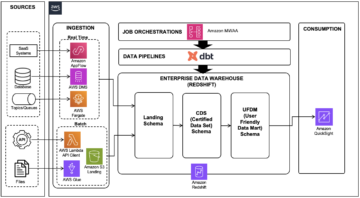
Amazon RedShift é um data warehouse rápido, escalável, seguro e totalmente gerenciado que permite analisar todos os seus dados usando SQL padrão de maneira fácil e econômica. Amazon Redshift Compartilhamento de dados permite que os clientes compartilhem com segurança dados ao vivo e transacionalmente consistentes em um cluster do Amazon Redshift com outro cluster do Amazon Redshift entre contas e regiões sem a necessidade de copiar ou mover dados de um cluster para outro.
O Amazon Redshift Data Sharing foi lançado inicialmente em Março de 2021, e suporte adicionado para compartilhamento de dados entre contas foi adicionado em Agosto de 2021. O suporte entre regiões tornou-se geralmente disponível em Fevereiro de 2022. Isso fornece total flexibilidade e agilidade para compartilhar dados entre clusters Redshift na mesma conta da AWS, contas diferentes ou regiões diferentes.
O compartilhamento de dados do Amazon Redshift é usado para redefinir fundamentalmente as arquiteturas de implantação do Amazon Redshift em um modelo de malha de dados hub-spoke para melhor atender aos SLAs de desempenho, fornecer isolamento de carga de trabalho, executar análises entre grupos, integrar facilmente novos casos de uso e, o mais importante, fazer tudo isso sem a complexidade de movimentação de dados e cópias de dados. Algumas das perguntas mais comuns feitas durante a implantação do compartilhamento de dados são: “Qual deve ser o tamanho dos meus clusters de consumidores e clusters de produtores?” e “Como obtenho o melhor desempenho de preço para isolamento de carga de trabalho?”. Como as características da carga de trabalho, como tamanho dos dados, taxa de ingestão, padrão de consulta e atividades de manutenção, podem afetar o desempenho do compartilhamento de dados, deve ser implementada uma estratégia contínua para dimensionar clusters de consumidores e produtores para maximizar o desempenho e minimizar os custos. Nesta postagem, fornecemos uma abordagem passo a passo para ajudá-lo a determinar os tamanhos dos clusters de produtores e consumidores para obter o melhor desempenho de preço com base em sua carga de trabalho específica.
Orientação genérica de dimensionamento do consumidor
As etapas a seguir mostram a estratégia genérica para dimensionar seus clusters de produtores e consumidores. Você pode usá-lo como ponto de partida e modificá-lo de acordo para atender ao seu cenário de caso de uso específico.
Dimensione seu cluster de produtor
Você deve sempre certificar-se de dimensionar adequadamente seu cluster de produtor para obter o desempenho necessário para atender ao seu SLA. Você pode aproveitar a calculadora de dimensionamento do console do Amazon Redshift para obter uma recomendação para o cluster de produtor com base no tamanho de seus dados e nas características de consulta. Olhe para Me ajude a escolher no console nas regiões da AWS que oferecem suporte a tipos de nó RA3 para usar esta calculadora de dimensionamento. Observe que esta é apenas uma recomendação inicial para começar, e você deve testar a execução de toda a carga de trabalho no cluster de tamanho inicial e redimensionar o cluster para cima e para baixo de acordo para obter o melhor desempenho de preço.
