Introdução
Vimos alguns termos sofisticados para IA e aprendizagem profunda, como modelos pré-treinados, aprendizagem por transferência, etc. Deixe-me educá-lo com uma tecnologia amplamente utilizada e uma das mais importantes e eficazes: aprendizagem por transferência com YOLOv5.
You Only Look Once, ou YOLO, é um dos métodos de identificação de objetos baseados em aprendizagem profunda mais amplamente usados. Usando um conjunto de dados personalizado, este artigo mostrará como treinar uma de suas variações mais recentes, YOLOv5.
Objetivos de aprendizagem
- Este artigo se concentrará principalmente no treinamento do modelo YOLOv5 em uma implementação de conjunto de dados personalizado.
- Veremos o que são modelos pré-treinados e o que é aprendizagem por transferência.
- Vamos entender o que é o YOLOv5 e por que estamos usando a versão 5 do YOLO.
Então, sem perder tempo, vamos começar o processo
Tabela de conteúdo
- Modelos Pré-Treinados
- Aprendizagem por transferência
- O que e por que YOLOv5?
- Etapas envolvidas na aprendizagem por transferência
- Implementação
- Alguns desafios que você pode enfrentar
- Conclusão
Modelos pré-treinados
Você deve ter ouvido os cientistas de dados usarem amplamente o termo “modelo pré-treinado”. Depois de explicar o que um modelo/rede de aprendizado profundo faz, explicarei o termo. Um modelo de aprendizagem profunda é um modelo que contém várias camadas empilhadas juntas para servir a um propósito solitário, como classificação, detecção, etc. As redes de aprendizagem profunda aprendem descobrindo estruturas complicadas nos dados que lhes são fornecidos e salvando os pesos em um arquivo que são usados posteriormente para executar tarefas semelhantes. Modelos pré-treinados já são modelos treinados de Deep Learning. O que isso significa é que eles já foram treinados em um enorme conjunto de dados contendo milhões de imagens.
Aqui está como o TensorFlow o site define modelos pré-treinados: Um modelo pré-treinado é uma rede salva que foi previamente treinada em um grande conjunto de dados, normalmente em uma tarefa de classificação de imagens em grande escala.
Alguns altamente otimizados e extraordinariamente eficientes modelos pré-treinados estão disponíveis na internet. Diferentes modelos são usados para realizar diferentes tarefas. Alguns dos modelos pré-treinados são VGG-16, VGG-19, YOLOv5, YOLOv3 e ResNet 50.
Qual modelo usar depende da tarefa que você deseja executar. Por exemplo, se eu quiser realizar um detecção de objetos tarefa, usarei o modelo YOLOv5.
Aprendizagem por transferência
Aprendizagem por transferência é a técnica mais importante que facilita a tarefa de um cientista de dados. Treinar um modelo é uma tarefa pesada e demorada; se um modelo for treinado do zero, geralmente não produz resultados muito bons. Mesmo se treinarmos um modelo semelhante a um modelo pré-treinado, ele não terá um desempenho tão eficaz e pode levar semanas para o treinamento de um modelo. Em vez disso, podemos usar os modelos pré-treinados e os pesos já aprendidos, treinando-os em um conjunto de dados personalizado para realizar uma tarefa semelhante. Esses modelos são altamente eficientes e refinados em termos de arquitetura e desempenho, e chegaram ao topo com melhor desempenho em diferentes competições. Esses modelos são treinados em grandes quantidades de dados, tornando-os mais diversificados em conhecimento.
Portanto, transferir aprendizagem significa basicamente transferir o conhecimento adquirido ao treinar o modelo em dados anteriores para ajudar o modelo a aprender melhor e mais rápido para executar uma tarefa diferente, mas semelhante.
Por exemplo, usando um YOLOv5 para detecção de objetos, mas o objeto é algo diferente dos dados anteriores do objeto usados.
O que e por que YOLOv5?
YOLOv5 é um modelo pré-treinado que significa que você só olha quando a versão 5 é usada para detecção de objetos em tempo real e provou ser altamente eficiente em termos de precisão e tempo de inferência. Existem outras versões do YOLO, mas como seria de prever, o YOLOv5 tem um desempenho melhor do que outras versões. YOLOv5 é rápido e fácil de usar. É baseado na estrutura PyTorch, que possui uma comunidade maior que o Yolo v4 Darknet.
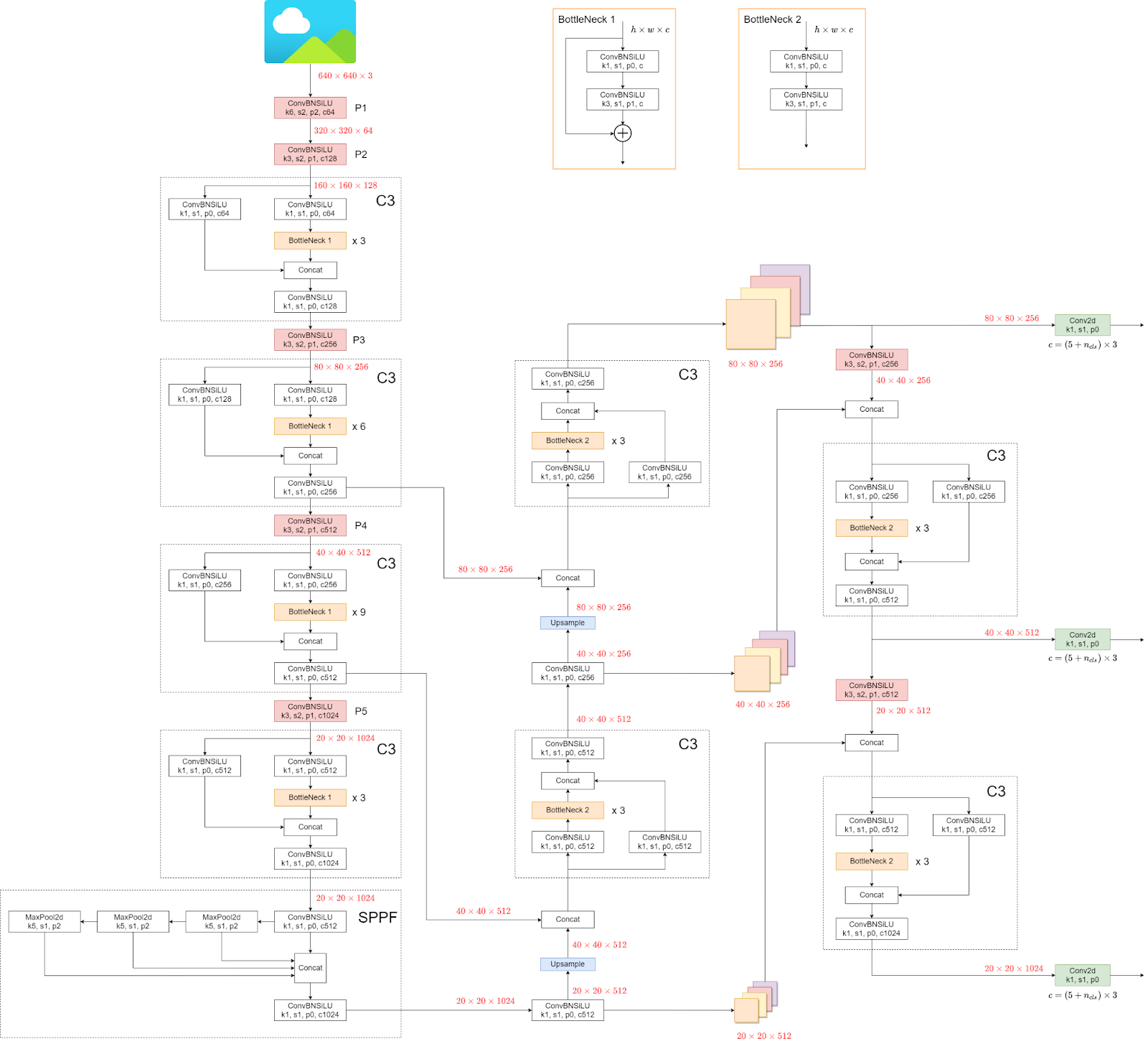
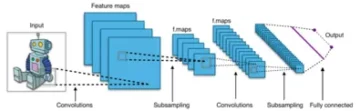
Veremos agora a arquitetura do YOLOv5.
