Novo Nordisk é uma empresa farmacêutica líder global, responsável pela produção de medicamentos que salvam vidas e atendem a mais de 34 milhões de pacientes por dia. Eles fazem isso de acordo com sua linha de base tripla - que devem se esforçar para serem ambientalmente sustentáveis, socialmente sustentáveis e financeiramente sustentáveis. A combinação de uso da AWS e dados oferece suporte a todos esses destinos.
Os dados são difundidos em toda a cadeia de valor da Novo Nordisk. Desde pesquisa fundamental, linhas de fabricação, vendas e marketing, ensaios clínicos, farmacovigilância, até aplicativos orientados a dados voltados para o paciente. Portanto, obter a base sobre como os dados são armazenados, protegidos e usados de forma a fornecer o máximo valor é um dos principais impulsionadores de melhores resultados de negócios.
Junto com Serviços Profissionais AWS, estamos construindo uma solução de dados e análises usando uma arquitetura de dados moderna. A colaboração entre a Novo Nordisk e a AWS Professional Services é um compromisso estratégico e de longo prazo, em que desenvolvedores de ambas as organizações trabalham juntos há anos. Os ambientes de dados e análises são construídos com base nos princípios básicos da malha de dados — propriedade de domínio descentralizada de dados, dados como um produto, infraestrutura de dados de autoatendimento e governança computacional federada. Isso permite que os usuários do ambiente trabalhem com os dados da maneira que gera os melhores resultados de negócios. Combinamos isso com elementos de arquiteturas evolutivas que nos permitirão adaptar diferentes funcionalidades à medida que a AWS desenvolve continuamente novos serviços e recursos.
Nesta série de postagens, você aprenderá como a Novo Nordisk e a AWS Professional Services construíram um ecossistema de dados e análises para acelerar a inovação em escala de petabytes:
- Nesta primeira postagem, você aprenderá como o design geral permitiu que os componentes individuais se juntassem de maneira modular. Nós nos aprofundamos em como construímos uma solução de gerenciamento de dados com base na arquitetura de malha de dados.
- O segundo post discute como construímos uma rede de confiança entre os sistemas que compõem toda a solução. Mostramos como usamos arquiteturas orientadas a eventos, juntamente com o uso de controles de acesso baseados em atributos, para garantir que os limites de permissão sejam respeitados em escala.
- Na terceira postagem, mostramos como os usuários finais podem consumir dados de sua ferramenta de escolha, sem comprometer a governança de dados. Isso inclui como configurar o Okta, Formação AWS Lake, e o Microsoft Power BI para habilitar o uso federado baseado em SAML de Amazona atena para uma atividade de business intelligence (BI) empresarial.
Ambiente compatível com produtos farmacêuticos
Como uma indústria farmacêutica, a conformidade GxP é um mandato para a Novo Nordisk. GxP é uma abreviação geral para as diretrizes e regulamentações de qualidade “Boas x Práticas” definidas por reguladores, como Agência Europeia de Medicamentos, Administração de Alimentos e Medicamentos dos EUA e outros. Estas diretrizes são elaboradas para garantir que os medicamentos sejam seguros e eficazes para o uso pretendido. No contexto de um ambiente de dados, a conformidade GxP envolve a implementação de controles de integridade para dados usados na tomada de decisões e processos e é usado para orientar como os processos de gerenciamento de mudanças são implementados para garantir continuamente a conformidade ao longo do tempo.
Como esse ambiente de dados oferece suporte a equipes em toda a organização, cada proprietário de dados individual deve manter a responsabilidade sobre seus dados. As funcionalidades foram pensadas para dar aos proprietários dos dados autonomia e transparência na gestão dos seus dados, permitindo-lhes assumir esta responsabilidade. Isso inclui a capacidade de lidar com dados de informações de identificação pessoal (PII) e outras cargas de trabalho confidenciais. Para fornecer rastreabilidade no ambiente, foram adicionados recursos de auditoria, que descrevemos mais neste post.
Visão geral da solução
A solução completa é um amplo cenário de serviços independentes que trabalham juntos para permitir dados e análises com um modelo descentralizado de governança de dados em escala de petabytes. Esquematicamente, pode ser representado como na figura a seguir.

A arquitetura é dividida em três camadas independentes: gerenciamento de dados, virtualização e consumo. O usuário final fica na camada de consumo e trabalha com a ferramenta de sua escolha. Destina-se a abstrair o máximo de recursos nativos da AWS para primitivas de aplicativos. A camada de consumo é integrada à camada de virtualização, que abstrai o acesso aos dados. O objetivo da camada de virtualização é traduzir entre o consumo de dados e as soluções de gerenciamento de dados. O acesso aos dados é gerido pelo que designamos por soluções de gestão de dados. Discutimos uma de nossas soluções versáteis de gerenciamento de dados mais adiante neste post. Cada camada nesta arquitetura é independente uma da outra e depende apenas de interfaces bem definidas.
Central para esta arquitetura é que o acesso é encapsulado em um Gerenciamento de acesso e identidade da AWS (IAM) sessão de função. A camada de gerenciamento de dados se concentra em fornecer à função IAM as permissões e governança corretas, a camada de virtualização fornece acesso à função e a camada de consumo abstrai o uso das funções nas ferramentas de escolha.