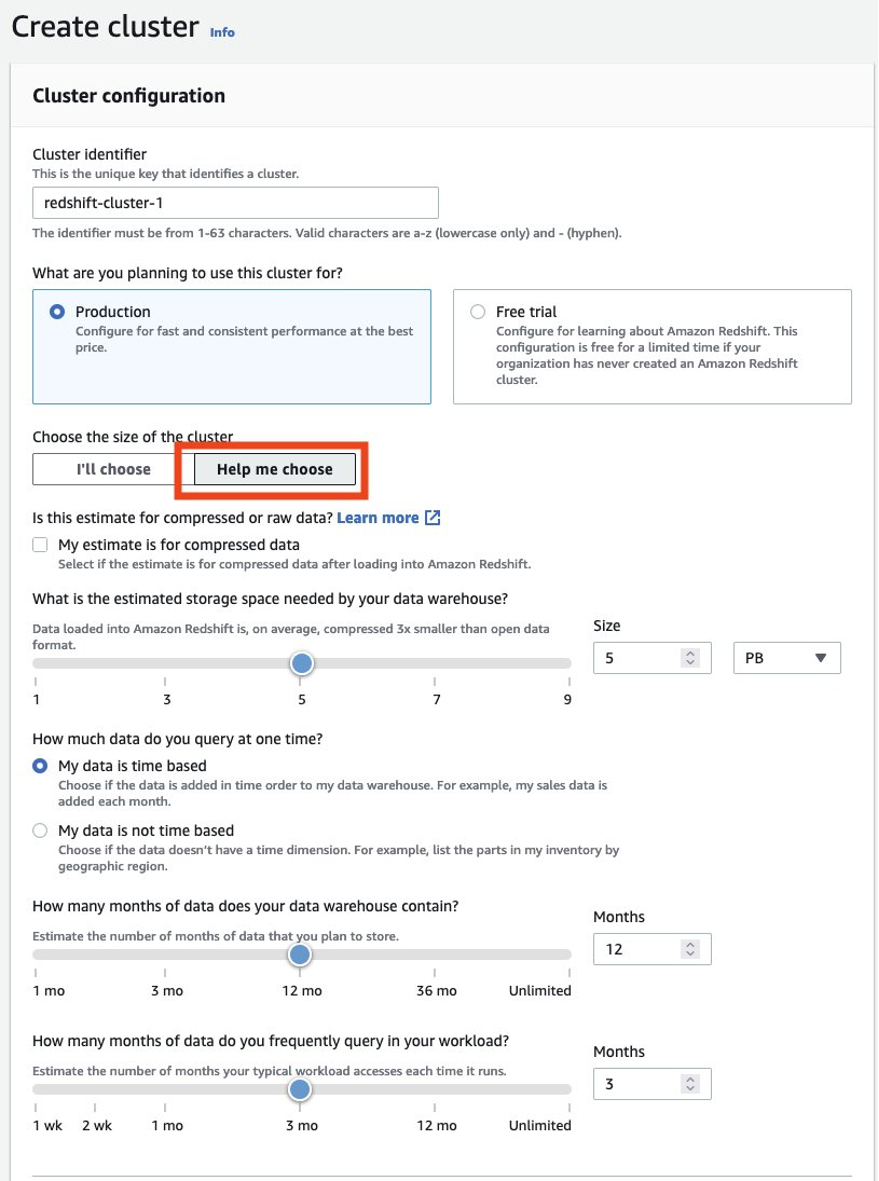
Dimensionar e configurar o cluster de consumidor inicial
Você sempre deve dimensionar seu cluster de consumidor com base em suas necessidades de computação. Uma maneira de começar é seguir o guia de dimensionamento de cluster genérico semelhante ao cluster de produtor acima.
Configurar o compartilhamento de dados do Amazon Redshift
Configure o compartilhamento de dados do produtor para o consumidor depois de configurar o cluster do produtor e do consumidor. Consulte isso postar para obter orientação sobre como configurar o compartilhamento de dados.
Testar a carga de trabalho somente do consumidor no cluster inicial do consumidor
Teste a carga de trabalho apenas do consumidor no novo cluster de consumidor inicial. Isso pode ser feito apontando aplicativos do consumidor, por exemplo, ferramentas ETL, aplicativos de BI e clientes SQL, para o novo cluster do consumidor e executando novamente a carga de trabalho para avaliar o desempenho em relação aos seus requisitos.