A estrutura pode parecer confusa, mas não importa, pois não precisamos olhar para a arquitetura, em vez disso, usar diretamente o modelo e os pesos.
Na aprendizagem por transferência, usamos o conjunto de dados personalizado, ou seja, os dados que o modelo nunca viu antes OU os dados nos quais o modelo não foi treinado. Como o modelo já está treinado em um grande conjunto de dados, já temos os pesos. Agora podemos treinar o modelo para várias épocas nos dados com os quais queremos trabalhar. O treinamento é necessário porque o modelo viu os dados pela primeira vez e exigirá algum conhecimento para executar a tarefa.
Etapas envolvidas na aprendizagem por transferência
A aprendizagem por transferência é um processo simples e podemos fazê-lo em algumas etapas simples:
- Preparação de dados
- O formato certo para as anotações
- Mude algumas camadas se quiser
- Treine novamente o modelo para algumas iterações
- Validar/Testar
Preparação de dados
A preparação de dados pode ser demorada se os dados escolhidos forem um pouco grandes. Preparação de dados significa anotar as imagens, que é um processo em que você rotula as imagens fazendo uma caixa ao redor do objeto na imagem. Ao fazer isso, as coordenadas do objeto marcado serão salvas em um arquivo que será então alimentado no modelo para treinamento. Existem alguns sites, como faz sentido.ai e roboflow. com, o que pode ajudá-lo a rotular os dados.
Veja como você pode anotar os dados do modelo YOLOv5 em makesense.ai.