Arquitetura técnica
Cada uma das três camadas na arquitetura geral tem uma responsabilidade distinta, mas nenhuma implementação singular. Pense nelas como classes abstratas. Eles podem ser implementados em classes concretas e, em nosso caso, contam com serviços e recursos fundamentais da AWS. Vamos passar por cada uma das três camadas.
Camada de gerenciamento de dados
A camada de gerenciamento de dados é responsável por fornecer acesso e governança de dados. Conforme ilustrado no diagrama a seguir, uma construção mínima na camada de gerenciamento de dados é a combinação de um Serviço de armazenamento simples da Amazon (Amazon S3) e uma função IAM que dá acesso ao bucket S3. Esta construção pode ser expandida para incluir permissão granular com Lake Formation, auditando com AWS CloudTraile recursos de resposta de segurança de Centro de segurança da AWS. O diagrama a seguir também mostra que uma única solução de gerenciamento de dados não tem extensão singular. Ele pode abranger muitas contas da AWS e ser composto por qualquer número de combinações de funções do IAM.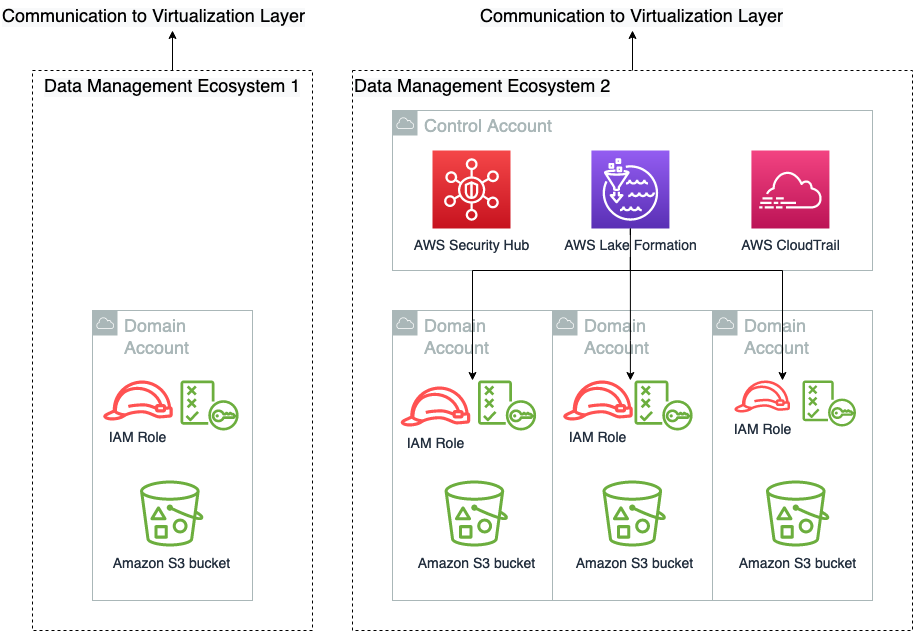
Não ilustramos propositadamente a política de confiança dessas funções nesta figura, porque essas são uma responsabilidade colaborativa entre a camada de virtualização e a camada de gerenciamento de dados. Entramos em detalhes de como isso funciona no próximo post desta série. Os profissionais de engenharia de dados geralmente interagem diretamente com a camada de gerenciamento de dados, onde eles selecionam e preparam os dados para consumo.
Camada de virtualização
O objetivo da camada de virtualização é acompanhar quem pode fazer o quê. Ele não possui recursos em si, mas traduz os requisitos dos ecossistemas de gerenciamento de dados para as camadas de consumo e vice-versa. Ele permite que os usuários finais na camada de consumo acessem e manipulem dados em um ou mais ecossistemas de gerenciamento de dados, de acordo com suas permissões. Essa camada abstrai dos usuários finais os detalhes técnicos sobre acesso a dados, como modelo de permissão, suposições de função e local de armazenamento. Ele possui as interfaces para as outras camadas e impõe a lógica da abstração. No contexto das arquiteturas hexagonais (ver Desenvolvendo arquitetura evolutiva com AWS Lambda), a camada de interface desempenha o papel da lógica de domínio, portas e adaptadores. As outras duas camadas são atores. A camada de gerenciamento de dados comunica o estado da camada para a camada de virtualização e, inversamente, recebe informações sobre o cenário de serviço confiável. A arquitetura da camada de virtualização é mostrada no diagrama a seguir.

Camada de consumo
A camada de consumo é onde estão os usuários finais dos produtos de dados. Podem ser cientistas de dados, analistas de inteligência de negócios ou qualquer terceiro que gere valor a partir do consumo dos dados. É importante para esse tipo de arquitetura que a camada de consumo tenha um fluxo de login baseado em gancho, onde a autorização no aplicativo pode ser modificada no momento do login. Isso é para traduzir o requisito específico da AWS nos aplicativos de destino. Depois que a sessão no aplicativo do lado do cliente foi iniciada com sucesso, cabe ao próprio aplicativo instrumentar a abstração da camada de dados, porque isso será específico do aplicativo. E esta é uma importante dissociação adicional, onde alguma responsabilidade é empurrada para as unidades descentralizadas. Muitos aplicativos modernos de software como serviço (SaaS) oferecem suporte a esses mecanismos integrados, como Bancos de dados or Laboratório de dados dominó, enquanto aplicativos mais tradicionais do lado do cliente, como Servidor RStudio têm suporte nativo mais limitado para isso. No caso de falta de suporte nativo, uma conversão para a sessão do usuário do SO pode ser feita para habilitar a abstração. A camada de consumo é mostrada esquematicamente no diagrama a seguir.