Teste a carga de trabalho somente do consumidor em diferentes configurações de cluster do consumidor
Se o cluster de consumidor de tamanho inicial atender ou exceder os requisitos de desempenho da carga de trabalho, você poderá continuar usando essa configuração de cluster ou testar configurações menores para ver se pode reduzir ainda mais o custo e ainda obter o desempenho necessário.
Por outro lado, se o cluster de consumidor de tamanho inicial não atender aos requisitos de desempenho da carga de trabalho, você poderá testar configurações maiores para obter a configuração que atenda ao seu SLA.
Como regra geral, dimensione o cluster do consumidor em 2x a configuração inicial do cluster de forma incremental até que ele atenda aos seus requisitos de carga de trabalho.
Depois de planejar qual configuração deseja testar, use o redimensionamento elástico para redimensionar o cluster inicial para a configuração do cluster de destino. Após a conclusão do redimensionamento elástico, execute o mesmo teste de carga de trabalho e avalie o desempenho em relação ao seu SLA. Selecione a configuração que atende a sua meta de desempenho de preço.
Testar a carga de trabalho somente do produtor em diferentes configurações de cluster do produtor
Depois de mover a carga de trabalho do consumidor para o cluster do consumidor com o desempenho de preço ideal, pode haver uma oportunidade de reduzir o recurso de computação no produtor para economizar custos.
Para conseguir isso, você pode executar novamente a carga de trabalho somente do produtor em 1/2x do tamanho original do produtor e avaliar o desempenho da carga de trabalho. O redimensionamento do cluster para cima e para baixo depende do resultado e, em seguida, você seleciona a configuração mínima do produtor que atende aos requisitos de desempenho da carga de trabalho.
Reavalie após uma execução completa da carga de trabalho ao longo do tempo
À medida que o Amazon Redshift continua evoluindo e há lançamentos de melhoria contínua de desempenho e escalabilidade, o desempenho do compartilhamento de dados continuará melhorando. Além disso, várias variáveis podem afetar o desempenho das consultas de compartilhamento de dados. Os seguintes são apenas alguns exemplos:
- Taxa de ingestão e quantidade de alteração de dados
- Padrão e característica de consulta
- Alterações na carga de trabalho
- Concorrência
- Atividades de manutenção, por exemplo, vácuo, análise e ATO
É por isso que você deve reavaliar o dimensionamento do cluster de produtor e consumidor usando a estratégia acima ocasionalmente, especialmente após uma implantação de carga de trabalho completa, para obter o novo melhor desempenho de preço da configuração de seu cluster.
Soluções de dimensionamento automatizado
Se seu ambiente envolver uma arquitetura mais complexa, por exemplo, com várias ferramentas ou aplicativos (BI, ingestão ou streaming, ETL, ciência de dados), talvez não seja viável usar o método manual da orientação genérica acima. Em vez disso, você pode aproveitar as soluções nesta seção para reproduzir automaticamente a carga de trabalho de seu cluster de produção nos clusters de consumidor e produtor de teste para avaliar o desempenho.
Utilitário de Repetição Simples será aproveitado como a solução automatizada para guiá-lo no processo de obtenção do tamanho certo de clusters de produtores e consumidores para obter o melhor desempenho de preço.
O Simple Replay é uma ferramenta para realizar uma análise hipotética e avaliar o desempenho de sua carga de trabalho em diferentes cenários. Por exemplo, você pode usar a ferramenta para comparar sua carga de trabalho real em um novo tipo de instância como RA3, avaliar um novo recurso ou avaliar diferentes configurações de cluster. Ele também inclui suporte aprimorado para reprodução de ingestão de dados e pipelines de exportação com instruções COPY e UNLOAD. Para começar e reproduzir suas cargas de trabalho, baixe a ferramenta no Repositório GitHub do Amazon Redshift.