1. Visite a https://www.makesense.ai/.
2. Clique em começar no canto inferior direito da tela.
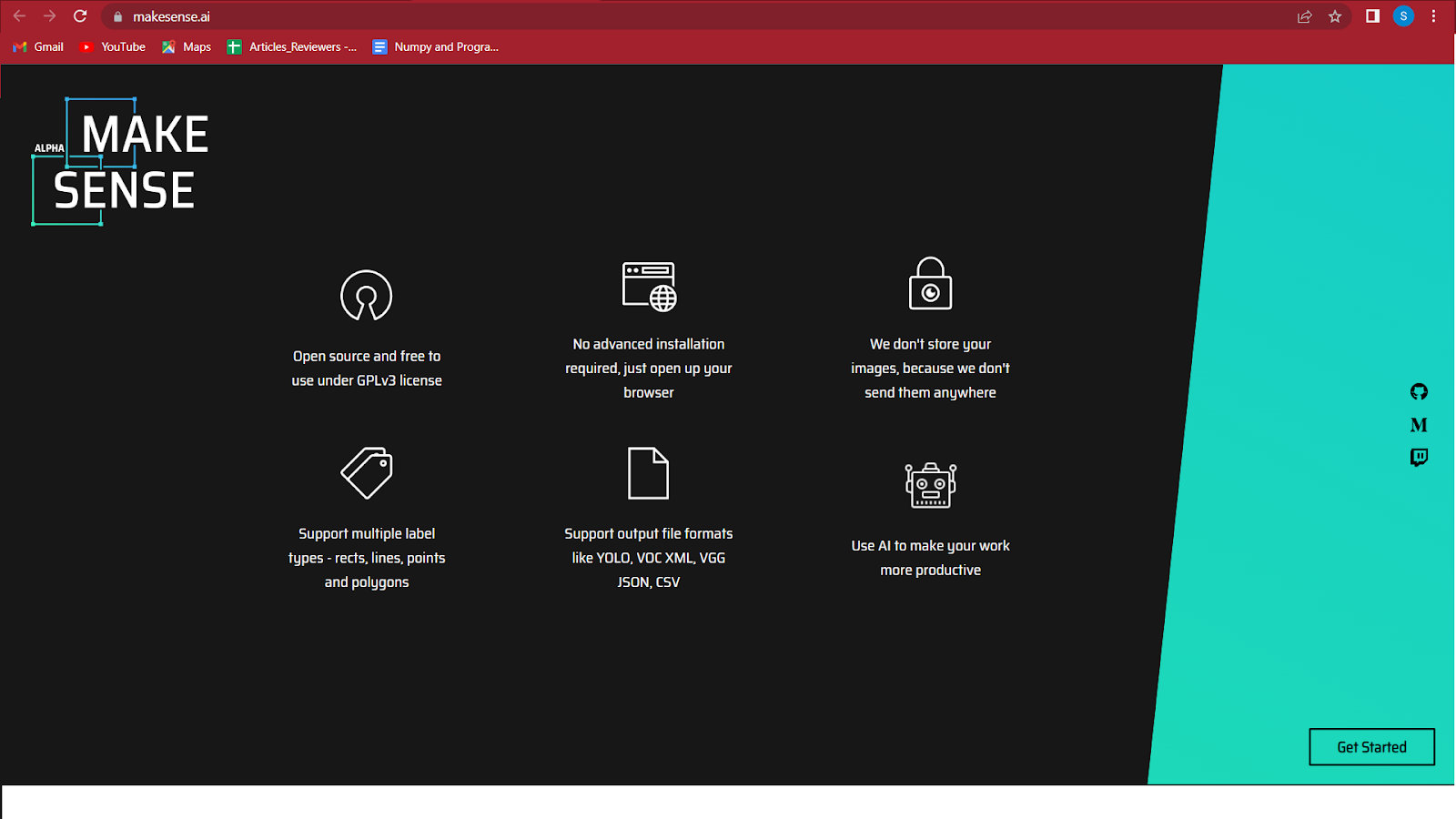
3. Selecione as imagens que deseja rotular clicando na caixa destacada no centro.
Carregue as imagens que deseja anotar e clique em detecção de objetos.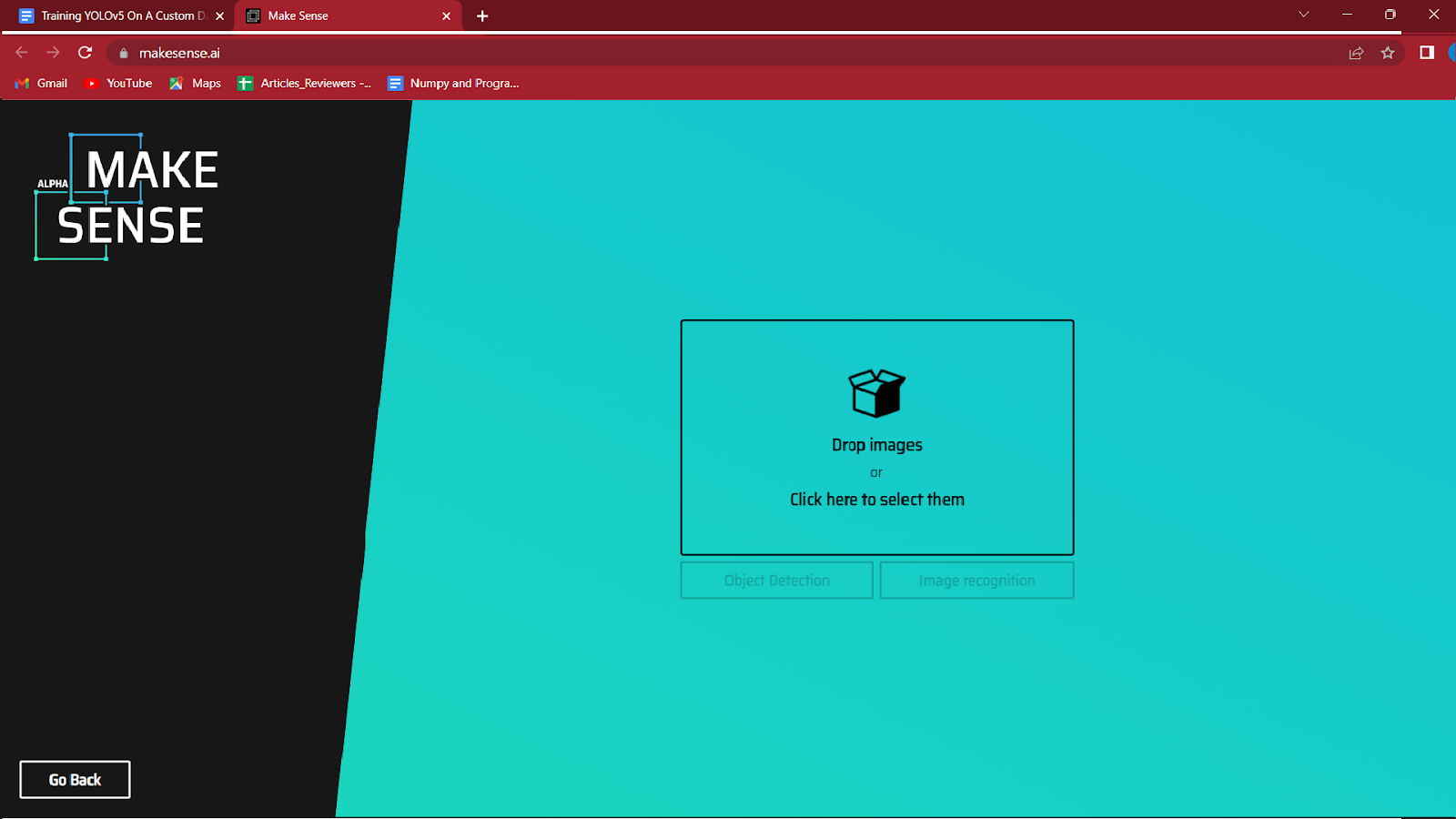
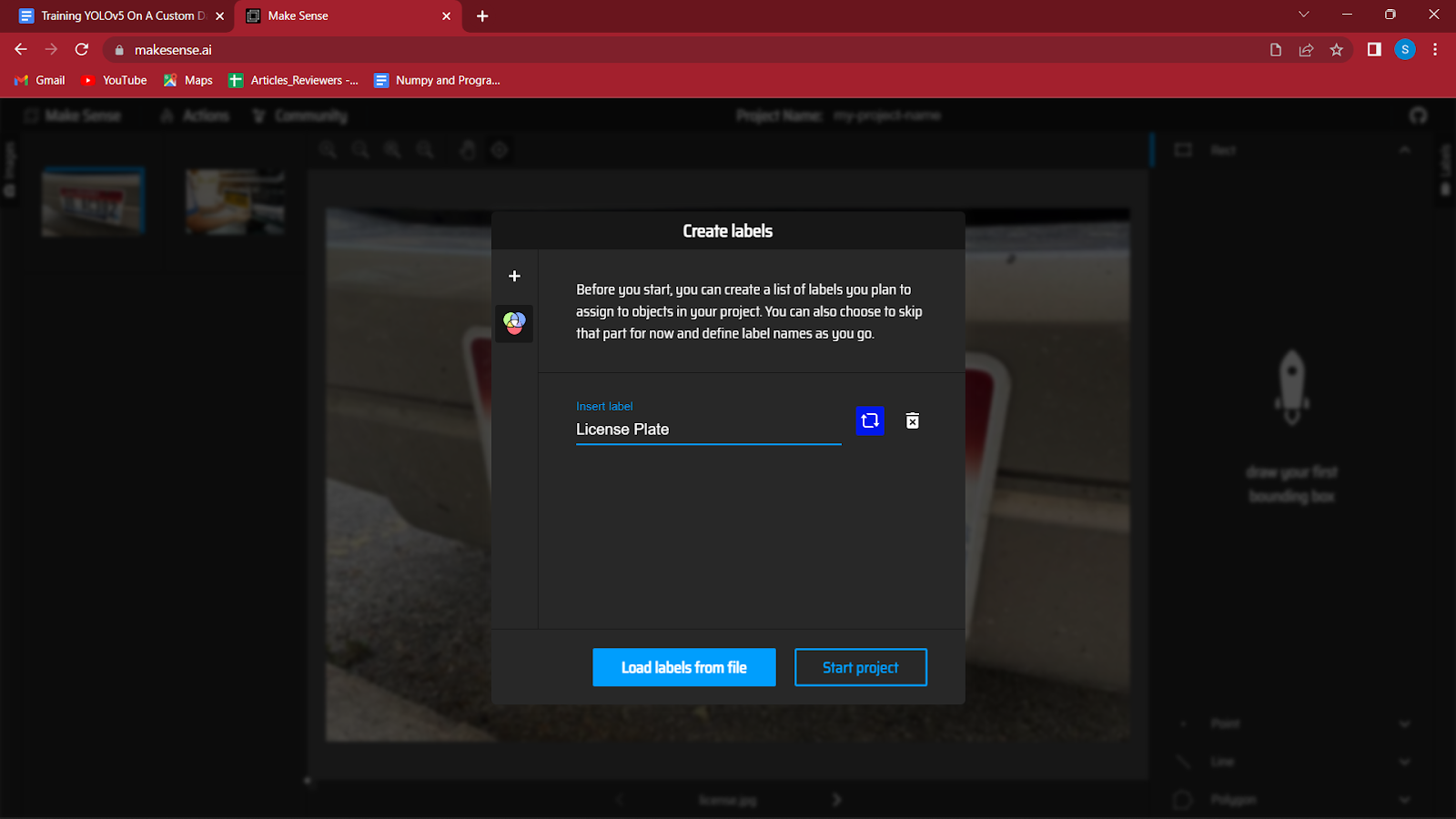
4. Após carregar as imagens, você será solicitado a criar rótulos para as diferentes classes do seu conjunto de dados.
Estou detectando placas de um veículo, então o único rótulo que usarei é “Placa de Veículo”. Você pode criar mais rótulos simplesmente pressionando Enter clicando no botão ‘+’ no lado esquerdo da caixa de diálogo.