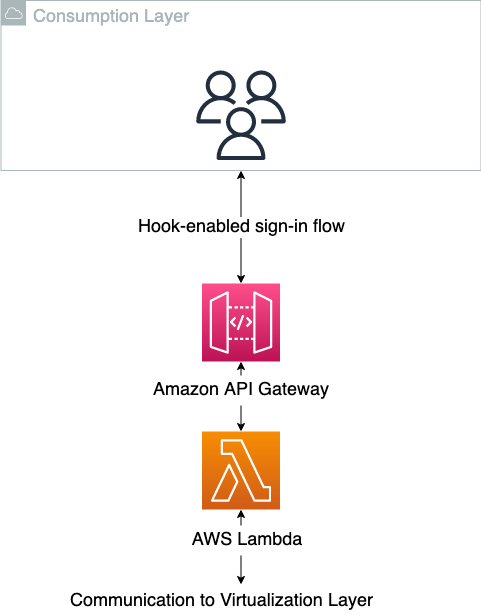
Ao usar a camada de consumo como pretendido, os usuários não sabem que a camada de virtualização existe. O diagrama a seguir ilustra os padrões de acesso a dados.
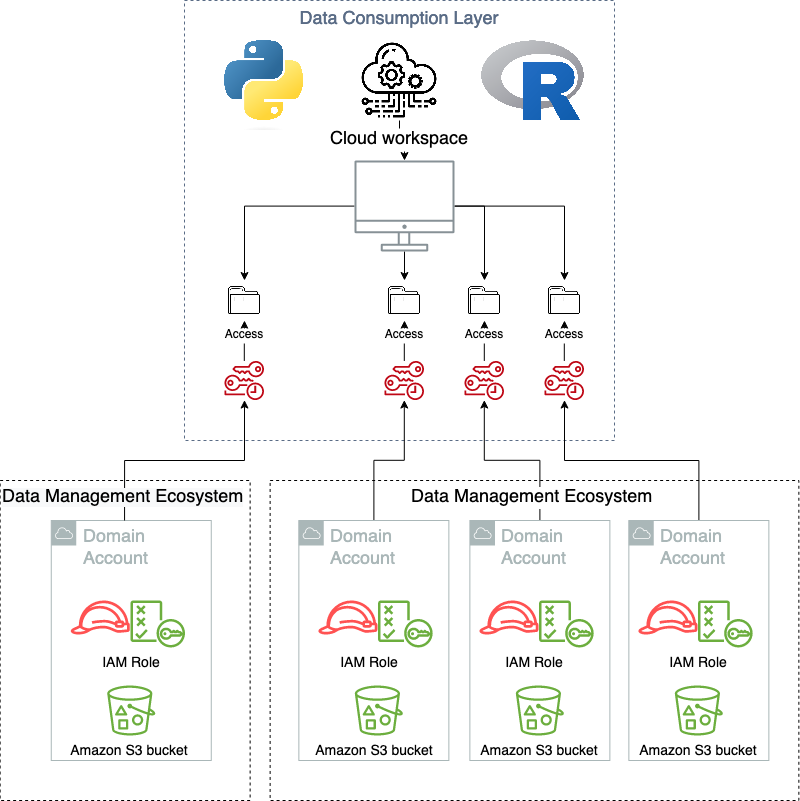
Modularidade
Uma das principais vantagens de adotar o padrão de arquitetura hexagonal, e delegar tanto a camada de consumo quanto a camada de gerenciamento de dados para atores primários e secundários, significa que eles podem ser alterados ou substituídos à medida que novas funcionalidades são lançadas e requerem novas soluções. Isso fornece um padrão do tipo hub-and-spoke, onde muitos tipos diferentes de sistemas do tipo produtor/consumidor podem ser conectados e trabalhar simultaneamente em união. Um exemplo disso é que a solução atual em execução na Novo Nordisk oferece suporte a várias soluções simultâneas de gerenciamento de dados e são expostas de maneira homogênea na camada de consumo. Isso inclui um data lake, a solução de malha de dados apresentada neste post e várias soluções independentes de gerenciamento de dados. E eles estão expostos a vários tipos de aplicativos de consumo, desde aplicativos gerenciados e auto-hospedados personalizados até ofertas de SaaS.
