Este é um post convidado co-escrito com Raghu Boppanna do Vanguard.
At Vanguarda, a linha de negócios Enterprise Advice melhora os resultados dos investidores por meio do acesso digital a aconselhamento financeiro superior, personalizado e acessível. Eles tornaram isso possível, em parte, gerando economias de escala em todo o mundo para investidores com uma plataforma técnica altamente resiliente e eficiente. A Vanguard optou por uma arquitetura multirregional para essa carga de trabalho para ajudar a proteger contra deficiências de serviços regionais. Para fins de alta disponibilidade, é necessário disponibilizar os dados usados pela carga de trabalho não apenas na região primária, mas também na região secundária com atraso de replicação mínimo. No caso de falha de serviço na região primária, a solução deve ser capaz de fazer failover para a região secundária com o mínimo possível de perda de dados e a capacidade de retomar a ingestão de dados.
O Vanguard Cloud Technology Office e a AWS fizeram uma parceria para criar uma solução de infraestrutura na AWS que atendesse aos seus requisitos de resiliência. A solução de várias regiões permite um mecanismo robusto de failover, com capacidade de observação e recuperação integradas. A solução também oferece suporte ao streaming de dados de várias fontes para diferentes streams de dados do Kinesis. A solução está sendo implementada nas diferentes linhas de equipes de negócios para melhorar a postura de resiliência de suas cargas de trabalho.
O caso de uso discutido aqui requer Change Data Capture (CDC) para transmitir dados de uma fonte de dados remota (mainframe DB2) para Fluxos de dados do Amazon Kinesis, porque a capacidade de negócios depende desses dados. O Kinesis Data Streams é um serviço de streaming totalmente gerenciado, massivamente escalável, durável e de baixo custo que pode capturar e transmitir continuamente grandes quantidades de dados de várias fontes e disponibilizar os dados para consumo em milissegundos. O serviço foi criado para ser altamente resiliente e usa várias zonas de disponibilidade para processar e armazenar dados.
A solução discutida nesta postagem explica como a AWS e a Vanguard inovaram para criar uma arquitetura resiliente para atender às suas metas de alta disponibilidade.
Visão geral da solução
A solução usa AWS Lambda para replicar dados de streams de dados do Kinesis na região primária para uma região secundária. No caso de qualquer deficiência de serviço impactar o pipeline do CDC, o processo de failover promove a região secundária a primária para os produtores e consumidores. Nós usamos Tabelas globais do Amazon DynamoDB para pontos de verificação de replicação que permite retomar o fluxo de dados do ponto de verificação e também mantém um sinalizador de configuração de região primária que evita um loop de replicação infinito dos mesmos dados para frente e para trás.
A solução também oferece flexibilidade para os consumidores do Kinesis Data Streams usarem a região primária ou secundária na mesma conta da AWS.
O diagrama a seguir ilustra a arquitetura de referência.
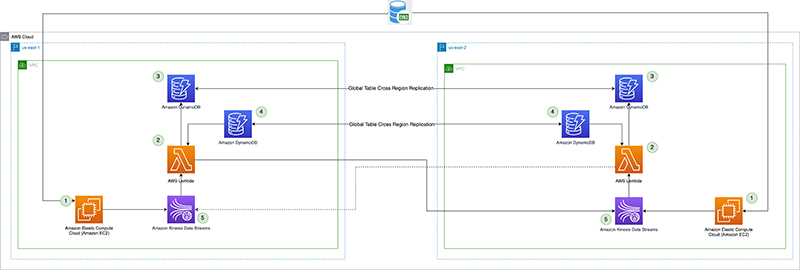
Vejamos cada componente em detalhes:
- Processador CDC (produtor) – Nesta arquitetura de referência, o produtor é implantado em Amazon Elastic Compute Nuvem (Amazon EC2) nas regiões primária e secundária, e está ativo na região primária e em modo de espera na região secundária. Ele captura dados CDC da fonte de dados externa (como um banco de dados DB2, conforme mostrado na arquitetura acima) e transmite para o Kinesis Data Streams na região primária. Vanguarda usa um 3rd ferramenta de terceiros Qlik Replicate como seu processador CDC. Ele produz uma carga útil bem formada, incluindo o carimbo de data/hora de confirmação do DB2 para o fluxo de dados do Kinesis, além dos dados de linha reais da fonte de dados remota. (
