Esta postagem foi escrita em parceria com Mahima Agarwal, engenheiro de aprendizado de máquina, e Deepak Mettem, gerente sênior de engenharia da VMware Carbon Black
VMware Black Carbon é uma solução de segurança renomada que oferece proteção contra todo o espectro de ataques cibernéticos modernos. Com terabytes de dados gerados pelo produto, a equipe de análise de segurança se concentra na criação de soluções de aprendizado de máquina (ML) para revelar ataques críticos e destacar ameaças emergentes de ruído.
É fundamental que a equipe do VMware Carbon Black projete e crie um pipeline MLOps de ponta a ponta personalizado que orquestre e automatize fluxos de trabalho no ciclo de vida de ML e permita treinamento, avaliações e implantações de modelos.
Há duas finalidades principais para a construção desse pipeline: oferecer suporte aos cientistas de dados para desenvolvimento de modelo em estágio avançado e previsões de modelo de superfície no produto, atendendo a modelos em alto volume e em tráfego de produção em tempo real. Portanto, o VMware Carbon Black e a AWS optaram por criar um pipeline MLOps personalizado usando Amazon Sage Maker por sua facilidade de uso, versatilidade e infraestrutura totalmente gerenciada. Orquestramos nossos pipelines de treinamento e implantação de ML usando Fluxos de trabalho gerenciados da Amazon para Apache Airflow (Amazon MWAA), que nos permite focar mais na criação programática de fluxos de trabalho e pipelines sem ter que nos preocupar com dimensionamento automático ou manutenção de infraestrutura.
Com esse pipeline, o que antes era uma pesquisa de ML baseada em notebook Jupyter agora é um processo automatizado que implanta modelos para produção com pouca intervenção manual de cientistas de dados. Anteriormente, o processo de treinamento, avaliação e implantação de um modelo poderia levar mais de um dia; com esta implementação, tudo está a apenas um gatilho de distância e reduziu o tempo total para alguns minutos.
Nesta postagem, os arquitetos VMware Carbon Black e AWS discutem como criamos e gerenciamos fluxos de trabalho de ML personalizados usando Gitlab, Amazon MWAA e SageMaker. Discutimos o que alcançamos até agora, outras melhorias no pipeline e as lições aprendidas ao longo do caminho.
Visão geral da solução
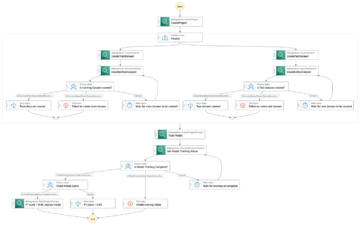
O diagrama a seguir ilustra a arquitetura da plataforma ML.

Projeto de solução de alto nível
Essa plataforma de ML foi idealizada e projetada para ser consumida por diferentes modelos em vários repositórios de código. Nossa equipe usa o GitLab como uma ferramenta de gerenciamento de código-fonte para manter todos os repositórios de código. Quaisquer alterações no código-fonte do repositório do modelo são continuamente integradas usando o CI do Gitlab, que invoca os fluxos de trabalho subsequentes no pipeline (treinamento de modelo, avaliação e implantação).
O diagrama de arquitetura a seguir ilustra o fluxo de trabalho de ponta a ponta e os componentes envolvidos em nosso pipeline de MLOps.

Fluxo de trabalho de ponta a ponta
Os pipelines de treinamento, avaliação e implantação do modelo de ML são orquestrados usando o Amazon MWAA, conhecido como Gráfico Acíclico Dirigido (DAG). Um DAG é uma coleção de tarefas juntas, organizadas com dependências e relacionamentos para dizer como elas devem ser executadas.
Em alto nível, a arquitetura da solução inclui três componentes principais:
- Repositório de código de pipeline de ML
- Pipeline de treinamento e avaliação de modelos de ML
- Pipeline de implantação de modelo de ML
Vamos discutir como esses diferentes componentes são gerenciados e como eles interagem uns com os outros.
Repositório de código de pipeline de ML
Depois que o repositório de modelo integra o repositório MLOps como seu pipeline downstream e um cientista de dados confirma o código em seu repositório de modelo, um executor do GitLab faz validação e teste de código padrão definido nesse repositório e aciona o pipeline MLOps com base nas alterações de código. Usamos o pipeline de vários projetos do Gitlab para habilitar esse gatilho em diferentes repositórios.