Ecossistema de gerenciamento de dados
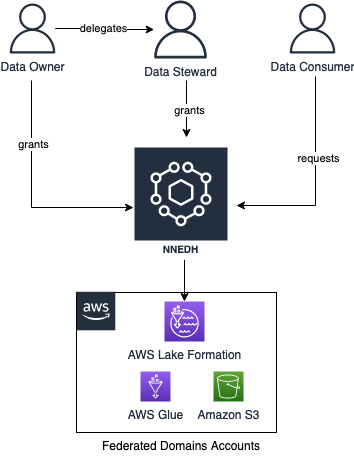
Para escalar o uso dos dados e aumentar a liberdade, a Novo Nordisk, em conjunto com a AWS Professional Services, construiu um ambiente de gerenciamento e governança de dados, denominado Novo Nordisk Enterprise DataHub (NNEDH). O NNEDH implementa uma arquitetura de dados distribuídos descentralizada e recursos de gerenciamento de dados, como um catálogo de dados de negócios corporativos e fluxo de trabalho de compartilhamento de dados. NNEDH é um exemplo de um ecossistema de gerenciamento de dados na estrutura conceitual apresentada anteriormente.
Arquitetura descentralizada: de um data lake centralizado a uma arquitetura distribuída
O data lake centralizado da Novo Nordisk consiste em 2.3 PB de dados de mais de 30 domínios de dados de negócios em todo o mundo, atendendo a mais de 2000 usuários internos em toda a cadeia de valor. Funciona com sucesso há vários anos. É um dos ecossistemas de gerenciamento de dados atualmente suportados.
Dentro da arquitetura de dados centralizada, os dados de cada domínio de dados são copiados, armazenados e processados em um local central: um data lake central hospedado em um armazenamento de dados. Esse padrão apresenta desafios em escala porque mantém a propriedade dos dados com a equipe central. Em escala, esse modelo retarda a jornada em direção a uma organização orientada por dados, porque a propriedade dos dados não está suficientemente ancorada nos profissionais mais próximos do domínio.
A arquitetura monolítica do data lake é mostrada no diagrama a seguir.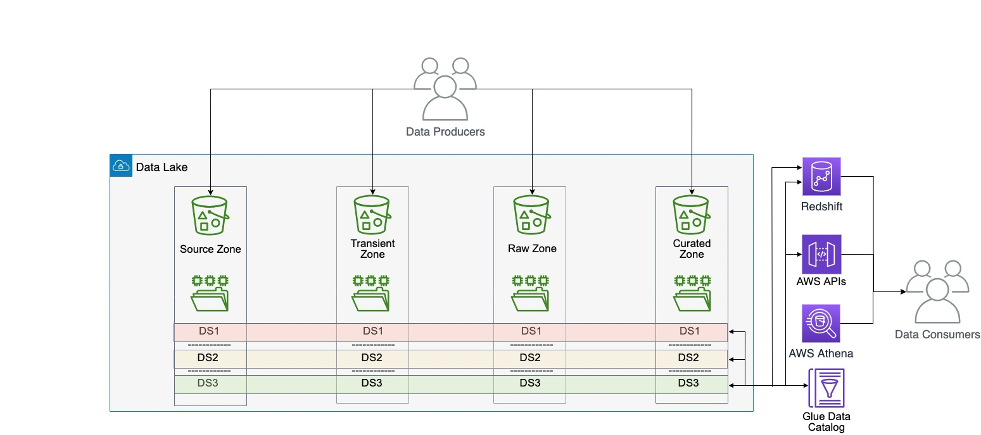
Dentro da arquitetura de dados distribuídos descentralizada, os dados de cada domínio são mantidos dentro do domínio em seu próprio armazenamento de dados e conta de computação. Nesse caso, os dados são mantidos próximos aos especialistas do domínio, porque são eles que conhecem melhor seus próprios dados e, em última análise, são os proprietários de quaisquer produtos de dados criados com base em seus dados. Eles geralmente trabalham em estreita colaboração com analistas de negócios para criar o produto de dados e, portanto, sabem o que bons dados significam para os consumidores de seus produtos de dados. Neste caso, a responsabilidade dos dados também é descentralizada, onde cada domínio tem seu próprio dono de dados, colocando a responsabilidade sobre os verdadeiros donos dos dados. No entanto, esse modelo pode não funcionar em pequena escala, por exemplo, uma organização com apenas uma unidade de negócios e dezenas de usuários, porque introduziria mais sobrecarga na equipe de TI para gerenciar os dados da organização. É mais adequado para grandes organizações ou pequenas e médias que gostariam de crescer e escalar.
A arquitetura de malha de dados da Novo Nordisk é mostrada no diagrama a seguir.

Domínios de dados e ativos de dados
Para permitir a escalabilidade dos domínios de dados em toda a organização, é obrigatório ter um modelo de permissão padrão e um padrão de acesso a dados. Este padrão não deve ser muito restritivo a ponto de ser um bloqueador para casos de uso específicos, mas deve ser padronizado de forma a utilizar a mesma interface entre as camadas de gerenciamento de dados e virtualização.
Os domínios de dados em NNEDH são implementados por uma construção chamada meio Ambiente. Um ambiente é composto por pelo menos uma conta da AWS e uma região da AWS. É um local de trabalho onde as equipes de domínio de dados podem trabalhar e colaborar para criar produtos de dados. Ele vincula o plano de controle NNEDH às contas da AWS onde residem os dados e a computação do domínio. As permissões de acesso aos dados também são definidas no nível do ambiente, gerenciadas pelo proprietário do domínio de dados. Os ambientes têm três componentes principais: uma camada de gerenciamento e governança de dados, ativos de dados e esquemas opcionais para processamento de dados.