example-stream-1neste exemplo). O código a seguir é um payload de amostra contendo apenas a chave primária do registro que foi alterado e o carimbo de data/hora do commit (para simplificar, o restante dos dados da linha da tabela não é mostrado abaixo):{ "eventSource": "aws:kinesis", "kinesis": { "ApproximateArrivalTimestamp": "Mon July 18 20:00:00 UTC 2022", "SequenceNumber": "49544985256907370027570885864065577703022652638596431874", "PartitionKey": "12349999", "KinesisSchemaVersion": "1.0", "Data": "eyJLZXkiOiAxMjM0OTk5OSwiQ29tbWl0VGltZXN0YW1wIjogIjIwMjItMDctMThUMjA6MDA6MDAifQ==" }, "eventId": "shardId-000000000000:49629136582982516722891309362785181370337771525377097730", "invokeIdentityArn": "arn:aws:iam::6243876582:role/kds-crr-LambdaRole-1GZWP67437SD", "eventName": "aws:kinesis:record", "eventVersion": "1.0", "eventSourceARN": "arn:aws:kinesis:us-east-1:6243876582:stream/kds-stream-1/consumer/kds-crr:6243876582", "awsRegion": "us-east-1" }O valor decodificado em Base64 de
Dataé o seguinte. O registro real do Kinesis conteria todos os dados da linha da tabela que foi alterada, além da chave primária e do carimbo de data/hora da confirmação.{"Key": 12349999,"CommitTimestamp": "2022-07-18T20:00:00"}A
CommitTimestampnoDataO campo é usado no ponto de verificação de replicação e é crítico para rastrear com precisão quantos dados de fluxo foram replicados para a região secundária. O ponto de verificação pode então ser usado para facilitar um failover do processador CDC (produtor) e retomar com precisão a produção de dados a partir do carimbo de data/hora do ponto de verificação de replicação em diante.A alternativa ao uso de uma fonte de dados remota
CommitTimestamp(se indisponível) é usar oApproximateArrivalTimestamp(que é o carimbo de data/hora quando o registro é realmente gravado no fluxo de dados). - Função Lambda de replicação entre regiões – A função é implantada em regiões primárias e secundárias. Ele é configurado com um mapeamento de fonte de evento para o fluxo de dados que contém os dados do CDC. A mesma função pode ser usada para replicar dados de vários fluxos. Ele é invocado com um lote de registros do Kinesis Data Streams e replica o lote para uma região de replicação de destino (que é fornecida por meio do ambiente de configuração do Lambda). Para considerações de custo, se os dados do CDC forem produzidos ativamente apenas na região primária, a simultaneidade reservada da função na região secundária poderá ser definida como zero e modificada durante o failover regional. A função tem Gerenciamento de acesso e identidade da AWS (IAM) permissões de função para fazer o seguinte:
- Leia e grave nas tabelas globais do DynamoDB usadas nesta solução, dentro da mesma conta.
- Leia e grave no Kinesis Data Streams em ambas as regiões na mesma conta.
- Publicar métricas personalizadas para Amazon CloudWatch em ambas as Regiões dentro da mesma conta.
- Ponto de verificação de replicação – O ponto de verificação de replicação usa a tabela global do DynamoDB nas regiões primária e secundária. Ele é usado pela função do Lambda de replicação entre regiões para persistir o carimbo de data/hora de confirmação do último registro de replicação como o ponto de verificação de replicação para cada fluxo configurado para replicação. Para esta postagem, criamos e usamos uma tabela global chamada
kdsReplicationCheckpoint. - Configuração da região ativa – A região ativa usa a tabela global do DynamoDB nas regiões primária e secundária. Ele usa o recurso nativo de replicação entre regiões da tabela global para replicar a configuração. Ele é pré-preenchido com dados sobre qual é a região principal de um stream, para impedir a replicação de volta à região principal pela função do Lambda na região de espera. Essa configuração pode não ser necessária se a função do Lambda na região de espera tiver uma simultaneidade reservada definida como zero, mas pode servir como uma verificação de segurança para evitar um loop infinito de replicação dos dados. Para esta postagem, criamos uma tabela global chamada
kdsActiveRegionConfige coloque um item com os seguintes dados:{ "stream-name": "example-stream-1", "active-region" : "us-east-1" } - Streams de dados Kinesis – O fluxo para o qual o processador CDC produz os dados. Para esta postagem, usamos um fluxo chamado
example-stream-1em ambas as Regiões, com a mesma configuração de shard e políticas de acesso.
Sequência de etapas na replicação entre regiões
Vejamos brevemente como a arquitetura é exercida usando o diagrama de sequência a seguir.