O pipeline MLOps GitLab executa um determinado conjunto de estágios. Ele conduz a validação básica de código usando pylint, empacota o treinamento do modelo e o código de inferência dentro da imagem do Docker e publica a imagem do contêiner para Registro do Amazon Elastic Container (Amazon ECR). O Amazon ECR é um registro de contêiner totalmente gerenciado que oferece hospedagem de alto desempenho, para que você possa implantar imagens e artefatos de aplicativos de forma confiável em qualquer lugar.
Pipeline de treinamento e avaliação de modelos de ML
Após a publicação da imagem, ela aciona o treinamento e avaliação Fluxo de ar Apache canalização através do AWS Lambda função. O Lambda é um serviço de computação sem servidor e orientado a eventos que permite executar código para praticamente qualquer tipo de aplicativo ou serviço de back-end sem provisionar ou gerenciar servidores.
Depois que o pipeline é acionado com sucesso, ele executa o DAG de treinamento e avaliação, que por sua vez inicia o treinamento do modelo no SageMaker. No final deste pipeline de treinamento, o grupo de usuários identificado recebe uma notificação com os resultados do treinamento e da avaliação do modelo por e-mail por meio de Serviço de notificação simples da Amazon (Amazon SNS) e Slack. O Amazon SNS é um serviço de publicação/assinatura totalmente gerenciado para mensagens A2A e A2P.
Após análise meticulosa dos resultados da avaliação, o cientista de dados ou engenheiro de ML pode implantar o novo modelo se o desempenho do modelo recém-treinado for melhor em comparação com a versão anterior. O desempenho dos modelos é avaliado com base nas métricas específicas do modelo (como pontuação F1, MSE ou matriz de confusão).
Pipeline de implantação de modelo de ML
Para iniciar a implantação, o usuário inicia o trabalho do GitLab que aciona o Deployment DAG por meio da mesma função do Lambda. Depois que o pipeline é executado com êxito, ele cria ou atualiza o ponto de extremidade do SageMaker com o novo modelo. Isso também envia uma notificação com os detalhes do endpoint por e-mail usando Amazon SNS e Slack.
Em caso de falha em qualquer um dos pipelines, os usuários são notificados pelos mesmos canais de comunicação.
O SageMaker oferece inferência em tempo real, ideal para cargas de trabalho de inferência com baixa latência e requisitos de alta taxa de transferência. Esses endpoints são totalmente gerenciados, com balanceamento de carga e dimensionamento automático e podem ser implantados em várias zonas de disponibilidade para alta disponibilidade. Nosso pipeline cria esse endpoint para um modelo depois que ele é executado com sucesso.
Nas seções a seguir, expandimos os diferentes componentes e nos aprofundamos nos detalhes.
GitLab: modelos de pacote e pipelines de gatilho
Usamos o GitLab como nosso repositório de código e para o pipeline para empacotar o código do modelo e acionar DAGs do Airflow downstream.
Pipeline de vários projetos
O recurso de pipeline GitLab multiprojeto é usado onde o pipeline pai (upstream) é um repositório de modelo e o pipeline filho (downstream) é o repositório MLOps. Cada repositório mantém um .gitlab-ci.yml, e o seguinte bloco de código habilitado no pipeline upstream aciona o pipeline MLOps downstream.
O pipeline upstream envia o código do modelo para o pipeline downstream, onde os trabalhos de CI de empacotamento e publicação são acionados. O código para conter o código do modelo e publicá-lo no Amazon ECR é mantido e gerenciado pelo pipeline MLOps. Ele envia as variáveis como ACCESS_TOKEN (pode ser criado em Configurações, Acesso a), JOB_ID (para acessar artefatos upstream) e variáveis $CI_PROJECT_ID (a ID do projeto do repositório do modelo), para que o pipeline MLOps possa acessar os arquivos de código do modelo. Com o artefatos de trabalho recurso do Gitlab, o repositório downstream acessa os artefatos remotos usando o seguinte comando:
O repositório de modelo pode consumir pipelines downstream para vários modelos do mesmo repositório estendendo o estágio que o aciona usando o se estende palavra-chave do GitLab, que permite reutilizar a mesma configuração em diferentes estágios.
Depois de publicar a imagem do modelo no Amazon ECR, o pipeline MLOps aciona o pipeline de treinamento Amazon MWAA usando o Lambda. Após a aprovação do usuário, ele aciona o pipeline Amazon MWAA de implantação do modelo também usando a mesma função do Lambda.