Para gerenciamento e governança de dados, os domínios de dados dependem do Lake Formation, Cola AWSe CloudTrail. O método de implantação e a configuração desses componentes são padronizados nos domínios de dados. Dessa forma, o plano de controle NNEDH pode fornecer conectividade e gerenciamento aos domínios de dados de maneira padronizada.
Os ativos de dados de cada domínio que residem em um ambiente são organizados em um conjunto de dados, que é uma coleção de dados relacionados usados para construir um produto de dados. Inclui metadados técnicos, como formato de dados, tamanho e tempo de criação, e metadados de negócios, como produtor, classificação de dados e definição de negócios. Um produto de dados pode usar um ou vários conjuntos de dados. Ele é implementado por meio de buckets S3 gerenciados e do Catálogo de dados do AWS Glue.
O processamento de dados pode ser implementado de diferentes maneiras. A NNEDH fornece esquemas para pipelines de dados com conectividade predefinida para ativos de dados para acelerar a entrega de produtos de dados. Os usuários do domínio de dados têm a liberdade de usar qualquer outro recurso de computação em seu domínio, por exemplo, usando serviços da AWS não predefinidos nos blueprints ou acessando os conjuntos de dados de outras ferramentas analíticas implementadas na camada de consumo, conforme mencionado anteriormente neste post.
Personas e funções do domínio de dados
No NNEDH, os níveis de permissão nos domínios de dados são gerenciados por meio de personas predefinidas, por exemplo, proprietário dos dados, administradores de dados, desenvolvedores e leitores. Cada persona está associada a uma função do IAM que tem um nível de permissão predefinido. Essas permissões são baseadas nas necessidades típicas dos usuários nessas funções. No entanto, para dar mais flexibilidade aos domínios de dados, essas permissões podem ser personalizadas e estendidas conforme necessário.
As permissões associadas a cada persona estão relacionadas apenas às ações permitidas na conta AWS do domínio de dados. Para a responsabilidade sobre ativos de dados, o acesso aos dados aos ativos é gerenciado por políticas de recursos específicas em vez de funções do IAM. Somente o proprietário de cada conjunto de dados ou administradores de dados delegados pelo proprietário podem conceder ou revogar o acesso aos dados.
No nível do conjunto de dados, uma persona necessária é o proprietário dos dados. Normalmente, eles trabalham em estreita colaboração com um ou mais administradores de dados como gerentes de produtos de dados. O administrador de dados é o especialista no assunto de dados do domínio do produto de dados, responsável por interpretar os dados e metadados coletados para obter insights de negócios profundos e criar o produto. O administrador de dados faz a ponte entre os usuários de negócios e as equipes técnicas em cada domínio de dados.
Catálogo de dados de negócios corporativos
Para permitir a liberdade e tornar os ativos de dados da organização detectáveis, um catálogo de dados do portal baseado na web é implementado. Ele indexa em um único repositório metadados de conjuntos de dados criados em domínios de dados, quebrando silos de dados em toda a organização. O catálogo de dados permite a pesquisa e descoberta de dados em diferentes domínios, bem como automação e governança no compartilhamento de dados.
O catálogo de dados corporativos implementa processos de governança de dados dentro da organização. Ele garante a propriedade dos dados - alguém na organização é responsável pela origem, definição, atributos de negócios, relacionamentos e dependências dos dados.
A construção central de um catálogo de dados de negócios é um conjunto de dados. É a unidade de pesquisa dentro do catálogo de negócios, contendo metadados técnicos e comerciais. Para coletar metadados técnicos de dados estruturados, ele conta com crawlers do AWS Glue para reconhecer e extrair estruturas de dados dos formatos de dados mais populares, incluindo CSV, JSON, Avro e Apache Parquet. Ele fornece informações como tipo de dados, data de criação e formato. Os metadados podem ser enriquecidos por usuários de negócios adicionando uma descrição do contexto de negócios, tags e classificação de dados.
A definição do conjunto de dados e os metadados relacionados são armazenados em um Amazon Aurora sem servidor banco de dados e Serviço Amazon OpenSearch, permitindo executar consultas textuais no catálogo de dados.
Compartilhamento de dados
O NNEDH implementa um fluxo de trabalho de compartilhamento de dados, permitindo o compartilhamento de dados ponto a ponto entre contas da AWS usando o Lake Formation. O fluxo de trabalho é o seguinte:
- Um consumidor de dados solicita acesso ao conjunto de dados.
- O proprietário dos dados concede acesso aprovando a solicitação de acesso. Eles podem delegar a aprovação de solicitações de acesso ao administrador de dados.
- Após a aprovação de uma solicitação de acesso, uma nova permissão é adicionada ao conjunto de dados específico no Lake Formation da conta do produtor.
O fluxo de trabalho de compartilhamento de dados é mostrado esquematicamente na figura a seguir.
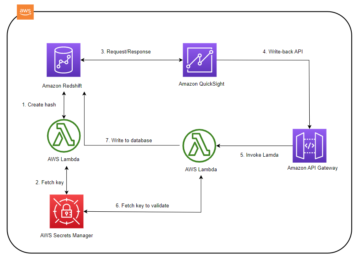
Segurança e auditoria
Os dados na malha de dados da Novo Nordisk estão nas contas da AWS pertencentes às contas comerciais da Novo Nordisk. A configuração e os estados da malha de dados são armazenados em Serviço de banco de dados relacional da Amazon (RDS da Amazônia). A arquitetura de segurança da Novo Nordisk é mostrada na figura a seguir.