Aqui, percorremos as etapas para extrair seus logs de carga de trabalho do cluster de produção de origem e reproduzi-los em um ambiente isolado. Isso permite que você faça uma comparação direta entre esses clusters do Amazon Redshift sem problemas e selecione a configuração de clusters que melhor atenda à sua meta de desempenho de preço.
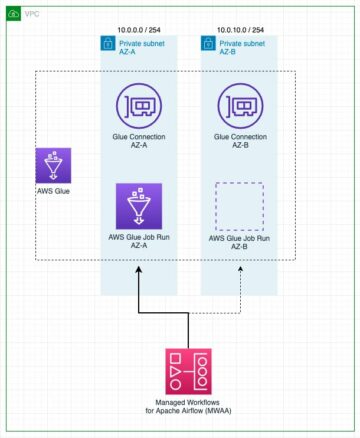
O diagrama a seguir mostra a arquitetura da solução.
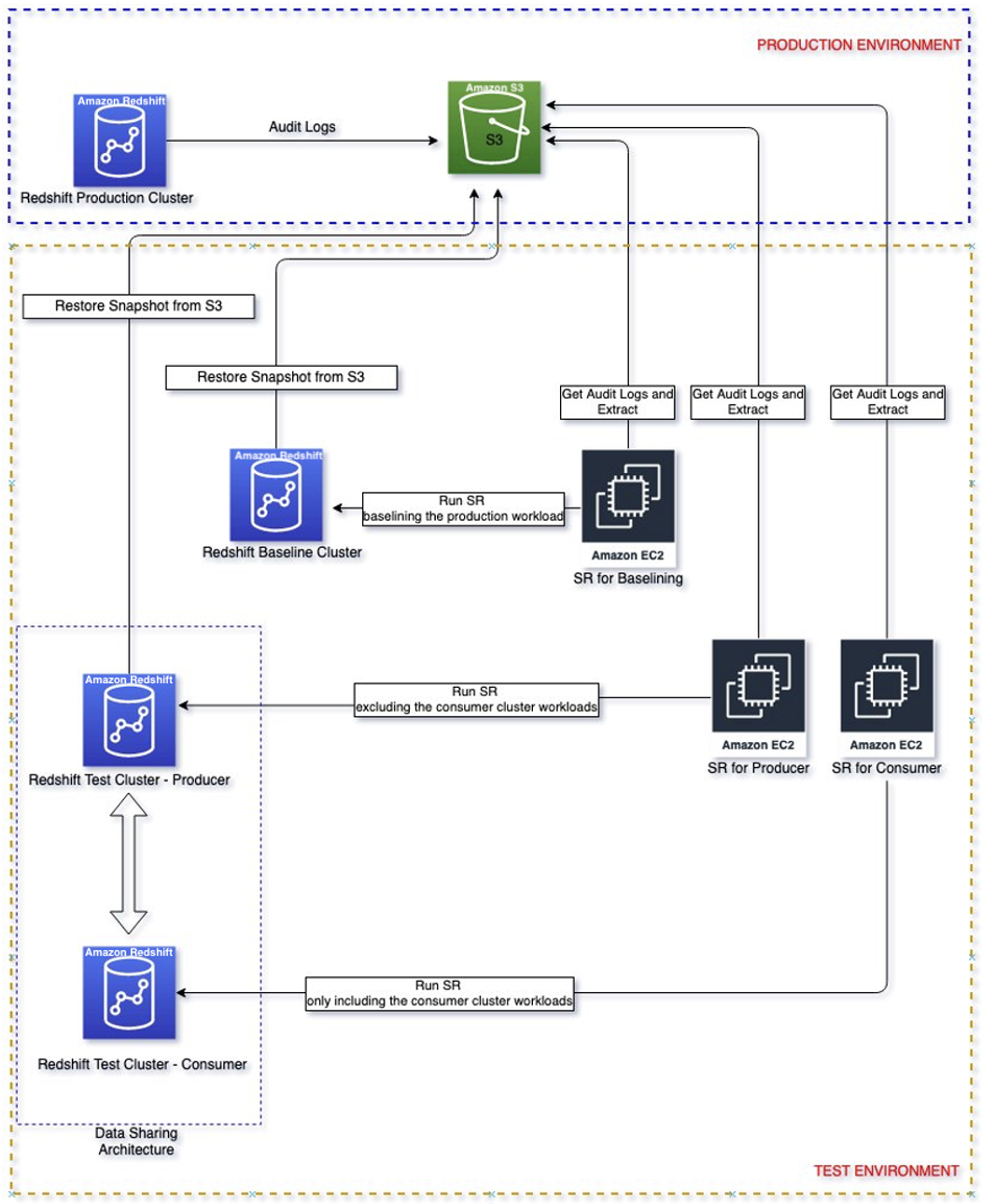
Passo a passo da solução
Siga estas etapas para percorrer a solução para dimensionar seus clusters de consumidor e produtor.