Versão semântica e passagem de versões downstream
Desenvolvemos código personalizado para versões de imagens ECR e modelos SageMaker. O pipeline MLOps gerencia a lógica de versão semântica para imagens e modelos como parte do estágio em que o código do modelo é conteinerizado e passa as versões para estágios posteriores como artefatos.
Retreinamento
Como o retreinamento é um aspecto crucial do ciclo de vida de ML, implementamos recursos de retreinamento como parte de nosso pipeline. Usamos a API de modelos de lista do SageMaker para identificar se é um retreinamento com base no número da versão de retreinamento do modelo e carimbo de data/hora.
Gerenciamos a programação diária do pipeline de retreinamento usando Pipelines de programação do GitLab.
Terraform: configuração da infraestrutura
Além de um cluster Amazon MWAA, repositórios ECR, funções Lambda e tópico SNS, esta solução também usa Gerenciamento de acesso e identidade da AWS funções, usuários e políticas (IAM); Serviço de armazenamento simples da Amazon (Amazon S3) baldes e um Amazon CloudWatch encaminhador de log.
Para simplificar a configuração e manutenção da infraestrutura para os serviços envolvidos em todo o nosso pipeline, usamos Terraform para implementar a infraestrutura como código. Sempre que atualizações infra são necessárias, as alterações de código acionam um pipeline GitLab CI que configuramos, que valida e implanta as alterações em vários ambientes (por exemplo, adicionando uma permissão a uma política IAM em contas dev, stage e prod).
Amazon ECR, Amazon S3 e Lambda: facilitação de pipeline
Usamos os seguintes serviços principais para facilitar nosso pipeline:
- ECR da Amazon – Para manter e permitir recuperações convenientes das imagens de contêiner do modelo, nós as marcamos com versões semânticas e as carregamos para repositórios ECR configurados por
${project_name}/${model_name}através da Terraforma. Isso permite uma boa camada de isolamento entre modelos diferentes e nos permite usar algoritmos personalizados e formatar solicitações e respostas de inferência para incluir informações de manifesto do modelo desejado (nome do modelo, versão, caminho de dados de treinamento e assim por diante). - Amazon S3 – Usamos buckets S3 para persistir dados de treinamento de modelo, artefatos de modelo treinados por modelo, Airflow DAGs e outras informações adicionais exigidas pelos pipelines.
- Lambda – Como nosso cluster Airflow é implantado em uma VPC separada por questões de segurança, os DAGs não podem ser acessados diretamente. Portanto, usamos uma função do Lambda, também mantida com o Terraform, para acionar qualquer DAG especificado pelo nome do DAG. Com a configuração adequada do IAM, o trabalho GitLab CI aciona a função Lambda, que passa pelas configurações até os DAGs de treinamento ou implantação solicitados.
Amazon MWAA: pipelines de treinamento e implantação
Conforme mencionado anteriormente, usamos o Amazon MWAA para orquestrar os pipelines de treinamento e implantação. Usamos os operadores SageMaker disponíveis no Pacote de provedor da Amazon para Airflow para integrar com o SageMaker (para evitar modelos jinja).
Usamos os seguintes operadores neste pipeline de treinamento (mostrado no seguinte diagrama de fluxo de trabalho):

Pipeline de Treinamento MWAA
Usamos os seguintes operadores no pipeline de implantação (mostrado no seguinte diagrama de fluxo de trabalho):

Pipeline de implantação do modelo
Usamos o Slack e o Amazon SNS para publicar as mensagens de erro/sucesso e os resultados da avaliação em ambos os pipelines. O Slack oferece uma ampla variedade de opções para personalizar mensagens, incluindo as seguintes:
- Operador SnsPublish - Nós usamos Operador SnsPublish para enviar notificações de sucesso/falha para e-mails do usuário
- API Slack – Criamos o URL de webhook de entrada para obter as notificações do pipeline para o canal desejado
CloudWatch e VMware Wavefront: monitoramento e registro
Usamos um painel do CloudWatch para configurar o monitoramento e registro de endpoints. Ele ajuda a visualizar e acompanhar várias métricas de desempenho operacional e de modelo específicas para cada projeto. Além das políticas de dimensionamento automático configuradas para rastrear alguns deles, monitoramos continuamente as alterações no uso de CPU e memória, solicitações por segundo, latências de resposta e métricas de modelo.
O CloudWatch é ainda integrado a um painel do VMware Tanzu Wavefront para que possa visualizar as métricas dos endpoints do modelo, bem como de outros serviços no nível do projeto.