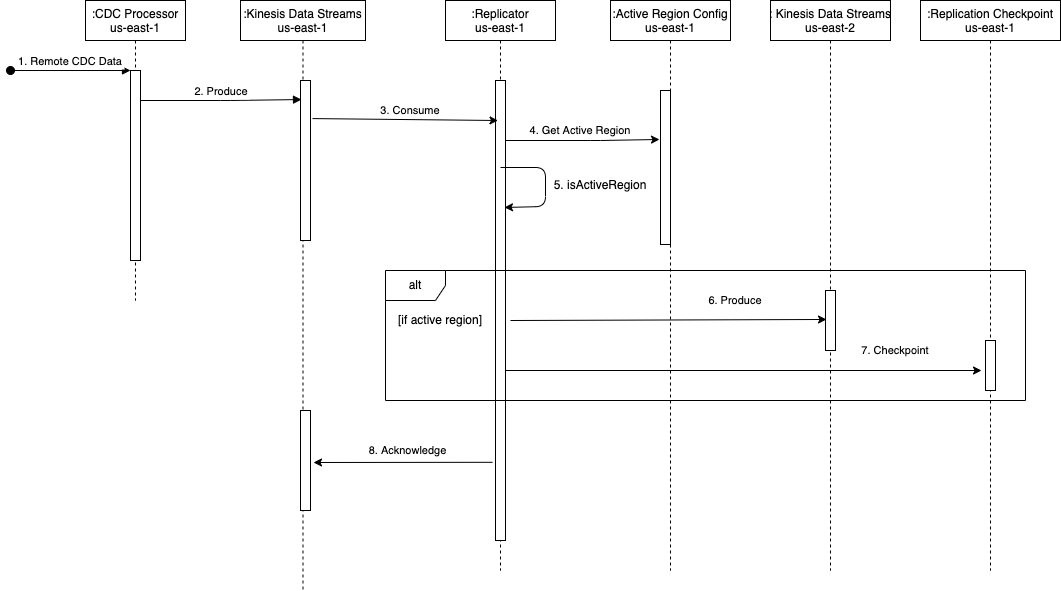
A sequência consiste nas seguintes etapas:
- O processador CDC (em
us-east-1) lê os dados CDC da fonte de dados remota. - O processador CDC (em
us-east-1) transmite os dados do CDC para o Kinesis Data Streams (emus-east-1). - A função Lambda de replicação entre regiões (em us-east-1) consome os dados do fluxo de dados (em
us-east-1). O padrão de difusão aprimorado é recomendado para taxa de transferência dedicada e aumentada para replicação entre regiões. - A função Lambda do replicador (em
us-east-1) valida sua região atual com a configuração de região ativa para o fluxo que está sendo consumido, com a ajuda dokdsActiveRegionConfigTabela global do DynamoDBO código de amostra a seguir (em Java) pode ajudar a ilustrar a condição que está sendo avaliada:// Fetch the current AWS Region from the Lambda function’s environment String currentAWSRegion = System.getenv(“AWS_REGION”); // Read the stream name from the first Kinesis Record once for the entire batch being processed. This is done because we are reusing the same Lambda function for replicating multiple streams. String currentStreamNameConsumed = kinesisRecord.getEventSourceARN().split(“:”)[5].split(“/”)[1]; // Build the DynamoDB query condition using the stream name Map<String, Condition> keyConditions = singletonMap(“streamName”, Condition.builder().comparisonOperator(EQ).attributeValueList(AttributeValue.builder().s(currentStreamNameConsumed).build()).build()); // Query the DynamoDB Global Table QueryResponse queryResponse = ddbClient.query(QueryRequest.builder().tableName("kdsActiveRegionConfig").keyConditions(keyConditions).attributesToGet(“ActiveRegion”).build()); - A função avalia a resposta do DynamoDB com o seguinte código:
// Evaluate the response if (queryResponse.hasItems()) { AttributeValue activeRegionForStream = queryResponse.items().get(0).get(“ActiveRegion”); return currentAWSRegion.equalsIgnoreCase(activeRegionForStream.s()); } - Dependendo da resposta, a função executa as seguintes ações:
- Se a resposta for
true, a função do replicador produz os registros para o Kinesis Data Streams emus-east-2de forma sequencial.- Se houver uma falha, o número de sequência do registro é rastreado e a iteração é interrompida. A função retorna a lista de números de sequência com falha. Ao retornar o número de sequência com falha, a solução usa o recurso de Ponto de verificação lambda poder retomar o processamento de um lote de registros com falhas parciais. Isso é útil ao lidar com qualquer deficiência de serviço, em que a função tenta replicar os dados entre as regiões para garantir a paridade do fluxo e nenhuma perda de dados.
- Se não houver falhas, uma lista vazia é retornada, o que indica que o lote foi bem-sucedido.
