Introdução
O mundo dos dados de auditoria pode ser complexo, com muitos desafios a serem superados. Um dos maiores desafios é lidar com atributos categóricos ao lidar com conjuntos de dados. Neste artigo, vamos nos aprofundar no mundo da auditoria de dados, detecção de anomalias e o impacto da codificação de atributos categóricos em modelos.
Um dos principais desafios associados à detecção de anomalias para dados de auditoria é lidar com atributos categóricos. A codificação de atributos categóricos é obrigatória porque os modelos não podem interpretar a entrada de texto. Geralmente, isso é feito usando codificação Label ou codificação One Hot. No entanto, em um grande conjunto de dados, a codificação One-hot pode levar a um baixo desempenho do modelo devido à maldição da dimensionalidade.
Objetivos de aprendizagem
-
Entender o conceito de auditoria de dados e o desafio
- Avaliar diferentes métodos de detecção de anomalias profundas não supervisionadas.
- Compreender o impacto da codificação de atributos categóricos em modelos usados para detecção de anomalias em dados de auditoria.
Este artigo foi publicado como parte do Blogathon de Ciência de Dados.
Conteúdo
- O que é Auata?
- O que é detecção de anomalias?
- Principais desafios enfrentados durante a auditoria de dados
- Auditando conjuntos de dados para detecção de anomalias
- Codificação de Atributos Categoriais
- Codificações categóricas
- Modelos de detecção de anomalias não supervisionados
- Como a codificação de atributos categóricos afeta os modelos?
8.1 Representação t-SNE do conjunto de dados de seguro de carro
8.2 Representação t-SNE do conjunto de dados de Seguro de Veículo
8.3 Representação t-SNE do conjunto de dados de Reivindicações de Veículos - Conclusão
em são dados de auditoria?
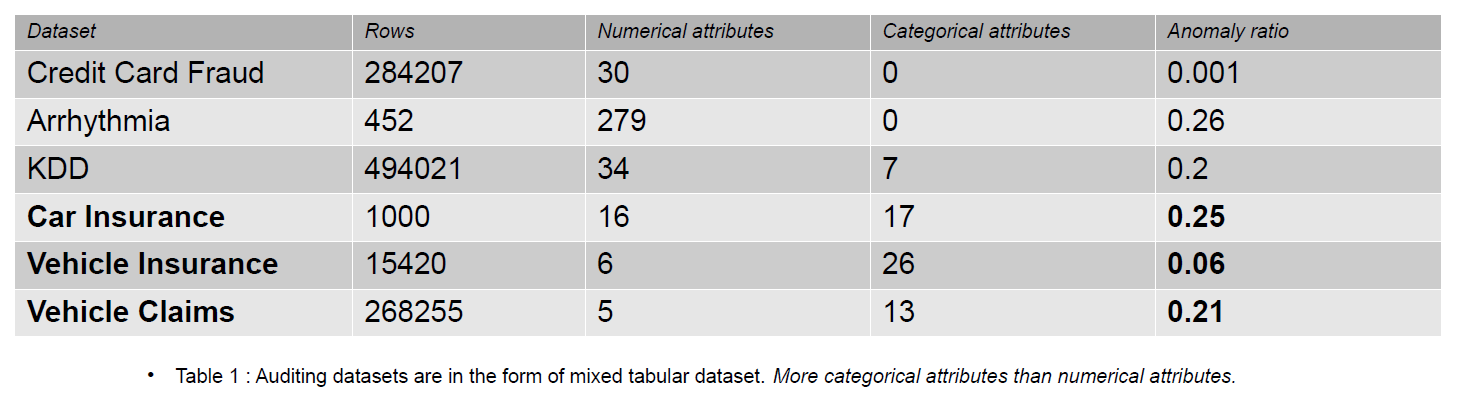
Os dados de auditoria podem incluir diários, reivindicações de seguro e dados de invasão para sistemas de informação; neste artigo, os exemplos fornecidos são sinistros de seguros de veículos. As reivindicações de seguro são distinguíveis dos conjuntos de dados de detecção de anomalias, por exemplo, KDD, por um número maior de características categóricas.