Benefícios comerciais e o que vem a seguir
Os pipelines de ML são muito cruciais para os serviços e recursos de ML. Nesta postagem, discutimos um caso de uso de ML de ponta a ponta usando recursos da AWS. Construímos um pipeline personalizado usando SageMaker e Amazon MWAA, que podemos reutilizar em projetos e modelos, e automatizamos o ciclo de vida de ML, o que reduziu o tempo desde o treinamento do modelo até a implantação da produção para apenas 10 minutos.
Com a transferência da carga do ciclo de vida de ML para o SageMaker, ele forneceu uma infraestrutura otimizada e escalável para o treinamento e implantação do modelo. A exibição de modelos com o SageMaker nos ajudou a fazer previsões em tempo real com latências de milissegundos e recursos de monitoramento. Usamos o Terraform para facilitar a configuração e gerenciar a infraestrutura.
As próximas etapas para esse pipeline seriam aprimorar o pipeline de treinamento de modelo com recursos de retreinamento, seja agendado ou baseado na detecção de desvio de modelo, suporte à implantação de sombra ou teste A/B para implantação de modelo mais rápida e qualificada e rastreamento de linhagem de ML. Também planejamos avaliar Pipelines Amazon SageMaker porque a integração do GitLab agora é suportada.
As lições aprendidas
Como parte da construção desta solução, aprendemos que você deve generalizar desde o início, mas não generalizar demais. Quando terminamos o design da arquitetura, tentamos criar e aplicar modelos de código para o código do modelo como uma prática recomendada. No entanto, foi tão cedo no processo de desenvolvimento que os modelos eram muito generalizados ou muito detalhados para serem reutilizáveis para modelos futuros.
Depois de entregar o primeiro modelo pelo pipeline, os templates saíram naturalmente com base nos insights do nosso trabalho anterior. Um pipeline não pode fazer tudo desde o primeiro dia.
A experimentação do modelo e a produção geralmente têm requisitos muito diferentes (ou às vezes até conflitantes). É crucial equilibrar esses requisitos desde o início como uma equipe e priorizar de acordo.
Além disso, talvez você não precise de todos os recursos de um serviço. Usar recursos essenciais de um serviço e ter um design modularizado são as chaves para um desenvolvimento mais eficiente e um pipeline flexível.
Conclusão
Neste post, mostramos como construímos uma solução MLOps usando SageMaker e Amazon MWAA que automatizou o processo de implantação de modelos para produção, com pouca intervenção manual de cientistas de dados. Incentivamos você a avaliar vários serviços da AWS, como SageMaker, Amazon MWAA, Amazon S3 e Amazon ECR, para criar uma solução MLOps completa.
*Apache, Apache Airflow e Airflow são marcas registradas ou marcas comerciais da Fundação Apache Software nos Estados Unidos e / ou outros países.
Sobre os autores
 Deepak Mettem é um Gerente de Engenharia Sênior na VMware, Unidade Carbon Black. Ele e sua equipe trabalham na criação de aplicativos e serviços baseados em streaming altamente disponíveis, escaláveis e resilientes para oferecer aos clientes soluções baseadas em aprendizado de máquina em tempo real. Ele e sua equipe também são responsáveis por criar as ferramentas necessárias para que os cientistas de dados construam, treinem, implantem e validem seus modelos de ML na produção.
Deepak Mettem é um Gerente de Engenharia Sênior na VMware, Unidade Carbon Black. Ele e sua equipe trabalham na criação de aplicativos e serviços baseados em streaming altamente disponíveis, escaláveis e resilientes para oferecer aos clientes soluções baseadas em aprendizado de máquina em tempo real. Ele e sua equipe também são responsáveis por criar as ferramentas necessárias para que os cientistas de dados construam, treinem, implantem e validem seus modelos de ML na produção.
 Mahima Agarwal é Engenheiro de Machine Learning na VMware, Carbon Black Unit.
Mahima Agarwal é Engenheiro de Machine Learning na VMware, Carbon Black Unit.
Ela trabalha projetando, construindo e desenvolvendo os principais componentes e a arquitetura da plataforma de aprendizado de máquina para o VMware CB SBU.
 Vamshi Krishna Enabothala é Arquiteto Especialista em IA Aplicada Sênior na AWS. Ele trabalha com clientes de diferentes setores para acelerar dados de alto impacto, análises e iniciativas de aprendizado de máquina. Ele é apaixonado por sistemas de recomendação, NLP e áreas de visão computacional em IA e ML. Fora do trabalho, Vamshi é um entusiasta de RC, construindo equipamentos de RC (aviões, carros e drones) e também gosta de jardinagem.