- Se a resposta for
false, a função do replicador retorna sem executar nenhuma replicação. Para reduzir o custo das invocações do Lambda, você pode definir a simultaneidade reservada da função na região DR (us-east-2) a zero. Isso impedirá que a função seja invocada. Ao fazer o failover, você pode atualizar esse valor para um número apropriado com base na taxa de transferência do CDC e definir a simultaneidade reservada da função emus-east-1para zero para evitar que seja executado desnecessariamente.
- Se a resposta for
- Depois que todos os registros são produzidos para o Kinesis Data Streams em
us-east-2, os pontos de verificação da função do replicador para okdsReplicationCheckpointTabela global do DynamoDB (emus-east-1) com os seguintes dados:{ "streamName": "example-stream-1", "lastReplicatedTimestamp": "2022-07-18T20:00:00" } - A função retorna após o processamento bem-sucedido do lote de registros.
Considerações de desempenho
As expectativas de desempenho da solução devem ser entendidas com relação aos seguintes fatores:
- Seleção de região – A latência de replicação é diretamente proporcional à distância percorrida pelos dados, portanto, entenda sua seleção de região
- Velocidade – A velocidade de entrada dos dados ou o volume de dados sendo replicados
- Tamanho da carga útil – O tamanho da carga que está sendo replicada
Monitore a replicação entre regiões
É recomendável rastrear e observar a replicação à medida que ela ocorre. Você pode personalizar a função do Lambda para publicar métricas personalizadas no CloudWatch com as seguintes métricas ao final de cada chamada. A publicação dessas métricas nas regiões primária e secundária ajuda a proteger você contra deficiências que afetam a observabilidade na região primária.
- Produtividade – O tamanho atual do lote de invocação do Lambda
- ReplicationLagSeconds – A diferença entre o timestamp atual (depois de processar todos os registros) e o
ApproximateArrivalTimestampdo último registro que foi replicado
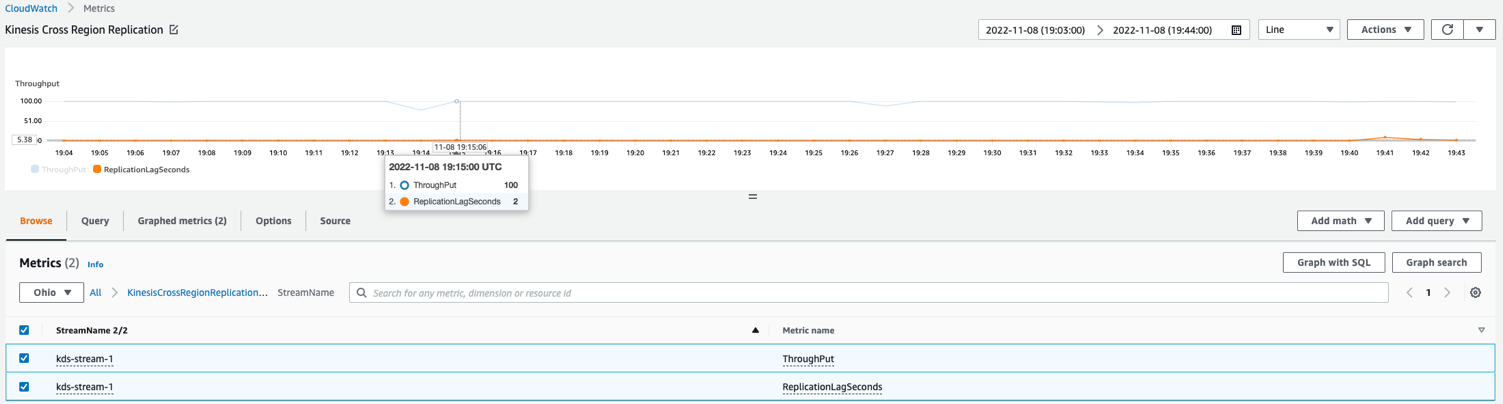
O exemplo de gráfico de métricas do CloudWatch a seguir mostra que o atraso médio da replicação foi de 2 segundos com uma taxa de transferência de 100 registros replicados de us-east-1 para us-east-2.
Estratégia comum de failover
Durante quaisquer deficiências que afetem o pipeline do CDC na região primária, as necessidades de continuidade dos negócios ou recuperação de desastres podem exigir um failover do pipeline para a região secundária (em espera). Isso significa que algumas coisas precisam ser feitas como parte desse processo de failover:
- Se possível, interrompa todas as tarefas do CDC na ferramenta do processador CDC em
us-east-1. - O processador CDC deve sofrer failover para a região secundária, para que possa ler os dados CDC da fonte de dados remota enquanto estiver operando fora da região em espera.