Dimensione seu cluster de produção
Você deve sempre certificar-se de dimensionar adequadamente seu cluster de produção existente para obter o desempenho necessário para atender aos requisitos de carga de trabalho. Você pode aproveitar a calculadora de dimensionamento do console do Amazon Redshift para obter uma recomendação sobre o cluster de produção com base no tamanho de seus dados e nas características de consulta. Olhe para Me ajude a escolher no console nas regiões da AWS que oferecem suporte a tipos de nó RA3 para usar esta calculadora de dimensionamento. Observe que esta é apenas uma recomendação inicial para começar. Você deve testar a execução de toda a carga de trabalho no cluster de tamanho inicial e redimensionar o cluster para cima e para baixo para obter o melhor desempenho de preço.
Identifique a carga de trabalho a ser isolada
Você pode ter cargas de trabalho diferentes em execução no cluster original, mas a primeira etapa é identificar a carga de trabalho mais crítica para os negócios que queremos isolar. Isso ocorre porque queremos garantir que a nova arquitetura possa atender aos seus requisitos de carga de trabalho. Esse postar é uma boa referência em um caso de uso de isolamento de carga de trabalho de compartilhamento de dados que pode ajudá-lo a decidir qual carga de trabalho pode ser isolada.
Configurar replay simples
Depois de conhecer sua carga de trabalho crítica, você deve habilitar registro de auditoria em seu cluster de produção onde a carga de trabalho crítica identificada acima está em execução para capturar atividades de consulta e armazenar em Serviço de armazenamento simples da Amazon (Amazon S3). Observe que pode levar até três horas para que os logs de auditoria sejam entregues ao Amazon S3. Assim que o log de auditoria estiver disponível, prossiga para configurar replay simples e depois extrato a carga de trabalho crítica do log de auditoria. Observe que start_time e end_time podem ser usados como parâmetros para filtrar a carga de trabalho crítica se essas cargas de trabalho forem executadas em determinados períodos de tempo, por exemplo, das 9h às 11h. Caso contrário, ele extrairá todas as atividades registradas.
Carga de trabalho de linha de base
Crie um cluster de linha de base com a mesma configuração do cluster do produtor restaurando a partir do instantâneo de produção. O propósito de começar com a mesma configuração é estabelecer a linha de base do desempenho com um ambiente isolado.
Quando o cluster de linha de base estiver disponível, repetir a carga de trabalho extraída no cluster de linha de base. A saída desse replay será a linha de base usada para comparar com os replays subsequentes em diferentes configurações do consumidor.
Configurar clusters de teste inicial de produtor e consumidor
Crie um cluster de produtor com a mesma configuração de cluster de produção restaurando a partir do instantâneo de produção. Crie um cluster de consumidor com o tamanho de consumidor inicial recomendado da orientação anterior. Além disso, configure o compartilhamento de dados entre o produtor e o consumidor.