O acesso e as edições dos dados em NNEDH precisam ser registrados para fins de auditoria. Precisamos saber quem modificou os dados, quando a modificação ocorreu e quais modificações foram aplicadas. Além disso, precisamos ser capazes de responder por que a modificação foi permitida por aquela pessoa naquele momento.
Para atender a esses requisitos, usamos os seguintes componentes:
- CloudTrail para registrar chamadas de API. Habilitamos especificamente o registro de eventos de dados CloudTrail para objetos e depósitos S3. Ao ativar o log, podemos rastrear qualquer modificação em qualquer arquivo no data lake até a pessoa que fez a modificação. Reforçamos o uso de identidade de origem para sessões de função do IAM para garantir a rastreabilidade do usuário.
- Usamos o Amazon RDS para armazenar a configuração da malha de dados. Registramos consultas no banco de dados RDS. Juntamente com o CloudTrail, esse log nos permite responder à pergunta de por que uma modificação em um arquivo no Amazon S3 em um momento específico por uma pessoa específica é possível.
- Amazon CloudWatch para registrar atividades em toda a malha.
Além desses mecanismos de log, os buckets do S3 são criados usando as seguintes propriedades:
- O bucket é criptografado usando criptografia do lado do servidor com Serviço de gerenciamento de chaves AWS (AWS KMS) e chaves gerenciadas pelo cliente
- O versionamento do Amazon S3 é ativado por padrão
O acesso aos dados em NNEDH é controlado no nível do grupo em vez de usuários individuais. O grupo corresponde ao grupo definido no grupo de diretórios da Novo Nordisk. Para rastrear a pessoa que modificou os dados nos data lakes, usamos o mecanismo de identidade de origem explicado no post Como relacionar a atividade de função do IAM à identidade corporativa.
Conclusão
Neste post, mostramos como a Novo Nordisk construiu uma arquitetura de dados moderna para acelerar a entrega de casos de uso orientados a dados. Ele inclui uma arquitetura de dados distribuída, para dimensionar o uso em escala de petabytes para mais de 2,000 usuários internos em toda a cadeia de valor, bem como uma segurança distribuída e arquitetura de auditoria que lida com responsabilidade e rastreabilidade de dados no ambiente para atender aos requisitos de conformidade.
A próxima postagem desta série descreve a implementação da governança e controle de dados distribuídos em escala da arquitetura de dados moderna da Novo Nordisk.
Sobre os autores
 Jonatan Selsing é um ex-cientista pesquisador com doutorado em astrofísica que se voltou para a nuvem. Atualmente, ele é o engenheiro líder de nuvem da Novo Nordisk, onde habilita cargas de trabalho de análise e dados em escala. Com ênfase na redução do custo total de propriedade de cargas de trabalho baseadas em nuvem, ao mesmo tempo em que oferece todos os benefícios das vantagens da nuvem, ele projeta, constrói e mantém soluções que permitem a pesquisa de medicamentos futuros.
Jonatan Selsing é um ex-cientista pesquisador com doutorado em astrofísica que se voltou para a nuvem. Atualmente, ele é o engenheiro líder de nuvem da Novo Nordisk, onde habilita cargas de trabalho de análise e dados em escala. Com ênfase na redução do custo total de propriedade de cargas de trabalho baseadas em nuvem, ao mesmo tempo em que oferece todos os benefícios das vantagens da nuvem, ele projeta, constrói e mantém soluções que permitem a pesquisa de medicamentos futuros.
 Hassen Riahi é arquiteto sênior de dados na AWS Professional Services. Ele é PhD em Matemática e Ciência da Computação em gerenciamento de dados em larga escala. Ele trabalha com clientes da AWS na criação de soluções baseadas em dados.
Hassen Riahi é arquiteto sênior de dados na AWS Professional Services. Ele é PhD em Matemática e Ciência da Computação em gerenciamento de dados em larga escala. Ele trabalha com clientes da AWS na criação de soluções baseadas em dados.
 Anwar Rizal é um consultor sênior de Machine Learning baseado em Paris. Ele trabalha com clientes da AWS para desenvolver soluções de dados e IA para expandir seus negócios de forma sustentável.
Anwar Rizal é um consultor sênior de Machine Learning baseado em Paris. Ele trabalha com clientes da AWS para desenvolver soluções de dados e IA para expandir seus negócios de forma sustentável.
 Moisés Artur tem formação em matemática e pesquisa computacional e é PhD em Inteligência Computacional, especializado em Graph Mining. Atualmente, ele é engenheiro de produto em nuvem na Novo Nordisk, construindo data lakes corporativos compatíveis com GxP e plataformas analíticas para as fábricas globais da Novo Nordisk que produzem produtos médicos digitalizados.
Moisés Artur tem formação em matemática e pesquisa computacional e é PhD em Inteligência Computacional, especializado em Graph Mining. Atualmente, ele é engenheiro de produto em nuvem na Novo Nordisk, construindo data lakes corporativos compatíveis com GxP e plataformas analíticas para as fábricas globais da Novo Nordisk que produzem produtos médicos digitalizados.