- A
kdsActiveRegionConfigA tabela global do DynamoDB precisa ser atualizada. Por exemplo, para o fluxoexample-stream-1usado em nosso exemplo, a região ativa é alterada paraus-east-2:
{ "stream-name": "example-stream-1", "active-Region" : "us-east-2"
}- Todos os pontos de verificação de fluxo precisam ser lidos do
kdsReplicationCheckpointTabela global do DynamoDB (emus-east-2), e os timestamps de cada um dos pontos de verificação são usados para iniciar as tarefas do CDC na ferramenta do produtor emus-east-2Região. Isso minimiza as chances de perda de dados e retoma com precisão o streaming dos dados do CDC da fonte de dados remota a partir do registro de data e hora do ponto de verificação. - Se estiver usando simultaneidade reservada para controlar invocações do Lambda, defina o valor como zero na região primária (
us-east-1) e para um valor diferente de zero adequado na região secundária (us-east-2).
Estratégia de failover de várias etapas da Vanguard
Algumas das ferramentas de terceiros usadas pela Vanguard têm um processo CDC de duas etapas de transmissão de dados de uma fonte de dados remota para um destino. A ferramenta preferida da Vanguard para seu processador CDC segue esta abordagem de duas etapas:
- A primeira etapa envolve a configuração de uma tarefa de fluxo de log que lê os dados da fonte de dados remota e persiste em um local de preparação.
- A segunda etapa envolve a configuração de tarefas individuais do consumidor que leem dados do local de preparação - que pode estar em Sistema de arquivos elástico da Amazon (Amazon EFS) ou Amazon FSx, por exemplo — e transmiti-lo para o destino. A flexibilidade aqui é que cada uma dessas tarefas do consumidor pode ser acionada para transmitir a partir de diferentes carimbos de data/hora de confirmação. A tarefa de fluxo de log geralmente começa a ler dados do mínimo de todos os carimbos de data/hora de confirmação usados pelas tarefas do consumidor.
Vejamos um exemplo para explicar o cenário:
- A tarefa A do consumidor está transmitindo dados de um registro de data e hora de confirmação 2022-07-19T20:00:00 em diante para
example-stream-1. - A tarefa do consumidor B está transmitindo dados de um registro de data e hora de confirmação 2022-07-19T21:00:00 em diante para
example-stream-2. - Nessa situação, o fluxo de logs deve ler os dados da fonte de dados remota a partir do mínimo de carimbos de data/hora usados pelas tarefas do consumidor, que é 2022-07-19T20:00:00.
O diagrama de sequência a seguir demonstra as etapas exatas a serem executadas durante um failover para us-east-2 (a região de espera).
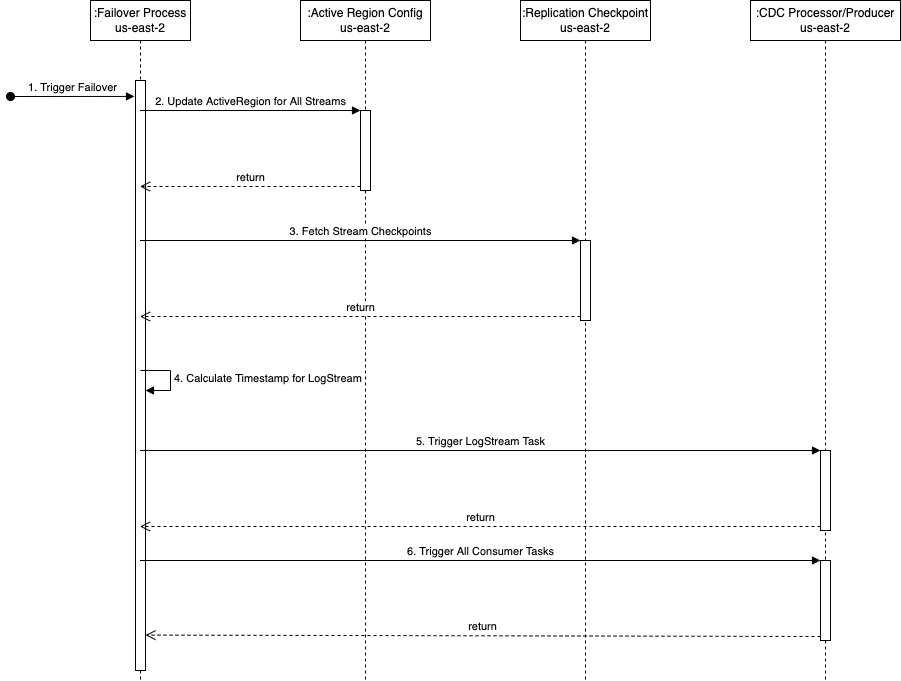
As etapas são as seguintes:
- O processo de failover é acionado na região de espera (
us-east-2neste exemplo) quando necessário. Observe que o gatilho pode ser automatizado usando verificações de integridade abrangentes do pipeline na região primária. - O processo de failover atualiza a tabela global kdsActiveRegionConfig DynamoDB com o novo valor para a região como
us-east-2para todos os nomes de fluxo. - A próxima etapa é buscar todos os pontos de verificação de fluxo do
kdsReplicationCheckpointTabela global do DynamoDB (emus-east-2). - Depois que as informações do ponto de verificação são lidas, o processo de failover encontra o mínimo de todos os
lastReplicatedTimestamp. - A tarefa de fluxo de log na ferramenta do processador CDC é iniciada em
us-east-2com o carimbo de data/hora encontrado na Etapa 4. Ele começa a ler os dados do CDC da fonte de dados remota a partir desse carimbo de data/hora e os persiste no local de preparação na AWS. - A próxima etapa é iniciar todas as tarefas do consumidor para ler dados do local de preparação e transmitir para o fluxo de dados de destino. É aqui que cada tarefa do consumidor recebe o carimbo de data/hora apropriado do
kdsReplicationCheckpointtabela de acordo com ostreamNamepara o qual a tarefa transmite os dados.