Vamshi Krishna Enabothala é Arquiteto Especialista em IA Aplicada Sênior na AWS. Ele trabalha com clientes de diferentes setores para acelerar dados de alto impacto, análises e iniciativas de aprendizado de máquina. Ele é apaixonado por sistemas de recomendação, NLP e áreas de visão computacional em IA e ML. Fora do trabalho, Vamshi é um entusiasta de RC, construindo equipamentos de RC (aviões, carros e drones) e também gosta de jardinagem.
 Sahil Thapar é arquiteto de soluções empresariais. Ele trabalha com clientes para ajudá-los a criar aplicativos altamente disponíveis, escaláveis e resilientes na Nuvem AWS. Atualmente, ele está focado em contêineres e soluções de aprendizado de máquina.
Sahil Thapar é arquiteto de soluções empresariais. Ele trabalha com clientes para ajudá-los a criar aplicativos altamente disponíveis, escaláveis e resilientes na Nuvem AWS. Atualmente, ele está focado em contêineres e soluções de aprendizado de máquina.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/how-vmware-built-an-mlops-pipeline-from-scratch-using-gitlab-amazon-mwaa-and-amazon-sagemaker/
- :é
- $UP
- 1
- 10
- 100
- 7
- 8
- a
- Sobre
- acelerar
- Acesso
- acessadas
- conformemente
- Contas
- alcançado
- em
- acíclico
- Adição
- Adicional
- Informação adicional
- Depois de
- contra
- AI
- algoritmos
- Todos os Produtos
- permite
- Amazon
- Amazon Sage Maker
- análise
- analítica
- e
- qualquer lugar
- apache
- api
- Aplicação
- aplicações
- aplicado
- IA aplicada
- aprovação
- arquitetura
- SOMOS
- áreas
- AS
- aspecto
- At
- Ataques
- autoria
- auto
- Automatizado
- automatiza
- disponibilidade
- disponível
- evitar
- AWS
- Backend
- Equilíbrio
- baseado
- basic
- BE
- Porque
- Começo
- Benefícios
- MELHOR
- Melhor
- entre
- Preto
- Bloquear
- Ramo
- trazer
- construir
- Prédio
- construído
- carga
- by
- CAN
- não podes
- capacidades
- carbono
- carros
- casas
- CB
- certo
- Alterações
- canais
- criança
- escolheu
- Na nuvem
- Agrupar
- código
- coleção
- Comunicação
- comparado
- completar
- componentes
- Computar
- computador
- Visão de Computador
- conduz
- Configuração
- configurações
- Conflitante
- confusão
- Considerações
- consumir
- consumida
- Recipiente
- Containers
- continuamente
- Conveniente
- núcleo
- poderia
- países
- CPU
- crio
- criado
- cria
- Criar
- crítico
- crucial
- Atualmente
- personalizadas
- Clientes
- personalizar
- ataques cibernéticos
- DAG
- diariamente
- painel de instrumentos
- dados,
- cientista de dados
- dia
- definido
- entregando
- implantar
- implantado
- Implantação
- desenvolvimento
- Implantações
- implanta
- Design
- projetado
- concepção
- detalhado
- detalhes
- Detecção
- Dev
- desenvolvido
- em desenvolvimento
- Desenvolvimento
- diferente
- diretamente
- discutir
- discutido
- Estivador
- não
- down
- Drones
- cada
- Mais cedo
- Cedo
- facilidade de utilização
- eficiente
- ou
- emergente
- permitir
- habilitado
- permite
- encorajar
- end-to-end
- Ponto final
- engenheiro
- Engenharia
- Empreendimento
- Soluções Empresariais
- entusiasta
- ambientes
- equipamento
- essencial
- Éter (ETH)
- avaliar
- avaliadas
- avaliação
- avaliação
- avaliações
- Mesmo
- Evento
- Cada
- tudo
- exemplo
- Expandir
- estendendo
- f1
- facilitar
- Falha
- longe
- mais rápido
- Característica
- Funcionalidades
- poucos
- Arquivos
- Primeiro nome
- flexível
- Foco
- focado
- concentra-se
- seguinte
- Escolha
- formato
- da
- cheio
- espectro completo
- totalmente
- função
- funções
- mais distante
- futuro
- gerado
- ter
- Bom estado, com sinais de uso
- Grupo
- Ter
- ter
- ajudar
- ajudou