Características categóricas são discutidas em nossos dados que podem ser do tipo inteiro ou caractere. Recursos numéricos são atributos contínuos em nossos dados que sempre têm valor real. Conjuntos de dados com recursos numéricos são populares na comunidade de detecção de anomalias, como dados de fraude de cartão de crédito. A maioria dos conjuntos de dados disponíveis publicamente contém menos recursos categóricos do que os dados de sinistros de seguros. Os recursos categóricos são mais numerosos do que os recursos numéricos nos conjuntos de dados de sinistros de seguros.
Uma reivindicação de seguro inclui recursos como Modelo, Marca, Renda, Custo, Emissão, Cor, etc. O número de recursos categóricos é maior nos dados de auditoria do que nos conjuntos de dados de Cartão de Crédito e KDD. Esses conjuntos de dados são referências em métodos de detecção de anomalias não supervisionados. Conforme visto na tabela abaixo, os conjuntos de dados de sinistros de seguros têm recursos mais categóricos, que são importantes para entender o comportamento dos dados fraudulentos.
Os conjuntos de dados de auditoria usados para avaliar o impacto de codificações categóricas são seguro de carro, seguro de veículo e reclamações de veículo.
O que é detecção de anomalias?
Uma anomalia é uma observação localizada longe dos dados normais em um conjunto de dados por uma distância específica (limiar). Em termos de dados de auditoria, preferimos o termo dados fraudulentos. A detecção de anomalias distingue entre dados normais e fraudulentos usando aprendizado de máquina ou modelo de aprendizado profundo. Métodos diferentes pode ser usado para detecção de anomalias, como estimativa de densidade, erro de reconstrução e métodos de classificação.
- Estimativa de densidade – Esses métodos estimam a distribuição normal de dados e classificam dados anômalos se não tiverem sido amostrados da distribuição aprendida.
- Erro de reconstrução – Métodos baseados em erro de reconstrução são baseados no princípio de que dados normais podem ser reconstruídos com perdas menores do que dados anômalos. Quanto maior a perda de reconstrução, aumentam as chances de que os dados sejam uma anomalia.
- Métodos de classificação - Métodos de classificação como Floresta Aleatória, Isolation Forest, One Class – Support Vector Machines e Local Outlier Factors podem ser usados para detecção de anomalias. A classificação na detecção de anomalias envolve a identificação de uma das classes como a anomalia. Ainda assim, as classes são divididas em dois grupos (0 e 1) no cenário multiclasse, e a classe com menos dados é a classe anômala.
A saída dos métodos acima são pontuações de anomalias ou erros de reconstrução. Então temos que decidir sobre um limite, de acordo com o qual classificamos os dados anômalos.
Principais desafios enfrentados durante a auditoria de dados
- Manipulação de Atributos Categóricos: A codificação de atributos categóricos é obrigatória porque o modelo não pode interpretar a entrada de texto. Portanto, os valores são codificados com codificação Label ou codificação One Hot. Mas em um grande conjunto de dados, One hot encoding transforma os dados em um espaço de alta dimensão aumentando o número de atributos. O modelo tem um desempenho ruim devido ao maldição da dimensionalidade.
- Selecionando o limite para classificação: Se os dados não forem rotulados, é difícil avaliar o desempenho do modelo porque não sabemos o número de anomalias presentes no conjunto de dados. O conhecimento prévio sobre o conjunto de dados facilita a determinação do limite. Digamos que temos 5 de 10 amostras anômalas em nossos dados. Portanto, podemos selecionar o limite na pontuação do percentil 50.
- Conjuntos de dados públicos: A maioria dos conjuntos de dados de auditoria são confidenciais porque pertencem a empresas corporativas e contêm informações confidenciais e pessoais. Uma maneira possível de mitigar os problemas de confidencialidade é treinar usando conjuntos de dados sintéticos (reivindicações de veículos).
Auditando conjuntos de dados para detecção de anomalias
As reivindicações de seguro para veículos incluem informações sobre as propriedades do veículo, como modelo, marca, preço, ano e tipo de combustível. Inclui informações sobre o motorista, data de nascimento, sexo e profissão. Além disso, a reclamação pode incluir informações sobre o custo total do reparo. Os conjuntos de dados usados neste artigo são todos de um único domínio, mas variam no número de atributos e no número de instâncias.