Carga de trabalho de repetição no produtor e consumidor inicial
Responder a carga de trabalho do produtor apenas no cluster de produtor de tamanho inicial. Isso pode ser obtido usando o parâmetro de filtro "Excluir" para excluir as consultas do consumidor, por exemplo, o usuário que executa as consultas do consumidor.
Responder a carga de trabalho somente do consumidor no cluster de consumidor de tamanho inicial. Isso pode ser obtido usando o parâmetro de filtro “Incluir” para excluir as consultas do consumidor, por exemplo, o usuário que executa as consultas do consumidor.
Avalie o desempenho dessas repetições em relação aos requisitos de desempenho da linha de base e da carga de trabalho.
Reproduza a carga de trabalho do consumidor em diferentes configurações
Se o cluster de consumidor de tamanho inicial atender ou exceder os requisitos de desempenho da carga de trabalho, você poderá usar essa configuração de cluster ou seguir estas etapas para testar configurações menores para ver se pode reduzir ainda mais os custos e ainda obter o desempenho necessário.
Compare os resultados iniciais de desempenho do consumidor com seus requisitos de carga de trabalho:
- Se o resultado exceder os requisitos de desempenho da carga de trabalho, você poderá reduzir o tamanho do cluster do consumidor de forma incremental, começando com 1/2x, repetir a reprodução e avaliar o desempenho e, em seguida, redimensionar para cima ou para baixo de acordo com o resultado até que atenda à sua carga de trabalho requisitos. O objetivo é obter um ponto ideal onde você se sinta confortável com os requisitos de desempenho e obtenha o preço mais baixo possível.
- Se o resultado não atender aos requisitos de desempenho da carga de trabalho, você poderá aumentar o tamanho do cluster de forma incremental, começando com 2x o tamanho original, repita a reprodução e avalie o desempenho até atender aos requisitos de desempenho da carga de trabalho.
Reproduza a carga de trabalho do produtor em diferentes configurações
Depois de dividir suas cargas de trabalho em clusters de consumidor, a carga no cluster de produtor deve ser reduzida e você deve avaliar o desempenho da carga de trabalho do cluster de produtor para buscar a oportunidade de reduzir o tamanho para economizar custos.
As etapas são semelhantes à reprodução do consumidor. Elastic redimensiona o cluster do produtor de forma incremental começando com 1/2x o tamanho original, reproduz a carga de trabalho somente do produtor e avalia o desempenho e, em seguida, redimensiona para cima ou para baixo até atender aos requisitos de desempenho da carga de trabalho. O objetivo é obter um ponto ideal onde você se sinta confortável com os requisitos de desempenho da carga de trabalho e obtenha o preço mais baixo possível. Depois de ter a configuração de cluster de produtor desejada, repita as cargas de trabalho do consumidor no cluster de consumidor para garantir que o desempenho não foi afetado pelas alterações na configuração do cluster de produtor. Por fim, você deve reproduzir as cargas de trabalho do produtor e do consumidor simultaneamente para garantir que o desempenho seja alcançado em um cenário de carga de trabalho completa.
Reavalie após uma execução completa da carga de trabalho ao longo do tempo
Semelhante à orientação genérica, você deve reavaliar o dimensionamento dos clusters de produtores e consumidores usando a estratégia anterior ocasionalmente, especialmente após a implantação de carga de trabalho completa para obter o novo melhor desempenho de preço da configuração do seu cluster.
limpar
A execução desses testes de dimensionamento em sua conta da AWS pode ter algumas implicações de custo porque provisiona novos clusters do Amazon Redshift, que podem ser cobrados como instâncias sob demanda se você não tiver instâncias reservadas. Ao concluir suas avaliações, recomendamos excluir os clusters do Amazon Redshift para economizar custos. Também recomendamos pausar seus clusters quando eles não estiverem em uso.