Depois que todas as tarefas do consumidor são iniciadas, os dados são produzidos para os fluxos de dados do Kinesis em us-east-2. A partir daí, o processo de replicação entre regiões é o mesmo descrito anteriormente – a função Lambda de replicação em us-east-2 começa a replicar dados para o fluxo de dados em us-east-1.
Espera-se que os aplicativos consumidores que leem dados dos fluxos sejam idempotentes para serem capazes de lidar com duplicatas. Duplicatas podem ser introduzidas no fluxo devido a vários motivos, alguns dos quais são mencionados abaixo.
- O produtor ou o processador CDC introduz duplicatas no fluxo enquanto reproduz os dados CDC durante um failover
- A tabela global do DynamoDB usa replicação assíncrona de dados entre regiões e, se o
kdsReplicationCheckpointos dados da tabela tiverem um atraso de replicação, o processo de failover pode usar um carimbo de data/hora de ponto de verificação mais antigo para reproduzir os dados do CDC.
Além disso, os aplicativos do consumidor devem verificar o CommitTimestamp do último registro que foi consumido. Isso é para facilitar um melhor monitoramento e recuperação.
Caminho para a maturidade: recuperação automatizada
O estado ideal é automatizar totalmente o processo de failover, reduzindo o tempo de recuperação e atendendo ao objetivo de nível de serviço (SLO) de resiliência. No entanto, na maioria das organizações, a decisão de fazer failover, failback e acionar o failover requer intervenção manual na avaliação da situação e na decisão do resultado. Criar automação com script para executar o failover que pode ser executado por um humano é um bom ponto de partida.
A Vanguard automatizou todas as etapas do failover, mas ainda permite que os humanos decidam quando invocá-lo. Você pode personalizar a solução para atender às suas necessidades e dependendo da ferramenta do processador CDC que você usa em seu ambiente.
Conclusão
Nesta postagem, descrevemos como a Vanguard inovou e criou uma solução para replicar dados entre regiões no Kinesis Data Streams para tornar os dados altamente disponíveis. Também demonstramos uma estratégia de ponto de verificação robusta para facilitar um failover regional do processo de replicação quando necessário. A solução também ilustrou como usar as tabelas globais do DynamoDB para rastrear os pontos de verificação e a configuração da replicação. Com essa arquitetura, a Vanguard conseguiu implantar cargas de trabalho dependendo dos dados do CDC em várias regiões para atender às necessidades de negócios de alta disponibilidade diante de deficiências de serviço que afetam os pipelines do CDC na região principal.
Se você tiver algum comentário, por favor, deixe um comentário na seção de comentários abaixo.
Sobre os autores
 Raghu Boppanna trabalha como Enterprise Architect no Chief Technology Office da Vanguard. Raghu é especialista em análise de dados, migração/replicação de dados, incluindo pipelines de CDC, recuperação de desastres e bancos de dados. Ele ganhou várias certificações da AWS, incluindo AWS Certified Security – Specialty e AWS Certified Data Analytics – Specialty.
Raghu Boppanna trabalha como Enterprise Architect no Chief Technology Office da Vanguard. Raghu é especialista em análise de dados, migração/replicação de dados, incluindo pipelines de CDC, recuperação de desastres e bancos de dados. Ele ganhou várias certificações da AWS, incluindo AWS Certified Security – Specialty e AWS Certified Data Analytics – Specialty.