Depois de criar todos os rótulos, clique em iniciar projeto.
Se você perdeu algum rótulo, poderá editá-lo mais tarde clicando nas ações e depois editando os rótulos.
5. Comece criando uma caixa delimitadora ao redor do objeto na imagem. Este exercício pode ser um pouco divertido inicialmente, mas com dados muito grandes pode ser cansativo.
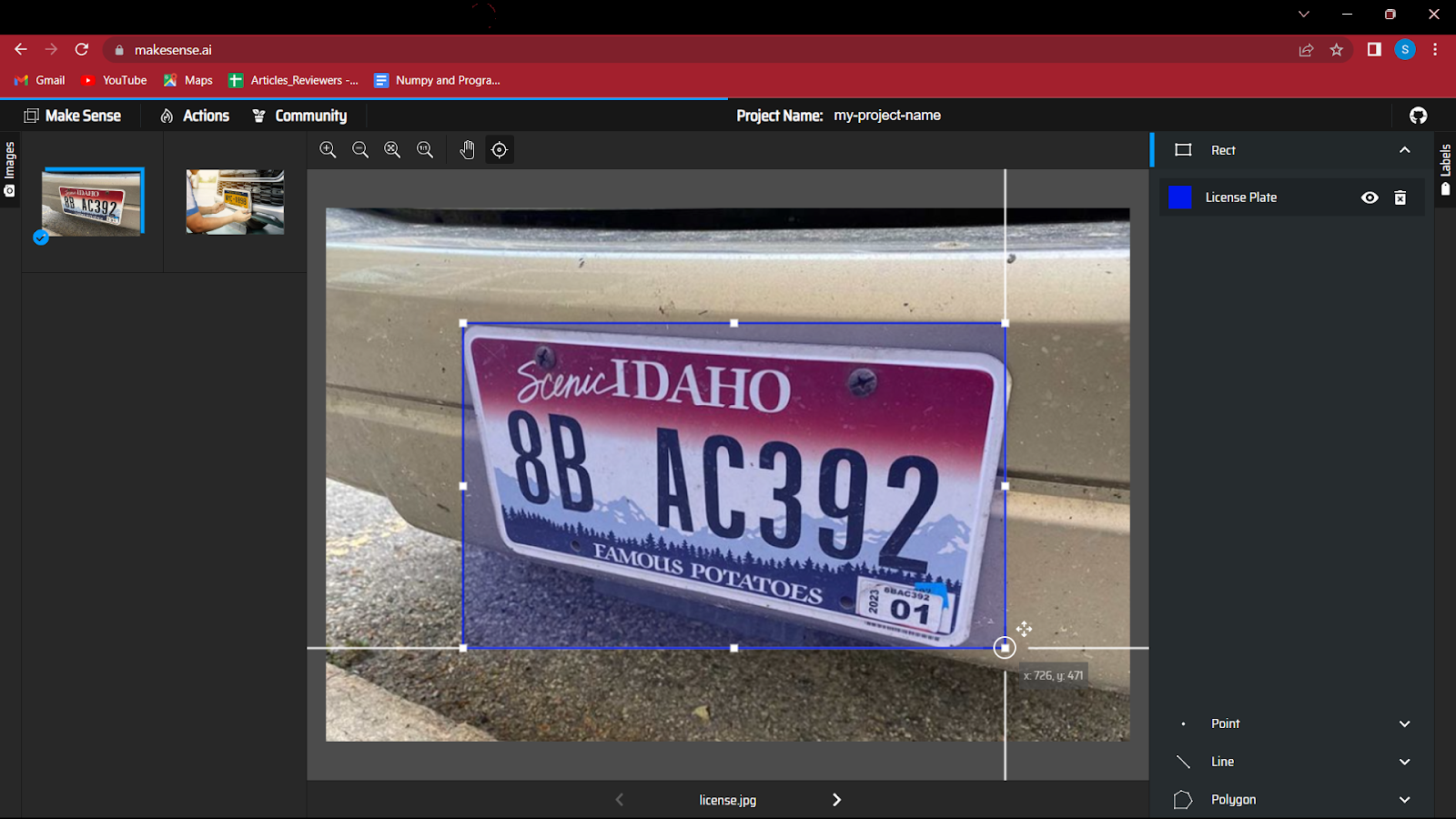
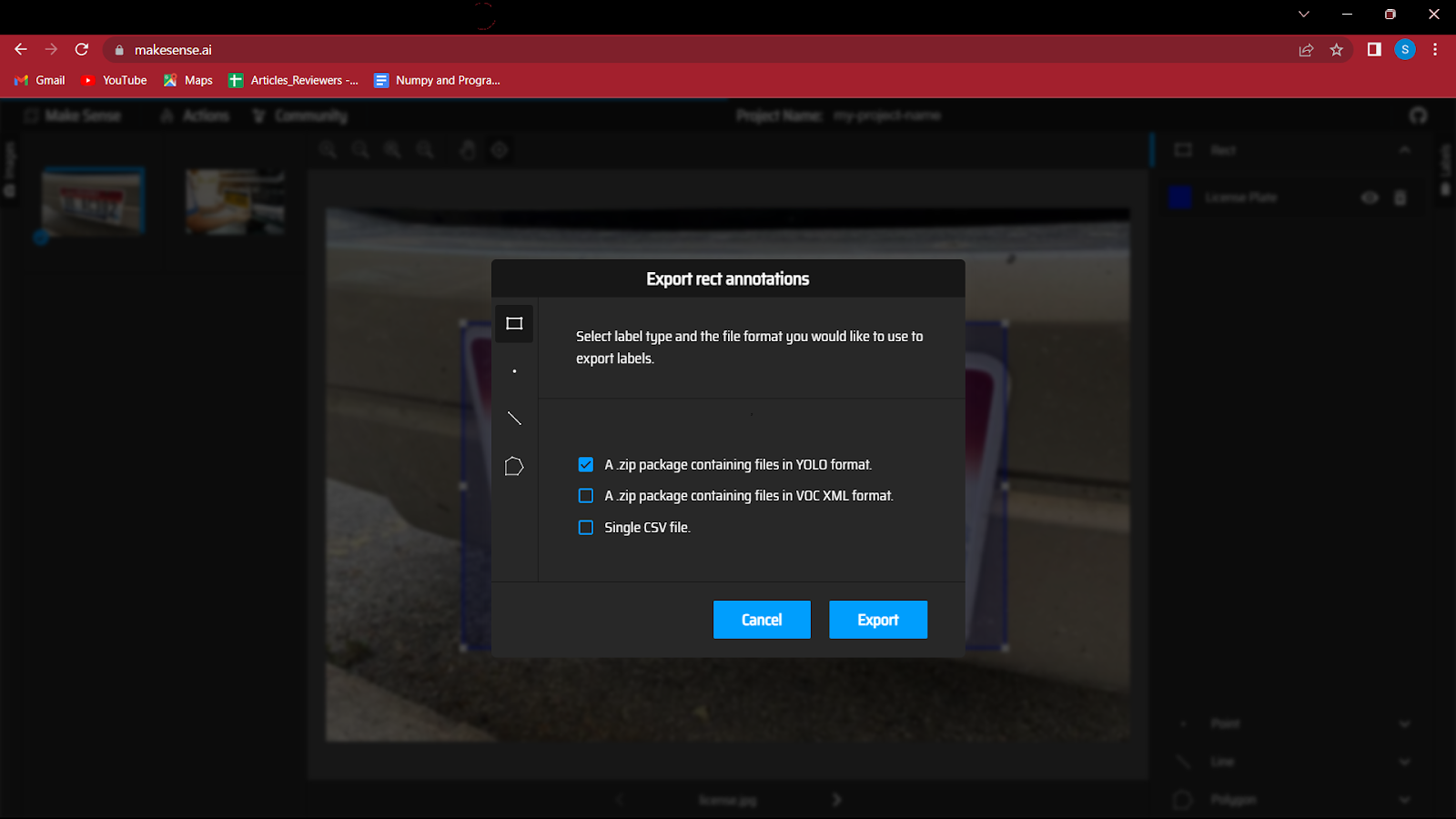
6. Após anotar todas as imagens você precisa salvar o arquivo que conterá as coordenadas das caixas delimitadoras junto com a classe.