 Alessandro Fior é arquiteto sênior de dados na AWS Professional Services. Com mais de 10 anos de experiência no fornecimento de soluções de dados e análises, ele é apaixonado por projetar e construir plataformas de dados modernas e escaláveis que aceleram as empresas a obter valor de seus dados.
Alessandro Fior é arquiteto sênior de dados na AWS Professional Services. Com mais de 10 anos de experiência no fornecimento de soluções de dados e análises, ele é apaixonado por projetar e construir plataformas de dados modernas e escaláveis que aceleram as empresas a obter valor de seus dados.
 Kumari Ramar é gerente de engajamento sênior com certificação Agile e PMP da AWS Professional Services. Ela oferece soluções de dados e IA/ML que aceleram a análise entre sistemas e modelos de aprendizado de máquina, que permitem que as empresas tomem decisões baseadas em dados e impulsionem inovações.
Kumari Ramar é gerente de engajamento sênior com certificação Agile e PMP da AWS Professional Services. Ela oferece soluções de dados e IA/ML que aceleram a análise entre sistemas e modelos de aprendizado de máquina, que permitem que as empresas tomem decisões baseadas em dados e impulsionem inovações.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/how-novo-nordisk-built-a-modern-data-architecture-on-aws/
- 000
- 10
- 100
- a
- Capaz
- Sobre
- RESUMO
- resumos
- acelerar
- Acesso
- Acesso a dados
- acessando
- Segundo
- Conta
- responsabilidade
- Contas
- em
- ações
- ativando
- atividades
- atividade
- adaptar
- adicionado
- Adição
- Adicional
- administração
- Adotando
- vantagens
- Depois de
- contra
- agência
- ágil
- AI
- AI / ML
- Todos os Produtos
- permite
- Amazon
- Amazon RDS
- Analistas
- analítica
- e
- responder
- apache
- api
- Aplicação
- específico do aplicativo
- aplicações
- aplicado
- aprovação
- arquitetura
- por aí
- Ativos
- associado
- astrofísica
- atributos
- auditor
- auditoria
- aurora
- autorização
- Automação
- AWS
- Cola AWS
- Serviços Profissionais AWS
- em caminho duplo
- fundo
- baseado
- Porque
- beneficiar
- MELHOR
- Melhor
- entre
- Inferior
- limites
- Quebra
- pontes
- construir
- Prédio
- Constrói
- construído
- construídas em
- negócio
- inteligência de negócios
- chamado
- chamadas
- capacidades
- casas
- casos
- catálogo
- central
- centralizada
- Non-GMO
- cadeia
- desafios
- alterar
- escolha
- aulas
- classificação
- Clínico
- ensaios clínicos
- Fechar
- de perto
- Na nuvem
- colaborar
- colaboração
- colaborativo
- coletar
- coleção
- combinação
- combinações
- combinado
- como
- Empresas
- Empresa
- compliance
- componentes
- composta
- Composto
- comprometendo
- Computar
- computador
- Ciência da Computação
- conceptual
- Configuração
- conectado
- Conectividade
- construir
- consultor
- consumir
- consumidor
- Consumidores
- consumo
- contexto
- ao controle
- controlado
- controles
- núcleo
- Responsabilidade
- corresponde
- Custo
- acoplado
- criado
- criação
- Atravessar
- Atual
- Atualmente
- personalizadas
- cliente
- Clientes
- dados,
- acesso a dados
- infraestrutura de dados
- lago data
- gestão de dados
- informática
- compartilhamento de dados
- armazenamento de dados
- orientado por dados
- banco de dados
- Bancos de dados
- conjuntos de dados
- Data
- dia
- Descentralizada
- decisão
- Tomada de Decisão
- decisões
- profundo
- entregando
- entrega
- Entrega
- desenvolvimento
- descreve
- descrição
- Design
- projetado
- concepção
- projetos
- detalhe
- detalhes
- desenvolver
- desenvolvedores
- desenvolve
- diferente
- diretamente
- descoberta
- discutir
- distinto
- distribuído
- Não faz
- domínio
- domínios
- não
- down
- distância
- Drivers
- droga
- cada
- Mais cedo
- ecossistema
- ecossistemas
- Eficaz
- elementos
- ênfase
- permitir
- habilitado
- permite
- permitindo
- encapsulado
- criptografada
- criptografia
- COMPROMETIMENTO
- engenheiro
- Engenharia
- enriquecido
- garantir
- garante
- Empreendimento
- empresas
- Todo
- Meio Ambiente
- Ambientalmente
- ambientes
- Éter (ETH)
- Europa
- Evento
- exemplo
- existe
- expandido
- vasta experiência
- especialista
- especialistas
- explicado
- exposto
- extrato
- fábricas
- Funcionalidades
- Figura
- Envie o
- Arquivos
- financeiramente
- Primeiro nome
- Flexibilidade
- fluxo
- concentra-se
- seguinte
- segue
- comida
- Food and Drug Administration
- formato
- treinamento
- Antigo
- Foundation
- Quadro
- Freedom
- da
- cheio