 Parameswaran V Vaidyanathan é arquiteto de resiliência de nuvem sênior da Amazon Web Services. Ele ajuda grandes empresas a atingir as metas de negócios arquitetando e construindo soluções escaláveis e resilientes na Nuvem AWS.
Parameswaran V Vaidyanathan é arquiteto de resiliência de nuvem sênior da Amazon Web Services. Ele ajuda grandes empresas a atingir as metas de negócios arquitetando e construindo soluções escaláveis e resilientes na Nuvem AWS.
 Richa Kaul é Líder Sênior em Soluções para Clientes atendendo clientes de Serviços Financeiros. Ela é baseada em Nova York. Ela tem uma vasta experiência em transformação de nuvem em grande escala, excelência de funcionários e soluções digitais de próxima geração. Ela e sua equipe se concentram em otimizar o valor da nuvem criando soluções de alto desempenho, resilientes e ágeis. Richa gosta de vários esportes como triatlos, música e aprender sobre novas tecnologias.
Richa Kaul é Líder Sênior em Soluções para Clientes atendendo clientes de Serviços Financeiros. Ela é baseada em Nova York. Ela tem uma vasta experiência em transformação de nuvem em grande escala, excelência de funcionários e soluções digitais de próxima geração. Ela e sua equipe se concentram em otimizar o valor da nuvem criando soluções de alto desempenho, resilientes e ágeis. Richa gosta de vários esportes como triatlos, música e aprender sobre novas tecnologias.
 Mithil Prasad é gerente principal de soluções para clientes da Amazon Web Services. Em sua função, Mithil trabalha com os clientes para impulsionar a realização do valor da nuvem, fornecer liderança de pensamento para ajudar as empresas a obter velocidade, agilidade e inovação.
Mithil Prasad é gerente principal de soluções para clientes da Amazon Web Services. Em sua função, Mithil trabalha com os clientes para impulsionar a realização do valor da nuvem, fornecer liderança de pensamento para ajudar as empresas a obter velocidade, agilidade e inovação.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/how-vanguard-made-their-technology-platform-resilient-and-efficient-by-building-cross-region-replication-for-amazon-kinesis-data-streams/
- 1
- 100
- 2022
- 28
- a
- habilidade
- Capaz
- Sobre
- acima
- Acesso
- Segundo
- Conta
- exatamente
- Alcançar
- em
- ações
- ativo
- ativamente
- Adição
- conselho
- afetando
- acessível
- Depois de
- contra
- ágil
- Todos os Produtos
- permite
- alternativa
- Amazon
- Amazon EC2
- Amazon Kinesis
- Amazon Web Services
- quantidades
- analítica
- e
- aplicações
- abordagem
- apropriado
- arquitetura
- automatizar
- Automatizado
- Automação
- disponibilidade
- disponível
- média
- evitar
- AWS
- Certificado AWS
- em caminho duplo
- baseado
- Porque
- ser
- abaixo
- Melhor
- entre
- brevemente
- Quebrado
- construir
- Prédio
- construído
- construídas em
- negócio
- a continuidade dos negócios
- negócios
- chamado
- capturar
- capturas
- casas
- CDC
- certificações
- Non-GMO
- chances
- alterar
- verificar
- Cheques
- chefe
- escolha
- Na nuvem
- TECNOLOGIA DE NUVEM
- código
- comentar
- comentários
- commit
- componente
- compreensivo
- Computar
- condição
- Configuração
- Considerações
- consumida
- consumidor
- Consumidores
- consumo
- continuamente
- ao controle
- Custo
- poderia
- Casal
- crio
- Criar
- crítico
- Atual
- Atualmente
- personalizadas
- cliente
- Soluções para clientes
- Clientes
- personalizar
- dados,
- Análise de Dados
- Perda de Dados
- banco de dados
- bases de dados
- Decidindo
- decisão
- dedicado
- demonstraram
- demonstra
- Dependendo
- depende
- implantar
- implantado
- descrito
- destino
- detalhe
- diferença
- diferente
- digital
- diretamente
- desastre
- discutido
- distância
- distância
- condução
- duplicatas
- durante
- cada
- Mais cedo
- ganhou
- economias
- Economias de escala
- eficiente
- Empregado
- permite
- aprimorada
- garantir
- Empreendimento
- empresas
- Todo
- Meio Ambiente
- Éter (ETH)
- avaliar