Então você precisa ir até o botão de ações e clicar em exportar anotações, não se esqueça de marcar a opção ‘Um pacote zip contendo arquivos no formato YOLO’, pois isso salvará os arquivos no formato correto conforme exigido no modelo YOLO.
7. Este é um passo significativo, portanto siga-o com atenção.
Depois de ter todos os arquivos e imagens, crie uma pasta com qualquer nome. Clique na pasta e crie mais duas pastas com nomes de imagens e rótulos dentro da pasta. Não se esqueça de nomear a pasta igual ao acima, pois o modelo procura automaticamente os rótulos depois de alimentar o caminho de treinamento no comando.
Para se ter uma ideia da pasta, criei uma pasta chamada ‘CarsData’ e nessa pasta criei duas pastas – ‘images’ e ‘labels’.
Dentro das duas pastas, você deve criar mais duas pastas chamadas ‘train’ e ‘val’. Na pasta de imagens você pode dividir as imagens de acordo com sua vontade, mas é preciso ter cuidado ao dividir a etiqueta, pois as etiquetas devem corresponder às imagens que você dividiu
8. Agora faça um arquivo zip da pasta e carregue-o no drive para que possamos usá-lo no Colab.
Implementação
Chegaremos agora à parte de implementação, que é muito simples, mas complicada. Se você não souber exatamente quais arquivos alterar, não será possível treinar o modelo no conjunto de dados personalizado.
Então aqui estão os códigos que você deve seguir para treinar o modelo YOLOv5 em um conjunto de dados personalizado
Eu recomendo que você use o Google Colab para este tutorial, pois ele também fornece GPU que fornece cálculos mais rápidos.
1. !git clone https://github.com/ultralytics/yolov5
Isso fará uma cópia do repositório YOLOv5, que é um repositório GitHub criado por ultralytics.
2. cd yolov5
Este é um comando shell de linha de comando usado para alterar o diretório de trabalho atual para o diretório YOLOv5.
3. !pip install -r requisitos.txt
Este comando instalará todos os pacotes e bibliotecas usados no treinamento do modelo.
4. !descompacte ‘/content/drive/MyDrive/CarsData.zip’
Descompactando a pasta que contém imagens e rótulos no google colab
Aí vem o passo mais importante…
Agora você executou quase todas as etapas e precisa escrever mais uma linha de código que irá treinar o modelo, mas, antes disso, você precisa realizar mais algumas etapas e alterar alguns diretórios para fornecer o caminho do seu conjunto de dados customizado e treine seu modelo com base nesses dados.
Aqui está o que você precisa fazer.
Após realizar os 4 passos acima, você terá a pasta yolov5 em seu google colab. Vá para a pasta yolov5 e clique na pasta ‘data’. Agora você verá uma pasta chamada ‘coco128.yaml’.
Vá em frente e baixe esta pasta.
Depois que a pasta for baixada, você precisará fazer algumas alterações nela e carregá-la de volta para a mesma pasta de onde baixou.
Vejamos agora o conteúdo do arquivo que baixamos e será parecido com isto.
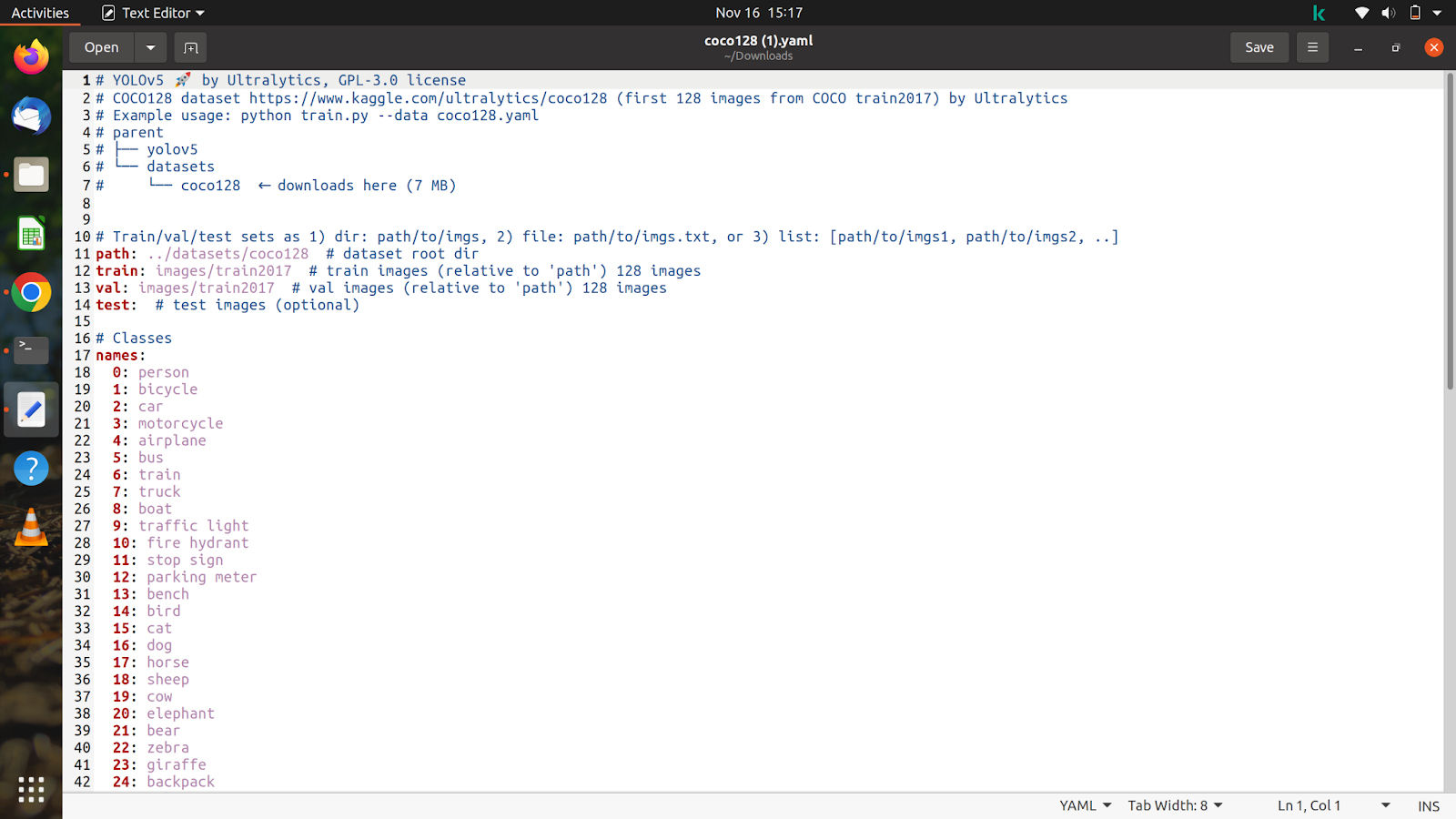
Vamos personalizar este arquivo de acordo com nosso conjunto de dados e anotações.