Aplicação do Amazon Redshift e práticas recomendadas de compartilhamento de dados
O dimensionamento adequado dos clusters de produtor e consumidor lhe dará um bom começo para obter o melhor desempenho de preço de sua implantação do Amazon Redshift. No entanto, o tamanho não é o único fator que pode maximizar seu desempenho. Nesse caso, entender e seguir as melhores práticas são igualmente importantes.
As melhores práticas gerais de ajuste de desempenho do Amazon Redshift são aplicáveis à implantação de compartilhamento de dados. Certifique-se de que sua implantação siga estas melhores práticas.
Existem inúmeras práticas recomendadas específicas de compartilhamento de dados que você deve seguir para garantir a maximização do desempenho. Consulte isso postar para mais detalhes.
Resumo
Não há recomendação única para tamanhos de cluster de produtores e consumidores. Ele varia de acordo com as cargas de trabalho e seu SLA de desempenho. O objetivo desta postagem é fornecer orientações sobre como você pode avaliar seu desempenho de carga de trabalho de compartilhamento de dados específico para determinar os tamanhos de cluster de consumidor e produtor para obter o melhor desempenho de preço. Considere testar suas cargas de trabalho no produtor e no consumidor usando replay simples antes de adotá-lo na produção para obter o melhor desempenho de preço.
Sobre os autores
 BP Yau é Gerente de Produto Sênior na AWS. Ele é apaixonado por ajudar os clientes a arquitetar soluções de big data para processar dados em escala. Antes da AWS, ele ajudou a Amazon.com Supply Chain Optimization Technologies a migrar seu data warehouse Oracle para o Amazon Redshift e construir sua plataforma de análise de big data de próxima geração usando tecnologias da AWS.
BP Yau é Gerente de Produto Sênior na AWS. Ele é apaixonado por ajudar os clientes a arquitetar soluções de big data para processar dados em escala. Antes da AWS, ele ajudou a Amazon.com Supply Chain Optimization Technologies a migrar seu data warehouse Oracle para o Amazon Redshift e construir sua plataforma de análise de big data de próxima geração usando tecnologias da AWS.
 Sidhanth Muralidhar é gerente técnico principal de contas da AWS. Ele trabalha com grandes clientes corporativos que executam suas cargas de trabalho na AWS. Ele é apaixonado por trabalhar com clientes e ajudá-los a arquitetar cargas de trabalho para custos, confiabilidade, desempenho e excelência operacional em escala em sua jornada para a nuvem. Ele também tem um grande interesse em análise de dados.
Sidhanth Muralidhar é gerente técnico principal de contas da AWS. Ele trabalha com grandes clientes corporativos que executam suas cargas de trabalho na AWS. Ele é apaixonado por trabalhar com clientes e ajudá-los a arquitetar cargas de trabalho para custos, confiabilidade, desempenho e excelência operacional em escala em sua jornada para a nuvem. Ele também tem um grande interesse em análise de dados.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/how-to-get-best-price-performance-from-your-amazon-redshift-data-sharing-deployment/
- 100
- a
- Sobre
- acima
- conformemente
- Conta
- Contas
- Alcançar
- alcançado
- em
- atividades
- adicionado
- Adotando
- Depois de
- contra
- Todos os Produtos
- permite
- sempre
- Amazon
- Amazon.com
- quantidade
- análise
- analítica
- analisar
- e
- Outro
- relevante
- aplicações
- abordagem
- arquitetura
- auditor
- Automatizado
- automaticamente
- disponível
- AWS
- baseado
- Linha de Base
- Porque
- antes