-
O conjunto de dados Vehicle Claims é grande, contendo mais de 250,000 linhas, e seus atributos categóricos têm uma cardinalidade de 1171. Devido ao seu grande tamanho, esse conjunto de dados sofre da maldição da dimensionalidade.
- O conjunto de dados de seguro de veículos é de tamanho médio, com 15,420 linhas e 151 valores categóricos exclusivos. Isso o torna menos propenso a sofrer com a maldição da dimensionalidade.
- O conjunto de dados Car Insurance é pequeno, com rótulos e 25% de amostras anômalas, e contém um número semelhante de características numéricas e categóricas. Com 169 categorias únicas, não sofre da maldição da dimensionalidade.
Codificação de Atributos Categóricos
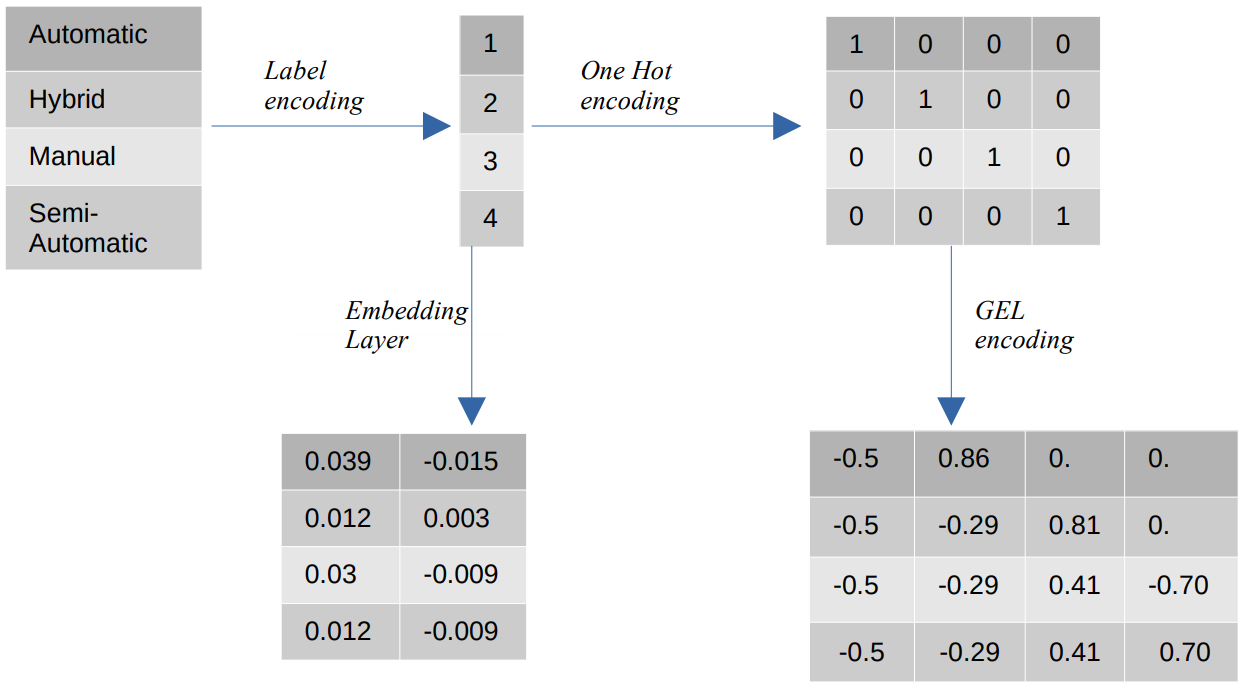
Diferentes codificações de valores categóricos
- Codificação de etiquetas – Na codificação de rótulo, os valores categóricos são substituídos por valores numéricos inteiros entre 1 e o número de categorias. A codificação de rótulo representa as categorias da maneira pretendida para valores ordinais. Ainda assim, quando as feições são nominais, a representação é incorreta, pois os valores categóricos não obedecem a uma ordem específica.