Já descompactamos o conjunto de dados no colab, então vamos copiar o caminho do nosso trem e imagens de validação. Após copiar o caminho das imagens do trem, que estará na pasta do conjunto de dados e se parece com ‘/content/yolov5/CarsData/images/train’, cole-o no arquivo coco128.yaml, que acabamos de baixar.
Faça o mesmo com as imagens de teste e validação.
Agora, depois de terminarmos isso, mencionaremos o número de classes como ‘nc: 1’. O número de turmas, neste caso, é de apenas 1. A seguir citaremos o nome conforme imagem abaixo. Remova todas as outras classes e a parte comentada, que não é necessária, após o que nosso arquivo deverá ficar parecido com isto.
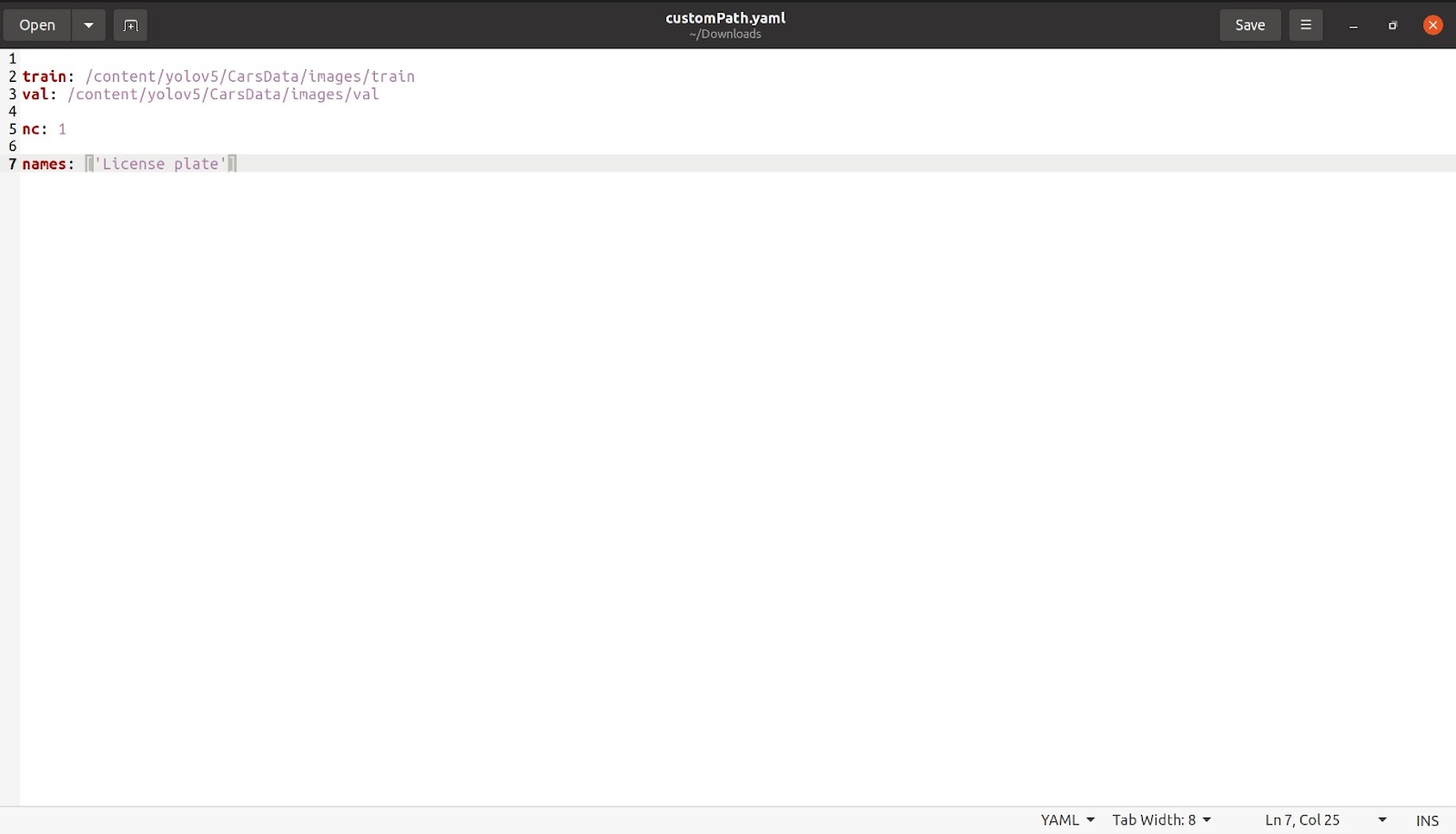
Salve este arquivo com o nome que desejar. Salvei o arquivo com o nome customPath.yaml e agora carrego esse arquivo de volta para o colab no mesmo local onde estava coco128.yaml.
Agora terminamos a parte de edição e estamos prontos para treinar o modelo.
Execute o comando a seguir para treinar seu modelo para algumas interações em seu conjunto de dados personalizado.
Não se esqueça de alterar o nome do arquivo que você carregou ('customPath.yaml). Você também pode alterar o número de épocas em que deseja treinar o modelo. Nesse caso, vou treinar o modelo apenas por 3 épocas.
5. !python train.py –img 640 –batch 16 –épocas 10 –data /content/yolov5/customPath.yaml –weights yolov5s.pt
Lembre-se do caminho onde você carregou a pasta. Se o caminho for alterado, os comandos não funcionarão de todo.
Depois de executar este comando, seu modelo deverá começar a treinar e você verá algo assim na tela.
