popular
- possível
- Publique
- Postgresql
- potencialmente
- preferido
- preço
- principalmente
- privado
- processo
- processos
- em processamento
- produtividade
- Produtos
- Programas
- protocolos
- fornecer
- fornece
- publicar
- Publishing
- compra
- compras
- qualidade
- Frequentes
- rapidamente
- Preços
- Cru
- dados não tratados
- alcançar
- Leitura
- pronto
- em tempo real
- receber
- recomendações
- Recomenda
- registro
- regiões
- relevante
- Denunciar
- Relatórios
- repositório
- representar
- requeridos
- exige
- se assemelha
- Recursos
- aqueles
- Restritivo
- retenção
- receita
- papéis
- regras
- Execute
- mesmo
- San
- San Francisco
- satisfação
- AMPLIAR
- escalável
- Escala
- Escalas
- dimensionamento
- Ciência
- Seção
- seções
- firmemente
- segurança
- senior
- separado
- Serverless
- serviço
- Serviços
- Partilhar
- compartilhado
- compartilhando
- mudança
- Baixo
- rede de apoio social
- mostrar
- Shows
- semelhante
- simples
- So
- Redes Sociais
- solução
- Soluções
- alguns
- fonte
- Fontes
- Espaço
- especialista
- especializado
- especializando
- específico
- especificamente
- gastar
- Passar
- gastando dinheiro
- SQL
- pilha
- padrão
- começo
- começa
- Estado
- Stewardship
- armazenamento
- loja
- lojas
- de streaming
- Serviços de transmissão
- estruturada
- tudo incluso
- sucesso
- bem sucedido
- tal
- ajuda
- Suportado
- Apoiar
- suportes
- sistemas
- tomar
- equipes
- Dados Técnicos:
- Tecnologias
- Equipar
- condições
- que
- A
- o hub
- A fonte
- deles
- Eles
- Este
- coisas
- Terceiro
- terceiro
- De terceiros
- milhares
- Através da
- Cronometrado
- cronometragem
- para
- ferramenta
- ferramentas
- trades
- Trem
- transacional
- transferência
- Transformar
- Transformação
- transformado
- Tendências
- Passando
- tipos
- tipicamente
- compreender
- compreensão
- unificado
- imprevisível
- Atualizar
- Atualizações
- us
- usar
- Utilizador
- usuários
- geralmente
- utilizar
- validação
- vário
- fornecedores
- visualizações
- Virtual
- moedas virtuais
- Armazém
- Armazenagem
- web
- Web-Based
- soquete da web
- BEM
- O Quê
- se
- qual
- enquanto
- QUEM
- precisarão
- Vitórias
- de
- dentro
- sem
- Força de trabalho
- trabalho
- mundo
- anos
- investimentos
- zefirnet
- zero