- referência
- MELHOR
- melhores práticas
- Melhor
- entre
- Grande
- Big Data
- construir
- negócio
- capturar
- casas
- casos
- certo
- cadeia
- Alterações
- característica
- características
- carregada
- clientes
- Na nuvem
- Agrupar
- COM
- confortável
- comum
- comparar
- comparação
- completar
- Efetuado
- integrações
- complexidade
- Computar
- condutor
- Configuração
- Considerar
- consistente
- cônsul
- consumidor
- continuar
- continua
- contínuo
- Custo
- custos
- poderia
- crio
- crítico
- Clientes
- dados,
- Análise de Dados
- ciência de dados
- compartilhamento de dados
- entregue
- depende
- desenvolvimento
- detalhes
- Determinar
- diferente
- diretamente
- não
- down
- download
- durante
- facilmente
- ou
- permite
- aprimorada
- Empreendimento
- Meio Ambiente
- igualmente
- especialmente
- Éter (ETH)
- avaliar
- avaliações
- evolução
- exemplo
- exemplos
- excede
- Excelência
- existente
- exportar
- extrato
- falha
- RÁPIDO
- factível
- Característica
- filtro
- Finalmente
- Primeiro nome
- Flexibilidade
- seguir
- seguinte
- segue
- da
- cheio
- fundamentalmente
- mais distante
- Além disso
- Ganho
- geralmente
- geração
- ter
- obtendo
- GitHub
- OFERTE
- Go
- Bom estado, com sinais de uso
- guia
- ajudar
- ajudou
- ajuda
- HORÁRIO
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTTPS
- identificado
- identificar
- Impacto
- impactada
- implementado
- implicações
- importante
- melhoria
- melhorar
- in
- inclui
- Crescimento
- do estado inicial,
- inicialmente
- instância
- em vez disso
- interesse
- envolvido
- isolado
- isolamento
- IT
- viagem
- Afiado
- Saber
- grande
- Maior
- lançado
- Permite
- Alavancagem
- viver
- carregar
- olhar
- manutenção
- fazer
- Gerente
- manual
- Maximizar
- Conheça
- atende
- método
- poder
- migrado
- mínimo
- modelo
- mais
- a maioria
- mover
- movimento
- múltiplo
- você merece...
- necessitando
- Cria
- Novo
- Próximo
- nó
- numeroso
- ocasião
- A bordo
- ONE
- operacional
- Oportunidade
- otimização
- ótimo
- oráculo
- original
- Outros
- de outra forma
- parâmetro
- parâmetros
- apaixonado
- padrão
- realizar
- atuação
- executa
- períodos
- plano
- plataforma
- platão
- Inteligência de Dados Platão
- PlatãoData
- ponto
- possível
- Publique
- práticas
- anterior
- preço
- Diretor
- processo
- produtor
- Produto
- gerente de produto
- Produção
- devidamente
- fornecer
- fornece
- propósito
- Frequentes
- Taxa
- recomendar
- Recomendação
- Recomenda
- reduzir
- Reduzido
- regiões
- Releases
- confiabilidade
- Requisitos
- reservado
- recurso
- restauração
- resultar
- Resultados
- Regra
- Execute
- corrida
- mesmo
- Salvar
- AMPLIAR
- escalável
- Escala
- cenários
- Ciência
- sem problemas
- Seção
- seguro
- firmemente
- Buscar
- serviço
- instalação
- Partilhar
- compartilhando
- rede de apoio social
- mostrar
- Shows
- semelhante
- simples
- Tamanho
- tamanhos
- menor
- Instantâneo
- solução
- Soluções
- alguns
- fonte
- específico
- divisão
- Spot
- padrão
- começo
- começado
- Comece
- declarações
- Passo
- Passos
- Ainda
- armazenamento
- loja
- Estratégia
- de streaming
- subseqüente
- supply
- cadeia de suprimentos
- Otimização da cadeia de suprimentos
- ajuda
- doce
- Tire
- Target
- Dados Técnicos:
- Tecnologias
- teste
- ensaio
- testes
- A
- A fonte
- deles
- três
- Através da
- tempo
- para
- ferramenta
- ferramentas
- tipos
- compreensão
- usar
- caso de uso
- Utilizador
- Vácuo
- O Quê
- qual
- QUEM
- precisarão
- sem
- trabalhar
- trabalho
- investimentos
- zefirnet