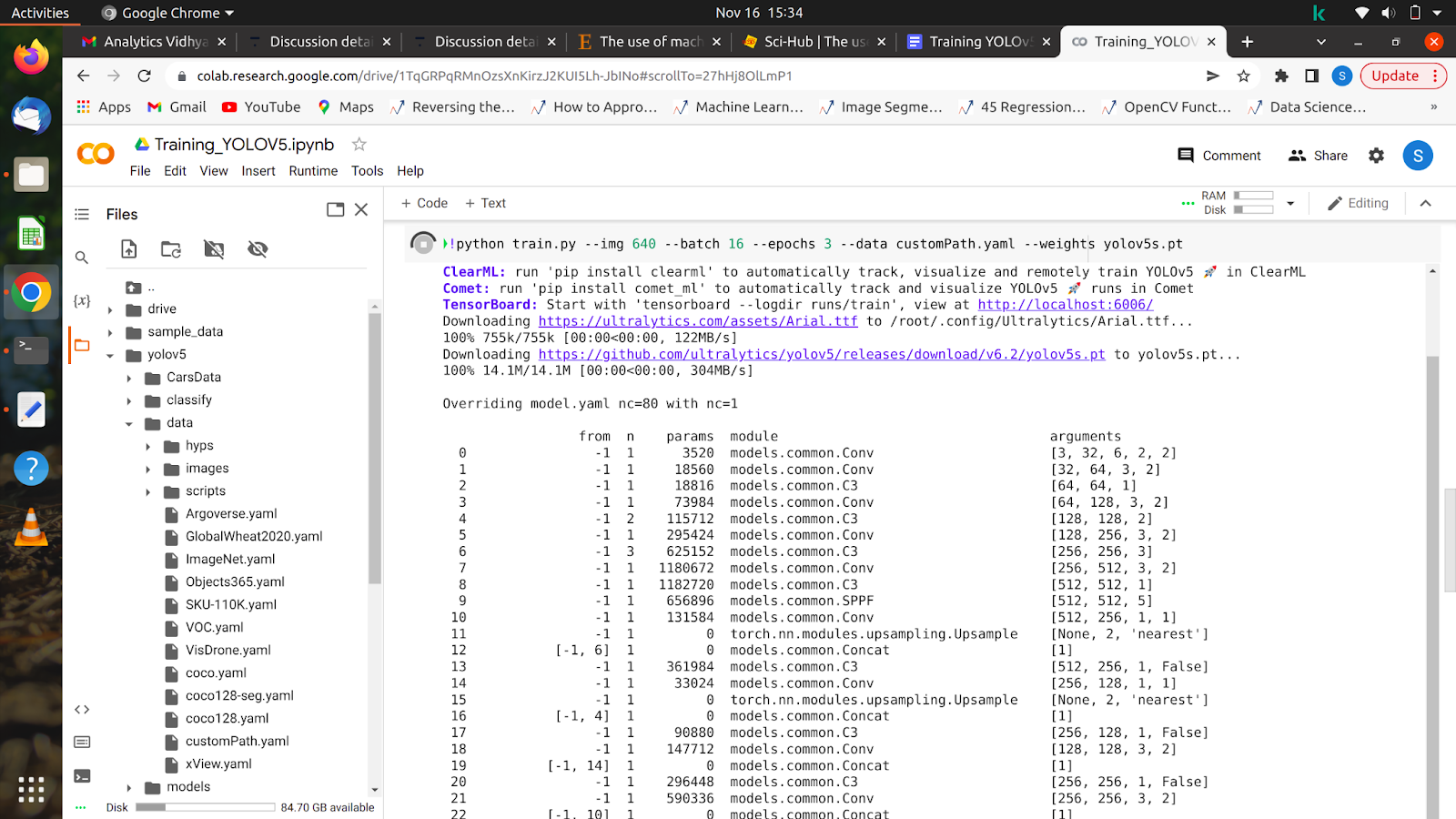
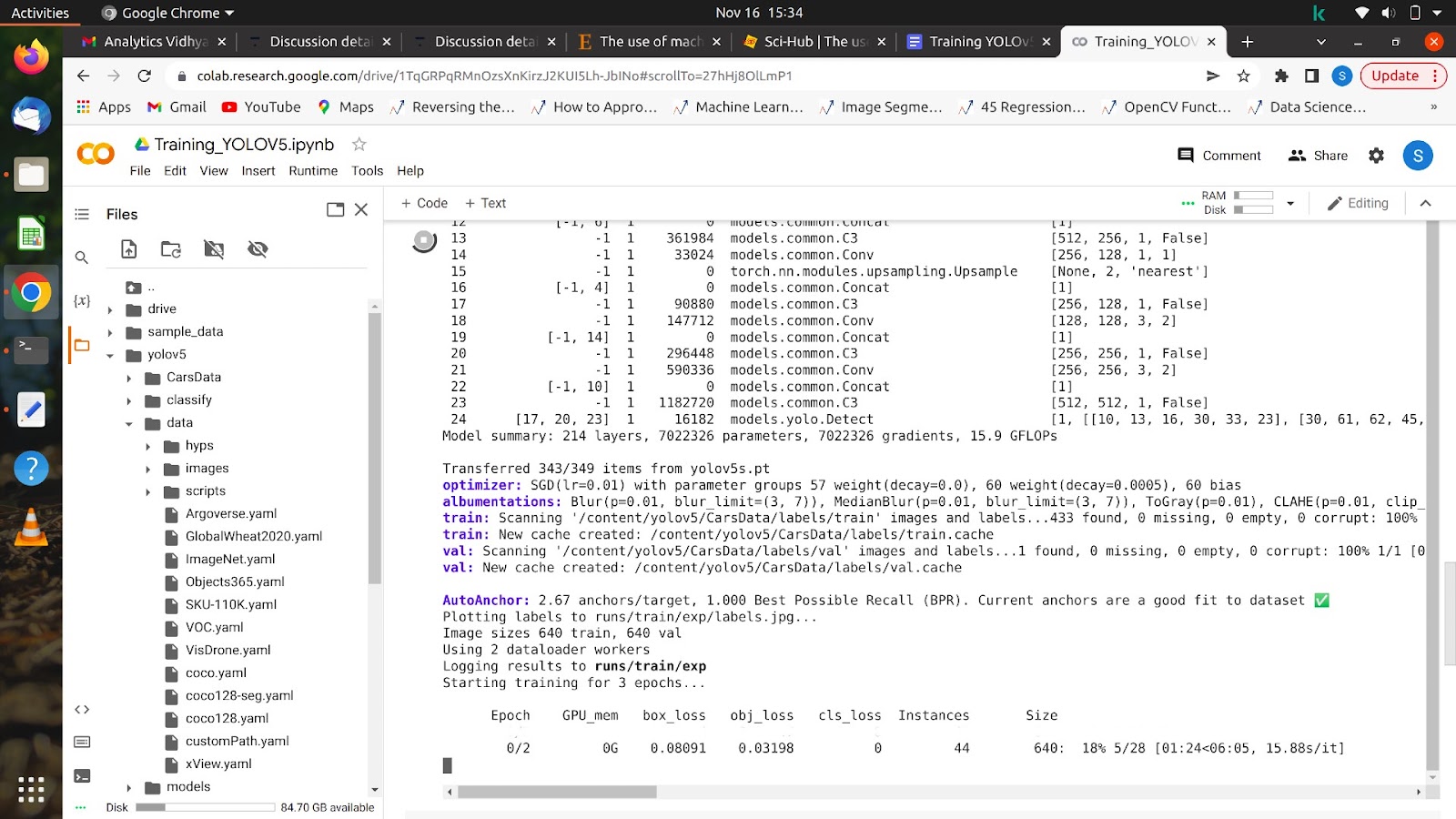
Depois que todas as épocas forem concluídas, seu modelo poderá ser testado em qualquer imagem.