Por exemplo, se tivermos categorias como Automático, Híbrido, Manual e Semiautomático em um recurso, a codificação de rótulo transformará esses valores em {1: Automático, 2: Híbrido, 3: Manual, 4:Semiautomático}. Essa representação não fornece informações sobre os valores categóricos, mas uma representação como {0: Baixo, 1: Médio, 2: Alto} fornece uma representação clara porque a variável de recurso Baixo recebe um valor numérico inferior. Portanto, a codificação de rótulo é melhor para valores ordinais, mas desvantajosa para valores nominais. - Uma codificação a quente – Uma codificação Hot é usada para resolver o problema de valores de codificação nominais, que transforma cada valor categórico em um recurso distinto no conjunto de dados que consiste em valores binários. Por exemplo, no caso de quatro categorias diferentes codificadas como {1, 2, 3, 4}, a codificação One Hot criaria novos recursos, como {Automático: [1,0,0,0], Híbrido: [0,1,0,0 ,0,0,1,0], Manual: [0,0,0,1], Semiautomático: [XNUMX]}.
A dimensão do conjunto de dados depende diretamente do número de categorias presentes no conjunto de dados. Como resultado, a codificação One Hot pode levar à maldição da dimensionalidade, que é uma desvantagem desse método de codificação. - Codificação GEL – A codificação GEL é uma técnica de incorporação que pode ser usada em métodos de aprendizado supervisionados e não supervisionados. Ele é baseado no princípio da codificação One Hot e pode ser usado para diminuir a dimensionalidade de recursos categóricos que foram codificados usando a codificação One Hot.
- Incorporando Camada - As incorporações de palavras fornecem uma maneira de usar uma representação compacta e densa na qual palavras semelhantes têm codificações semelhantes. Uma incorporação é um vetor denso de valores de ponto flutuante que são parâmetros treináveis. As incorporações de palavras podem variar de 8 dimensões (para pequenos conjuntos de dados) a 1024 dimensões (para grandes conjuntos de dados).
Uma incorporação dimensional mais alta pode capturar relacionamentos mais detalhados entre as palavras, mas requer mais dados para aprender. A camada de incorporação é uma tabela de pesquisa que converte cada palavra presente na matriz em um vetor de tamanho específico.
Modelos de detecção de anomalias não supervisionados
No mundo real, os dados não são rotulados na maioria dos casos, e rotular os dados é caro e demorado. Portanto, usaremos modelos não supervisionados para nossas avaliações.
- SOM - O Self-Organizing Map (SOM) é um método de aprendizado competitivo em que os pesos dos neurônios são atualizados competitivamente, em vez de usar o aprendizado de retropropagação. O SOM consiste em um mapa de neurônios, cada um com um vetor de peso do mesmo tamanho do vetor de entrada. O vetor de peso é inicializado com pesos aleatórios antes do início do treinamento. Durante o treinamento, cada entrada é comparada aos neurônios do mapa com base em uma métrica de distância (por exemplo, distância euclidiana) e é mapeada para a Best Matching Unit (BMU), que é o neurônio com a distância mínima ao vetor de entrada.
Os pesos da BMU são atualizados com os pesos do vetor de entrada e os neurônios vizinhos são atualizados com base no raio da vizinhança (sigma). Como os neurônios competem entre si para ser a melhor unidade correspondente, esse processo é conhecido como aprendizado competitivo. No final, os neurônios para amostras normais estão mais próximos do que os anômalos. As pontuações de anomalia são definidas pelo erro de quantização, que é a diferença entre a amostra de entrada e os pesos da melhor unidade correspondente. Um erro de quantização maior indica uma probabilidade maior de a amostra ser uma anomalia. - DAGMM – O Deep Autoencoding Gaussian Mixture Model (DAGMM) é um método de estimativa de densidade que assume que as anomalias estão em uma região de baixa probabilidade. A rede é dividida em duas partes: uma rede de compressão, que é usada para projetar dados em dimensões menores usando um autoencoder, e uma rede de estimação, que é usada para estimar os parâmetros do modelo de mistura gaussiana. DAGMM estima k número de misturas gaussianas, onde k pode ser qualquer número de 1 a N (o número de pontos de dados), e assume-se que os pontos normais estão em uma região de alta densidade, o que significa que a probabilidade de ser amostrado de um A mistura gaussiana é maior para pontos normais do que para amostras anômalas. As pontuações de anomalia são definidas pela energia estimada da amostra.