- avaliadas
- Evento
- Cada
- exemplo
- Excelência
- executando
- expectativas
- esperado
- vasta experiência
- Explicação
- Explica
- extenso
- externo
- Rosto
- facilitar
- fatores
- FALHA
- fracassado
- Falha
- Característica
- retornos
- campo
- Envie o
- financeiro
- serviços financeiros
- encontra
- Primeiro nome
- Flexibilidade
- Foco
- seguinte
- segue
- para Investidores
- encontrado
- da
- totalmente
- função
- geração
- Global
- globo
- Objetivos
- Bom estado, com sinais de uso
- gráfico
- Locatário
- Visitante Mensagem
- manipular
- Manipulação
- acontece
- Saúde
- ajudar
- ajuda
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- Alta
- altamente
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTTPS
- humano
- Humanos
- IAM
- ideal
- Dados de identificação:
- prejuízo
- melhorar
- melhora
- in
- Incluindo
- Entrada
- aumentou
- indicam
- Individual
- INFORMAÇÕES
- Infraestrutura
- Inovação
- instância
- da intervenção
- introduzido
- Introduz
- investidor
- Investidores
- envolve
- IT
- iteração
- Java
- Julho
- Chave
- Streams de dados Kinesis
- grande
- Sobrenome
- Latência
- líder
- Liderança
- aprendizagem
- Deixar
- Nível
- Line
- linhas
- Lista
- pequeno
- localização
- olhar
- fora
- moldadas
- mantém
- fazer
- FAZ
- gerenciados
- Gerente
- maneira
- manual
- muitos
- mapeamento
- massivamente
- maturidade
- significa
- mecanismo
- Conheça
- reunião
- métrico
- Métrica
- mínimo
- mínimo
- Moda
- modificada
- monitoração
- a maioria
- múltiplos
- múltiplo
- Música
- nome
- nomes
- nativo
- você merece...
- necessário
- Cria
- Novo
- Novas tecnologias
- New York
- Próximo
- número
- números
- objetivo
- observar
- Office
- operando
- otimizando
- organizações
- Resultado
- paridade
- parte
- parceria
- festa
- padrão
- realizar
- atuação
- realização
- permissões
- persiste
- Personalizado
- oleoduto
- Lugar
- plataforma
- platão
- Inteligência de Dados Platão
- PlatãoData
- por favor
- políticas
- possível
- Publique
- potencialmente
- evitar
- primário
- Diretor
- processo
- em processamento
- Subcontratante
- Produzido
- produtor
- Produtores
- promove
- proteger
- fornecer
- fornecido
- fornece
- publicar
- Publishing
- fins
- colocar
- Leia
- Leitura
- realização
- razões
- Recomenda
- registro
- registros
- Recuperar
- recuperação
- reduzir
- redução
- região
- regional
- regiões
- remoto
- replicado
- replica
- réplica
- requeridos
- Requisitos
- exige
- reservado
- resiliência
- resiliente
- resposta
- DESCANSO
- currículo
- retorno
- voltar
- Retorna
- uma conta de despesas robusta
- Tipo
- Enrolado
- LINHA
- Execute
- Segurança
- mesmo
- escalável
- Escala
- cenário
- Segundo
- secundário
- segundo
- Seção
- segurança
- senior
- Seqüência
- servir
- serviço
- Serviços
- de servir
- conjunto
- contexto
- vários
- rede de apoio social
- mostrando
- Shows
- simplicidade
- situação
- Tamanho
- So
- solução
- Soluções
- alguns
- fonte
- Fontes
- especializada
- Especialidade
- velocidade
- Esportes
- encenação
- começo
- começado
- começa
- Estado
- Passo
- Passos
- Ainda
- Dê um basta
- loja
- Estratégia
- transmitir canais
- de streaming
- Serviço de transmissão
- córregos
- bem sucedido
- entraram com sucesso
- adequado
- topo
- fornecidas
- suportes
- .
- mesa
- toma
- Target
- Tarefa
- tarefas
- Profissionais
- equipes
- Dados Técnicos:
- Tecnologias
- Equipar
- A
- deles
- coisas
- De terceiros
- pensamento
- liderança de pensamento
- Através da
- Taxa de transferência
- tempo
- timestamp
- para
- ferramenta
- ferramentas
- pista
- Rastreamento
- Transformação
- viajado
- desencadear
- desencadeado
- compreender
- Entendido
- desnecessariamente
- Atualizar
- Atualizada
- Atualizações
- usar
- caso de uso
- geralmente
- UTC
- valor
- Vanguarda
- Velocidade
- via
- volume
- web
- serviços web
- qual
- enquanto
- precisarão
- dentro
- sem
- trabalho
- seria
- escrever
- escrito
- investimentos
- você mesmo
- zefirnet
- zero
- zonas