Você pode fazer mais personalizações no arquivo detect.py sobre o que deseja salvar e o que não gosta, as detecções onde as placas são detectadas, etc.
6. !python detect.py –weight /content/yolov5/runs/train/exp/weights/best.pt –source path_of_the_image
Você pode usar este comando para testar a previsão do modelo em algumas imagens.
Alguns desafios que você pode enfrentar
Embora as etapas explicadas acima estejam corretas, existem alguns problemas que você pode enfrentar se não segui-las exatamente.
- Caminho errado: Isso pode ser uma dor de cabeça ou um problema. Se você entrou no caminho errado em algum lugar no treinamento da imagem, pode não ser fácil identificá-lo e você não conseguirá treinar o modelo.
- Formato errado de rótulos: Este é um problema generalizado enfrentado pelas pessoas durante o treinamento de um YOLOv5. O modelo aceita apenas um formato em que cada imagem possua seu próprio arquivo de texto com o formato desejado em seu interior. Freqüentemente, um arquivo no formato XLS ou um único arquivo CSV é alimentado na rede, resultando em um erro. Se você estiver baixando os dados de algum lugar, em vez de anotar cada imagem, pode haver um formato de arquivo diferente no qual os rótulos são salvos. Aqui está um artigo para converter o formato XLS para o formato YOLO. (link após a conclusão do artigo).
- Não nomear os arquivos corretamente: Não nomear o arquivo corretamente levará novamente a um erro. Preste atenção aos passos ao nomear as pastas e evite esse erro.
Conclusão
Neste artigo, aprendemos o que é aprendizagem por transferência e o modelo pré-treinado. Aprendemos quando e por que usar o modelo YOLOv5 e como treinar o modelo em um conjunto de dados personalizado. Passamos por cada etapa, desde a preparação do conjunto de dados até a alteração dos caminhos e, finalmente, alimentando-os na rede na implementação da técnica, e entendemos completamente as etapas. Também analisamos problemas comuns enfrentados durante o treinamento de um YOLOv5 e suas soluções. Espero que este artigo tenha ajudado você a treinar seu primeiro YOLOv5 em um conjunto de dados personalizado e que você goste do artigo.
Relacionado
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://www.analyticsvidhya.com/blog/2023/02/how-to-train-a-custom-dataset-with-yolov5/
- 1
- 10
- a
- Capaz
- acima
- Aceita
- Segundo
- precisão
- ações
- Depois de
- à frente
- AI
- Todos os Produtos
- já
- quantidades
- e
- arquitetura
- por aí
- artigo
- por WhatsApp.
- automaticamente
- disponível
- evitar
- em caminho duplo
- baseado
- Basicamente
- antes
- abaixo
- Melhor
- Pouco
- Inferior
- Caixa
- caixas
- botão
- cuidadoso
- cuidadosamente
- casas
- CD
- Centralização de
- desafios
- alterar
- Alterações
- mudança
- verificar
- escolhido
- classe
- aulas
- classificação
- código
- como
- comentou
- comum
- comunidade
- Efetuado
- realização
- complicado
- cálculos
- confuso
- contém
- conteúdo
- converter
- copiando
- corretamente
- crio
- criado
- Criar
- Atual
- personalizadas
- personalização
- personalizar
- darknet
- dados,
- Preparação de dados
- cientista de dados
- profundo
- deep learning
- Define
- depende
- detectou
- Detecção
- Diálogo
- diferente
- diretamente
- diretórios
- descobrindo
- diferente
- fazer
- não
- download
- distância
- cada
- Facilita
- educar
- Eficaz
- efetivamente
- eficiente
- Entrar
- entrou
- épocas
- erro
- etc.
- Mesmo
- Cada
- exatamente
- exemplo
- Exercício
- Explicação
- explicado
- explicando
- exportar
- extraordinariamente
- Rosto
- enfrentou
- RÁPIDO
- mais rápido
- Alimentado
- alimentação
- poucos
- Envie o
- Arquivos
- Finalmente
- Primeiro nome
- primeira vez
- Foco
- seguir
- seguinte
- formato
- Quadro
- da
- Diversão
- ter
- GitHub
- OFERTE
- Go
- vai
- Bom estado, com sinais de uso
- GPU
- cabeça
- ouviu
- ajudar
- ajudou
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- Destaque
- altamente
- batendo
- esperança
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTTPS
- enorme
- idéia
- identificação
- identificar
- imagem
- imagens
- implementação
- importante
- in
- inicialmente
- instalar
- em vez disso
- interações
- Internet
- envolvido
- IT
- Saber
- Conhecimento
- O rótulo
- Rótulos
- grande
- em grande escala
- Maior
- camadas
- conduzir
- APRENDER
- aprendido
- aprendizagem
- bibliotecas
- Licença
- Line
- LINK
- carregamento
- olhar
- olhou
- OLHARES
- moldadas
- fazer
- Fazendo
- marcado
- Match
- Importância
- max-width
- significa
- métodos
- poder
- milhões
- mente
- modelo
- modelos
- mais
- a maioria
- nome
- Nomeado
- nomeando
- você merece...
- necessário
- rede
- redes
- número
- objeto
- Detecção de Objetos
- ONE
- otimizado
- Opção
- ordem
- Outros
- próprio
- pacote
- pacotes
- parte
- caminho
- Pagar
- Pessoas
- realizar
- atuação
- realização
- executa
- Lugar
- platão
- Inteligência de Dados Platão
- PlatãoData
- predizer
- predição
- preparação
- anterior
- anteriormente
- Problema
- problemas
- processo
- projeto
- comprovado
- fornece
- propósito
- pytorch
- pronto
- em tempo real
- recentemente
- recomendar
- refinado
- remover
- repositório
- requerer
- requeridos
- Requisitos
- resultando
- Resultados
- Execute
- mesmo
- Salvar
- poupança
- Cientista
- cientistas
- Peneira
- servir
- concha
- rede de apoio social
- mostrar
- mostrando
- periodo
- semelhante
- simples
- simplesmente
- desde
- solteiro
- So
- solução
- alguns
- algo
- algum lugar
- divisão
- empilhado
- fica
- começo
- começado
- Passo
- Passos
- estrutura
- tal
- Tire
- Tarefa
- tarefas
- Equipar
- condições
- teste
- A
- deles
- completamente
- Através da
- tempo
- demorado
- para
- juntos
- topo
- Trem
- treinado
- Training
- transferência
- Transferir
- tutorial
- tipicamente
- compreender
- Entendido
- usar
- geralmente
- validação
- vário
- veículo
- versão
- Site
- sites
- semanas
- O Quê
- qual
- enquanto
- largamente
- generalizada
- precisarão
- sem
- Atividades:
- trabalhar
- seria
- escrever
- Errado
- yaml
- Yolo
- investimentos
- zefirnet
- Zip