- RSRAE – A camada de recuperação de superfície robusta para detecção de anomalias não supervisionada é um método de reconstrução de erros que primeiro projeta os dados em uma dimensão inferior usando um codificador automático. A representação latente é então submetida a uma projeção ortogonal em um subespaço linear robusto a outliers. O decodificador então reconstrói a saída do subespaço linear. Nesse método, um erro de reconstrução maior indica uma probabilidade maior de a amostra ser uma anomalia.
- SOM-DAGMM- Um mapa auto-organizado (SOM) - modelo de mistura gaussiana de codificação automática profunda (DAGMM) também é um modelo de estimativa de densidade. Como o DAGMM, ele também estima a distribuição de probabilidade de pontos de dados normais e classifica um ponto de dados como uma anomalia se tiver uma baixa probabilidade de ser amostrado da distribuição aprendida. A principal diferença entre o SOM-DAGMM e o DAGMM é que o SOM-DAGMM inclui as coordenadas normalizadas do SOM para a amostra de entrada, que fornece as informações topológicas ausentes no caso do DAGMM para a rede de estimativa. O objetivo também é semelhante ao DAGMM em que as pontuações de anomalia são definidas pela energia estimada da amostra, e baixa energia indica uma probabilidade maior da amostra como uma anomalia.
A seguir, abordaremos o desafio de lidar com atributos categóricos.
Como a codificação de atributos categóricos afeta os modelos?
Para entender o impacto de diferentes codificações em conjuntos de dados, usaremos t-SNE para visualizar as representações de baixa dimensão dos dados para diferentes codificações. O t-SNE projeta dados de alta dimensão em um espaço de dimensão inferior, facilitando a visualização. Ao comparar as visualizações t-SNE e os resultados numéricos de diferentes codificações do mesmo conjunto de dados, a diferença é observada nas representações resultantes e na compreensão do impacto da codificação no conjunto de dados.
Representação t-SNE do conjunto de dados de seguro de carro
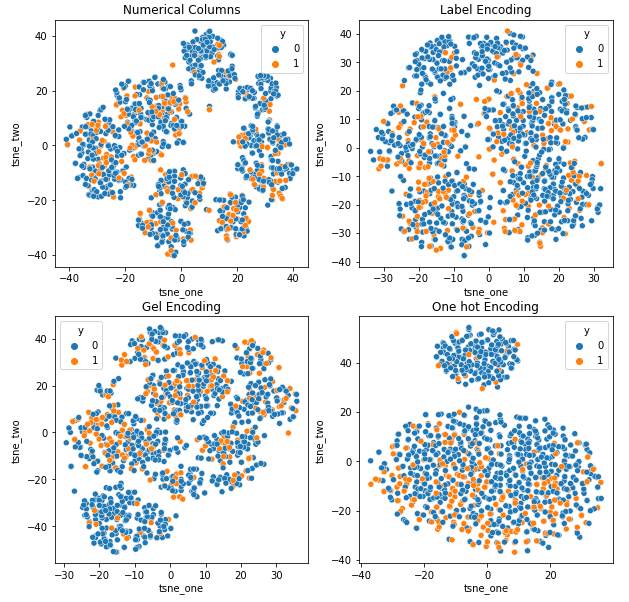
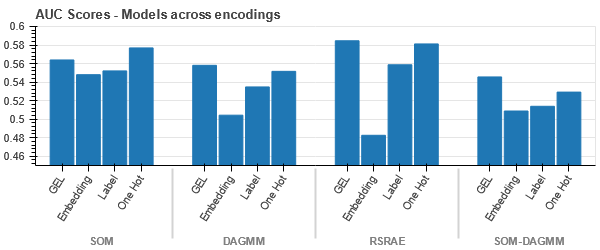
Representação t-SNE do conjunto de dados de seguro de veículos
-
Os dados estão mais próximos uns dos outros porque o número de linhas é maior do que no conjunto de dados Car Insurance. Torna-se difícil separar com dimensionalidade aumentada na codificação One Hot.