- funcionalidades
- futuro
- Geral
- gera
- ter
- obtendo
- OFERTE
- dá
- Dando
- Global
- Go
- Bom estado, com sinais de uso
- governo
- conceder
- subsídios
- gráfico
- Grupo
- Cresça:
- guia
- orientações
- manipular
- Manipulação
- aconteceu
- ter
- detém
- hospedado
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- HTTPS
- IAM
- Dados de identificação:
- implementação
- implementado
- implementação
- implementa
- importante
- melhorado
- in
- incluir
- inclui
- Incluindo
- Crescimento
- de treinadores em Entrevista Motivacional
- índices
- Individual
- indústria
- INFORMAÇÕES
- Infraestrutura
- Inovação
- e inovações
- insights
- em vez disso
- instrumento
- integrado
- integridade
- Inteligência
- Interface
- interfaces de
- interno
- introduzir
- introduzido
- IT
- se
- viagem
- json
- Guarda
- Chave
- Saber
- lago
- paisagem
- grande
- em grande escala
- camada
- camadas
- conduzir
- principal
- APRENDER
- aprendizagem
- Nível
- níveis
- Limitado
- linhas
- Links
- localização
- longo prazo
- máquina
- aprendizado de máquina
- moldadas
- a Principal
- mantém
- fazer
- Fazendo
- gerencia
- gerenciados
- de grupos
- Solução de gerenciamento
- Gerente
- Gerentes
- gestão
- Mandato
- obrigatório
- fabrica
- muitos
- Marketing
- matemática
- Importância
- significa
- mecanismo
- médico
- medicinal
- média
- Conheça
- mencionado
- metadados
- método
- Microsoft
- poder
- milhão
- mínimo
- Mineração
- desaparecido
- modelo
- modelos
- EQUIPAMENTOS
- modificações
- modificada
- modulares
- mais
- a maioria
- Mais populares
- múltiplo
- Nomeado
- nativo
- você merece...
- necessário
- Cria
- rede
- mesmo assim
- Novo
- novas soluções
- Próximo
- Novo
- Novo Nordisk
- número
- objetos
- Ofertas
- OKTA
- ONE
- organização
- organizações
- Organizado
- Origin
- OS
- Outros
- Outros
- global
- próprio
- propriedade
- proprietário
- proprietários
- propriedade
- possui
- Paris
- festa
- apaixonado
- pacientes
- padrão
- padrões
- peer to peer
- permissão
- permissões
- pessoa
- Pessoalmente
- petabyte
- Farmacêutica
- Pii
- Plataformas
- platão
- Inteligência de Dados Platão
- PlatãoData
- políticas
- Privacidade
- Popular
- Portal
- portas
- possível
- Publique
- POSTAGENS
- poder
- Power BI
- Preparar
- apresentado
- primário
- processos
- em processamento
- produtor
- Produto
- Produtos
- profissional
- Propriedades
- fornecer
- fornece
- fornecendo
- propósito
- fins
- empurrado
- Colocar
- qualidade
- questão
- alcançar
- leitores
- recebe
- reconhecer
- redução
- região
- regulamentos
- Reguladores
- relacionado
- Relacionamentos
- liberado
- substituído
- repositório
- representado
- solicitar
- pedidos
- requerer
- requeridos
- requerimento
- Requisitos
- pesquisa
- recurso
- Recursos
- respeitado
- resposta
- responsabilidade
- responsável
- Restritivo
- Tipo
- papéis
- Execute
- corrida
- SaaS
- seguro
- vendas
- mesmo
- AMPLIAR
- escalável
- Escala
- Ciência
- Cientista
- cientistas
- Pesquisar
- Segundo
- secundário
- segurança
- Autoatendimento
- sensível
- Série
- serviço
- Serviços
- de servir
- Sessão
- sessões
- instalação
- vários
- compartilhando
- rede de apoio social
- mostrar
- mostrando
- Shows
- simples
- simultaneamente
- solteiro
- singular
- Sentado
- Tamanho
- retarda
- pequeno
- socialmente
- Software
- software como serviço
- solução
- Soluções
- alguns
- fonte
- especializado
- específico
- especificamente
- velocidade
- divisão
- padrão
- começado
- Estado
- Unidos
- armazenamento
- loja
- armazenadas
- Estratégico
- lutar
- estruturada
- sujeito
- entraram com sucesso
- tal
- ajuda
- Suportado
- suportes
- sustentável
- sistemas
- Tire
- Target
- tem como alvo
- Profissionais
- equipes
- Dados Técnicos:
- princípios
- A
- A fonte
- O Estado
- deles
- assim sendo
- Terceiro
- três
- Através da
- todo
- tempo
- para
- juntos
- também
- ferramenta
- ferramentas
- Total
- para
- traçar
- Rastreabilidade
- pista
- tradicional
- traduzir
- Tradução
- Transparência
- ensaios
- triplo
- verdadeiro
- Confiança
- Virado
- tipos
- típico
- tipicamente
- nos
- Em última análise
- união
- unidade
- unidades
- us
- Uso
- usar
- Utilizador
- usuários
- valor
- versátil
- maneiras
- Web-Based
- bem definido
- O Quê
- qual
- enquanto
- QUEM
- precisarão
- dentro
- sem
- Atividades:
- trabalhar juntos
- trabalhou
- de gestão de documentos
- Local de trabalho
- trabalho
- no mundo todo
- seria
- X
- anos
- zefirnet