- ajuda
- Alta
- alta performance
- altamente
- hospedagem
- Como funciona o dobrador de carta de canal
- Contudo
- HTML
- http
- HTTPS
- IAM
- ID
- ideal
- identificado
- identificar
- Dados de identificação:
- imagem
- imagens
- executar
- implementação
- implementado
- in
- incluir
- inclui
- Incluindo
- INFORMAÇÕES
- Infraestrutura
- iniciativas
- insights
- integrar
- integrado
- Integra-se
- integração
- interagir
- da intervenção
- invoca
- envolvido
- isolamento
- IT
- ESTÁ
- Trabalho
- Empregos
- jpg
- Guarda
- Chave
- chaves
- Latência
- camada
- aprendido
- aprendizagem
- lições
- Lições Aprendidas
- Permite
- Nível
- wifecycwe
- como
- pequeno
- carregar
- Baixo
- máquina
- aprendizado de máquina
- a Principal
- a manter
- mantém
- manutenção
- fazer
- gerencia
- gerenciados
- de grupos
- Gerente
- gestão
- gestão
- manual
- Matriz
- Memória
- mencionado
- mensagens
- mensagens
- Métrica
- poder
- milissegundo
- minutos
- ML
- MLOps
- modelo
- modelos
- EQUIPAMENTOS
- Monitore
- monitoração
- mais
- mais eficiente
- múltiplo
- nome
- naturalmente
- necessário
- você merece...
- Novo
- Próximo
- PNL
- Ruído
- notificação
- notificações
- número
- of
- oferecendo treinamento para distância
- Oferece
- on
- ONE
- operacional
- operadores
- otimizado
- Opções
- orquestrada
- Organizado
- Outros
- lado de fora
- global
- pacote
- pacotes
- acondicionamento
- parte
- passes
- Passagem
- apaixonado
- caminho
- atuação
- permissão
- oleoduto
- plano
- Planos
- plataforma
- platão
- Inteligência de Dados Platão
- PlatãoData
- políticas
- Privacidade
- Publique
- prática
- Previsões
- anterior
- Priorizar
- processo
- Produto
- Produção
- projeto
- projetos
- adequado
- proteção
- fornecido
- provedor
- fornece
- publicar
- publicado
- Publica
- Publishing
- fins
- qualificado
- alcance
- em tempo real
- Recomendação
- Reduzido
- a que se refere
- registrado
- registro
- Relacionamentos
- remoto
- Famoso
- repositório
- solicitadas
- pedidos
- requeridos
- Requisitos
- pesquisa
- resiliente
- resposta
- responsável
- Resultados
- reciclagem
- reutilizável
- papéis
- Execute
- corredor
- sábio
- mesmo
- escalável
- dimensionamento
- cronograma
- programado
- Cientista
- cientistas
- Segundo
- seções
- Setores
- segurança
- senior
- separado
- Serverless
- Servidores
- serviço
- Serviços
- de servir
- conjunto
- instalação
- Shadow
- MUDANÇA
- rede de apoio social
- mostrando
- simples
- folga
- So
- até aqui
- Software
- solução
- Soluções
- alguns
- fonte
- código fonte
- especialista
- específico
- especificada
- Espectro
- Holofote
- Etapa
- Estágio
- padrão
- começo
- começa
- Unidos
- Passos
- armazenamento
- Estratégia
- de streaming
- simplificar
- subseqüente
- entraram com sucesso
- tal
- ajuda
- Suportado
- superfície
- sistemas
- TAG
- Tire
- tarefas
- Profissionais
- modelos
- Terraform
- ensaio
- que
- A
- deles
- Eles
- assim sendo
- Este
- ameaças
- três
- Através da
- todo
- Taxa de transferência
- tempo
- timestamp
- para
- juntos
- também
- ferramenta
- ferramentas
- topo
- tópico
- pista
- Rastreamento
- marcas registradas
- tráfego
- Trem
- treinado
- Training
- desencadear
- desencadeado
- VIRAR
- para
- unidade
- Unido
- Estados Unidos
- Atualizações
- us
- Uso
- usar
- caso de uso
- Utilizador
- usuários
- VALIDAR
- validação
- variáveis
- vário
- versão
- praticamente
- visão
- visualizar
- vmware
- volume
- Caminho..
- BEM
- O Quê
- se
- qual
- Largo
- Ampla variedade
- com
- dentro
- sem
- Atividades:
- de gestão de documentos
- fluxos de trabalho
- trabalho
- seria
- zefirnet
- Zip
- zonas