-
A codificação GEL é melhor do que a codificação One Hot em todos os casos, exceto DAGMM.
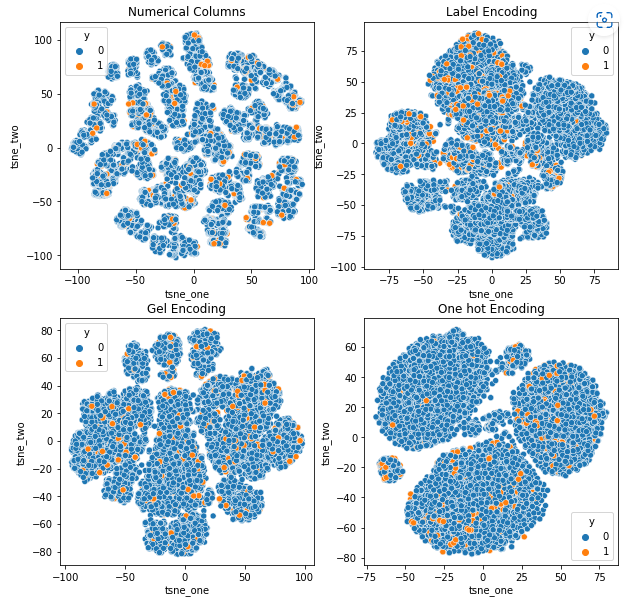
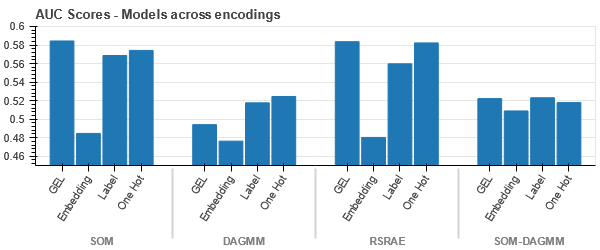
Representação t-SNE do conjunto de dados de reivindicações de veículos
-
Os dados são fortemente vinculados em todos os casos, dificultando a separação com maior dimensionalidade. Esta é uma das razões para o baixo desempenho dos modelos devido ao aumento da dimensionalidade.
- O SOM supera todos os outros modelos para este conjunto de dados. Ainda assim, a camada de incorporação é mais adequada na maioria dos casos, o que nos permite uma alternativa à codificação atributos categóricos para detecção de anomalias.
Conclusão
Este artigo apresenta uma breve visão geral dos dados de auditoria, detecção de anomalias e codificações categóricas. É importante entender que lidar com atributos categóricos em dados de auditoria é um desafio. Ao entender o impacto da codificação dos atributos nos modelos, podemos melhorar a precisão da detecção de anomalias nos conjuntos de dados. As principais conclusões deste artigo são:
- À medida que o tamanho dos dados aumenta, é importante usar abordagens de codificação alternativas para atributos categóricos, como codificação GEL e camadas de incorporação, porque a codificação One Hot não é adequada.
- Um modelo não funciona para todos os conjuntos de dados. Para conjuntos de dados tabulares, o conhecimento do domínio é extremamente importante.
- A escolha do método de codificação depende da escolha do modelo.
O código para avaliação de modelos está disponível em GitHub.
A mídia mostrada neste artigo não é propriedade da Analytics Vidhya e é usada a critério do Autor.
Relacionado
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://www.analyticsvidhya.com/blog/2023/01/impact-of-categorical-encodings-on-anomaly-detection-methods/
- 000
- 1
- 10
- 420
- a
- Sobre
- acima
- Segundo
- precisão
- Adicionalmente
- endereço
- Todos os Produtos
- permite
- alternativa
- sempre
- analítica
- Análise Vidhya
- e
- detecção de anomalia
- se aproxima
- artigo
- atribuído
- associado
- assumiu
- atributos
- auditoria
- Automático
- disponível
- baseado
- Porque
- torna-se
- antes
- ser
- abaixo
- benchmarks
- MELHOR
- Melhor
- entre
- O maior
- obrigado
- interesse?
- não podes
- capturar
- carro
- seguro de carro
- cartão
- casas
- casos
- Categorias
- desafiar
- desafios
- desafiante
- chances
- personagem
- escolha
- reivindicar
- reivindicações
- classe
- aulas
- classificação
- classificar
- remover filtragem
- mais próximo
- código
- cor
- geralmente
- comunidade
- Empresas
- comparado
- comparando
- competir
- competitivo
- integrações
- conceito
- confidencialidade
- Consistindo
- contém
- contínuo
- Responsabilidade
- Custo
- crio
- crédito
- cartão de crédito
- dados,
- Os pontos de dados
- conjuntos de dados
- Data
- lidar
- diminuir
- profundo
- deep learning
- depende
- detalhado
- Detecção
- Determinar
- diferença
- diferente
- difícil
- Dimensão
- dimensões
- diretamente
- critério
- distância
- distinto
- distribuição
- dividido
- domínio
- motorista
- durante
- cada
- mais fácil
- ou
- energia
- erro
- erros
- estimativa
- estimado
- estimativas
- etc.
- avaliar
- avaliação
- avaliações
- exemplo
- exemplos
- Exceto
- caro
- extremamente
- enfrentou
- fatores
- Característica
- Funcionalidades
- Primeiro nome
- floresta
- fraude
- fraudulento
- da
- Combustível
- Gênero
- Do grupo
- Manipulação
- Alta
- superior
- HOT
- Contudo
- HTTPS
- HÍBRIDO
- identificar
- Impacto
- importante
- melhorar
- in
- incluir
- inclui
- Passiva
- aumentou
- Aumenta
- aumentando
- indicam
- INFORMAÇÕES
- Sistemas de Informação
- entrada
- com seguro
- isolamento
- emitem
- questões
- IT
- Chave
- Saber
- Conhecimento
- conhecido
- O rótulo
- marcação
- Rótulos
- grande
- Maior
- camada
- camadas
- conduzir
- APRENDER
- aprendido
- aprendizagem
- local
- localizado
- pesquisa
- fora
- perdas
- Baixo
- máquina
- aprendizado de máquina
- máquinas
- a Principal
- FAZ
- Fazendo
- obrigatório
- manual
- muitos
- mapa,
- correspondente
- Matriz
- significado
- Mídia
- média
- método
- métodos
- métrico
- mínimo
- desaparecido
- Mitigar
- mistura
- modelo
- modelos
- mais
- a maioria
- rede
- Neurônios
- Novo
- Novos Recursos
- normal
- número
- objetivo
- ONE
- ordem
- Outros
- Supera o desempenho
- Superar
- Visão geral
- propriedade
- parâmetros
- parte
- peças
- atuação
- executa
- pessoal
- platão
- Inteligência de Dados Platão
- PlatãoData
- ponto
- pontos
- pobre
- Popular
- possível
- preferir
- presente
- presentes
- preço
- princípio
- Prévio
- probabilidade
- Problema
- processo
- profissão
- projeto
- dados do projeto
- Projeção
- projetos
- Propriedades
- fornecer
- fornecido
- fornece
- publicado
- acaso
- alcance
- reais
- mundo real
- razões
- recuperação
- região
- Relacionamentos
- reparação
- substituído
- representação
- representa
- exige
- resultar
- resultando
- Resultados
- uma conta de despesas robusta
- mesmo
- Ciência
- sensível
- separado
- mostrando
- Sigma
- semelhante
- desde
- solteiro
- Tamanho
- pequeno
- menor
- So
- Espaço
- específico
- começa
- Ainda
- tal
- Sofre
- adequado
- ajuda
- superfície
- sintético
- sistemas
- mesa
- Takeaways
- condições
- A
- o mundo
- assim sendo
- limiar
- hermeticamente
- demorado
- para
- Total
- Trem
- Training
- compreender
- compreensão
- único
- unidade
- aprendizado não supervisionado
- Atualizada
- us
- usar
- valor
- Valores
- veículo
- Veículos
- peso
- O Quê
- O que é a
- qual
- enquanto
- precisarão
- Word
- palavras
- Atividades:
- mundo
- seria
- ano
- zefirnet